B 樹的簡單認識
理解 B 樹的概念
B 樹是一種自平衡的查詢樹,能夠保持資料有序。這種資料結構能夠讓查詢資料、順序存取、插入資料及刪除資料的動作,都能在對數時間內完成。
同一般的二叉查詢樹不同,B 樹是一棵多路平衡查詢樹,其特性是:結點的孩子結點數可以多於兩個,且每一個結點處可以儲存多個元素。
在 B 樹中,非葉子結點可以擁有可變數量的子結點,為了維持在預先設定的數量範圍內,通常是對非葉子結點進行合併和分離。其優勢是不需要像其他自平衡查詢樹那樣頻繁地重新保持平衡,其劣勢是結點未被完全填充時會浪費一些空間。
特性
通常,我們會在 B 樹的名稱前新增階數以示說明,如 m 階 B 樹。一個 m 階的 B 樹具有以下特性:
- 任意結點最多有 m 個孩子結點
- 任意除根結點以外的非葉子結點最少有 \(\frac{m}{2}\) 個子結點
- 如果根結點不是葉子結點,那麼它至少有 2 個孩子結點
- 有 k 個孩子結點的非葉子結點有 k-1 個鍵
- 所有的葉子結點都在同一層,B 樹也是通過此約束來保持樹的平衡
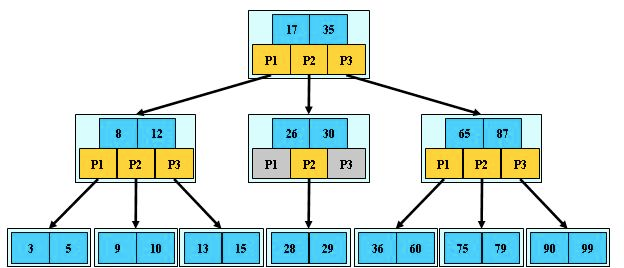
下述展示的是一個 3 階 B 樹:
變體
B 樹可以指一個特定的樹形結構,也可以指大體上的一類樹形結構。
對於 B 樹這一類樹形結構,還包括了 B+ 樹和 B* 樹等結構,它們的簡單定義如下:
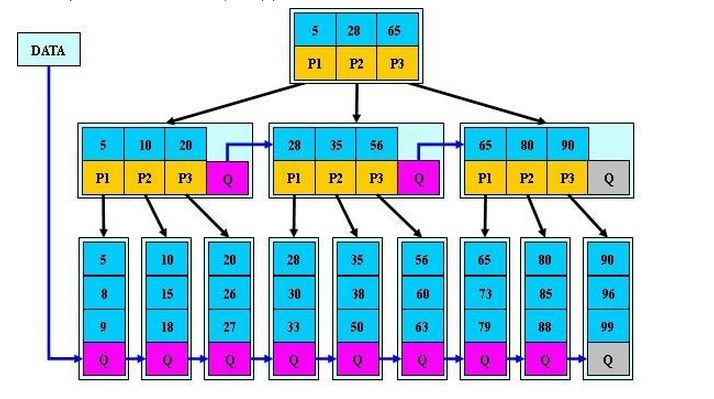
對於 B+ 樹,關鍵字只儲存在葉子結點,非葉子結點儲存的是葉子結點所儲存關鍵字的部分拷貝,所有的葉子結點也都在相同的高度,葉子結點本身按關鍵字大小從小到大連結。
B* 樹是 B+ 樹的變體,在 B+ 樹的基礎上,非葉子結點(除根結點外)會增加指向同一層兄弟的指標,且非葉子結點關鍵字個數至少為 \(\frac{2m}{3}\),即塊的最低使用率為 \(\frac{2}{3}\)(B+ 樹為 \(\frac{1}{2}\))。
下面為 B* 樹的結構:
起源和運用
其實,B 樹就是一種為磁碟而設計的樹形結構,主要是降低其他樹形結構存取磁碟的 IO 次數。
磁碟讀取
從磁碟讀取資料的時間主要涉及到「尋道時間」和「旋轉延遲」:
- 尋道時間指的是磁碟接收到系統指令後,磁頭從頭開始移動到資料所在磁軌所需要的時間,可能是 0 到 20 毫秒甚至更久
- 旋轉延遲指的是尋道結束後,磁碟將對應的磁區旋轉到磁頭下所需要的時間,其平均時間大約在旋轉週期的 50% 左右,對於一個 7200 轉的磁碟,採用 60×1000÷7200 的公式計算得知一次旋轉週期事件為 8.33 毫秒左右
磁碟的順序讀寫會比隨機讀寫快也是這個原因,在順序讀寫時,磁頭不需要再做尋道,僅需很少的旋轉時間,而隨機讀寫則需要不停地移動磁頭尋找對應的磁軌。
磁碟預讀
為了儘量減少 IO 操作,計算機系統一般採取預讀的方式,預讀的長度一般為頁(Page)的整數倍。
頁是計算機管理記憶體的邏輯塊,硬體及作業系統往往將主記憶體和磁碟儲存區分割為連續的大小相等的塊,每個儲存塊稱為一頁(多數作業系統頁的大小為 4k),主記憶體和磁碟以頁為單位交換資料。
計算機系統是分頁讀取和儲存的,每次讀取和存取的最小單元為一頁,而磁碟預讀時通常會讀取頁的整數倍。
索引結構
