python建立分類器小結
簡介:分類是指利用資料的特性將其分成若干型別的過程。
監督學習分類器就是用帶標記的訓練資料建立一個模型,然後對未知資料進行分類。
一、簡單分類器
首先,用numpy建立一些基本的資料,我們建立了8個點;
檢視程式碼
X = np.array([[3, 1], [2, 5], [1, 8], [6, 4], [5, 2], [3, 5], [4, 7], [4, -1]])給這8個點的資料賦予預設的分類標籤
檢視程式碼
y = [0, 1, 1, 0, 0, 1, 1, 0]
class_0 = np.array([X[i] for i in range(len(X)) if y[i] == 0])
class_1 = np.array([X[i] for i in range(len(X)) if y[i] == 1])我們將這些資料畫出來看看
檢視程式碼
plt.figure()
# 畫散點圖 (scatterplot)
plt.scatter(class_0[:, 0], class_0[:, 1], color='black', marker='s')
plt.scatter(class_1[:, 0], class_1[:, 1], color='black', marker='x')
plt.show()
對於混淆矩陣,還可以進行視覺化
檢視程式碼plt.imshow(confusion_mat, interpolation='nearest', cmap='gray') # 亮色: cmap=plt.cm.Paired
plt.title('Confusion matrix')
plt.colorbar()
tick_marks = np.arange(4)
plt.xticks(tick_marks, tick_marks)
plt.yticks(tick_marks, tick_marks)
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show() 
從圖中,我們可以看出,對角線的顏色很亮,我們希望的是對角線的顏色越亮越好,在非對角線的區域如果全部是黑色,表示沒有錯誤;如果有灰色區域,那麼表示分類錯誤的樣本量。從混淆矩陣的視覺化圖中,我們可以看到下標2(即第3類)和下標3(即第4類)存在灰色區域,說明第3類和第4類存在分類錯誤的情況。
sklearn類還內建了效能報告,我們可以直接用classification_report方法進行提取檢視演演算法的分類效果。
檢視程式碼target_names = ['Class-0', 'Class-1', 'Class-2', 'Class-3']
report = classification_report(y_test, y_pred, target_names=target_names)
print(report)
報告中最後一列support表示的是樣本數,總的樣本數為2000個,我們設定了0.25比例的訓練集,那麼訓練數就有500個,132,122,120,126則表示每一類的樣本數,加起來總共也是500個。
以上,用的是高斯葉斯分類器的訓練和預測結果,我們也可以用伯努利貝葉斯看看結果如何。

