MySQL並行複製(MTS)原理(完整版)
-
在MySQL 5.7版本,官方稱為enhanced multi-threaded slave(簡稱MTS),複製延遲問題已經得到了極大的改進,可以說在MySQL 5.7版本後,複製延遲問題永不存在。
-
5.7的MTS本身就是:master基於組提交(group commit)來實現的並行事務分組,再由slave通過SQL thread將一個組提交內的事務分發到各worker執行緒,實現並行應用。
MySQL 5.6並行複製架構
MySQL 5.7並行複製原理
MySQL 5.6基於庫的並行複製出來後,基本無人問津,在沉寂了一段時間之後,MySQL 5.7出來了,它的並行複製以一種全新的姿態出現在了DBA面前。
MySQL 5.7才可稱為真正的並行複製,這其中最為主要的原因就是slave伺服器的回放與master是一致的,即master伺服器上是怎麼並行執行的,那麼slave上就怎樣進行並行回放。不再有庫的並行複製限制,對於二進位制紀錄檔格式也無特殊的要求(基於庫的並行複製也沒有要求)。
從MySQL官方來看,其並行複製的原本計劃是支援表級的並行複製和行級的並行複製,行級的並行複製通過解析ROW格式的二進位制紀錄檔的方式來完成,WL#4648。但是最終出現給小夥伴的確是在開發計劃中稱為:MTS(Prepared transactions slave parallel applier),可見:WL#6314。該並行複製的思想最早是由MariaDB的Kristain提出,並已在MariaDB 10中出現,相信很多選擇MariaDB的小夥伴最為看重的功能之一就是並行複製。MTS實現了事務的並行,從某種程度來說也實現了行的並行(事務對行處理)。
下面來看看MySQL 5.7中的並行複製究竟是如何實現的?
order commit (group commit) -> logical clock ->> MTS
Master
組提交(group commit)
組提交(group commit):通過對事務進行分組,優化減少了生成二進位制紀錄檔所需的運算元。當事務同時提交時,它們將在單個操作中寫入到二進位制紀錄檔中。如果事務能同時提交成功,那麼它們就不會共用任何鎖,這意味著它們沒有衝突,因此可以在Slave上並行執行。所以通過在主機上的二進位制紀錄檔中新增組提交資訊,這些Slave可以並行地安全地執行事務。
首先,MySQL 5.7的並行複製基於一個前提,即所有已經處於prepare階段的事務,都是可以並行提交的。這些當然也可以在從庫中並行提交,因為處理這個階段的事務,都是沒有衝突的,該獲取的資源都已經獲取了。反過來說,如果有衝突,則後來的會等已經獲取資源的事務完成之後才能繼續,故而不會進入prepare階段。這是一種新的並行複製思路,完全擺脫了原來一直致力於為了防止衝突而做的分發演演算法,等待策略等複雜的而又效率底下的工作。
MySQL 5.7並行複製的思想一言以蔽之:一個組提交(group commit)的事務都是可以並行回放,因為這些事務都已進入到事務的prepare階段,則說明事務之間沒有任何衝突(否則就不可能提交)。
根據以上描述,這裡的重點是——
- 如何來定義哪些事務是處於prepare階段的?
- 在生成的Binlog內容中該如何告訴Slave哪些事務是可以並行複製的?
——為了相容MySQL 5.6基於庫的並行複製,5.7引入了新的變數slave-parallel-type,其可以設定的值有:
- DATABASE(預設值,基於庫的並行複製方式)
- LOGICAL_CLOCK(基於組提交的並行複製方式)
支援並行複製的GTID
那麼如何知道事務是否在同一組中?原版的MySQL並沒有提供這樣的資訊。
在MySQL 5.7版本中,其設計方式是將組提交的資訊存放在GTID中。
那麼如果引數gtid_mode設定為OFF,使用者沒有開啟GTID功能呢?
MySQL 5.7又引入了稱之為Anonymous_Gtid(ANONYMOUS_GTID_LOG_EVENT)的二進位制紀錄檔event型別,
如:
mysql> SHOW BINLOG EVENTS in 'mysql-bin.000006';
+------------------+-----+----------------+-----------+-------------+-----------------------------------------------+
| Log_name | Pos | Event_type | Server_id | End_log_pos | Info |
+------------------+-----+----------------+-----------+-------------+-----------------------------------------------+
| mysql-bin.000006 | 4 | Format_desc | 88 | 123 | Server ver: 5.7.7-rc-debug-log, Binlog ver: 4|
| mysql-bin.000006 | 123 | Previous_gtids | 88 | 194 | |
| mysql-bin.000006 | 194 | Anonymous_Gtid | 88 | 259 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' |
| mysql-bin.000006 | 259 | Query | 88 | 330 | BEGIN |
| mysql-bin.000006 | 330 | Table_map | 88 | 373 | table_id: 108 (aaa.t) |
| mysql-bin.000006 | 373 | Write_rows | 88 | 413 | table_id: 108 flags: STMT_END_F |
......
