羅景:連線效率優化實踐
分享嘉賓:羅景 58同城 高階架構師
編輯整理:洪鵬飛
內容來源:DataFun AI Talk《連線效率優化實踐》
出品社群:DataFun
導讀:本次分享由以下幾個部分構成——
- 58的業務背景
- 綜合排序框架
- 效率優化框架
- 基礎資料流程(資料)
- 策略優化路徑(演演算法)
- 效率優化平臺(工程)
- 總結和思考

--
01 58的業務背景
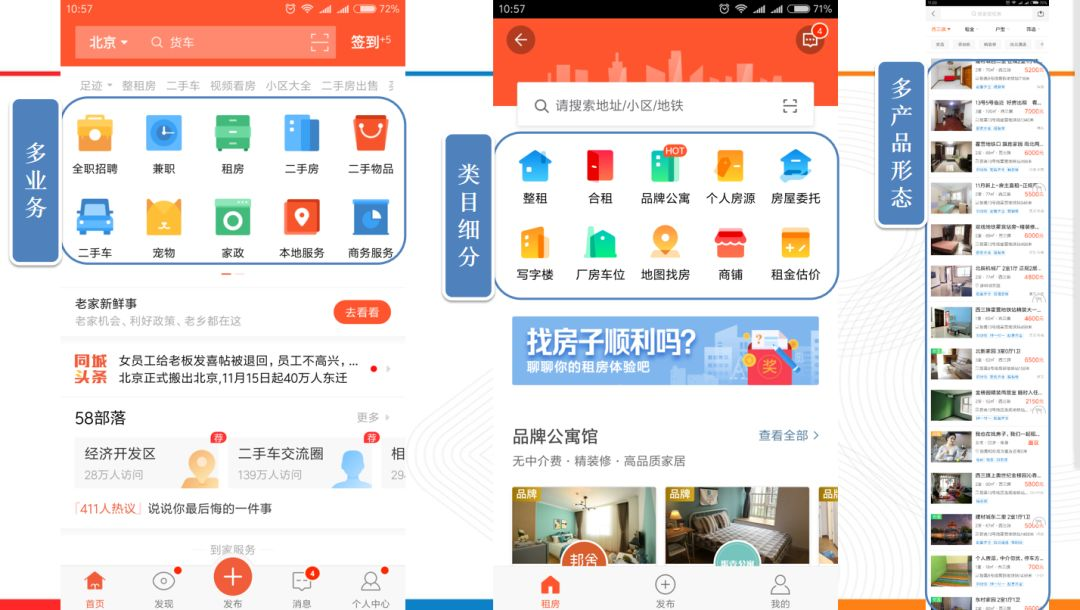
這是58app端的業務展示,可以看出58的業務場景豐富且複雜,產品形態多樣,涵蓋了租房、二手房、二手車、招聘、本地服務以及二手物品等多種業務,針對每個業務,又分為置頂,精品,普通等多種不同的產品形態。
--
02 綜合排序框架

如上圖所示,整個演演算法層分為三個階段:粗排、精排和調序。
粗排階段,主要考慮減小模型壓力,篩選出一部分排序候選集。主要採用時效性策略以及質量因子的降權策略。分別根據不同週期進行分層處理,用於時間降權;同時對質量因子,採用價格偏離、類目錯發、位置虛假等因子進行降權排序。
精排階段,主要考慮列表點選率、有效轉化率、個性化以及相關性資訊,對粗排後的集合進行精細化排序。
調序階段,根據業務相關以及過濾相關等策略進行重新排序。
在上述粗排、精排以及調序三個階段中,演演算法團隊重點輸出了質量治理,效率優化以及流量調控三種核心能力。
--
03 效率優化框架
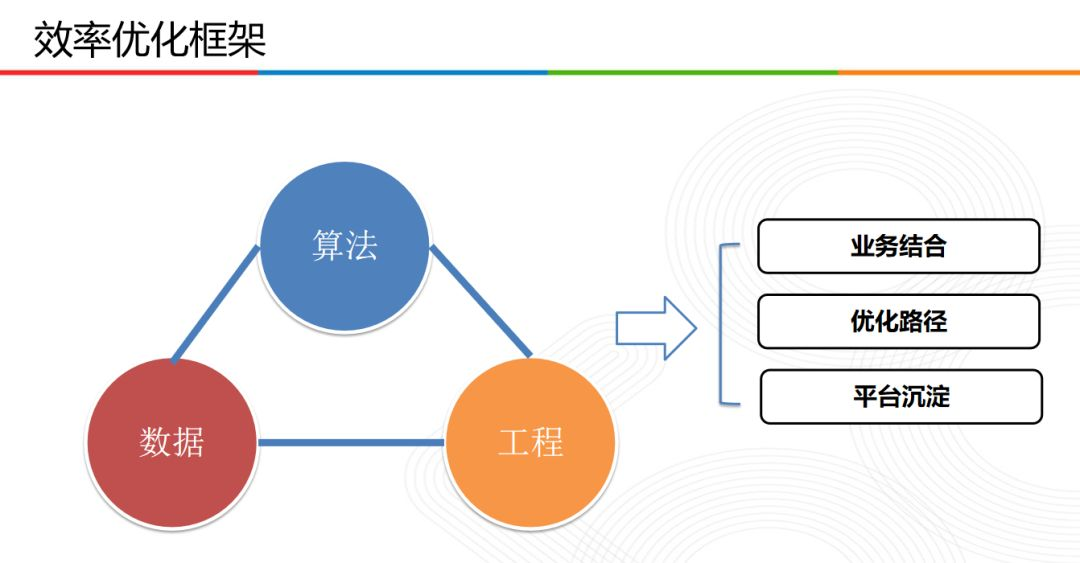