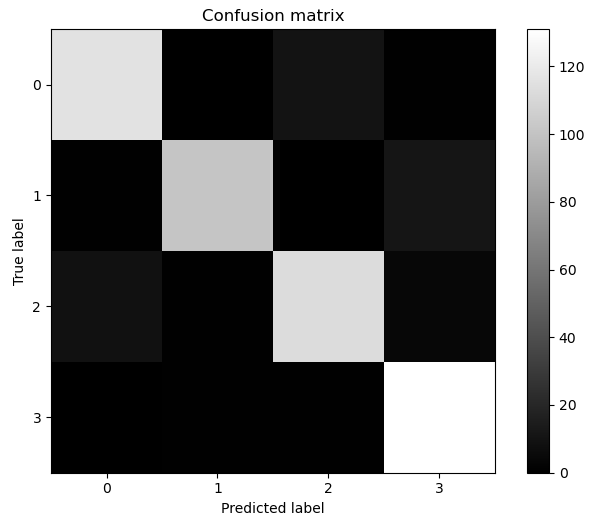
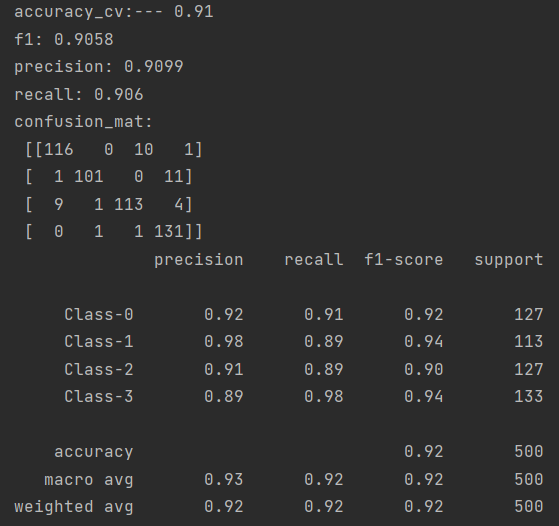
我們可以看到,對於這個資料集,第1類分錯的情況變多了,從混淆矩陣的視覺化圖中,看到有灰色的矩陣出現,從報告中看出precision從93%降低到了92%,第4類分類錯誤也變多,由92%降低到了89%。這樣導致整體的平均precision由92%降低到了90%,不過對於第2類的分類準確率是提高了,92%提高到了98%。
四、分類器案例:根據汽車特徵評估質量
需求分析:根據汽車的特徵進行訓練,得到訓練模型,用模型預測具體某輛汽車的質量情況。
資料分析:
目標:「汽車質量」,(unacc,ACC,good,vgood)分別代表(不可接受,可接受,好,非常好)
6個屬性變數分別為:
「買入價」buying:取值範圍是vhigh、high、med、low
「維護費」maint:取值範圍是vhigh,high,med,low
「車門數」doors:取值範圍 2,3,4,5more
「可容納人數」persons:取值範圍2,4, more
「後備箱大小」lug_boot: 取值範圍 small,med,big
「安全性」safety:取值範圍low,med,high
值得一提的是6個屬性變數全部是有序類別變數,比如「可容納人數」值可為「2,4,more」,「安全性」值可為「low, med, high」
檢視資料分佈情況:

匯入必要的包,包括sklearn(建模,交叉驗證,學習曲線), numpy(計算), matplotlib(畫圖):
檢視程式碼import matplotlib.pyplot as plt
from sklearn import preprocessing
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score, validation_curve
import numpy as np
from utils.views import plot_curve
import pandas as pd載入資料:
檢視程式碼input_file = 'data/car.data.txt'
df = pd.read_table(input_file, header=None, sep=',')
df.rename(columns={0:'buying', 1:'maint', 2:'doors', 3:'persons', 4:'lug_boot', 5:'safety', 6:'quality'}, inplace=True)
df.head(10) 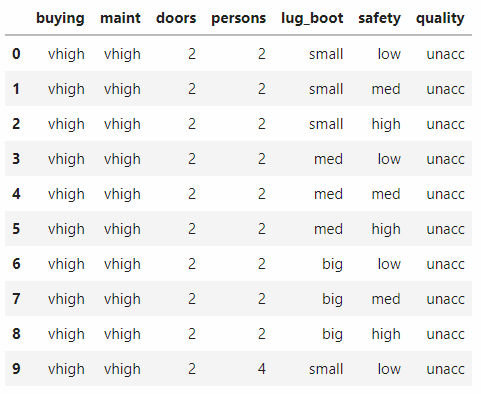
將字串轉換成數值:
檢視程式碼label_encoder = []
for i in range(df.shape[1]):
label_encoder.append(preprocessing.LabelEncoder())
df.iloc[:, i] = label_encoder[-1].fit_transform(df.iloc[:, i])
df.head(10)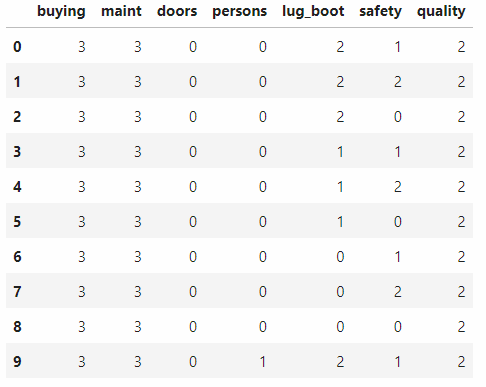
