.NET C#基礎(5):結構體
0. 文章目的
本文面向有一定.NET C#基礎知識的學習者,介紹C#中結構體定義、使用以及特點。
1. 閱讀基礎
瞭解C#基本語法
瞭解.NET中的棧與託管堆
2. 值型別
2.1 .NET的兩大型別
在.NET中,所有型別都是object型別的子類,而在object繁多的子類中,又可以將它們歸結為兩種型別:參照型別與值型別,兩者最大的區別在於值型別物件會在棧上分配,而參照型別物件則是在託管堆中分配,由於對棧上資料的操作通常遠遠快於對託管堆中資料的操作,因此對值型別存取與操作通常會更高效。.NET中的值型別有一個最為明顯的特點,就是所有的值型別都繼承自類ValueType。
2.2 ValueType
ValueType是一個繼承自object的特殊抽象類,它是所有值型別的基礎類別,它的意義在於區分值型別與參照型別。然而ValueType本身的定義很簡單,只是重寫了object中的Equals、GetHashCode以及ToString方法,並隱藏了預設構造方法:
public abstract class ValueType
{
protected ValueType() { ... }
public override bool Equals(object obj) { ... }
public override int GetHashCode() { ... }
public override string? ToString() { ... }
}ValueType通過重寫Equals方法,讓其子類的比較行為為比較相等性(而非object預設的用於比較同一性),這也符合「值」的特點-兩個值應該比較是否相等而是否同一。儘管ValueType表面上看起來只是一個普通的抽象類,但是這是用於編譯器的類,編譯器禁止程式設計師顯式從ValueType派生類,也就是說下面的程式碼是不允許的:
class Foo : ValueType { ... } // 不允許從ValueType派生不過將其用作型別宣告是允許的,儘管大多數時候這一行為沒有什麼意義:
ValueType val = 1; // val的型別是ValueType
ValueType Add(ValueType a, ValueType b) { ... } // 將ValueType用於引數型別與返回型別總而言之,型別是否繼承自ValueType是.NET中參照型別與值型別的分界線。
3.3 C#中的值型別
(1)基元型別中的值型別
C#中最基礎的值型別就是其基元型別中的值型別,如下:
| C#基元型別 | 對應的FCL型別 |
| sbyte |
System.SByte
|
| byte |
System.Byte
|
| short | System.Int16 |
| ushort | System.UInt16 |
| int | System.Int32 |
| uint | System.UInt32 |
| long | System.Int64 |
| ulong | System.UInt64 |
| char | System.Char |
| float | System.Single |
| double | System.Double |
| bool | System.Boolean |
| decimal | System.Decimal |
這些型別都是常用且重要的型別,CLR也對上述型別提供了直接操作IL碼,擁有相比於其他型別來說更高的操作效率。
(2)列舉型別
C#中的列舉型別也是值型別,因為所有列舉型別都繼承自Enum型別,而Enum型別則繼承自ValueType。列舉型別相比基元型別更復雜,需要一定的篇幅講解,但考慮到本文重點,這裡不做過多介紹。
(3)自定義值型別:結構體
C#也允許程式設計師通過使用struct來定義自己的值型別,這一型別被稱為結構體。定義一個結構體的定義和定義一個類在語法上沒有太大的區別,下面是一個簡單的結構體的範例:
struct Point
{
public float X;
public float Y;
}上述程式碼定義了一個名為Point的結構體,該結構體中有兩個float型別的欄位,名為X與Y。你會發現其和定義一個類的區別似乎僅在於將class關鍵字替換為了struct。甚至在使用上也幾乎與普通的類無異:
Point p = new Point();
