阿里雲一面:並行場景下的底層細節
最近看書看到的偽共用問題,直接觸碰到知識盲區了,之前確實沒聽說過這個東西,開啟百度就像吃飯一樣自然。
雖然面經上出現的次數不多,不過我覺得還是很重要的一個問題,而且不難,花個五分鐘就能弄清楚~
老規矩,背誦版在文末。公眾號【飛天小牛肉】定期更新大廠面試題,提供背誦版和詳解版
三級快取架構
眾所周知,為了緩解記憶體和 CPU 之間速度不匹配的矛盾,引入了快取記憶體這個東西,它的容量比記憶體小很多,但是交換速度卻比記憶體要快得多。
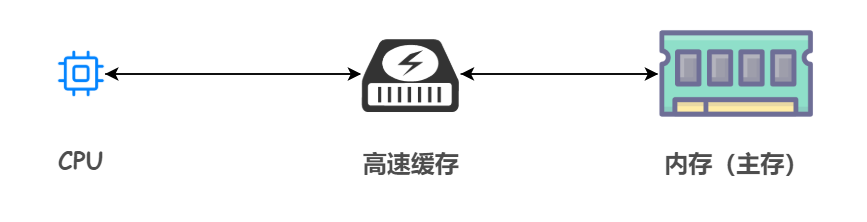
之前我們畫過這樣的分級儲存體系結構:
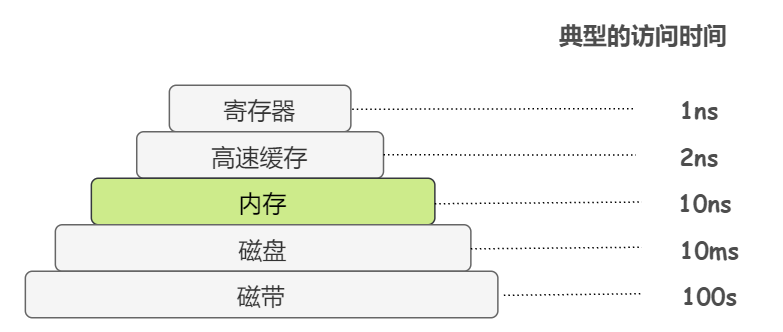
事實上,快取記憶體仍然存在細分,也稱為三級快取結構:一級(L1)快取、二級(L2)快取、三級(L3)快取
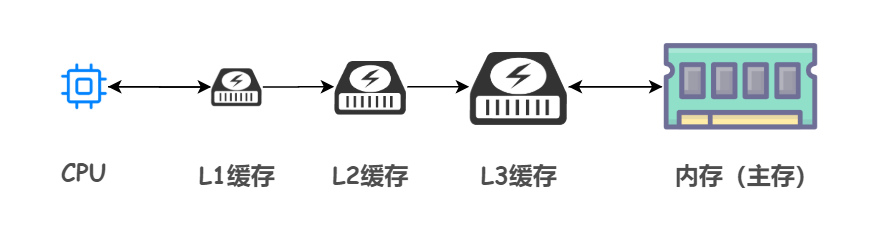
越靠近 CPU 的快取,速度越快,容量也越小。所以 L1 快取容量最小但是速度最快;L3 快取容量最大同時速度也最慢
當 CPU 執行運算的時候,它會先去 L1 快取查詢所需的資料、如果沒有找到的話就再去 L2 快取、然後是 L3 快取,如果最後這三級快取中都沒有命中,那麼 CPU 就要去存取記憶體了。
顯然,CPU 走得越遠,運算耗費的時間就越長。所以儘量確保資料存在 L1 快取中能夠提升大計算量情況下的執行速度。
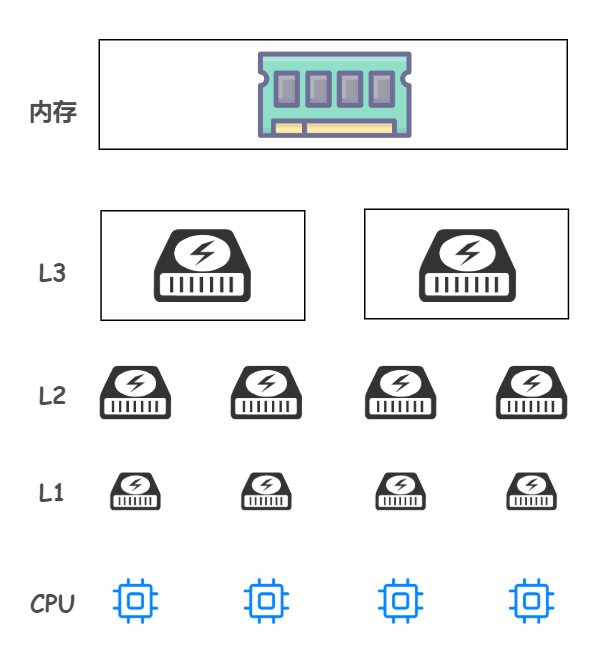
需要注意的是,CPU 和三級快取以及記憶體的對應使用關係:
- L1 和 L2 都是隻能被一個單獨的 CPU 核心使用
- L3 可以被單個插槽上的所有 CPU 核心共用
- 記憶體由全部插槽上的所有 CPU 核心共用
如下圖所示:
另外,這三級快取空間中的資料是如何組織起來的呢?換句話說,資料在這三級快取中的儲存形式是什麼樣的呢?
