以位元組跳動內部 Data Catalog 架構升級為例聊業務系統的效能優化
背景
位元組跳動 Data Catalog 產品早期,是基於 LinkedIn Wherehows 進行二次改造,產品早期只支援 Hive 一種資料來源。後續為了支援業務發展,做了很多修修補補的工作,系統的可維護性和擴充套件性變得不可忍受。比如為了支援資料血緣能力,引入了位元組內部的圖資料庫 veGraph,寫入時,需要業務層處理 MySQL、ElasticSearch 和 veGraph 三種儲存,模型也需要同時理解關係型和圖兩種。更多的背景可以參照之前的文章。
新版本保留了原有版本全量的產品能力,將儲存層替換成了 Apache Atlas。然而,當我們把存量資料匯入到新系統時,許多介面的讀寫效能都有嚴重下降,伺服器資源的使用也被拉伸到誇張的地步,比如:
- 寫入一張超過 3000 列的 Hive 表後設資料時,會持續將服務節點的 CPU 佔用率提升到 100%,十幾分鍾後觸發超時
- 一張幾十列的埋點表,上下游很多,開啟詳情展示時需要等 1 分鐘以上
為此,我們進行了一系列的效能調優,結合 Data Catlog 產品的特點,調整了 Apache Atlas 以及底層 Janusgraph 的實現或設定,並對優化效能的方法論做了一些總結。
業務系統優化的整體思路
在開始討論更多細節之前,先概要介紹下我們做業務類系統優化的思路。本文中的業務系統,是相對於引擎系統的概念,特指解決某些業務場景,給使用者直接暴露前端使用的 Web 類系統。
優化之前,首先應明確優化目標。