p.X = 1;然而這只是表面上看起來,由於使用了struct來定義Point,Point現在是一個值型別而非參照型別,意味著它遵守值型別棧上分配的規則,同時還有一些更深層次的東西。
3.4 與C++的不同
如果你寫過C++,可能使用下面的方法來決定物件的分配方式:
Point p; // 分配到棧
Point* p = new Point(); // 分配到堆但在.NET中,你會意識到物件究竟會分配到棧還是分配到堆並不在分配時決定,而是在定義型別時就決定了(當然另一方面,C++中可以通過對解構函式與new運運算元的私有化來實現在定義時限定分配方式)。
3. C#中的結構體
3.1 定義與使用結構體
3.1.1 定義
一個結構體的定義非常簡單,從語法上來說只需要將定義一個類使用的class關鍵字替換為struct即可,如下:
public struct Point
{
public float X;
public float Y;
}同樣和定義類一樣,你可以定義為結構體新增存取修飾符,例如上述定義中就為其新增了public存取修飾符。同樣的,你也可以在結構體中定義屬性,方法,甚至事件。
3.1.2 使用
結構體的使用也非常簡單,和類的使用基本一致:
Point p = new Point(); // 範例化一個Point
p.X = 1; // 將p的欄位X的值設為1
int x = p.X; // 獲取p的欄位X的值 簡而言之,從語法層面來說,結構體的定義與使用和類的定義與使用沒有太大的差別,兩者大多數的操作基本可以通用。真正讓結構體與類區分開來的是它作為的值型別特點。
3.2 結構體的特點
3.2.1 棧上分配
在前文對值型別的簡介中已經提到過,值型別在範例化時物件會被直接分配到棧上。而參照物件的變數只有在範例化的時候才會分配實際所需的記憶體:
FooClass foo; // 此處只是宣告了一個FooClass物件的參照,FooClass範例尚未建立
foo = new FooClass(); // 到這裡才實際分配了所需記憶體並範例化了一個FooClass物件而值型別是棧上物件,意味著當你宣告值型別的變數後就會立馬分配記憶體:
FooStruct foo; // 立馬在棧上分配可以容納FooStruct大小的記憶體,並將所有欄位初始化為0
FooStruct foo = new FooStruct(); // 同上,但是語意更明確儘管上述程式碼的第一種寫法無法通過編譯,但這只是編譯器的要求,第一行程式碼和第二行程式碼的作用在預設情況下完全相同(預設情況是指使用結構體的自動生成的構造方法)。你可以認為,棧上物件的記憶體分配在你寫下的一瞬間就決定好了。你可以嘗試如下程式碼來體會這一區別:
????? Foo {
public long A;
public long B;
public long C;
public long D;
public long E;
}
var foos = new Foo[100 * 100 * 100];
Console.WriteLine(GC.GetTotalAllocatedBytes());上述程式碼執行時會輸出程式執行時分配過的記憶體大小,將開頭的‘?????’替換為class或struct,你會發現當其為struct時程式所佔的記憶體明顯高於其為class時,原因在於當Foo為struct時陣列中的每一項所佔的記憶體就是儲存一個Foo物件所需要的所有空間,而為class時則只會儲存一個參照所佔的記憶體(通常為8位元組或4位元組,取決於平臺設定)。就像下圖這樣:

分配到棧是值型別的重要特徵,理解這一點對於值型別的很多性質的理解以及正確使用值型別有巨大幫助。
3.2.2 無繼承
結構體不支援繼承,所有的結構體都是隱式密封的,也就是說,下面的程式碼是不可行的:
struct Foo { }
struct Foo2 : Foo { } // 結構體不允許繼承但是結構體可以實現介面:
struct Foo : IEquatable<Foo> { ... }關於為何結構體不可繼承,其中一個重要的原因是由於結構體所代表的值型別需要直接分配到棧上,在入棧出棧的時候必須能夠確定其資料大小,因此結構體需要提供明確固定的大小。如果允許繼承,下面這種情況是難以預測的:
struct Foo { }
struct Foo2 : Foo { }
Foo foo;
foo = new Foo();
