從零開始訓練神經網路【學習筆記】[2/2]
任務目標
經過上次從零開始訓練神經網路---Keras【學習筆記】[1/2] 後,這次我們不借助Keras,自己使用程式碼編寫並訓練神經網路,以實現輸入一張手寫數點陣圖片後,網路輸出該圖片對應的數位的目的。
基本要求
我們的程式碼要匯出三個介面,分別完成以下功能:
- 初始化initialisation,設定輸入層,中間層,和輸出層的節點數。
- 訓練train:根據訓練資料不斷的更新權重值
- 查詢query,把新的資料輸入給神經網路,網路計算後輸出答案。(推理)
設計Network並編寫程式碼:
下文將採用《Python Crash Course》2nd edition.,即蟒蛇書的程式碼擴充書寫方式來展示我們逐步擴充神經網路程式碼的過程:
一、建立一個類(class):
class NeuralNetWork:
"""一個全連結神經網路"""
def __init__(self):
"""
初始化網路,設定輸入層,中間層,和輸出層節點數
"""
pass
def train(self):
"""
根據輸入的訓練資料更新節點鏈路權重
"""
pass
def query(self):
"""
根據輸入資料計算並輸出答案
"""
pass
二、完善初始化initialisation部分
2.1 補充class的屬性
由於神經網路需要設定各層的節點數,以及學習率等「超引數」,來決定網路的結構、大小等性質。而這些超引數就可以在class的屬性中初始化。
class NeuralNetWork:
"""一個全連結神經網路"""
def __init__(self, input_nodes, hidde_nnodes, output_nodes, learning_rate):
"""
初始化網路,設定輸入層,中間層,和輸出層節點數
:param input_nodes: 輸入層節點數
:param hidden_nodes: 中間層(隱藏層)節點數
:param output_nodes: 輸出層節點數
:param learning_rate: 學習率
"""
self.inodes = input_nodes
self.hnodes = hidden_nodes
self.onodes = output_nodes
self.lr = learning_rate
pass
--snip--
2.1.1 驗證程式碼可用性
練習初始化一個輸入層,中間層和輸出層都有3個節點的3層神經網路。
input_nodes = 3
hidden_nodes = 3
output_nodes = 3
learning_rate = 0.3
n = NeuralNetWork(input_nodes, hidden_nodes, output_nodes, learning_rate)
out:

2.2 初始化權重屬性
由於前層輸入進行層間傳遞到後層某個節點須服從wx+b形式,因此我們需要構造初始化的全中矩陣。
具體地,權重矩陣的形狀應當遵守:
- 權重矩陣的列數 == 前層輸入的個數(節點數)
- 權重矩陣的行數 == 後層接受的節點數
這一點不熟悉的,可以參考我之前的部落格:練習推導一個最簡單的BP神經網路訓練過程【個人作業/數學推導】
由於權重不一定都是正的,它完全可以是負數,因此我們在初始化時,把所有權重初始化為-0.5到0.5之間。
class NeuralNetWork:
"""一個全連結神經網路"""
def __init__(self, input_nodes, hidde_nnodes, output_nodes, learning_rate):
"""
初始化網路,設定輸入層,中間層,和輸出層節點數
:param input_nodes: 輸入層節點數
:param hidden_nodes: 中間層(隱藏層)節點數
:param output_nodes: 輸出層節點數
:param learning_rate: 學習率
"""
self.inodes = input_nodes
self.hnodes = hidden_nodes
self.onodes = output_nodes
self.lr = learning_rate
"""
構造層間權重矩陣。
根據矩陣乘法。構造的權重矩陣的行數由後層節點數決定,列數由前層節點數決定。
"""
self.wih = numpy.random.rand(self.hnodes, self.inodes) - 0.5
# wih矩陣是一個(隱藏層節點數, 輸入層節點數),各元素取值[-0.5, 0.5]的矩陣,符合要求。下同。
self.who = numpy.random.rand(self.onodes, self.hnodes) - 0.5
pass
--snip--
三、query函數的實現
3.1 層間傳遞演演算法編寫
class NeuralNetWork:
"""一個全連結神經網路"""
--snip--
def query(self, inputs):
"""
根據輸入資料計算並輸出答案
:param inputs: 暫時理解為輸入層的輸入資料矩陣
"""
hidden_inputs = numpy.dot(self.wih, inputs)
# hidden_inputs是一個一維向量,每個元素對應著中間層某個節點從輸入層神經元傳過來後的號誌總和。
pass
3.2 層內啟用演演算法編寫
