Lucene從入門到實戰
Lucene
在瞭解Lucene之前,我們先了解下全文資料查詢。
全文資料查詢
我們的資料一般分為兩種:結構化資料和非結構化資料
- 結構化資料:有固定格式或有限長度的資料,如資料庫中的資料、後設資料
- 非結構化資料:又叫全文資料,指不定長或無固定格式的資料,如郵件、word檔案
資料庫適合結構化資料的精確查詢,而不適合半結構化、非結構化資料的模糊查詢及靈活搜尋(特別是資料量大時),無法提供想要的實時性。
全文資料查詢
- 順序掃描法
所謂順序掃描,就是要找內容包含一個字串的檔案,就是一個檔案一個檔案的看。對於每一個檔案,從頭看到尾,如果此檔案包含此字串,則此檔案為我們要找的檔案,接著看下一個檔案,直到掃描完所有的檔案。
- 全文檢索
全文檢索是指計算機索引程式通過掃描文章中的每一個詞,對每一個詞建立一個索引,指明該詞在文章中出現的次數和位置,當用戶查詢時,檢索程式就根據事先建立的索引進行查詢,並將查詢的結果反饋給使用者的檢索方式。這個過程類似於通過字典中的檢索字表查字的過程。
全文檢索的基本思路,就是將非結構化資料中的一部分資訊提取出來,重新組織,使其變得有一定結構,然後對這個有一定結構的資料進行搜尋,從而達到搜尋相對較快的目的。
這部分從非結構化資料中提取出的然後重新組織的資訊,我們稱之索引,這種先建立索引,再對索引進行搜尋的過程就叫全文檢索(Full-text Search) 。
具體應用的有單機軟體的搜尋(word中的搜尋) 站內搜尋 ( 京東、 taobao、拉勾職位搜尋) 專業搜尋引擎公司 (google、baidu)的搜尋。
全文檢索通常使用倒排索引來實現。
3. 正排索引
正排索引是指檔案ID為key,表中記錄每個關鍵字出現的次數位置等,查詢時掃描表中的每個檔案中字的資訊,直到找到所有包含查詢關鍵字的檔案。
格式如下:
檔案1的ID > 單詞1:出現次數,出現位置列表;單詞2:出現次數,出現位置列表…………
檔案2的ID > 單詞1:出現次數,出現位置列表;單詞2:出現次數,出現位置列表…………
當用戶在主頁上搜尋關鍵詞「華為手機」時,假設只存在正向索引(forward index),那麼就需要掃描索引庫中的所有檔案,找出所有包含關鍵詞「華為手機」的檔案,再根據打分模型進行打分,排出名次後呈現給使用者。因為網際網路上收錄在搜尋引擎中的檔案的數目是個天文數位,這樣的索引結構根本無法滿足實時返回排名結果的要求
4. 倒排索引
被用來儲存在全文搜尋下某個單詞在一個檔案或一組檔案中的儲存位置的對映。它是檔案檢索系統中常用的資料結構。通過倒排索引,可以根據單詞快速獲取包含這個單詞的檔案列表。
格式如下:
關鍵詞1 > 檔案1的ID :出現次數,出現的位置;檔案2的ID:出現次數 ,出現的位置…………
關鍵詞2 > 檔案1的ID :出現次數,出現的位置;檔案2的ID:出現次數 ,出現的位置…………
Lucene基礎入門
Lucene簡介
Lucene的作者Doug Cutting是資深的全文索引/檢索專家,最開始釋出在他本人的主頁上,2000年開源,2001年10月貢獻給Apache,成為Apache基金的一個子專案。官網https://lucene.apache.org/core。現在是開源全文檢索方案的重要選擇。
Lucene是非常優秀的成熟的開源的免費的純java語言的全文索引檢索工具包。
Lucene是一個高效能、可伸縮的資訊搜尋(IR)庫。 Information Retrieval (IR) library.它可以為你的應用程式新增索引和搜尋能力。
Lucene是為軟體開發人員提供一個簡單易用的工具包,以方便的在目標系統中實現全文檢索的功能,或者是以此為基礎建立起完整的全文檢索引擎。由Apache軟體基金會支援和提供,Lucene提供了一個簡單卻強大的應用程式介面,能夠做全文索引和搜尋。Lucene是當前以及最近幾年非常受歡迎的免費Java資訊檢索程式庫。
Lucene實現的產品
作為一個開放原始碼專案,Lucene從問世之後,引發了開放原始碼社群的巨大反響,程式設計師們不僅使用它構建具體的全文檢索應用,而且將之整合到各種系統軟體中去,以及構建Web應用,甚至某些商業軟體也採用了Lucene作為其內部全文檢索子系統的核心。
Nutch:Apache頂級開源專案,包含網路爬蟲和搜尋引擎(基於lucene)的系統(同 百度、google)。