提取特徵X和目標值y
檢視程式碼X = df.iloc[:, :-1]
y = df.iloc[:, -1]
接下來訓練分類器,這裡我們使用隨機森林分類器
檢視程式碼params = {
'n_estimators': 200,
'max_depth': 8,
'random_state': 7
}
clf = RandomForestClassifier(**params)
clf.fit(X, y)接下來開始驗證模型的效果,採用十折交叉驗證。注意,用十折交叉驗證的時候就不需要做資料集的劃分,直接用全量資料集即可。
檢視程式碼accuracy = cross_val_score(clf, X, y, scoring='accuracy', cv=10)
print('accuracy:', round(accuracy.mean(), 3)) 
建立分類器的目的就是對孤立的未知資料進行分類,下面對單一資料點進行分類。
檢視程式碼input_data = ['low', 'vhigh', '2', '2', 'small', 'low']
input_data_encoded = [-1] * len(input_data)
for i, item in enumerate(input_data):
input_data_encoded[i] = int(label_encoder[i].transform([input_data[i]]))
input_data_encoded = np.array(input_data_encoded)
print(input_data_encoded)將單一資料由字串型別轉換成數值型別:

預測資料點的輸出型別:
檢視程式碼output_class = clf.predict(input_data_encoded.reshape(1, -1))
print('output class:', label_encoder[-1].inverse_transform(output_class)[0])
用predict進行預測輸出,輸出的是數值編碼,顯然是看不懂具體的含義的,需要用inverse_transform對標記編碼進行解碼,轉換成原來的形式。
引數調優
通過生成驗證曲線,網格搜尋進行引數的調優。
我們對 n_estimators(弱學習器的個數) 這個引數,太小容易欠擬合,太大容易過擬合。
檢視程式碼
parameter_grid = np.linspace(25, 200, 8).astype(int)
train_scores, validation_scores = validation_curve(clf, X, y, param_name='n_estimators',
param_range=parameter_grid, cv=5)
print('\n ##### VALIDATION CURVES #####')
print('\nParam: n_estimators \n Training scores: \n', train_scores)
