用一個效能提升了666倍的小案例說明在TiDB中正確使用索引的重要性
背景
最近在給一個物流系統做TiDB POC測試,這個系統是基於MySQL開發的,本次投入測試的業務資料大概10個庫約900張表,最大單表6千多萬行。
這個規模不算大,測試資料以及庫表結構是用Dumpling從MySQL匯出,再用Lightning匯入到TiDB中,整個過程非常順利。
系統在TiDB上跑起來後,通過Dashboard觀察到有一條SQL非常規律性地出現在慢查詢頁面中,開啟SQL一看只是個單表查詢並不複雜,感覺必有蹊蹺。

問題現象
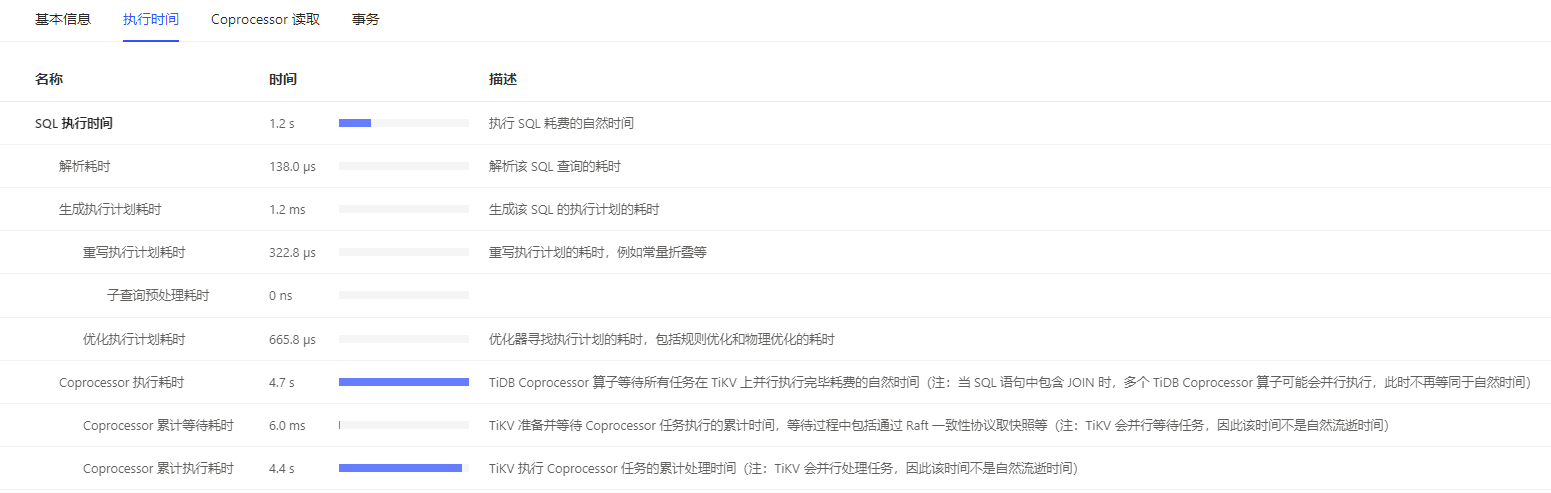
以下是從Dashboard中抓出來的原始SQL和執行計劃,總共消耗了1.2s,其中絕大部分時間都花在了Coprocessor掃描資料中:
SELECT {31個欄位}
FROM
job_cm_data
WHERE
(
group_id = 'GROUP_MATERIAL'
AND cur_thread = 1
AND pre_excutetime < '2022-04-27 11:55:00.018'
AND ynflag = 1
AND flag = 0
)
ORDER BY
id
LIMIT
200;
id task estRows operator info actRows execution info memory disk
Projection_7 root 200 test_ba.job_cm_data.id, test_ba.job_cm_data.common_job_type, test_ba.job_cm_data.org_code, test_ba.job_cm_data.key_one, test_ba.job_cm_data.key_two, test_ba.job_cm_data.key_three, test_ba.job_cm_data.key_four, test_ba.job_cm_data.key_five, test_ba.job_cm_data.key_six, test_ba.job_cm_data.key_seven, test_ba.job_cm_data.key_eight, test_ba.job_cm_data.permission_one, test_ba.job_cm_data.permission_two, test_ba.job_cm_data.permission_three, test