C++ 煉氣期之資料是主角
1. 前言
資料在程式中的重要性,怎麼強調都不為過,程式的本質就是通過提供資料處理邏輯,把資料從一種狀態變成另一種狀態的過程。處理邏輯一定是有針對性的,針對的是資料本身的特性。
只有瞭解了資料本身的內在邏輯含義以及資料間的邏輯關係,才能提供恰到好處的處理邏輯。如,根據麵粉的特性適用於製作麵包、麵條的處理邏輯,並不適合辣條的製作邏輯。
資料是程式的主角,邏輯是程式的劇本。本文將從如下幾個方面聊聊C++中的資料這個主角。
- 資料的儲存。
- 資料的型別。
- 資料的來源。
2. 資料的儲存
談論資料儲存之前,先要知道資料是什麼?
資料是計算機世界對現實世界中資訊的對映,對映資料的過程也是計算機認知現實世界的過程。
對映還有一個專業概念:數位建模。
認知過程包括:
- 識別: 比如:文字資訊還是視訊資訊或是圖片資訊或是數位資訊……識別過程就是對現實世界中的資訊進行分類的過程。因為型別不同,其對映模型將不同、給其分配的劇本(處理邏輯)也不同。
- 採集: 計算機只能識別二進位制資料,現實世界中的任一型別資訊在計算機中都只能以二進位制形式儲存,所謂
採集就是把現實世界中的資訊以二進位制式的形式描述,此過程也稱為編碼。 - 儲存: 以二進位制的資料格式儲存在計算機中。
資料的儲存包含靜態儲存和動態儲存,本文只講解動態儲存,也就是程式執行時是如何儲存資料。程式執行時所需要的資料會儲存在變數中。
什麼是變數?
變數是指位於記憶體中的一個儲存塊。這個儲存塊又是由一個或多個基本儲存單元格組成。一個基本儲存單元格的大小一般為 1位元組(1 B)。
位元
(bit)是計算機的最小儲存單位。此單位太小,引入了位元組單位,1位元組等於8個位元(1B=8bit)。

因儲存塊中的資料可以根據邏輯的需要隨時發生變化,變數一詞由此而來。
變數的詞義強調了儲存塊中資料的動態性、靈活性。
什麼是變數名?
為了方便存取變數,開發者需要給變數起一個名字,這便是變數名。
當C++執行系統根據開發者的請求指令開闢了儲存空間後,便會把變數名和變數進行關聯。如此便可以在程式中通過變數名這唯一的變數識別符號號存取變數中的資料了。
由開發者提供的變數名,也稱為變數的邏輯名。
C++底層機制會建立一張對映表,用來儲存變數名和對應儲存塊的對映關係。
變數名由開發者指定,由系統關聯。開發者在給變數命名時,需要遵循變數名命名的語法規則。
變數名命名規則:
- 首字母只能以字母、下劃線開頭。
- 除首字母之外的其它部分只能是字母、下劃線、數位組成。
- 因
C++語言區分大小寫,所以NAME和name是 2 個不同的變數名。
變數名命名規範:
如果說規則是法律約束,則規範就是道德約束。規則遵循的是語法標準,不能不遵守,規範遵循的是事實標準。所謂事實標準指行業裡的傳承或約定。你可以不遵守,但會破壞程式碼的閱讀性和格式一致性。
-
編寫
C++程式時,要求變數名遵循駱駝命名法則,如myName。如果變數名由2個以上的英文單片語成,則從第二個英文單詞開始首字母大寫。 -
還有一點,變數名儘可能能描述其儲存的資料的含義。或者叫知名達義,通過名字便能知道變數中資料的含義。
類似於爸爸媽媽給自己的孩子起名字,都會起一個有寓意的名字。
在需要儲存資料時,需要向C++執行系統提出變數的申請。這裡會有一個常識,申請時需要告之變數的實際使用大小,類似於做衣服時,你對老闆說,給我做件衣服,僅這樣的資訊還是不夠的。你必須告訴老闆衣服的尺寸,這樣老闆才能合理使用布料。
那麼,申請變數時,如何告訴底層機制你所需的變數的大小?
