論文閱讀 dyngraph2vec: Capturing Network Dynamics using Dynamic Graph Representation Learning
6 dyngraph2vec: Capturing Network Dynamics using Dynamic Graph Representation Learning207
DTDG
Abstract
本文通過迴圈(在文中表示為LSTM)和稠密(在文中表現為autoencoder)網路學習圖中的時間變換。
Conclusion
本文介紹了動態網路中用於捕獲時間模式的dyngraph2vec模型。它學習了單個節點的進化模式,並提供了一種能夠更精確地預測未來連結的嵌入方式。基於具有不同功能的架構,提出了模型的三種變體。實驗表明,我們的模型可以在合成資料集和真實資料集上捕捉時間模式,並在連結預測方面優於最先進的方法。未來的研究方向如下:(1)通過擴充套件模型的可解釋性,以更好地理解網路和時間的動態變化(2)自動超引數優化,提高精度;(3)通過圖折積學習節點屬性,減少引數數量。
Figure and table
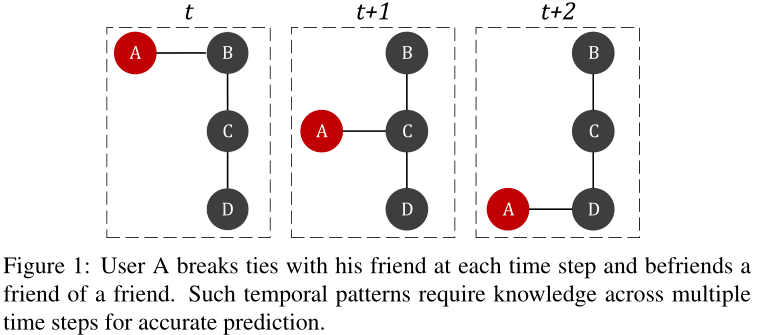
圖1 表示使用者A在每個時間步下,和上個朋友斷交,與朋友的朋友建交(用這個例子說明當A與C建交時,基於靜態網路的方法只能觀察t + 1時刻的網路,無法確定下一個時間步A是和B還是D成為朋友。相反,觀察多個快照可以捕捉網路動態,並高確定性地預測A與D的連線)

圖2 不同模型下的社群轉移
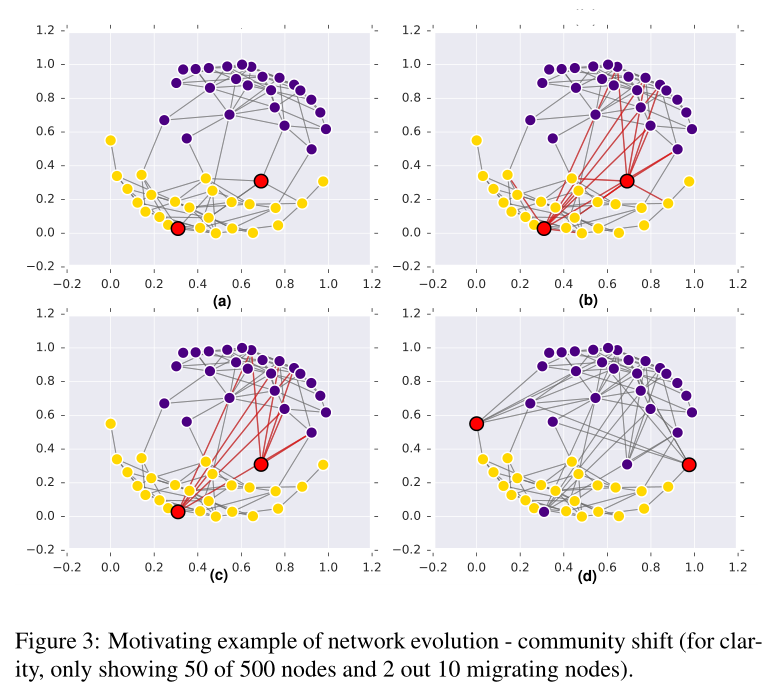
圖3 社群轉移的具體例子 從500個點中選50個作為樣例說明
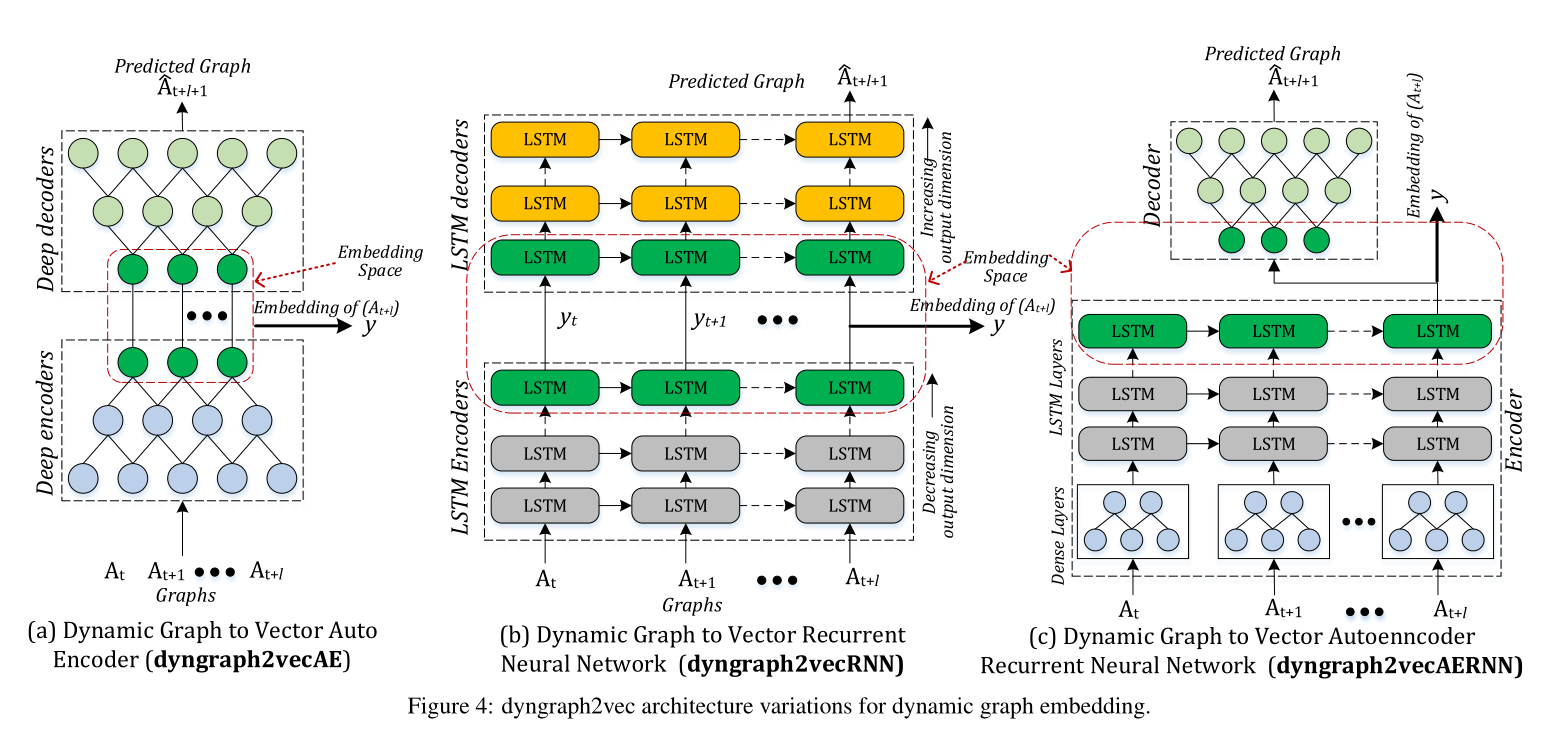
圖4 動態圖嵌入的Dyngraph2vec模型架構變體。