_ba.job_cm_data.cur_thread, test_ba.job_cm_data.group_id, test_ba.job_cm_data.max_execute_count, test_ba.job_cm_data.remain_execute_count, test_ba.job_cm_data.total_execute_count, test_ba.job_cm_data.pre_excutetime, test_ba.job_cm_data.related_data, test_ba.job_cm_data.delay_time, test_ba.job_cm_data.error_message, test_ba.job_cm_data.flag, test_ba.job_cm_data.ynflag, test_ba.job_cm_data.create_time, test_ba.job_cm_data.update_time, test_ba.job_cm_data.create_user, test_ba.job_cm_data.update_user, test_ba.job_cm_data.ip, test_ba.job_cm_data.version_num 0 time:1.17s, loops:1, Concurrency:OFF 83.8 KB N/A
└─Limit_14 root 200 offset:0, count:200 0 time:1.17s, loops:1 N/A N/A
└─Selection_31 root 200 eq(test_ba.job_cm_data.ynflag, 1) 0 time:1.17s, loops:1 16.3 KB N/A
└─IndexLookUp_41 root 200 0 time:1.17s, loops:1, index_task: {total_time: 864.6ms, fetch_handle: 26.1ms, build: 53.3ms, wait: 785.2ms}, table_task: {total_time: 4.88s, num: 17, concurrency: 5} 4.06 MB N/A
