蘇濤:對抗樣本技術在網際網路安全領域的應用

導讀: 驗證碼作為網路安全的第一道屏障,其重要程度不言而喻。當前,折積神經網路的高速發展使得許多驗證碼的安全性大大降低,一些新型驗證碼甚至選擇犧牲可用性從而保證安全性。針對對抗樣本技術的研究,給驗證碼領域帶來了新的契機,並已應用於驗證碼反識別當中,為這場曠日持久攻防對抗注入了新的活力。
分享內容包括三大方面:
- 對抗樣本介紹
- 極驗對抗樣本技術探索與應用
- 後續的工作與思考
--
01 對抗樣本介紹
1. 什麼是對抗樣本

對抗樣本 ( Adversarial Examples ) 的概念最早是 Christian Szegedy(克里斯蒂安·塞格迪)在 ICLR2014 (國際學習表徵會議)上提出來的,即在資料集中通過故意新增細微的非隨機的干擾所形成輸入樣本,受干擾之後的輸入導致模型以高置信度給出了一個錯誤的輸出。
如上圖(左)原始影象以57%的置信度判斷為「熊貓」,但是加入了微小的干擾之後,在人眼完全看不出差別的情況下,模型卻以99%的置信度輸出「長臂猿」。
當然,對抗樣本不僅僅會出現在圖片上,語音、文字上也會出現對抗樣本,一段語音上加入微不可察的背景音,可以讓語音識別模型輸出錯誤的語音內容;在一段文字上使用近義詞替換,也可以構造出對抗樣本,誤導語言模型。
那麼為什麼深度神經網路會出現對抗樣本呢?
目前獲得普遍認可的15年古德菲洛的觀點,是深度神經網路的高維線性性導致了對抗樣本的出現。
直觀的理解,在進行一個高維度的線性運算時,每個維度都做一些微小的改動,會使輸出結果發生巨大的變化。如上圖,原始的輸入是x,線性運算的權重是w,此時將樣本分類到類別1的概率是5%,但是我們將輸入的每一個維度都改變0.5,此時將樣本分類到類別1的概率就變成了88%。
以上是對抗樣本的一些簡單的定義和目前比較被廣泛認可的原因。
2. 為什麼需要對抗樣本
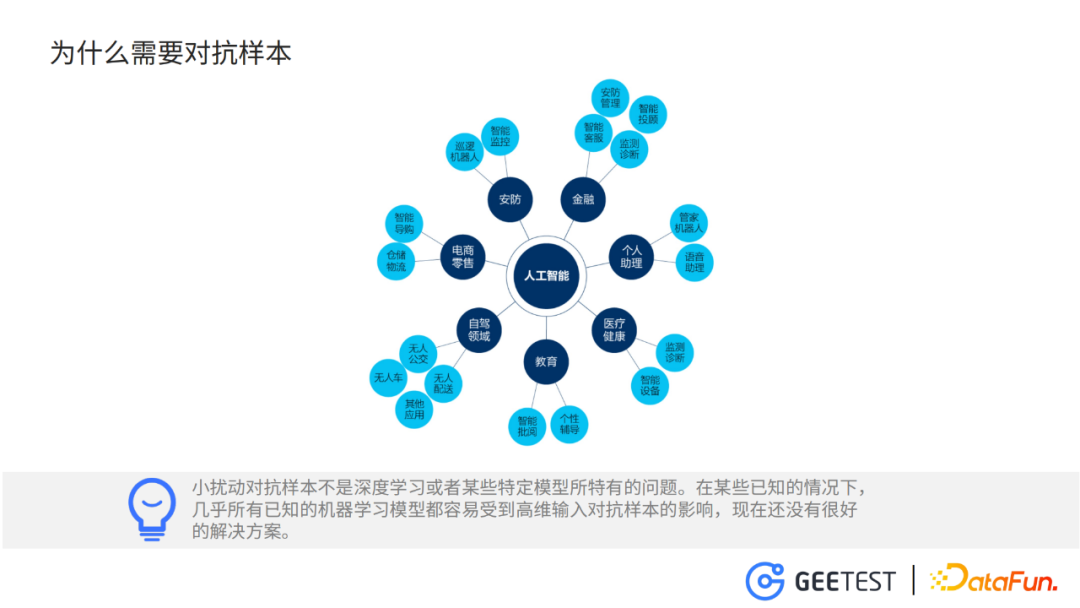
自從2012年AlexNet誕生以來,深度神經網路迎來了一段爆發式發展,並且廣泛地應用於自動駕駛、醫療、金融、安防等領域。可以說深度神經網路模型已經深入我們生活的方方面面。對抗樣本對這些模型的威脅是一個客觀存在的事實,如果將STOP交通指示牌上加上一些微小的擾動,就會被檢測模型識別為減速。行人穿上帶有訓練好的馬賽克圖案的衣服,就能在智慧監控模型的視線中「隱身」。
所以,我們大力研究對抗樣本技術,一方面是利用對抗樣本探索深度神經網路的安全性,另一個方面利用對抗樣本防禦AI濫用的情況,如自動化驗證碼的識別,臉部辨識模型的濫用,自動化魚叉式的釣魚攻擊。
3. 對抗樣本發展史和研究態勢
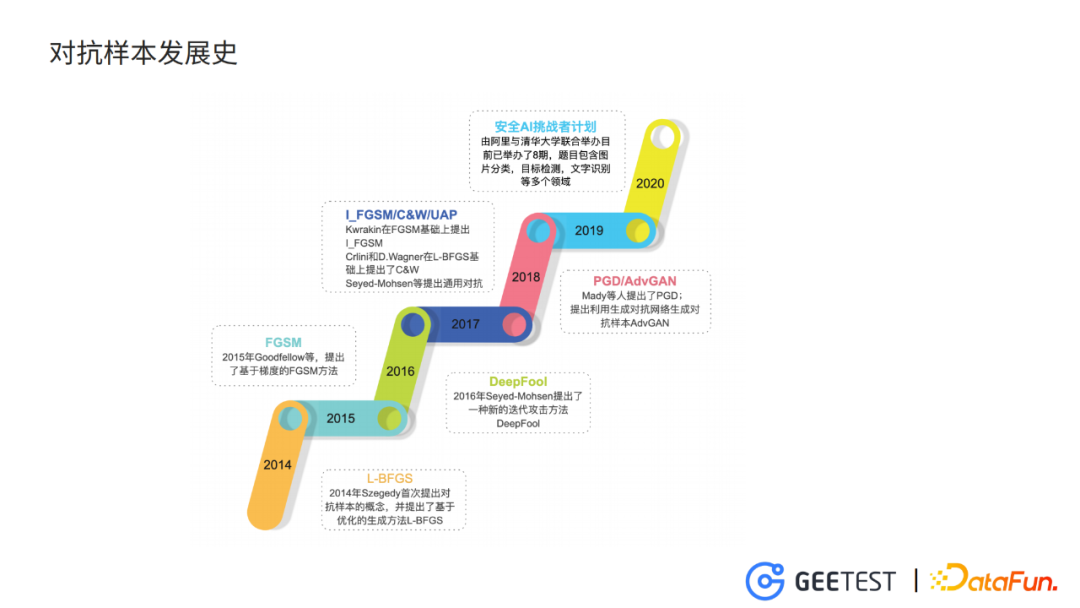
Szegedy在2014年的表徵學習國際會議上提出對抗樣本的概念,他認為這是高維非線性導致的,並且提出了基於優化方法的L-BFGS方法。第二年Goodfellow等人,證明了對抗樣本的出現是高維線性的結果,並提出了基於梯度的快速梯度符號法。之後,各種以FGSM為基礎的對抗樣本生成方法紛紛出現,其中比較有代表性的是I_FGSM,它在FGSM基礎上進行多次迭代。
在L-BFGS基礎上提出的C&W,這個奇怪的名字是兩位作者名字的首字母 。
2018年肖超偉提出的advGAN,輸入原始clean圖片,使用生成對抗網路來生成對抗圖片。
隨後各種基於梯度迭代的攻擊方法,基於優化的攻擊方法和基於GAN的方法逐漸豐富起來。並且,對抗樣本在計算機視覺、nlp、語音識別等各個領域的應用也逐漸被挖掘出來。
在dblp搜尋adversarial example可以發現,從14年以來,對抗樣本相關的論文也日益增長,對抗樣本儼然成為了一大熱門的研究領域。
--
02 極驗對抗樣本技術探索與應用
上面我們已經對對抗樣本技術有了一個些初步的瞭解,下面我們來介紹一下我們極驗在對抗樣本技術上的探索與對抗樣本技術在驗證碼上的應用。
1. 驗證碼的破解方法
極驗從2012年就開發了拼圖驗證碼,隨後又上線了九宮格驗證碼和文字點選驗證碼。我們也研究了各種市面上的驗證碼的破解方法。
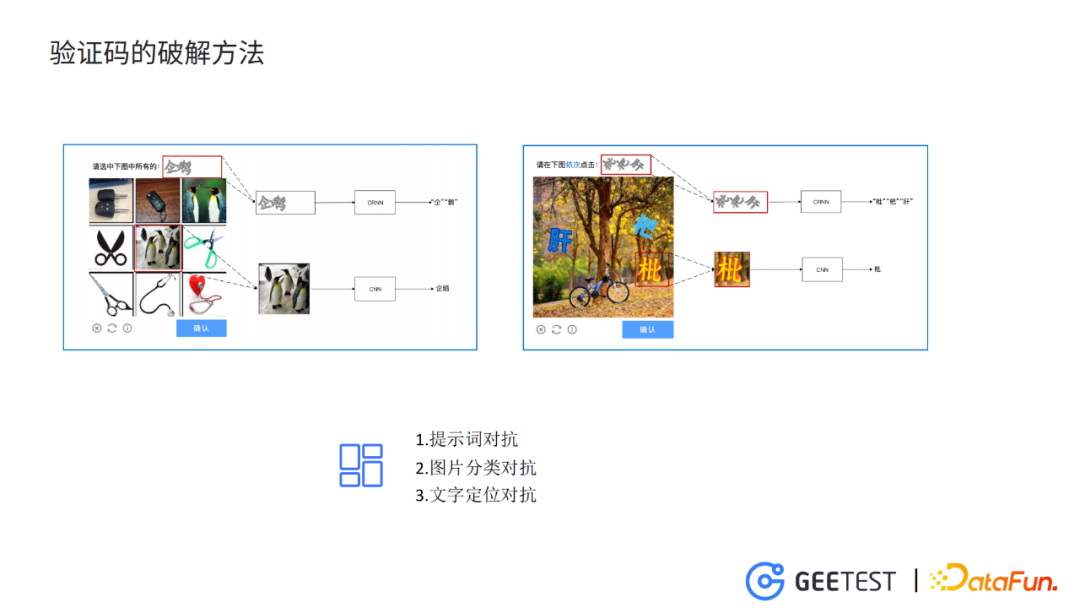
圖片中分別是極驗的九宮格驗證碼和文字點選驗證碼。
對於九宮格驗證碼,我們的破解方式和破解流程如下:從驗證碼上摳出上面的提示詞,進入CRNN網路,輸出這個提示詞的內容。然後分別摳出9個小圖片,進入CNN,預測出每個圖片的類別。結合給出的提示詞的內容和每個小圖片的類別,得到最後的答案。
對於文字點選驗證碼的破解,同樣是摳出提示詞,進入到CRNN。但是對於文字位置的識別,我們需要用到一個目標檢測的模型來檢測出文字的位置,然後再根據位置將圖片中的每個字摳出來,之後的流程與九宮格驗證碼的破解方式相同。
洞悉了主流的九宮格驗證碼和文字點選驗證碼的破解方式,我們就可以針對模型識別的每一個環節來生成對抗樣本。例如針對提示詞的對抗,針對圖片分類的對抗,針對目標檢測定位文字位置的對抗。
2. 幾何感知對抗樣本生成框架
- 黑點表示clean樣本
- 兩條虛線f,h分別是訓練模型和驗證模型,實線g測試模型
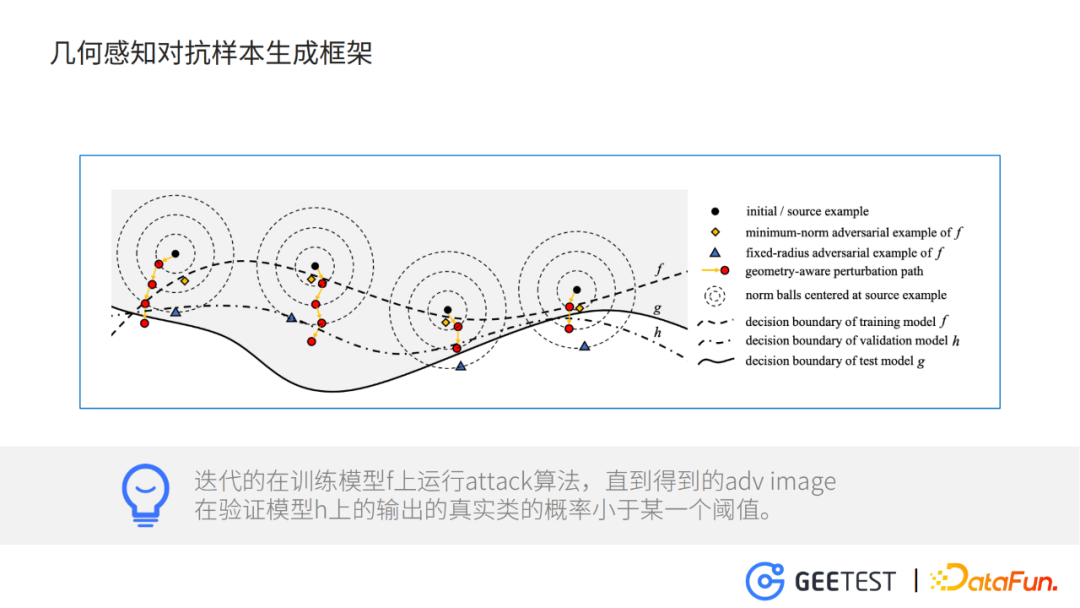
整個框架做的事情就是,迭代的在模型f上執行attack演演算法,直到得到的adv image在驗證模型h上的輸出正確類別的概率小於某一個閾值,並且在迭代的過程中逐步放開對抗干擾的L-p範數的限制。
為什麼要把模型分成訓練模型、驗證模型和測試模型?主要是為了提升對抗樣本的轉移率,也就是說,在模型A上訓練得到的對抗樣本,在模型B上也能有很好的效果。這方面可以類比為提升一個模型在沒有見過的資料集上的泛化性。
比如,黃色菱形表示f的最優對抗樣本,如果不用驗證模型h做一下約束,只利用訓練模型f生成對抗樣本,那麼很可能迭代到這個位置就停止了,這樣對抗樣本在訓練模型f上,過擬合了。
至於為什麼要逐步放開對抗干擾的約束限制,主要是為了保證在達到對抗效果的情況下,能夠使對抗圖片相對於原始圖片,看起來差不多。
比如,對於一張圖片,先設定干擾的約束值為6,如果更新幾次後就能夠達到攻擊的效果,那麼迭代停止;如果多次更新仍然不能達到攻擊效果,那麼再增大約束值到10,繼續更新。
上圖中最右邊的樣本,經過2次增大約束值,就達到了攻擊的效果,最左邊的樣本,經過了4次,才達到效果。
3. 具體的攻擊方法
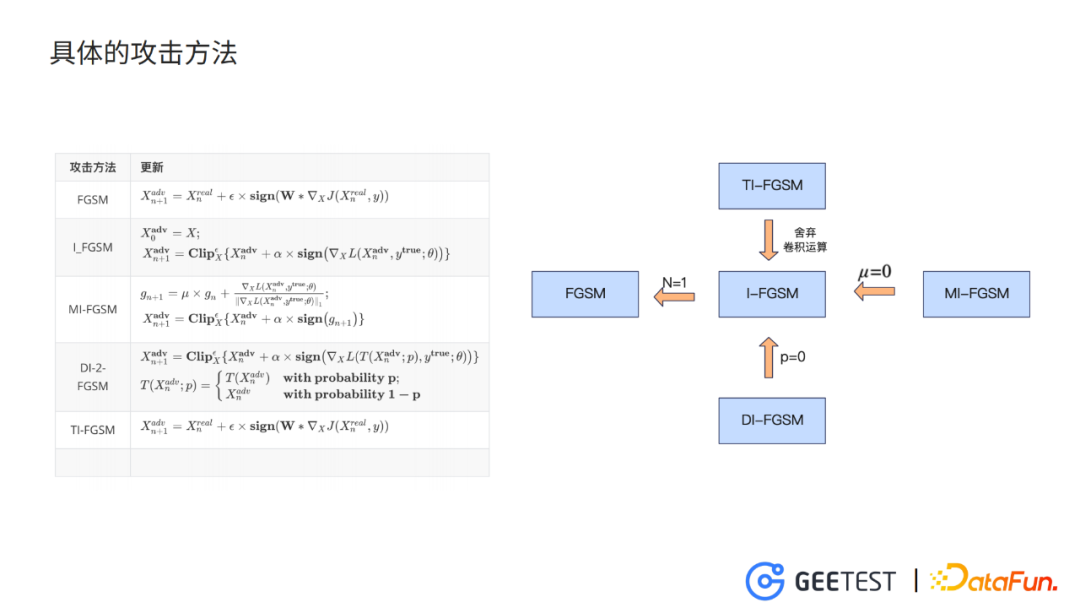
內部的攻擊方法比較簡單,用的是FGSM和它的一些增加了技巧的變體,主要是為了提升對抗樣本的對抗性和轉移力。
FGSM,是最速梯度符號法,演演算法的思想很簡單:
- 訓練模型時增大loss函數,需要計算loss函數對干擾噪聲的梯度,此時我們在梯度的正方向上更新引數,就能夠使loss函數增大。
- FGSM只進行一次引數的更新,I-FGSM迭代多次。
- MI-FGSM引入動量m,保留短期梯度的歷史資訊,提升穩定性。
- DI-FGSM以一定的概率p,對輸入進行多樣化處理,可以理解成一個小的data augmentaion。
- TI-FGSM利用一個事先定義好的kernel,對擾動引數的梯度進行折積平滑,同樣是為了提升對抗轉移率。
以上就是我們的整個架構內部攻擊的一些方法。
4. 對抗樣本初步效果
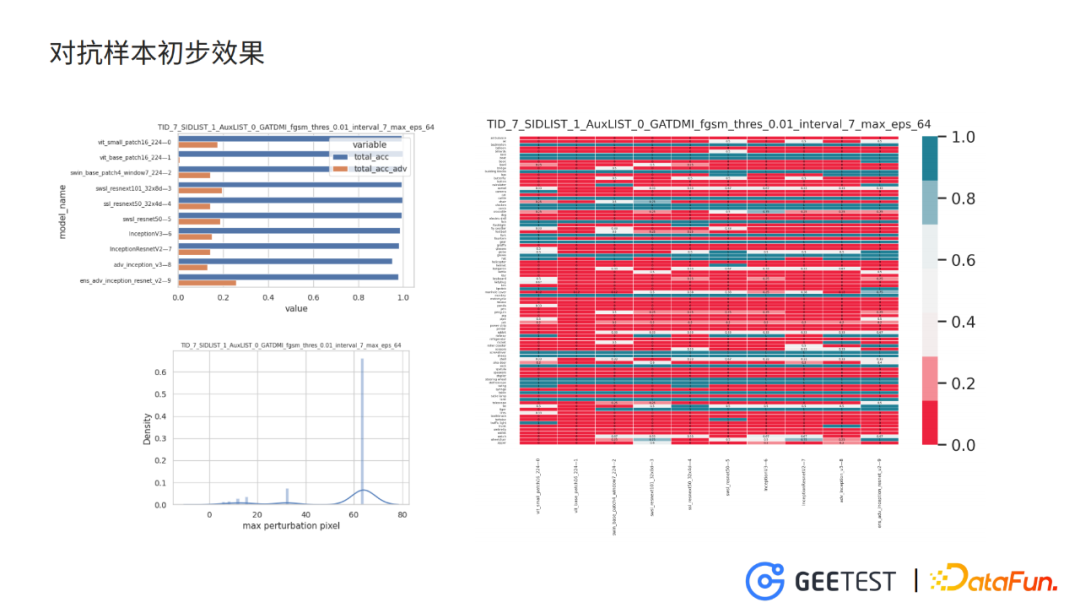
這裡我們利用在imagenet預訓練的引數,微調出10個識別九宮格驗證碼的模型,這10個模型有不同的結構——有vision transformer、resnet、inception作為基礎block的深度神經網路。這些模型在乾淨樣本上的分類準確度均達到了98%以上。
以 model7作為攻擊目標,model1作為訓練模型,model0作為驗證模型,允許的最大幹擾畫素值為64(這個引數會影響生成的對抗樣本圖片的質量),並且對抗樣本在驗證模型上對正確類別上的置信度小於0.01。
實驗結論 :
如上圖(左上)條形圖是各個模型分別在乾淨樣本和在對抗樣本上的分類準確度,從實驗的結果來看,僅僅在單個模型上訓練的對抗干擾,就能將其他沒見過的模型的分類準確度下降到20%以下。
如上圖(右)熱圖,反應每個類別、各個模型在對抗樣本上的分類準確率。對抗樣本在各個類別的圖片上對抗效果都比較理想。
如上圖(左下)最大擾動畫素值的分佈圖,大部分的對抗圖片的最大擾動畫素值是64,可以預見這批對抗圖片與原始圖片的差異較大。

如圖,上圖是對抗圖片生成的驗證碼,下圖是乾淨圖片生成的驗證碼;可以看出對抗圖片較為模糊,與原圖差距非常大,部分圖片僅僅只能通過物品的輪廓勉強分辨圖片的內容(如椅子、水壺、斧頭等),有的圖片甚至完全無法辨認(如右一的火箭)。
這是我們初步實驗的結果。模型的對抗性和可用性可能需要經過一系列的權衡,最終達到一個均衡的效果。
5. 權衡圖片質量與對抗效果
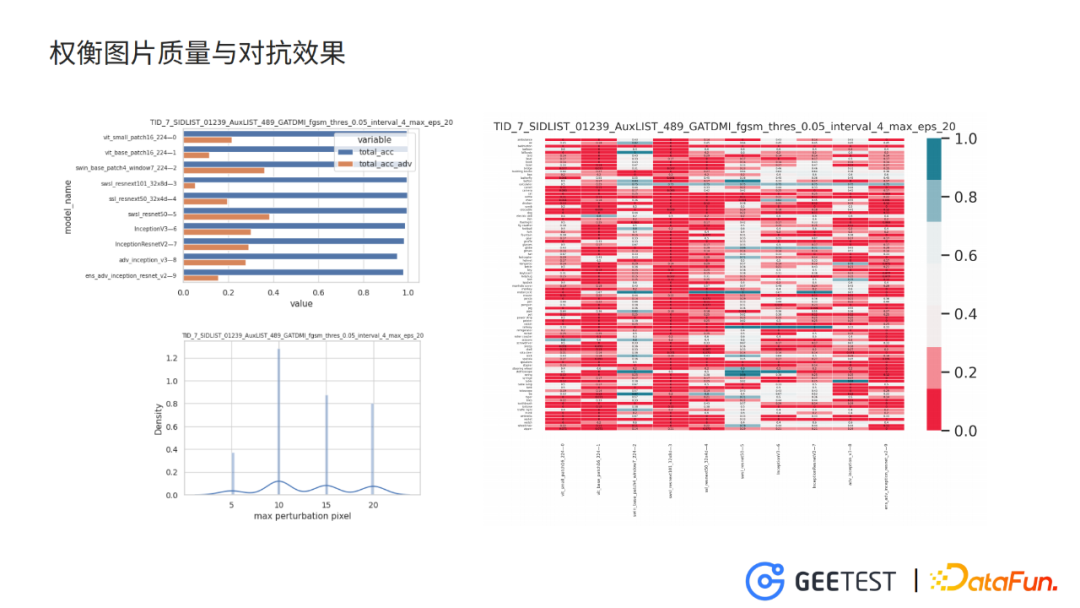
設定最大幹擾畫素值為64,驗證模型置信度閾值0.01時,訓練得到的對抗樣本圖片干擾太過嚴重,使得圖片雪花點比較多、比較模糊,圖片可用性小。
逐漸減少最大幹擾畫素,增大驗證模型置信度閾值,同時將訓練模型和驗證模型設定為多個模型的Ensemble,這樣使對抗樣本在不損失太多對抗性的情況下,提升圖片質量。
以 model7作為攻擊目標,model 01239作為訓練模型,model 489作為驗證模型,允許的最大幹擾畫素值為20,並且對抗樣本在驗證模型上對正確類別上的置信度小於0.05。
對抗圖片在目標模型上的分類準確度在30%左右,同時在其他沒見過的模型上的準確度也在30%-40%,對抗效果與之前的訓練設定相比存在下降。
但是,分析最大幹擾畫素的分佈,大部分圖片在畫素閾值增大到10之後就達到對抗效果,並停止了迭代。此時對抗圖片的圖片質量能夠保證可用性。

圖片中雖然還是存在少量比較模糊的圖片,比如右上角聽診器,但是大部分圖片跟原始圖片相差不是很大。在真正使用的時候,我們可以用評估圖片質量的演演算法將這些比較模糊的圖片剔除掉。
6. 語序識別的對抗初探
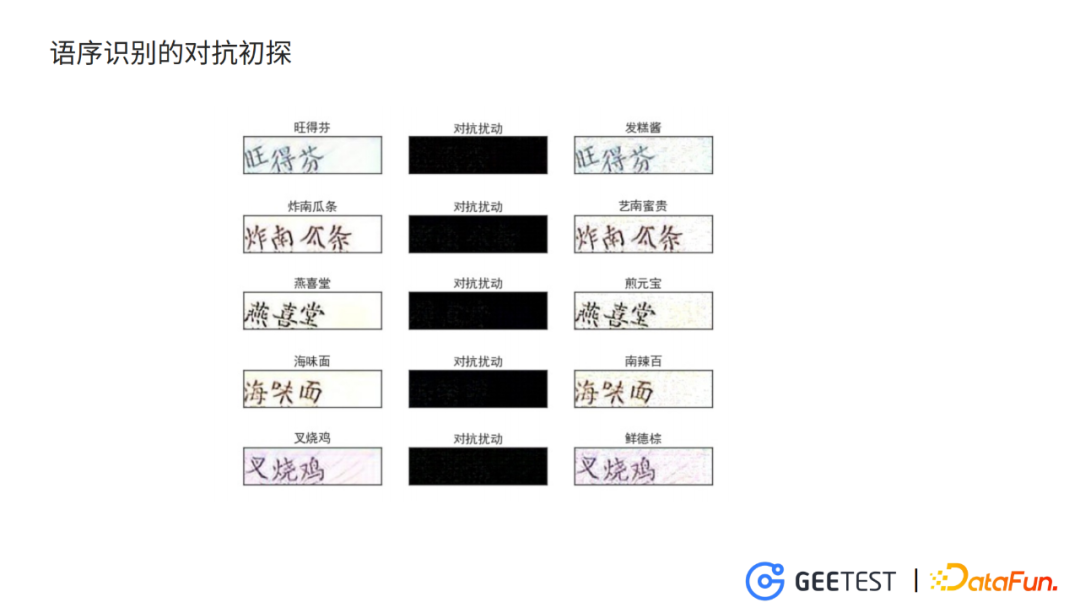
除了對九宮格驗證碼的破解模型生成了防禦性質的對抗樣本,在針對語序識別的crnn和針對文字位置識別的目標檢測模型的對抗做了初步的探索。
同樣是用I_FGSM攻擊方法,迭代使crnn模型的ctc loss不斷增大,生成的對抗樣本在訓練crnn模型上輸出錯誤的結果,如「炸南瓜條」 被識別為「藝南蜜貴」,「燕喜堂」被識別為「煎元寶」。但是肉眼看上去,對抗樣本與原始的乾淨樣本差別不大。
7. 目標識別的對抗

目標檢測對抗樣本,我們嘗試了針對yolov3的攻擊,初始化干擾,加到原始圖片上進入yolov3檢測模型,迭代更新干擾,最小化真實文字位置的預測置信度。
攻擊的結果,如上圖yolov3對文字點選驗證碼中的文字無法完全定位,而且肉眼也幾乎無法分辨對抗樣本與乾淨樣本的差別。
8. 九宮格對抗樣本的工程化
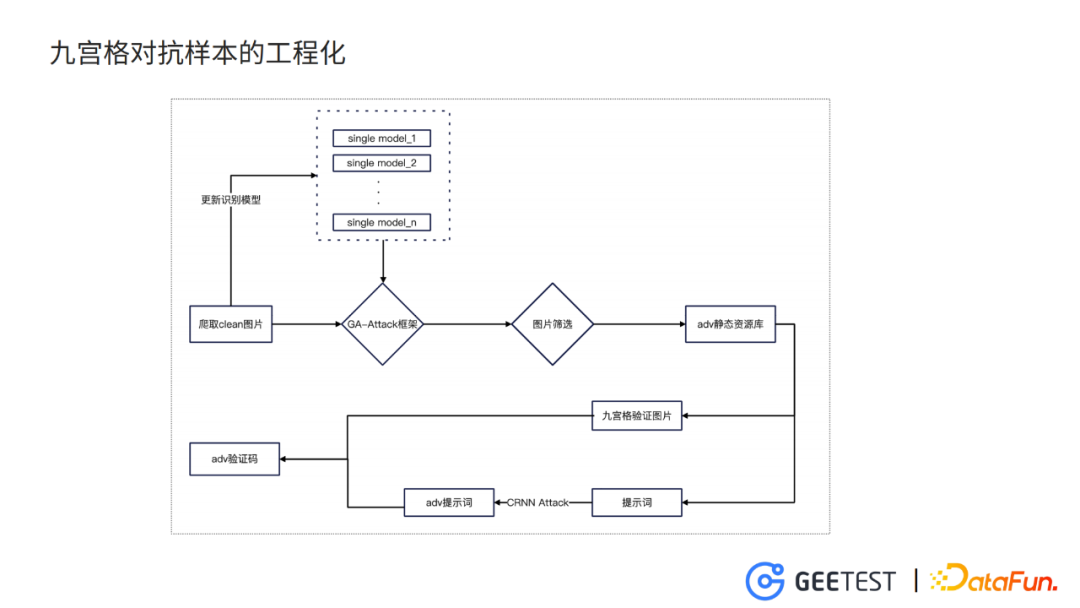
我們先爬取各種需要類別的圖,然後更新模型庫的每一個模型,進入剛才提到的幾何感知的框架,訓練得到對抗樣本的圖片,再經過一輪圖片的篩選,就得到一個靜態資源庫。
而生成九宮格驗證碼的時候,從靜態資源庫裡提取圖片,生成九宮格驗證碼的圖片,再生成乾淨的提示詞,之後利用CRNN的攻擊,生成對抗的提示詞,組合得到最終的九宮格驗證碼的對抗樣本。
--
03 後續的工作與思考
以上是我們目前做的關於對抗樣本在驗證碼領域應用的一些工作和探索,對後續的工作我們也有一些規劃和思考。
1. 基於GAN的生成技術AdvGAN
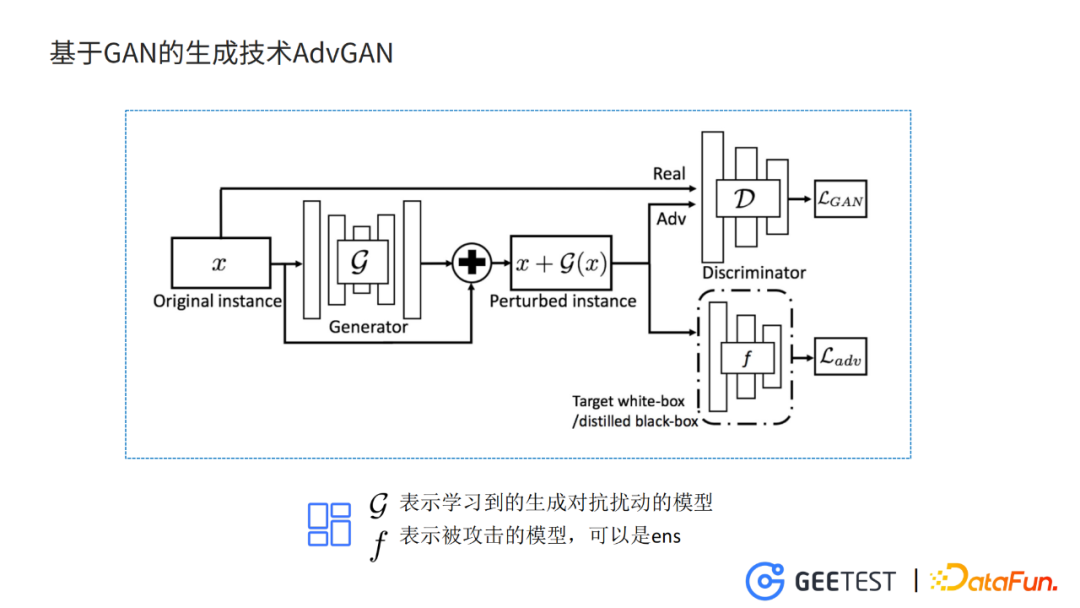
之前我們使用FGSM這個比較簡單的方法來生成對抗樣本,生成的過程和模型訓練的過程是沒有辦法分開的,這樣沒有辦法把模型的框架完整移植到針對目標檢測和針對提示詞的攻擊上。我們想到換一個框架,用基於GAN的生成技術,比如AdvGAN。
基於GAN的對抗樣本生成方式,好處是直接在G模型訓練的過程中,將對抗干擾的特徵儲存在G模型的引數中,實現模型的訓練和對抗樣本生成的過程解耦。對抗樣本的生成過程,不再需要迭代或者優化,提升生成的效率,也減小了部署的成本。
今天的分享就到這裡,謝謝大家。
本文首發於微信公眾號「DataFunTalk」。