全域性鎖、表鎖、行鎖
全域性鎖、表鎖和行鎖
MySQL45講基礎篇:根據加鎖的範圍,MySQL裡面的鎖大致分為全域性鎖、表鎖、行鎖三類
全域性鎖
實現:對整個資料庫範例進行加鎖,使用FTWRL.
Flush table with read lock
效果:整個庫處於唯讀狀態,DML和DDL以及更新事務的提交語句都會被阻塞。
全域性鎖使用場景:做全庫邏輯備份(binlog)--也就是把整庫每個表都 select 出來存成文字
做全庫邏輯備份:
- 加全域性鎖:整個庫處於阻塞狀態,無法更新,這對線上是不可能採用的
- 不加全域性鎖:當我在備份的時候,由資料更新,造成,備份庫和本地庫不匹配,沒有意義
準確點說:
不加鎖的話,備份系統備份的得到的庫不是一個邏輯時間點,這個檢視是邏輯不一致的
由此,可以引出前面所說的事務隔離中的可重複讀(檢視中的資料前後一致):
一個事務執行過程中看到的資料,總是跟這個事務在啟動時看到的資料是 一致的。當然在可重複讀隔離級別下,未提交變更對其他事務也是不可見的。
MySQL多版本並行控制(MVCC):同一條記錄在系統中可以存在多個版本,不同時刻啟動的事務會有不同的read-view(值)。
具體的實現是:
官方自帶的邏輯備份工具是 mysqldump。當 mysqldump 使用引數–single-transaction(所有的表使用事務引擎的庫(InnoDB )) 的時候,導資料之前就會啟動一個事務,來確保拿到一致性檢視。而由於 MVCC 的支援,這個過程中資料是可以正常更新的。
FTWRL與set global readonly=true對比:
- FTWRL:適用於不支援事務的引擎;並且使用後如果使用者端發生異常連線斷開,那麼MySQL會自動釋放全域性鎖。
為了使全庫已讀,也不推薦:set global readonly=true
- 一是,在有些系統中,readonly 的值會被用來做其他邏輯,比如用來判斷一個庫是主庫還是備庫。因此,修改 global 變數的方式影響面更大,我不建議你使用。
- 二是,將整個庫設定為 readonly 之後,如果使用者端發生異常,則資料庫就會一直保持 readonly 狀態,這樣會導致整個庫長時間處於不可寫狀態,風險較高
表級鎖(表鎖)