效率優化框架由三部分組成:資料、演演算法以及工程。在進行效率優化框架設計和迭代過程中,主要結合相關業務,對策略的相關優化路徑進行迭代更新,最後對相關技術以及方案進行相關積累,形成平臺化沉澱,方便以後複用。
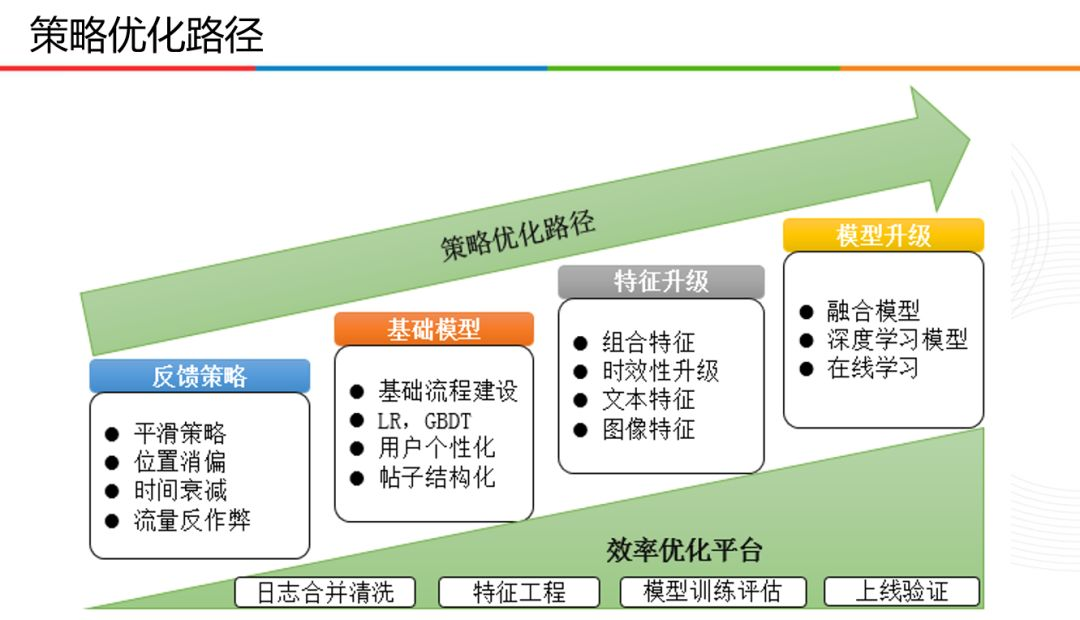
優化路徑,包括:策略優化路徑和效率優化平臺。
關於策略優化路徑,主要分為四個階段:
- 反饋策略。這主要運用於業務建模初期,採用平滑策略,位置消偏,時間衰減,流量反作弊策略進行初期模型的相關排序;
- 基礎模型。主要進行基礎流程建設,涉及LR、GBDT模型,使用者個性化,貼文結構化這幾方面進行優化;
- 特徵升級。主要針對組合特徵,時效性升級,文字特徵以及影象特徵幾個方面,使模型效果更佳;
- 模型升級。主要針對融合模型,深度學習模型,以及線上學習方面進行相關迭代。
關於效率優化平臺,主要針對紀錄檔合併清洗,特徵工程,模型訓練評估以及上線驗證四個階段進行優化。

進一步對效率優化平臺進行介紹:主要針對紀錄檔系統,紀錄檔樣本,機器學習,上線試驗以及線上系統進行相關優化。
- 紀錄檔系統:針對紀錄檔樣本、機器學習、上線試驗這幾個方面進行平臺化整合,包括流程執行、流程管理、特徵開放以及設定管理等。
- 紀錄檔樣本:涉及紀錄檔預處理,貼文特徵抽取,個性化生成,樣本生成等;
- 機器學習:涉及樣本取樣,特徵工程,模型訓練,評估分析等;
- 上線試驗:涉及推播流程,實驗系統,報表系統等。
