深度學習與CV教學(12) | 目標檢測 (兩階段,R-CNN系列)

- 作者:韓信子@ShowMeAI
- 教學地址:http://www.showmeai.tech/tutorials/37
- 本文地址:http://www.showmeai.tech/article-detail/271
- 宣告:版權所有,轉載請聯絡平臺與作者並註明出處
- 收藏ShowMeAI檢視更多精彩內容

本系列為 斯坦福CS231n 《深度學習與計算機視覺(Deep Learning for Computer Vision)》的全套學習筆記,對應的課程視訊可以在 這裡 檢視。更多資料獲取方式見文末。
引言
ShowMeAI在前面的內容中給大家做了很多影象分類的介紹,主要圍繞折積神經網路(LeNet / AlexNet / NIN / VGG / Google / ResNet / MobileNet / squeezenet)講解,但計算機視覺領域有其他一些更為複雜的任務,例如本篇開始介紹的目標檢測(object detection)問題。
1. 計算機視覺任務
大家知道人工智慧領域的3大熱點方向是計算機視覺(CV,computer vision)、自然語言處理(Natural Language Process, NLP )和語音識別(Speech Recognition) 應用 。而計算機視覺領域又有影象分類、目標檢測、影象分割三大任務,如下圖所示
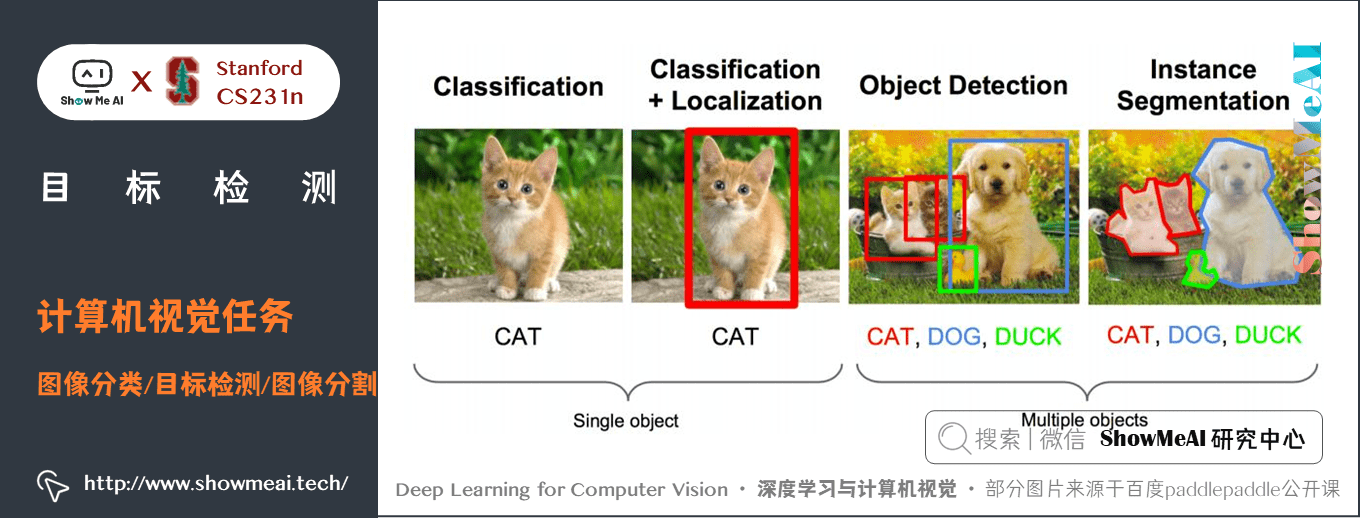
這3大任務其實對應機器視覺理解影象的3個主要層次:
1.1 影象分類(Classification)
影象分類任務中,我們要將影象識別判定為某個類別。它是最簡單、最基礎的影象理解任務,也是深度學習模型最先取得突破和實現大規模應用的任務。大家在前面也瞭解到了 ImageNet 這個權威評測集,每年的ILSVRC催生了大量的優秀深度網路結構,為其他任務提供了基礎。
有一些其他的應用,包括臉部辨識、場景識別等都可以化歸為分類任務來解決。
1.2 目標檢測(Detection)
影象分類任務關心整體圖片類別,而目標檢測則關注特定的物體目標,要求在圖片中,同時識別出目標物的類別資訊和位置資訊(是一個classification + localization的問題)。
相比分類,目標檢測任務要求我們需要從背景中分離出感興趣的目標,並確定這一目標的描述(類別和位置),檢測模型的輸出形式通常是一個列表,列表的每一項使用一個陣列給出檢出目標的類別和位置(常用矩形檢測框的座標表示)。
1.3 影象分割(Segmentation)
影象分割包括語意分割(semantic segmentation)和範例分割(instance segmentation),前者是對前背景分離的拓展,要求分離開具有不同語意的影象部分(相當於畫素級別的分類),而後者是檢測任務的拓展,要求描述出目標的輪廓(相比檢測框更為精細)。
分割是對影象的畫素級描述,它賦予每個畫素類別意義,適用於理解要求較高的場景,如無人駕駛中對道路和非道路的分割,醫療影像中對於不同區域的劃分。
1.4 總結