├─IndexRangeScan_38 cop[tikv] 7577.15 table:job_cm_data, index:idx_group_id(group_id), range:["GROUP_MATERIAL","GROUP_MATERIAL"], keep order:true 258733 time:3.34ms, loops:255, cop_task: {num: 1, max: 2.45ms, proc_keys: 0, rpc_num: 1, rpc_time: 2.43ms, copr_cache_hit_ratio: 1.00}, tikv_task:{time:146ms, loops:257} N/A N/A
└─Selection_40 cop[tikv] 200 eq(test_ba.job_cm_data.cur_thread, 1), eq(test_ba.job_cm_data.flag, 0), lt(test_ba.job_cm_data.pre_excutetime, 2022-04-27 11:55:00.018000) 0 time:4.68s, loops:17, cop_task: {num: 18, max: 411.4ms, min: 15.1ms, avg: 263ms, p95: 411.4ms, max_proc_keys: 20480, p95_proc_keys: 20480, tot_proc: 4.41s, tot_wait: 6ms, rpc_num: 18, rpc_time: 4.73s, copr_cache_hit_ratio: 0.00}, tikv_task:{proc max:382ms, min:12ms, p80:376ms, p95:382ms, iters:341, tasks:18}, scan_detail: {total_process_keys: 258733, total_process_keys_size: 100627600, total_keys: 517466, rocksdb: {delete_skipped_count: 0, key_skipped_count: 258733, block: {cache_hit_count: 1296941, read_count: 0, read_byte: 0 Bytes}}} N/A N/A
└─TableRowIDScan_39 cop[tikv] 7577.15 table:job_cm_data, keep order:false 258733 tikv_task:{proc max:381ms, min:12ms, p80:375ms, p95:381ms, iters:341, tasks:18} N/A N/A