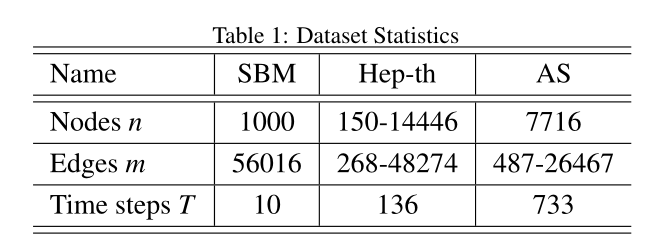
表1 資料集引數
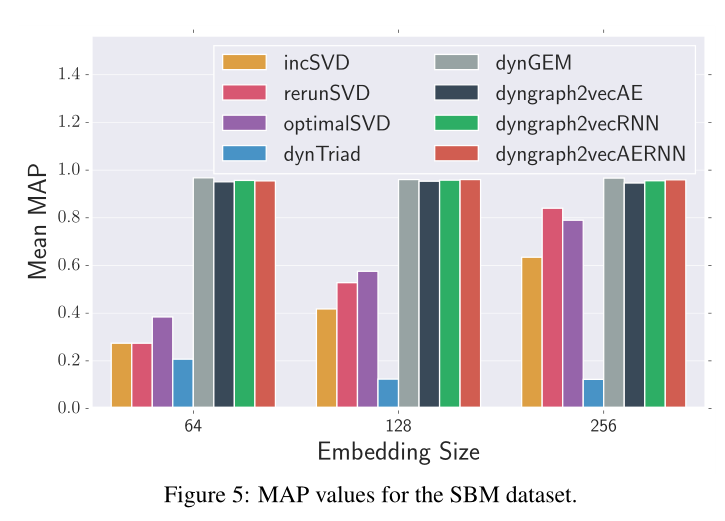
圖5 SBM資料集的MAP值。

圖6 Hep-th資料集的MAP值
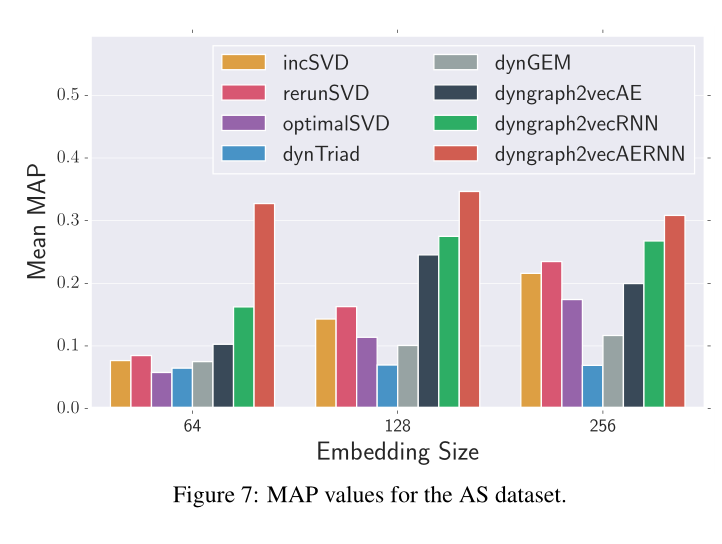
圖7 AS資料集的MAP值

表2 不同嵌入尺寸的平均MAP值
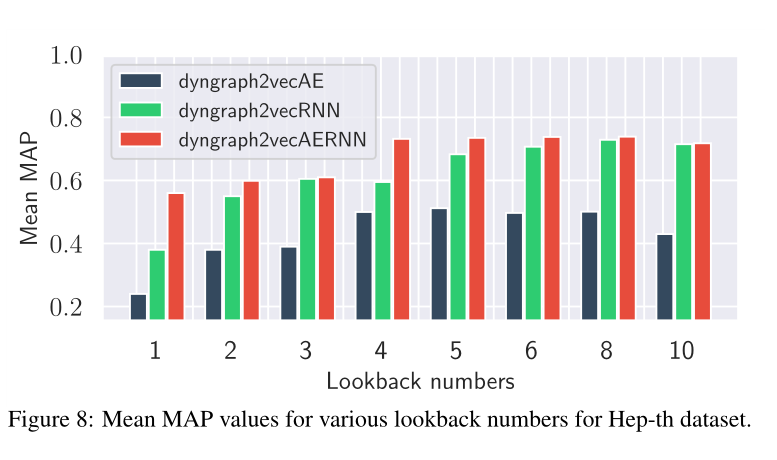
圖8 在Hep-th資料集下,各種回看值(由lookback翻譯來,下同)的平均MAP值。
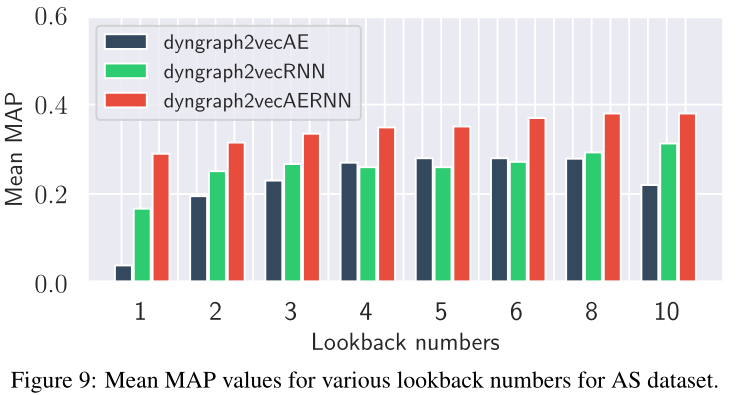
圖9 在AS資料集下,各種回看值(由lookback翻譯來,下同)的平均MAP值。
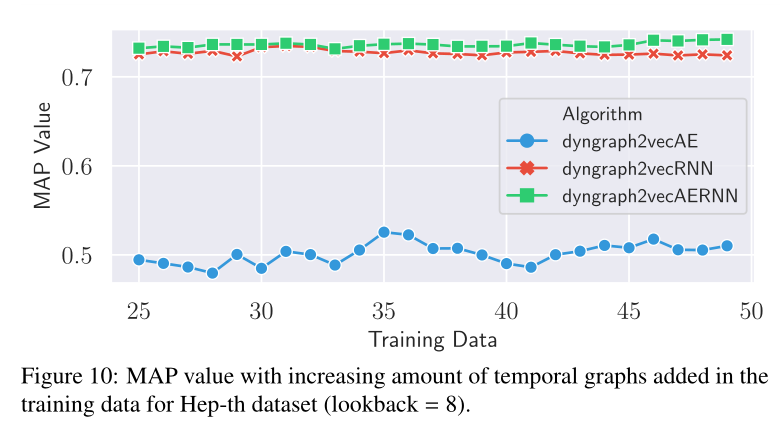
圖10 在Hep-th資料集的訓練資料中,MAP值隨時間圖數量(快照數量)的增加而增加
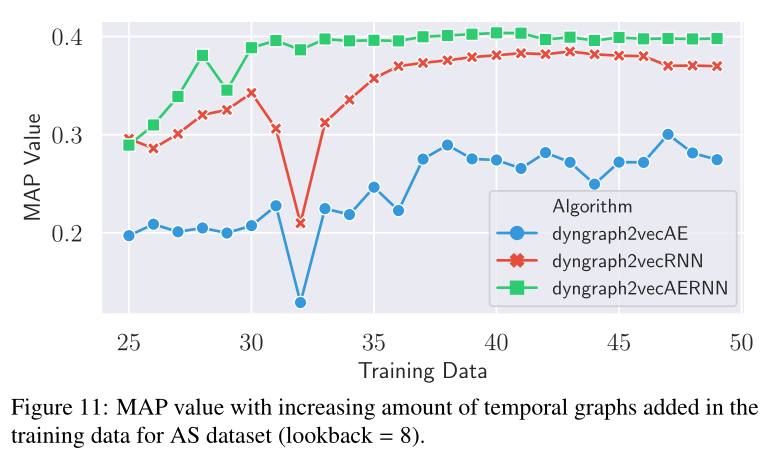
圖10 在AS資料集的訓練資料中,MAP值隨時間圖數量(快照數量)的增加
Introduction
總結如下
1 靜態表示預測能力不如快照下的預測
2 不同的邊持續時間不同,DynamicTriad[15]、DynGEM[16]和TIMERS[17]方法假設模式持續時間較短(長度為2)只考慮之前的時間步長圖來預測新連結。此外,DynGEM和TIMERS假設變化是平滑的,並使用正則化來禁止快速變化。
3 所以本文提出了Dyngraph2vec,使用多個非線性層來學習每個網路中的結構模式。此外,它利用迴圈層來學習網路中的時間轉換。迴圈層中的回顧引數控制學習到的時間模式的長度。
本文的4點貢獻
1)提出了動態圖嵌入模型dyngraph2vec,該模型捕捉時間動態。
2)證明了捕獲網路動態可以顯著提高鏈路預測的效能。