foo = new Foo2();foo的尺寸應該以Foo為準還是以Foo2為準?答案是Foo,然而根據「基礎類別參照可以指向派生類參照」這一規則,foo應該也可以指向Foo2的範例。然而值型別是棧上分配,其記憶體大小在宣告的一瞬間就已經確定,顯然如果Foo2中有額外的欄位,已分配給Foo物件的棧空間中將沒有額外的儲存空間容納這些欄位,另外從事實上來說,foo甚至不是一個參照。所以結構體不允許繼承是理所當然的。
3.3.3 副本式賦值
對一個參照型別進行賦值的時候,獲得的是對指向物件的參照:
class Foo
{
public int Value;
}
Foo f1 = new Foo();
Foo f2 = f;
f2.Value = 10;
Console.WriteLine(f1.Value);上述程式碼將輸出10,儘管是對f2賦值,但是實際上是將f1所指向的物件的參照賦值給了f2,此時f1與f2指向的是同一個物件,因此f2修改Value的值時等同於修改f1指向的物件的Value的值。但對於值型別來說則不如此:
struct Foo
{
public int Value;
}
Foo f1 = new Foo();
Foo f2 = f;
f2.Value = 10;
Console.WriteLine(f1.Value);上述程式碼將輸出0,這是上述的賦值行為實際是將f的副本賦值給了f2,也就是說,不同於Foo為類時f1與f2指向的是同一個物件,f2在此時持有的是一個和f相同的副本,兩者互不相干,因此修改f2的Value不會影響f1的值。
結構體的賦值方式如下:
- 範例化一個相同型別的結構體,作為副本
- 將當前結構體各個欄位的值逐一賦給建立的副本中相同的欄位
不只於賦值操作,結構體作為方法引數、方法返回值時也是按值傳遞:
????? Foo
{
public int Value;
}
void IncreaseValue(Foo foo)
{
foo.Value += 1;
}
Foo f1 = new Foo();
IncreaseValue(f1);
Console.WriteLine(f1.Value);若Foo定義為class,則上述程式碼輸出的為1,若Foo為struct,上述程式碼輸出為0。原因是定義為class時,將f1作為引數傳入後foo獲得的是f1對其參照物件的參照,因此foo此時指向的就是f1指向的物件;而定義為struct時,foo此時獲取的是f1的副本。這一行為有時候會帶來一些奇怪的表現,例如:
struct CatCard
{
public int ID;
}
class Cat
{
public CatCard Card { get; } = new CatCard();
}
Cat cat = new Cat();
cat.CatCard.ID = 10;上述程式碼嘗試修改直接修改Cat中CatCard屬性的ID欄位,咋一看好像沒問題,但實際上上述程式碼甚至無法通過編譯。不要忘記一個很重要的點:屬性的本質是方法,因此上面的賦值程式碼的實質如下:
CatCard card = cat.get_Card();
card.ID = 10;你可能已經發現問題了:get_Card()返回了一個CatCard物件,然而根據值型別按副本賦值的特點,get_Card()返回的其實是Cat中Card屬性的副本,因此card此時並不是表示Cat中的Card,而是其副本,這意味著對card的修改將不會對Cat的Card屬性產生任何影響。為了防止潛在的程式設計錯誤,這一行為會被編譯器阻止。
不過,就像C++中可以按參照傳遞棧上物件一樣,C#也支援通過參照傳值而直接修改原始資料,具體方法會在後文提到。
3.4. 特殊結構體
3.4.1 唯讀結構體(readonly)
基元型別中的值型別的範例是不可變的,例如,下面的程式碼是無法通過編譯的:
1 = 2;(字面值1可以視為Int32的一個範例)
這一點很容易理解,將數位2賦值給數位1從數學上來說是及其令人困惑的,因此基元型別的值型別都是不可變型別。不可變型別可以帶來諸多好處,例如更安全的程式設計,可以基於不可變做出許多假設而進行優化等等,因此將型別定義為不可變型別是有意義的。你可以通過在結構體中只宣告唯讀欄位來保證這一點:
struct Point
{
public readonly float X;
public readonly float Y;
}這樣當Point的範例建立後就無法修改其成員值了。當然這個結構體沒有什麼意義,因為它的X和Y值將永遠是0。為此,你還需要提供構造方法來允許在範例化時指定欄位的值:
struct Point
{
public readonly float X;