影象分類對應將影象劃分為單個類別的過程,它通常對應於影象中最突出的物體。實際現實世界的很多影象通常包含多個物體,如果僅僅使用影象分類模型分配單一標籤是非常粗糙的,並不準確。而目標檢測(object detection)模型可以識別一張圖片的多個物體,並可以給出不同物體的具體位置(邊界框)。目標檢測在很多場景有用,如無人駕駛和安防系統。
2. 常用目標檢測(Object Detection)演演算法綜述
2.1 總體介紹
常見的經典目標檢測演演算法如下圖所示:

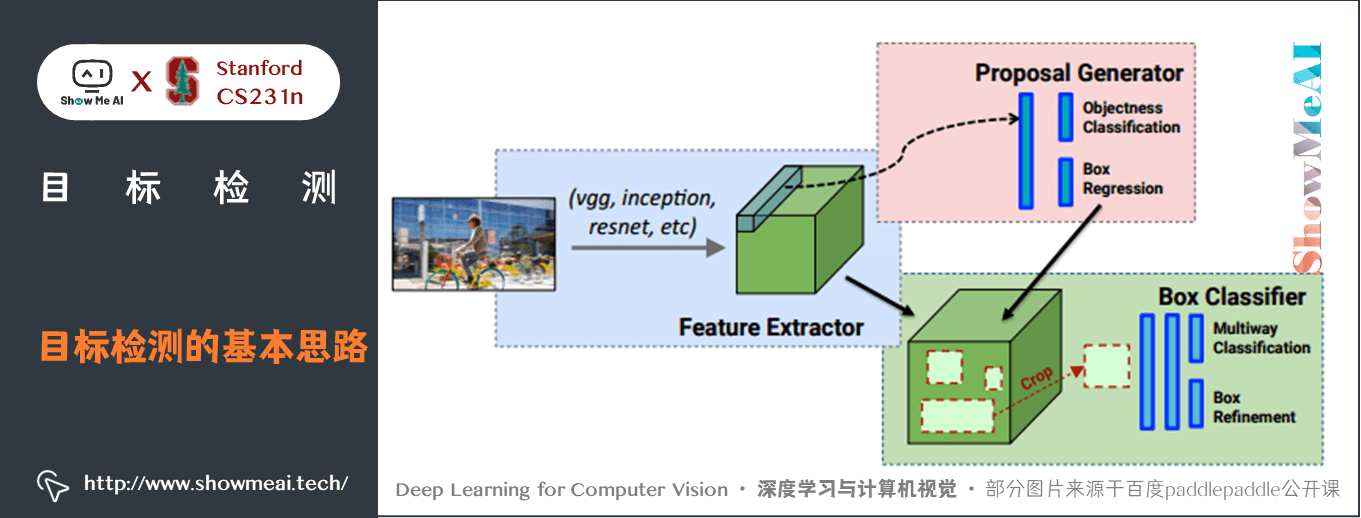
目標檢測的基本思路是:解決定位(localization) + 識別(Recognition) 兩個任務。
一個大致的pipeline如下圖所示,我們可以用同樣的特徵抽取過程,藉助兩個不同的分支輸出。
- 一個分支用於做影象分類,即全連線 + Softmax 判斷目標類別,和單純影象分類區別在於這裡還另外需要一個「背景」類。
- 另一個分支用於識別目標位置,即完成迴歸任務輸出四個數位標記包圍盒位置(例如中心點橫縱座標和包圍盒長寬),該分支輸出結果只有在分類分支判斷不為「背景」時才使用。
2.2 傳統方法
傳統的目標檢測框架,主要包括三個步驟:
- ① 利用不同尺寸的滑動視窗框住圖中的某一部分作為候選區域;
- ② 提取候選區域相關的視覺特徵。比如人臉檢測常用的 Harr 特徵;行人檢測和普通目標檢測常用的 HOG 特徵等;
- ③ 利用分類器進行識別,比如常用的 SVM 模型。
2.3 兩階段vs一階段 方法
現在主流的深度學習目標檢測方法主要分為兩類:兩階段(Two Stages)目標檢測演演算法和一階段(One Stage)目標檢測演演算法。
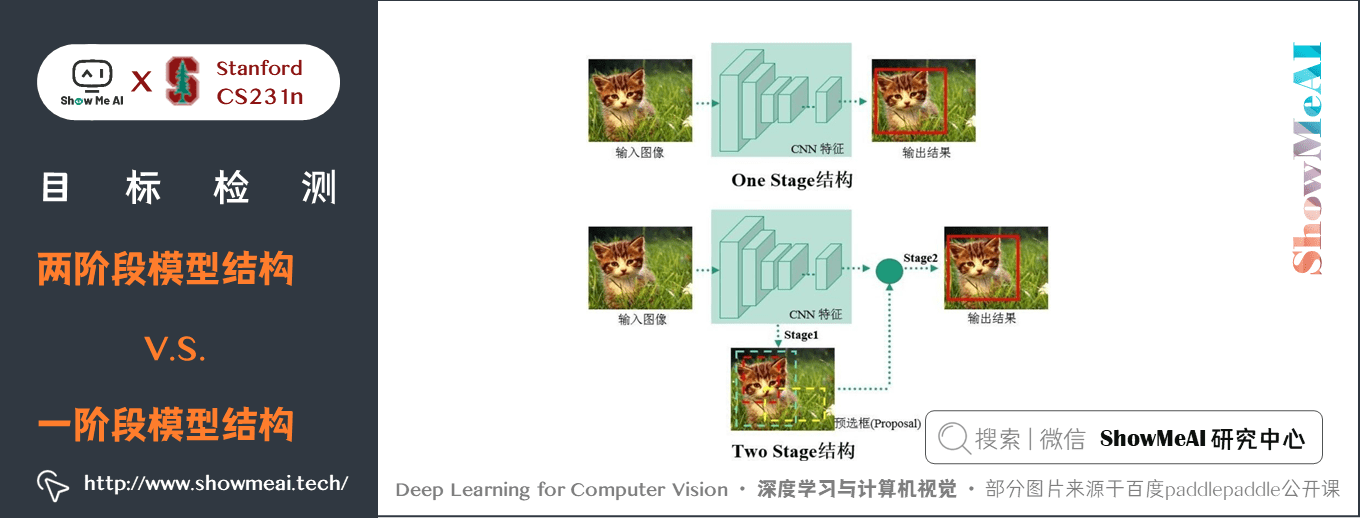
1) 兩階段(Two Stages)
- 首先由演演算法(algorithm)生成一系列作為樣本的候選框,再通過折積神經網路進行分類。
- 常見的演演算法有 R-CNN、Fast R-CNN、Faster R-CNN 等等。
2) 一階段(One Stage )
- 不需要產生候選框,直接將目標框定位的問題轉化為迴歸(Regression)問題處理(Process)。
- 常見的演演算法有YOLO、SSD等等。
上述兩類方法,基於候選區域(Region Proposal)的方法(兩階段)在檢測準確率和定位精度上佔優,基於端到端(一階段)的演演算法速度佔優。相對於R-CNN系列的「兩步走」(候選框提取和分類),YOLO等方法只「看一遍」。
我們在本篇中給大家介紹兩階段的目標檢測方法,主要是R-CNN系列目標檢測方法,在下篇內容目標檢測 (SSD,YOLO系列)中給大家介紹一階段的目標檢測方法(YOLO系列,SSD等)。
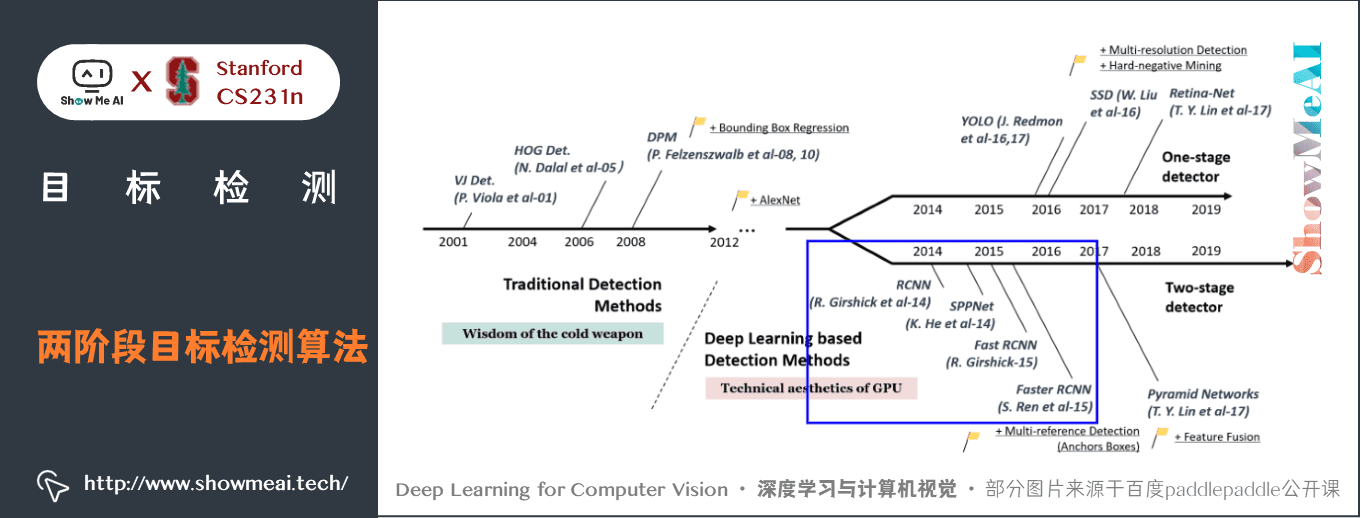
3.兩階段目標檢測演演算法發展史
4.兩階段目標檢測典型演演算法
4.1 R-CNN
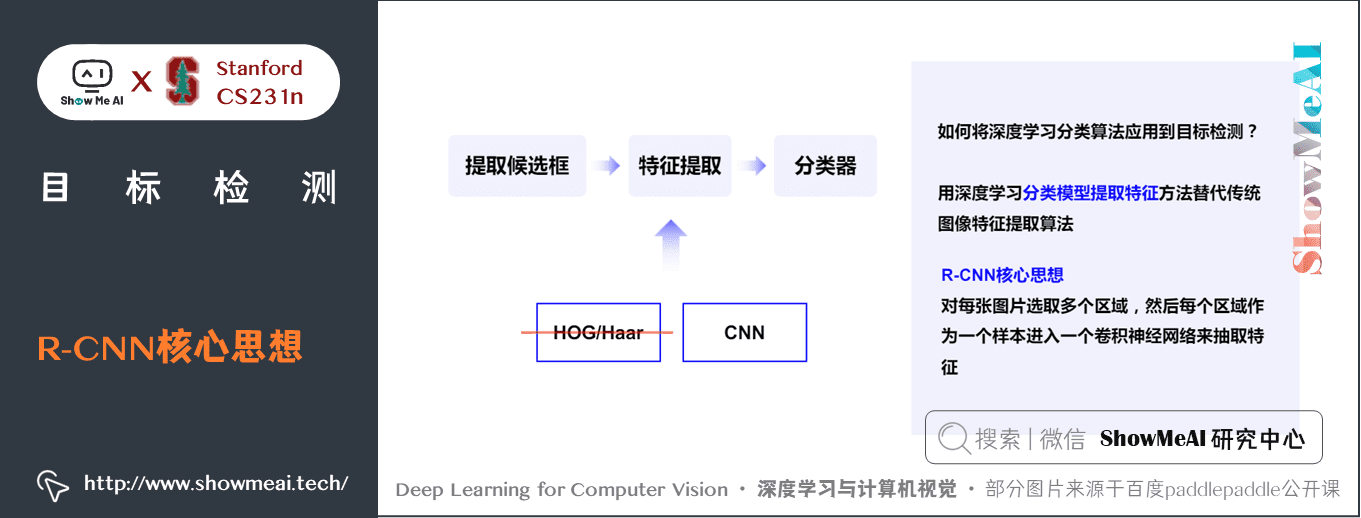
如何將深度學習分類演演算法應用到目標檢測?