這個執行計劃比較簡單,稍微分析一下可以看出它的執行流程:
- 先用
IndexRangeScan運算元掃描idx_group_id這個索引,得到了258733行符合條件的rowid - 接著拿rowid去做
TableRowIDScan掃描每一行資料並進行過濾,得到了0行資料 - 以上兩步組成了一個
IndexLookUp回表操作,返回結果交給TiDB節點做Limit,得到0行資料 - 最後做一個欄位投影
Projection得到最終結果
從execution info中看到主要的時間都花在Selection_40這一步,初步判斷為大量回表導致效能問題。
小技巧:看到IndexRangeScan中Loops特別大的要引起重視了。
深入分析
根據經驗推斷,回表多說明索引效果不好,先看一下這個表的總行數是多少:
mysql> select count(1) from job_cm_data;
+----------+
| count(1) |
+----------+
| 311994 |
+----------+
1 row in set (0.05 sec)
從回表數量來看,這個索引欄位的區分度肯定不太行,進一步驗證這個推斷:
mysql> select group_id,count(1) from job_cm_data group by group_id;
+------------------------------+----------+
| group_id | count(1) |
+------------------------------+----------+
| GROUP_HOUSELINK | 20 |
| GROUP_LMSMATER | 37667 |
| GROUP_MATERIAL | 258733 |
| GROUP_MATERISYNC | 15555 |
| GROUP_WAREHOUSE_CONTRACT | 7 |
| GROUP_WAREHOUSE_CONTRACT_ADD | 12 |
+------------------------------+----------+
6 rows in set (0.01 sec)
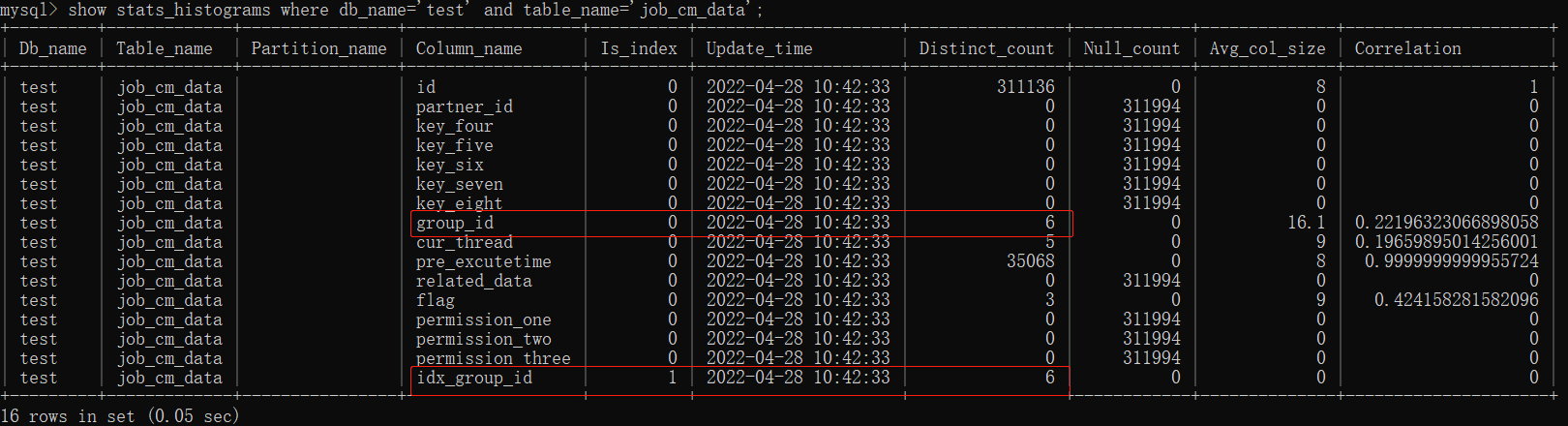
從上面兩個結果可以判斷出idx_group_id這個索引有以下問題:
- 區分度非常差,只有6個不同值
- 資料分佈非常不均勻,GROUP_MATERIAL這個值佔比超過了80%