Hadoop因它而生。
Solr : Lucene下的子專案,基於Lucene構建的獨立的企業級開源搜尋平臺,一個服務。它提供了基於xml/JSON/http的api供外界存取,還有web管理介面。
Elasticsearch:基於Lucene的企業級分散式搜尋平臺,它對外提供restful-web介面,讓程式設計師可以輕鬆、方便使用搜尋平臺。
還有大家所熟知的OSChina、Eclipse、MyEclipse、JForum等等都是使用了Lucene做搜尋方塊架來實現自己的搜尋部分內容,在我們自己的專案中很有必要加入他的搜尋能力,可以大大提高我們開發系統的搜尋體驗度。
Lucene的特性
- 穩定、索引效能高
- 每小時能夠索引150GB以上的資料。
- 對記憶體的要求小,只需要1MB的堆記憶體
- 增量索引和批次索引一樣快。
- 索引的大小約為索引文字大小的20%~30%。
- 高效、準確、高效能
- 範圍搜尋 - 優先返回最佳結果很多強大的
- 良好的搜尋排序。
- 強大的查詢方式支援:短語查詢、萬用字元查詢、臨近查詢、範圍查詢等。
- 支援欄位搜尋(如標題、作者、內容)。
- 可根據任意欄位排序
- 支援多個索引查詢結果合併
- 支援更新操作和查詢操作同時進行
- 支援高亮、join、分組結果功能
- 速度快
- 可延伸排序模組,內建包含向量空間模型、BM25模型可選
- 可設定儲存引擎
- 跨平臺
- 純java編寫
- Lucene有多種語言實現版(如C、C++、Python等)
Lucence模組構成
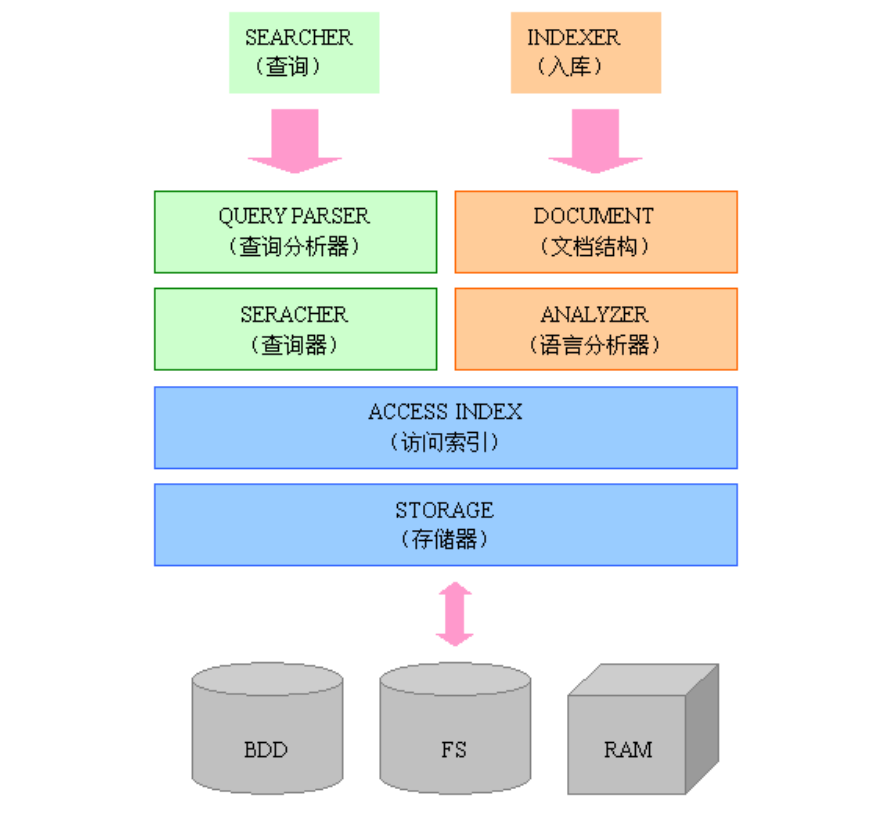
Lucene是一個用Java寫的高效能、可伸縮的全文檢索引擎工具包,它可以方便的嵌入到各種應用中實現針對應用的全文索引、檢索功能。Lucene的目標是為各種中小型應用程式加入全文檢索功能
Lucene應用實戰
索引建立流程
第一步:採集一些要索引的原檔案資料
採集資料分類:
1、對於網際網路上網頁,可以使用工具將網頁抓取到本地生成html檔案。
2、資料庫中的資料,可以直接連線資料庫讀取表中的資料。
3、檔案系統中的某個檔案,可以通過I/O操作讀取檔案的內容。
第二步:建立檔案物件,進行語法分析,將檔案傳給分詞器(Tokenizer)形成一系列詞(Term)
獲取原始內容的目的是為了索引,在索引前需要將原始內容建立成檔案(Document),檔案中包括一個一個的域(Field),域中儲存內容,再對域中的內容進行分析,分析成為一個一個的單詞(Term)。每個Document可以有多個Field。
第三步:索引建立,將得到的詞傳給索引元件(Indexer)形成倒排索引結構
對所有檔案分析得出的詞彙單元進行索引,索引的目的是為了搜尋,最終要實現只搜尋被索引的語彙單元從而找到Document(檔案)。
建立索引是對語彙單元索引,通過詞語找檔案,這種索引的結構叫倒排索引結構。
第四步:通過索引記憶體,將索引寫入到磁碟
Java程式碼實現索引建立
引入依賴:
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>${lucene-version}</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>${lucene-version}</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>${lucene-version}</version>
</dependency>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.5</version>
</dependency>
public class TestLuceneIndex {
public static void main(String[] args) throws Exception{
// 1. 採集資料
List<Book> bookList = new ArrayList<Book>();
Book book1=new Book();
book1.setId(1);
book1.setName("Lucene");