- 用深度學習分類模型提取特徵方法代替傳統影象特徵提取演演算法。
R-CNN核心思想: 對每張圖片選取多個區域,然後每個區域作為一個樣本進入一個折積神經網路來抽取特徵。
1) R-CNN網路結構
R-CNN演演算法是較早提出的兩階段目標檢測演演算法,它先找出 Region Proposal,再進行分類和迴歸。
- 所謂 Region Proposal 就是圖中目標可能出現的位置。
- 因為傳統方法需要列舉的區域太多了,所以通過利用影象中的紋理、邊緣、顏色等資訊,可以保證在選取較少視窗(幾千甚至幾百)的情況下保持較高的響應比。所以,問題就轉變成找出可能含有物體的候選框,這些框之間是可以互相重疊互相包含的,這樣我們就可以避免暴力列舉的所有框了。
2) R-CNN應用流程
對於每張輸入的影象,R-CNN目標檢測主要包括下述步驟:
- ① 利用選擇性搜尋 Selective Search 演演算法在影象中從下到上提取 2000個左右的可能包含物體的候選區域 Region Proposal
- ② 因為獲取到的候選區域大小各不相同,所以需要將每個 Region Proposal 縮放(warp)成統一的 \(227 \times 227\) 的大小並輸入到 CNN,將CNN的 fc7 層的輸出作為特徵
- ③ 將每個 Region Proposal 提取到的CNN特徵輸入到SVM進行分類
- ④ 使用這些區域特徵來訓練線性迴歸器對區域位置進行調整

3) R-CNN不足與優化
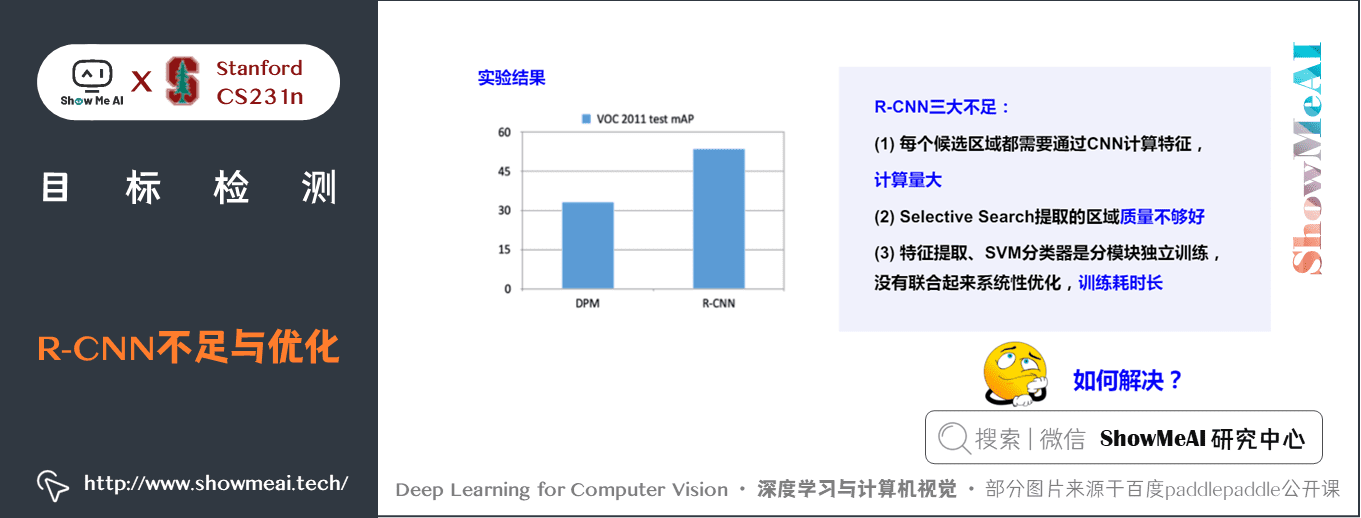
R-CNN 的效果如下圖所示,它有一些不足之處(也是系列演演算法後續改進的點):
- R-CNN 雖然不需要窮舉所有框了,但是它需要對所有ss演演算法選取出的候選框region proposal (2000多個)進行CNN提取特徵 + SVM分類,計算量很大,導致R-CNN檢測速度很慢,一張圖都需要47s。
- Selective search提取的區域質量不夠好
- 特徵提取與後續SVM分類器是獨立訓練的,沒有聯合優化,且訓練耗時長
優化方式為:
- 2000個region proposal是影象的一部分,可以對影象只進行一次折積提取特徵,然後將region proposal在原圖的位置對映到折積層特徵圖上,得到對映後的各個proposal的特徵輸入到全連線層做後續操作。
- 每個region proposal的大小都不一樣,而全連線層輸入必須是固定的長度,因此不能將proposal的特徵直接輸入全連線層,後續改進向R-CNN模型引入了SPP-Net(也因此誕生了Fast R-CNN模型)。
4.2 SPP-Net
1) 設計出發點
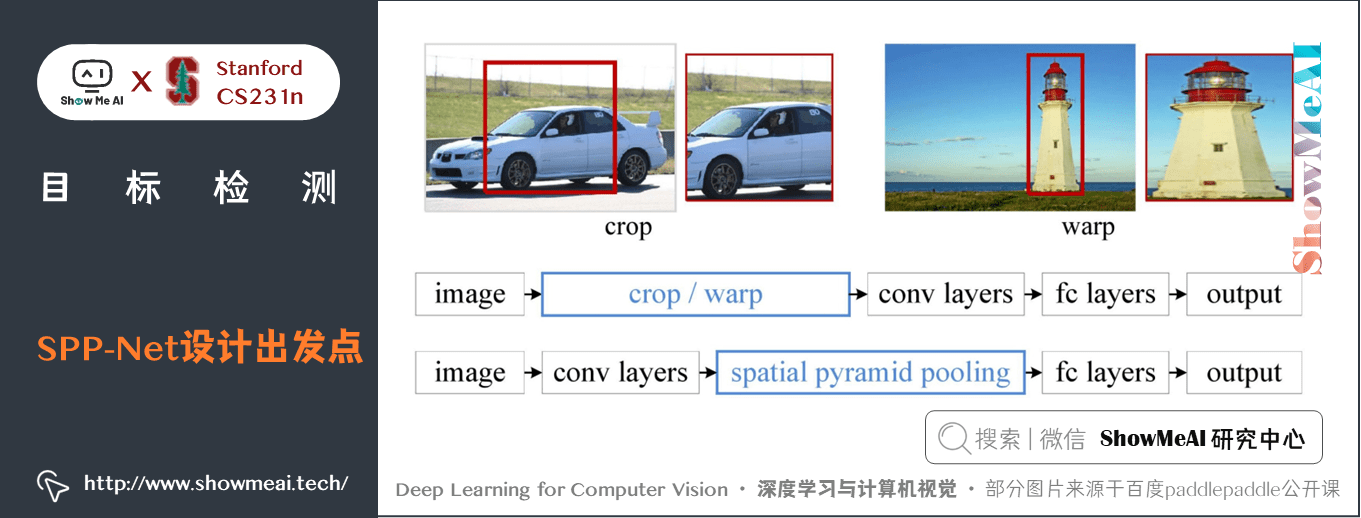
我們通過前面的 CNN 相關知識學習知道,CNN 的折積層不需要固定尺寸的影象,而全連線層是需要固定大小的輸入。所以當全連線層面對各種尺寸的輸入資料時,就需要對輸入資料進行 crop(摳圖)或者 wrap(影象resize)操作。
在 R-CNN中,因為不同的 proposal 大小不同,所以需要先 resize 成相同大小再輸入到 CNN 中。既然折積層是可以接受任何尺寸的,可以在折積層後面加上一部分結構使得後面全連線層的輸入為固定的,這個「化腐朽為神奇」的結構就是 spatial pyramid pooling layer。
