Node.js精進(2)——非同步程式設計
雖然 Node.js 是單執行緒的,但是在融合了libuv後,使其有能力非常簡單地就構建出高效能和可延伸的網路應用程式。
下圖是 Node.js 的簡單架構圖,基於 V8 和 libuv,其中 Node Bindings 為 JavaScript 和 C++ 搭建了一座溝通的橋樑,使得 JavaScript 可以存取 V8 和 libuv 向上層提供的 API。

本系列所有的範例原始碼都已上傳至Github,點選此處獲取。
一、術語解析
接下來會對幾個與 Node.js 相關的術語做單獨的解析,其中事件迴圈會單獨細講。
1)libuv
libuv 是一個事件驅動、非阻塞非同步的 I/O 庫,並且具備跨平臺的能力,提供了一套事件迴圈(Event Loop)機制和一些核心工具,例如定時器、檔案存取、執行緒池等。
2)非阻塞非同步的I/O
非阻塞是指執行緒不會被作業系統掛起,可以處理其他事情。
非同步是指呼叫者發起一個呼叫後,可以立即返回去做別的事。
I/O(Input/Output)即輸入/輸出,通常指資料在記憶體或其他周邊裝置之間的輸入和輸出。
它是資訊處理系統(例如計算機)與外部世界(可能是人類或另一資訊處理系統)之間的通訊。
將這些關鍵字組合在一起就能理解 Node.js 的高效能有一部分是通過避免等待 I/O(讀寫資料庫、檔案存取、網路呼叫等)響應來實現的。
3)事件驅動
事件驅動是一種非同步化的程式設計模型,通過使用者動作、作業系統或應用程式產生的事件,來驅動程式完成某個操作。
在 Node.js 中,事件主要來源於網路請求、檔案讀寫等,它們會被事件迴圈所處理。
在瀏覽器的 DOM 系統中使用的也非常廣泛,例如為按鈕繫結 click 事件,在用點選按鈕時,彈出提示或提交表單等。
4)單執行緒
Node.js 的單執行緒是指執行 JavaScript 程式碼的主執行緒,網路請求或非同步任務等都交給了底層的執行緒池中的執行緒來處理,其處理結果再通過事件迴圈向主執行緒告知。
單執行緒意味著所有任務需要排隊有序執行,如果出現一個計算時間很長的任務,那麼就會佔據主執行緒,其他任務只能等待,所以說 Node.js 不適合 CPU 密集型的場景。
經過以上術語的分析可知,Node.js 的高效能和高並行離不開非同步,所以有必要深入瞭解一下 Node.js 的非同步原理。
二、事件迴圈
當 Node.js 啟動時會初始化事件迴圈,這是一個無限迴圈。
下圖是事件迴圈的一張執行機制圖,新任務或完成 I/O 任務的回撥,都會新增到事件迴圈中。
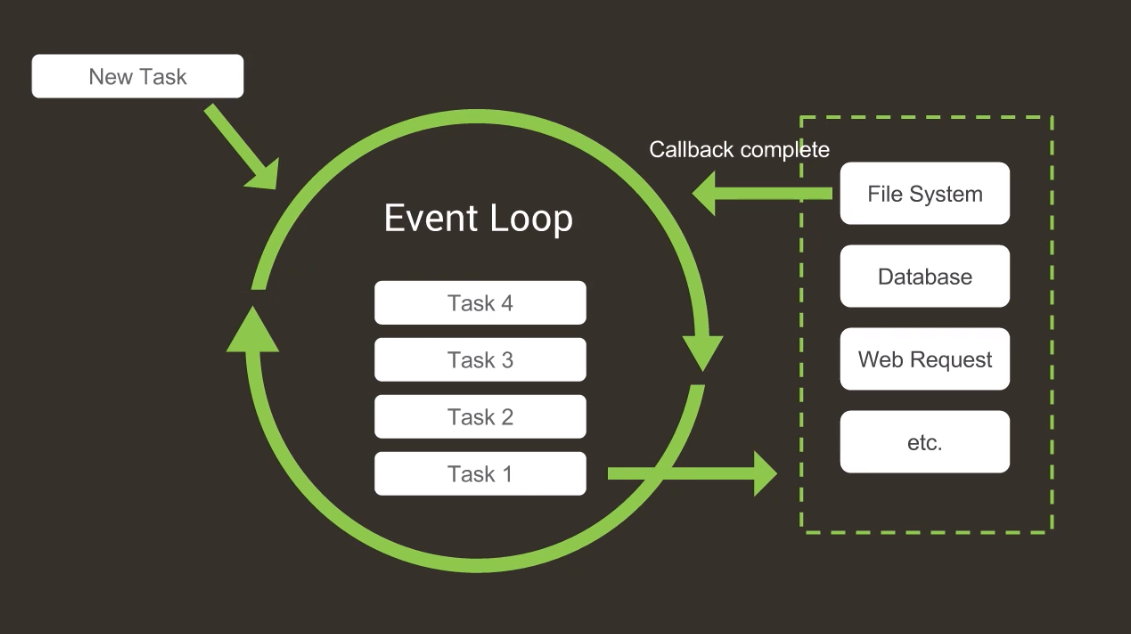
下面是按照執行優先順序簡化後的六個迴圈階段。
┌───────────────────────────┐ ┌─>│ timers │ │ └─────────────┬─────────────┘ │ ┌─────────────┴─────────────┐ │ │ pending callbacks │ │ └─────────────┬─────────────┘ │ ┌─────────────┴─────────────┐ │ │ idle, prepare │ │ └─────────────┬─────────────┘ ┌───────────────┐ │ ┌─────────────┴─────────────┐ │ incoming: │ │ │ poll │<─────┤ connections, │ │ └─────────────┬─────────────┘ │ data, etc. │ │ ┌─────────────┴─────────────┐ └───────────────┘ │ │ check │ │ └─────────────┬─────────────┘ │ ┌─────────────┴─────────────┐ └──┤ close callbacks │ └───────────────────────────┘
每個階段都有一個 FIFO 回撥佇列,當佇列耗盡或達到回撥上限時,事件迴圈將進入下一階段,如此往復。
- timers:執行由 setTimeout() 和 setInterval() 安排的回撥。在此階段內部,會維護一個定時器的小頂堆,按到期時間排序,先到期的先執行。
- pending callbacks:處理上一輪迴圈未執行的 I/O 回撥,例如網路、I/O 等異常時的回撥。
- idle,prepare:僅 Node 內部使用。
- poll:執行與 I/O 相關的回撥,除了關閉回撥、定時器排程的回撥和 setImmediate() , 適當的條件下 Node 將阻塞在這裡。
- check:呼叫 setImmediate() 回撥。