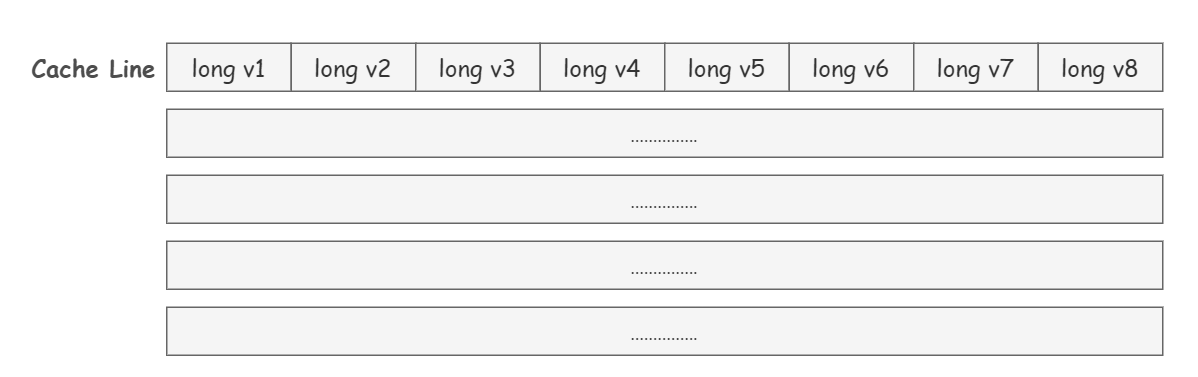
Cache Line(快取行)!
快取中的基本儲存單元就是 Cache Line。
每個 Cache Line 通常是 64 位元組,也就是說,一個 Java 的 long 型別變數是 8 位元組,一個 Cache Line 中可以存 8 個 long 型別的變數。
所以小夥伴們看出來了嗎~ 快取中的資料並不是按照一個一個單獨的變數這樣儲存組織起來的,而是多個變數會放到一行中。
偽共用問題 False Sharing
說了這麼多似乎還並未觸及偽共用問題,別急,我們離真相已經很近~
在程式執行的過程中,由於快取的基本單元 Cache Line 是 64 位元組,所以快取每次更新都會從記憶體中載入連續的 64 個位元組。
如果存取的是一個 long 型別陣列的話,當陣列中的一個值比如 v1 被載入到快取中時,接下來地址相鄰的 7 個元素也會被載入到快取中。(這也能解釋為啥我們陣列總是能夠這麼快,像連結串列這種離散儲存的資料結構,就無法享受到這種紅利)。
But,這波紅利很可能帶來無妄之災。
舉個例子,如果我們定義了兩個 long 型別的變數 a 和 b,他們在記憶體中的地址是緊挨著的,會出現什麼問題?