答案是通過資料型別。
//在C++ 中需要變數時,一定要指定資料型別
資料型別 變數名;
資料型別在宣告變數語法中有 2 個作用:
- 確定變數的大小。
- 確定變數中資料的用途。
之於資料型別的具體概念是什麼?以及為什麼指定資料型別便能讓底層執行機制知道開發者所需的變數大小,下文將詳細介紹。
3. 資料型別
什麼是資料型別?
所謂資料型別,就是計算機世界對現實世界中資訊的分類。
為什麼要對資料分類?
分類是對資料識別的過程,分類的過程也是瞭解各種資料特徵的過程,只有瞭解了資料的特性方能擬定行之有效的解決方案。
自動駕駛汽車系統最複雜的地方在於:汽車在行駛過程中要實時對周邊的資料進行分類,是石頭還是人類還是花花草草或是一隻小狗小貓……只有在類別清楚的情況才能給出對應的處理方案。是人,停下來,是花花草草可以開過去,是石塊,還要區分其大小。
計算機對現實世界的資訊分類越精細,其處理領域以及處理能力會越強。如果人類對化學元素週期表中的元素僅瞭解其 1/3 ,則人類的科技文明將要遠遠低於現在的科技成就。
化學週期表中的元素有限,但是可以利用元素之間的關係,進行復合創造。這點很重要。在
C++語言體系中,同樣能根據基礎分類構建出更復雜的型別,如結構體、類、列舉……
C++把現實世界的資訊分為 2 大基礎類:
- 數位型資料。
- 非數位型資料。
3.1 數位型資料
數位型資料又分為整型資料和浮點型資料。整型資料通俗理解就是不帶小數點的數位,浮點資料可理解為帶小數點的數位。
2.1.1 整型資料
C++用 int統稱整型資料,又以 int為邊界根據數位的範圍大小分為:
short int:短整型。long int:長整型。long long int:長長整型。
儲存不同型別的資料時,C++會根據型別分配相應的儲存空間,導致所描述的數位大小也不一樣。
那麼!上述各種資料型別所描述的數位範圍到底有多大?
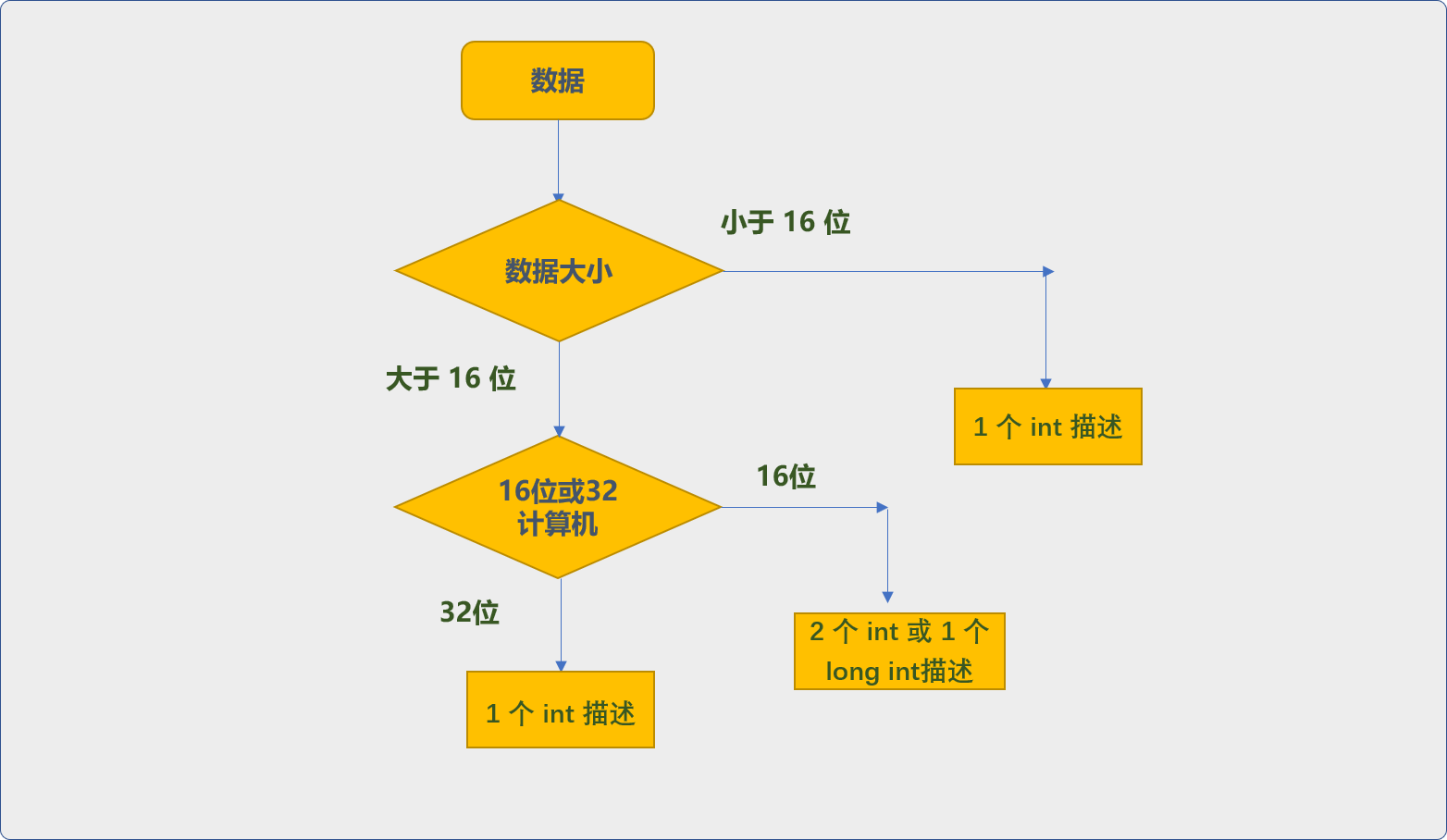
C++與其它的高階語言有所不同,如 JAVA中嚴格規定了 int 為 4 個位元組大小。但是 C++標準中對 int只做了一個抽象規定,其描述的數位範圍大小與機器字相同。
-
int是一個機器字。 -