接下來對涉及到的相關技術點進行介紹:
- 資料:日反作弊、特徵開放平臺、樣本選取;
- 演演算法:反饋策略、基礎模型、特徵升級、模型升級;
- 工程:特徵元件化、融合模型框架化、平臺化整合。
1. 基礎資料流程(資料)
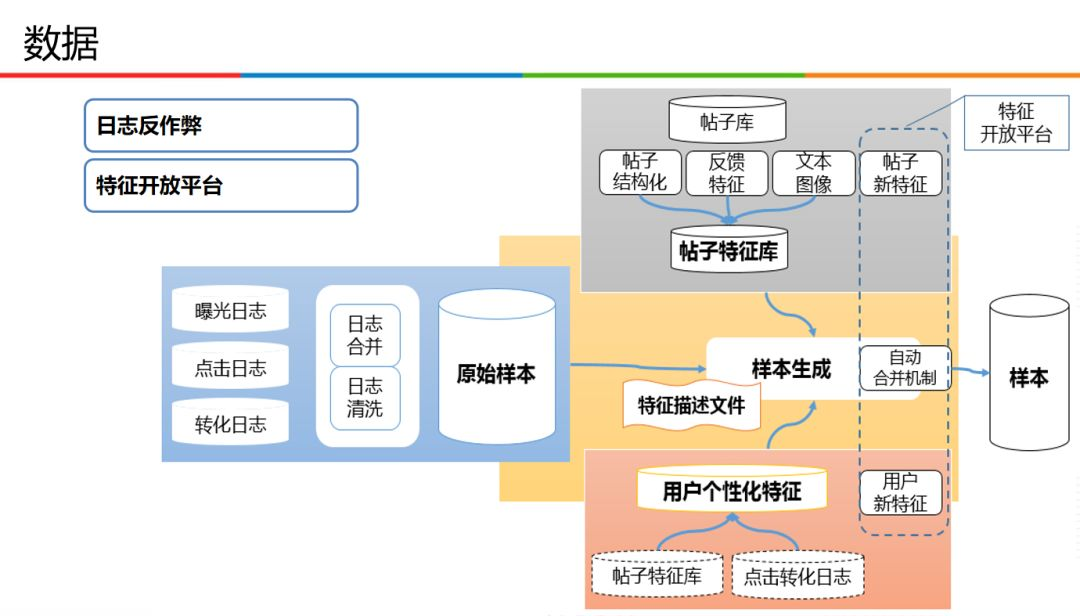
關於資料,主要涉及紀錄檔反作弊和特徵開放平臺。
資料的生成分為兩個階段,第一個階段為原始樣本生成,第二個階段為樣本生成。
原始樣本主要來自於曝光、點選以及轉化紀錄檔,在相關紀錄檔的合併以及清洗之後可以獲得原始樣本資料。
樣本生成,主要是在特徵開放平臺上生成。涉及到貼文特徵庫,使用者個性化特徵,以及相關的特徵描述檔案。
其中,貼文特徵庫由貼文結構化,反饋特徵,文字影象特徵三個方面組成;使用者個性化特徵,主要由貼文特徵庫和點選轉化紀錄檔而來。
對於樣本新特徵問題,平臺採用自動合併機制,對新增加的貼文新特徵以及使用者新特徵進行合併。
經過上述兩步的處理,樣本資料便形成了。

在資料紀錄檔反作弊階段,主要針對IP,使用者進行相關紀錄檔反作弊處理,主要涉及到多指標判斷機制以及作弊標記機制:
- 在多指標判斷機制中,主要有曝光量、點選量、轉化量、點選率、轉化率這多個指標進行相關的判斷;
- 在作弊標記機制中,主要對特徵的欄位進行相關的作弊型別標識。
下面是針對IP反作弊規則的例子:
- 採用曝光大於某個閾值,CTR小於某個閾值,對曝光異常但是點選合理的IP資料進行相關的過濾;