- close callbacks:關閉回撥,例如 socket.on("close", callback)。
在deps/uv/src/unix/core.c檔案中宣告了事件迴圈的核心程式碼,旁邊還有個 win 目錄,應該就是指 Windows 系統中 libuv 相關的處理。
其實事件迴圈就是一個大的 while 迴圈 ,具體如下所示。
程式碼中的 UV_RUN_ONCE 就是上文 poll 階段中的適當的條件,在每次迴圈結束前,執行完 close callbacks 階段後,會再執行一次已到期的定時器。
static int uv__loop_alive(const uv_loop_t* loop) { return uv__has_active_handles(loop) || uv__has_active_reqs(loop) || loop->closing_handles != NULL; } int uv_run(uv_loop_t* loop, uv_run_mode mode) { int timeout; int r; int ran_pending; // 檢查事件迴圈中是否還有待處理的handle、request、closing_handles是否為NULL r = uv__loop_alive(loop); // 更新事件迴圈時間戳 if (!r) uv__update_time(loop); // 啟動事件迴圈 while (r != 0 && loop->stop_flag == 0) { uv__update_time(loop); uv__run_timers(loop); // timers階段,執行已到期的定時器 ran_pending = uv__run_pending(loop); // pending階段 uv__run_idle(loop); // idle階段 uv__run_prepare(loop);// prepare階段 timeout = 0; if ((mode == UV_RUN_ONCE && !ran_pending) || mode == UV_RUN_DEFAULT) timeout = uv_backend_timeout(loop); uv__io_poll(loop, timeout); // poll階段 /* Run one final update on the provider_idle_time in case uv__io_poll * returned because the timeout expired, but no events were received. This * call will be ignored if the provider_entry_time was either never set (if * the timeout == 0) or was already updated b/c an event was received. */ uv__metrics_update_idle_time(loop); uv__run_check(loop); // check階段 uv__run_closing_handles(loop); // close階段 if (mode == UV_RUN_ONCE) { /* UV_RUN_ONCE implies forward progress: at least one callback must have * been invoked when it returns. uv__io_poll() can return without doing * I/O (meaning: no callbacks) when its timeout expires - which means we * have pending timers that satisfy the forward progress constraint. * * UV_RUN_NOWAIT makes no guarantees about progress so it's omitted from * the check. */ uv__update_time(loop); uv__run_timers(loop); // 執行已到期的定時器 } r = uv__loop_alive(loop); // 在 UV_RUN_ONCE 和 UV_RUN_NOWAIT 模式中,跳出當前迴圈 if (mode == UV_RUN_ONCE || mode == UV_RUN_NOWAIT) break; } /* The if statement lets gcc compile it to a conditional store. Avoids * dirtying a cache line. */ if (loop->stop_flag != 0) loop->stop_flag = 0; // 標記當前的 stop_flag 為 0,表示跑完這輪,事件迴圈就結束了 return r; }