下圖是 R-CNN 和 SPP-Net 檢測流程的比較:
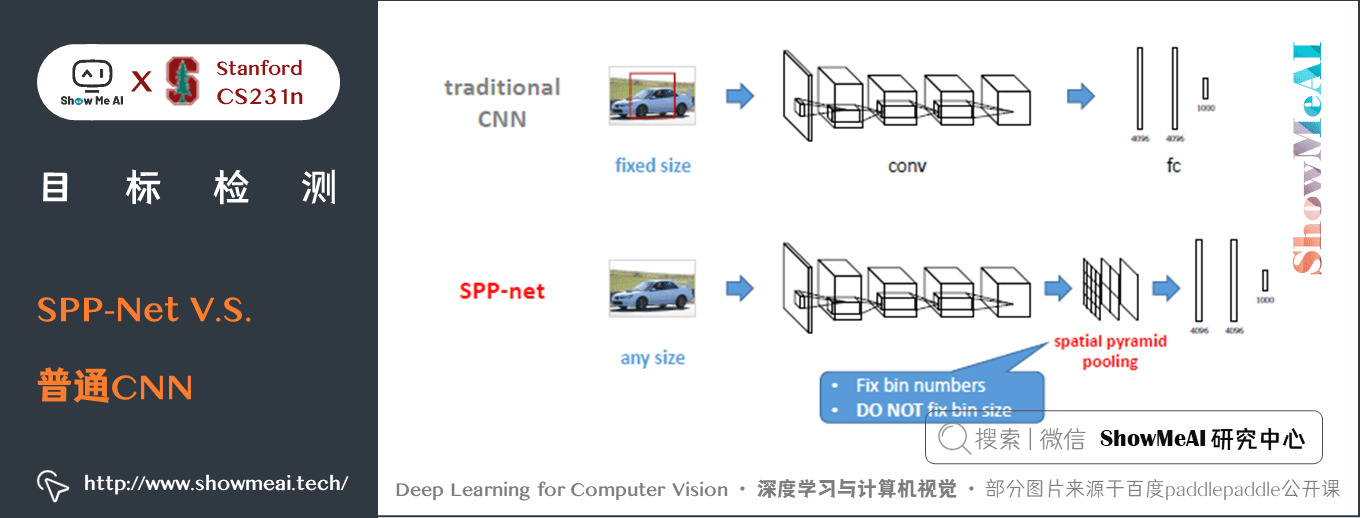
SPP-Net 和普通 CNN 的對比結構如下,在網路結構上,直接把 pool5 層替換成 SPP 層:
SPP-Net 的具體細節如下,由 features map 上確定的 region proposal 大小不固定,將提取的 region proposal 分別經過三個折積 \(4 \ast 4\),\(2 \ast 2\),\(1 \ast 1\) ,都將得到一個長度為 21 的向量(21是資料集類別數,可以通過調整折積核大小來調整),因此不需要對 region proposal 進行尺寸調整:
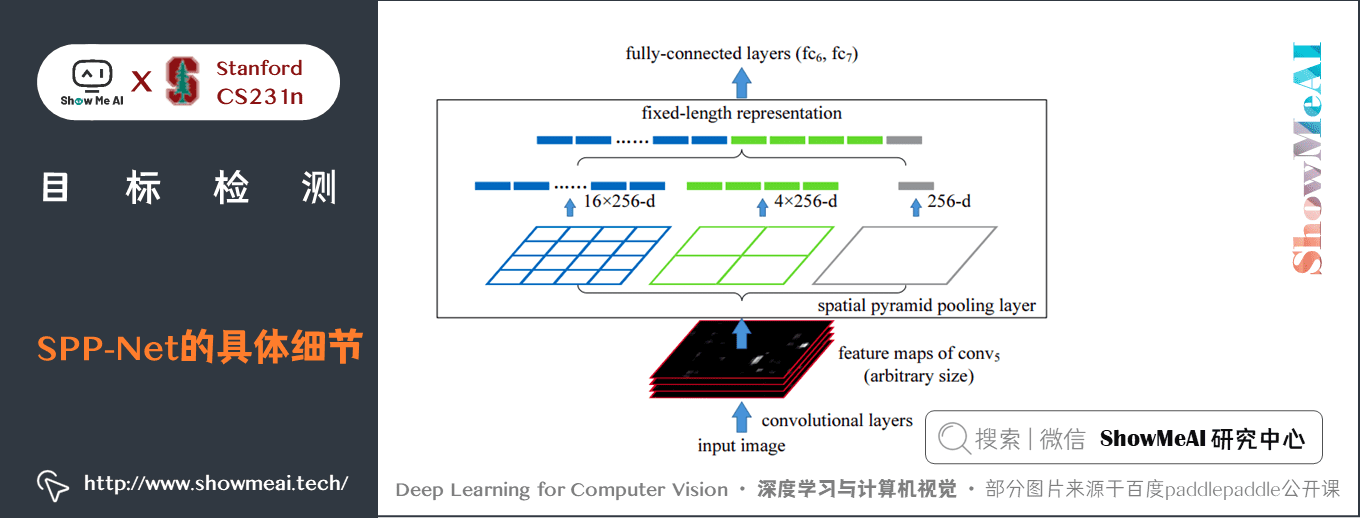
相比R-CNN,SPP-Net有兩大優點。
① 通過「特徵金字塔池化」模組,實現了 CNN 的多尺度輸入,使得網路的輸入影象可以是任意尺寸的,輸出則不變,同樣是一個固定維數的向量。
② R-CNN 要對每個區域計算折積,而 SPPNet 只需要計算一次折積,從而節省了大量的計算時間。
- R-CNN 流程中,先用 ss 演演算法得到2000個proposal分別做折積操作
- SPP-Net 只對原圖進行一次折積計算,得到整張圖的折積特徵feature map,然後找到每個候選框在 feature map 上的對映 patch,將此 patch 作為每個候選框的折積特徵,輸入到 SPP 層以及之後的層,完成特徵提取工作。
4.3 Fast R-CNN
對於 RCNN 速度過慢等問題,提出了基於 RCNN 的改善模型 Fast RCNN。
1) 核心改進
Fast RCNN 主要改進以下部分:
- ① 將 classification 和 detection 的部分融合到 CNN 中,不再使用額外的 SVM 和 Regressor,極大地減少了計算量和訓練速度。
- ② Selective Search 後不再對 region proposal 得到的 2k 個候選框進行擷取輸入,改用 ROI Project,將 region proposal 對映到 feature map 上
- ③ 使用 ROI pooling 將在 feature map 上不同尺度大小的ROI歸一化成相同大小後就可以通過FC層。
2) 核心環節
如下圖所示為Fast R-CNN流程與網路結構
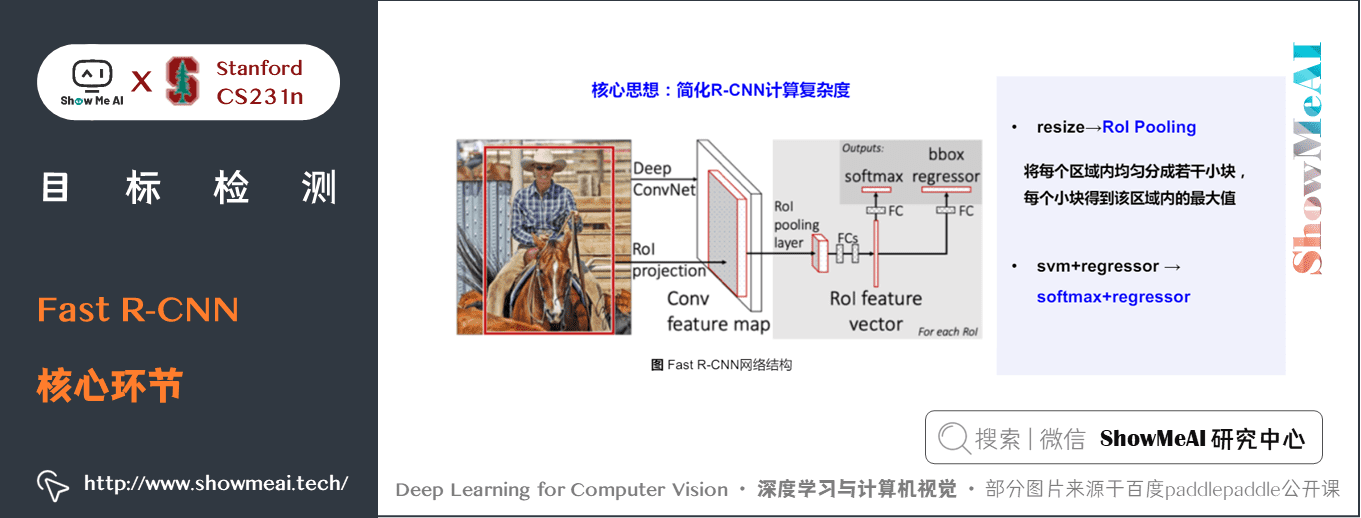
Fast R-CNN具體包括的核心環節如下:
① Region Proposal:與 R-CNN 一致
跟RCNN一樣,Fast-RCNN 採用的也是 Selective Search 的方法來產生 Region Proposal,每張圖片生成 2k 張圖片。但是不同的是,之後不會對 2k 個候選區域去原圖擷取,後輸入 CNN,而是直接對原圖進行一次 CNN,在 CNN 後的 feature map,通過 ROI project 在 feature map 上找到 Region Proposal的位置。
② Convolution & ROI 對映