- 採用曝光大於某個閾值,轉化小於某個閾值,過濾掉曝光異常但轉化量偏低的IP資料;
- 採用CTR大於某個閾值,過濾掉CTR異常的IP資料;
- 採用轉化除以點選大於某個閾值,過濾掉點選到轉化異常的IP資料;
- 採用CVR大於某個閾值,過濾掉CVR異常的IP資料等等。

模型的效果主要由特徵,特徵工程以及演演算法組成,特徵工程在模型效果方面表現的異常重要。資料特徵開放平臺是主要為了簡化新特徵嘗試流程,降低嘗試代價,並快速支援試驗。特徵開放平臺採用規範化後設資料描述、管理,自定義合併機制,支援時效性對齊,自動觸發,以及客製化化回溯機制,其基本流程為,首先在特徵註冊平臺上進行註冊,完善特徵的後設資料描述;接著按規範格式與約定時效性在給定的儲存位置生成資料;最後根據樣本生成流程基於特徵描述緊張自動化合並。
2.策略優化路徑(演演算法)

反饋策略在建模初期使用,主要採用平滑策略,位置消偏,時間衰減三種策略進行優化迭代,對準實時反饋以及歷史反饋分別進行7天為週期分鐘級捲動統計點選率和轉化率以及30天為週期按天捲動的點選率與轉化率。在實行反饋策略後,實時點選率有10%的提升,而歷史轉化率方面,轉化效果有一定提升。

在資料樣本選取方面,支援多種場景,例如模型型別、業務型別、產品形態,並實現了靈活設定樣本的選取機制,大致有以下四種機制:
- 基於表示式;
- 預定義預設元件(Raito,Pos,Neighbor,Random,Unique..);
- 組合方式(and,or,not);
- 自定義元件。