與引擎類系統不同,業務類系統不會追求極致的效能體驗,更多是以解決實際的業務場景和問題出發,做針對性的調優,需要格外注意避免過早優化與過度優化。
準確定位到瓶頸,才能事半功倍。
一套業務系統中,可以優化的點通常有很多,從業務流程梳理到底層元件的效能提升,但是對瓶頸處優化,才是 ROI 最高的。
根據問題型別,挑價效比最高的解決方案。
解決一個問題,通常會有很多種不同的方案,就像條條大路通羅馬,但在實際工作中,我們通常不會追求最完美的方案,而是選用價效比最高的。
優化的效果得能快速得到驗證。
效能調優具有一定的不確定性,當我們做了某種優化策略後,通常不能上線觀察效果,需要一種更敏捷的驗證方式,才能確保及時發現策略的有效性,並及時做相應的調整。
業務系統優化的細節
優化目標的確定
在業務系統中做優化時,比較忌諱兩件事情:
- 過早優化:在一些功能、實現、依賴系統、部署環境還沒有穩定時,過早的投入優化程式碼或者設計,在後續系統發生變更時,可能會造成精力浪費。
- 過度優化:與引擎類系統不同,業務系統通常不需要跑分或者與其他系統產出效能對比報表,實際工作中更多的是貼合業務場景做優化。比如使用者直接存取前端介面的系統,通常不需要將響應時間優化到 ms 以下,幾十毫秒和幾百毫秒,已經是滿足要求的了。
優化範圍選擇
對於一個業務類 Web 服務來說,特別是重構階段,優化範圍比較容易圈定,主要是找出與之前系統相比,明顯變慢的那部分 API,比如可以通過以下方式收集需要優化的部分:
• 通過前端的慢查詢捕捉工具或者後端的監控系統,篩選出 P90 大於 2s 的 API