1)setTimeout 和 setImmediate
setTimeout 會在最前面的 timers 階段被執行,而 setImmediate 會在 check 階段被執行。
但在下面的範例中,timeout 和 immediate 的列印順序是不確定的。
在 setTimeout() 官方檔案中曾提到,當延遲時間大於 2147483647(24.8天) 或小於 1 時,將預設被設為 1。
所以下面的 setTimeout(callback, 0) 相當於 setTimeout(callback, 1)。
雖然在原始碼中會先執行 uv__run_timers(),但是由於上一次的迴圈耗時可能超過 1ms,也可能小於 1ms,所以定時器有可能還未到期。
如此的話,就會造成列印順序的不確定性,上述分析過程參考了此處。
setTimeout(() => { console.log('timeout') }, 0); setImmediate(() => { console.log('immediate') });
如果將 setTimeout() 和 setImmediate() 註冊到 I/O 回撥中執行,那麼順序就是確定的,先 immediate 再 timeout。
const fs = require('fs')
fs.readFile(__filename, () => {
setTimeout(() => {
console.log('timeout');
}, 0)
setImmediate(() => {
console.log('immediate')
})
});
這是因為 readFile() 的回撥會在 poll 階段執行,而在 uv__io_poll() 之後,就會立即執行 uv__run_check(),從而就能保證先列印 immediate 。
在自己的日常工作中,曾使用過一個基於 setTimeout() 的定時任務庫:node-schedule。
由於延遲時間最長為 24.8 天,所以該庫巧妙的運用了一個遞回來彌補時間的上限。
Timeout.prototype.start = function() { if (this.after <= TIMEOUT_MAX) { this.timeout = setTimeout(this.listener, this.after) } else { var self = this this.timeout = setTimeout(function() { self.after -= TIMEOUT_MAX self.start() }, TIMEOUT_MAX) } if (this.unreffed) { this.timeout.unref() } }
2)與瀏覽器中的事件迴圈的差異
在瀏覽器的事件迴圈中,沒有那麼細的迴圈階段,不過有兩個非常重要的概念,那就是宏任務和微任務。
宏任務包括 setTimeout()、setInterval()、requestAnimationFrame、Ajax、fetch()、指令碼標籤程式碼等。
微任務包括 Promise.then()、MutationObserver。
在 Node.js 中,process.nextTick()是微任務的一種,setTimeout()、setInterval()、setImmediate() 等都屬於宏任務。
在 Node版本 < 11 時,執行完一個階段的所有任務後,再執行process.nextTick(),最後是其他微任務。
可以這樣理解,process.nextTick() 維護了一個獨立的佇列,不存在於事件迴圈的任何階段,而是在各個階段切換的間隙執行。
即從一個階段切換到下個階段前執行,執行時機如下所示。
┌───────────────────────────┐ ┌─>│ timers │ │ └─────────────┬─────────────┘ │ nextTickQueue │ ┌─────────────┴─────────────┐ │ │ pending callbacks │ │ └─────────────┬─────────────┘ │ nextTickQueue │ ┌─────────────┴─────────────┐ │ │ idle, prepare │ │ └─────────────┬─────────────┘ nextTickQueue nextTickQueue │ ┌─────────────┴─────────────┐ │ │ poll │ │ └─────────────┬─────────────┘ │ nextTickQueue │ ┌─────────────┴─────────────┐ │ │ check │ │ └─────────────┬─────────────┘ │ nextTickQueue │ ┌─────────────┴─────────────┐ └──┤ close callbacks │ └───────────────────────────┘