所以這是一個非常失敗的索引。
對於本文中的SQL而言,首先要從索引中掃描出258733個rowid,再拿這258733個rowid去查原始資料,不僅不能提高查詢效率,反而讓查詢變的更慢了。
不信的話,我們把這個索引刪掉再執行一遍SQL。
mysql> alter table job_cm_data drop index idx_group_id;
Query OK, 0 rows affected (0.52 sec)

從這個執行計劃看到現在已經變成了全表掃描,但是執行時間卻比之前縮短了一倍多,而且當命中Coprocessor Cache的時候那速度就更快了:
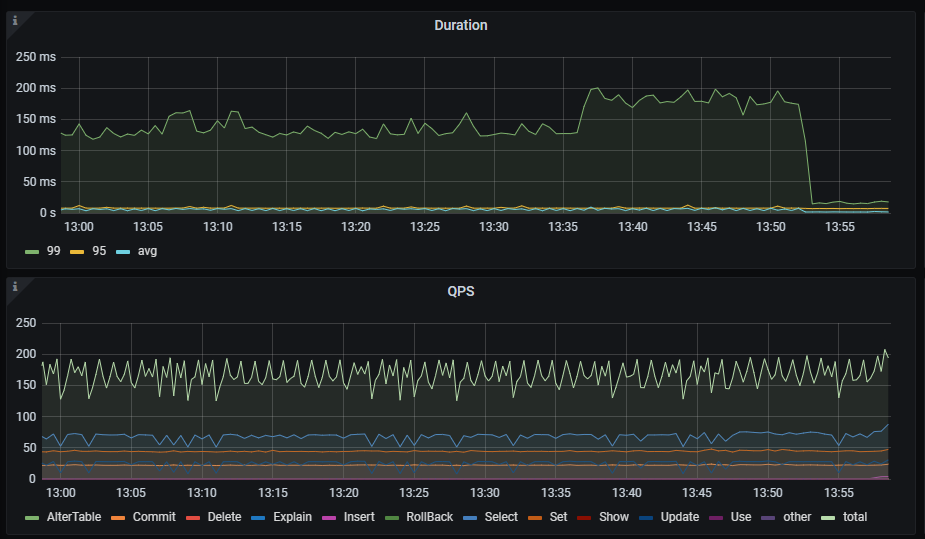
 正當我覺得刪掉索引就萬事大吉的時候,監控裡的Duration 99線突然升高到了200多ms,滿臉問號趕緊查一下慢紀錄檔是什麼情況。
正當我覺得刪掉索引就萬事大吉的時候,監控裡的Duration 99線突然升高到了200多ms,滿臉問號趕緊查一下慢紀錄檔是什麼情況。
發現這條SQL執行時間雖然變短了,但是慢SQL突然就變多了:
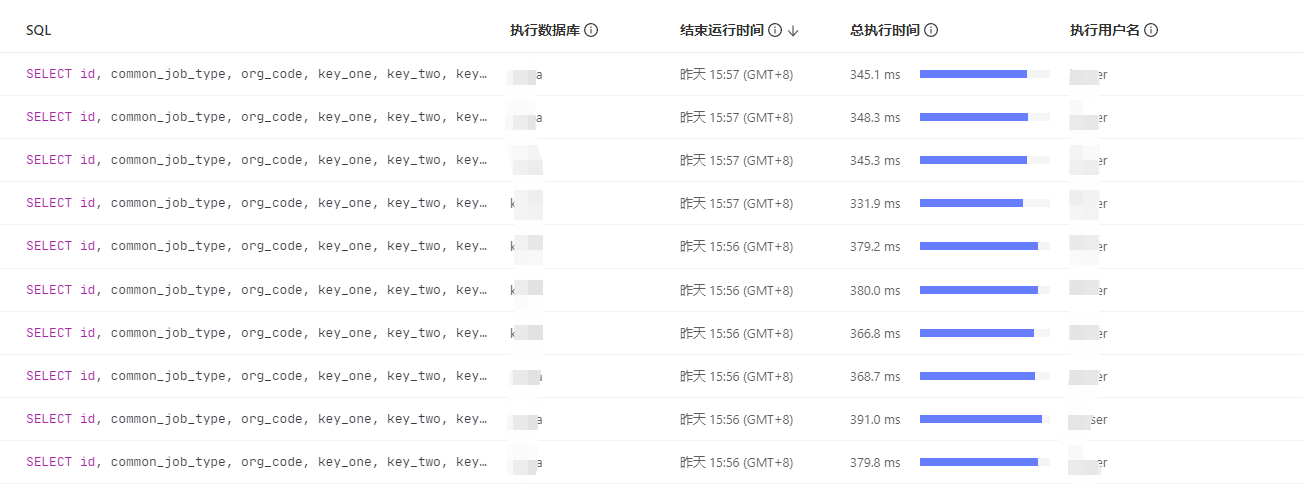 仔細對比SQL後發現,這些SQL是分別查詢了
仔細對比SQL後發現,這些SQL是分別查詢了group_id的6個值,而且頻率還很高。也就是說除了前面貼出來的那條SQL變快,其他group_id的查詢都變慢了。
其實這個也在預期內,group_id比較少的資料就算走了索引它的回表次數也很少,這個時間仍然比全表掃描要快的多。
因此要解決這個問題僅僅刪掉索引是不行的,不僅慢查詢變多duration變高,全表掃描帶來的後果導致TiKV節點的讀請求壓力特別大。
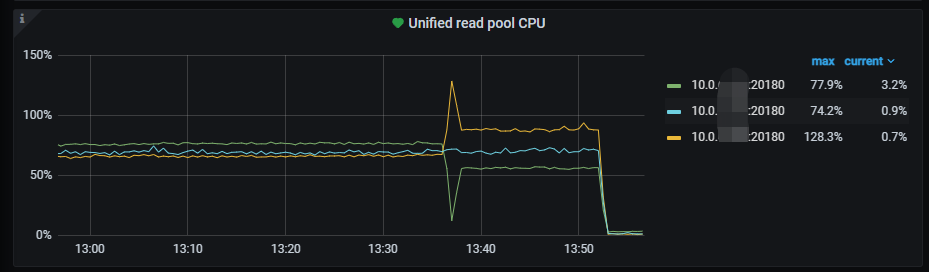
初始情況下這個表只有2個region,而且leader都在同一個store上,導致該節點CPU使用量暴增,讀熱點問題非常明顯。
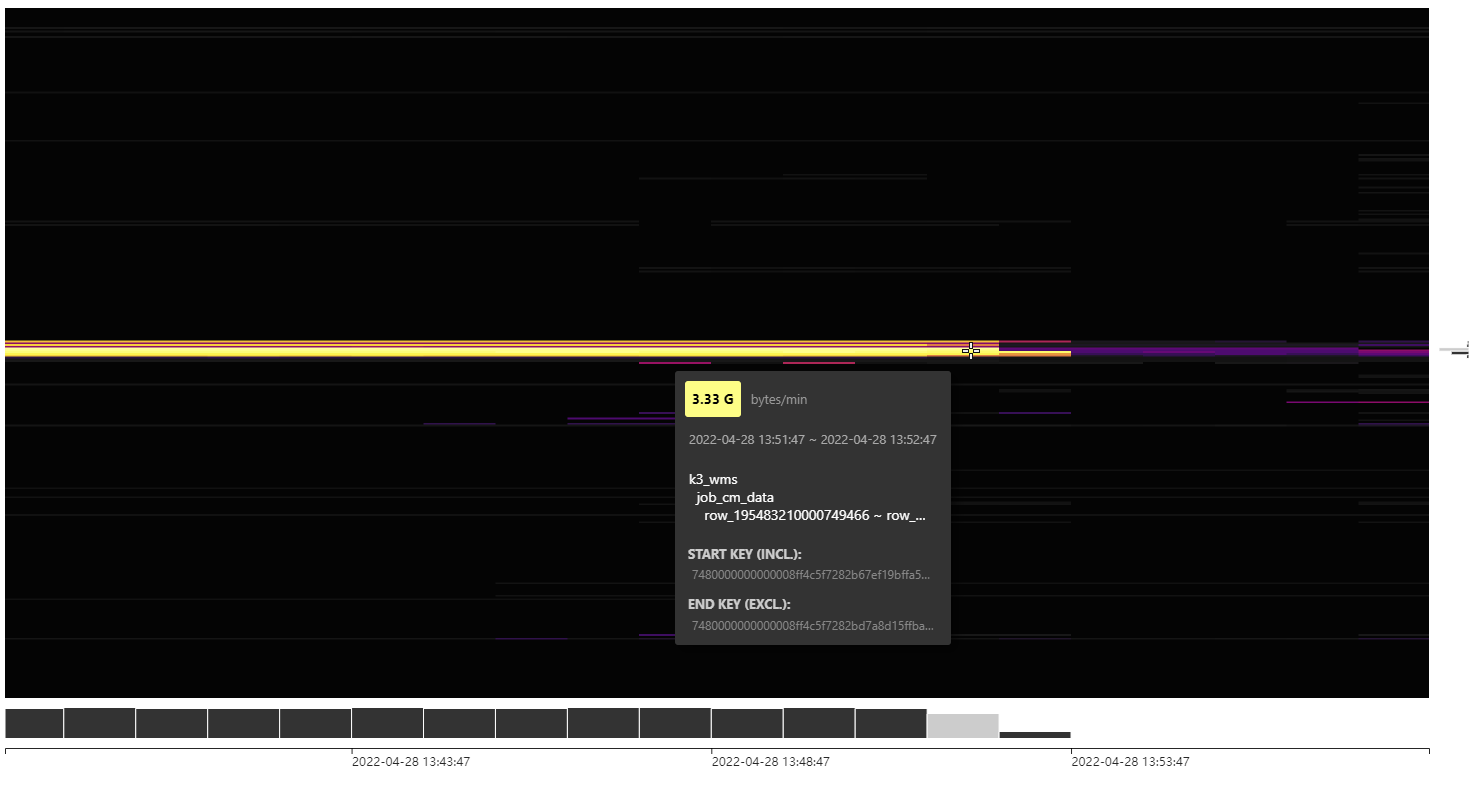
經過手動切分region後把請求分攤到3個TiKV節點中,但Unified Readpool CPU還是都達到了80%左右,熱力圖最高每分鐘流量6G。
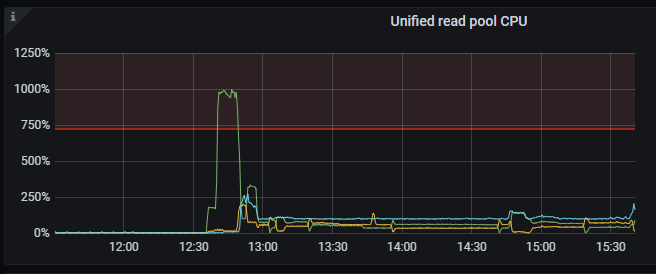
繼續盤它。
解決思路
既然全表掃描行不通,那解決思路還是想辦法讓它用上索引。