就是對原圖輸入到 CNN 中去計算,Fast-RCNN 的工具包提供提供了 3 種 CNN 的結構,預設是使用 VGG-16 作為 CNN 的主幹結構。根據 VGG-16 的結構,Fast-RCNN 只用了 4 個 MaxPooling 層,最後一個換成了 ROI Pooling,因此,只需要對 Region Proposal 的在原圖上的 4 元座標 \((x, y, w, h)\) 除以 \(16\),並找到最近的整數,便是 ROI Project 在 feature map 上對映的座標結果。最終得到 \(2k\) 個 ROI。
③ ROI Pooling
對每一個 ROI 在 feature map 上擷取後,進行 ROI Pooling,就是將每個 ROI 擷取出的塊,通過 MaxPooling 池化到相同維度。
ROI Pooling的計算原理是,將每個不同大小的 ROI 平均劃分成 \(7 \times 7\) 的 grid,在每個 grid 中取最大值,最後所有 ROI 都會池化成大小為 \(7 \times 7\) 維度。
④ 全連線層 & 輸出
將每個 ROI Pooling 後的塊,通過全連線層生成 ROI 特徵向量,最後用一個 Softmax 和一個 bbox regressor 進行分類和迴歸預測,得到每個 ROI 的類別分數和 bbox 座標。全連線層為矩陣相乘運算,執行消耗較多,速度較慢,作者在這裡提出可以使用 SVD 矩陣分解來加快全連線層的計算。
⑤ 多工損失
Fast-RCNN 的兩個任務:
- 一個是分類,分為 \(n(種類) + 1(背景)\) 類,使用的是Cross Entropy + Softmax 的損失函數
- 第二個是 Bbox 的 Localization 迴歸,使用跟 Faster-RCNN 一樣的基於 Offset 的迴歸,損失函數使用的是 Smooth L1 Loss,具體原理在下方 Faster-RCNN 中介紹。
3) Fast R-CNN網路效果
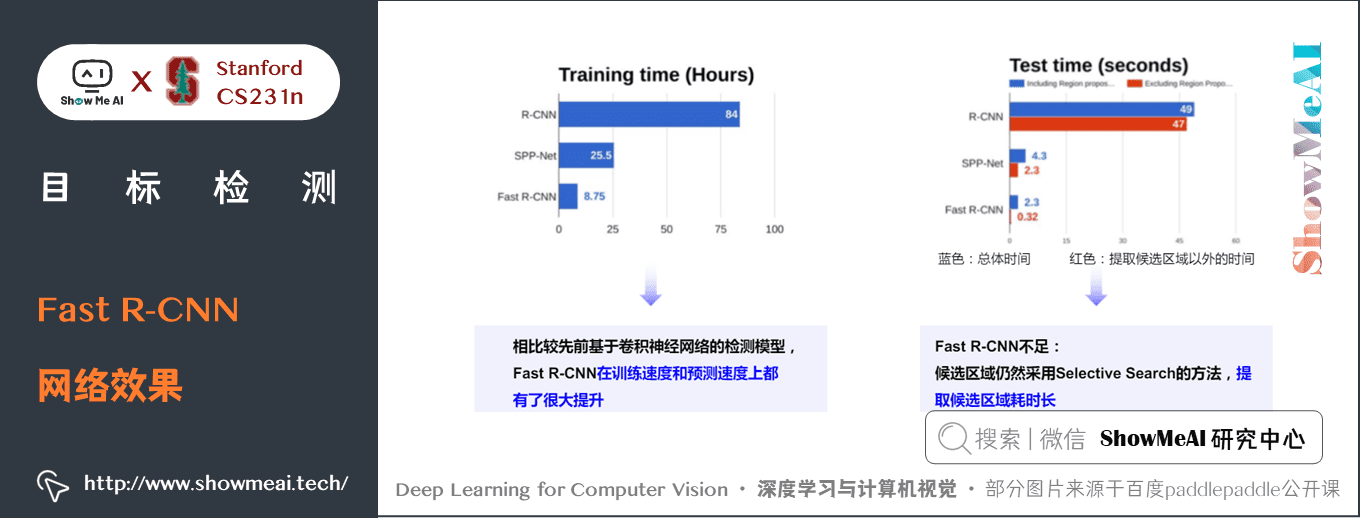
Fast R-CNN 效果如上圖所示,相比之 R-CNN 它在訓練和預測速度上都有了很大的提升,但它依舊有不足之處,大家觀察整個流程,會發現在候選區域選擇上,依舊使用的 Selective Search 方法,它是整個流程中的時間消耗瓶頸,無法用 GPU 硬體與網路進行加速。
4.4 Faster R-CNN
Faster-RCNN 在 Fast-RCNN 的基礎上做了兩個重大的創新改進:
- ① 在 Region Proposal 階段提出了 RPN(Region Proposal Network)來代替了 Selective Search
- ② 使用到了 Anchor
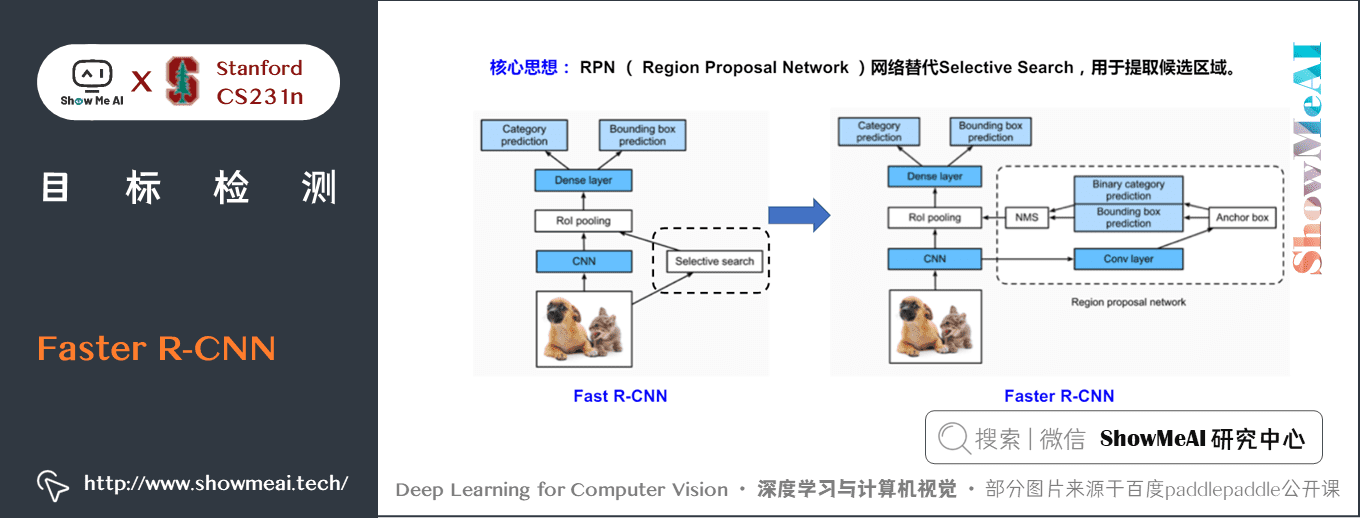
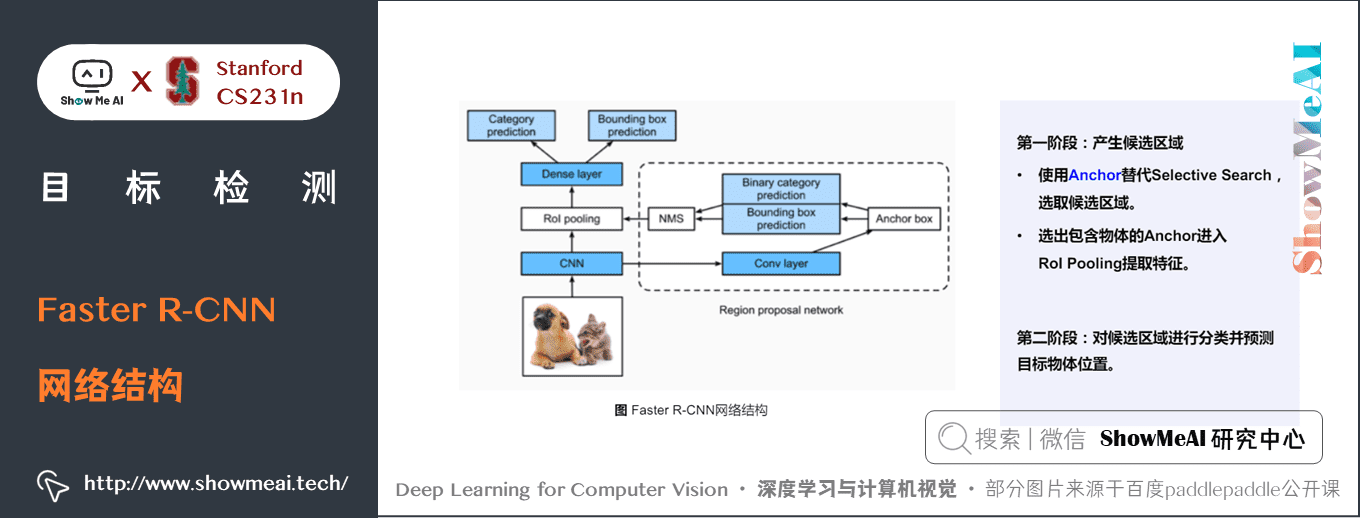
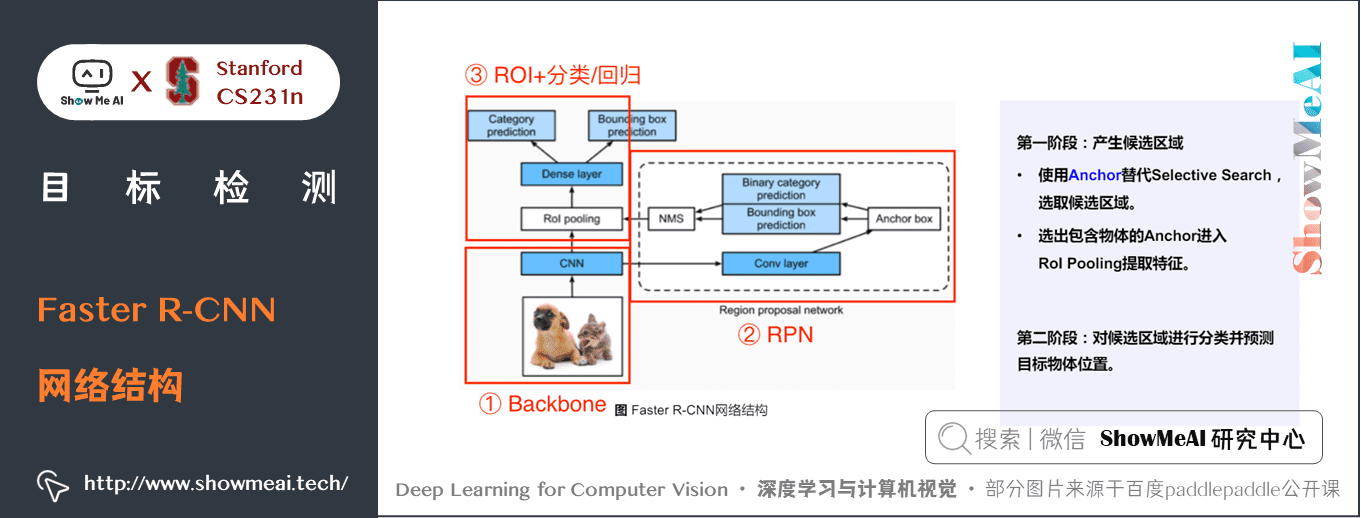
1) Faster R-CNN網路結構
Faster R-CNN的總體流程結構如下,可分為Backbone、RPN、ROI+分類 / 迴歸 三個部分。
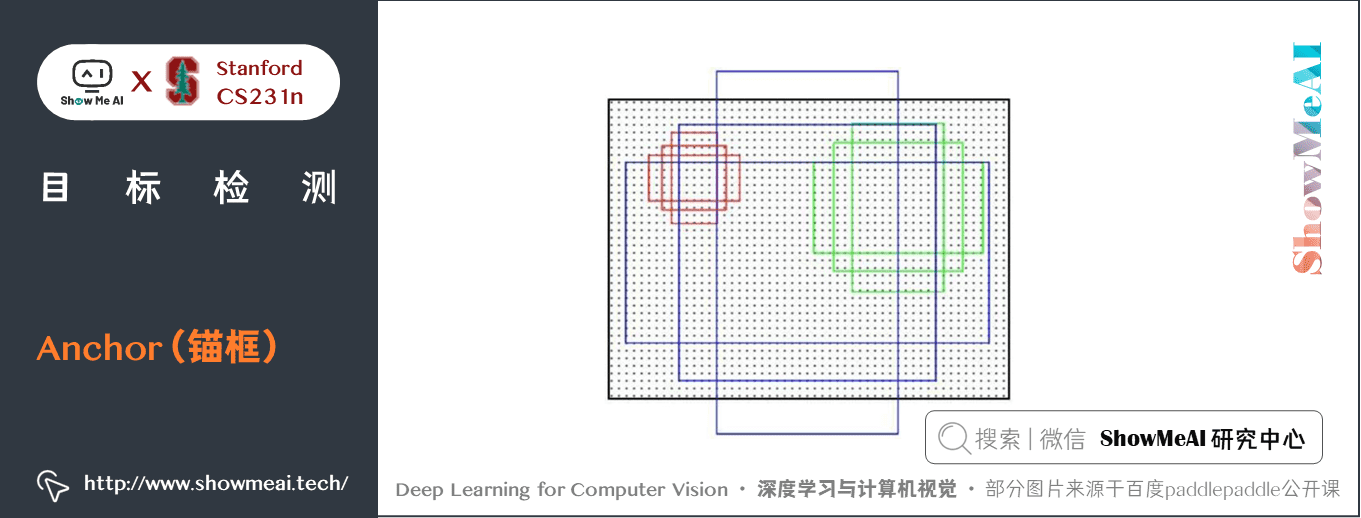
2) Anchor(錨框)
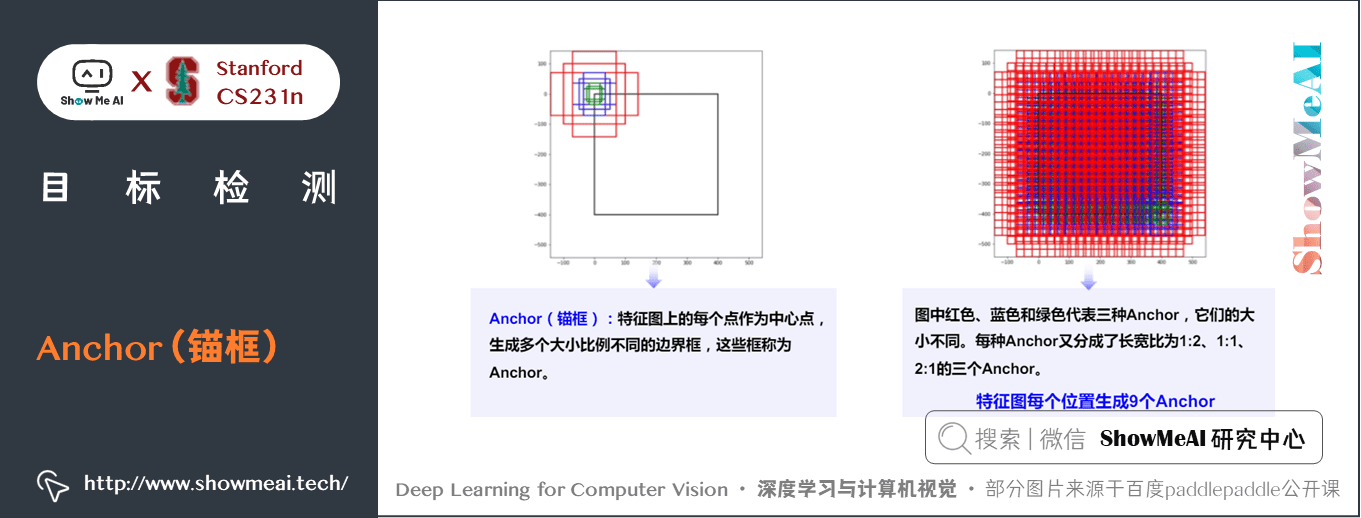
Anchor 是影象檢測領域一個常用的結構,它可以用來表示原圖中物體所在的區域,是一個以feature map 上某個點為中心的矩形框。