public readonly float Y;
public Point(float x, float y)
{
X = x;
Y = y;
}
}
Point p = new Point(1, 2); // 使用範例儘管如此,有時在編碼時依然可能出現失誤而導致忘記將某個欄位設定為唯讀欄位,並且只是在對欄位宣告唯讀顯然缺乏更清晰的語意,因此C#還提供了一種語法來宣告‘唯讀結構體’,唯讀結構體的所有的欄位必須宣告為唯讀欄位,否則會出現編譯錯誤:
readonly struct Point
{
public readonly float X;
public readonly float Y;
public float Z; // 編譯錯誤,欄位必須為唯讀
}如上,在struct關鍵字前新增readonly關鍵字,即可將結構體宣告為唯讀結構體。編譯器會為readonly結構體加上IsReadonlyAttribute,因此上述程式碼會被翻譯為如下:
[System.Runtime.CompilerServices.IsReadOnly]
struct Point
{
public readonly float X;
public readonly float Y;
}(當然,IsReadonlyAttribute是一個internal的類,主要用於標記後設資料,程式設計師不應該使用它)
除了唯讀欄位外,同樣還可以宣告唯讀屬性:
struct Point
{
public float X { get; }
public float Y { get; }
}和類的唯讀屬性一樣,結構體的唯讀屬性同樣是依賴一個唯讀欄位實現。同樣的,你可以設定init存取器來允許在‘物件初始值設定項’中初始化欄位的值,避免定義過多的構造方法:
struct Point
{
public float X { get; init; }
public float Y { get; init; }
}
Point p = new Point()
{
X = 1,
Y = 2
};此外你還可以定義唯讀方法:
struct Point
{
// ... 省略其他程式碼
public readonly void Print()
{
// X = 1; // 不允許的操作
Console.WriteLine(X + Y);
}
}被readonly修飾的方法意味方法做出保證:不會修改範例狀態,也就是說readonly方法中不能對欄位進行賦值操作,只能存取欄位。因此如果將上面Print方法的X = 1那一行取消註釋,編譯器將會報錯,因為它嘗試修改結構體的狀態。
3.4.2 僅棧分配結構體(ref)
‘結構體分配到棧上’這一重點被反覆強調,然而有時候可能並不是那麼簡單:
struct Point
{
public float X;
public float Y;
}
class Square
{
public Point Position;
}
Square square = new Square();上述程式碼中,Square的Position欄位並沒有分配到棧上,反而是和Square的範例一起被分配到了託管堆中。除此之外,裝箱也會導致結構體範例分配到託管堆:
Point point = new Point();
object obj = point; // 裝箱,結構體轉移到託管堆上述程式碼從邏輯上來說是可行的,但有時候因為效能要求或者種種原因我們希望結構體只能分配到棧上,此時便可以使用僅棧分配結構體,即ref結構體:
ref struct Point
{
public float X;
public float Y;
}儘管ref這一關鍵字讓人疑惑,但是在struct關鍵字前新增ref確實是指將結構體宣告為只能在棧上分配的結構體,對於這種結構體,任何可能將其轉移到託管堆的行為都將被阻止(例如在參照型別中定義ref結構體欄位,或者進行裝箱操作):
class Square
{
public Point Position; // 錯誤,Position會隨著Square範例轉移到託管堆
}
Point point = new Point();
object obj = point; // 錯誤,point會被裝箱到託管堆ref結構體保證了結構體只能在棧上分配,但是也因此有了諸多限制,MSDN上指出了ref結構體的的使用限制:
- 不能是陣列的元素型別。
- 不能是類或非 ref 結構的欄位的宣告型別。
- 不能實現介面。