表鎖語法:lock tables ...read/write
釋放鎖:unlock tables 或者在使用者端斷開的時候自動釋放
缺點:除了限制別的執行緒的讀寫外,也限定了本執行緒接下來的操作物件
執行緒A:
lock tables t1 read, t2 write;
如果在某個執行緒 A 中執行 lock tables t1 read, t2 write; 這個語句,則其他執行緒寫 t1、讀寫 t2 的語句都會被阻塞。同時,執行緒 A 在執行 unlock tables 之前,也只能執行讀 t1、讀寫 t2 的操作。連寫 t1 都不允許,自然也不能存取其他表。
儘量不要使用全域性表鎖,對於有innodb引擎的資料庫來說,推薦使用:single-transaction
MDL(metadata lock): 不顯示使用,在存取一個表的時候會被自動加上。
server層的鎖;
規則:讀讀共用,讀寫互斥,寫寫互斥;
問題:表加欄位,導致整個庫掛掉
給一個表加欄位,或者修改欄位,或者加索引,需要掃描全表的資料
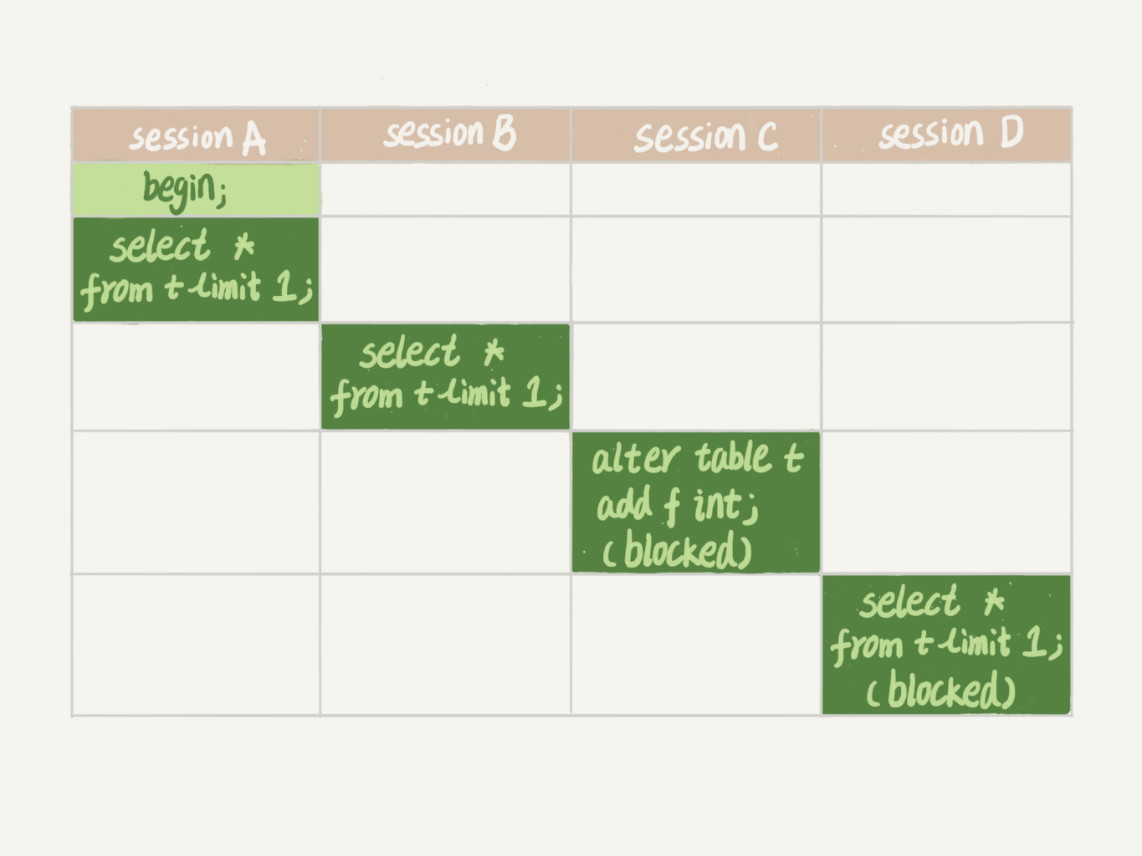
對錶進行增刪改查(隱式提交)的時候都會自動加上MDL;
顯示使用事務:begin---commit;
- sessionA 加讀鎖--未釋放
- sessionB 加讀鎖,讀讀不互斥,可以使用
- sessionC 修改表(加欄位--寫鎖),前面讀鎖未釋放,所以等待
- 後續對於t表的操作都會阻塞
如果某個表上的查詢語句頻繁,而且使用者端有重試機制,也就是說超時後會再起一個新 session 再請求的話,這個庫的執行緒很快就會爆滿;
實踐:


事務提交以後:
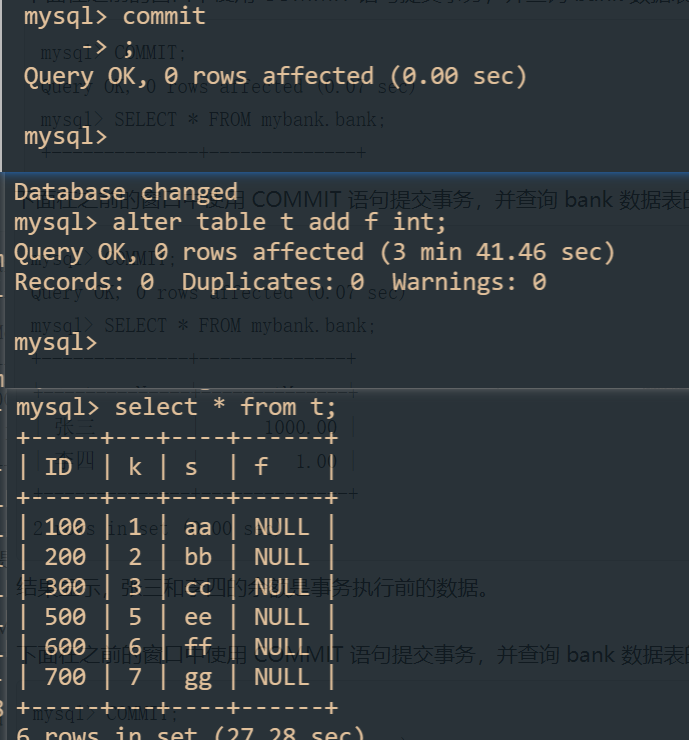
由上引出如何安全給表加欄位:
明確產生的原因:解決長事務,事務不提交,就會一直佔著 MDL 鎖;
如果表的實時性不是很重要,可以考慮暫停DDL的變更或者kill長事務;
表(熱點表--請求頻繁)的實時性很高的話(資料都是熱點資料):
在 alter table 語句裡面設定等待時間,如果在這個指定的等待時間裡面能夠拿到 MDL 寫鎖最好,拿不到也不要阻塞後面的業務語句,先放棄。之後開發人員或者 DBA 再通過重試命令重複這個過程.