• 頁面測試過程中,研發和測試同學陸續反饋的 API
• 資料匯入過程中,研發發現的寫入慢的 API 等
優化目標確立
針對不同的業務功能和場景,定義儘可能細緻的優化目標,以 Data Catalog 系統為例:
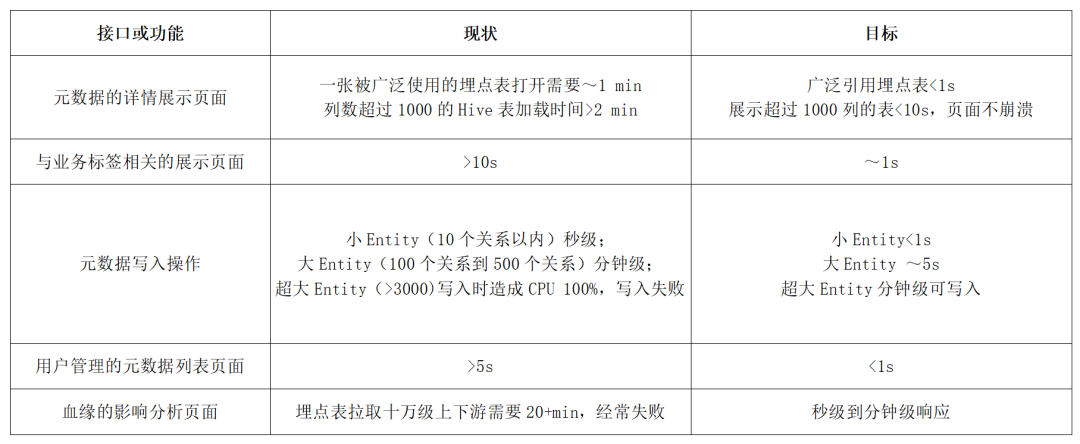
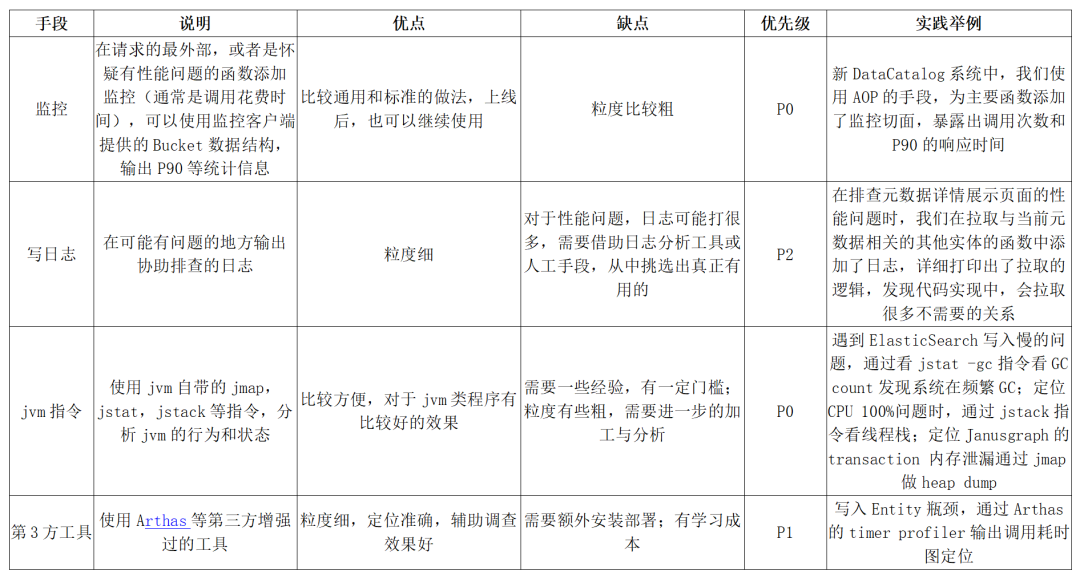
定位效能瓶頸手段
系統複雜到一定程度時,一次簡單的介面呼叫,都可能牽扯出底層廣泛的呼叫,在優化某個具體的 API 時,如何準確找出造成效能問題的瓶頸,是後續其他步驟的關鍵。下面的表格是我們總結的常用瓶頸排查手段。
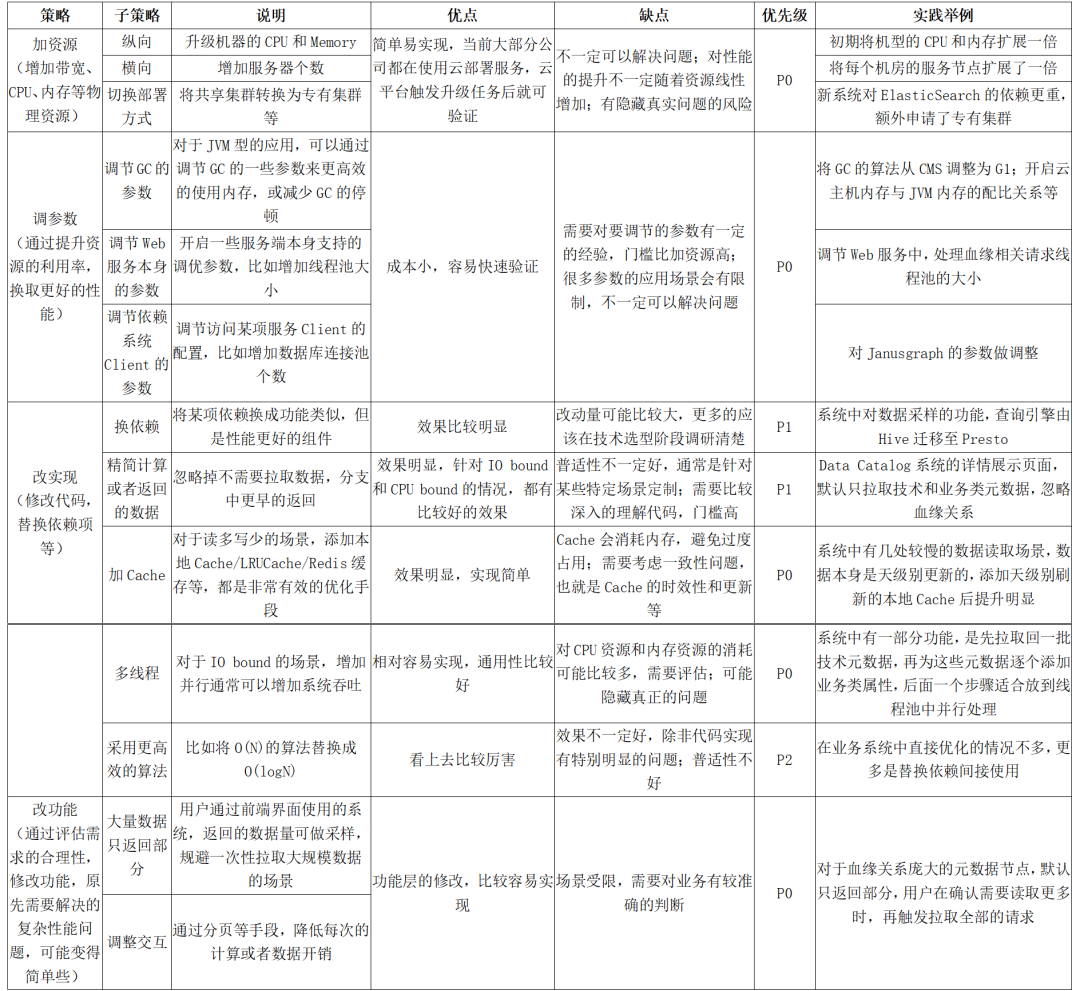
優化策略
在找到某個介面的效能瓶頸後,下一步是著手處理。同一個問題,修復的手段可能有多種,實際工作中,我們優先考慮價效比高的,也就是實現簡單且有明確效果。
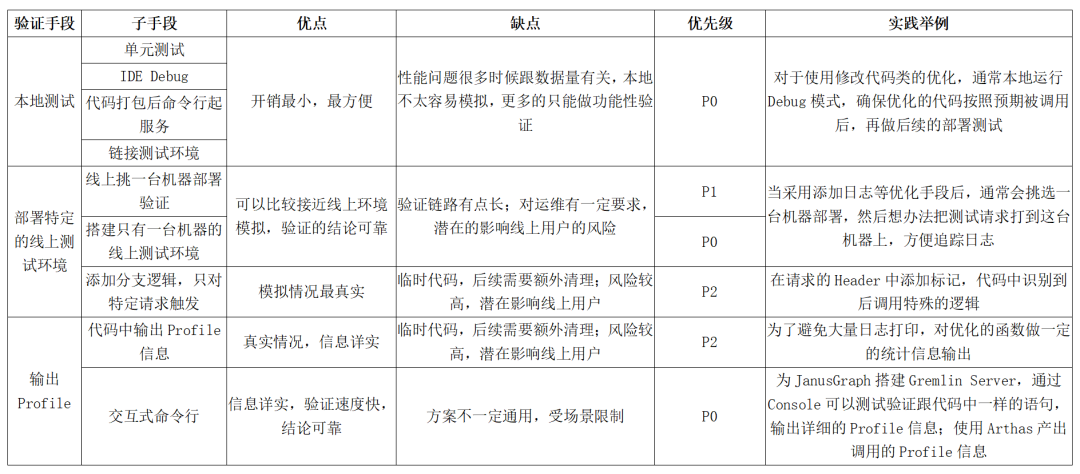
快速驗證
優化的過程通常需要不斷的嘗試,所以快速驗證特別關鍵,直接影響優化的效率。
Data Catalog 系統優化舉例
在我們升級位元組 Data Catalog 系統的過程中,廣泛使用了上文中介紹的各種技巧。本章節,我們挑選一些較典型的案例,詳細介紹優化的過程。
調節 JanusGraph 設定
實踐中,我們發現以下兩個引數對於 JanusGraph 的查詢效能有比較大的影響:
- query.batch = ture
- query.batch-property-prefetch=true