book1.setPrice(new BigDecimal("100.45"));
book1.setDesc("Lucene Core is a Java library providing powerful indexing\n" +
"and search features, as well as spellchecking, hit highlighting and advanced\n" +
"analysis/tokenization capabilities. The PyLucene sub project provides Python\n" +
"bindings for Lucene Core");
bookList.add(book1);
Book book2=new Book();
book2.setId(2);
book2.setName("Solr");
book2.setPrice(new BigDecimal("66.45"));
book2.setDesc("Solr is highly scalable, providing fully fault tolerant\n" +
"distributed indexing, search and analytics. It exposes Lucene's features through\n" +
"easy to use JSON/HTTP interfaces or native clients for Java and other languages");
bookList.add(book2);
Book book3=new Book();
book3.setId(3);
book3.setName("Hadoop");
book3.setPrice(new BigDecimal("318.33"));
book3.setDesc("The Apache Hadoop software library is a framework that\n" +
"allows for the distributed processing of large data sets across clusters of\n" +
"computers using simple programming models");
bookList.add(book3);
//2. 建立docment檔案物件
List<Document> documents = new ArrayList<>();
bookList.forEach(x->{
Document document=new Document();
document.add(new TextField("id",x.getId().toString(), Field.Store.YES));
document.add(new TextField("name",x.getName(), Field.Store.YES));
document.add(new TextField("price",x.getPrice().toString(), Field.Store.YES));
document.add(new TextField("desc",x.getDesc(), Field.Store.YES));
documents.add(document);
});
//3.建立Analyzer分詞器,對檔案分詞
Analyzer analyzer=new StandardAnalyzer();
//建立Directory物件,宣告索引庫的位置
Directory directory=FSDirectory.open(Paths.get("D://lucene/index"));
//建立IndexWriteConfig物件,寫入索引需要的設定
IndexWriterConfig config=new IndexWriterConfig(analyzer);
//4.建立IndexWriter物件,新增檔案document
IndexWriter indexWriter=new IndexWriter(directory,config);
documents.forEach(doc-> {
try {
indexWriter.addDocument(doc);