short int是半個機器字。 -
long int是1或2個機器字。 -
long long int是2個機器字。
機器字,就是計算機的運算單元在單位時間內能處理的資料位數。如我們經常會說
16位處理器,32位處理器。
16位處理器單位時間內能處理16位也就是2位元組的資料。
32處理器單位時間內能處理32位也就是4位元組的資料。
所以,同一個程式,執行在不同的計算機平臺上時,int 所能描述的資料範圍是不一樣的。現假設本程式執行在 32 位的計算機上,在編寫如下變數宣告以及賦值程式碼時,請注意其中的細節。
- 預設情況下,所有數位字面常數都是
int型別。如下常數34就是int。 數位字面值預設情況下十進位制格式,也可以使用八進位制或十六進位制度。
//十進位制
int num_1=34;
//八進位制,前面使用 0 作為字首
int num02=023;
//十六進位制,前面使用 0X 作為字首
int num03=0x12;
- 在使用
short int儲存資料時,不要儲存超過short int型別描述的數位大小。如下是正確的。在32位處理平臺上,short int能儲存的數位範圍是-32768~32767。23在這個範圍之內。
short int num_a=23;
如下是錯誤的賦值操作,因為常數 100000已經超過了 short int描述的數位範圍。
short int num_a=100000;
- 使用
long int時,如果儲存的數位沒有超過long int所描述的範圍,可以直接賦值,如下是正確的。
long int num_3=45;
最好在數位後面新增 L或l字尾。根據測試,編寫本文時測試程式碼用的計算機上的 long int和 int描述的數位範圍是相同的,都是 4 B。
long int num_3=10000000000L;
- 使用
long long int時,請在賦值的數位後面新增字尾LL和ll。經過測試,本機long long int是8 B。當然如果不指定LL特定描述符,C++也能自動轉換。
long long int num_3=10000000000LL;
因 int 型別大小的不確定性,C++程式在跨平臺使用時,存在移植問題。
什麼是移植問題?