- 不能被裝箱為 System.ValueType 或 System.Object。
- 不能是型別引數。
- 不能由 lambda 表示式或本地函數捕獲。
- 不能在 async 方法中使用。 但是,可以在同步方法中使用 ref 結構變數,例如,在返回 Task 或 Task<TResult>的方法中使用結構變數。
- 不能在迭代器中使用。
需要說明的是,你可以宣告在其他ref結構體中宣告ref結構體欄位,因為ref結構體保證棧上分配:
ref struct AlsoPoint
{
public Point Point; // 允許,因為XPoint同樣保證了棧上分配
}另外,你可以宣告唯讀ref結構體:
readonly ref struct Point
{
public Point Point; // 允許,因為XPoint同樣保證了棧上分配
}(注意,readonly關鍵字必須位於ref之前)
ref結構體可以讓程式設計師對結構體的分配做出預設,從而放心實現一些高效能的庫。例如Span<T>與ReadOnlySpan<T>就是對ref結構體的具體應用。
3.4.3 記錄結構體(record)
record是一個新的概念,闡述它需要一定的篇幅,這不是本文的重點,因此這裡不多做闡述,只是簡單說明以下可以將結構體也宣告為記錄:
record struct Point
{
public float X;
public float Y;
}從實質上來講,記錄結構體就是實現了IEquatable<>介面,重寫了ToString、GetHashCode與Equals方法,並過載了==與!=運運算元的結構體,不過這些操作均由編譯器自動完成。另外,同樣可以用下面的語法宣告宣告記錄結構體:
record struct Point3(float X, float Y);上述程式碼的對等程式碼大概如下:
檢視程式碼
record struct Point
{
private float _x;
private float _y;
public float X
{
get => this._x;
set => this._x = value;
}
public float Y
{
get => this._y;
set => this._y = value;
}
public Point(float X, float Y)
{
this._x = X;
this._y = Y;
}
public void Deconstruct(out float X, out float Y)
{
X = this.X;
Y = this.Y;
}
}(注意Point的X和Y是被定義為屬性而非欄位,並且這種宣告方式還實現了Deconstruct解構方法)
同樣的,可以宣告唯讀記錄結構體。
3.4.4 不安全結構體(unsafe)
所謂不安全結構體就是允許出現不安全成員的結構體,例如:
unsafe struct Window
{
public void* Handle;
}Handle是一個void*指標,是不安全程式碼,因此使用該欄位的結構體需要宣告為unsafe。unsafe結構體不是什麼新東西,只是unsafe作用於結構體範圍的體現,不安全程式碼也不是本文重點,故這裡不多做闡述。
3.4.5 多特性結構體
可以將readonly、record、ref、unsafe等修飾符組合,來建立諸如‘唯讀ref結構體’、‘唯讀記錄結構體’、‘唯讀不安全結構體’等具有多種特性的結構體。鑑於這些結構體只是相應修飾符含義的組合,這裡不過多闡述。
4. 對結構體的特殊操作
4.1 按參照傳遞值型別
來看下面的一個例子:
struct Point
{
public int X;
public int Y;
}
void AddX(Point point)
{
point.X += 1;
point.Y += 1;
}
Point p = new Point();
AddX(p);
Console.WriteLine(point.X);上述程式碼中將輸出0。請記住結構體預設是副本式複製,也就是說上述程式碼中呼叫AddX方法,並將p作為引數傳入後,方法中的point只是p的副本而非p本身,因此對point的改變不會影響到p。但有時候確實需要通過方法直接修改p的值,此時可以使用按參照傳遞:
void AddX(ref Point point)
{
point.X += 1;
point.Y += 1;
}
Point p = new Point();