Faster-RCNN 的 anchor,在 feature map 上每個點,生成 3 種尺度和 3 種比例共 9 個 anchor。
- 下圖是一個 anchor 的示意圖,每個點會生成尺度為小( \(128\times128\))、中(\(256\times256\))、大(\(512\times512\)),如圖中紅、綠、藍色的anchor,\(1:1\), \(2:1\), \(1:2\) 三種比例共 9 個 anchor。
- 這樣充分考慮了被檢測物體的大小和形狀,保證物體都能由 anchor 生成 region proposal。
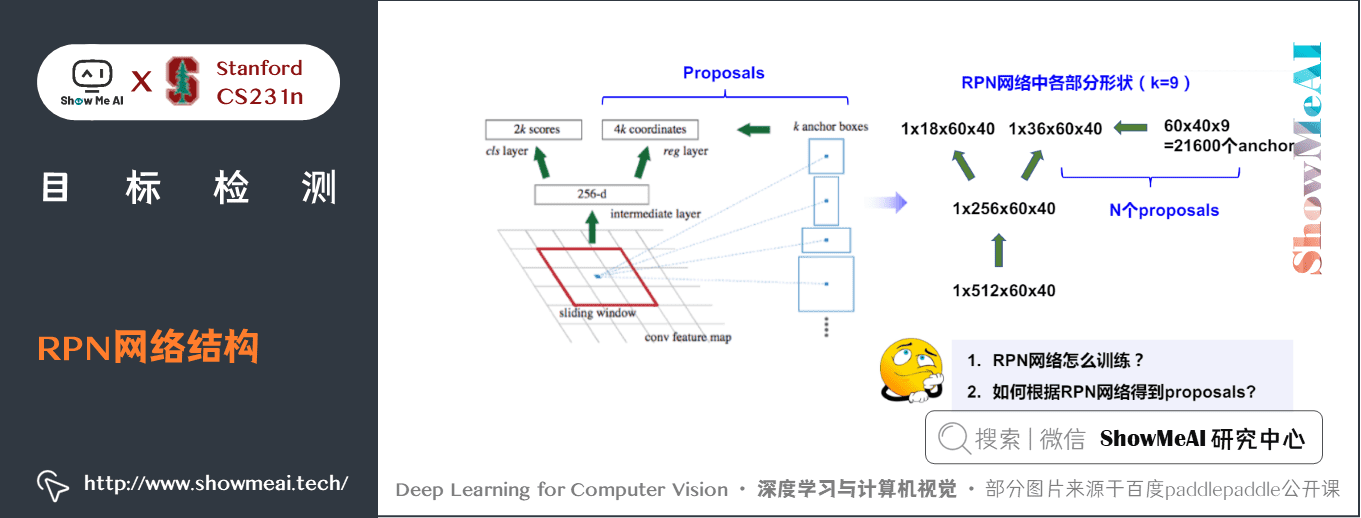
3) RPN網路結構
RPN 是一個全折積的神經網路,它的工作原理可以分成 classification,regression 和 proposal 三個部分
① Classification/分類
Classification 部分將得到的 feature map 通過一個 \(3 \times 3\) 和 \(1 \times 1\) 的折積後,輸出的維度為 \([1 \times 18 \times 38 \times 50]\),這18個channel可以分解成 \(2\times9\),2代表著是否是感興趣物體備選區域(region proposal)的 0/1 的 score,9 代表著 9 個 anchors。
因此,特徵圖維度 \(38\times50\) 的每一個點都會生成 9 個 anchor,每個 anchor 還會有 0/1 的 score。
② Regression/迴歸
Regression 部分原理和 Classification 部分差不多,feature map通過一個 \(3 \times 3\) 和 \(1 \times 1\) 的折積後,輸出的維度為 \([1 \times 36 \times 38 \times 50]\),其中 36 個channel可以分成 \(4 \times 9\),9就是跟 cls 部分一樣的 9 個anchor,4 是網路根據 anchor 生成的 bbox 的 4 元座標 target 的 offset。通過 offset 做 bbox regression,再通過公式計算,算出預測 bbox 的 4 元座標 \((x, y, w, h)\) 來生成 region proposal。
③ Proposal/候選區
將前兩部分的結果綜合計算,便可以得出 Region Proposals。
- 若 anchor 的 \(IoU > 0.7\),就認為是前景
- 若 \(IoU < 0.3\),就認為是背景
- 其他的 anchor 全都忽略
一般來說,前景和背景的 anchor 保留的比例為 \(1:3\)
① RPN網路訓練策略
RPN 網路的訓練樣本有如下的策略和方式:

② RPN網路監督資訊
RPN 網路是監督學習訓練,包含分類和迴歸兩個任務,分類分支和迴歸分支的預測值和 label 構建方式如下:

③ RPN網路LOSS
RPN 網路的總體 loss 由 2 部分構成,分別是分類 loss 和迴歸 loss,為其加權求和結構。其中分類 loss 使用常規的交叉熵損失,迴歸損失函數使用的是 Smooth L1 Loss,本質上就是L1 Loss 和 L2 Loss 的結合。

④ RPN網路迴歸分支Loss