但是在 Node 版本 >= 11 之後,會處理的和瀏覽器一樣,也是每執行完一個宏任務,就將其微任務也一併完成。
在下面這個範例中, setTimeout() 內先宣告 then(),再宣告 process.nextTick(),最後執行一條列印語句。
接著在 setTimeout() 之後再次宣告了 process.nextTick()。
// setTimeout setTimeout(() => { Promise.resolve().then(function() { console.log('promise'); }); process.nextTick(() => { console.log('setTimeout nextTick'); }); console.log('setTimeout'); }, 0); // nextTick process.nextTick(() => { console.log('nextTick'); });
我本地執行的 Node 版本是 16,所以最終的列印順序如下所示。
nextTick
setTimeout
setTimeout nextTick
promise
外面的 process.nextTick() 要比 setTimeout() 先執行,裡面的列印語句最先執行,然後是 process.nextTick(),最後是 then()。
3)sleep()
有一道比較經典的題目是編寫一個 sleep() 函數,實現執行緒睡眠,在日常開發中很容易就會遇到。
蒐集了多種實現函數,有些是同步,有些是非同步。
第一種是同步函數,建立一個迴圈,佔用主執行緒,直至迴圈完畢,這種方式也叫回圈空轉,比較浪費CPU效能,不推薦。
function sleep(ms) { var start = Date.now(), expire = start + ms; while (Date.now() < expire); }
第二至第四種都是非同步函數,本質上執行緒並沒有睡眠,事件迴圈仍在執行,下面是 Promise + setTimeout() 組合實現的 sleep() 函數。
function sleep(ms) { return new Promise(resolve => setTimeout(resolve, ms)); }
第三種是利用 util 庫的promisify()函數,返回一個 Promise 版本的定時器。
function sleep(ms) { const { promisify } = require('util'); return promisify(setTimeout)(ms); }
第四種是當 Node 版本 >= 15 時可以使用,在timers庫中直接得到一個 Promise 版本的定時器。
function sleep(ms) { const { setTimeout } = require('timers/promises'); return setTimeout(ms); }
第五種是同步函數,可利用Atomics.wait阻塞事件迴圈,直至執行緒超時,實現細節在此不做說明了。
function sleep(ms) { const sharedBuf = new SharedArrayBuffer(4); const sharedArr = new Int32Array(sharedBuf); return Atomics.wait(sharedArr, 0, 0, ms); }
還可以編寫 C/C++ 外掛,直接呼叫作業系統的 sleep() 函數,此處不做展開。
參考資料:
JavaScript 執行機制詳解:再談Event Loop
Node.js Event Loop 的理解 Timers,process.nextTick()
瀏覽器與Node的事件迴圈(Event Loop)有何區別?
Why is the EventLoop for Browsers and Node.js Designed This Way?
Node.js 事件迴圈 Phases of the Node JS Event Loop