} catch (IOException e) {
e.printStackTrace();
}
});
//釋放資源
indexWriter.close();
}
}
索引搜尋流程
- 使用者輸入查詢語句
- 對查詢語句經過詞法分析和語言分析得到一系列詞(Term)
- 通過語法分析得到一個查詢樹
- 通過索引儲存將索引讀到記憶體
- 利用查詢樹搜尋索引,從而得到每個詞(Term)的檔案列表,對檔案列表進行交、差、並得到結果檔案
- 將搜尋到的結果檔案按照對查詢語句的相關性進行排序
- 返回查詢結果給使用者
Java程式碼實現索引查詢
public class TestLuceneSearch {
public static void main(String[] args) throws IOException, ParseException {
//1. 建立Query搜尋物件
Analyzer analyzer=new StandardAnalyzer();
//建立搜尋解析器
QueryParser queryParser=new QueryParser("id",analyzer);
Query query=queryParser.parse("desc:data");
//2. 建立Directory流物件,宣告索引庫位置
Directory directory=FSDirectory.open(Paths.get("D:/lucene/index"));
//3. 建立索引讀取物件IndexReader
IndexReader reader=DirectoryReader.open(directory);
// 4. 建立索引搜尋物件
IndexSearcher searcher= new IndexSearcher(reader);
//5. 執行搜尋,指定返回最頂部的10條資料
TopDocs topDocs = searcher.search(query, 10);
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
//6. 解析結果集
Stream.of(scoreDocs).forEach(doc->{
//獲取檔案
Document document = null;
try {
document = searcher.doc(doc.doc);
} catch (IOException e) {
e.printStackTrace();
}
System.out.println(document.get("name"));
System.out.println(document.get("id"));
});
reader.close();
}
}
Field域
- Field屬性
Lucene儲存物件是以Document為儲存單元,物件中相關的屬性值則存放到Field中。Field是檔案中的域,包括Field名和Field值兩部分,一個檔案包括多個Field,Field值即為要索引的內容,也是要搜尋的內容。
Field的三大屬性:
- 是否分詞(tokenized)
是否做分詞處理。是:即將Field值進行分詞,分詞的目的是為了索引。
- 是否索引
是否進行索引,將Field分詞後的詞或整個Field值進行索引,索引的目的是為了搜尋。
- 是否儲存
將Field的值儲存在檔案中,儲存在檔案中的Field中才可以從Document中獲取。
- Field常用型別
| Field型別 | 資料型別 | 是否分詞 | 是否索引 | 是否儲存 | 說明 |
|---|---|---|---|---|---|
| StringField(FieldName,FieldValue, Store.YES) | 字串 | N | Y | Y/N | 字串型別Field, 不分詞, 作為一個整體進行索引(如: 身份證號, 訂單編號), 是否需要儲存由Store.YES或Store.NO決定 |
| TextField(FieldName,FieldValue, Store.NO) | 文字型別 | Y | Y | Y/N | 文字型別Field,分詞並且索引,是否需要儲存由Store.YES或Store.NO決定 |