ALTER TABLE tbl_name NOWAIT add column ...
ALTER TABLE tbl_name WAIT N add column ...
行鎖(innodb)
行鎖每次鎖定的是一行資料,行級鎖定不是MySQL自己實現鎖定的方式,是由儲存引擎實現的(InnoDB)自己實現的。
兩段鎖:
在 InnoDB 事務中,行鎖是在需要的時候才加上的,但並不是不需要了就立刻釋放,而是要等到事務結束時才釋放。這個就是兩階段鎖協定
通過給索引上的索引項加鎖來實現的,也就意味著:只有通過索引條件檢索資料,InnoDB才使用行級鎖,否則,InnoDB將使用表鎖。這一點在實際應用中特別需要注意,不然的話可能導致大量的鎖衝突,從而影響引發並行效能
--共用鎖就是允許多個執行緒同時獲取一個鎖,一個鎖可以同時被多個執行緒擁有
select ... lock in share mode;
--排它鎖,也稱作獨佔鎖,一個鎖在某一時刻只能被一個執行緒佔有,其它執行緒必須等待鎖被釋放之後才可能獲取到鎖。
select ... for update
如果你的事務中需要鎖多個行,要把最可能造成鎖衝突、最可能影響並行度的鎖儘量往後放。
減少衝突造成的阻塞時間過長。
死鎖和死鎖檢測:
當並行系統中不同執行緒出現迴圈資源依賴,涉及的執行緒都在等待別的執行緒釋放資源時,就會導致這幾個執行緒都進入無限等待的狀態,稱為死鎖
解決策略:
- 直接進入等待,直到超時,超時時間引數:innodb_lock_wait_timeout(預設值50s)
- 發起死鎖檢測,發現死鎖後,主動回滾死鎖鏈條中的某一個事務,讓其他事務得以繼續執行。將引數 innodb_deadlock_detect 設定為 on,表示開啟這個邏輯
對於innodb_lock_wait_timeout的預設值來說,時間太長,如果設定一個很小的值,會造成誤傷。
推薦使用:主動死鎖檢測
檢測對系統來說還是有額外的負擔;這裡有一個邊界情況:所有事務都要更新同一行的場景
假設有 1000 個並行執行緒要同時更新同一行,那麼死鎖檢測操作就是 100 萬這個量級的。雖然最終檢測的結果是沒有死鎖,但是這期間要消耗大量的 CPU 資源。因此,你就會看到 CPU 利用率很高,但是每秒卻執行不了幾個事務
怎麼解決由這種熱點行更新導致的效能問題呢?
問題的癥結在於,死鎖檢測要耗費大量的 CPU 資源。
-
臨時關閉死鎖檢測,但並不可靠
-
控制並行度:控制同一行最大執行緒運算元
問題:如果你要刪除一個表裡面的前 10000 行資料,有以下三種方法可以做到:
- 第一種,直接執行 delete from T limit 10000;(X)
- 第二種,在一個連線中迴圈執行 20 次 delete from T limit 500;(
√) - 第三種,在 20 個連線中同時執行 delete from T limit 500。(X)
你會選擇哪一種方法呢?為什麼呢?
- 長事務,佔用的時間比較長,造成等待時間較長,應該避免;
- 將一個長事務,分為20個短事務,每次事務佔用鎖的時間相對較短;
- 造成鎖衝突,當第一個連線中的事務沒有提交,那麼會阻塞剩餘執行緒。
部分圖片引入來源:MySQL實戰45講