如果我們想要存取 a 的話,那麼 b 也會被儲存到快取中來。
懵了懵了,這有什麼問題嗎,看起來似乎沒有什麼毛病,多麼 nice 的特性啊
來來來,直接上個例子
回想下上文提到的 CPU 和三級快取以及記憶體的對應使用關係,設想這種情況,如果一個 CPU 核心的執行緒 T1 在對 a 進行修改,另一個 CPU 核心的執行緒 T2 卻在對 b 進行讀取。
當 T1 修改 a 的時候,除了把 a 載入到 Cache Line,還會享受一波紅利,把 b 同時也載入到 T1 所處 CPU 核心的 Cache Line 中來,對吧。
根據 MESI 快取一致性協定,修改完 a 後這個 Cache Line 的狀態就是 M(Modify,已修改),而其它所有包含 a 的 Cache Line 中的 a 就都不是最新值了,所以都將變為 I 狀態(Invalid,無效狀態)
這樣,當 T2 來讀取 b 時,誒,發現他所處的 CPU 核心對應的這個 Cache Line 已經失效了,mmp,它就需要花費比較長的時間從記憶體中重新載入了。
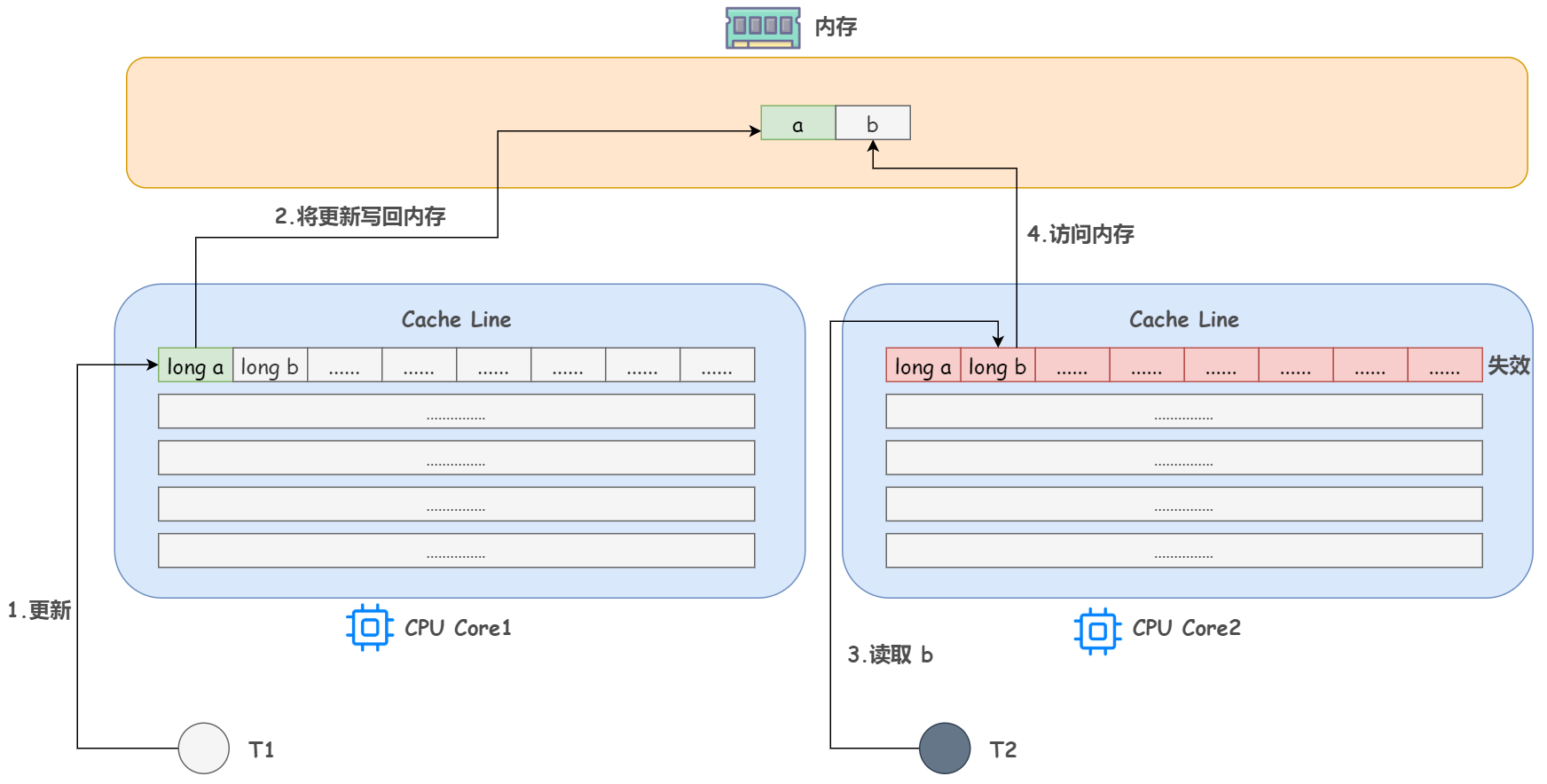
問題已經顯而易見了,b 和 a 沒有任何關係,每次卻要因為 a 的更新導致他需要從記憶體中重新讀取,拖慢了速度。這就是偽共用
表面上 a 和 b 都是被獨立執行緒操作的,而且兩操作之間也沒有任何關係。只不過它們共用了一個快取行,但所有競爭衝突都是來源於共用。
用更書面的解釋來定義偽共用:當多執行緒修改互相獨立的變數時,如果這些變數共用同一個快取行,就會無意中影響彼此的效能,導致無法充分利用快取行特性,這就是偽共用。
偽共用解決方案
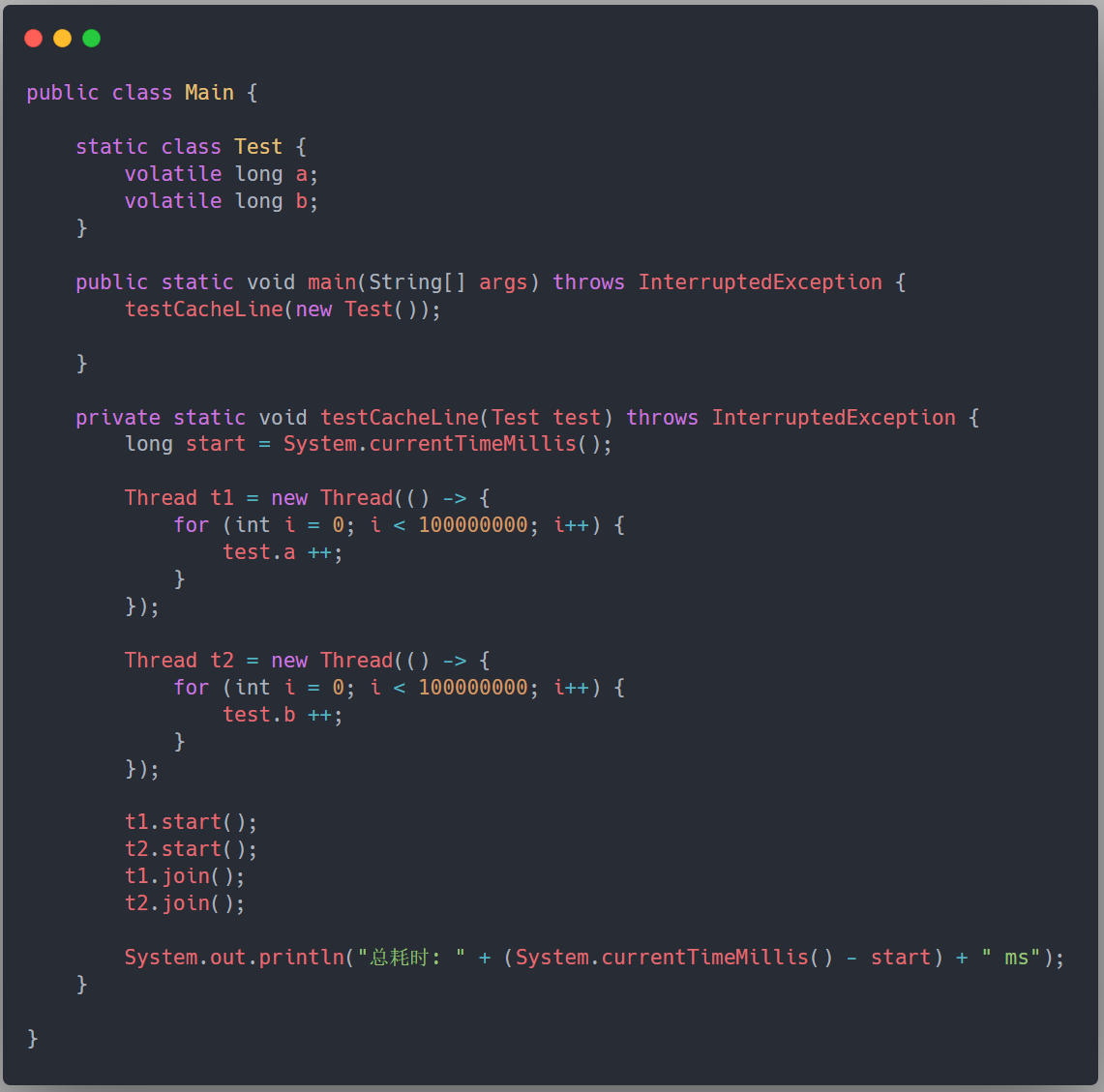
我們先來舉個例子看看一段偽共用程式碼的耗時,如下所示,我們定義一個 Test 類,它包含兩個 long 的變數,分別用兩個執行緒對這兩個變數進行自增 1 億次,這段程式碼耗時 5625ms
對於偽共用,一般有兩種方法,其實思想都是一樣的:
1)padding:就是增大陣列元素之間的間隔,使得不同執行緒存取的元素位於不同的快取行上,以空間換時間
