在實際的專案需求中瞭解技術架構的演進
想象一下,你家樓上有個業主在裝修,施工不當,導致你家裡有個臥室漏水了,這個時候你怎麼辦?
在程式中的體現:
單體應用:
專案所有的模組都打包到一起,然後扔到伺服器上部署執行。假如這個專案是一個電商專案,裡面有下單模組,派送模組等等。你把這些模組想象成你家的房間,一個模組對應一個房間,現在派送模組對應的房間漏水了,這個時候怎麼辦?沒辦法,只能全家出去住了,為啥,因為你所有的模組都打包到一個專案裡面去了,一個模組掛了,整個專案都得停下來,等派送模組修好了,再啟動專案繼續執行。缺點一目瞭然。
微服務應用:
為了解決單體式應用的不足,微服務的概念橫空出世。核心就是「拆」,把一整個專案按模組拆成一個個的小專案,所有拆分的小專案之間進行合作通訊形成原先的整體專案。這樣有什麼好處,當我們的專案在執行的時候,同樣派送模組掛了,這時候掛了的只有這一個模組服務,你其它模組的服務還是能後正常執行,使用者還是能夠正常下單,老闆還是正常賺錢。維修人員只需要把派送模組修好之後重新執行起來,然後加進來繼續給使用者下的單送貨。當然,最重要的就是,你不用全家出去睡了!
後面會展開講阿里的一套。
2、三個臭皮匠頂個諸葛亮——系統應用的高並行怎麼處理
在學校的時候,自己的畢業課設是《網上求職招聘管理系統》,做完了之後,和同學室友測了請求響應都很迅速,沒啥毛病。但是,當在面試的時候,面試官問我這個系統的並行量、效能問題的時候,我只能說額,今天天氣真不錯。
實際在公司做專案的時候,不僅僅是系統能夠正常跑起來這麼簡單而已,更重要的是系統能夠承受住的使用者並行請求。當用戶數量龐大時,我們就需要更好的機器、更好的CPU、更大的記憶體、更好的網路環境去應對請求的高並行。
為了應對這種高並行的情況,兩種處理方式:
垂直擴充套件
那就是在一臺伺服器的基礎上,不斷升級其中的配件,加入更多的磁碟、升級更大的記憶體、買更好更快的CPU......更加強大的伺服器當然能夠處理更高的並行量。總結一句話,充錢使你更加強大。
但是,這樣也是有弊端的,首先就是老闆與客戶不一定願意花錢(有錢當我沒說),更重要的一點還是,就算你給這臺伺服器 所有的配件都升級成最好的。但是,單臺伺服器處理效能還是有瓶頸的。那怎麼辦呢?俗話說得好,三個臭皮匠能頂一個諸葛亮。於是水平擴充套件出現了。
水平擴充套件
既然一臺伺服器有瓶頸,那就多換幾個機器來處理使用者請求,把單體應用轉變成分散式叢集應用。不僅省錢,處理並行 的能力也好。

3、快取架構提高系統的讀能力
講個簡單的場景:前臺使用者存取系統應用的資料,後臺是通過查詢資料庫的資料返回給前端展示的,在低存取量的情況下,這簡單的流程,系統還是能夠妥妥處理的。但是,你想想,在淘寶雙11的活動下,成千上萬的使用者同時存取淘寶,購買商品,同一個時間點,幾百萬幾千萬的使用者請求往後臺的資料庫打,能直接把後臺資料庫給打崩。
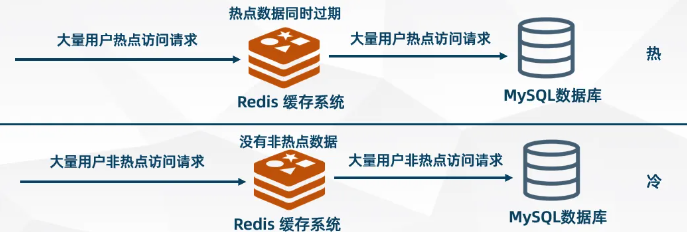
為了防止這種情況的發生,快取出現了。在原來的邏輯中間加一層快取,前臺使用者請求來的時候,不用每次都去資料庫裡運算元據,而是將應用程式需要的資料暫存在快取之中,請求來了,先查快取,快取中有的話就不用去資料庫裡查。這樣就能夠大大減少資料庫直接被使用者打崩的情況,而且快取是在記憶體中的,使用者請求不用去I/O磁碟,而是直接讀取記憶體資料,快得很。
4、非同步架構提高系統的寫能力
快取架構的出現,大大提高了程式的讀能力,那麼系統寫的能力有沒有什麼方法提高呢?這時候,非同步架構的概念就出現了,也就是訊息佇列的應用。
同步概念