同時可以採用標準方式選取,相關範例取樣以及樣本過濾操作。

在基礎階段模型上,通常採用14天的資料做訓練,並取樣成1:15的正負樣本比例,使用3天資料做為測試,並以AUC作為主要離線評測指標。原始特徵在150維左右,針對LR模型採用離散化編碼處理方式,特徵超高維度。模型方面,對原始特徵主要採用XGB進行訓練。
在效果方面,針對租房普通列表頁面上,有20%以上的轉化率提升;而在租房精選上實現了30%以上的ECPM提升;而在普通列表頁面上,電話接通率提升10%以上。
3.效率優化平臺(工程)
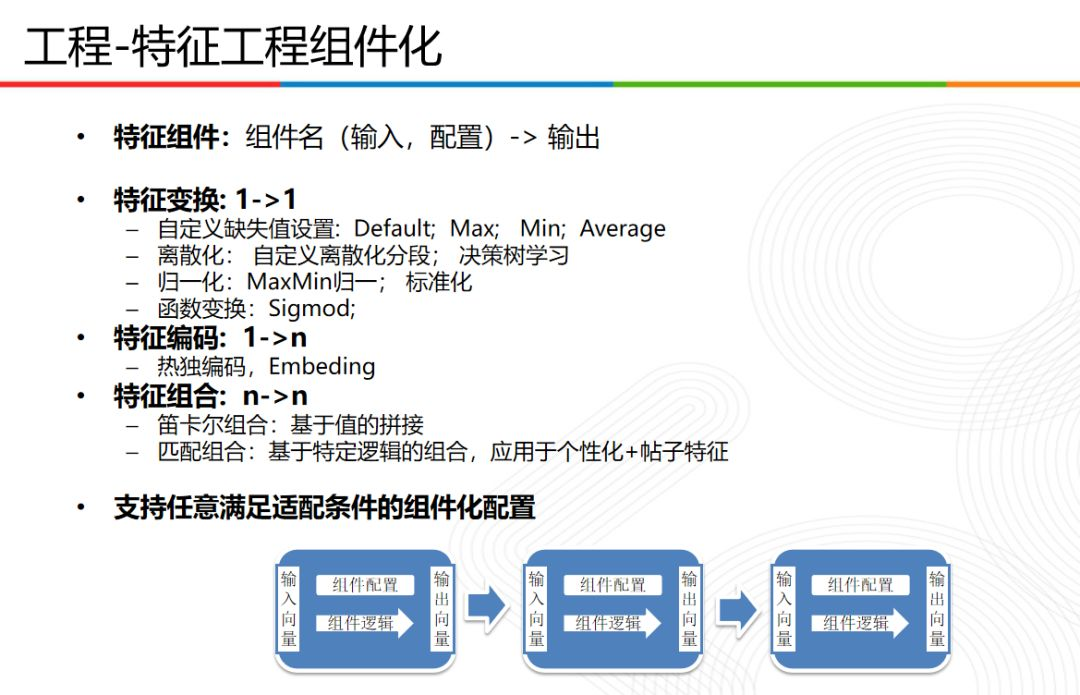
在特徵工程元件化方面,採用元件名(輸入,設定)到輸出的設定方案,其中涉及1對1的特徵變換,1對n的特徵編碼,n對n的特徵組合,同時還滿足各種適配條件進行相關元件化設定。
在工程融合模型框架化方面,可以擁有以下兩種功能:
第一種,支援表示式設定,靈活,支援多種形式的組合;
第二種,樣本標識機制下,保證了批次處理框架下的樣本對齊。
同時模型融合方面,主要採用結果融合以及特徵融合,結果融合主要將模型預測結果作為特徵,而特徵融合方面,利用訓練好的模型來構建特徵,例如GBDT編碼特徵,NN編碼,FM隱向量等方式。
融合流程:
- 第一步,在效率優化平臺按照正常流程訓練好待融合模型;
- 第二步,準備目標模型樣本資料;
- 第三步,基於樣本資料生成基於待融合模型提取的特徵;
- 第四步,將初始樣本資料與根據帶融合模型提取的特徵進行合併,形成融合模型樣本;