經過和業務方溝通,得知這是一個儲存定時任務後設資料的表,雖然查詢很頻繁但是每次返回的結果集很少,真實業務中沒有那多需要處理的任務。
基於這個背景,我聯想到可以通過查索引得出最終符合條件的rowid,再拿這個小結果集去回表就可以大幅提升效能了。
那麼很顯然,我們需要一個複合索引,也稱為聯合索引、組合索引,即把多個欄位放在一個索引中。對於本文中的案例,可以考慮把where查詢欄位組成一個複合索引。
但怎麼去組合欄位其實是大有講究的,很多人可能會一股腦把5個條件建立索引:
ALTER TABLE `test`.`job_cm_data`
ADD INDEX `idx_muti`(`group_id`, `cur_thread`,`pre_excutetime`,`ynflag`,`flag`);

確實,從這個執行計劃可以看到效能有了大幅提升,比全表掃描快了10倍。那是不是可以收工了?還不行。
這個索引存在兩個問題:
- 5個索引欄位有點太多了,維護成本大
- 5萬多個索引掃描結果也有點太多(因為只用到了3個欄位)
基於前面貼出來的表統計資訊和索引建立原則,索引欄位的區分度一定要高,這5個查詢欄位裡面pre_excutetime有35068個不同的值比較適合建索引,group_id從開始就已經排除了,cur_thread有6個不同值每個值數量都很均勻也不適合,ynflag列所有資料都是1可以直接放棄,最後剩下flag需要特別看一下。
mysql> select flag,count(1) from job_cm_data group by flag;
+------+----------+
| flag | count(1) |
+------+----------+
| 2 | 277832 |
| 4 | 30 |
| 1 | 34132 |
+------+----------+
3 rows in set (0.06 sec)
從上面這個輸出結果來看,它也算不上一個好的索引欄位,但巧就巧在實際業務都是查詢flag=0的資料,也就是說如果給它建了索引,在索引裡就能排除掉99%以上的資料。
有點意思,那就建個索引試試。
ALTER TABLE `test`.`job_cm_data`
ADD INDEX `idx_muti`(`pre_excutetime`,`flag`);
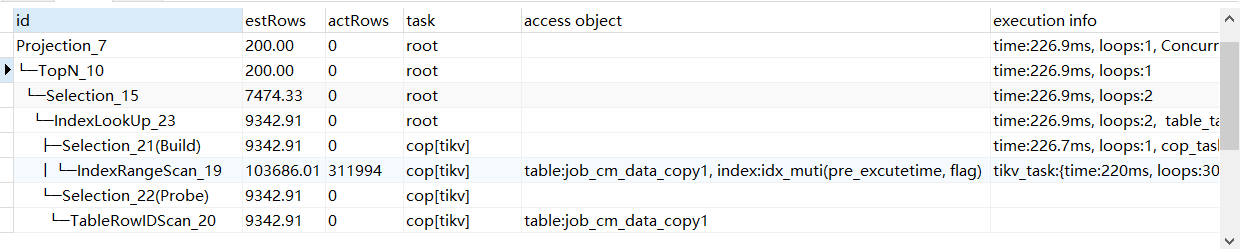
這個結果好像和預期的不太對呀,怎麼搞成掃描31萬行索引了?