對於檔案系統和資料庫系統的索引,通常以檔案的形式儲存在磁碟上,因此查詢索引也會執行磁碟 IO 操作,如果查詢過程中磁碟 IO 的存取次數過多會影響索引的效率。
資料庫系統普遍使用 B 樹或者 B+ 樹作為索引結構,其巧妙地利用了磁碟預讀原理,將一個結點設定為一個頁的大小,這樣每個結點只需要一次 IO 就可以完全載入。
同時,在使用過程中還運用了以下技巧:
- 每次新建結點時,直接申請一個頁的空間,實現一個結點只需一次 IO
- 將根結點常駐記憶體,在實際使用時可以減少 1 次 IO
使用 B 樹作為索引結構時,由於結點的大小等於一個頁的大小,通常階會比較大,因此樹的深度較淺(通常不超過 3),查詢效率非常高。
缺點
雖然資料庫系統普遍使用 B 樹作為索引結構,但是仍然有以下缺點:
- 非葉子結點直接儲存資料,同一結點儲存的索引數會比較少
- 資料即可能儲存在葉子結點,也可能儲存在非葉子結點,查詢效率相對不穩定
- 在同層結點之間沒有指標相鄰,不適合做一些資料遍歷操作
插入和刪除
插入

B 樹所有的插入過程都以根結點起始,首先是要查詢到新元素所要儲存的結點,然後判斷插入結點的元素數量:
-
如果結點儲存的元素數量小於最大值,那麼有空間容納新的元素,直接插入並保持結點內部有序即可;
-
如果結點儲存的元素數量大於等於最大值,將它平均地分裂成 2 個結點:
- 從該結點的原有元素和新的元素中選擇出中位數(按順序排列的一組資料中居於中間位置的數);
- 小於中位數的元素放入左邊結點,大於中位數的元素放入右邊結點,中位數作為分隔值;
- 將分隔值插入到父結點中,這也可能會造成父結點發生分裂,父結點的分裂也可能會造成它的父結點分裂,以此類推;如果沒有父結點,就建立一個新的父結點。
刪除
刪除 B 樹中的結點有兩種常用的策略:
- 定位並刪除元素,然後調整樹使它滿足約束條件
- 從上到下處理這棵樹,在進入一個結點之前,調整樹使得其之後一旦遇到要刪除的鍵,可以被直接刪除而不需要再進行調整
對於前一種刪除策略,其刪除流程如下:
- 如果刪除葉子結點中的元素,將它直接刪除,如果結點中的元素數量小於最小值,則進行重新平衡操作;
- 如果刪除非葉子結點中的元素,選擇一個新的分隔值(左子樹中最大的元素或右子樹中最小的元素),將它從葉子結點中移除,替換掉被刪除的元素作為新的分隔值,如果該葉子結點中的元素數量小於最小值,則進行重新平衡操作;
- 重新平衡操作從葉子結點開始,向根結點進行,直到樹重新平衡。
在刪除結點中,使 B 樹重新平衡主要會有以下情況:
-
如果缺少元素結點的右兄弟結點存在且擁有多餘的元素,那麼向左旋轉:
- 將父結點的分隔值移動到左子樹中最大元素處;
- 將右兄弟結點的最小元素移動到原父結點的分隔值處;
-
如果缺少元素結點的左兄弟結點存在且擁有多餘的元素,那麼向右旋轉:
- 將父結點的分隔值移動到右子樹中最小元素處;
- 將左兄弟結點的最大元素移動到原父結點的分隔值處;
-
如果缺少元素結點的兩個直接兄弟結點都只有最小數量的元素,那麼將它與左兄弟結點以及它們在父結點中的分隔值合併:
- 將分隔值複製到左邊的結點;
- 將此缺少元素結點中的所有元素移動到左邊結點;
- 將缺少元素的結點移除;
- 如果父結點是根結點且沒有元素,則釋放它並讓合併後的結點成為新的根結點;如果父結點的元素數量小於最小值,重新平衡父結點。
對 B 樹做刪除元素的操作比較複雜,但仍然是以保持 B 樹平衡為主,並且不使其導致特性失效。