IO高?業務慢?在DWS實際業務場景中因IO高、IO瓶頸導致的效能問題非常多,其中應用業務設計不合理導致的問題佔大多數。本文從應用業務優化角度,以常見觸發IO慢的業務SQL場景為例,指導如何通過優化業務去提升IO效率和降低IO。
說明 :因磁碟故障(如慢盤)、raid卡讀寫策略(如Write Through)、叢集主備不均等非應用業務原因導致的IO高不在本次討論。
一、確定IO瓶頸&識別高IO的語句
1、查等待檢視確定IO瓶頸
SELECT wait_status,wait_event,count(*) AS cnt FROM pgxc_thread_wait_status WHERE wait_status <> 'wait cmd' AND wait_status <> 'synchronize quit' AND wait_status <> 'none' GROUP BY 1,2 ORDER BY 3 DESC limit 50;
IO瓶頸時常見等待狀態如下:

2、抓取高IO消耗的SQL
主要思路為先通過OS命令識別消耗高的執行緒,然後結合DWS的執行緒號資訊找到消耗高的業務SQL,具體方法參見附件中iowatcher.py指令碼和README使用介紹
3、SQL級IO問題分析基礎
在抓取到消耗IO高的業務SQL後怎麼分析?主要掌握以下兩點基礎知識:
1)PGXC_THREAD_WAIT_STATUS檢視功能,詳細介紹參見:
https://support.huaweicloud.com/devg2-dws/dws_0402_0892.html
2)EXPLAIN功能,至少需掌握的知識點有Scan運算元、A-time、A-rows、E- rows,詳細介紹參見:
https://bbs.huaweicloud.com/blogs/197945
二、常見觸發IO瓶頸的高頻業務場景
場景1:列存小CU膨脹
某業務SQL查詢出390871條資料需43248ms,分析計劃主要耗時在Cstore Scan

Cstore Scan的詳細資訊中,每個DN掃描出2w左右的資料,但是掃描了有資料的CU(CUSome) 155079個,沒有資料的CU(CUNone) 156375個,說明當前小CU、未命中資料的CU極多,也即CU膨脹嚴重。

觸發因素:對列存表(分割區表尤甚)進行高頻小批次匯入會造成CU膨脹
處理方法:
1、列存表的資料入庫方式修改為攢批入庫,單分割區單批次入庫資料量大於DN個數*6W為宜
2、如果確因業務原因無法攢批,則考慮次選方案,定期VACUUM FULL此類高頻小批次匯入的列存表。
3、當小CU膨脹很快時,頻繁VACUUM FULL也會消耗大量IO,甚至加劇整個系統的IO瓶頸,這時需考慮整改為行存表(CU長期膨脹嚴重的情況下,列存的儲存空間優勢和順序掃描效能優勢將不復存在)。
場景2:髒資料&資料清理
某SQL總執行時間2.519s,其中Scan佔了2.516s,同時該表的掃描最終只掃描到0條符合條件資料,過濾了20480條資料,也即總共掃描了20480+0條資料卻消耗了2s+,這種掃描時間與掃描資料量嚴重不符的情況,基本就是髒資料多影響掃描和IO效率。

檢視表髒頁率為99%,Vacuum Full後效能優化到100ms左右

觸發因素:表頻繁執行update/delete導致髒資料過多,且長時間未VACUUM FULL清理
處理方法:
- 對頻繁update/delete產生髒資料的表,定期VACUUM FULL,因大表的VACUUM FULL也會消耗大量IO,因此需要在業務低峰時執行,避免加劇業務高峰期IO壓力。
- 當髒資料產生很快,頻繁VACUUM FULL也會消耗大量IO,甚至加劇整個系統的IO瓶頸,這時需要考慮髒資料的產生是否合理。針對頻繁delete的場景,可以考慮如下方案:1)全量delete修改為truncate或者使用臨時表替代 2)定期delete某時間段資料,設計成分割區表並使用truncate&drop分割區替代
場景3:表儲存傾斜
例如表Scan的A-time中,max time dn執行耗時6554ms,min time dn耗時0s,dn之間掃描差異超過10倍以上,這種集合Scan的詳細資訊,基本可以確定為表儲存傾斜導致

通過table_distribution發現所有資料傾斜到了dn_6009單個dn,修改分佈列使的表儲存分佈均勻後,max dn time和min dn time基本維持在相同水平400ms左右,Scan時間從6554ms優化到431ms。