print('\nParam: n_estimators \n Validation scores:\n', validation_scores)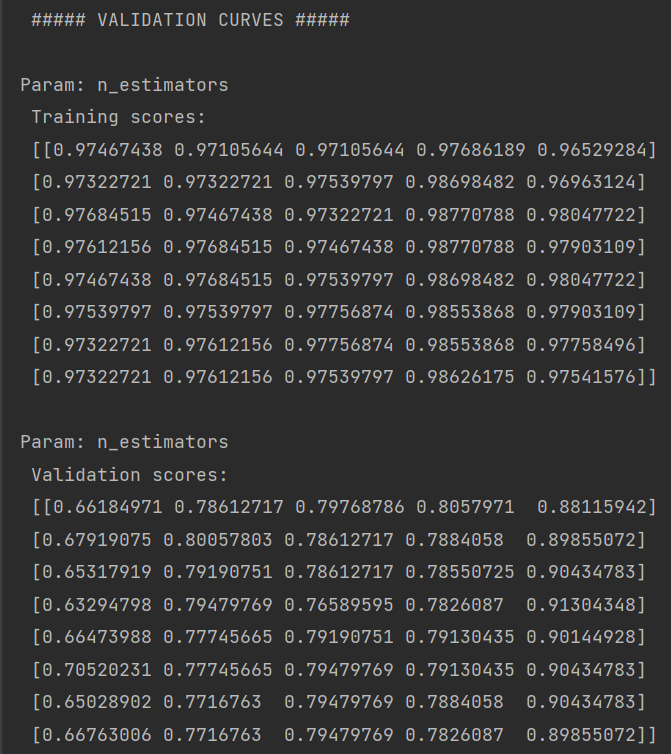
驗證曲線畫圖:
檢視程式碼plt.figure()
plt.plot(parameter_grid, 100 * np.average(train_scores, axis=1), color='black')
plt.title('Training curve')
plt.xlabel( 'Number of estimators')
plt.ylabel('Accuracy')
plt.show()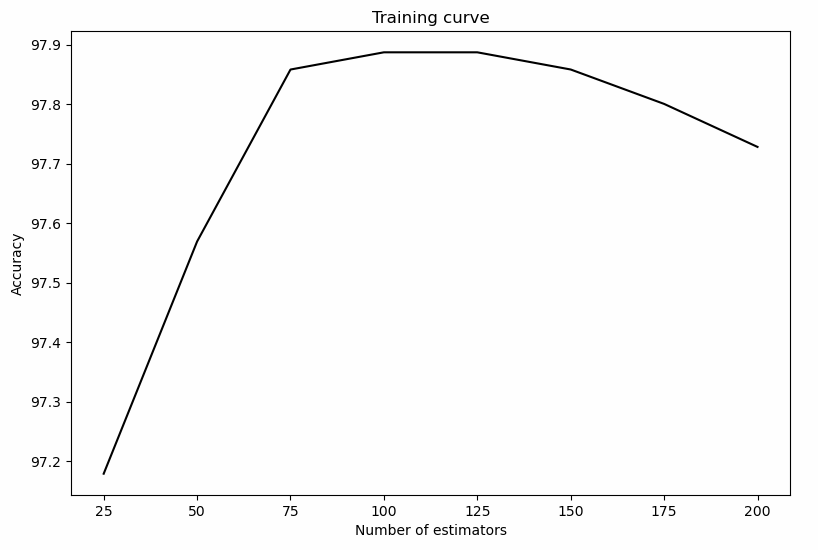
由圖可以看出,estimate在100附近,達到最大的準確率。
同理對max_depth生成驗證曲線。
檢視程式碼max_depth_grid = np.linspace(2, 10, 5).astype(int)
train_scores, validation_scores = validation_curve(clf, X, y, param_name='max_depth',
param_range=max_depth_grid, cv=5)
plot_curve(max_depth_grid, train_scores, 'Validation curve', 'Maximum depth of the tree')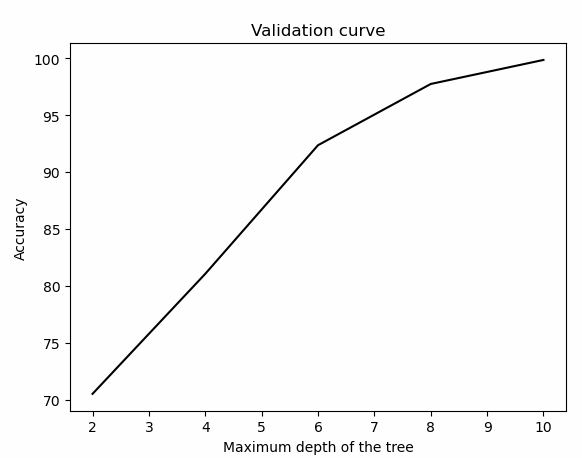
可以看出,max_depth在10附近,準確率達到最大值。
生成學習曲線
學習曲線可以幫助我們理解訓練資料集的大小對機器學習模型的影響。當計算能力限制的時候,這點非常有用。下面改變訓練資料集的大小,繪製學習曲線。
檢視程式碼parameter_grid = np.array([200, 500, 800, 1100])
train_size, train_scores, validation_scores = learning_curve(clf, X, y, train_sizes=parameter_grid, cv=10)
print('\n ##### LEARNING CURVES #####')
print('\n Training scores: \n', train_scores)
print('\n Validation scores:\n', validation_scores)
plot_curve(parameter_grid, train_scores, 'Learning curve', 'Number of training samples') 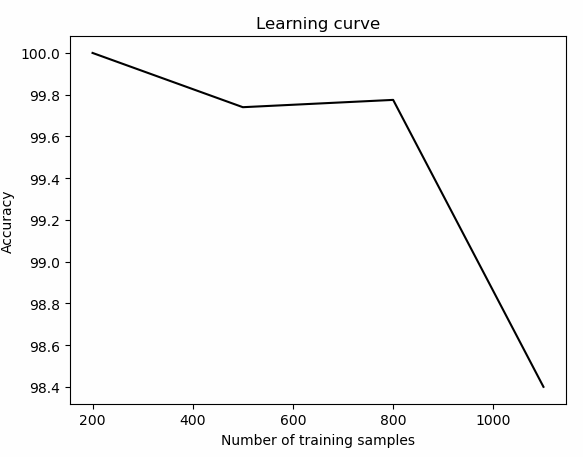
可以看到訓練的資料集規模越小,訓練的準確率越高。
但是,這樣也會容易造成一個問題,那就是過擬合。如果選擇規模較大的資料集,會消耗更多的資源,所以訓練集的規模選擇是一個結合計算能力需要綜合考慮的問題。
以上用到資料集下載:
car.data.txt: https://url87.ctfile.com/f/21704187-595799592-6f0749?p=7287 (存取密碼: 7287)