這裡必然會出現一個問題,我在 32 位計算機編寫程式時,使用 int 描述了一個32 位的資料。如果讓此程執行在 16 位的計算機上,則會出現編譯無法通過或丟失資料的情況。
類似於我在一家銀行儲存物件時,此銀行給了我
4個儲存櫃用來儲存我的物件,我也把4個櫃子存滿了。轉到另一家銀行時,人家說最多隻能給我
2個櫃子,這肯定是存不下我所有的物件,會發生資料丟失。如果情形反過來,倒沒有多大影響。
問題出現了,必然是要解決的,一種解決方案就是程式級解決,在編寫程式時,獲取到程式執行時的計算機的機器字,然後根據計算機的機器字採用不同的資料型別儲存。
在程式邏輯中,還要隨時獲取到底層硬體的工作狀態,這與高階語言的理念相矛盾,且增加了開發者的負擔,且易出現忽視的地方,導致程式在移植時 bug滿天飛。
當然,C++也可以讓開發者可以統一使用 int描述資料,在編譯器中,由編譯器根據計算機的機器字,然後採用是否拆分儲存的方案。也就是把上述邏輯由開發層面移到編譯器層面。
這是常規解決方案,但是會增加編譯器的工作負擔,影響編譯的速度。
另一種解決方案,C++在語法層面提供了明確描述數位範圍的型別關鍵字,可以由開發者根據自行選擇。這樣在語法層面和編譯層面有了統一的協定,編譯器不需要進行條件判斷。
__int8:表示8位。__int16:表示16位。__int32:表示32位。__int64:表示64位。
有符號和無符號的問題:
預設情況下,int是有符號,意味著可以儲存正數,也能儲存負數。如下 2 行程式碼的語意是一樣的。
signed int num_1=34;
int num_2=34;
如果需要表示無符號的整型資料型別,則需要使用 unsigned 關鍵字。使用此關鍵字後變數中不能儲存負數。如下程式碼從語法上沒有錯誤,但是,從變數 num_1並不能獲取資料 -34,而是垃圾資料。
unsigned int num_1=-34;
C++語言有一個讓讓人頭大的地方。如下程式碼,很明顯,
1000000000098788已經遠遠超過了int描述的範圍,語法上沒有任何提示,並且能正確編譯執行,只是從變數num_3中獲得的資料是垃圾資料。int num_3=1000000000098;
C++的語法較為寬鬆,編譯器較"圓滑",一切就靠開發者自己步步驚心了。可以說是缺點,但也是優點,正因為不設防,才能讓其編譯速度較快。
無符號資料可以在資料中新增 u或 U作為無符號資料的識別符號號。