別忘了,複合索引有個最左匹配原則,而這個pre_excutetime剛好是範圍查詢,所以實際只用到了pre_excutetime這個索引,而偏偏整個表的資料都符合篩選的時間段,其實就相當於IndexFullScan了。
那行,再把欄位順序換個位置:
ALTER TABLE `test`.`job_cm_data`
ADD INDEX `idx_muti`(`flag``pre_excutetime`);
 看到執行時間這下滿足了,在沒有使用Coprocessor Cache的情況下執行時間也只需要1.8ms。一個小小的索引調整,效能提升666倍。
看到執行時間這下滿足了,在沒有使用Coprocessor Cache的情況下執行時間也只需要1.8ms。一個小小的索引調整,效能提升666倍。

建複合索引其實還有個原則,就是區分度高的欄位要放在前面。因為複合索引是從左往右去對比,區分割區高的欄位放前面就能大幅減少後面欄位對比的範圍,從而讓索引的效率最大化。
這就相當於層層過濾器,大家都希望每一層都儘可能多的過濾掉無效資料,而不希望10萬行進來的時候到最後一層還是10萬行,那前面的過濾就都沒意義了。在這個例子中,flag就是一個最強的過濾器,放在前面再合適不過。
不過這也要看實際場景,當查詢flag的值不為0時,會引起一定量的回表,我們以4(30行)和1(34132行)做下對比:


真實業務中,flag=0的資料不會超過50行,參考上面的結果,50次回表也就10ms以內,效能依然不錯,完全符合要求。
我覺得應用層面允許調整SQL的話,再限制下pre_excutetime的最小時間,就可以算是個最好的解決方案了。
最後上一組圖看看優化前後的對比。
nice~
總結
這個例子就是提示大家,索引是個好東西但並不是銀彈,加的不好就難免適得其反。
本文涉及到的索引知識點:
- 索引欄位的區分割區要足夠高,最佳範例就是唯一索引
- 使用索引查詢的效率不一定比全表掃描快
- 充分利用索引特點減少回表次數
- 複合索引的最左匹配原則
- 複合索引區分度高的欄位放在前面
碰到問題要能夠具體情況具體分析,索引的使用原則估計很多人都背過,怎麼能融會貫通去使用還是需要多思考。
索引不規範,DBA兩行淚,珍惜身邊每一個幫你調SQL的DBA吧。
文章作者:hoho 首發論壇:部落格園 文章出處:http://www.cnblogs.com/hohoa/ 歡迎大家一起討論分享,喜歡請點右下角的推薦鼓勵一下,我會有更多的動力來寫出好文章!歡迎持續關注我的部落格! 歡迎轉載,轉載的時候請註明作者和原文連結。