其中,關於第二個設定項的細節,可以參照我們之前釋出的文章。這裡重點講一下第一個設定。
JanusGraph 做查詢的行為,有兩種方式:
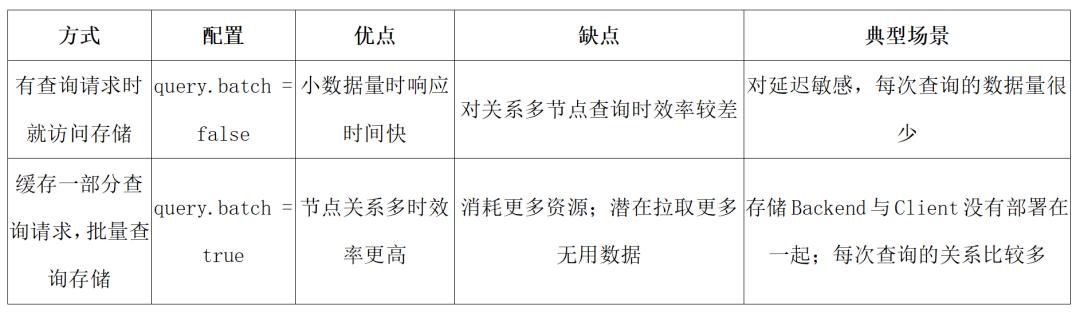
針對位元組內部的應用場景,後設資料間的關係較多,且後設資料結構複雜,大部分查詢都會觸發較多的節點存取,我們將 query.batch 設定成 true 時,整體的效果更好。
調整 Gremlin 語句減少計算和 IO
一個比較典型的應用場景,是對通過關係拉取的其他節點,根據某種屬性做 Count。在我們的系統中,有一個叫「BusinessDomain」的標籤型別,產品上,需要獲取與某個此類標籤相關聯的後設資料型別,以及每種型別的數量,返回類似下面的結構體:
{ "guid": "XXXXXX", "typeName": "BusinessDomain", "attributes": { "nameCN": "直播", "nameEN": null, "creator": "XXXX", "department": "XXXX", "description": "直播業務標籤" }, "statistics": [ { "typeName": "ClickhouseTable", "count": 68 }, { "typeName": "HiveTable", "count": 601 } ] }
我們的初始實現轉化為 Gremlin 語句後,如下所示,耗時 2~3s:
g.V().has('__typeName', 'BusinessDomain') .has('__qualifiedName', eq('XXXX')) .out('r:DataStoreBusinessDomainRelationship') .groupCount().by('__typeName') .profile();
優化後的 Gremlin 如下,耗時~50ms:
g.V().has('__typeName', 'BusinessDomain') .has('__qualifiedName', eq('XXXX')) .out('r:DataStoreBusinessDomainRelationship') .values('__typeName').groupCount().by() .profile();
Atlas 中根據 Guid 拉取資料計算邏輯調整
對於詳情展示等場景,會根據 Guid 拉取與實體相關的資料。我們優化了部分 EntityGraphRetriever 中的實現,比如:
- mapVertexToAtlasEntity 中,修改邊遍歷的讀資料方式,調整為以點以及點上的屬性過濾拉取,觸發 multiPreFetch 優化。
- 支援根據邊型別拉取資料,在應用層根據不同的場景,指定不同的邊型別集合,做資料的裁剪。最典型的應用是,在詳情展示頁面,去掉對血緣關係的拉取。
- 限制關係拉取的深度,在我們的業務中,大部分關係只需要拉取一層,個別的需要一次性拉取兩層,所以我們介面實現上,支援傳入拉取關係的深度,預設一層。
配合其他的修改,對於被廣泛參照的埋點表,讀取的耗時從~1min 下降為 1s 以內。