AddX(ref p);
Console.WriteLine(point.X);現在AddX方法的point現在是一個ref引數,傳遞引數p時,point此時直接指向p所在的資料地址,因此修改point的值等同於直接修改p。ref引數並不奇怪,你很可能已經用過了。但現在回過頭來看前文的一個例子:
struct CatCard
{
public int ID;
}
class Cat
{
public CatCard Card { get; } = new CatCard();
}
Cat cat = new Cat();
cat.CatCard.ID = 10; // 報錯上述程式碼無法通過編譯,然而如果將上述程式碼中Cat的Card屬性修改為欄位,則程式碼可以正常執行:
class Cat
{
public CatCard Card = new CatCard(); // 修改為欄位
}
Cat cat = new Cat();
cat.CatCard.ID = 10; // 此時可以通過編譯這是由於屬性的本質是方法,因此當Card為屬性時,其等效程式碼類似如下:
struct CatCard
{
public int ID;
}
class Cat
{
private readonly CatCard _card = new CatCard();
public CatCard get_Card()
{
return this._card;
};
}
Cat cat = new Cat();
cat.get_Card().ID = 10; // 報錯請思考一下為何編譯器不允許上述程式碼:get_Card是方法,返回一個CatCard型別的物件,而CatCard是一個結構體,這意味著該方法返回的將是欄位_card的副本而非_card欄位本身,因此修改get_Card的返回值不會對_card欄位本身造成任何影響,而僅僅是修改_card欄位的一個臨時副本的X,並在修改完成後就丟棄此副本。由於這一問題會導致人對程式碼本身做的事產生誤解而編寫出錯誤的程式碼,因此C#編譯器禁止了上述行為。但就像按引數可以參照傳遞一樣,返回值也可以按參照返回,因此,你可以寫出如下程式碼:
class Cat
{
// ... 省略其他程式碼
public ref CatCard get_Card()
{
return ref this._card;
};
}
Cat cat = new Cat();
cat.get_Card().ID = 10; // 正確,get_Card()返回的是欄位_card的參照注意cat.get_Card().ID = 10等效程式碼如下:
ref CatCard card = ref cat.get_Card(); // 而不是CatCard card = cat.get_Card(),否則card依然只是副本
card.ID = 10回到屬性上,你可以宣告按參照返回的值型別屬性:
class Cat
{
private readonly CatCard _card;
public ref CatCard Card
{
get
{
return ref this._card;
}
}
}
Cat cat = new Cat();
cat.CatCard.ID = 10; // 正確基於顯而易見的原因,這種屬性不能有set存取器。
4.2 裝箱與拆箱
既然結構體是值型別,那麼結構體也存在裝箱與拆箱,將資料在棧與託管堆之間遷移:
struct Foo { }
Foo foo = new Foo();
object obj = foo; // 裝箱,移動到託管堆
Foo foo2 = (Foo)obj; // 拆箱,從託管堆中獲取資料並移動到棧上裝箱與拆箱的相關概念不是本文的重點,故此處不做過多介紹。另外,理所當然的,ref結構體(僅棧上結構體)不允許裝箱與拆箱。
4.3. 控制結構體的記憶體佈局
既然結構體是分配到棧上的,那結構體需要的記憶體大小必然是在編譯時與執行時都可以確定的。例如下述結構體:
struct Point
{
public int X;
public int Y;
}Point結構體有兩個int型別的欄位,C#中每個int直接對映到System.Int32型別,因此每個int欄位長度為4位元組,故儲存上述結構體所需要的記憶體大小就是4+4=8位元組。可以通過sizeof來檢視結構體所需的記憶體大小:
unsafe
{
Console.WriteLine(sizeof(Point)); // 輸出8