| LongField(FieldName,FieldValue, Store.YES) 或LongPoint(String name,int... point)等 | 數值型代表 | Y | Y | Y/N | 在Lucene 6.0中,LongField替換為LongPoint,IntField替換為IntPoint,FloatField替換為FloatPoint,DoubleField替換為DoublePoint。對數值型欄位索引,索引不儲存。要儲存結合StoredField即可。 |
| StoredField(FieldName,FieldValue) | 支援多種型別 | N | N | Y | 構建不同型別的Field,不分詞,不索引,要儲存 |
- Field程式碼應用
public static void main(String[] args) throws IOException {
// 1. 採集資料
List<Book> bookList = Book.buildBookData();
List<Document> documents=new ArrayList<>();
bookList.forEach(book -> {
Document document=new Document();
Field id=new IntPoint("id",book.getId());
Field id_v=new StoredField("id",book.getId());
Field name=new TextField("name",book.getName(),Field.Store.YES);
Field price=new FloatPoint("price",book.getPrice().floatValue());
Field desc=new TextField("desc",book.getDesc(),Field.Store.NO);
document.add(id);
document.add(id_v);
document.add(name);
document.add(price);
document.add(desc);
documents.add(document);
});
StandardAnalyzer analyzer = new StandardAnalyzer();
Directory directory=FSDirectory.open(Paths.get("D:/lucene/index2"));
IndexWriterConfig indexWriterConfig=new IndexWriterConfig(analyzer);
IndexWriter indexWriter=new IndexWriter(directory,indexWriterConfig);
documents.forEach(doc-> {
try {
indexWriter.addDocument(doc);
} catch (IOException e) {
e.printStackTrace();
}
});
indexWriter.close();
}
索引維護
- 索引新增
indexWriter.addDocument(document);
- 索引刪除
根據Term項刪除
indexWriter.deleteDocuments(new Term("name", "solr"));
全部刪除
indexWriter.deleteAll();
- 更新索引
public static void main(String[] args) throws IOException {
Analyzer analyzer=new StandardAnalyzer();
Directory directory=FSDirectory.open(Paths.get("d:/lucene/index2"));
IndexWriterConfig config=new IndexWriterConfig(analyzer);
IndexWriter indexWriter=new IndexWriter(directory,config);
Document document=new Document();