這意味著在MySQL 5.7版本中即使不開啟GTID,每個事務開始前也是會存在一個Anonymous_Gtid,而這個Anonymous_Gtid事件中就存在著組提交的資訊。反之,如果開啟了GTID後,就不會存在這個Anonymous_Gtid了,從而組提交資訊就記錄在非匿名GTID事件中。
-
PREVIOUS_GTIDS_LOG_EVENT
用於表示上一個binlog最後一個gitd的位置,每個binlog只有一個,當沒有開啟GTID時此事件為空。
-
GTID_LOG_EVENT
-
當開啟GTID時,每一個操作語句(DML/DDL)執行前就會新增一個GTID事件,記錄當前全域性事務ID。
-
同時在MySQL 5.7版本中,組提交資訊也存放在GTID事件中,有兩個關鍵欄位last_committed,sequence_number就是用來標識組提交資訊的。
-
在InnoDB中有一個全域性計數器(global counter),在每一次儲存引擎提交之前,計數器值就會增加。在事務進入prepare階段之前,全域性計數器的當前值會被儲存在事務中,這個值稱為此事務的commit-parent(也就是last_committed)。
-
slave
LOGICAL_CLOCK(由order commit實現),實現的group commit目的
然而,通過上述的SHOW BINLOG EVENTS,我們並沒有發現有關組提交的任何資訊。但是通過mysqlbinlog工具,就能發現組提交的內部資訊——
$ mysqlbinlog mysql-bin.0000006 | grep last_committed
#150520 14:23:11 server id 88 end_log_pos 259 CRC32 0x4ead9ad6 GTID last_committed=0 sequence_number=1
#150520 14:23:11 server id 88 end_log_pos 1483 CRC32 0xdf94bc85 GTID last_committed=0 sequence_number=2
#150520 14:23:11 server id 88 end_log_pos 2708 CRC32 0x0914697b GTID last_committed=0 sequence_number=3
#150520 14:23:11 server id 88 end_log_pos 3934 CRC32 0xd9cb4a43 GTID last_committed=0 sequence_number=4
#150520 14:23:11 server id 88 end_log_pos 5159 CRC32 0x06a6f531 GTID last_committed=0 sequence_number=5
#150520 14:23:11 server id 88 end_log_pos 6386 CRC32 0xd6cae930 GTID last_committed=0 sequence_number=6
#150520 14:23:11 server id 88 end_log_pos 7610 CRC32 0xa1ea531c GTID last_committed=6 sequence_number=7
#150520 14:23:11 server id 88 end_log_pos 8834 CRC32 0x96864e6b GTID last_committed=6 sequence_number=8
#150520 14:23:11 server id 88 end_log_pos 10057 CRC32 0x2de1ae55 GTID last_committed=6 sequence_number=9
#150520 14:23:11 server id 88 end_log_pos 11280 CRC32 0x5eb13091 GTID last_committed=6 sequence_number=10
#150520 14:23:11 server id 88 end_log_pos 12504 CRC32 0x16721011 GTID last_committed=6 sequence_number=11
#150520 14:23:11 server id 88 end_log_pos 13727 CRC32 0xe2210ab6 GTID last_committed=6 sequence_number=12
#150520 14:23:11 server id 88 end_log_pos 14952 CRC32 0xf41181d3 GTID last_committed=12 sequence_number=13
...
上述的last_committed和sequence_number代表的就是所謂的LOGICAL_CLOCK。
