為什麼 SQL 語句使用了索引,但卻還是慢查詢?
一、索引與慢查詢
聊一聊索引和慢查詢,經常遇到的一個問題:一個SQL語句使用了索引,為什麼還是會記錄到慢查詢紀錄檔之中?
為了說明,建立一個表t,該表3個欄位,一個主鍵索引,一個普通索引
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `a` (`a`)
) ENGINE=InnoDB;
insert into t values (1, 1, 1), (2, 2, 2);
首先MySQL判斷一個語句是不是慢查詢語句,用的是語句執行時間,它把語句執行時間跟long_query_time這個系統引數做比較,如果語句執行時間比long_query_time還大,就會把這個語句記錄到慢查詢紀錄檔裡。
long_query_time這個引數它的預設值是10s,在生產上我們不會設定這麼大的值,一般會設定1s,對於一些對延遲比較敏感的業務,會設定一個比1還小的值,而對於語句是否使用了索引,它的意思是語句執行過程中有沒有用到表的索引。
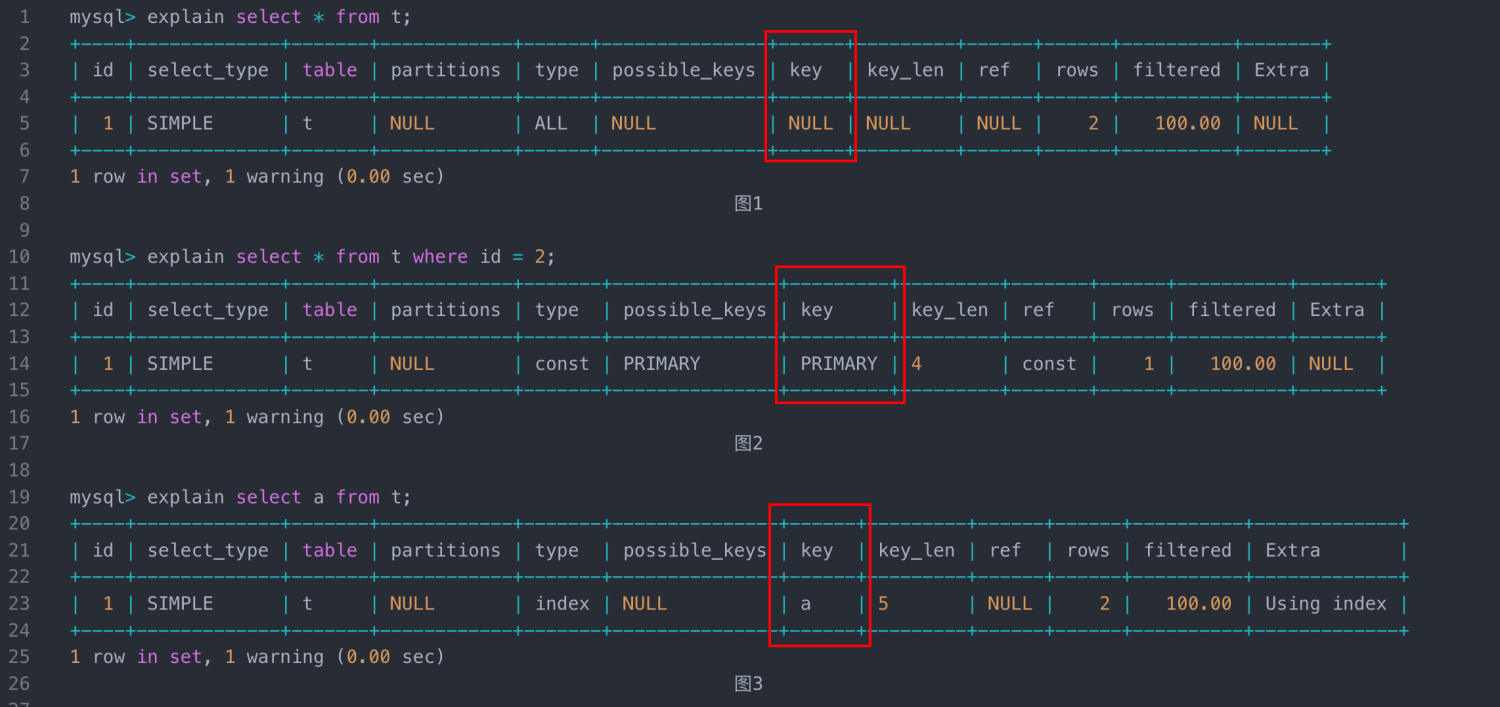
具體到表象中是explain一個語句的時候,輸出結果裡面key的值不是NULL,圖1就是執行 explain select * from t; 的結果。可以看到key這一列顯示的是NULL。圖2就是執行explain select * from t where id = 2的結果,這裡key顯示的是PRIMARY,就是我們常說的使用了主鍵索引。圖3就是執行select a from t 的結果,這裡key這一列顯示的是a,表示使用了a這個索引。可以看到圖2和圖3的結果裡key的欄位都不是NULL,而實際上圖3是掃描了整個索引樹a。