document.add(new TextField("id","1002", Field.Store.YES));
document.add(new TextField("name","修改後", Field.Store.YES));
indexWriter.updateDocument(new Term("name","solr"),document);
indexWriter.close();
}
分詞器
分詞器相關概念
分詞器:採集到的資料會儲存到Document物件的Field域中,分詞器就是將Document中Field的value的值切分為一個一個的詞。
停用詞:停用詞是為了節省儲存空間和提高搜尋效率,搜尋程式在索引頁面或處理搜尋請求時回自動忽略某些字或詞,這些字或詞被稱為Stop Wordds(停用詞)。比如語氣助詞、副詞、介詞、連線詞等。如:「的」、「啊」、「a」、「the」
擴充套件詞:就是分詞器預設不會切出的詞,但我們希望分詞器切出這樣的詞
藉助一些工具,我們可以看到分詞後的結果:
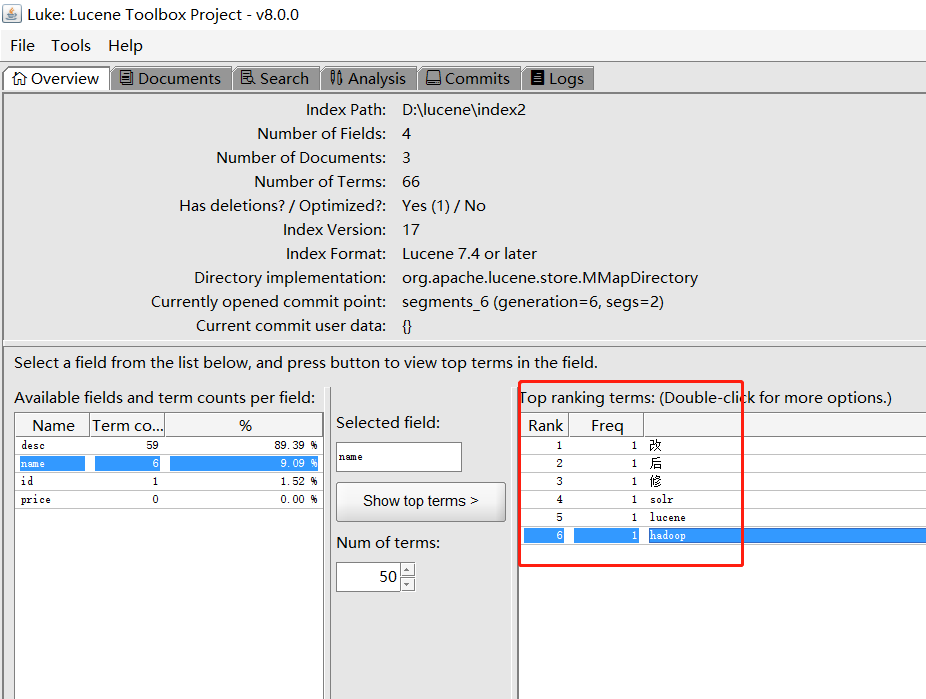
可以看出他將我們的詞「修改後」分為了3個字:「修」、「改」、「後」。另外英文是按照一個個單詞分的。
中文分詞器
英文是以單詞為單位的,單詞與單詞之間以空格或逗號分開,所以英文程式是比較好處理的。
而中文是以字為單位,字又組成詞,字和詞又組成句子。比如「我愛吃紅薯」,程式不知道「紅薯」是一個詞語還是「吃紅」是一個詞語。
為了解決這個問題,中文分詞器IKAnalyzer應運而生
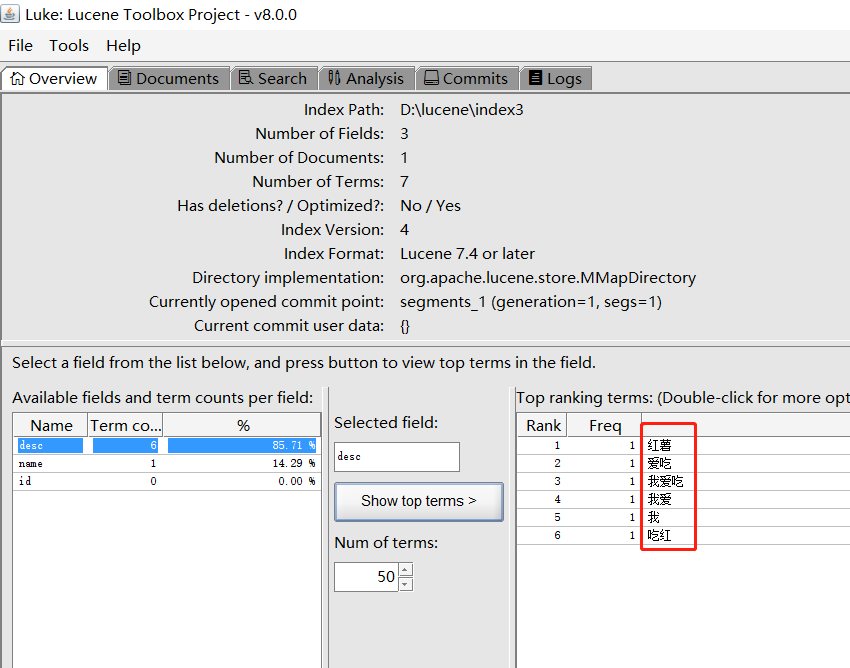
可以看出它把「我愛吃紅薯」分成了很多個符合我們語意的詞語了。但是裡面有一個「吃紅」我們是不需要的。這種就需要我們自己自定義設定
擴充套件中文詞庫
如果想設定擴充套件詞和停用詞,就建立擴充套件詞的檔案和停用詞的檔案。ik給我們提供了自定義設定的擴充套件,從IKAnalyzer.cfg.xml組態檔可以看出:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 擴充套件設定</comment>
<!--使用者可以在這裡設定自己的擴充套件字典 -->
<entry key="ext_dict">ext.dic;</entry>
<!--使用者可以在這裡設定自己的擴充套件停止詞字典-->
<entry key="ext_stopwords">stopword.dic;</entry>
</properties>
我們新建一個ext.dic,並配上「吃紅」。
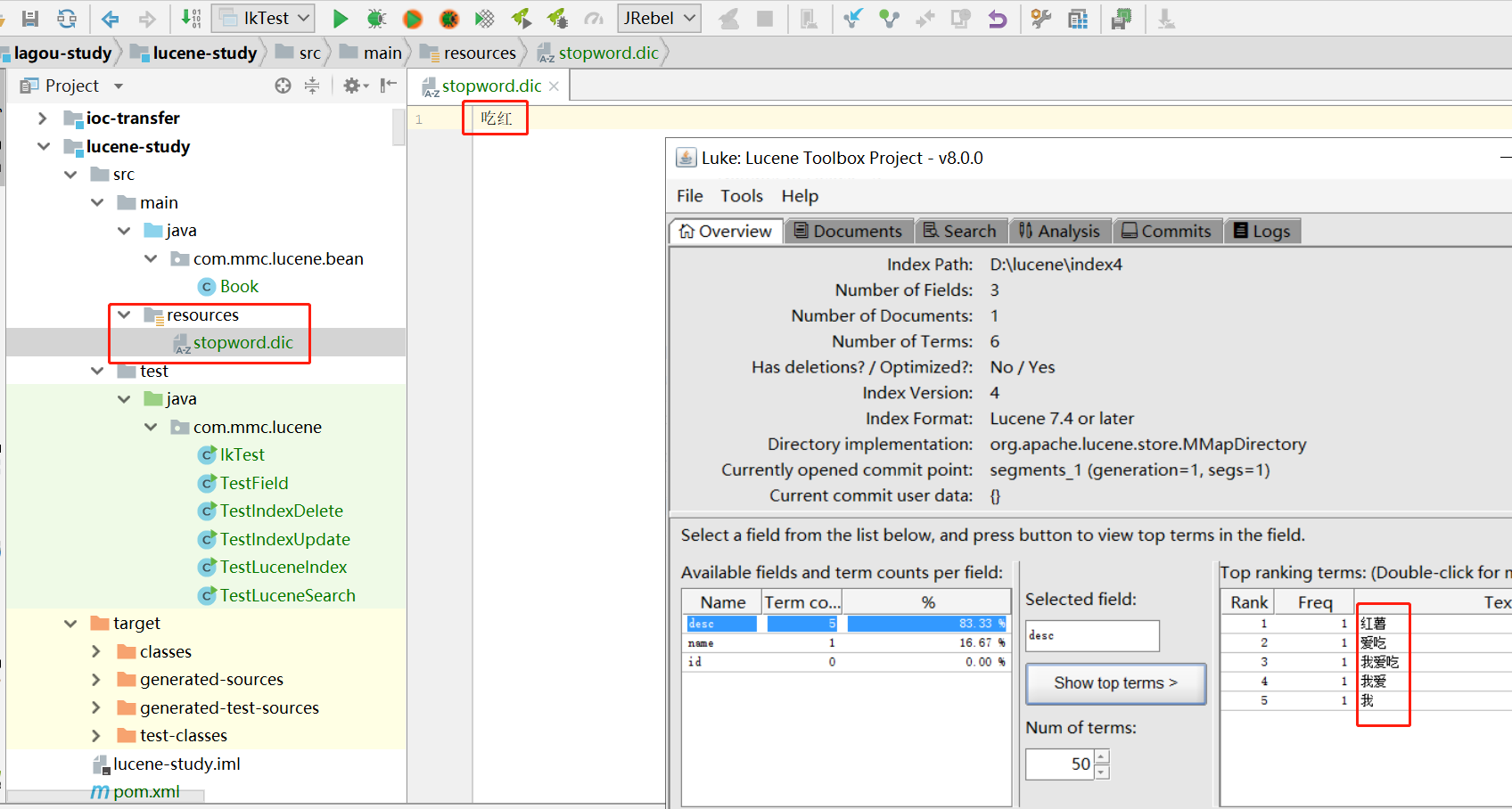
現在看就沒有「吃紅」這個詞了。擴充套件詞典同理。
注意:不要用window自帶的記事本儲存擴充套件詞檔案和停用詞檔案,那樣的話,格式中是含有bom的
搜尋
建立查詢的兩種方式。
1)使用Lucene提供的Query子類
2)使用QueryParse解析查詢表示式
Query子類

- TermQuery
TermQuery詞項查詢,TermQuery不使用分詞器,精確搜尋Field域中的詞。
public class TestSearch {
public static void main(String[] args) throws IOException {
Query query=new TermQuery(new Term("name","solr"));
doSearch(query);
}
private static void doSearch(Query query) throws IOException {
Directory directory=FSDirectory.open(Paths.get("D:/lucene/index"));
IndexReader indexReader=DirectoryReader.open(directory);
IndexSearcher searcher=new IndexSearcher(indexReader);
TopDocs topDocs = searcher.search(query, 10);
System.out.println("查詢到資料的總條數:"+topDocs.totalHits);