unsigned int num_3=34u;
有符號 int和無符號 int 所表示的數位範圍並不相同。32系統中,無符號 int 型別範圍如下圖,也就是 0~4294967295。
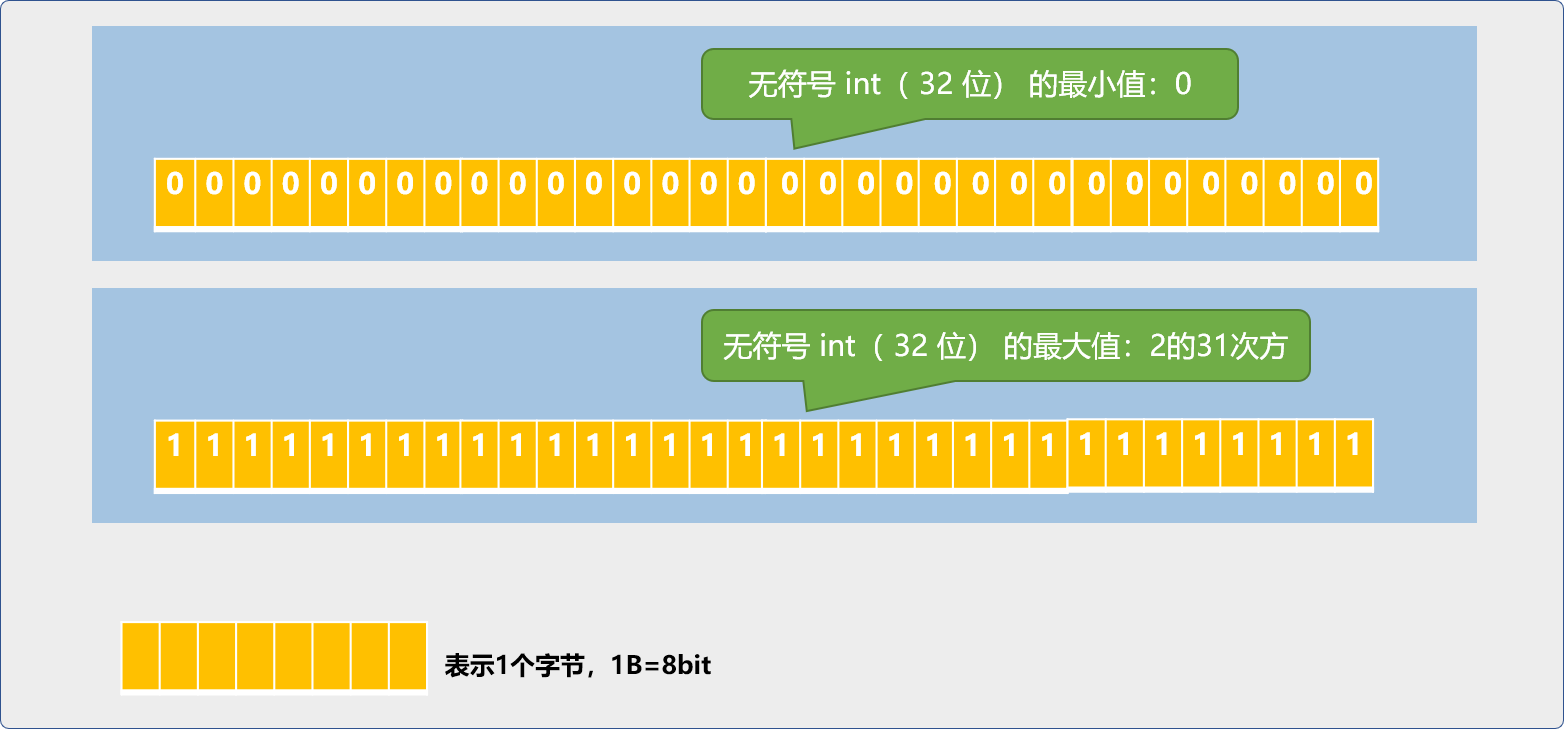
unsigned int num_1=4294967295;
unsigned int num_2=num_1+1;
cout<<num_1<<endl;
cout<<num_2<<endl;
return 0;
//輸出結果
4294967295
0
int型別預設是有符號,只是省略signed ,在 32 位的平臺上, int的範圍是-2147483648~2147483647。
在有符號描述中,最高位並不表示有效的資料位,而是標誌位:
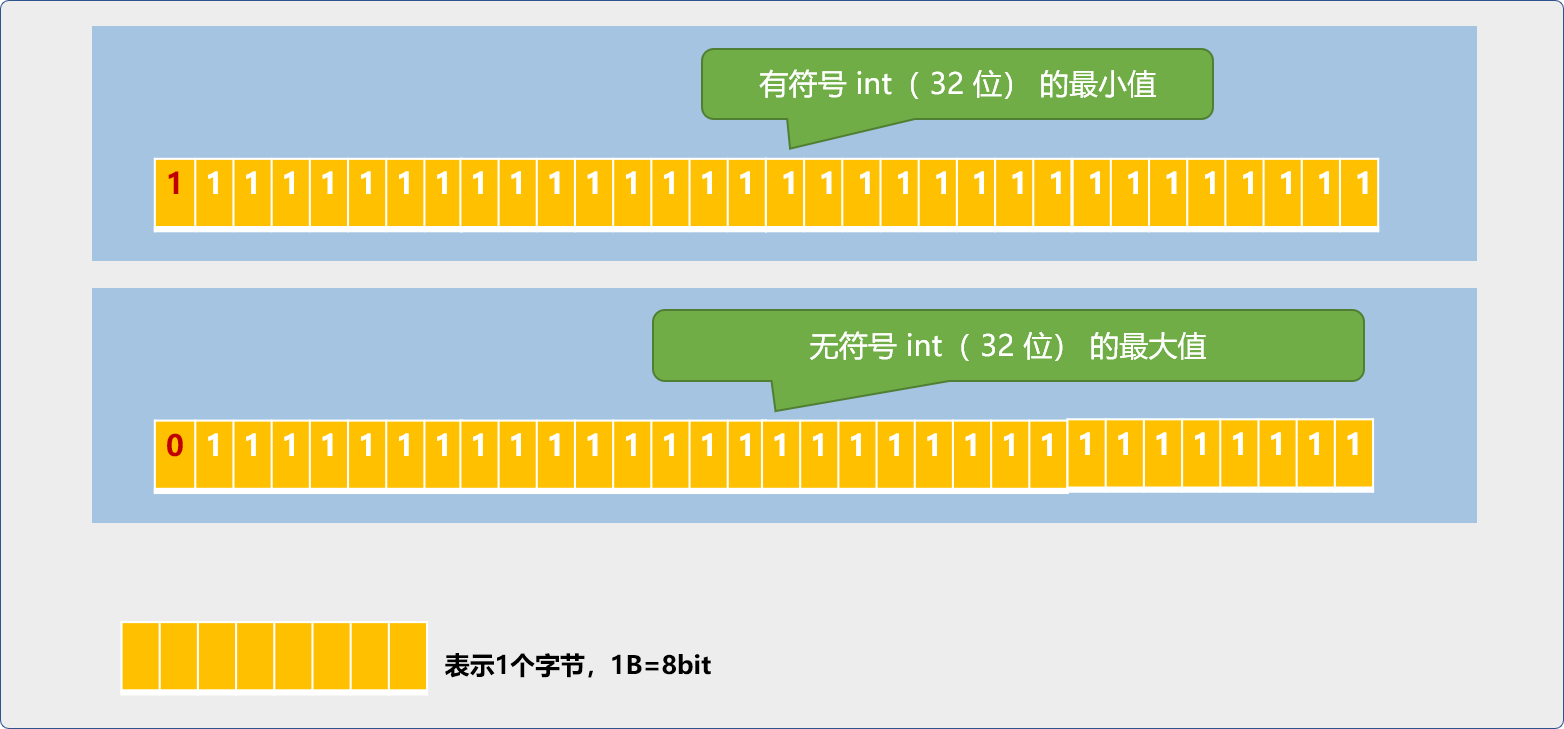
-
當此位置設為
0時,表示儲存的是正數。最大值求解表示式:1X230+1X229……1X20=2147483647
-
當此位置設為
1時,表示儲存的是負數。最小值的求解可理解為無符號位的最大值減去有符號位的最大值再取反,
-(4294967295-2147483647)=-2147483648。
2.1.2 浮點資料
浮點資料指帶小數點的資料,C++用 float 和double表示浮點資料型別。
float表示單精度浮點資料。C++標準約定float的有效位是一個機器字(32位平臺是32位)。double表示雙精度浮點資料。C++標準約定double的有效位是2個機器字(32位平臺是64位)。double還有一個兄弟:long double,其有效位至少應該和double大小一樣(可以是80、96、128位)。
什麼是有效位?
有效位指資料中的有意義的位數。
- 如數位
14567其有效位為5位。 - 如數位
14500,則有效位為3,後面的0為被認為是預留位置,不計算到有效位中。 - 如
245.89有效位也是5。有效位與是否有小數點以及小數點位置無關。
預設情況下,字面浮點常數是double資料型別。如下的 34.0就是double型別。
double num=34.0;
站在數學的角度,
34.0後面的0是沒有意義的,但是C++依然把它當成浮點數位。
在浮點常數後面新增f或F字尾。則表示為 float資料型別。