觸發因素:分散式場景,表分佈列選擇不合理會導致儲存傾斜,同時導致DN間壓力失衡,單DN IO壓力大,整體IO效率下降。
解決辦法:修改表的分佈列使表的儲存分佈均勻,分佈列選擇原則參《GaussDB 8.x.x 產品檔案》中「表設計最佳實踐」之「選擇分佈列章節」。
場景4:無索引、有索引不走
例如某點查詢,Seq Scan掃描需要3767ms,因涉及從4096000條資料中獲取8240條資料,符合索引掃描的場景(海量資料中尋找少量資料),在對過濾條件列增加索引後,計劃依然是Seq Scan而沒有走Index Scan。
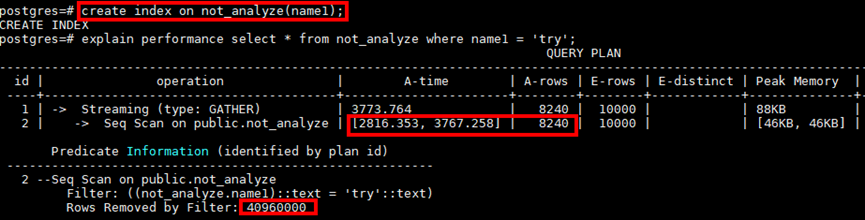
對目標表analyze後,計劃能夠自動選擇索引,效能從3s+優化到2ms+,極大降低IO消耗

常見場景:行存大表的查詢場景,從大量資料中存取極少資料,沒走索引掃描而是走順序掃描,導致IO效率低,不走索引常見有兩種情況:
- 過濾條件列上沒建索引
- 有索引但是計劃沒選索引掃描
觸發因素:
- 常用過濾條件列沒有建索引
- 表中資料因DML產生資料特徵變化後未及時ANALYZE導致優化器無法選擇索引掃描計劃,ANALYZE介紹參見https://bbs.huaweicloud.com/blogs/192029
處理方式:
1、對行存表常用過濾列增加索引,索引基本設計原則:
- 索引列選擇distinct值多,且常用於過濾條件,過濾條件多時可以考慮建組合索引,組合索引中distinct值多的列排在前面,索引個數不宜超過3個
- 大量資料帶索引匯入會產生大量IO,如果該表涉及大量資料匯入,需嚴格控制索引個數,建議匯入前先將索引刪除,導數完畢後再重新建索引;
2、對頻繁做DML操作的表,業務中加入及時ANALYZE,主要場景:
- 表資料從無到有
- 表頻繁進行INSERT/UPDATE/DELETE
- 表資料隨插即用,需要立即存取且只存取剛插入的資料
場景5:無分割區、有分割區不剪枝
例如某業務表進場使用createtime時間列作為過濾條件獲取特定時間資料,對該表設計為分割區表後沒有走分割區剪枝(Selected Partitions數量多),Scan花了701785ms,IO效率極低。
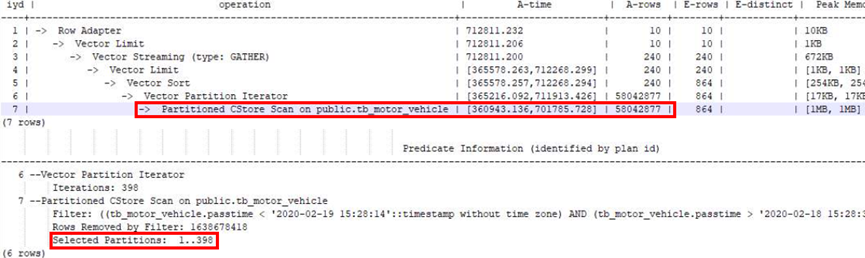
在增加分割區鍵creattime作為過濾條件後,Partitioned scan走分割區剪枝(Selected Partitions數量極少),效能從700s優化到10s,IO效率極大提升。

常見場景:按照時間儲存資料的大表,查詢特徵大多為存取當天或者某幾天的資料,這種情況應該通過分割區鍵進行分割區剪枝(只掃描對應少量分割區)來極大提升IO效率,不走分割區剪枝常見的情況有:
- 未設計成分割區表
- 設計了分割區沒使用分割區鍵做過濾條件
- 分割區鍵做過濾條件時,對列值有函數轉換
觸發因素:未合理使用分割區表和分割區剪枝功能,導致掃描效率低
處理方式:
- 對按照時間特徵儲存和存取的大表設計成分割區表
- 分割區鍵一般選離散度高、常用於查詢filter條件中的時間型別的欄位
- 分割區間隔一般參考高頻的查詢所使用的間隔,需要注意的是針對列存表,分割區間隔過小(例如按小時)可能會導致小檔案過多的問題,一般建議最小間隔為按天。
場景6:行存表求count值
例如某行存大表頻繁全表count(指不帶filter條件或者filter條件過濾很少資料的count),其中Scan花費43s,持續佔用大量IO,此類作業並行起來後,整體系統IO持續100%,觸發IO瓶頸,導致整體效能慢。

對比相同資料量的列存表(A-rows均為40960000),列存的Scan只花費14ms,IO佔用極低

觸發因素:行存表因其儲存方式的原因,全表scan的效率較低,頻繁的大表全表掃描,導致IO持續佔用。
解決辦法:
- 業務側審視訊繁全表count的必要性,降低全表count的頻率和並行度
- 如果業務型別符合列存表,則將行存表修改為列存表,提高IO效率
場景7:行存表求max值
例如求某行存表某列的max值,花費了26772ms,此類作業並行起來後,整體系統IO持續100%,觸發IO瓶頸,導致整體效能慢。

針對max列增加索引後,語句耗時從26s優化到32ms,極大減少IO消耗

觸發因素:行存表max值逐個scan符合條件的值來計算max,當scan的資料量很大時,會持續消耗IO
解決辦法:給max列增加索引,依靠btree索引天然有序的特徵,加速掃描過程,降低IO消耗。
場景8:大量資料帶索引匯入
某客戶場景資料往DWS同步時,延遲嚴重,叢集整體IO壓力大。
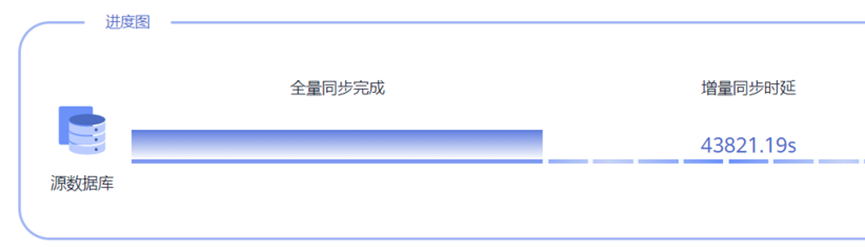
後臺檢視等待檢視有大量wait wal sync和WALWriteLock狀態,均為xlog同步狀態

觸發因素:大量資料帶索引(一般超過3個)匯入(insert/copy/merge into)會產生大量xlog,導致主備同步慢,備機長期Catchup,整體IO利用率飆高。歷史案例參考:https://bbs.huaweicloud.com/blogs/242269
解決方案:
- 嚴格控制每張表的索引個數,建議3個以內
- 大量資料匯入前先將索引刪除,導數完畢後再重新建索引;
場景9:行存大表首次查詢
某客戶場景出現備DN持續Catcup,IO壓力大,觀察某個sql等待檢視在wait wal sync

排查業務發現某查詢語句執行時間較長,kill後恢復
觸發因素:行存表大量資料入庫後,首次查詢觸發page hint產生大量XLOG,觸發主備同步慢及大量IO消耗。
解決措施:
- 對該類一次性存取大量新資料的場景,修改為列存表
- 關閉wal_log_hints和enable_crc_check引數(故障期間有丟數風險,不推薦)
場景10:小檔案多IOPS高
某業務現場一批業務起來後,整個叢集IOPS飆高,另外當出現叢集故障後,長期building不完,IOPS飆高,相關表資訊如下:
SELECT relname,reloptions,partcount FROM pg_class c INNER JOIN ( SELECT parented,count(*) AS partcount FROM pg_partition GROUP BY parentid ) s ON c.oid = s.parentid ORDER BY partcount DESC;
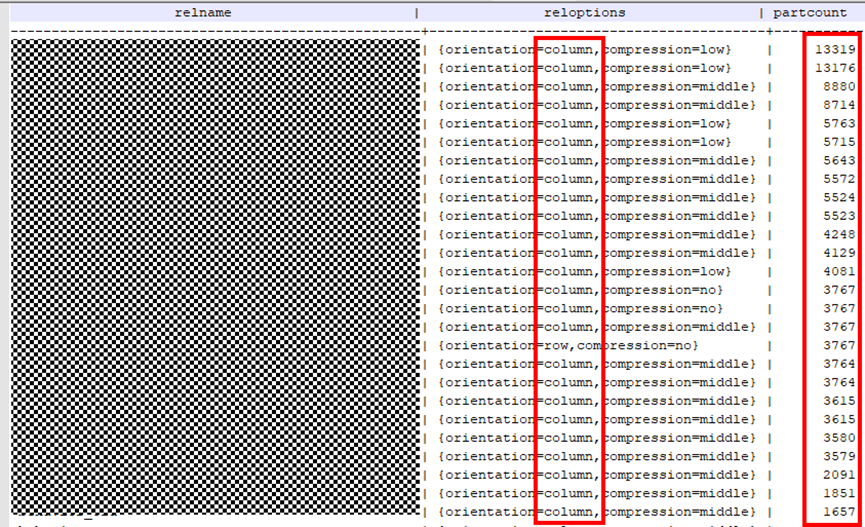
觸發因素:某業務庫大量列存多分割區(3000+)的表,導致小檔案巨多(單DN檔案2000w+),存取效率低,故障恢復Building極慢,同時building也消耗大量IOPS,發向影響業務效能。
解決辦法:
- 整改列存分割區間隔,減少分割區個數來降低檔案個數
- 列存表修改為行存表,行存的儲存特徵決定其檔案個數不會像列存那麼膨脹嚴重
三、小結
經過前面案例,稍微總結下不難發現,提升IO使用效率概括起來可分為兩個維度,即提升IO的儲存效率和計算效率(又稱存取效率),提升儲存效率包括整合小CU、減少髒資料、消除儲存傾斜等,提升計算效率包括分割區剪枝、索引掃描等,大家根據實際場景靈活處理即可。