對大量節點依次獲取資訊加並行處理
在血緣相關介面中,有個場景是需要根據血緣關係,拉取某個後設資料的上下游 N 層後設資料,新拉取出的後設資料,需要額外再查詢一次,做屬性的擴充。
我們採用增加並行的方式優化,簡單來說:
- 設定一個 Core 執行緒較少,但 Max 執行緒數較多的執行緒池:需要拉取全量上下游的情況是少數,大部分情況下幾個 Core 執行緒就夠用,對於少數情況,再啟用額外的執行緒。
- 在批次拉取某一層的後設資料後,將每個新拉取的後設資料頂點加入到一個執行緒中,線上程中單獨做屬性擴充
- 等待所有的執行緒返回
對於關係較多的後設資料,優化效果可以從分鐘級到秒級。
對於寫入瓶頸的優化
位元組的數倉中有部分大寬表,列數超過 3000。對於這類後設資料,初始的版本幾乎沒法成功寫入,耗時也經常超過 15 min,CPU 的利用率會飆升到 100%。
定位寫入的瓶頸
我們將線上的一臺機器從 LoadBalance 中移除,並構造了一個擁有超過 3000 個列的後設資料寫入請求,使用 Arthas 的 itemer 做 Profile,得到下圖:
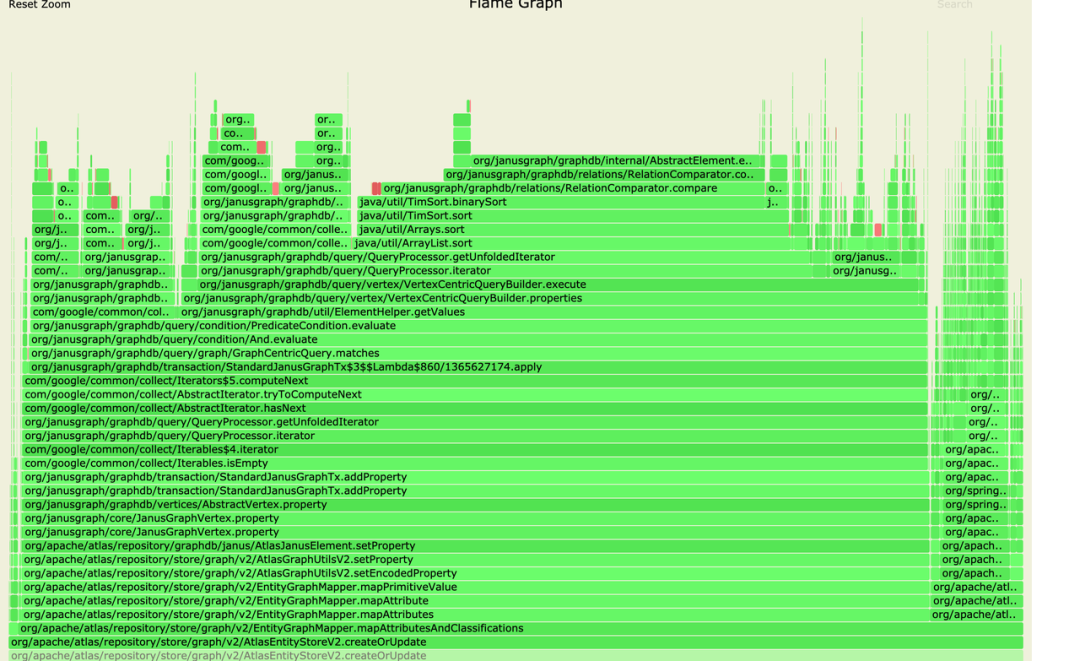
從上圖可知,總體 70%左右的時間,花費在 createOrUpdate 中參照的 addProperty 函數。
耗時分析
-
JanusGraph 在寫入一個 property 的時候,會先找到跟這個 property 相關的組合索引,然後從中篩選出 Coordinality 為「Single」的索引