float num=34.5f;
在浮點常數後面新增L字尾,則為 long double資料型別 。
long double num=34.5L;
當浮點型常數字尾f、F、l、L時,只能用在十進位制開式中。C++在描述浮點型資料時,還可以使用科學計數法開式。科學計數法指數位中帶有指數表示方式。
如下程式碼,表示的是 3*102
double num=3e2;
這裡
2稱為指數,3稱為尾數。
如下程式碼,表示的是 3.4*10-2
double num=3e-2;
在計算機底層,儲存整型資料和浮點資料的方式是不同的。整型資料可以直接儲存,浮點資料則是將資料分成 2 個部分分別儲存。
- 一部分用來儲存數值。
- 一部分用來儲存放大或縮小因子。
舉一個例如,儲存 3.457 十進位制時,可以分成下面 2 個部分儲存 :
- 儲存數值
3457。 - 縮放因子
1000。
當讀取資料時,通過縮放因子縮小數值,就能得到 3.457。縮放或放大因子的作用是移動小數點的位置。上面是以十進位制為例子說明問題,事實是計算機底層以二進位制儲存,縮放因子是以 2 為冪。
正因為小數點可以移動,所以稱這類資料為浮點型別。
但是要知道,原理是這麼一回事,而事實是浮點資料的底層儲存結構要比整型儲存結構複雜的多。
3.2 非數位型別
C++非數位型別有 char和bool。
3.2.1 字元型別
char用來表示單個字元或小整數,char常數需要使用單引號括起來。
char myChar='A';
計算機能直接儲存數位型別資料,只需要把數位轉換成二進位制便可。計算機不能直接儲存字元,所以需要遵循一種統一的標準,把字元轉換成一個數位後再儲存,這個過程叫字元編碼。
計算機最早使用的是 ASCII編碼標準,主要是用於編碼英文中使用的字元。因英文字元並不多,所以 1B的儲存空間就夠用了,C++最初對 char型別的儲存標準就是 1 位元組的儲存空間。
但對於其它國家的語言來講,則遠遠不夠,預設情況下,char是不能儲存中文字元的,因為中文至少需要 2 個位元組的儲存空間。
中文編碼標準有
gb2312、GBK, 這2種標準僅只能對中文字元編碼。另有國際統一的
uncode標準,用來對全世界所有語言的字元進行統一編碼。
如下的程式碼看似能儲存,但其真正儲存的是一個垃圾資料。正如前文所說,C++並不會在語法層面 檢查資料是否合理,編譯器採用原則是能儲存存則儲存,不能儲存就儲存能儲存的一部分。