3)將展示模型的各種變化,以顯示關鍵的優勢和差異。
4)釋出了一個庫DynamicGEM,實現了dyngraph2vec和最先進的動態嵌入方法的變體
Method
4. Methodology
4.1. Problem Statement
對於權重圖\(G(V,E)\), \(V\)為頂點集,\(E\)為邊集,\(A\)為該圖的鄰接矩陣,即對於一條邊\((i, j)\in E\), \(A_{ij}\)表示其權值,否則\(A_{ij}=0\)。圖G的演化記為\(G = \{ G_1,..., G_T \}\),其中\(G_t\)表示圖在t時刻的狀態。
我們定義我們的問題如下:給定圖\(G\)的一個演化\(\mathcal{G}\),目標是通過對映\(f\), 使得圖中的節點對映到低位空間中表示為$ { y_{v_1}, . . . y_{v_t}} \(,其中\)y_{v_t}\(表示為節點\)v\(在時間\)t\(的嵌入,具體來說描述為:\)f_t : { V_1, . . . , V_t, E_1, . . . E_t } →R^d\(,\)y_{v_i} = f_i(v_1, . . . , v_i, E_1, . . . E_i)\(,這樣\)y_{v_i}\(就能捕捉到預測\)y_{v_{i+1}}$所需的時間模式。換句話說,每個時間步的嵌入函數利用圖演化的資訊來捕捉網路動態,從而可以更精確地預測鏈路。
4.2. Dyngraph2vec
dyngraph2vec是一個深度學習模型,它將之前的一組圖作為輸入,並在下一個時間步生成作為輸出的圖,從而在每個時間步和多個時間步捕獲頂點之間高度非線性的相互作用。因為嵌入可以捕獲網路的連結時序演化,這使得我們可以去預測連結,模型通過優化以下損失函數學習時間步長t時的網路嵌入:
\(t+d\)時刻的嵌入是圖在\(t,t+1,...,t+l\)時刻的函數,即可寫作\(y_{t+l} = f(y_t,y_{t+1},...,y_{t+l})\)(原文這裡寫的The embedding at time step t+d is a function of the graphs at time steps t, t+1, . . . , t+l where l is the temporal look back)
這裡用\(t\)到\(t+l\)時間段的快照來預測\(t+l+1\)的圖的情況,\(\mathcal{B}\)作為權重矩陣,給存在的邊加權為\(\beta\),即
if (i, j) in E[t+l+1] :
B[i][j] = beta
else:
B[i][j] = beta
其中
\(\beta\)為給定的超引數
\(\odot\)為哈達瑪積
基於圖4所示的深度學習模型架構,提出了三種模型變體:
(1) dyngraph2vecAE
(2) dyngraph2vecRNN
(3) dyngraph2vecAERNN
三種方法只在對映函數f(.)的表述上有所不同。
如果想把編碼器擴充套件到動態圖上使用,一個簡單的方法是將關於以前\(l\)個圖的快照資訊作為輸入新增到自動編碼器中。
因此,模型dyngraph2vecAE使用多個完全連線的層來對時間內和跨時間的節點互連進行建模。
具體來說,對於節點u的鄰居向量集\(u_{1..t} = [a_{u_t}, . . . , a_{u_{t+l}}]\),第一層的隱藏表示為:
其中
\(f_a\)為啟用函數
至此我一個一個引數看了一遍,想弄清楚(2)這個式子輸入輸出的維度,沒看懂,他前面說以前\(l\)個圖的資訊作為輸入新增到自動編碼器中,在後面實驗的分析階段我看lookback的值\(l\)是大於0的值。也就是說對於上式來說,我想在lookback的值為l的情況下,得到節點u在t時刻的嵌入,我猜測上式的\(u_{1..t}\)應改為\(u_{1..t} = [a_{u_{t-l}}, . . . , a_{u_{t}}]\)(下面的dyngraph2vecRNN和dyngraph2vecAERNN也一樣),總不能為了得到\(t\)時刻的嵌入去輸入\(t\)到\(t+l\)時刻的狀態吧,