-
在寫入之前,會 check 這些為 Single 的索引是否已經含有了當前要寫入的 propertyValue
-
組合索引在 JanusGraph 中的儲存格式為:

-
Atlas 預設建立的「guid」屬性被標記為 globalUnique,他所對應的組合索引是__guid。
-
對於其他在型別定義檔案中被宣告為「Unique」的屬性,比如我們業務語意上全域性唯一的「qualifiedName」,Atlas 會理解為「perTypeUnique」,對於這個 Property 本身,如果也需要建索引,會建出一個 coordinity 是 set 的完全索引,為「propertyName+typeName」生成一個唯一的完全索引
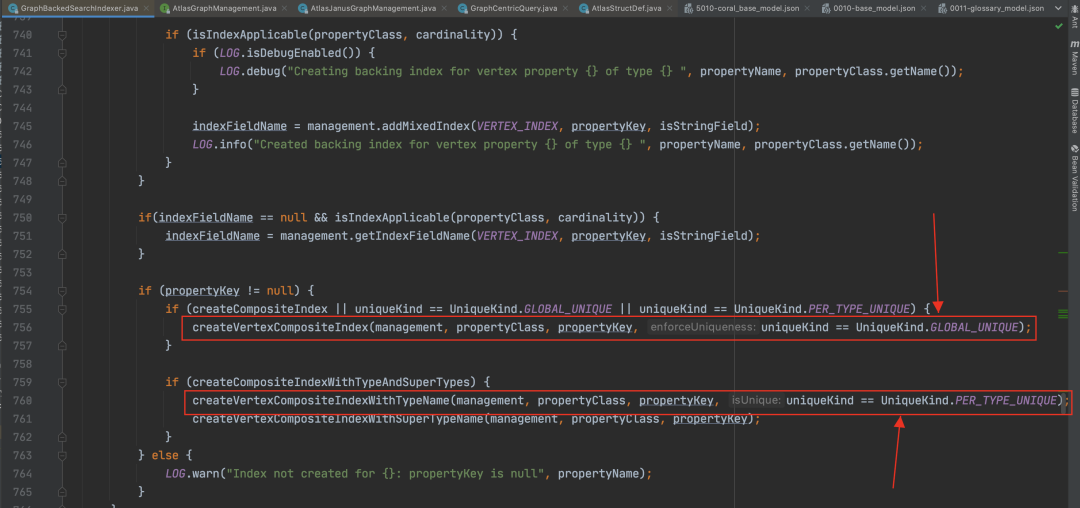
-
在呼叫「addProperty」時,會首先根據屬性的型別定義,查詢「Unique」的索引。針對「globalUnique」的屬性,比如「guid」,返回的是「__guid」;針對「perTypeUnique」的屬性,比如「qualifiedName」,返回的是「propertyName+typeName」的組合索引。
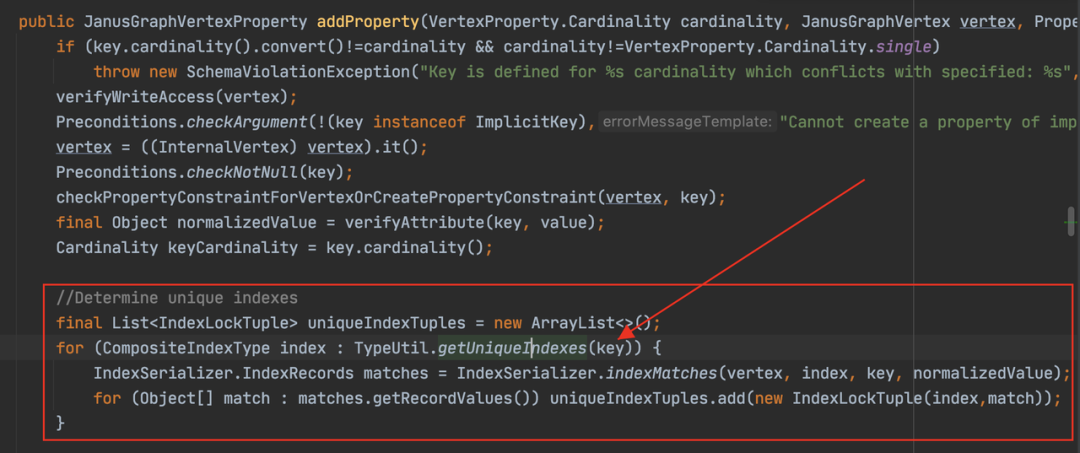
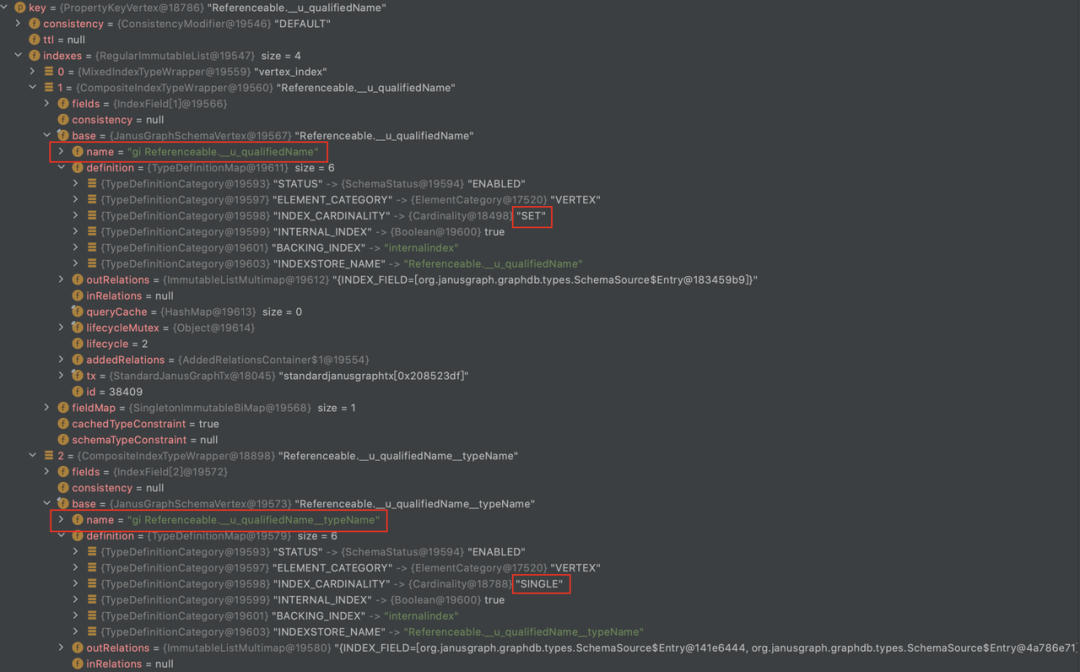
-
針對唯一索引,會嘗試檢查「Unique」屬性是否已經存在了。方法是拼接一個查詢語句,然後到圖裡查詢
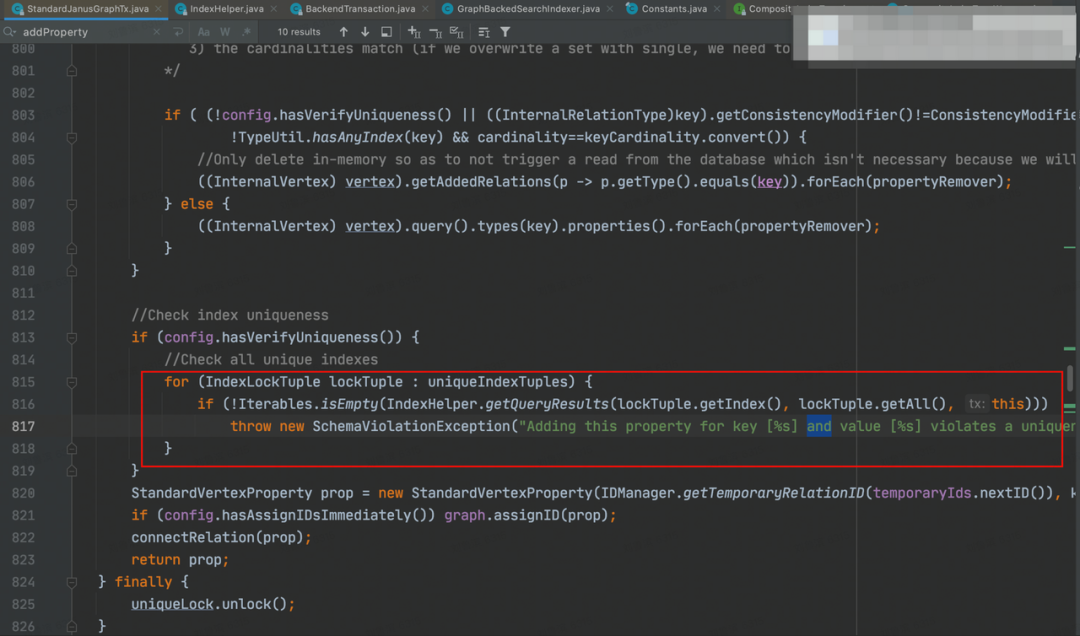