char myChar='中';
C++還有一種 wchar_t 字元資料型別,叫寬字元型別,其儲存大小為 2 位元組。
wchar_t myChar='中';
另C++ 11標準中還有 char16_t 和char32_t型別描述,主要支援 unicode編碼標準,都是無符號型別。字面意思便能知道一個支援16位儲存,一個支援32位儲存。
無符號字元型
char在預設情況下既不是沒有符號,也不是有符號,因為並沒有編碼為負數的 ASCII字元。算是留了一個可延伸餘地。
C++有無符號的字元型別(unsigned char),其取值,除了包括 ASCII碼錶上的所有字元外,還包括一個擴充套件 ASCII碼錶上的字元。擴充套件字元指通過鍵盤無法輸入的字元。但可以通過字元與整數的關係,來初始化或賦值無符號字元型變數。
unsigned char myChar=128;
有符號和無符號char所表示的範圍是不相同的:
signed char表示範圍為-128~127。unsigned char表示範圍是0~255。
3.2.2 bool型別
bool型別用來表示true和false。在C++中可以把非零值當成 true。零值當成 false。
bool exist=true;
bool exist_=1;
bool exist01=false;
bool exist01_=0;
4. 資料的獲取
程式中資料的源頭有多種途徑:已知資料,互動資料,資料庫中資料、網路資料、檔案中的資料……
已知資料,指直接出現在程式中的字面資料,也稱為常數資料,可以直接參與到運算中,一般用來賦值。
互動資料,也稱為輸入資料。在程式執行時,通過互動機制獲取到使用者輸入的資料。
int num=0;
cout<<"請輸入一個數位";
cin>>num;
cout<<"你剛輸入的數位是"<<num<<endl;
C++通過 cin和重定向指令完成互動資料的獲取。
如果要獲取資料庫中的資料則需要依靠資料庫驅動 API。如果要獲取檔案中的資料則需要使用檔案讀寫API,需要網路上資料則需要網路相關的API`。這已經超過本文要聊的主題,有興趣者可查閱相關檔案。
5. 總結
本文試圖從資料的儲存、資料的型別、資料的源頭上講解資料的本質。程式這個劇本要開始,資料這個主角先要到位,對資料的瞭解多少,決定了邏輯的精彩度。
本文內容雖然很基礎 ,但尤為重要,基礎建設是否牢固決定了高層構建的高度。