- 第五步,訓練目標模型。
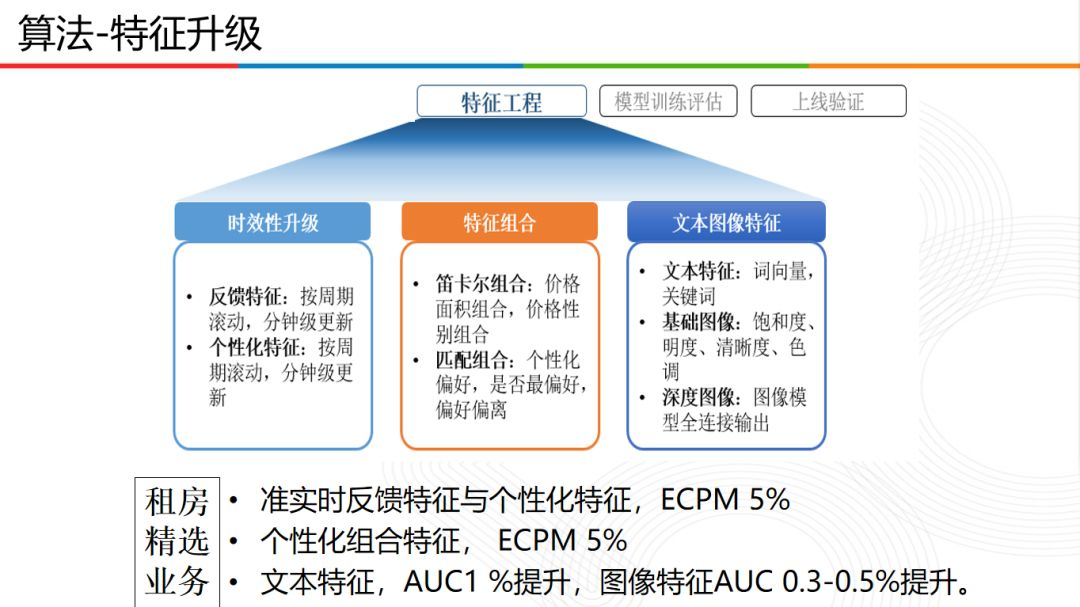
特徵升級主要包括:
- 時效性升級:反饋特徵按週期捲動,分鐘級更新,同時還提取了相應週期的個性化特徵;
- 特徵組合:採用笛卡爾組合和匹配組合方式,例如價格面積組合,價格性別組合,個性化偏好等;
- 文字影象特徵:採用詞向量,關鍵詞,影象飽和度,影象全連線模型輸出特徵等。
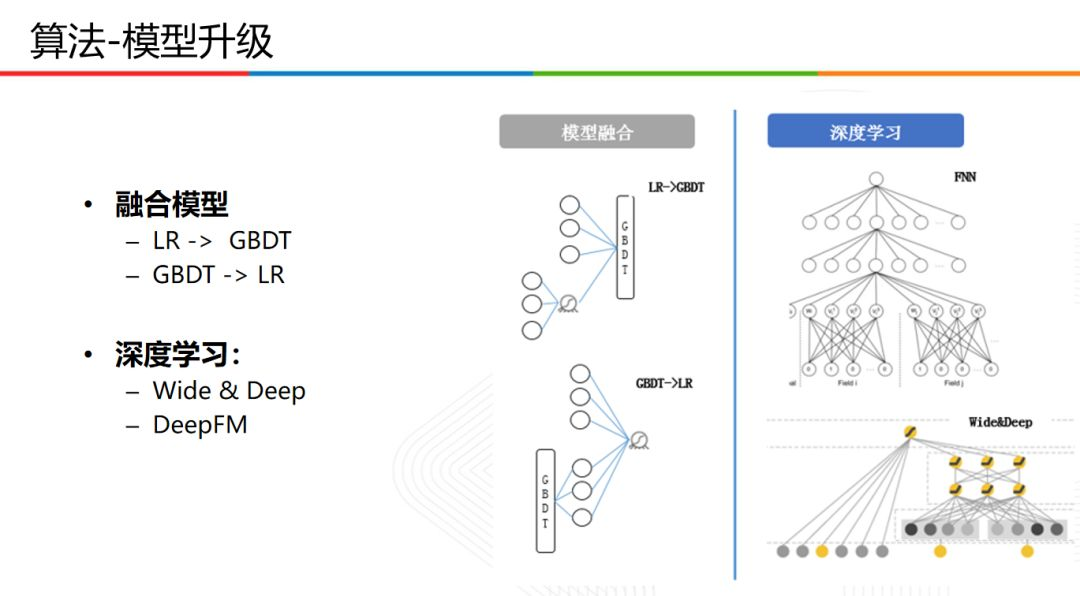
關於模型升級,主要採用LR的預測結果接入GBDT,或者GBDT的結果接入LR;而在深度學習方面,採用Wide&Deep以及DeepFM等技術實現演演算法迭代。

在WideDeep實現方面,主要將wide部分的連續特徵進行離散化,相關特徵有RCrctr,HCtagfhgectrap等特徵;並將列舉離散化特徵,主要用於離散特徵個數較少的情況;而Hash離散特徵,主要使用者離散值數量較大的特徵,離散分桶最大值為5000;在交叉特徵方面,主要由貼文維度組合,貼文與使用者基礎屬性組合。而在deep部分,連續特徵主要採用離散化最大最小歸一化處理,列舉離散特徵和wide部分一致,而Hash離散特徵採用embedding_size方式,而在Embedding特徵方面,採用個性化加個性化組合的方式。
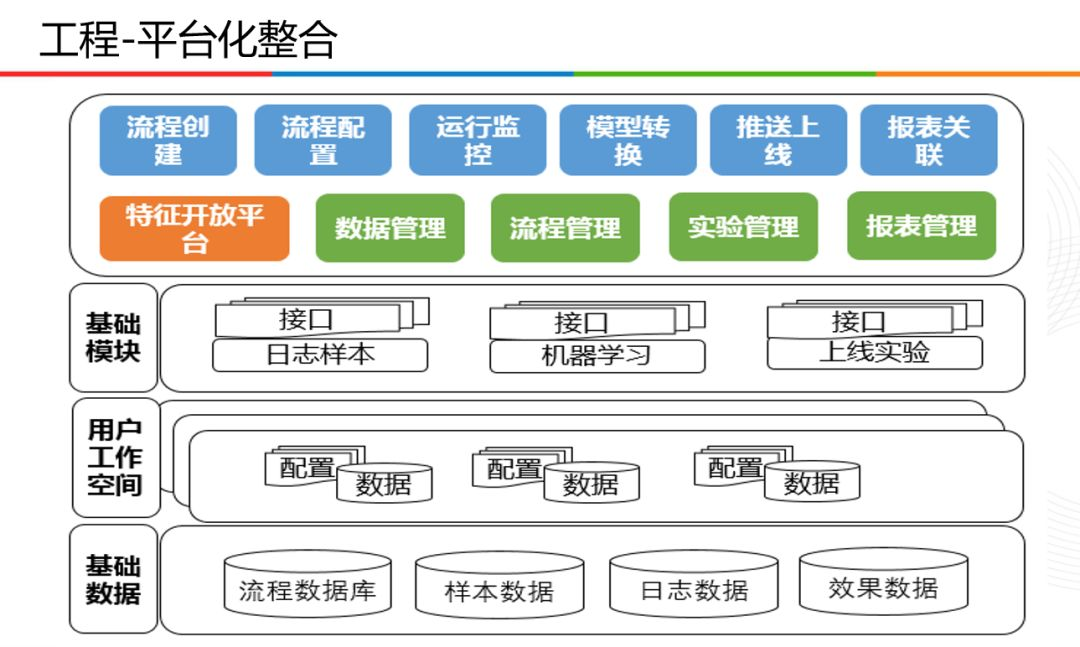
而在平臺整合方面,主要由三個大的模組組成:
- 第一個模組為基礎模組,包括紀錄檔樣本、機器學習以及上線試驗;
- 第二個模組為使用者工作空間,主要用於資料相關的設定;
- 第三個模組為基礎資料,主要涉及流程資料庫,樣本資料,紀錄檔資料,和效果資料。
通過這三個模組,平臺擁有流程建立,流程設定,執行監控,模型轉換,推播上線,報表關聯等功能,同時應對了特徵開放平臺,資料管理,流程管理,實驗管理,報表管理等方面。
上圖為機器學習平臺的設定頁面,可以看出從基礎設定,訓練取樣,測試取樣,特徵以及訓練,可以看出模型測試和訓練簡潔便利,做到了5+專屬的流程切換,全效率優化流程管理,策略成電分享複用,也降低了維護代價,降低優化的門檻。
4.效果和下一步
經過整個流程的優化,可以看出效果:房產精選(二手房精選、租房精選)實現了相比基線40%到60%的ECPM(千次展現收入)提升。而在普通業務方面,租房,二手房,二手車上實現10%的轉化率提升。
下一階段,將對深度學習進行相關的探索,嘗試多種深度模型,並整合Tensorflow到模型訓練流程,探索線上、離線學習一體化平臺,同時要利用豐富的資料,例如有效轉化資料,文字影象視訊特徵等。
--
04 總結&思考
在策略優化上,要儘可能循序漸進,關注資料豐富度與質量,同時明確業務優化目標,兵保證線下線上的一致性,此外還要保證新技術探索與優化目標的權衡。在平臺建設上,要重視工程能力,監控預警機制,同時進行迭代優化。
今天的分享就到這裡,謝謝大家。
本文首發於微信公眾號「DataFunTalk」。