快遞員在送快遞的時候,往往都會要求買家在收到快遞的時候籤個名字,有的時候,買家不在家還需要站在門口等買家回來,浪費自己送快遞的時間。
在程式中的體現:A系統向另一個B系統發了一個訊息,此時,A系統要收到B系統的回信才能進行其他的操作,否則這個程序就一直卡在這裡。問題來了,要是B系統能夠立即回覆還好,要是因為網路等原因一直在延遲,那麼A系統的CPU資源就一直在那裡等著,也就是說那些CPU資源就是被浪費了。
非同步概念
快遞員在送快遞的時候,不需要使用者直接簽名簽收,我直接給你放快遞櫃裡就行了,你人回家直接去快遞櫃裡掃碼取件就行了。
在程式中的體現:你在微信給你的好朋友發一條訊息,發完之後你就可以不用管了,手機想玩啥就玩啥,不用等到對方回了你的訊息你才能夠使用手機玩別的。
流程示意圖:
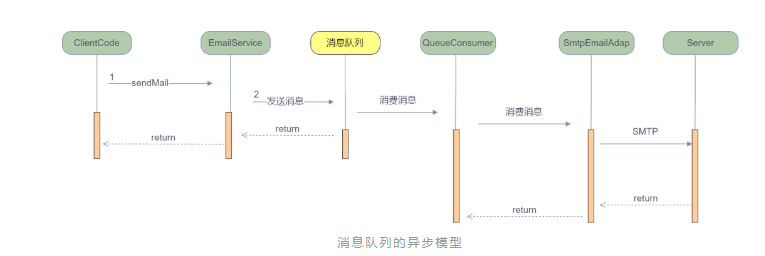
你只需要將訊息發給中間新加入的訊息佇列元件,訊息佇列在收到你發的訊息之後就給你立即返回,至於這條訊息發給另一個使用者的操作訊息佇列自己會處理就不用你關心了。
這樣做的好處:
-
給你快速的響應,避免白白等待,浪費系統資源。
-
流量削峰,在淘寶雙11活動下,加入這個訊息佇列,成千上萬的使用者請求過來,系統一時間處理不過來,就可以把使用者的請求放到這個訊息佇列裡面,讓系統進行排隊處理。
-
降低系統的耦合度,在呼叫者系統和被呼叫者系統之間加入訊息佇列,這樣兩者之間的程式碼依賴就少了,互動的部分交給中間的訊息佇列處理就好了。
5、解決機器不幹活——負載均衡的出現
前面說到,使用多臺機器代替一臺機器用來處理前臺使用者的請求。那麼問題來了,前臺過來的應用,發到後臺來,後臺三個伺服器大眼瞪小眼,誰來幹活呢?這時候負載均衡就出現了。
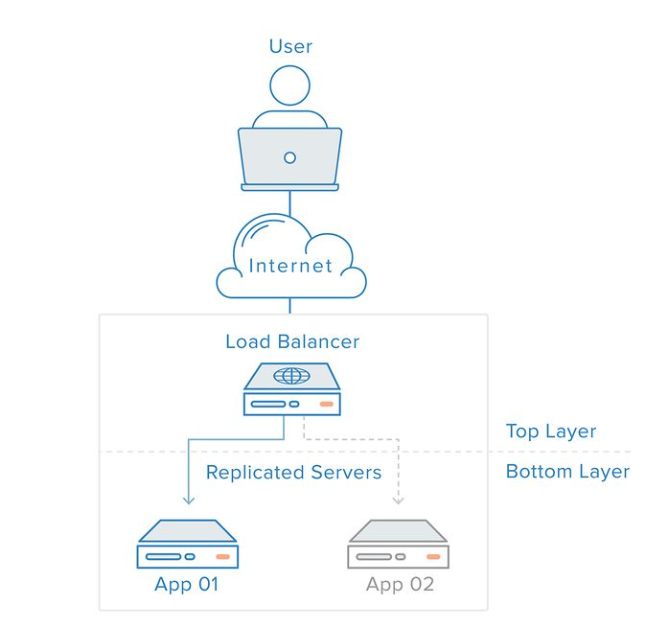
請求來到後臺的時候,先要經過負載均衡處理器的一道處理,這裡可以想象這個負載均衡器是一個包工頭,專案來的時候,把專案分給自己手下管理的小弟來做。
當然,這個負載均衡裡會涉及到很多不同的演演算法,輪詢、隨機、最多、最少......等。簡單來講就是,輪詢演演算法包工頭會把上面派下來的任務平均分到每一個小弟的手上,當然,包工頭也可以根據心情,故意讓你多做或者故意讓你少幹,這就是裡面你選擇的負載均衡演演算法,後面會開新篇單獨講。
6、狡兔三窟——資料儲存
前面說到,大量的使用者請求都需要存取資料庫。你想過沒有,如果系統只有一個資料庫,當這個資料庫因為停電啥的故障壞了怎麼辦,那麼整個系統就都涼涼了。為了解決這個問題,那就是給資料做好備份,多臺資料庫伺服器提供使用者服務。當一臺資料庫伺服器掛了的時候,其它的還可以頂上去,繼續給使用者提供服務。
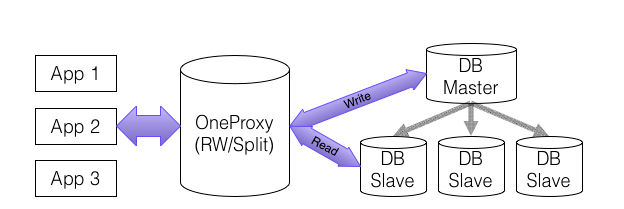
用專業的話來講就是,主從複製,整個伺服器有一臺主伺服器多臺從伺服器,從伺服器定時同步主伺服器的資料,這樣,當主伺服器掛了的時候,從伺服器頂上,系統照樣能夠正常執行。
這種技術手段在大部分資料庫裡都有使用,如mysql、redis,後面會拆成單篇講。
7、看起來不太聰明的樣子——搜尋引擎
相信對於程式設計師來講,面向百度谷歌程式設計這句話大家都比較熟悉。但是,當程式出現bug的時候,開啟百度的搜尋欄,想了半天不知道怎麼搜尋問題。為了能夠快速找到問題的解決方案,當然是輸入的關鍵詞越接近問題,顯示出來的答案更加準確。

想百度谷歌這種大型的搜尋網站都有屬於自己的一套搜尋引擎,根據這些搜尋引擎裡面的演演算法,可以根據我們提供的搜尋鍵碼,排序顯示給我們問題的答案。
現在比較熱門搜尋引擎有es、solr,後面也會展開單篇講。