-
在我們的設計中,寫入表的場景,每一列都有被標記為唯一的「guid」和「qualifiedName」,「guid」會作為全域性唯一來查詢對應的完全索引,「qualifiedName」會作為「perTypeUnique」的查詢「propertyName+typeName」的組合完全索引,且整個過程是順序的,因此當寫入列很多、屬性很多、關係很多時,總體上比較耗時。
優化思路
- 對於「guid」,其實在建立時已經根據「guid」的生成規則保證了全域性唯一性,幾乎不可能有衝突,所以我們可以考慮去掉寫入時對「guid」的唯一性檢查,節省了一半時間。
- 對於「qualifiedName」,根據業務的生成規則,也是「globalUnique」的,與「perTypeUnique」的效能差別幾乎是一倍:
優化實現效果
- 去除 Atlas 中對於「guid」的唯一性的檢查。
- 新增「Global_Unqiue」設定項,在型別定義時使用,在初始化時對「__qualifiedName」建立全域性唯一索引。
- 配合其他優化手段,對於超多屬性與關係的 Entity 寫入,耗時可以降低為分鐘級。
總結
- 業務類系統的效能優化,通常會以解決某個具體的業務場景為目標,從介面入手,逐層解決
- 效能優化基本遵循思路:發現問題->定位問題->解決問題->驗證效果->總結提升
- 優先考慮「巧」辦法,「土」辦法,比如加機器改引數,不為了追求高大上而走彎路
立即跳轉火山引擎巨量資料研發治理套件 DataLeap 官網瞭解詳情!
歡迎關注位元組跳動資料平臺同名公眾號