這個範例的表裡面只有兩行,那如果有100萬行呢,有100萬行的時候圖2的語句還是可以執行很快,但是圖3就肯定慢了,如果是更極端的情況,比如如果這個資料庫上CPU壓力非常地高,那可能第二個語句的執行時間也會超過long_query_time,會記錄到慢查詢紀錄檔裡面,所以如果簡單地回答這個問題,是否使用索引只是表示了一個SQL語句的執行過程,而是否記錄到慢查詢紀錄檔中是由它的執行時間決定的,而這個執行時間可能會受各種外部因素的影響,也就是說是否使用索引和是否記錄慢查詢之間沒有必然的聯絡。
二、索引的過濾性
如果我們再深層次的看這個問題其實它還潛藏著一個問題需要澄清就是,什麼叫做使用了索引。我們知道InnoDB是索引組織表,所有的資料都是儲存在索引樹上面的,比如表t,這個表它包含了兩個索引,一個主鍵索引一個普通索引a,在InnoDB裡資料是放在主鍵索引裡的。我們來看一下這個表的資料示意圖,可以看到資料都放在主鍵索引上,如果從邏輯上說,所有的在InnoDB表上的查詢,都至少用了一個索引,現在有一個問題:如果執行explain select * from t where id > 0; 這個語句有用上索引嗎?
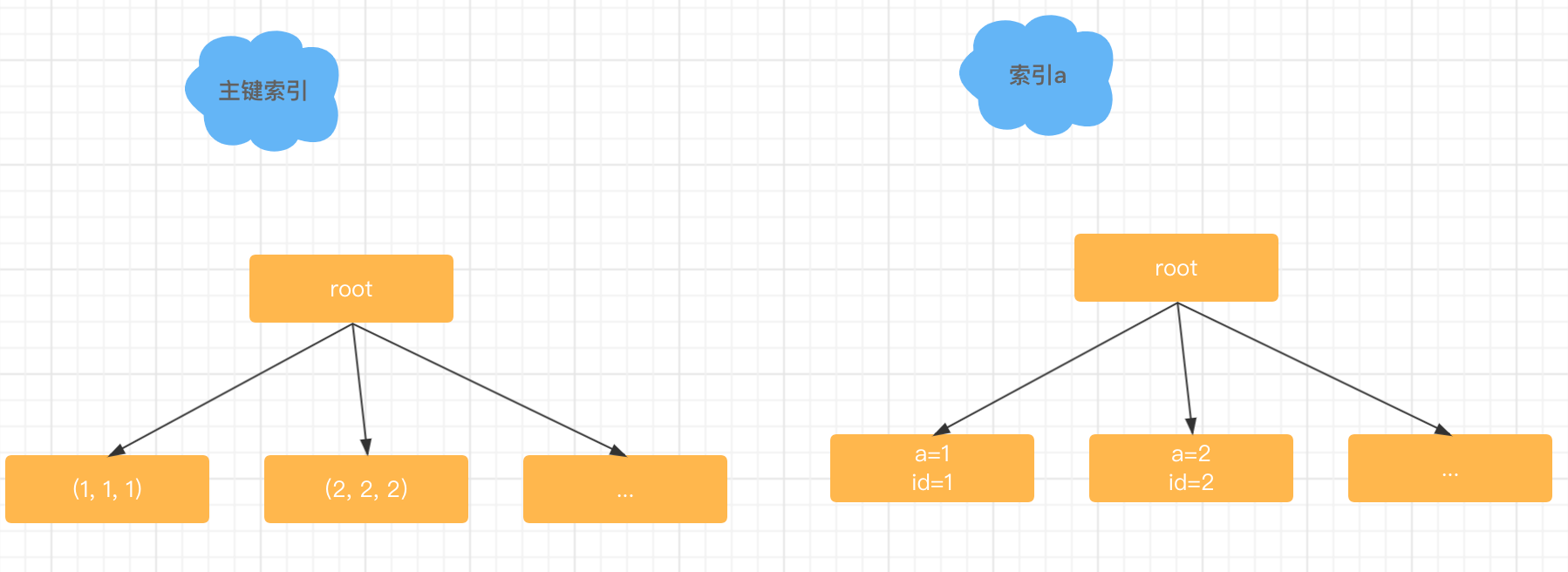

現在我們來看看這個語句的explain的結果,在輸出結果裡,key這裡顯示的是PRIMARY,其實從資料上你是知道的這個語句一定是做了全表掃描,但是優化器認為,這個語句的執行過程中,需要根據主鍵索引定位到第一個滿足id>0的值,也算用到了索引。所以你看,即使explain結果裡面寫了key不是NULL,實際上也可能是全表掃描的,因此InnoDB裡面只有一種情況叫做沒有使用索引,那就是從主鍵索引的最左邊的葉節點開始,向右掃描整個索引樹,也就是說,沒有使用索引並不是一個準確的描述,你可以用全表掃描來表示一個查詢遍歷了整個主鍵索引樹。也可以用全索引掃描來說明,像select a from t這樣的查詢,它掃描了整個普通索引樹。而像select * from t where id = 2; 這樣的語句才是我們平時說的使用了索引,它表示的意思是我們使用了索引的快速搜尋功能,並且有效的減少了掃描行數。
那麼除了全索引掃描,還有哪些是使用了索引但是執行速度不夠快的例子呢,這就要說到索引的過濾性,假設你現在維護了一個表,這個表記錄了全中國人的基本資訊,然後你現在要查出年齡在10到15歲之間的小朋友的姓名和基本資訊,那麼你的語句會這麼寫,select * from t_people where age between 10 and 15;你一看這個語句一定要在age欄位上建索引了,否則就是個全表掃描。但是你會發現在age上建了索引以後,這個語句還是執行慢,因為滿足這個條件的資料有超過1億行。我們來看看建立了這個索引以後這個表的組織結構圖,這個語句的執行流程是這樣的。從索引age上用樹搜尋,取到第一個age等於10的記錄,得到它的主鍵ID的值,根據ID的值去主鍵索引取整行的資訊,作為結果集的一部分返回,在索引age上向右掃描,取下一個ID值,到主鍵索引上取整行資訊,作為結果集的一部分返回,重複上面的步驟直到碰到第一個age>15的記錄。你看這個語句,雖然它用了索引,但是它掃描超過了一億行,而上面select * from t;這個語句雖然沒有用索引,但其實也只掃描了兩行。
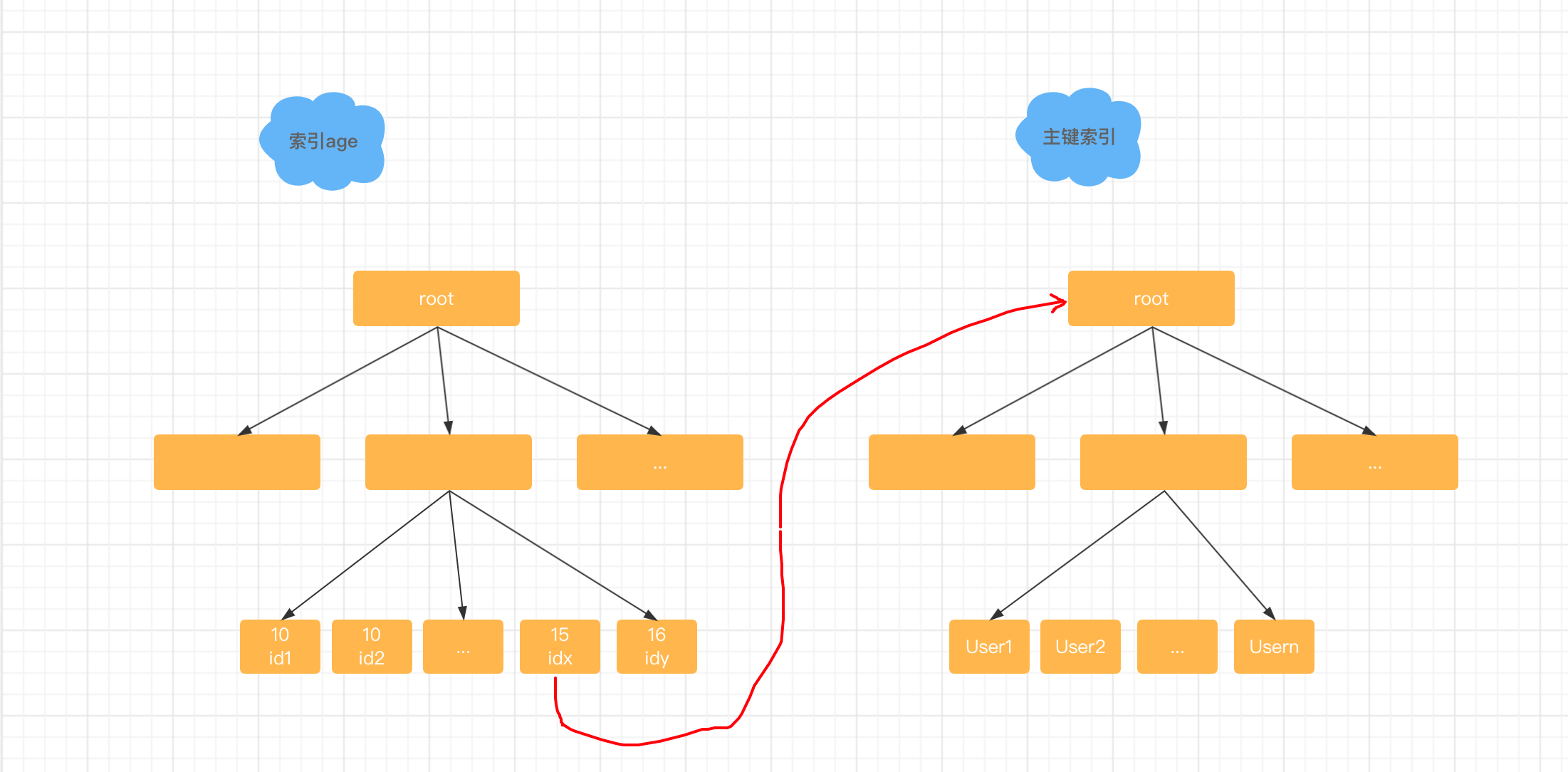
所以你現在知道了,當我們討論有沒有使用索引的時候,其實我們關心的是掃描行數,對於一個大表,不止要有索引,索引的過濾性還要足夠好,像剛才這個例子age這個索引它的過濾性就不夠好。在設計表結構的時候,我們要讓索引的過濾性足夠好,也就是區分度足夠高。那麼過濾性好了,是不是表示查詢的掃描行數就一定少呢,我們再來看一個例子。
三、索引的掃描行數
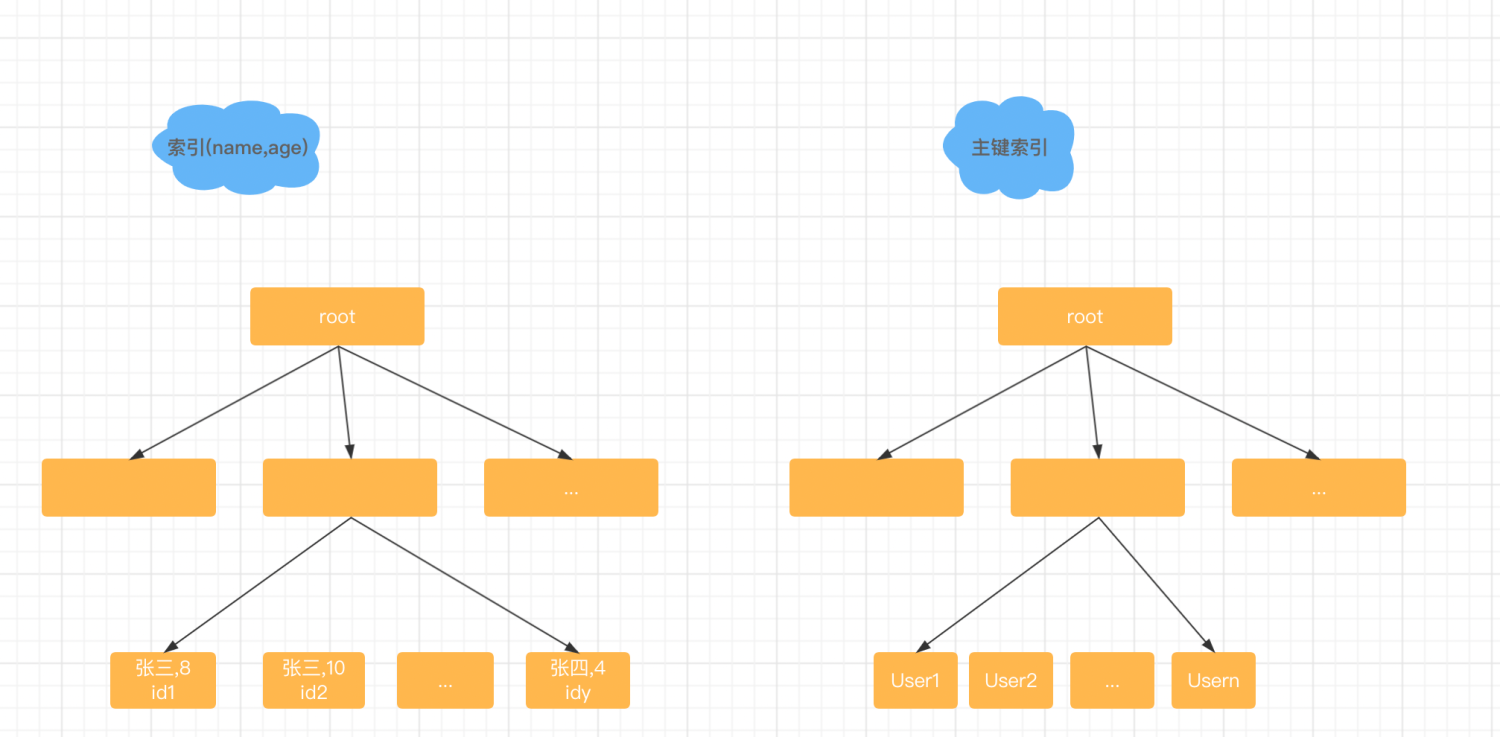
如果這個t_people表上有一個索引是姓名、年齡的聯合索引,那這個聯合索引的過濾性應該不錯,如果你的執行語句是select * from t_people where name = '張三' and age = 8; 就可以在一個索引上快速找到第一個姓名是張三並且年齡是8歲的小朋友,當然這樣的小朋友就該不多,因此向右掃描的行數很少,查詢效率就很高,但是查詢的過濾性和索引的過濾性可並不一定是一樣的。如果現在你的需求是查出所有名字第一個字是張並且年齡是8歲的所有小朋友,你的語句會怎麼寫呢?你的語句要這麼寫:select * from t_people where name like '張%' and age = 8; 在MySQL5.5和之前的版本中,這個語句的執行流程是這樣的。首先從聯合索引樹上找到第一個姓名欄位是張開頭的記錄,取出主鍵ID,然後到主鍵索引上,根據ID取出整行的值,判斷年齡欄位是否等於8如果是就作為結果集的一行返回,如果不是就丟棄,我們把根據ID到主鍵索引上查詢整行資料這個動作稱為回表,在聯合索引上向右遍歷,並重復做回表和判斷的邏輯直到碰到聯合索引樹上名字第一個字不是張的記錄為止。你可以看到這個執行過程裡面最耗費時間的步驟就是回表,假設全國名字第一個字是張的人有8000萬,那麼這個過程就要回表8000萬次,在定位第一行記錄的時候,只能使用索引和聯合索引的最左字首,稱為最左字首原則。那你可以看到這個執行過程它的回表次數特別多,效能不夠好,那有沒有優化的方法呢?有的在MySQL5.6版本引入了index condition pushdown的優化,我們來看看這個優化的執行流程。
首先從聯合索引樹上找到第一個姓名欄位是張開頭的記錄,判斷這個索引記錄裡面年齡的值是不是8,如果是就回表,取出整行資料作為結果集的一部分返回,如果不是就丟棄。在聯合索引樹上向右遍歷,並判斷年齡欄位後根據需要做回表,直到碰到聯合索引樹上名字的第一個字不是張的記錄為止。這個過程跟上面過程的差別是在遍歷聯合索引的過程中,將年齡等於8這個條件下推到索引遍歷的過程中,減少了回表的次數,假設全國名字第一個字是張的人裡面朋100萬個是8歲的小朋友,那麼這個查詢過程中,在聯合索引裡要遍歷8000萬次,而回表只需要100萬次。可以看到,index condition pushdown 優化的效果還是很不錯的,但是這個優化,還是沒有繞開最左字首原則的限制,因此在聯合索引裡,還是要掃描8000萬行,那有沒有更進一下的優化方法呢?我們可以把名字的第一個字,和年齡做一個聯合索引來試試,這裡可以用到MySQL 5.7引入的虛擬列來實現,對應的修改表結構的SQL語句是這麼寫的。
alter table t_people add name_first varchar(2) generated always as
(left(name, 1)), add index (name_first, age);
CREATE TABLE `t_people` (
`id` int(11) DEFAULT NULL,
`name` varchar(20) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`info` varchar(255) DEFAULT NULL,
`name_first` varchar(2) GENERATED ALWAYS AS (left(`name`, 1)) VIRTUAL,
KEY `name_first` (`name_first`, `age`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
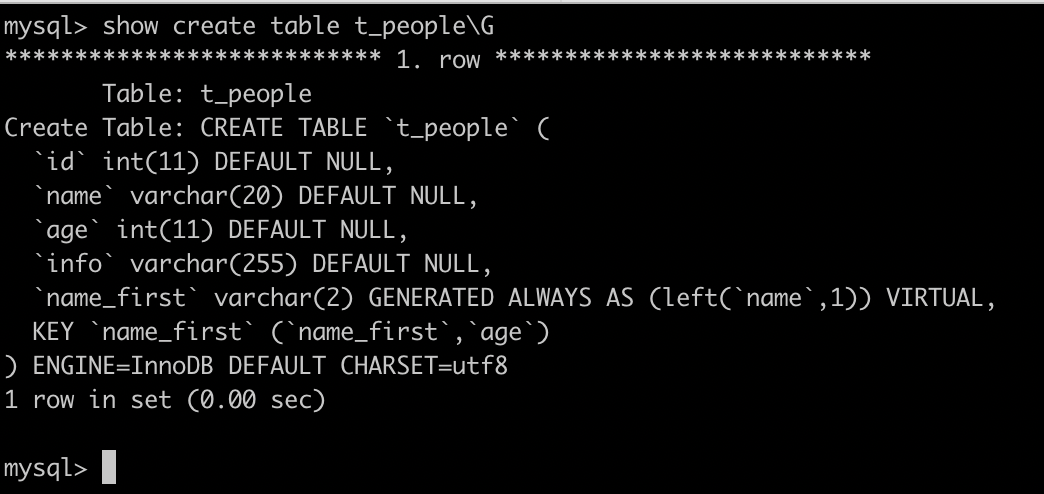
上圖是這個DDL語句的執行效果,首先它在t_people上建立一個欄位叫name_first虛擬列,然後給name_first和age上建立一個聯合索引,並且讓這個虛擬列的值,總是等於name欄位的前兩個位元組,虛擬列在插入資料的時候,不能指定值,在更新的時候也不能指定修改,它的值會根據定義自動生成,在name欄位修改的時候,也會自動修改,有了這個新的聯合索引,我們再找名字第一個字是張並且年齡是8的小朋友的時候,這個SQL語句就可以這麼寫:select * from t_people where name_fist = '張' and age = 8; 這樣這個語句的執行過程,就只需要掃描聯合索引的100萬行並回表100萬次。這個優化的本質是建立了一個更緊湊的索引來加速了查詢的過程。
四、小結
今天介紹了索引的基本結構和一些查詢優化的基本思路,現在我們知道了:
1、使用索引和慢查詢沒有必然聯絡,使用索引的SQL也有可能是慢查詢語句;
2、檢查一個查詢語句的執行效率最終要看的是掃描行數,我們查詢優化的過程往往就是減少掃描行數的過程;
3、使用虛擬列和聯合索引來提升複雜查詢的執行效率。