深度學習與CV教學(13) | 目標檢測 (SSD,YOLO系列)

- 作者:韓信子@ShowMeAI
- 教學地址:http://www.showmeai.tech/tutorials/37
- 本文地址:http://www.showmeai.tech/article-detail/272
- 宣告:版權所有,轉載請聯絡平臺與作者並註明出處
- 收藏ShowMeAI檢視更多精彩內容

本系列為 斯坦福CS231n 《深度學習與計算機視覺(Deep Learning for Computer Vision)》的全套學習筆記,對應的課程視訊可以在 這裡 檢視。更多資料獲取方式見文末。
引言
目標檢測 ( Object Detection )是計算機視覺領域非常重要的任務,目標檢測模型要完成「預測出各個物體的邊界框(bounding box)」和「給出每個物體的分類概率」兩個子任務。
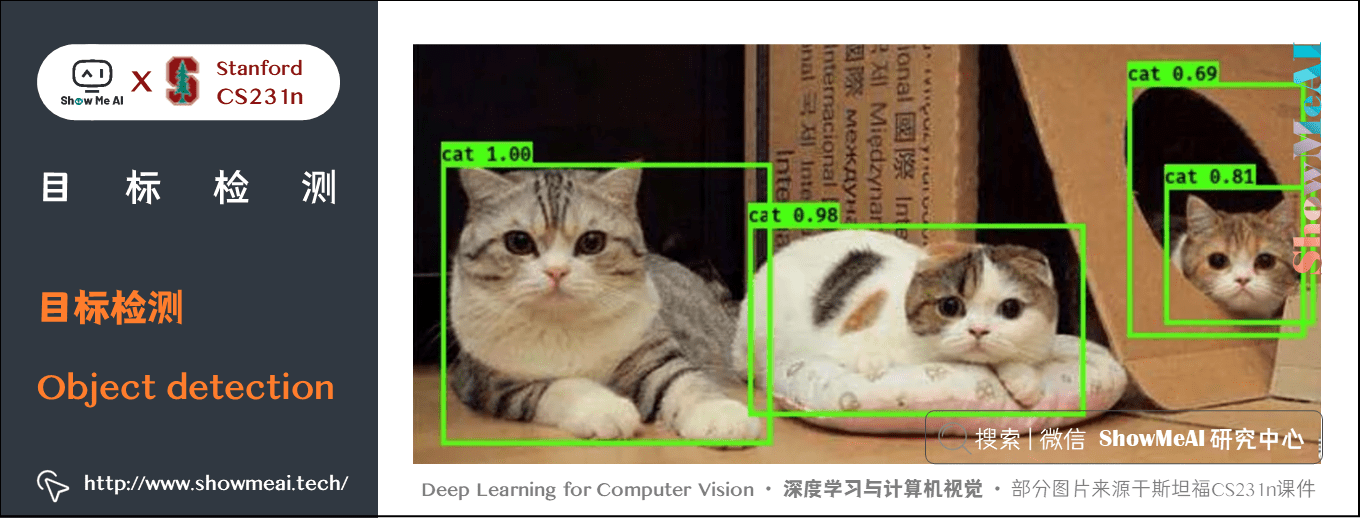
通常情況下,在對一張圖片進行目標檢測後,會得到許多物體的邊界框和對應的置信度(代表其包含物體的可能性大小)。
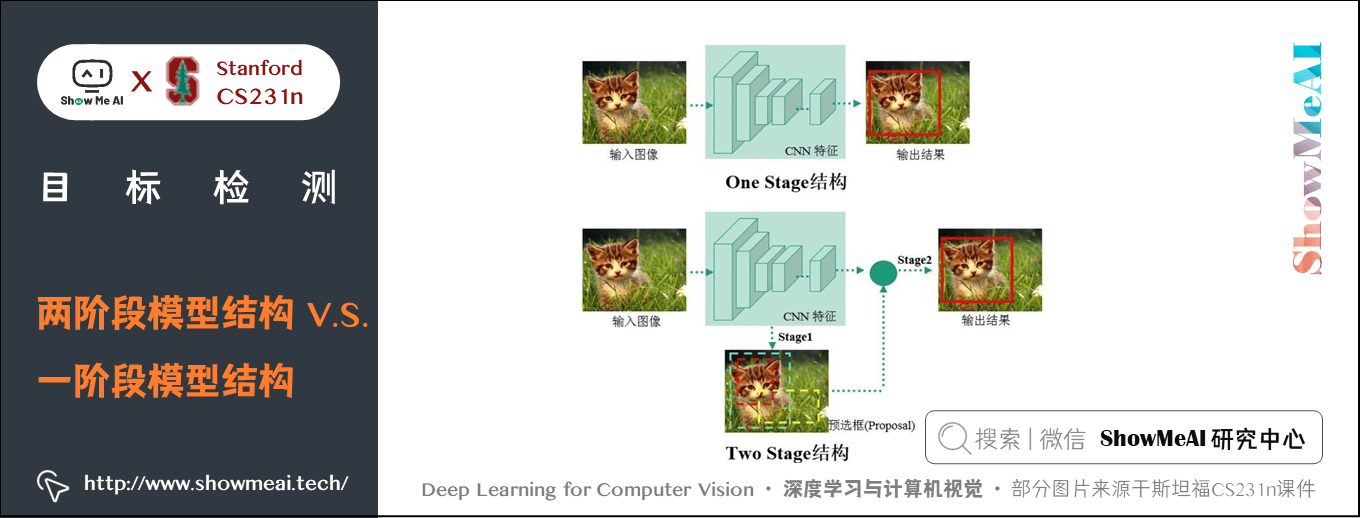
目標檢測演演算法主要集中在 two-stage 演演算法和 one-stage 演演算法兩大類:
① two-stage演演算法
- 如 R-CNN 系列演演算法,需要先生成 proposal(一個有可能包含待檢物體的預選框),然後進行細粒度的物體檢測。
- ShowMeAI在上一篇 深度學習與CV教學(12) | 目標檢測 (兩階段, R-CNN系列) 中做了介紹。
② one-stage演演算法
- 直接在網路中提取特徵來預測物體分類和位置。
two-stage 演演算法速度相對較慢但是準確率高,one-stage 演演算法準確率沒有 two-stage 演演算法高但是速度較快。在本篇我們將聚焦 one-stage 的目標檢測方法進行講解,主要包括 YOLO 系列演演算法和 SSD 等。
1.YOLO演演算法(YOLO V1)
關於 YOLO 的詳細知識也可以對比閱讀ShowMeAI的深度學習教學 | 吳恩達專項課程 · 全套筆記解讀中的文章 CNN應用: 目標檢測 中對於 YOLO 的講解。
1.1 演演算法核心思想
YOLO 演演算法採用一個單獨的 CNN 模型實現 end-to-end 的目標檢測。首先將輸入圖片 resize 到 \(448 \times 448\),然後送入 CNN 網路,最後處理網路預測結果得到檢測的目標。相比 R-CNN 演演算法,其是一個統一的框架,其速度更快,而且 YOLO 的訓練過程也是 端到端 / end-to-end 的。所謂的 YOLO 全名是 You Only Look Once,意思是演演算法只需要一次的推斷運算。

相比上述滑動視窗演演算法,YOLO 演演算法不再是視窗滑動,而是直接將原始圖片分割成互不重合的小方塊,然後通過折積得到同等 size 的特徵圖,基於上面的分析,可以認為特徵圖的每個元素也是對應原始圖片的一個小方塊,可以用每個元素來可以預測那些中心點在該小方塊內的目標。
YOLO演演算法的CNN網路將輸入的圖片分割成 \(N\times N\) 網格,然後每個單元格負責去檢測那些中心點落在該格子內的目標。

如圖所示,可以看到,狗這個目標的中心落在左下角一個單元格內,那麼該單元格負責預測這個狗。每個單元格會預測 $B $ 個邊界框(bounding box)以及邊界框的置信度(confidence score)。
所謂置信度其實包含兩個方面,一是這個邊界框含有目標的可能性大小,二是這個邊界框的準確度。
前者記為 \(P(object)\),當該邊界框是背景時(即不包含目標時),\(P(object)=0\)。而當該邊界框包含目標時,\(P(object)=1\)。
邊界框的準確度可以用預測框與 ground truth 的 IoU (交併比)來表徵,記為 \(\text{IoU}^{truth}_{pred}\)。因此置信度可以定義為 \(Pr(object) \ast \text{IoU}^{truth}_{pred}\)。
邊界框的大小與位置可以用 4 個值來表徵: \((x, y,w,h)\),其中 \((x,y)\) 是邊界框的中心座標,而 \(w\) 和 \(h\) 是邊界框的寬與高。
還有一點要注意,中心座標的預測值 \((x,y)\) 是相對於每個單元格左上角座標點的偏移值,並且單位是相對於單元格大小的,單元格的座標定義如上方圖所示。
邊界框的 \(w\) 和 \(h\) 預測值是相對於整個圖片的寬與高的比例,因此理論上4個元素的大小應該在 \([0,1]\) 範圍。這樣,每個邊界框的預測值實際上包含5個元素: \((x,y,w,h,c)\),其中前4個表徵邊界框的大小與位置,最後一個值是置信度。
除此之外,每一個單元格預測出 \(C\) 個類別概率值,其表徵的是由該單元格負責預測的邊界框中的目標屬於各個類別的概率。這些概率值其實是在各個邊界框置信度下類別的條件概率,即 \(Pr(class_{i}|object)\)。
值得注意的是,不管一個單元格預測多少個邊界框,其只預測一組類別概率值。同時,我們可以計算出各個邊界框的類別置信度 :
邊界框類別置信度表徵的是該邊界框中目標屬於各個類別的可能性大小以及邊界框匹配目標的好壞。
1.2 YOLO網路結構
YOLO演演算法採用CNN來提取特徵,使用全連線層來得到預測值。網路結構參考GoogleNet,包含24個折積層和2個全連線層,如下圖所示。
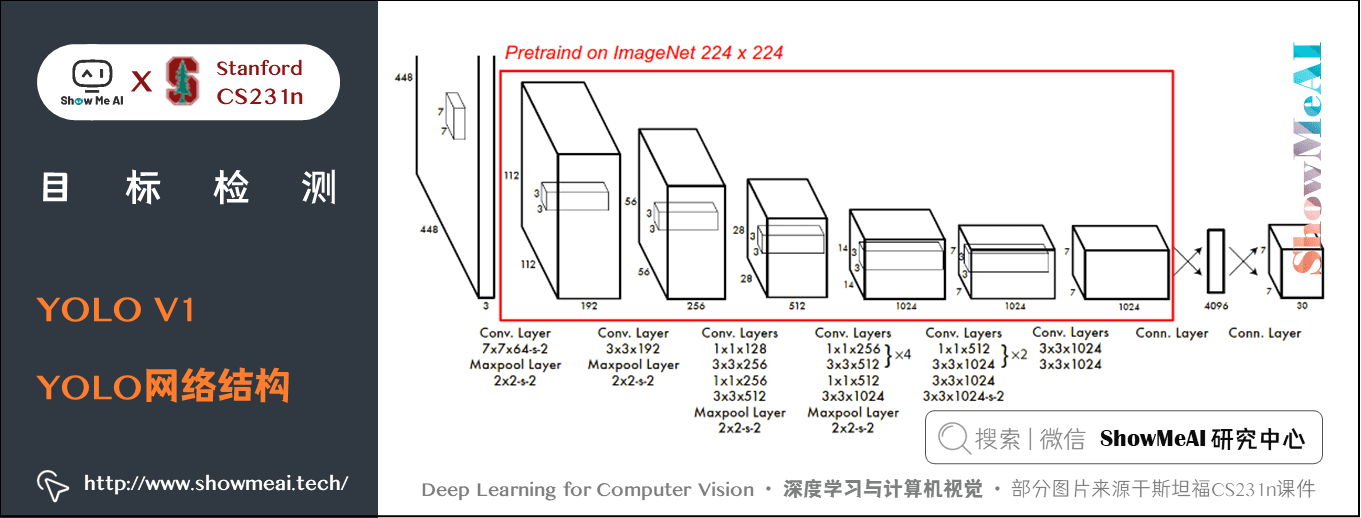
對於折積層,主要使用 \(1 \times 1\) 折積來做通道數降低,用 \(3 \times 3\) 折積提取特徵。對於折積層和全連線層,採用 Leaky ReLU 啟用函數: \(max(x, 0.1x)\),最後一層卻採用線性啟用函數。
1.3 YOLO訓練與預測
在訓練之前,先在 ImageNet 上進行預訓練,其預訓練的分類模型採用上圖中前20個折積層,然後新增一個 average-pool 層和全連線層。
在預訓練結束之後之後,在預訓練得到的 20 層折積層之上加上隨機初始化的 4 個折積層和 2 個全連線層進行 fine-tuning。由於檢測任務一般需要更高清的圖片,所以將網路的輸入從 \(224 \times 224\) 增加到了 \(448 \times 448\)。
整個網路的流程如下圖所示:
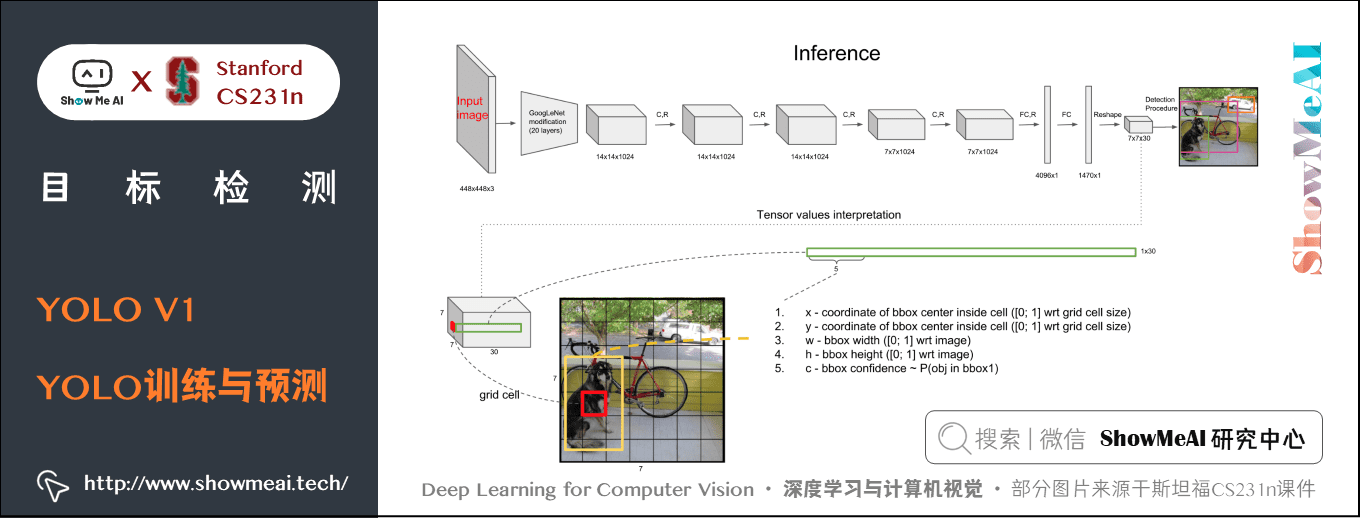
YOLO 演演算法將目標檢測問題看作迴歸問題,所以採用的是 MSE loss,對不同的部分採用了不同的權重值。首先區分定位誤差和分類誤差。
- 對於定位誤差,即邊界框座標預測誤差,採用較大的權重 \(\lambda=5\)。
- 然後其區分不包含目標的邊界框與含有目標的邊界框的置信度,對於前者,採用較小的權重值 \(\lambda =0.5\)。其它權重值均設為 \(1\)。
- 然後採用均方誤差,其同等對待大小不同的邊界框,但是實際上較小的邊界框的座標誤差應該要比較大的邊界框要更敏感。為了保證這一點,將網路的邊界框的寬與高預測改為對其平方根的預測,即預測值變為 \((x,y,\sqrt{w}, \sqrt{h})\)。
由於每個單元格預測多個邊界框。但是其對應類別只有一個。
訓練時,如果該單元格內確實存在目標,那麼只選擇與 ground truth 的 IoU 最大的那個邊界框來負責預測該目標,而其它邊界框認為不存在目標。這樣設定的一個結果將會使一個單元格對應的邊界框更加專業化,其可以分別適用不同大小,不同高寬比的目標,從而提升模型效能。
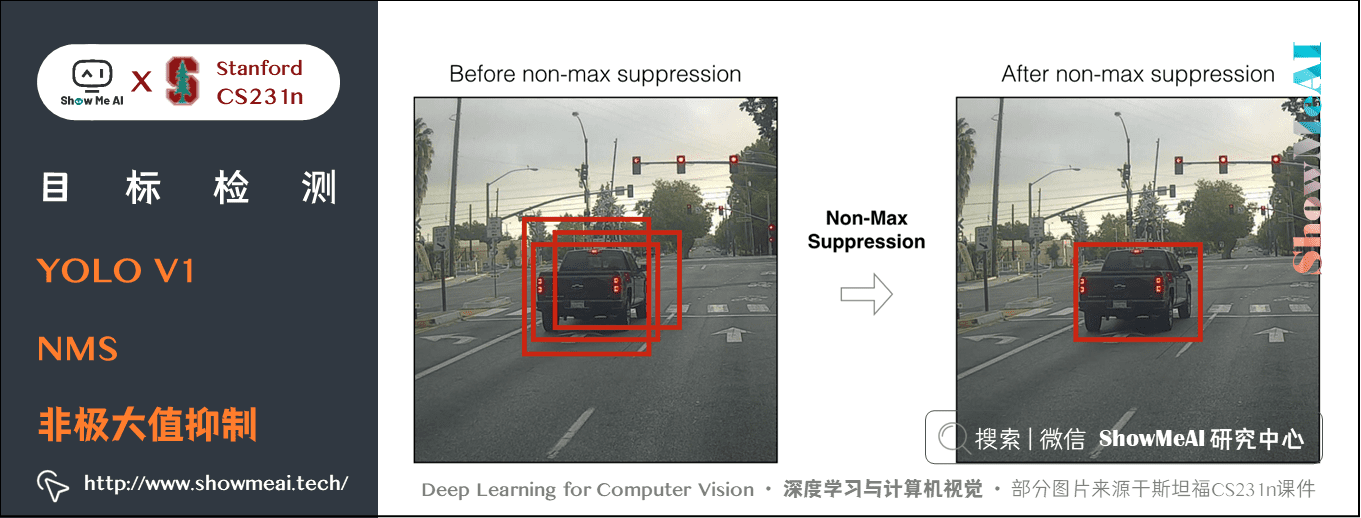
YOLO演演算法預測時採用非極大值抑制 (NMS) 。NMS 演演算法主要解決的是一個目標被多次檢測的問題,如圖中的汽車檢測,可以看到汽車被多次檢測,但是其實我們希望最後僅僅輸出其中一個最好的預測框。
比如對於上圖中的汽車,只想要位置最正那個檢測結果。那麼可以採用 NMS 演演算法來實現這樣的效果:
- 首先從所有的檢測框中找到置信度最大的那個框,然後挨個計算其與剩餘框的 IoU,如果 IoU 大於一定閾值(重合度過高),那麼就將該框(剩餘框)剔除;
- 然後對剩餘的檢測框重複上述過程,直到處理完所有的檢測框。
1.4 YOLO演演算法細節
1) bbox生成步驟
① 輸入影象分成 \(S \times S\) 的網格。現在是劃分成了 \(7 \times 7\) 的,如果物品的中點落在某一個網格單元,這個網格單元將負責識別出這個物體。

注意只是看該目標的中心點,而不是整體。比如 \(A(2, 3)\) 是狗的中心點,那麼 \(A\) 就負責來負責預測狗
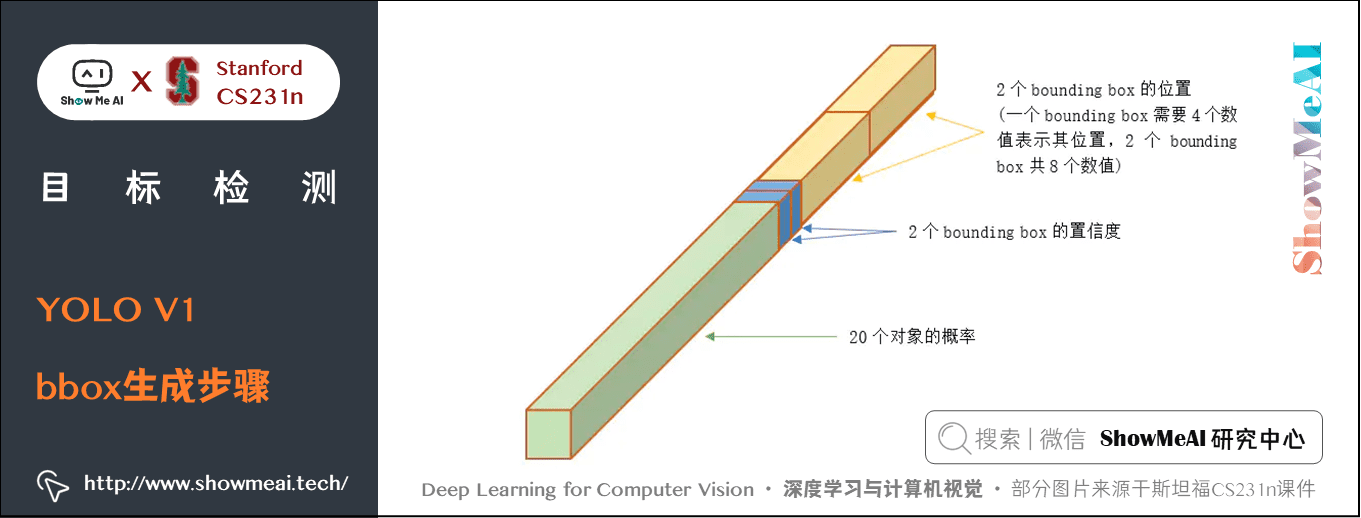
② 每個網格自身也要預測 \(n\) 個邊界框 bounding box 和邊界框的置信度 confidence。論文中 \(b=2\)
邊界框包含四個資料 \(x\),\(y\),\(w\),\(h\):\((x,y)\) 框中心是相對於網格單元的座標,\(w\) 和 \(h\) 是框相當於整幅圖的寬和高。
置信度有兩部分構成:含有物體的概率和邊界框覆蓋的準確性。
- $ IoU$ 交併比
- \(Pr\) 就是概率 \(p\)
如果有 object 落在一個 grid cell 裡,第一項取 \(1\),否則取 \(0\)。 第二項是預測的 bounding box 和實際的 ground truth 之間的 IoU 值。
每個邊界框又要預測五個數值:\(x\), \(y\), \(w\), \(h\), \(confidence\)。\((x,y)\) 框中心是相對於網格單元的座標,\(w\) 和 \(h\) 是框相當於整幅圖的寬和高,confidence 代表該框與 ground truth 之間的 IoU (框裡沒有物體分數直接為 \(0\))。
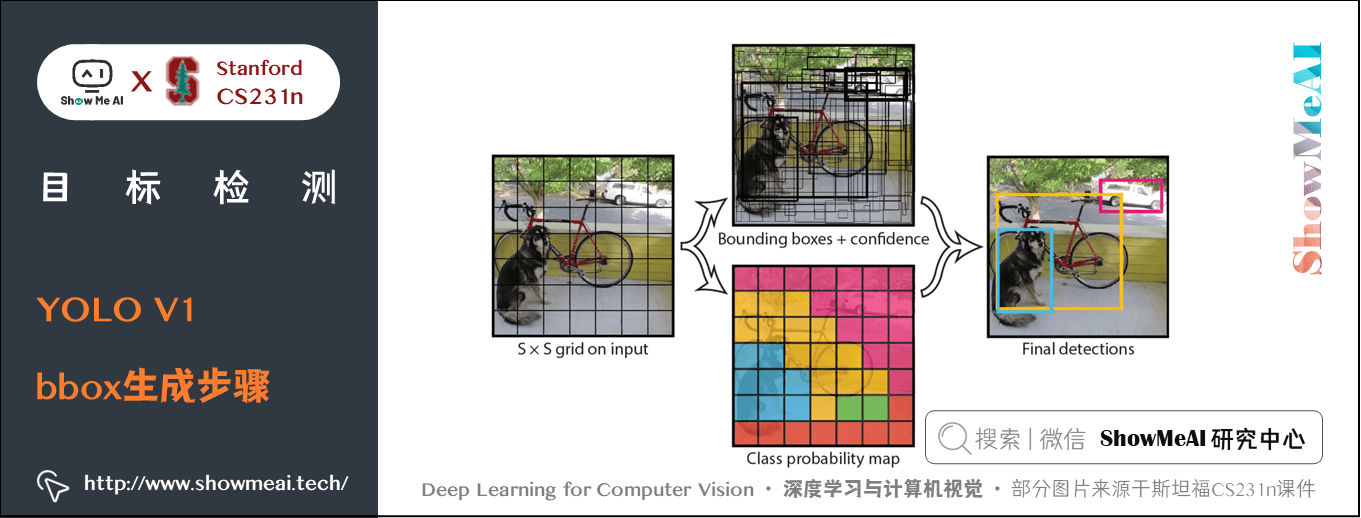
每個網格都要預測 \(b= 2\) 個框,49 個網格就會輸出 98 個邊界框,每個框還有它的分數。每個格子最多隻預測出一個物體。當物體佔畫面比例較小,如影象中包含畜群或鳥群時,每個格子包含多個物體,但卻只能檢測出其中一個。這是 YOLO 方法的一個缺陷。
最後每個單元格再預測他的 \(n\) 個邊界框中的物體分類概率,有 \(c\) 個類別就要計算 \(c\) 個概率,和全連線層類似。
本文中有20個類別:即 \(7 \ast 7(2 \ast 5+20)\)
總結:每個方格要找到 \(n\) 個邊界框,然後還要計算每個邊界框的置信度,最後再計算每個邊界框的分類的可能性。
生成的 bounding box 的 \((x, y)\) 被限制在 cell 裡, 但長寬是沒有限制的(即生成的 bounding box 可超出 cell 的邊界)
2) 損失函數
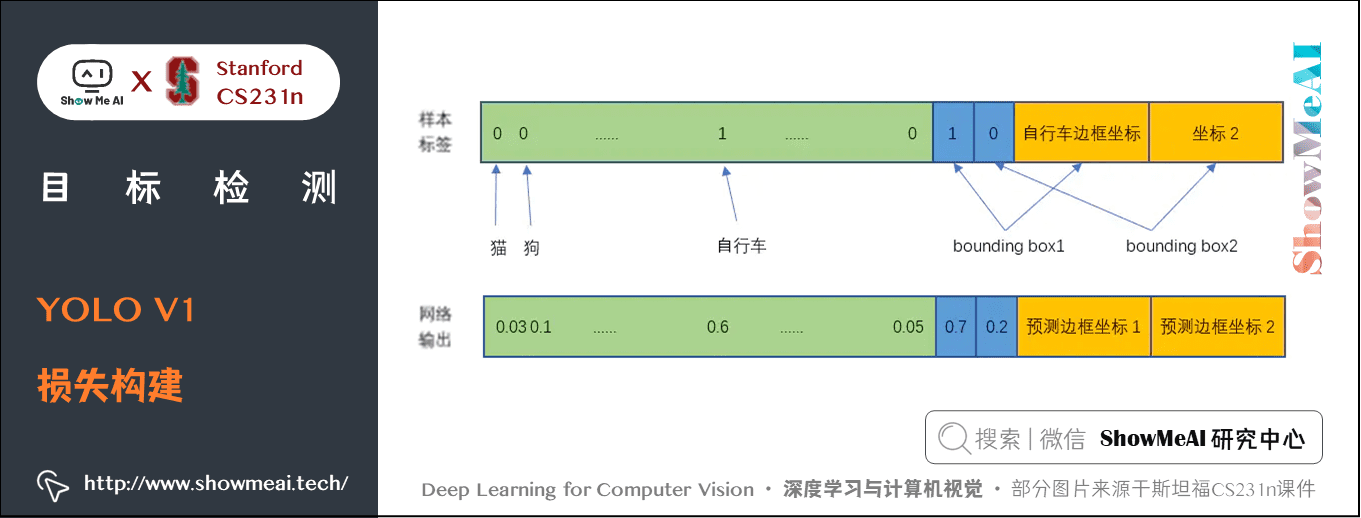
YOLO V1 的損失函數就是把三類損失加權求和,用的也都是簡單的平方差:
邊緣中心點誤差:
邊框寬度、高度誤差:
置信度誤差(邊框內有物件) :
置信度誤差(邊框內無物件) :
物件分類誤差:
其中
- \(1_{i}^{o b j}\) 意思是網格 \(i\) 中存在物件。
- \(1_{i j}^{o b j}\) 意思是網格的第 \(j\) 個 bounding box 中存在物件。
- \(1_{i j}^{n o o b j}\) 意思是網格 \(i\) 的第 個 bounding box 中不存在物件。
損失函數計算是有條件的,是否存在物件對損失函數的計算有影響。
先要計算位置誤差:預測中點和實際中點之間的距離,再計算 bbox 寬度和高度之間的差距,權重為 5 調高位置誤差的權重
置信度誤差:要考慮兩個情況:這個框裡實際上有目標;這個框裡沒有目標,而且要成一個權重降低他的影響,調低不存在物件的 bounding box 的置信度誤差的權重,論文中是 \(0.5\)
物件分類的誤差:當該框中有目標時才計算,概率的二範數
3) YOLO V1 的缺陷
不能解決小目標問題,YOLO 對邊界框預測施加了嚴格的空間約束,因為每個網格單元只能預測兩個邊界框,並且只能有一個類。這個空間約束限制了我們模型能夠預測的臨近物件的數量。
YOLO V1 在處理以群體形式出現的小物件時會有困難,比如成群的鳥。
2. SSD 演演算法
SSD 演演算法全名是 Single Shot Multibox Detector,Single shot指明瞭 SSD 演演算法屬於 one-stage 方法,MultiBox 指明瞭 SSD 是多框預測。
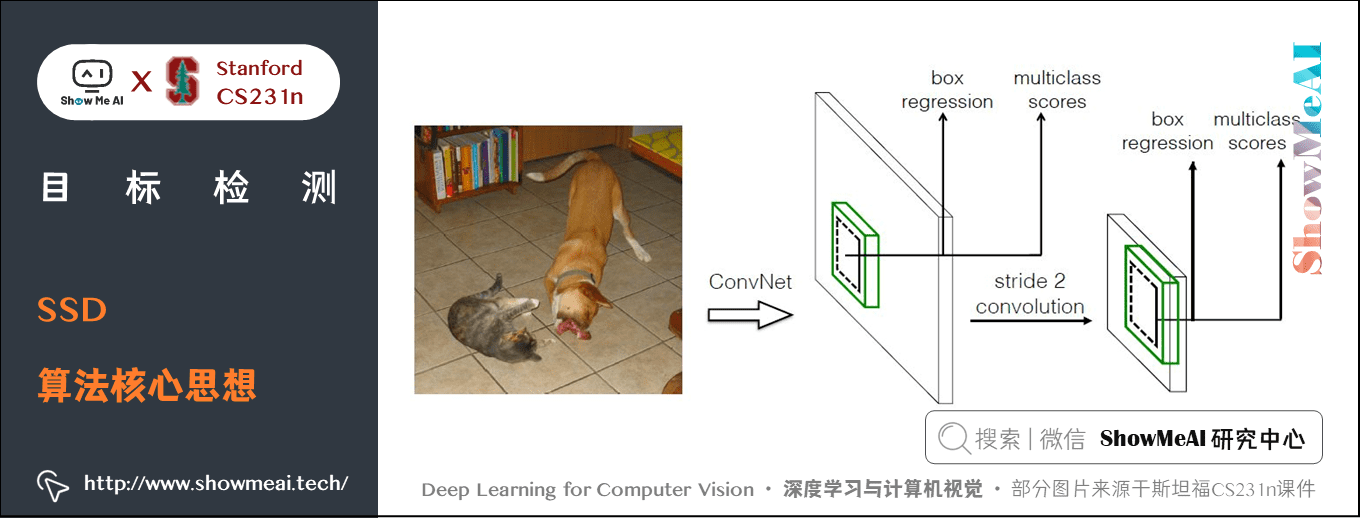
SSD 演演算法在準確度和速度上都優於最原始的 YOLO 演演算法。對比 YOLO,SSD 主要改進了三點:多尺度特徵圖,利用折積進行檢測,設定先驗框。
- SSD 採用CNN來直接進行檢測,而不是像 YOLO 那樣在全連線層之後做檢測。
- SSD 提取了不同尺度的特徵圖來做檢測,大尺度特徵圖(較靠前的特徵圖)可以用來檢測小物體,而小尺度特徵圖(較靠後的特徵圖)用來檢測大物體。
- SSD 採用了不同尺度和長寬比的先驗框(在Faster R-CNN 中叫做 anchor )。
下面展開講解 SSD 目標檢測演演算法。
2.1 演演算法核心思想
1) 採用多尺度特徵圖用於檢測
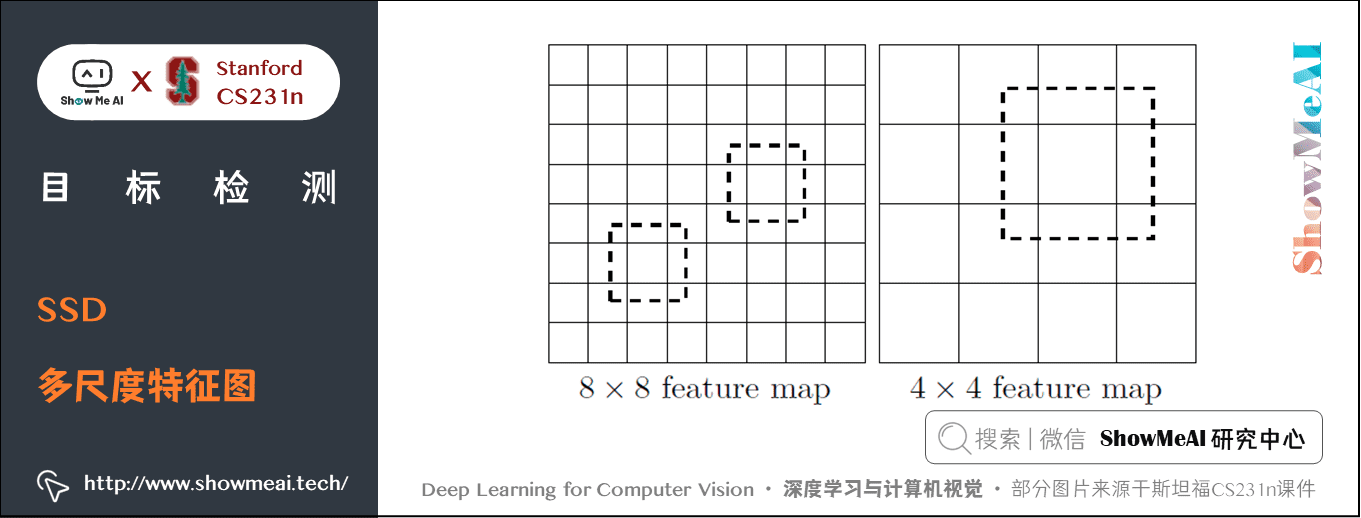
所謂多尺度特徵圖,就是採用大小不同的特徵圖進行檢測。
CNN 網路一般前面的特徵圖比較大,後面會逐漸採用 \(stride=2\) 的折積或者 pool 來降低特徵圖大小,如下圖所示,一個比較大的特徵圖和一個比較小的特徵圖,它們都用來做檢測。
- 這樣做的好處是比較大的特徵圖來用來檢測相對較小的目標,而小的特徵圖負責檢測大目標。
- \(8 \times 8\) 的特徵圖可以劃分更多的單元,但是其每個單元的先驗框尺度比較小。
2) 利用折積進行檢測
與 YOLO 最後採用全連線層不同,SSD 直接採用折積對不同的特徵圖來進行提取檢測結果。
對於形狀為 \(m\times n \times p\) 的特徵圖,只需要採用 \(3\times 3 \times p\) 這樣比較小的折積核得到檢測值。
3) 設定先驗框
在 YOLO 中,每個單元預測多個邊界框,但是其都是相對這個單元本身(正方塊),但是真實目標的形狀是多變的,YOLO 需要在訓練過程中自適應目標的形狀。
SSD 借鑑了Faster R-CNN 中 anchor 的理念,每個單元設定尺度或者長寬比不同的先驗框,預測的bbox是以這些先驗框為基準的,在一定程度上減少訓練難度。

一般情況下,每個單元會設定多個先驗框,其尺度和長寬比存在差異,如圖所示,可以看到每個單元使用了 4 個不同的先驗框,圖片中貓和狗分別採用最適合它們形狀的先驗框來進行訓練,後面會詳細講解訓練過程中的先驗框匹配原則。
SSD 的檢測值也與 YOLO 不太一樣。對於每個單元的每個先驗框,其都輸出一套獨立的檢測值,對應一個邊界框,主要分為兩個部分。
- 第1部分是各個類別的置信度,值得注意的是 SSD 將背景也當做了一個特殊的類別,如果檢測目標共有 \(c\) 個類別,SSD 其實需要預測 \(c+1\) 個置信度值,第一個置信度指的是不含目標或者屬於背景的評分。在預測過程中,置信度最高的那個類別就是邊界框所屬的類別,特別地,當第一個置信度值最高時,表示邊界框中並不包含目標。
- 第2部分就是邊界框的location,包含4個值 \((cx, cy, w, h)\),分別表示邊界框的中心座標以及寬和高。然而,真實預測值其實只是邊界框相對於先驗框的轉換值。先驗框位置用 \(d=(d^{cx}, d^{cy}, d^w, d^h)\) 表示,其對應邊界框用 \(b=(b^{cx}, b^{cy}, b^w, b^h)\) 表示,那麼邊界框的預測值 \(l\) 其實是 \(b\) 相對於 \(d\) 的轉換值:
習慣上,我們稱上面這個過程為邊界框的編碼(encode),預測時,你需要反向這個過程,即進行解碼(decode),從預測值 \(l\) 中得到邊界框的真實位置 \(b\) :
2.2 SSD 網路結構
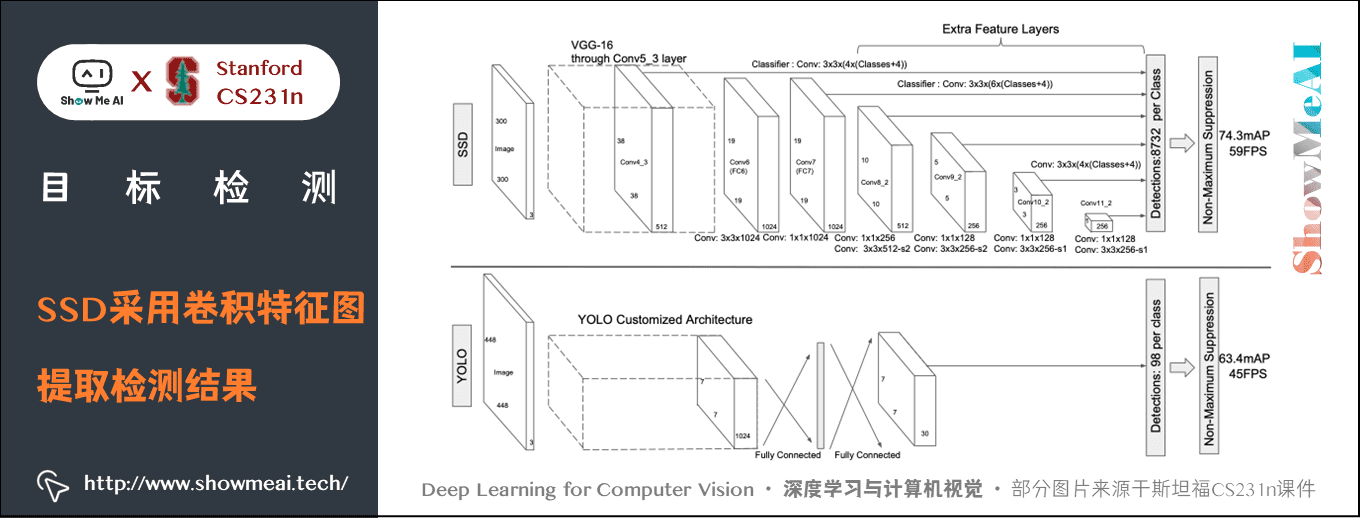
SSD 採用 VGG16 作為基礎模型,然後在 VGG16 的基礎上新增了折積層來獲得更多的特徵圖以用於檢測。SSD 的網路結構如下圖所示。
SSD 利用了多尺度的特徵圖做檢測。模型的輸入圖片大小是 \(300 \times 300\)。
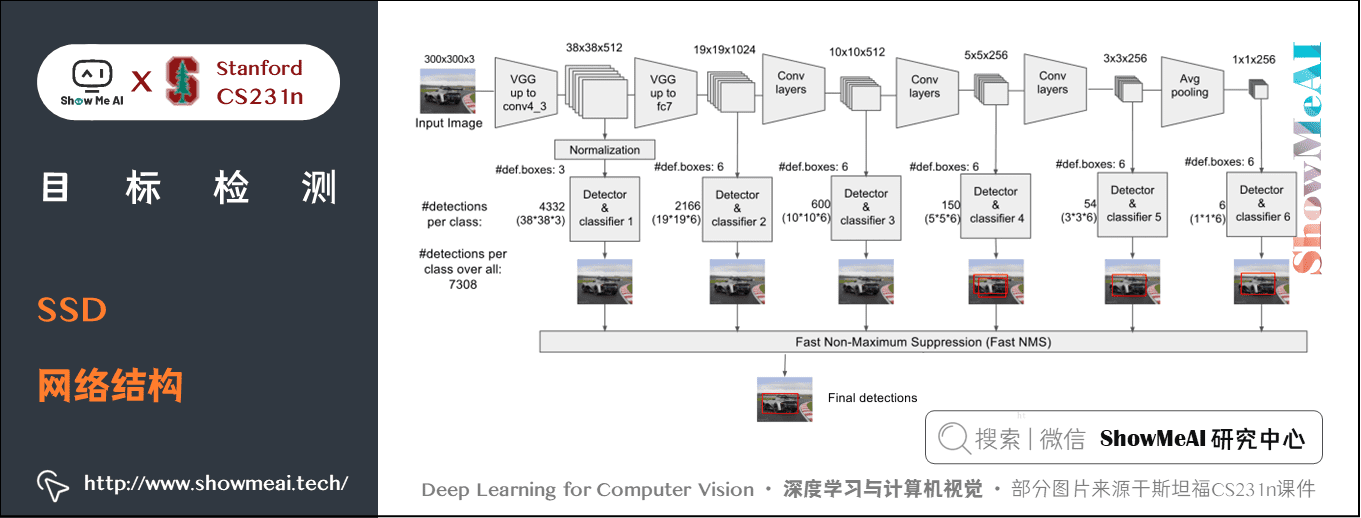
採用 VGG16 做基礎模型,首先VGG16是在 ILSVRC CLS-LOC 資料集上做預訓練。
然後,分別將 VGG16 的全連線層 fc6 和 fc7 轉換成 \(3 \times 3\) 折積層 conv6 和 \(1 \times 1\) 折積層 conv7,同時將池化層 pool5 由原來的 \(stride=2\) 的 $2\times 2 $ 變成 \(stride=1\) 的 \(3\times 3\),為了配合這種變化,採用了一種 Atrous Algorithm,就是 conv6 採用擴張折積(空洞折積),在不增加引數與模型複雜度的條件下指數級擴大了折積的視野,其使用擴張率(dilation rate)引數,來表示擴張的大小。
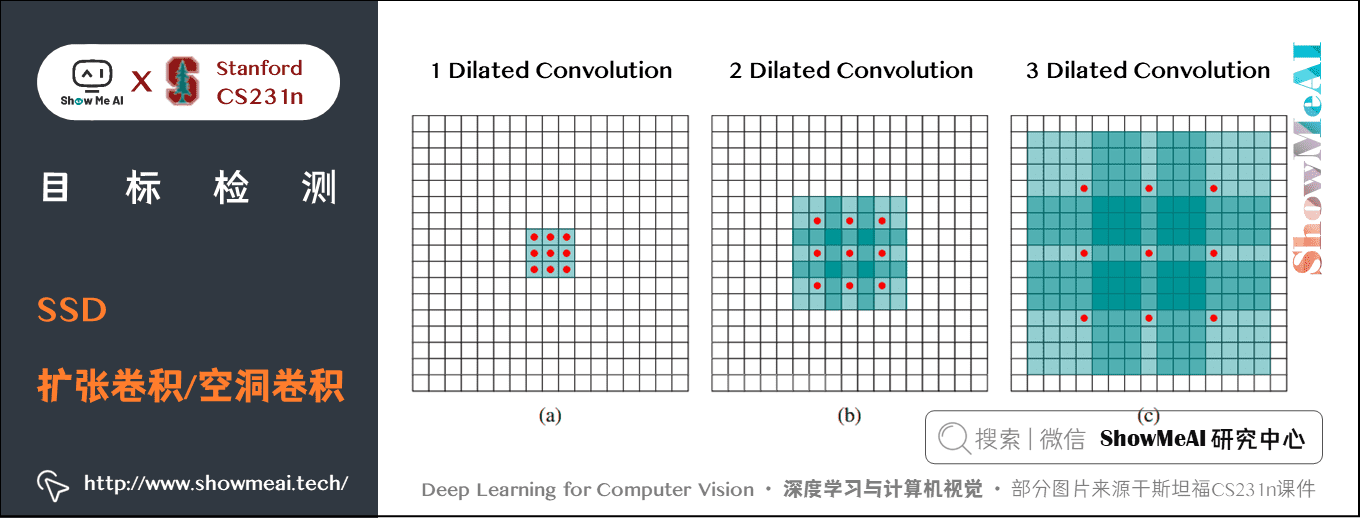
如下圖所示:
- (a)是普通的 \(3\times3\) 折積,其視野就是 \(3\times3\)
- (b)是擴張率為2,此時視野變成 \(7\times7\)
- (c)擴張率為4時,視野擴大為 \(15\times15\),但是視野的特徵更稀疏了。
Conv6 採用 \(3\times3\) 大小但 \(dilation rate=6\) 的擴充套件折積。然後移除 Dropout 層和 fc8 層,並新增一系列折積層,在檢測資料集上做 fine-tuning。
2.3 SSD 訓練與預測
在訓練過程中,首先要確定訓練圖片中的 ground truth (真實目標)與哪個先驗框來進行匹配,與之匹配的先驗框所對應的邊界框將負責預測它。
在 YOLO 中:ground truth 的中心落在哪個單元格,該單元格中與其 IoU 最大的邊界框負責預測它。
在 SSD 中:處理方式不一樣,SSD 的先驗框與 ground truth 有2個匹配原則。
- 第1原則:對於圖片中每個 ground truth,找到與其 IoU 最大的先驗框,該先驗框與其匹配,這樣,可以保證每個 ground truth 一定與某個先驗框匹配。通常稱與 ground truth 匹配的先驗框為正樣本,反之,若一個先驗框沒有與任何 ground truth 進行匹配,那麼該先驗框只能與背景匹配,就是負樣本。
- 然而,由於一個圖片中 ground truth 是非常少的,而先驗框卻很多,如果僅按上述原則匹配,很多先驗框會是負樣本,正負樣本極其不平衡,所以有下述第2原則。
- 第2原則:對於剩餘的未匹配先驗框,若某個 ground truth 的 \(\text{IoU}\) 大於某個閾值(一般是0.5),那麼該先驗框也與這個 ground truth 進行匹配。這意味著某個 ground truth 可能與多個先驗框匹配,這是可以的。但是反過來卻不可以,因為一個先驗框只能匹配一個 ground truth,如果多個 ground truth 與某個先驗框 \(\text{IoU}\) 大於閾值,那麼先驗框只與 IoU 最大的那個 ground truth 進行匹配。
第2原則一定在第1原則之後進行。
仔細考慮一下這種情況,如果某個 ground truth 所對應最大 \(\text{IoU}\) 小於閾值,並且所匹配的先驗框卻與另外一個 ground truth 的 \(\text{IoU}\) 大於閾值,那麼該先驗框應該匹配誰,答案應該是前者,首先要確保每個 ground truth 一定有一個先驗框與之匹配。
但是,這種情況存在的概率很小。由於先驗框很多,某個 ground truth 的最大 \(\text{IoU}\) 肯定大於閾值,所以可能只實施第二個原則既可以了。
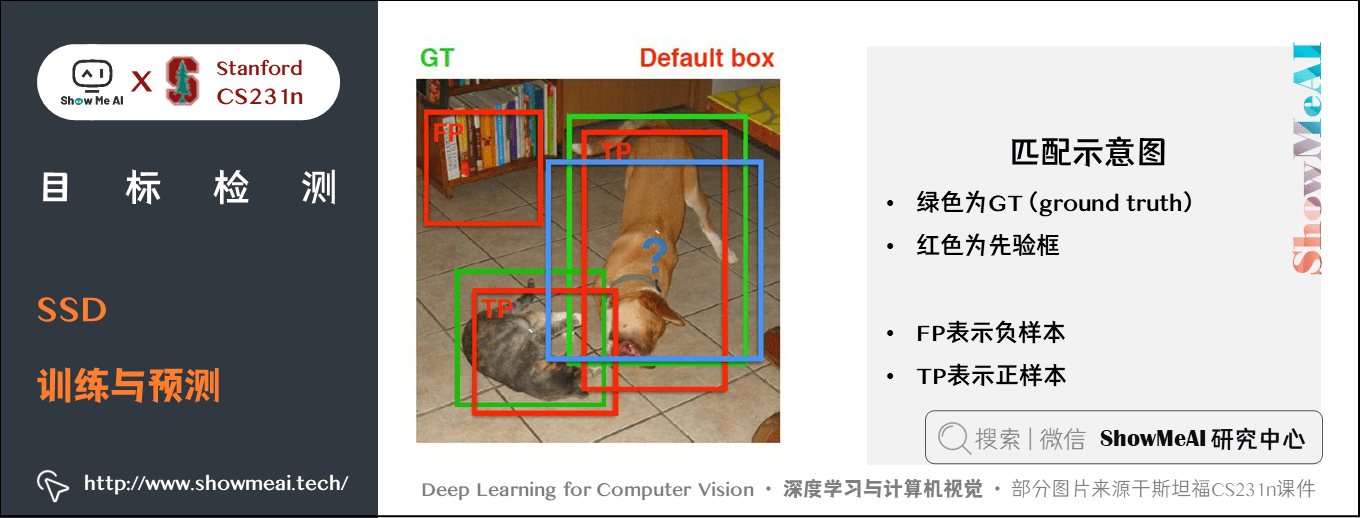
上圖為一個匹配示意圖,其中綠色的GT是 ground truth,紅色為先驗框,FP表示負樣本,TP表示正樣本。
儘管一個 ground truth 可以與多個先驗框匹配,但是 ground truth 相對先驗框還是太少了,所以負樣本相對正樣本會很多。
為了保證正負樣本儘量平衡,SSD 採用了hard negative mining演演算法,就是對負樣本進行抽樣,抽樣時按照置信度誤差(預測背景的置信度越小,誤差越大)進行降序排列,選取誤差的較大(置信度小)的 \(top-k\) 作為訓練的負樣本,以保證正負樣本比例接近 \(1:3\)。
3.YOLO V2
論文連結:https://openaccess.thecvf.com/content_cvpr_2017/papers/Redmon_YOLO9000_Better_Faster_CVPR_2017_paper.pdf
程式碼連結:https://github.com/longcw/YOLO2-pytorch
1) 演演算法簡介
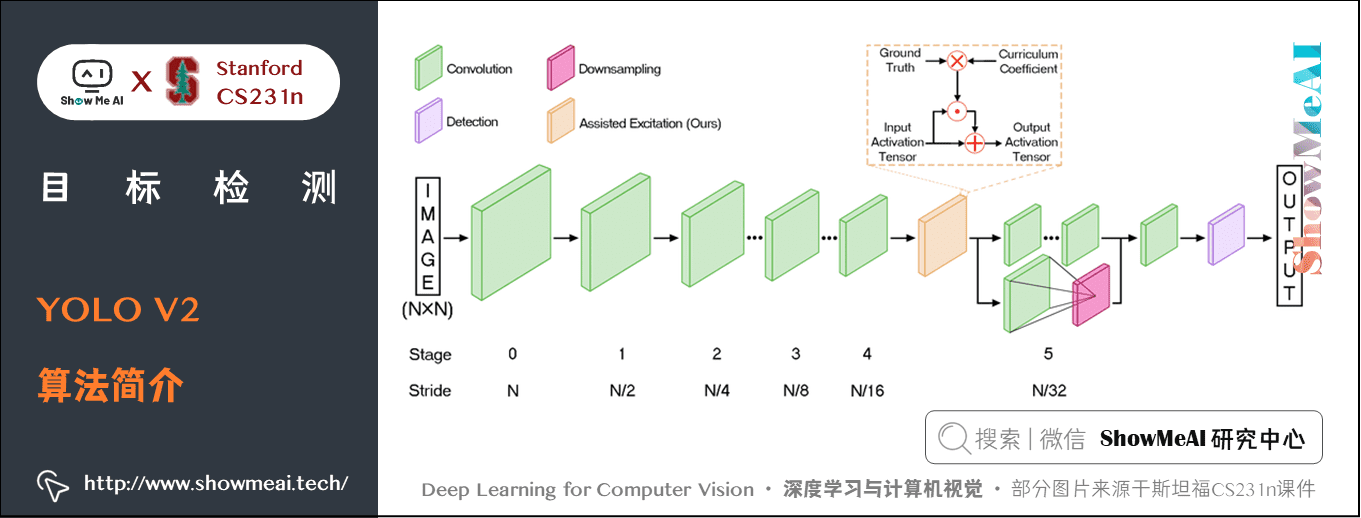
相比於 YOLO V1,YOLO V2 在精度、速度和分類數量上都有了很大的改進。YOLO V2使用DarkNet19作為特徵提取網路,該網路比 YOLO V2 所使用的 VGG-16 要更快。YOLO V2使用目標分類和檢測的聯合訓練技巧,結合Word Tree等方法,使得 YOLO V2的檢測種類擴充到了上千種,分類效果更好。
下圖展示了 YOLO V2 相比於 YOLO V1 在提高檢測精度上的改進策略。

2) 效能效果
YOLO V2 演演算法在VOC 2007 資料集上的表現為 67 FPS 時,mAP 為 76.8,在 40FPS時,mAP 為 78.6。
3) 缺點不足
YOLO V2 演演算法只有一條檢測分支,且該網路缺乏對多尺度上下文資訊的捕獲,所以對於不同尺寸的目標檢測效果依然較差,尤其是對於小目標檢測問題。
4. RetinaNet
論文連結:https://openaccess.thecvf.com/content_ICCV_2017/papers/Lin_Focal_Loss_for_ICCV_2017_paper.pdf
程式碼連結:https://github.com/yhenon/pytorch-retinanet
1) 演演算法簡介
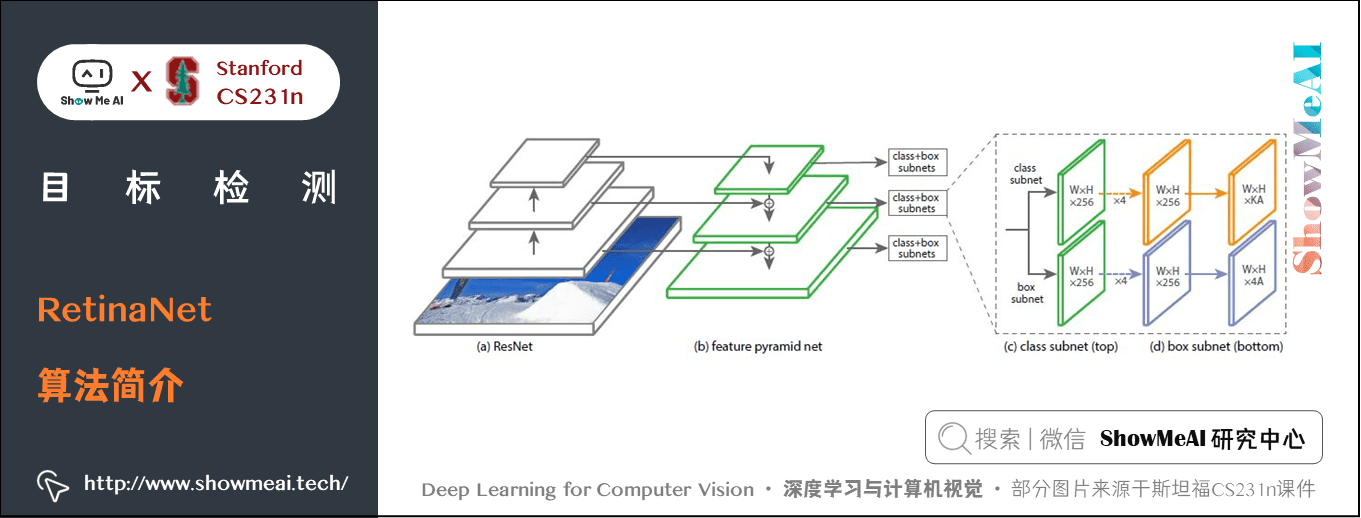
儘管一階段檢測算推理速度快,但精度上與二階段檢測演演算法相比還是不足。RetinaNet論文分析了一階段網路訓練存在的類別不平衡問題,提出能根據 Loss 大小自動調節權重的 Focal loss,代替了標準的交叉熵損失函數,使得模型的訓練更專注於困難樣本。同時,基於 FPN 設計了 RetinaNet,在精度和速度上都有不俗的表現。
2) 效能效果
RetinaNet在保持高速推理的同時,擁有與二階段檢測演演算法相媲美的精度( COCO \([email protected]=59.1\%\), \(mAP@[.5, .95]=39.1\%\))。
5.YOLO V3
論文連結:https://arxiv.org/pdf/1804.02767.pdf
程式碼連結:https://github.com/ultralytics/YOLOv3
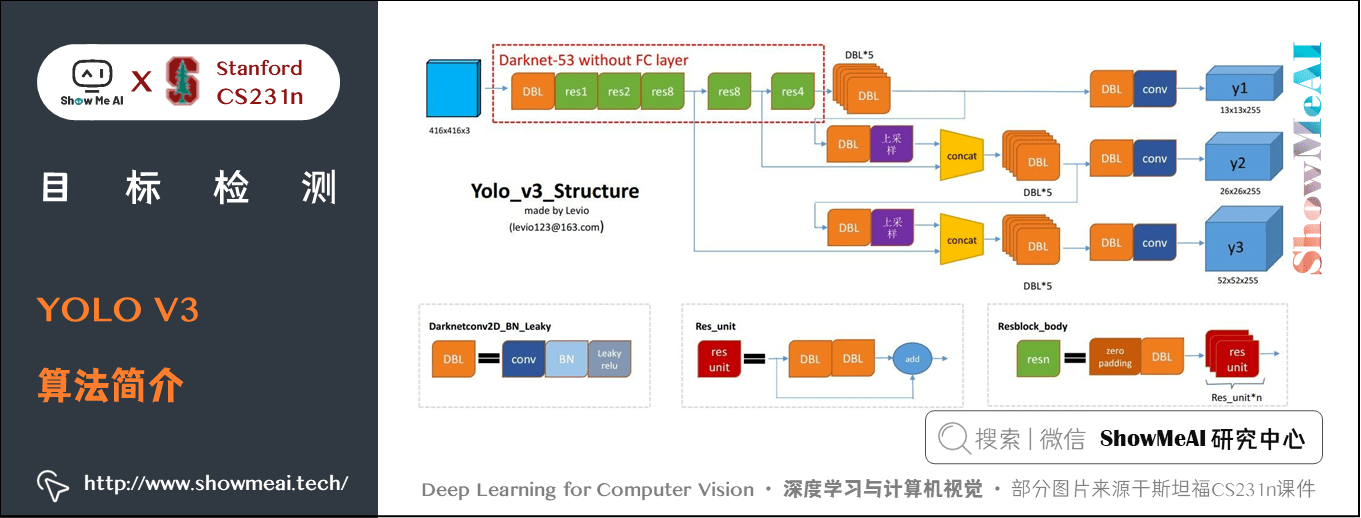
1) 演演算法簡介
相比於 YOLO V2,YOLO V3 將特徵提取網路換成了 DarkNet53,物件分類用 Logistic 取代了 Softmax,並借鑑了 FPN 思想採用三條分支(三個不同尺度/不同感受野的特徵圖)去檢測具有不同尺寸的物件。
2) 效能效果
YOLO V3 在 VOC 資料集,Titan X 上處理 \(608 \times 608\) 影象速度達到 20FPS,在 COCO 的測試資料集上 \([email protected]\) 達到 \(57.9\%\)。其精度比 SSD 高一些,比 Faster RCNN 相比略有遜色(幾乎持平),比 RetinaNet 差,但速度是 SSD 、RetinaNet 和 Faster RCNN 至少 2 倍以上,而簡化後的 YOLO V3 tiny 可以更快。
3) 缺點不足
YOLO V3採用MSE作為邊框迴歸損失函數,這使得 YOLO V3對目標的定位並不精準,之後出現的IOU,GIOU,DIOU和CIOU等一系列邊框迴歸損失大大改善了 YOLO V3對目標的定位精度。
6.YOLO V4
論文連結:https://arxiv.org/pdf/2004.10934
程式碼連結:https://github.com/Tianxiaomo/pytorch-YOLOv4
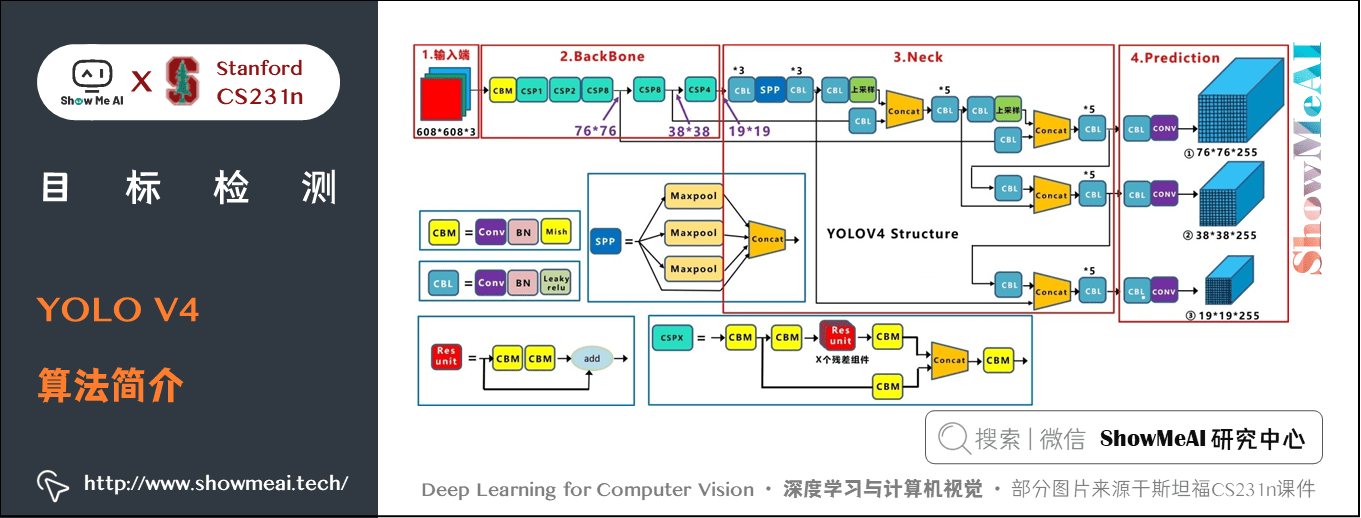
1) 演演算法簡介
相比於 YOLO V4,YOLO V4 在輸入端,引入了 Mosaic 資料增強、cmBN、SAT 自對抗訓練;在特徵提取網路上,YOLO V4 將各種新的方式結合起來,包括 CSPDarknet53,Mish啟用函數,Dropblock;在檢測頭中,引入了 SPP 模組,借鑑了 FPN+PAN 結構;在預測階段,採用了CIOU作為網路的邊界框損失函數,同時將 NMS 換成了DIOU_NMS 等等。總體來說,YOLO V4具有極大的工程意義,將近年來深度學習領域最新研究的tricks都引入到了 YOLO V4做驗證測試,在 YOLO V3的基礎上更進一大步。
2) 效能效果
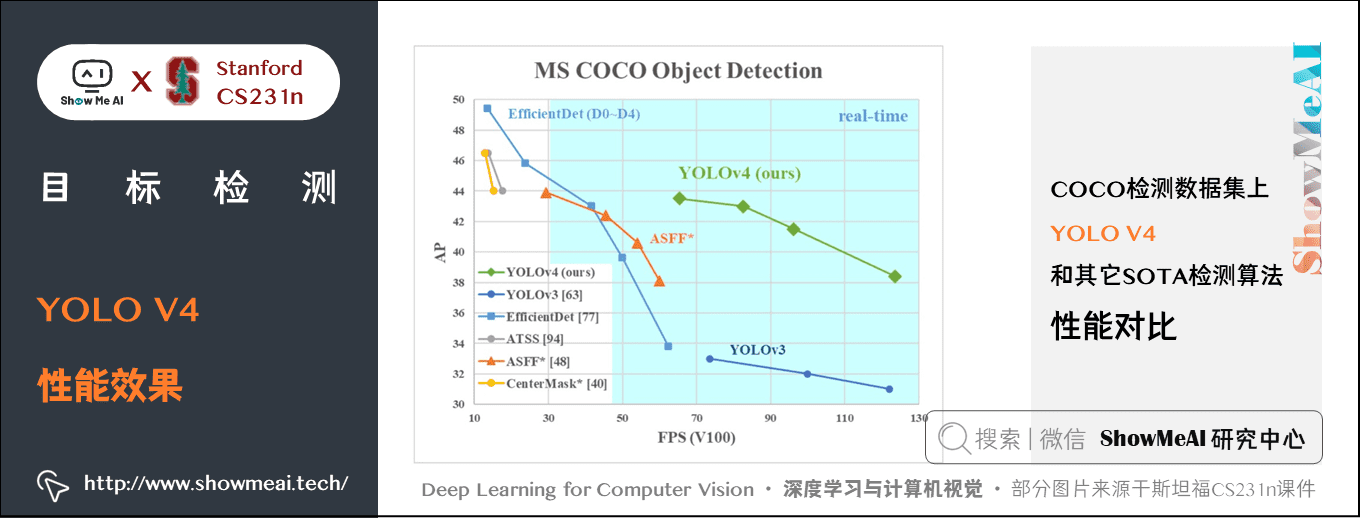
YOLO V4在 COCO 資料集上達到了\(43.5\%AP\)(\(65.7\% AP50\)),在 Tesla V100 顯示卡上實現了 65 fps 的實時效能,下圖展示了在 COCO 檢測資料集上 YOLO V4 和其它 SOTA 檢測演演算法的效能對比。
7.YOLO V5

1) 演演算法簡介
YOLO V5 與 YOLO V4 有點相似,都大量整合了計算機視覺領域的前沿技巧,從而顯著改善了 YOLO 對目標的檢測效能。相比於 YOLO V4,YOLO V5 在效能上稍微遜色,但其靈活性與速度上遠強於 YOLO V4,而且在模型的快速部署上也具有極強優勢。
2) 效能效果
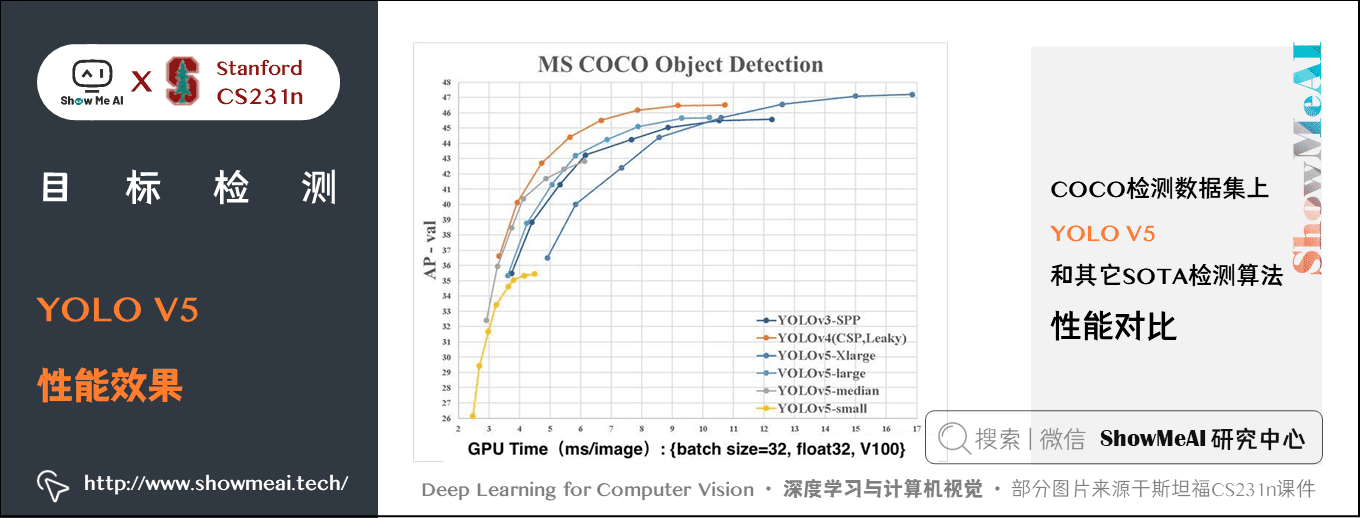
如下圖展示了在 COCO 檢測資料集上 YOLO V5 和其它 SOTA 檢測演演算法的效能對比。
8.推薦學習
可以點選 B站 檢視視訊的【雙語字幕】版本
- 【課程學習指南】斯坦福CS231n | 深度學習與計算機視覺
- 【字幕+資料下載】斯坦福CS231n | 深度學習與計算機視覺 (2017·全16講)
- 【CS231n進階課】密歇根EECS498 | 深度學習與計算機視覺
- 【深度學習教學】吳恩達專項課程 · 全套筆記解讀
- 【Stanford官網】CS231n: Deep Learning for Computer Vision
斯坦福 CS231n 全套解讀
- 深度學習與CV教學(1) | CV引言與基礎
- 深度學習與CV教學(2) | 影象分類與機器學習基礎
- 深度學習與CV教學(3) | 損失函數與最佳化
- 深度學習與CV教學(4) | 神經網路與反向傳播
- 深度學習與CV教學(5) | 折積神經網路
- 深度學習與CV教學(6) | 神經網路訓練技巧 (上)
- 深度學習與CV教學(7) | 神經網路訓練技巧 (下)
- 深度學習與CV教學(8) | 常見深度學習框架介紹
- 深度學習與CV教學(9) | 典型CNN架構 (Alexnet, VGG, Googlenet, Restnet等)
- 深度學習與CV教學(10) | 輕量化CNN架構 (SqueezeNet, ShuffleNet, MobileNet等)
- 深度學習與CV教學(11) | 迴圈神經網路及視覺應用
- 深度學習與CV教學(12) | 目標檢測 (兩階段, R-CNN系列)
- 深度學習與CV教學(13) | 目標檢測 (SSD, YOLO系列)
- 深度學習與CV教學(14) | 影象分割 (FCN, SegNet, U-Net, PSPNet, DeepLab, RefineNet)
- 深度學習與CV教學(15) | 視覺模型視覺化與可解釋性
- 深度學習與CV教學(16) | 生成模型 (PixelRNN, PixelCNN, VAE, GAN)
- 深度學習與CV教學(17) | 深度強化學習 (馬爾可夫決策過程, Q-Learning, DQN)
- 深度學習與CV教學(18) | 深度強化學習 (梯度策略, Actor-Critic, DDPG, A3C)
ShowMeAI 系列教學推薦
- 大廠技術實現:推薦與廣告計算解決方案
- 大廠技術實現:計算機視覺解決方案
- 大廠技術實現:自然語言處理行業解決方案
- 圖解Python程式設計:從入門到精通系列教學
- 圖解資料分析:從入門到精通系列教學
- 圖解AI數學基礎:從入門到精通系列教學
- 圖解巨量資料技術:從入門到精通系列教學
- 圖解機器學習演演算法:從入門到精通系列教學
- 機器學習實戰:手把手教你玩轉機器學習系列
- 深度學習教學:吳恩達專項課程 · 全套筆記解讀
- 自然語言處理教學:斯坦福CS224n課程 · 課程帶學與全套筆記解讀
- 深度學習與計算機視覺教學:斯坦福CS231n · 全套筆記解讀