(作者原話: 所以我我感覺這個地方應該是他寫錯了)
所以我我感覺這個地方應該是他寫錯了)
其中\(a_{u_{t}}\)表示為在\(t\)時刻節點\(u\)的鄰接向量,\(a_{u_t} \in \mathbb{R}^n\)
所以這裡有幾個維度,鄰接向量的\(n\)即為\(n\)個節點,回顧值的\(l\),輸出維度\(d^{(1)}\),所以\(W_{A E}^{(1)} \in \mathbb{R}^{d^{(1)} \times n l}\)
定義第k層的表示為
為了減少模型引數的數量(\(k*n*l*d^{(1)}\)),實現更有效的時序學習,提出了dyngraph2vecRNN和dyngraph2vecAERNN。
dyngraph2vecRNN中引入LSTM的結構,公式模型如下
貼一下知乎大佬關於lstm的解釋:https://zhuanlan.zhihu.com/p/463363474
其中
\(C_{u_{t}}\)表示為單元記憶儲存(cell memory&cell states)
\(f_{u_{t}}\)表示為遺忘門閾值
\(o_{u_{t}}^{(1)}\)表示為輸出門閾值
\(i_{u_{t}}^{(1)}\)表示更新門的閾值
\(\tilde{C}_{u_{t}}^{(1)}\)當前時刻的新資訊(candidate values)有哪些需要新增到cell states
\(b\)為偏置項
在第一層連結\(l\)個LSTM將\(C_{u_{t}}\)和嵌入以鏈式的形式從\(t−l\)傳遞到\(t\)時刻的LSTM那麼第\(k\)層的表示如下:
能看到,如果直接用lstm的架構,但節點u的鄰居是一個稀疏向量,就會導致引數量變大,所以作者提出dyngraph2vecAERNN,利用autoencoder去降維表示後再過lstm去做時序的資訊捕捉,可寫為
其中p為全連線編碼器的輸出層。然後將這個表示傳遞給LSTM網路
然後將LSTM網路生成的隱藏表示傳遞給全連線解碼器。
4.3 Optimization
使用隨機梯度下降和(Adam)對模型進行優化。
Experiment
5. Experiments
5.1 Datasets
資料集
5.2 baseline
Optimal Singular Value Decomposition (OptimalSVD):
Incremental Singular Value Decomposition (IncSVD):
Rerun Singular Value Decomposition (RerunSVD or TIMERS):
Dynamic Embedding using Dynamic Triad Closure Process(dynamicTriad) :
Deep Embedding Method for Dynamic Graphs(dynGEM) :
5.3. Evaluation Metrics
在我們的實驗中,我們通過使用時間步長t之前的所有圖來評估我們的模型在時間步長t + 1的鏈路預測。評估方法為MAP
6.Results and Analysis
sota情況見圖5,6,7
超引數(lookback value and length of training sequence)影響見圖8,9,10,11
Summary
讀下來感覺下標和引數解釋不太清楚,尤其是對於時序下標的編寫,讀起來要比較費勁甚至去猜作者什麼意思,這篇論文告訴我在問題定義小節應該儘可能的把除了模型的其他引數解釋明白(比如對鄰居集的定義)。再回過來說模型,autoencoder+lstm的組合效果看起來還不錯,感覺算是一種處理非歐時序結構的基礎模型。