可以發現MySQL 5.7二進位制紀錄檔較之原來的二進位制紀錄檔內容多了last_committed和sequence_number。
- last_committed表示事務提交時上次事務提交的編號,事務在進入prepare階段時會將上次事務的sequence_number記錄為自己的last_committed,如果事務具有相同的last_committed,表示這些事務都在一組內,可以進行並行的回放。
- 例如上述last_committed為0的事務有6個,表示組提交時提交了6個事務,而這6個事務在slave是可以進行並行回放的。
- 而sequence_number是順序增長的,每個事務對應一個序列號,當事務完成committed時便會得到這個sequence_number。
另外,還有一個細節,下一個事務組的last_committed和上一個事務的sequence_number是相等的。這也很容易理解,因為事物是順序提交的,這麼理解起來並不奇怪。本組的 sequence_number最小值肯定大於last_committed。(這一塊描述不嚴謹,在5.7後續版本中,官方優化了slave進行並行apply的規則,但是這裡為了便於理解,不做修改,理解這個思路後閱讀後面基於鎖的並行規則也很容易。)
這兩個值的有效作用域都在檔案內,只要換一個binlog檔案(flush binary logs),這兩個值就都會從0開始計數。
MySQL是如何做到將這些事務分組的?
還有一個重要的技術問題:MySQL是如何做到將這些事務分組的?
要搞清楚這個問題,首先需要了解一下MySQL事務提交方式。
1. 事務兩階段提交
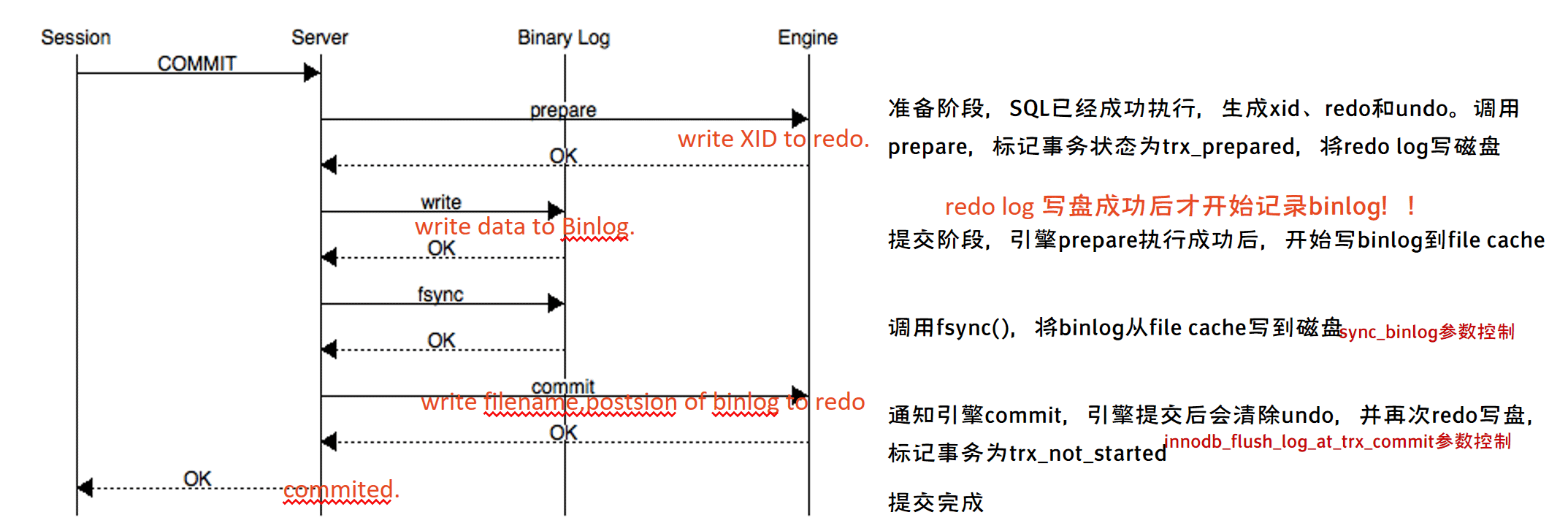
事務的提交主要分為兩個主要步驟:
-
準備階段(Storage Engine(InnoDB)Transaction Prepare Phase)
此時SQL已經成功執行,並生成xid資訊及redo和undo的記憶體紀錄檔。然後呼叫prepare方法完成第一階段,papare方法實際上什麼也沒做,將事務狀態設為TRX_PREPARED,並將redo log刷磁碟。
-
提交階段(Storage Engine(InnoDB)Commit Phase)
-
記錄Binlog紀錄檔。
如果事務涉及的所有儲存引擎的prepare都執行成功,則呼叫TC_LOG_BINLOG::log_xid方法將SQL語句寫到binlog。
(write()將binary log記憶體紀錄檔資料寫入檔案系統快取,fsync()將binary log檔案系統快取紀錄檔資料永久寫入磁碟)。
此時,事務已經鐵定要提交了。否則,呼叫ha_rollback_trans方法回滾事務,而SQL語句實際上也不會寫到binlog。
-
告訴引擎做commit。
最後,呼叫引擎的commit完成事務的提交。會清除undo資訊,刷redo紀錄檔,將事務設為TRX_NOT_STARTED狀態。
-
(不好理解這段就看上面的圖解好了。)
2. Order Commit:是LOGICAL_CLOCK並行複製的基礎
關於MySQL是如何提交的,內部使用ordered_commit函數來處理的。先看它的邏輯圖,如下:

從圖中可以看到,只要事務提交(呼叫ordered_commit),就都會先加入佇列中。
提交有三個步驟,包括FLUSH、SYNC及COMMIT,相應地也有三個佇列。
-
首先要加入的是FLUSH佇列:
- 如果某個事務加入時,佇列還是空的,則這個事務就擔任隊長,來代表其他事務執行提交操作。
- 而在其他事務繼續加入時,就會發現此時佇列已經不為空了,那麼這些事務就會在佇列中等待隊長幫它們完成提交操作。在上圖中,事務2-6都是這種坐享其成之輩,事務1就是隊長了。
- 這裡需要注意一點,不是說隊長會一直等待要提交的事務不停地加入,而是有一個時限,這個時限就是從隊長加入開始,到它去處理佇列的時間——等待binlog_group_commit_sync_delay毫秒,便進行一次組提交,如果在等待事件範圍內提前達到binlog_group_commit_sync_no_delay_count事務個數時,也會直接進行一次組提交。
- 只要隊長將這個佇列中的事務取出,其他事務就可以加入這個等待佇列了。第一個加入的還是隊長,但此時必須要等待。因為此時有事務正在做FLUSH,做完FLUSH之後,其他的隊長才能帶著隊員做FLUSH。
- 在同一時刻,只能有一個組在做FLUSH。這就是上圖中所示的等待事務組2和等待事務組3,此時隊長會按照順序依次做FLUSH。
- 做FLUSH的過程中,有一些重要的事務需要去做,如下:
-
要保證順序必須是提交加入到佇列的順序。
-
如果有新的事務提交,此時佇列為空,則可以加入到FLUSH佇列中。不過,因為此時FLUSH臨界區正在被佔用,所以新事務組必須要等待。
-
給每個事務分配sequence_number,如果是第一個事務,則將這個組的last_committed設定為sequence_number-1.
-
將帶著last_committed與sequence_number的GTID事件FLUSH到Binlog檔案中。
-
將當前事務所產生的Binlog內容FLUSH到Binlog檔案中。
這樣,一個事務的FLUSH就完成了。接下來,依次做完組內所有事務的FLUSH。然後做SYNC。
做完FLUSH之後,FLUSH臨界區會空閒出來,此時在等待這個臨界區的組就可以做FLUSH操作了。
-
-
SYNC佇列
如果SYNC的臨界區是空的,則直接做SYNC操作,而如果已經有事務組在做,則必須要等待。 -
COMMIT佇列
到COMMIT時,實際做的是儲存引擎提交,引數binlog_order_commits會影響提交行為。- 如果設定為ON,那麼此時提交就變為序列操作了,就以佇列的順序為提交順序。
- 如果設定為OFF,提交就不會在這裡進行,而會在每個事務(包括隊長和隊員)做finish_commit(FINISH)時各自做儲存引擎的提交操作。
- 組內每個事務做finish_commit是在隊長完成COMMIT工序之後進行,到步驟DONE時,便會喚醒每個等待提交完成的事務,告訴他們可以繼續了,那麼每個事務就會去做finish_commit。
- 而後,隊長自己再去做finish_commit。這樣,一個組的事務就都按部就班地提交完成了。
現在應該搞明白關於order commit的原理了,而這也是LOGICAL_CLOCK並行複製的基礎。
因為order commit使得所有的事務分了組,並且有了序列號,從庫拿到這些資訊之後,就可以根據序號放心大膽地做分發了。
探索:binlog_group_commit_sync_delay 、binlog_group_commit_sync_no_delay_count對group commit的影響:
從時間上說,從隊長開始入隊,到取佇列中的所有事務出來,這之間的時間是非常非常小的,所以在這段時間內其實不會有多少個事務。
只有在壓力很大,提交的事務非常多的時候,才會提高並行度(組內事務數變大)。
不過這個問題也可以解釋得通,主庫壓力小的時候,從庫何必要那麼大的並行度呢?只有主庫壓力大的時候,從庫才會延遲。
這種情況下也可以通過調整主伺服器上的引數binlog_group_commit_sync_delay、binlog_group_commit_sync_no_delay_count。
- binlog_group_commit_sync_delay表示事務延遲提交多少時間來加大整個組提交的事務數量,從而減少進行磁碟刷盤sync的次數,單位為1/1000000秒,最大值1000000也就是1秒;
- binlog_group_commit_sync_no_delay_count表示組提交的事務數量湊齊多少此值時就跳出等待,然後提交事務,而無需等待binlog_group_commit_sync_delay的延遲時間;但是binlog_group_commit_sync_no_delay_count也不會超過binlog_group_commit_sync_delay設定。
兩個引數都是為了增加主伺服器組提交的事務比例,從而增大從機MTS的並行度。
事務group commit,logical clock(order commit)示意圖:
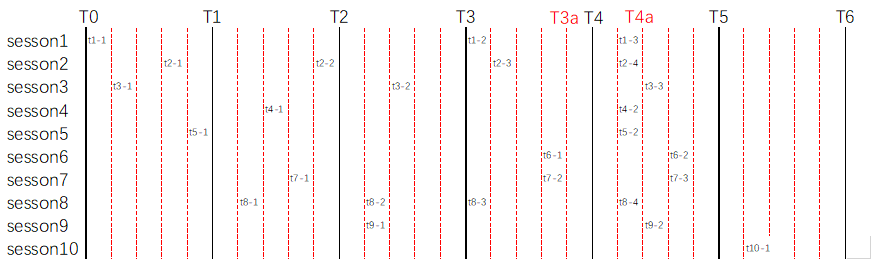
假設當前環境設定引數:
binlog_group_commit_sync_delay = 1000
binlog_group_commit_sync_no_delay_count = 5
圖中:
T0->T1->..->T6,每一個區間表示一個binlog_group_commit_sync_delay = 1000 時間範圍,紅虛線將該時間範圍5等分。
其中,T0為session1 - session10 十個對談同時開啟事務的時間節點。
tn-m,為session-n在當前位置進行了第m次提交動作。
-
當時間進行到T1時,達到binlog_group_commit_sync_delay = 1000 的delay時間限制,本次group commit內容為:(不考慮隊長順序)
t1-1,last_committed=0, sequence_number=1 t2-1,last_committed=0, sequence_number=2 t3-1,last_committed=0, sequence_number=3 t5-1,last_committed=0, sequence_number=4 -
當時間進行到T2時,再一次達到binlog_group_commit_sync_delay = 1000 的delay時間限制,本次group commit內容為:(不考慮隊長順序)
t2-2,last_committed=4, sequence_number=5 t4-1,last_committed=4, sequence_number=6 t7-1,last_committed=4, sequence_number=7 t8-1,last_committed=4, sequence_number=8 -
當時間進行到T3時,再一次達到binlog_group_commit_sync_delay = 1000 的delay時間限制,本次group commit內容為:(不考慮隊長順序)
t3-2,last_committed=8, sequence_number=9 t8-2,last_committed=8, sequence_number=10 t9-1,last_committed=8, sequence_number=11 -
當時間進行到T3a時,儘管未達到binlog_group_commit_sync_delay = 1000 的delay時間限制,但是已經發生5次提交,達到binlog_group_commit_sync_no_delay_count = 5計數上限,將立即進行組提交,本次group commit內容為:(不考慮隊長順序)
t1-2,last_committed=11, sequence_number=12 t2-3,last_committed=11, sequence_number=13 t6-1,last_committed=11, sequence_number=14 t7-2,last_committed=11, sequence_number=15 t8-3,last_committed=11, sequence_number=16 -
當時間進行到T4a時,儘管未達到binlog_group_commit_sync_delay = 1000 的delay時間限制,但是已經發生5次提交,達到binlog_group_commit_sync_no_delay_count = 5計數上限,將立即進行組提交,本次group commit內容為:(不考慮隊長順序)
t1-3,last_committed=16, sequence_number=17 t2-4,last_committed=16, sequence_number=18 t4-2,last_committed=16, sequence_number=19 t5-2,last_committed=16, sequence_number=20 t8-4,last_committed=16, sequence_number=21 -
一個彩蛋。當t10-1事務提交後,將會立即執行組提交,為什麼?
- 因為T4a時間點進行組提交後,delay 1000(5格時間單位)的提交時間點剛好在t10-1事務提交發生的同一時間。
- 也因為T4a時間點進行組提交後,截至t10-1事務提交,count剛好達到計數上限——5。
本次group commit內容為:(不考慮隊長順序)t3-3,last_committed=21, sequence_number=22 t6-2,last_committed=21, sequence_number=23 t7-3,last_committed=21, sequence_number=24 t9-2,last_committed=21, sequence_number=25 t10-1,last_committed=21, sequence_number=26
從庫多執行緒複製分發原理
知道了order commit原理之後,現在很容易可以想到在從庫端是如何分發的:
從庫以事務為單位做APPLY的,每個事務有一個GTID事件,因此都有一個last_committed及sequence_number值。
1. 基於last_committed分發原理如下:
因為last_committed值的記錄方式是:master將上一組最後一個sequence_number記錄為下一組的last_committed,因此本組的sequence_number最小值肯定大於last_committed,下一組的last_committed肯定大於前一組sequence_number的最小值(因為等於sequence_number最大值)
- sql thread拿到一個新事務,取出該事務的last_committed及sequence_number值。
- 將已經執行的事務的sequence_number的最小值(low water mark,lwm),與取出事務的last_committed值進行比較。(本組的sequence_number最小值肯定大於last_committed)
- 如果取出事務的last_committed小於已經執行的sequence(lwm),說明取出事務與當前執行組為同組,無需等待,直接由sql thread 分配事務到空閒worker執行緒。
- SQL執行緒通過統計,找到一個空閒的worker執行緒,如果沒有空閒,則SQL執行緒轉入等待狀態,直到找到一個空閒worker執行緒為止。將當前事務打包,交給選定的worker,之後worker執行緒會去APPLY這個事務,此時的SQL執行緒就會處理下一個事務。
- 如果取出事務的last_committed大於等於已經執行的lwm,說明取出事務與當前不為一組,取出事務為新組,需等待。
- 等待lwm增長,當已經執行的sequence(lwm)等於取出事務的last_committed時,說明前一組已經執行完成。sql thread 開始將取出事務的last_committed組事務分發給worker執行緒進行並行apply。
原理示意參考:
-
事務示意參考:
t3-3,last_committed=21, sequence_number=22 t6-2,last_committed=21, sequence_number=23 t7-3,last_committed=21, sequence_number=24 t9-2,last_committed=21, sequence_number=25 t10-1,last_committed=21, sequence_number=26 new,last_committed=26, sequence_number=27 -
假設此時sql thread 剛剛將事務t3-3分發給worker執行緒:
-
sql thread拿出事務(t6-2)的last_committed和sequence_number(21,23),
- 如果拿出事務的last_committed(21)小於當前已經執行的sequence_number的最小值(22),說明拿出的事務與正在執行的事務是同組,無需等待。
-
sql thread拿出事務(t7-3)的last_committed和sequence_number(21,24),
- 如果拿出事務的last_committed(21)小於當前已經執行的sequence_number的最小值(22),說明拿出的事務與正在執行的事務是同組,無需等待。
……
-
sql thread拿出事務(new)的last_committed和sequence_number(26,27),
- 如果拿出事務的last_committed(26)大於等於當前已經執行的sequence_number的最小值(22),說明拿出的事務是新的一組,拿出的事務需等待。
- 當sql thread判斷已經執行的sequence_number 等於拿出事務的last_committed時,說明可以開始新一組的apply了。
-
-
當事務(t10-1)執行後,已經執行的sequence_number(26) = 拿出事務的last_committed(26),前一組已經執行完成,sql thread 開始將last_committed=26的組事務分發給worker執行緒進行並行apply。
Commit-Parent-Based Scheme簡介(WL#7165)
- 在master上,有一個全域性計數器(global counter)。在每一次儲存引擎完成提交之前,計數器值就會增加。
- 在master上,在事務進入prepare階段之前,全域性計數器的當前值會被儲存在事務中。這個值稱為此事務的commit-parent(last_committed)。
- 在master上,commit-parent會在事務的開頭被儲存在binlog中。
- 在slave上,如果兩個事務有同一個commit-parent,他們就可以並行被執行。
此commit-parent就是我們在binlog中看到的last_committed。如果commit-parent相同,即last_committed相同,則被視為同一組,可以並行回放。
基於last_committed分發(Commit-Parent-Based Scheme)存在的問題
一句話:Commit-Parent-Based Scheme會降低複製的並行程度。
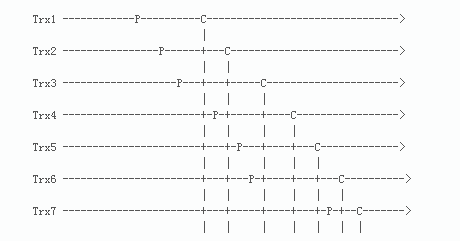
解釋一下圖:
-
水平虛線表示事務按時間順序往後走。
-
P表示事務在進入prepare階段之前讀到的commit-parent值的那個時間點(last_committed)。可以簡單的視為加鎖時間點。
-
C表示事務增加了全域性計數器(global counter)的值的那個時間點(sequence)。可以簡單的視為釋放鎖的時間點
-
P對應的commit-parent(last_commited)是取自所有已經執行完的事務的最大的C對應的sequence_number。
- 舉例來說:
- Trx4的P對應的commit-parent(last_commited)取自所有已經執行完的事務的最大的C對應的sequence_number=1,也就是Trx1的C對應的sequence_number。因為這個時候Trx1已經執行完,但是Trx2還未執行完。
- Trx5的P對應的commit-parent(last_commited)取自所有已經執行完的事務的最大的C對應的sequence_number=2,也就是Trx2的C對應的sequence_number;
- Trx6的P對應的commit-parent(last_commited)取自所有已經執行完的事務的最大的C對應的sequence_number=2,也就是Trx2的C對應的sequence_number。所以Trx5和Trx6具有相同的commit-parent(last_commited),在進行回放的時候,Trx5和Trx6可以並行回放。
- 舉例來說:
-
由圖可見:
- Trx5 和Trx6可以並行執行,因為他們的commit-parent是相同的,都是由Trx2設定的。
- Trx4和Trx5不能並行執行,
- Trx6和Trx7也不能並行執行。
可以注意到,在同一時段,Trx4和Trx5、Trx6和Trx7分別持有他們各自的鎖,事務互不衝突。如果在slave上並行執行,也是不會有問題的。
-
根據以上例子,可以得知:
- 在基於last_committed規則下,Trx4、Trx5和Trx6在同一時間持有各自的鎖,但Trx4無法並行執行,因為Trx4取到的laste_committed和後兩者不同。
- Trx6和Trx7在同一時間持有各自的鎖,但Trx7無法並行執行,原因一樣。
實際上,Trx4是可以和Trx5、Trx6並行執行,Trx6可以和Trx7並行執行。如果能實現這個,那麼並行複製的效果會更好。
所以官方對並行複製的機制做了改進,提出了一種新的並行複製的方式:Lock-Based Scheme。# 5.7開始基於lock interval的並行規則(WL#7165)
說明:上面的步驟是以事務為單位介紹的,其實實際處理中還是一個事件一個事件地分發。如果一個事務已經選定了worker,而新的event還在那個事務中,則直接交給那個worker處理即可。
從上面的分發原理來看,同時執行的都是具有相同last_committed值的事務,不同的只是後面的需要等前面做完了才能執行,這樣的執行方式有點如下圖所示:
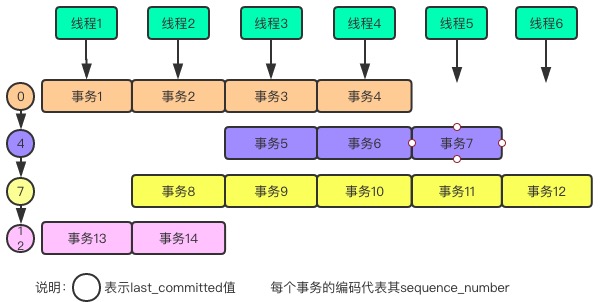
可以看出,事務都是隨機分配到了worker執行緒中,但是執行的話,必須是一行一行地執行。一行事務個數越多,並行度越高,也說明主庫瞬時壓力越大。
2. MySQL 5.7開始基於lock interval的並行規則(WL#7165)
實現:如果兩個事務在同一時間持有各自的鎖,就可以並行執行。
對前一個原理需要補充為:
因為last_committed值的記錄方式是:master將上一組最後一個sequence_number記錄為下一組的last_committed,master將MySQL全域性變數global.max_committed_transaction(所有已經結束lock interval的事務的最大的sequence_number)記錄為下一組的last_committed,因此本組的sequence_number最小值肯定大於last_committed,下一組的last_committed肯定大於前一組sequence_number的最小值(因為等於sequence_number最大值)
# 根據基於鎖特性,實際上是與本組第一個Prepare存在時間間隙的上一組C的那個事務的sequence,也就是說,如果前一組的後幾個事務與當前組的前幾個事務存在lock interval重疊,那麼前一組的這幾個事務再向前一個事務的sequence才是當前組的last_committed
Lock-Based Scheme簡介(WL#7165)
首先,定義了一個稱為lock interval的概念,含義:一個事務持有鎖的時間間隔。
- 當儲存引擎提交,第一把鎖釋放,lock interval結束。
- 當最後一把鎖獲取,lock interval開始。
假定:最後一把鎖獲取是在binlog_prepare階段。
假設有兩個事務:Trx1、Trx2。Trx1先於Trx2。那麼,
-
當且僅當Trx1、Trx2的lock interval有重疊,則可以並行執行。

Tx0 ,Tx1在同一個時間區間(lock interval),都持有各自的鎖。
也就是說,同一時間這兩個事務持有各自的鎖沒有衝突,因此這兩個事務可以並行apply。lock interval重疊可以並行。
-
換言之,如果Trx1的lock interval結束點與Trx2的lock interval開始點存在間隙,則不能並行執行。

Tx0 ,Tx1的兩個事務prepare到committed發生時間不重疊(lock interval不重疊),無法確定同一時間這兩個事務持有各自的鎖是否存在衝突
因此這兩個事務不可以並行apply。
-
MySQL會獲取全域性變數global.max_committed_transaction,含義:所有已經結束lock interval的事務的最大的sequence_number。
-
L表示lock interval的開始點
- 對於L(lock interval的開始點),MySQL會把
global.max_committed_timestamp分配給一個變數,並取名叫transaction.last_committed。
- 對於L(lock interval的開始點),MySQL會把
-
C表示lock interval的結束
- 對於C(lock interval的結束點),MySQL會給每個事務分配一個邏輯時間戳(logical timestamp),命名為:
transaction.sequence_number。
- 對於C(lock interval的結束點),MySQL會給每個事務分配一個邏輯時間戳(logical timestamp),命名為:
transaction.sequence_number和transaction.last_committed這兩個時間戳都會存放在binlog中。
- 根據以上分析,我們可以得出在slave上執行事務的條件:
如果所有正在執行的事務的最小的sequence_number大於一個事務的transaction.last_committed,那麼這個事務就可以並行執行。(這句話太繞,不用強求,看下面土味理解好了)
土味理解Lock-Based Scheme
在這先拋開writeset,不要混淆了,理解了這個會有助於理解writeset原理。
-
基於commit parent的方式, 事務的last_committed肯定等於前一組最後一個事務的sequence number。
-
但是在基於lock interval方式時,不是這樣了,事務的last_committed不一定等於前一組最後一個事務的sequence number了,而是等於所有已經結束lock interval的事務的最大的sequence_number。
-
舉例說明:
Lock-Based Scheme例子
…
t1,last_committed=0, sequence_number=3
t2,last_committed=3, sequence_number=4
t3,last_committed=3, sequence_number=5
t4,last_committed=3, sequence_number=6
t5,last_committed=3, sequence_number=7
t6,last_committed=6, sequence_number=8
t7,last_committed=6, sequence_number=9
t8,last_committed=9, sequence_number=10
- 事務t1,last_committed=0,sequence_number=3。第一個work執行緒會接手這個事務並開始工作。
- 事務t2,last_committed=3, sequence_number=4。直到事務t1完成,事務t2才能開始。因為last_committed=3不小於正在執行執行事務的sequence_number=3。所以這兩個事務只能序列。
- 雖然前2個事務可能會被分配到不同的work執行緒,但實際上他們是序列的,就像單執行緒複製那樣。
- 當sequence_number=3的事務完成,last_committed=3的三個事務就可以並行執行。
t3,last_committed=3, sequence_number=5 t4,last_committed=3, sequence_number=6 t5,last_committed=3, sequence_number=7 - 一旦前兩個(t3,t4)執行完成,下面這兩個可以開始執行:
last_committed=6 sequence_number=8 last_committed=6 sequence_number=9
因為last_committed=6小於正在執行執行事務的sequence_number=7,可以並行。
-
也就是說,當t5,last_committed=3, sequence_number=7正在執行的時候,sequence_number=8和sequence_number=9這兩個也可以並行執行。
-
這三個事務的結束沒有前後順序的限制。
-
因為這三個事務的lock interval有重疊,因此可以並行執行,所以事務之間並不會相互影響。
-
等到前面的事務均完成之後,下面這個事務才可以進行:
t8,last_committed=9, sequence_number=10 -
看完更暈了?沒關係,不用糾結,看下面:

-
首先說明,圖中事務Tx1作為參考事務,忽略它,它的意義就是為Tx2事務提供一個last_committed。
-
Tx2--Tx5為第一組,Tx6~Tx7為第二組,用底色做了區分。
-
可以看到:
- 事務Tx2~Tx5都存在lock interval重疊,這4個事務可以並行apply,因此這4個事務在一個組。
- 事務Tx6因為和事務Tx4沒有發生lock interval重疊,因此事務Tx6無法和Tx4並行,也就無法成為前一組的成員,只能自己成立新組。
- 第一組的最後一個事務Tx5和第二組的事務Tx6、Tx7三個事務存在lock interval重疊,雖然跨組,但是這3個事務是滿足並行邏輯,可以並行進行的。
- 第二組的last值=6,並不是第一組最後一個事務的sequence_number=7。(為什麼?↓)
-
實際上第二組的last_committed值是取自於這個規則:
-
幾個關鍵的時間點:
- 第二組第一個事務開始prepare的時間點稱為A點(last_committed)。
- A點發生時,第一組中所有已經結束lock interval的事務的最大的sequence_number稱為B點。
- 第一組最後一個事務Tx5的commit時間稱為C點(sequence_number)
-
在A點發生prepare時,B點和A點之間存在間隙(就是說,事務tx4和事務tx6不存在鎖重疊),Tx4,Tx6無法並行,因此A點進行prepare的事務Tx6成為了新組的事務。
-
A點取當時所有已經結束lock interval的事務的最大的sequence_number作為自己的last_committed。Tx6的last_committed=6。
總結一句話就是:last_committed值取自於前一組中,與本組事務不存在lock interval重疊的最後一個事務的sequence number
-
結論:
- 事務之間存在lock interval重疊便可以並行apply,但是隻要任意兩個事務之間存在gap(事務lock interval不重疊)便會導致分組。
- 分組只是避免鎖衝突,並不意味著無法並行(不管有沒有鎖衝突,只要事務不重疊就悲觀認為存在衝突,拒絕並行)。
- 能否並行的只根據一個情況判斷,就是事務之間lock interval重疊。因此即使事務在不同的組中,只要存在lock interval重疊,就可能會並行apply。
MySQL 5.7並行複製測試
下圖顯示了開啟MTS後,Slave伺服器的QPS。測試的工具是sysbench的單表全update測試,測試結果顯示在16個執行緒下的效能最好,從機的QPS可以達到25000以上,進一步增加並行執行的執行緒至32並沒有帶來更高的提升。而原單執行緒回放的QPS僅在4000左右,可見MySQL 5.7 MTS帶來的效能提升,而由於測試的是單表,所以MySQL 5.6的MTS機制則完全無能為力了。

並行複製設定與調優
-
master_info_repository
開啟MTS功能後,務必將引數master_info_repostitory設定為TABLE,這樣效能可以有50%~80%的提升。這是因為並行複製開啟後對於master.info這個檔案的更新將會大幅提升,資源的競爭也會變大。
-
slave_parallel_workers
若將slave_parallel_workers設定為0,則MySQL 5.7退化為原單執行緒複製,但將slave_parallel_workers設定為1,則SQL執行緒功能轉化為coordinator執行緒,但是隻有1個worker執行緒進行回放,也是單執行緒複製。然而,這兩種效能卻又有一些的區別,因為多了一次coordinator執行緒的轉發,因此slave_parallel_workers=1的效能反而比0還要差,測試下還有20%左右的效能下降,如下圖所示:
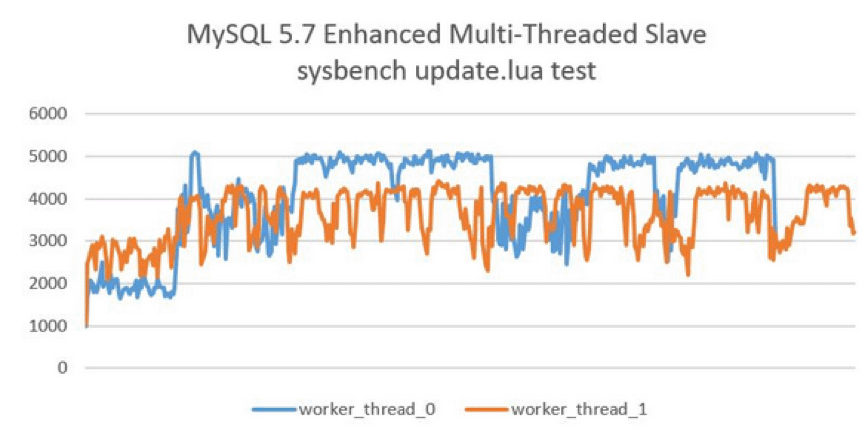
這裡其中引入了另一個問題,如果主機上的負載不大,那麼組提交的效率就不高,很有可能發生每組提交的事務數量僅有1個,那麼在從機的回放時,雖然開啟了並行複製,但會出現效能反而比原先的單執行緒還要差的現象,即延遲反而增大了。聰明的小夥伴們,有想過對這個進行優化嗎?
-
slave_preserve_commit_order
MySQL 5.7後的MTS可以實現更小粒度的並行複製,但需要將slave_parallel_type設定為LOGICAL_CLOCK,但僅僅設定為LOGICAL_CLOCK也會存在問題,因為此時在slave上應用事務的順序是無序的,和relay log中記錄的事務順序不一樣,這樣資料一致性是無法保證的,為了保證事務是按照relay log中記錄的順序來回放,就需要開啟引數slave_preserve_commit_order。
開啟該引數後,執行執行緒將一直等待, 直到提交之前所有的事務。當sql thread正在等待其他worker提交其事務時, 其狀態為等待前面的事務提交。
所以雖然MySQL 5.7新增MTS後,雖然slave可以並行應用relay log,但commit部分仍然是順序提交,其中可能會有等待的情況。
當開啟slave_preserve_commit_order引數後,slave_parallel_type只能是LOGICAL_CLOCK,如果你有使用級聯複製,那LOGICAL_CLOCK可能會使離master越遠的slave並行性越差。
但是經過測試,這個引數在MySQL 5.7.18中設定之後,也無法保證slave上事務提交的順序與relay log一致。
在MySQL 5.7.19設定後,slave上事務的提交順序與relay log中一致(所以生產要想使用MTS特性,版本大於等於MySQL 5.7.19才是安全的)。
說了這麼多,要開啟enhanced multi-threaded slave其實很簡單,只需根據如下設定:
# slave;
slave-parallel-type=LOGICAL_CLOCK
slave-parallel-workers=16
slave_pending_jobs_size_max = 2147483648
slave_preserve_commit_order=1
master_info_repository=TABLE
relay_log_info_repository=TABLE
relay_log_recovery=ON
在使用了MTS後,複製的監控依舊可以通過SHOW SLAVE STATUS\G,但是MySQL 5.7在performance_schema架構下多了以下這些後設資料表,使用者可以更細力度的進行監控:
mysql> show tables like 'replication%';
+---------------------------------------------+
| Tables_in_performance_schema (replication%) |
+---------------------------------------------+
| replication_applier_configuration |
| replication_applier_status |
| replication_applier_status_by_coordinator |
| replication_applier_status_by_worker |
| replication_connection_configuration |
| replication_connection_status |
| replication_group_member_stats |
| replication_group_members |
+---------------------------------------------+
8 rows in set (0.00 sec)
通過replication_applier_status_by_worker可以看到worker程序的工作情況:
mysql> select * from replication_applier_status_by_worker;
+--------------+-----------+-----------+---------------+--------------------------------------------+-------------------+--------------------+----------------------+
| CHANNEL_NAME | WORKER_ID | THREAD_ID | SERVICE_STATE | LAST_SEEN_TRANSACTION | LAST_ERROR_NUMBER | LAST_ERROR_MESSAGE | LAST_ERROR_TIMESTAMP |
+--------------+-----------+-----------+---------------+--------------------------------------------+-------------------+--------------------+----------------------+
| | 1 | 32 | ON | 0d8513d8-00a4-11e6-a510-f4ce46861268:96604 | 0 | | 0000-00-00 00:00:00 |
| | 2 | 33 | ON | 0d8513d8-00a4-11e6-a510-f4ce46861268:97760 | 0 | | 0000-00-00 00:00:00 |
+--------------+-----------+-----------+---------------+--------------------------------------------+-------------------+--------------------+----------------------+
2 rows in set (0.00 sec)
那麼怎樣知道從機MTS的並行程度又是一個難度不小。簡單的一種方法(姜總給出的),可以使用performance_schema庫來觀察,比如下面這條SQL可以統計每個Worker Thread執行的事務數量,在此基礎上再做一個聚合分析就可得出每個MTS的並行度:
SELECT thread_id,count_star FROM performance_schema.events_transactions_summary_by_thread_by_event_name
WHERE thread_id IN (SELECT thread_id FROM performance_schema.replication_applier_status_by_worker);
如果執行緒並行度太高,不夠平均,其實並行效果並不會好,可以試著優化。這種場景下,可以通過調整主伺服器上的引數binlog_group_commit_sync_delay、binlog_group_commit_sync_no_delay_count。前者表示延遲多少時間提交事務,後者表示組提交事務湊齊多少個事務再一起提交。總體來說,都是為了增加主伺服器組提交的事務比例,從而增大從機MTS的並行度。
雖然MySQL 5.7推出的Enhanced Multi-Threaded Slave在一定程度上解決了困擾MySQL長達數十年的複製延遲問題。然而,目前MTS機制基於組提交實現,簡單來說在主上是怎樣並行執行的,從伺服器上就怎麼回放。這裡存在一個可能,即若主伺服器的並行度不夠,則從機的並行機制效果就會大打折扣。MySQL 8.0最新的基於writeset的MTS才是最終的解決之道。即兩個事務,只要更新的記錄沒有重疊(overlap),則在從機上就可並行執行,無需在一個組,即使主伺服器單執行緒執行,從伺服器依然可以並行回放。相信這是最完美的解決之道,MTS的最終形態。
最後,如果MySQL 5.7要使用MTS功能,必須使用最新版本,最少升級到5.7.19版本,修復了很多Bug。
參考資訊
http://www.ywnds.com/?p=3894
運維內參書籍
姜總的公眾號文章
http://mysql.taobao.org/monthly/2017/12/03/
https://mp.weixin.qq.com/s/XbWMdVTl9qz1nSwL3l56XQ