}一般來說,結構體所需的記憶體大小就是各個欄位大小的總和,但有時候還需要考慮記憶體對齊的問題。例如下述結構體:
struct Point
{
public byte X;
public int Y;
}byte型別只佔用一個位元組,所以你可能會認為上述程式碼中Point的大小是1+4=5位元組,然而由於記憶體對齊,byte依然會需要佔據4位元組大小,因此該結構體實際上依然需要8位元組來儲存。關於記憶體對齊是一個需要一定篇幅來闡述的問題,這個不是本文的重點,如有興趣可以參考C語言中結構體的記憶體對齊的相關文章進行了解。
另一個重要的點是,你可以通過System.Runtime.InteropServices.StructLayoutAttribute來指定欄位佈局方案,該Attribute主要接受一個System.Runtime.InteropServices.LayoutKind列舉來指定對齊模式,該列舉有三個列舉值:
(1)Sequential:順序佈局,按欄位的宣告順序佈局,是預設行為
(2)Auto:自動佈局,自動排列欄位順序以用最小的空間來儲存欄位
例如對於下面結構體:
struct Foo
{
public byte A;
public int B;
public byte C;
}預設情況下由於記憶體對齊,該結構體所需的記憶體大小為4+8+4=12,但你可以按下面的順序宣告欄位讓其只需要8個位元組:
struct Foo
{
public byte A;
public byte C;
public int B;
}也就是說欄位的宣告順序影響結構體的記憶體佔用,而通過StructLayoutAttribute,你可以讓執行時對欄位順序自動調整以求最小記憶體浪費:
[StructLayout(LayoutKind.Auto)]
struct Foo
{
public byte A;
public int B;
public byte C;
}經過執行時的自動調整欄位儲存順序後,一個Foo物件在程式執行的時候的記憶體佔用同樣是8。
(3)Explicit:顯式佈局,手動指定欄位地址的偏移
你可以手動指定欄位的偏移值,來達到一些特殊的效果:
[StructLayout(LayoutKind.Explicit)]
struct Foo
{
[FieldOffset(0)]
public short A;
[FieldOffset(4)]
public int B;
[FieldOffset(2)]
public short C;
}通常,按照Foo中欄位的宣告順序,Foo的記憶體佈局應該如下圖:

但這裡將結構體的LayoutKind設定為了Explicit,並使用了FieldOffsetAttribute來顯式指定了各個欄位相對於結構體起始地址的偏移(以位元組為單位)。因此Foo的實際記憶體佈局如下圖:

這一功能一個比較重要的用途是用於模擬C語言中的聯合體(union),例如對於下面C中的聯合體定義:
union Foo
{
int IntValue;
long LongValue;
double DoubleValue;
};可以使用下述的C#的結構體來模擬:
[StructLayout(LayoutKind.Explicit)]
struct Foo
{
[FieldOffset(0)]
public int IntValue;
[FieldOffset(0)]
public long LongValue;
[FieldOffset(0)]
public double DoubleValue;
}上述結構體的記憶體佈局如下圖:
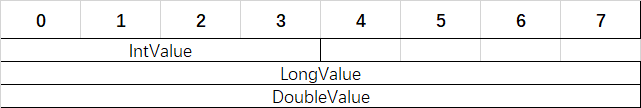
同樣,顯式指定記憶體也受記憶體對齊的影響。
5. 結構體雜談
5.1. 欄位 or 屬性
前文給出的結構體幾乎都是直接使用欄位而非屬性,但這只是為了避開屬性的複雜性,從而更方便更直觀地說明結構體的一些性質。在實際使用中,鑑於屬性的種種好處,一般情況下即便是結構體也應該優先使用屬性。
不過有時候確實使用欄位更好,例如定義與非受控程式碼互動的結構體的成員就最好使用欄位,或者效能瓶頸確實出現在使用屬性上因此不得不直接使用欄位(大多數情況這並不可能)。
簡而言之,除非確實真的有必要,否則對於結構體也應該優先使用屬性而非欄位。
5.2. 類 or 結構
通常使用結構體是因為結構體的棧上分配特點而有使其具有更好的操作效能,因此結構體通常是為高效能需要服務的。然而,結構體預設使用副本式傳值,可能會導致程式執行時建立不必要的副本,例如:
struct MethodArgs { ... }
MethodArgs args = new MethodArgs();
Method(args); // 第一次副本
Method(args); // 第二次建立副本
Method(args); // ...建立副本上述程式碼中每一次傳參都會有一次額外的建立副本的開銷,然而如果將MethodArgs定義為class,則只會傳遞對同一個範例參照,則避免了建立副本的開銷。當然,可以通過按參照傳遞引數來解決,但這仍然不是一個完美的解決方法。
此外,結構體不允許繼承,這意味著結構體的程式碼重用能力遠低於類,並且結構體不會有多型行為。
最後,從概念上來講,結構體是值型別,應當將其認為是表現類似於int、long、double這類數值型別的型別,遵循用於「表達一個值」的用法,並根據輕量原則,結構體不應該定義的過於複雜。
基於上述原因,《CLR via C#》一書中建議在下面的情況下使用結構體:
- 型別定義十分簡單,具有類似基元型別的表現。
- 不需要繼承,也不需要被繼承。
- 記憶體的範例較小(16位元組以下)
- 或者記憶體範例較大(16位元組以上),但是不會作為方法的引數與返回值使用
不過例外的是,與非受控程式碼互動時,記憶體佈局明確且不受託管堆影響的的結構體有不可替代的優勢,此時使用結構體基本是唯一的選擇。
5.3. 實現一個更好的結構體
(1)重寫Equals與GetHashCode方法
預設的結構體實現會使用ValueType中重寫的Equals方法,預設實現會考慮對普遍情況的可靠性,但這往往意味著它對特定實現來說是低效的,實際上ValueType對Equals的重寫方法遠比想象中的複雜。考慮到值型別往往需要在效能敏感的場合使用,因此有必要手動重寫其Equals方法,關於如何重寫Equals方法已經在另一篇文章中提出,這裡不再贅述。同樣的,也需要重寫結構體的GetHashCode方法。
(2)使用唯讀結構體
由於結構體最好具有基元型別的表現,因此最佳的做法是儘可能地將結構體定義為唯讀結構體。
(3)實現IEqualable<>介面
作為值型別,那麼結構體自然也應該可以進行相等性比較,實現IEquatable<>介面可以為結構體提供更好的比較方法,並提高結構體的泛用性。
(4)過載==與!=運運算元
理由同上,使用==與!=對值型別進行相等性比較是符合直覺的。
(5)僅包含欄位、屬性與唯讀方法
儘管可行,但是不應該在結構體中定義事件。此外,結構體中的方法應該儘可能定義為唯讀方法,或者說方法不應該修改結構體的欄位狀態。
5.4. 語法糖
C#中提供了一種名為with表示式的語法糖來獲得對結構體進行非破壞性修改的副本:
Point p1 = new Point();
Point p2 = p1 with { X = 1 };上述程式碼實際做的事如下:
Point p1 = new Point();
Point temp = p1;
temp.X = 1;
Poitn p2 = temp;在一些場合,這一語法可以有效減少不必要的程式碼量。
5.5. 奇技淫巧
如果結構體不是唯讀結構體,那麼下述程式碼是可行的:
struct Point
{
public float X;
public float Y;
public void Reset(Point p)
{
this = p; // 修改this
}
}這並不奇怪,結構體在宣告時就分配好了記憶體,並遵循按副本賦值。因此上述程式碼中this = p實際就是將p逐欄位賦值給this表示的範例的相應欄位的值而已。不過如果沒有必要還是應該避免這種迷惑性的操作。
5.6. 其他注意事項
(1)結構體型別無法巢狀,也就是說下面的程式碼是不可行的
struct Foo
{
public Foo Foo; // 巢狀一個位元組
}顯然,這會導致遞迴定義,所以是不允許的。
(2)構造方法必須保證對每個欄位都賦值
struct Foo
{
public int X;
public int Y;
public Foo(int x)
{
X = x;
}
}儘管可以看出上述程式碼中的構造方法是想僅設定X的值,讓Y的值保持其預設值0。然而該構造方法無法通過編譯,因為構造方法中還沒有完成對欄位Y賦值,需要將其修改為如下:
struct Foo
{
public int X;
public int Y;
public Foo(int x)
{
X = x;
Y = 0;
}
}