上面提到過,一個 64 位元組的 Cache Line 中可以存 8 個 long 型別的變數,我們在 a 和 b 這兩個 long 型別的變數之間再加 7 個 long 型別,使得 a 和 b 處在不同的 Cache Line 上面:
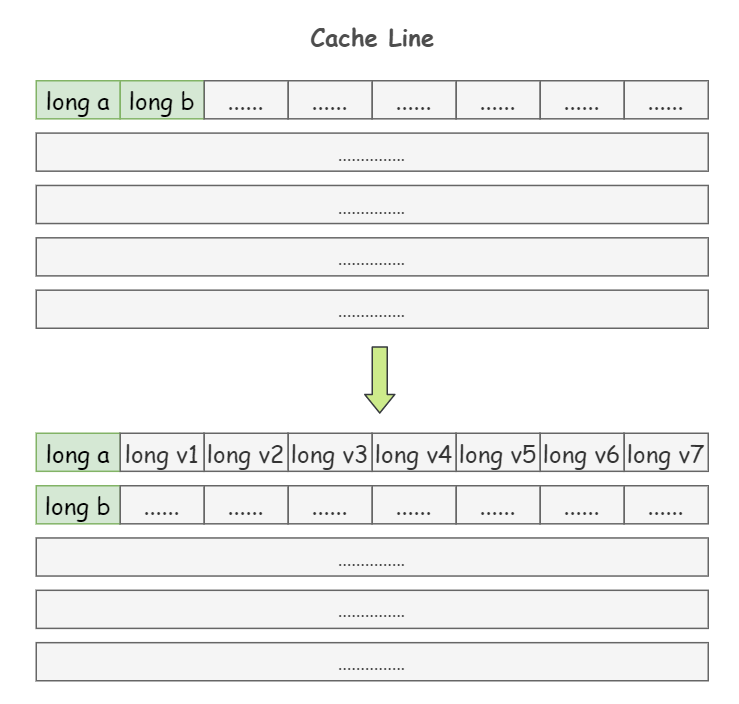
class Pointer {
volatile long a;
long v1, v2, v3, v4, v5, v6, v7;
volatile long b;
}
再次執行程式,會發現輸出時間神奇的縮短為了 955ms
2)JDK1.8 提供了 @Contended 註解:就是把我們手動 padding 的操作封裝到這個註解裡面了,這個註解可以放在類上也可以放在欄位上,這裡就不多做說明了
class Test {
@Contended
volatile long a; // 填充 a
volatile long b;
}
需要注意的是,預設使用這個註解是無效的,需要在 JVM 啟動引數加上 XX:-RestrictContended 才會生效
最後放上這道題的背誦版: