Halodoc使用 Apache Hudi 構建 Lakehouse的關鍵經驗
Halodoc 資料工程已經從傳統的資料平臺 1.0 發展到使用 LakeHouse 架構的現代資料平臺 2.0 的改造。在我們之前的部落格中,我們提到了我們如何在 Halodoc 實施 Lakehouse 架構來服務於大規模的分析工作負載。 我們提到了平臺 2.0 構建過程中的設計注意事項、最佳實踐和學習。
本部落格中我們將詳細介紹 Apache Hudi 以及它如何幫助我們構建事務資料湖。我們還將重點介紹在構建Lakehouse時面臨的一些挑戰,以及我們如何使用 Apache Hudi 克服這些挑戰。
Apache Hudi
讓我們從對 Apache Hudi 的基本瞭解開始。 Hudi 是一個豐富的平臺,用於在自我管理的資料庫層上構建具有增量資料管道的流式資料湖,同時針對湖引擎和常規批次處理進行了優化。
Apache Hudi 將核心倉庫和資料庫功能直接引入資料湖。 Hudi 提供表、事務、高效的 upserts/deletes、高階索引、流式攝取服務、資料Clustering/壓縮優化和並行性,同時將資料保持為開原始檔格式。
Apache Hudi 可以輕鬆地在任何雲端儲存平臺上使用。 Apache Hudi 的高階效能優化,使得使用任何流行的查詢引擎(包括 Apache Spark、Flink、Presto、Trino、Hive 等)的分析工作負載更快。
讓我們看看在構建Lakehouse時遇到的一些關鍵挑戰,以及我們如何使用 Hudi 和 AWS 雲服務解決這些挑戰。
在 LakeHouse 中執行增量 Upsert
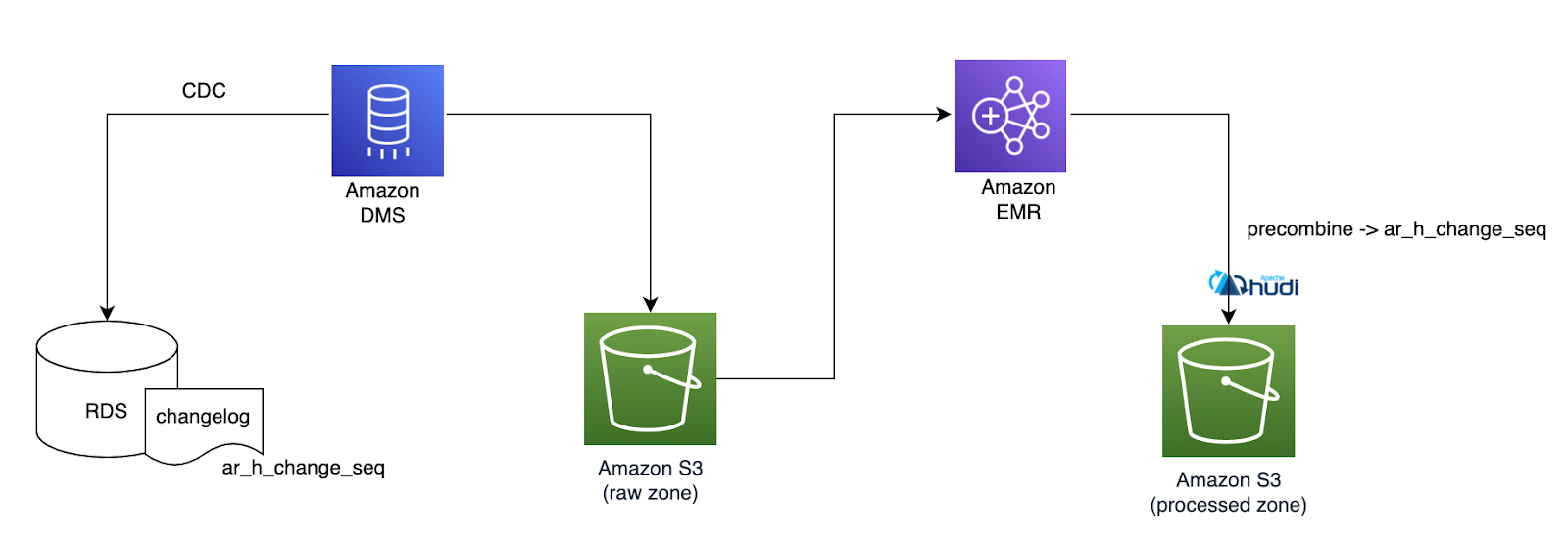
每個人在構建事務資料湖時面臨的主要挑戰之一是確定正確的主鍵來更新資料湖中的記錄。在大多數情況下都使用主鍵作為唯一識別符號和時間戳欄位來過濾傳入批次中的重複記錄。
在 Halodoc,大多數微服務使用 RDS MySQL 作為資料儲存。我們有 50 多個 MySQL 資料庫需要遷移到資料湖,交易經歷各種狀態,並且在大多數情況下經常發生更新。
問題:
MySQL RDS 以秒格式儲存時間戳欄位,這使得跟蹤發生在毫秒甚至微秒內的事務變得困難,使用業務修改的時間戳欄位識別傳入批次中的最新交易對我們來說是一項挑戰。
我們嘗試了多種方法來解決這個問題,通過使用 rank 函數或組合多個欄位並選擇正確的複合鍵。選擇複合鍵在表中並不統一,並且可能需要不同的邏輯來識別最新的交易記錄。
解決方案:
AWS Data Migration Service 可以設定為具有可以新增具有自定義或預定義屬性的附加檔頭的轉換規則。
ar_h_change_seq:來自源資料庫的唯一遞增數位,由時間戳和自動遞增數位組成。該值取決於源資料庫系統。
檔頭幫助我們輕鬆過濾掉重複記錄,並且我們能夠更新資料湖中的最新記錄。檔頭將僅應用於正在進行的更改。對於全量載入,我們預設為記錄分配了 0,在增量記錄中,我們為每條記錄附加了一個唯一識別符號。我們在 precombine 欄位中設定 ar_h_change_seq 以從傳入批次中刪除重複記錄。
Hudi設定:
precombine = ar_h_change_seq
hoodie.datasource.write.precombine.field: precombine
hoodie.datasource.write.payload.class: 'org.apache.hudi.common.model.DefaultHoodieRecordPayload'
hoodie.payload.ordering.field: precombine
資料湖中的小檔案問題
在構建資料湖時,會發生頻繁的更新/插入,從而導致每個分割區中都有很多小檔案。
問題:
讓我們看看小檔案在查詢時是如何導致問題的。當觸發查詢以提取或轉換資料集時,Driver節點必須收集每個檔案的後設資料,從而導致轉換過程中的效能開銷。
解決方案:
定期壓縮小檔案有助於保持正確的檔案大小,從而提高查詢效能。而Apache Hudi 支援同步和非同步壓縮。
- 同步壓縮:這可以在寫入過程本身期間啟用,這將增加 ETL 執行時間以更新 Hudi 中的記錄。
- 非同步壓縮:壓縮可以通過不同的程序來實現,並且需要單獨的記憶體來實現。這不會影響寫入過程,也是一個可延伸的解決方案。
在 Halodoc,我們首先採用了同步壓縮。慢慢地,我們計劃採用基於表大小、增長和用例的混合壓縮。
Hudi設定:
hoodie.datasource.clustering.inline.enable
hoodie.datasource.compaction.async.enable
保持儲存大小以降低成本
資料湖很便宜,並不意味著我們應該儲存業務分析不需要的資料。否則我們很快就會看到儲存成本越來越高。 Apache Hudi 會在每個 upsert 操作中維護檔案的版本,以便為記錄提供時間旅行查詢。每次提交都會建立一個新版本的檔案,從而建立大量版本化檔案。
問題:
如果我們不啟用清理策略,那麼儲存大小將呈指數增長,直接影響儲存成本。如果沒有業務價值,則必須清除較舊的提交。
解決方案:
Hudi 有兩種清理策略,基於檔案版本和基於計數(要保留的提交數量)。在 Halodoc,我們計算了寫入發生的頻率以及 ETL 過程完成所需的時間,基於此我們提出了一些要保留在 Hudi 資料集中的提交。
範例:如果每 5 分鐘安排一次將資料攝取到 Hudi 的作業,並且執行時間最長的查詢可能需要 1 小時才能完成,則平臺應至少保留 60/5 = 12 次提交。
Hudi設定:
hoodie.cleaner.policy: KEEP_LATEST_COMMITS
hoodie.cleaner.commits.retained: 12
或者
hoodie.cleaner.policy: KEEP_LATEST_FILE_VERSIONS
hoodie.cleaner.fileversions.retained: 1
根據延遲和業務用例選擇正確的儲存型別
Apache Hudi 有兩種儲存型別,用於儲存不同用例的資料集。一旦選擇了一種儲存型別,更改/更新到另外一種型別可能是一個繁瑣的過程(CoW變更為MoR相對輕鬆,MoR變更為CoW較為麻煩)。因此在將資料遷移到 Hudi 資料集之前選擇正確的儲存型別非常重要。
問題:
選擇不正確的儲存型別可能會影響 ETL 執行時間和資料消費者的預期資料延遲。
解決方案:
在 Halodoc我們將這兩種儲存型別都用於我們的工作負載。
MoR:MoR 代表讀取時合併。我們為寫入完成後需要即時讀取存取的表選擇了 MoR。它還減少了 upsert 時間,因為 Hudi 為增量更改紀錄檔維護 AVRO 檔案,並且不必重寫現有的 parquet 檔案。
MoR 提供資料集 _ro 和 _rt 的 2 個檢視。
- _ro 用於讀取優化表。
- _rt 用於實時表。
CoW:CoW 代表寫時複製。儲存型別 CoW 被選擇用於資料延遲、更新成本和寫入放大優先順序較低但讀取效能優先順序較高的資料集。
type = COPY_ON_WRITE / MERGE_ON_READ
hoodie.datasource.write.table.type: type
檔案列表很繁重,Hudi如何解決
一般來說分散式物件儲存或檔案系統上的 upsert 和更新是昂貴的,因為這些系統本質上是不可變的,它涉及跟蹤和識別需要更新的檔案子集,並用包含最新記錄的新版本覆蓋檔案。 Apache Hudi 儲存每個檔案切片和檔案組的後設資料,以跟蹤更新插入操作的記錄。
問題:
如前所述,在不同分割區中有大量檔案是Driver節點收集資訊的開銷,因此會導致記憶體/計算問題。
解決方案:
為了解決這個問題,Hudi 引入了後設資料概念,這意味著所有檔案資訊都儲存在一個單獨的表中,並在源發生變化時進行同步。這將有助於 Spark 從一個位置讀取或執行檔案列表,從而實現最佳資源利用。
這些可以通過以下設定輕鬆實現。
Hudi設定
hoodie.metadata.enabled: true
為 Hudi 資料集選擇正確的索引
在傳統資料庫中使用索引來有效地從表中檢索資料。 Apache Hudi 也有索引概念,但它的工作方式略有不同。 Hudi 中的索引主要用於強制跨表的所有分割區的鍵的唯一性。
問題:
想要構建事務資料湖時,維護/限制每個分割區或全域性分割區中的重複記錄始終至關重要
解決方案:
Hudi 通過使用 Hudi 資料集中的索引解決了這個問題,它提供全域性和非全域性索引。預設情況下使用Bloom Index。目前Hudi支援:
- Bloom Index:使用由記錄鍵構建的Bloom過濾器,還可以選擇使用記錄鍵範圍修剪候選檔案。
- Simple Index:對儲存表中的記錄和傳入更新/刪除記錄進行連線操作。
- Hbase Index:管理外部 Apache HBase 表中的索引對映。
在 Halodoc,我們利用全域性 Bloom 索引,以便記錄在分割區中是唯一的,使用索引時必須根據源行為或是否有人想要維護副本做出決定。
總結
在 Halodoc過去 6 個月我們一直在使用 Apache Hudi,它一直很好地服務於大規模資料工作負載。 一開始為 Apache Hudi 選擇正確的設定涉及一些學習曲線。
在這篇部落格中,我們分享了我們在構建 LakeHouse 時遇到的一些問題,以及在生產環境中使用 Apache Hudi 時正確設定引數/設定的最佳實踐。
PS:如果您覺得閱讀本文對您有幫助,請點一下「推薦」按鈕,您的「推薦」,將會是我不竭的動力!
作者:leesf 掌控之中,才會成功;掌控之外,註定失敗。
出處:http://www.cnblogs.com/leesf456/
本文版權歸作者和部落格園共有,歡迎轉載,但未經作者同意必須保留此段宣告,且在文章頁面明顯位置給出原文連線,否則保留追究法律責任的權利。
如果覺得本文對您有幫助,您可以請我喝杯咖啡!