特別說一下回歸部分使用到的 Smooth L1 Loss,對比於 L1 Loss 和 L2 Loss,Smooth L1 Loss 可以從兩方面限制梯度:
- ① 當預測框與 ground truth 的 Loss 很大的時候,梯度不至於像 L2 Loss 那樣過大
- ② 當預測框與 ground truth 的 Loss 較小的時候,梯度值比 L1 Loss 更小,不至於跳出區域性最優解。

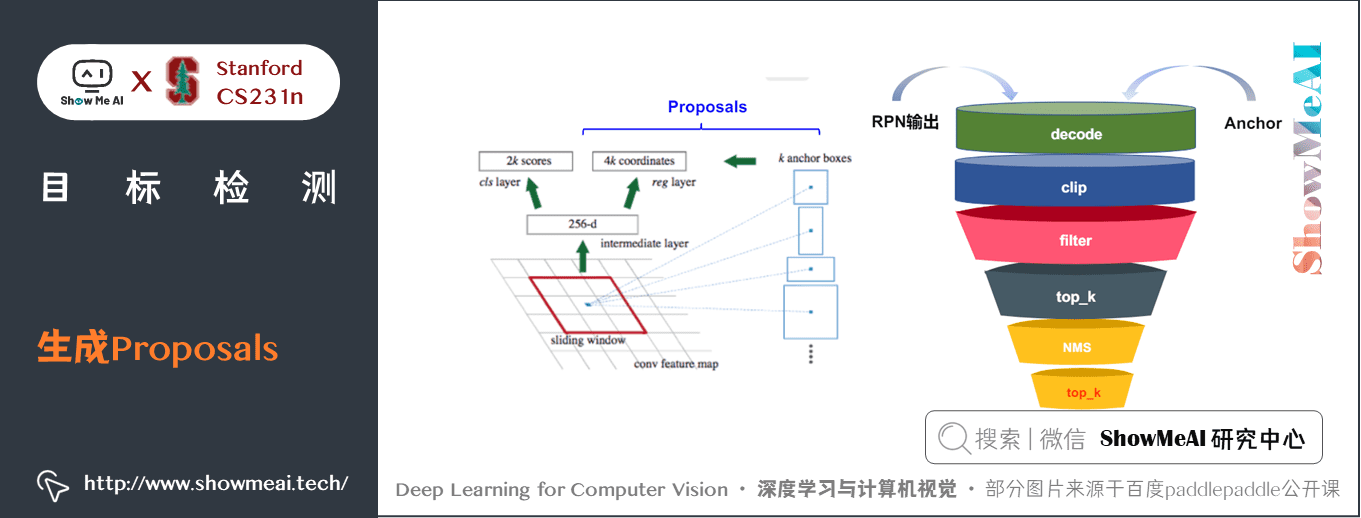
4) 生成Proposals
結合分類和迴歸結果得出 Region Proposals。若 anchor 的 \(IoU > 0.7\),就認為是前景;若 \(IoU < 0.3\),就認為是背景,其他的anchor全都忽略。一般來說,前景和背景的anchor保留的比例為 \(1:3\) 。
得到 Region Proposal 後,會先篩選除掉長寬小於 16 的預測框,根據預測框分數進行排序,取前N(例如6000)個送去 NMS,經過 NMS 後再取前 \(top_k\)(例如300)個作為 RPN 的輸出結果。
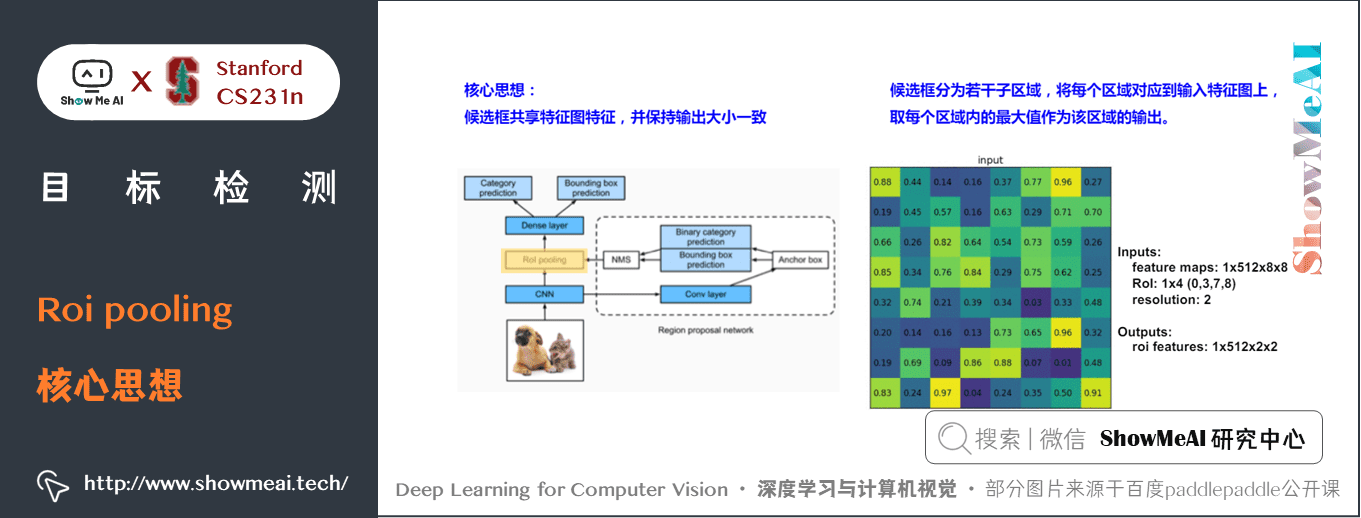
5) Rol Pooling
① Roi pooling核心思想
候選框共用特徵圖特徵,並保持輸出大小一致。
候選框分為若干子區域,將每個區域對應到輸入特徵圖上,取每個區域內的最大值作為該區域的輸出。
② Rol Pooling不足
在 ROI 對映中,涉及到 region proposal 的座標對映變換問題,在這過程中難免會產生小數座標。但是在 feature map 中的點相當於一個個的 pixel,是不存在小數的,因此會將小數座標量化成向下取整,這就會造成一定的誤差。
在 ROI Pooling 中,對每個 ROI 劃分 grid 的時候又會有一次座標量化向下取整。
這樣,整個過程畫素座標會經過兩次量化,導致 ROI 雖然在 feature map 上有不到 1 pixel 的誤差,對映回原圖後的誤差可能會大於 10 pixel,甚至誤差可能會大於整個物體,這對小物體的檢測非常不友好。

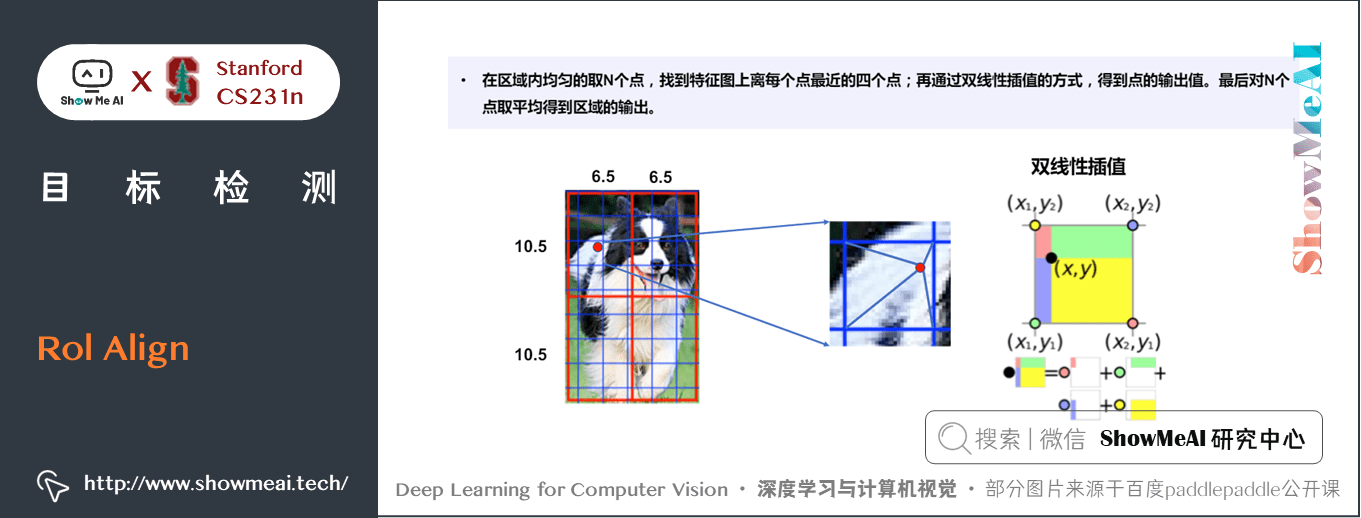
6) Rol Align
Faster R-CNN 中通過 ROI Align 消除 RoI Pooling 中產生的誤差。

ROI Align 的原理是,先將 ROI Project 和 ROI Pooling 時計算出的 ROI 帶小數的座標儲存在記憶體中,不直接量化成畫素座標。
隨後,ROI Align 不取每個 grid 的最大值,而是再將每個 grid 劃分成 \(2\times2\) 的小格,在每個小格中找到中心點,將離中心點最近的四個點的值進行雙線性差值,求得中心點的值,再取每個 \(grid\) 中四個中心點的最大值作為 \(Pooling\) 後的值。
7) BBox Head
下面是分類與迴歸的 BBox 頭部分,它的處理流程展開後如下圖所示:
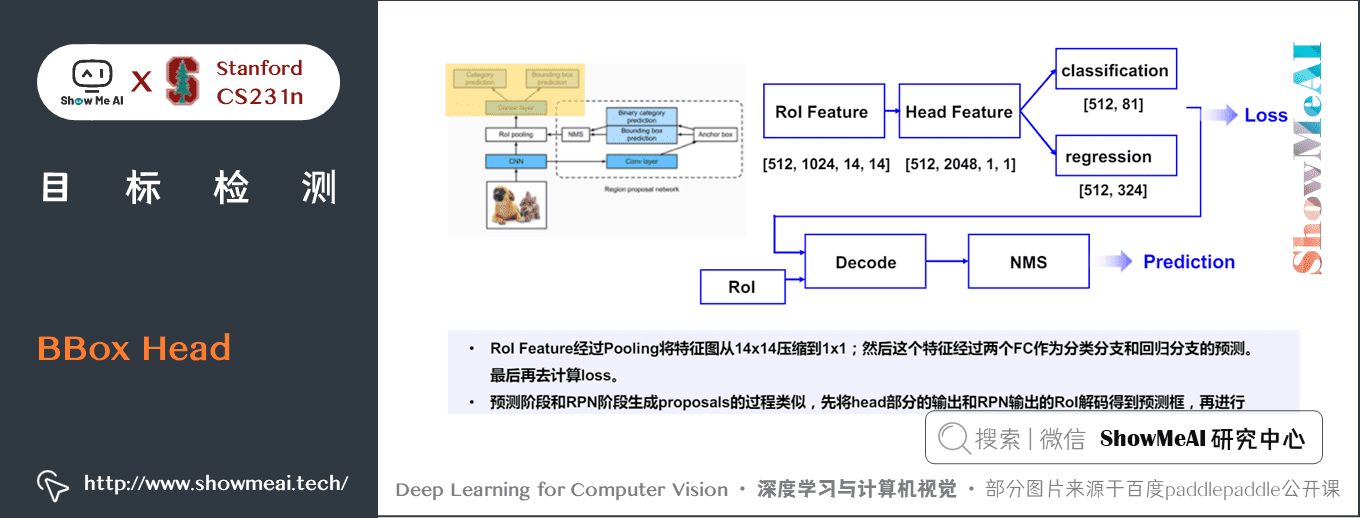
而BBox訓練階段的樣本構建方式如下,我們對比RPN階段的樣本構建方式:

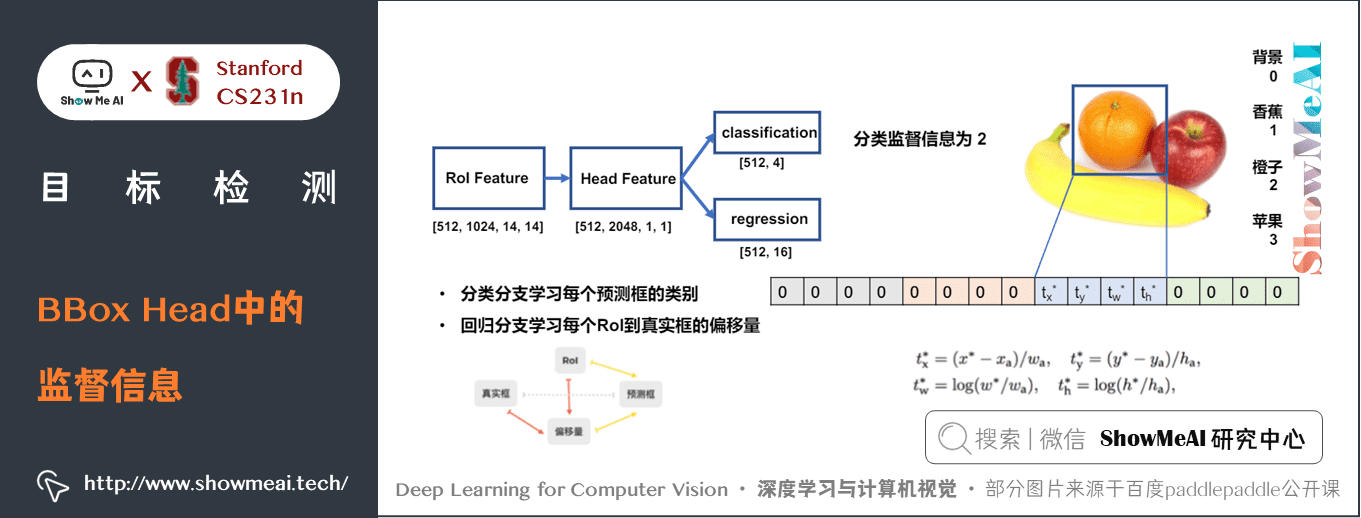
① BBox Head中的監督資訊