Stream.of(topDocs.scoreDocs).forEach(doc->{
//根據docId查詢檔案
Document document = null;
try {
document = searcher.doc(doc.doc);
} catch (IOException e) {
e.printStackTrace();
}
System.out.println(document);
});
}
}
- BooleanQuery
BooleanQuery,實現組合條件查詢。
public static void testBooleanQuery() throws IOException {
Query query1=new TermQuery(new Term("name","lucene"));
Query query2=new TermQuery(new Term("desc","java"));
BooleanQuery.Builder builder = new BooleanQuery.Builder();
builder.add(query1,BooleanClause.Occur.MUST);
builder.add(query2,BooleanClause.Occur.SHOULD);
doSearch(builder.build());
}
組合關係代表的意思如下:
- MUST和MUST表示「與」的關係,即「交集」。
- MUST和MUST_NOT前者包含後者不包含。
- MUST_NOT和MUST_NOT沒意義,查不出來資料
- SHOULD與MUST表示MUST,SHOULD失去意義,相當於僅MUST一個條件
- SHOULD與MUST_NOT相當於MUST與MUST_NOT。
- SHOULD與SHOULD表示「或」的關係,即「並集」。
- 短語查詢PhraseQuery
PhraseQuery phraseQuery = new PhraseQuery("desc","lucene");
兩個短語中間有間隔詞的查詢:
PhraseQuery phraseQuery = new PhraseQuery(3,"desc","lucene","java");
能把類似的句子查出來:
Lucene Core is a Java library providing
lucene和java之間隔了3個詞語
4. 跨度查詢
兩個詞語之間有其他詞語的情況的查詢
public static void testSpanTermQuery() throws IOException {
SpanTermQuery tq1 = new SpanTermQuery(new Term("desc", "lucene"));
SpanTermQuery tq2 = new SpanTermQuery(new Term("desc", "java"));
SpanNearQuery spanNearQuery = new SpanNearQuery(new SpanQuery[] { tq1, tq2
},3,true);
doSearch(spanNearQuery);
}
- 模糊查詢
WildcardQuery:萬用字元查詢,*代表0或多個字元,?代表1個字元,\是跳脫符。萬用字元查詢會比較慢,不可以萬用字元開頭(那樣就是所有詞項了)
public static void testWildcardQuery() throws IOException {
WildcardQuery wildcardQuery=new WildcardQuery(new Term("name","so*"));
doSearch(wildcardQuery);
}
FuzzyQuery:允許查詢中有錯別字
FuzzyQuery fuzzyQuery = new FuzzyQuery(new Term("name", "slors"), 2);
如上面的我把solr打成了slors,也能查詢到,上面的引數2代表錯別字能錯多少個,此引數最大為2.
- 數值查詢
通過 IntPoint, LongPoint,FloatPoint,DoublePoint中的方法構建對應的查詢。