BBox頭的分類與迴歸任務的標籤構建方式如下,其中分類分支是典型的分類問題,學習每個預測框的類別;迴歸分支則是學習每個 RoI 到真實框的偏移量。
② BBox Head Loss
BBox 頭的總體 loss 由分類 loss 和迴歸 loss 加權組合構成。

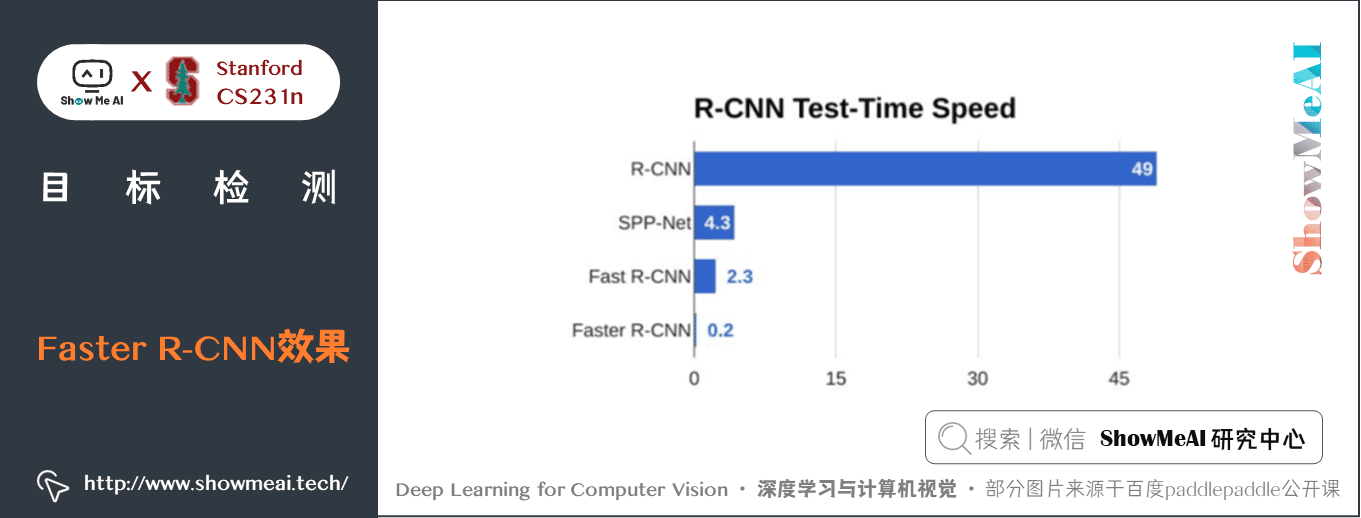
8) Faster R-CNN效果
Faster R-CNN的效果如下圖所示
5.推薦學習
可以點選 B站 檢視視訊的【雙語字幕】版本
- 【課程學習指南】斯坦福CS231n | 深度學習與計算機視覺
- 【字幕+資料下載】斯坦福CS231n | 深度學習與計算機視覺 (2017·全16講)
- 【CS231n進階課】密歇根EECS498 | 深度學習與計算機視覺
- 【深度學習教學】吳恩達專項課程 · 全套筆記解讀
- 【Stanford官網】CS231n: Deep Learning for Computer Vision
斯坦福 CS231n 全套解讀
- 深度學習與CV教學(1) | CV引言與基礎
- 深度學習與CV教學(2) | 影象分類與機器學習基礎
- 深度學習與CV教學(3) | 損失函數與最佳化
- 深度學習與CV教學(4) | 神經網路與反向傳播
- 深度學習與CV教學(5) | 折積神經網路
- 深度學習與CV教學(6) | 神經網路訓練技巧 (上)
- 深度學習與CV教學(7) | 神經網路訓練技巧 (下)
- 深度學習與CV教學(8) | 常見深度學習框架介紹
- 深度學習與CV教學(9) | 典型CNN架構 (Alexnet, VGG, Googlenet, Restnet等)
- 深度學習與CV教學(10) | 輕量化CNN架構 (SqueezeNet, ShuffleNet, MobileNet等)
- 深度學習與CV教學(11) | 迴圈神經網路及視覺應用
- 深度學習與CV教學(12) | 目標檢測 (兩階段, R-CNN系列)
- 深度學習與CV教學(13) | 目標檢測 (SSD, YOLO系列)
- 深度學習與CV教學(14) | 影象分割 (FCN, SegNet, U-Net, PSPNet, DeepLab, RefineNet)
- 深度學習與CV教學(15) | 視覺模型視覺化與可解釋性
- 深度學習與CV教學(16) | 生成模型 (PixelRNN, PixelCNN, VAE, GAN)
- 深度學習與CV教學(17) | 深度強化學習 (馬爾可夫決策過程, Q-Learning, DQN)
- 深度學習與CV教學(18) | 深度強化學習 (梯度策略, Actor-Critic, DDPG, A3C)
ShowMeAI 系列教學推薦
- 大廠技術實現:推薦與廣告計算解決方案
- 大廠技術實現:計算機視覺解決方案
- 大廠技術實現:自然語言處理行業解決方案
- 圖解Python程式設計:從入門到精通系列教學
- 圖解資料分析:從入門到精通系列教學
- 圖解AI數學基礎:從入門到精通系列教學
- 圖解巨量資料技術:從入門到精通系列教學
- 圖解機器學習演演算法:從入門到精通系列教學
- 機器學習實戰:手把手教你玩轉機器學習系列
- 深度學習教學:吳恩達專項課程 · 全套筆記解讀
- 自然語言處理教學:斯坦福CS224n課程 · 課程帶學與全套筆記解讀
- 深度學習與計算機視覺教學:斯坦福CS231n · 全套筆記解讀