public static void testPointQuery() throws IOException {
Query query = IntPoint.newRangeQuery("id", 1, 4);
doSearch(query);
}
QueryParser搜尋
- 基礎查詢
查詢語法:
Field域名 +":"+搜尋的關鍵字。 例如: name:java
- 範圍查詢
Field域名+":"+[最小值 TO 最大值]。例如: size:[A TO C]
注意:QueryParser不支援對數位範圍的搜尋,支援的是字串範圍
- 組合條件查詢
有兩種寫法:
寫法一:
使用+、減號和不用符號
| 邏輯 | 實現 |
|---|---|
| Occur.MUST 查詢條件必須滿足,相當於AND | +(加號) |
| Occur.SHOULD 查詢條件可選,相當於OR | 空(不用符號) |
| Occur.MUST_NOT 查詢條件不能滿足,相當於NOT非 | -(減號) |
範例:
+filename:lucene + content:lucene
+filename:lucene content:lucene
filename:lucene content:lucene
-filename:lucene content:lucene
寫法二:
使用 AND、OR 、NOT
QueryParser
public static void testQueryParser() throws ParseException, IOException {
Analyzer analyzer=new StandardAnalyzer();
QueryParser queryParser=new QueryParser("desc",analyzer);
Query query = queryParser.parse("desc:java AND name:lucene");
doSearch(query);
}
MultiFieldQueryParser
多個Field的查詢,以下查詢等同於:name:lucene desc:lucene
public static void testSearchMultiFieldQuery() throws IOException, ParseException {
Analyzer analyzer=new IKAnalyzer();
String[] fields={"name","desc"};
MultiFieldQueryParser multiFieldQueryParser=new MultiFieldQueryParser(fields,analyzer);
Query query = multiFieldQueryParser.parse("lucene");
System.out.println(query);
doSearch(query);
}
StandardQueryParser
public static void testStandardQuery() throws QueryNodeException, IOException {
Analyzer analyzer=new StandardAnalyzer();
StandardQueryParser parser = new StandardQueryParser(analyzer);
Query query = parser.parse("desc:java AND name:lucene", "desc");
System.out.println(query);
doSearch(query);
}
其他查詢:
/萬用字元匹配 建議萬用字元在後 萬用字元在前效率低
query = parser.parse("name:L*","desc");
query = parser.parse("name:L???","desc");
//模糊匹配
query = parser.parse("lucene~","desc");
//區間查詢
query = parser.parse("id:[1 TO 100]","desc");
//跨度查詢 ~2表示詞語之間包含兩個詞語
query= parser.parse("\"lucene java\"~2","desc");