前文提到前層輸入進行層間傳遞到後層某個節點須服從wx+b形式。那麼完成這一傳遞任務的就可以交給query()查詢函數。
然而query()查詢函數的任務不應該僅僅包括層間傳遞,還包括層內每個節點執行的啟用函數運算,轉化為該層的輸出(或者是最終結果,或者是下一層的輸入)。
sigmod啟用函數在Python中可以直接呼叫,我們要做的就是準備好引數。我們可以先把這個函數在初始化函數中設定好。
class NeuralNetWork:
"""一個全連結神經網路"""
def __init__(self, input_nodes, hidde_nnodes, output_nodes, learning_rate):
"""
初始化網路,設定輸入層,中間層,和輸出層節點數
:param input_nodes: 輸入層節點數
:param hidden_nodes: 中間層(隱藏層)節點數
:param output_nodes: 輸出層節點數
:param learning_rate: 學習率
"""
self.inodes = input_nodes
self.hnodes = hidden_nodes
self.onodes = output_nodes
self.lr = learning_rate
"""
構造層間權重矩陣。
根據矩陣乘法。構造的權重矩陣的行數由後層節點數決定,列數由前層節點數決定。
"""
self.wih = numpy.random.rand(self.hnodes, self.inodes) - 0.5
# wih矩陣是一個(隱藏層節點數, 輸入層節點數),各元素取值[-0.5, 0.5]的矩陣,符合要求。下同。
self.who = numpy.random.rand(self.onodes, self.hnodes) - 0.5
'''
scipy.special.expit對應的是sigmod函數.
使用Python保留關鍵字lambda構造匿名函數lambda x: scipy.special.expit(x)可以直接得到啟用函數計算後的返回值。
'''
self.activation_function = lambda x: scipy.special.expit(x)
--snip--
def query(self, inputs):
"""
根據輸入資料計算並輸出答案
:param inputs: 輸入層的輸入資料矩陣
"""
hidden_inputs = numpy.dot(self.wih, inputs)
# hidden_inputs是一個一維向量,每個元素對應著中間層某個節點從輸入層神經元傳過來後的號誌總和。
pass
3.3 繼續完成query函數編寫
至此我們就可以分別呼叫啟用函數計算中間層的輸出訊號,以及輸出層經過啟用函數後形成的輸出訊號。
class NeuralNetWork:
"""一個全連結神經網路"""
--snip--
def query(self, inputs):
"""
層間資料傳遞的計算,層內執行啟用函數計算
:param inputs: 輸入層的輸入資料矩陣
:return: 神經網路一次正向傳遞的最終輸出
"""
# 資料由輸入層向中間層(隱藏層)進行層間傳遞,按照加權求和的規則計算
hidden_inputs = np.dot(self.wih, inputs)
# 資料在中間層(隱藏層)的接收端向輸出端進行層內傳遞,經過啟用函數後形成的輸出資料矩陣
hidden_outputs = self.activation_function(hidden_inputs)
# 資料由中間層(隱藏層)向輸出層進行層間傳遞,按照加權求和的規則計算
final_inputs = np.dot(self.who, hidden_outputs)
# 資料在輸出層的接收端向輸出端進行層內傳遞,經過啟用函數後形成的最終的輸出資料矩陣
final_outputs = self.activation_function(final_inputs)
print(final_outputs)
return final_outputs
到目前為止,我們不妨使用一組資料來測試一下神經網路框架的程式碼:
input_n = 3
hidden_n = 3
output_n = 3
learning_r = 0.3
n = NeuralNetWork(input_n, hidden_n, output_n, learning_r)
n.query([1.0, 0.5, -1.5])
out:

四、訓練train過程的實現
完成以上程式碼後,神經網路的大體框架就完成了,我們留下最重要的train函數,也就是通過訓練樣本訓練鏈路權重的流程到下一步實現。
訓練過程分兩步:
- 計算輸入訓練資料,給出網路的計算結果,這點跟query()功能很像。(這正是我們完成query函數程式碼的原因)
- 將計算結果與正確結果相比對,獲取誤差,採用誤差反向傳播法更新網路里的每條鏈路權重。
4.1 正向傳播過程
我們先用程式碼完成第一步:
class NeuralNetWork:
"""一個全連結神經網路"""
--snip--
def train(self, inputs_list, targets_list):
"""
完成訓練過程
:param inputs_list: 輸入的訓練資料
:param targets_list: 訓練資料對應的正確結果
"""
inputs = np.array(inputs_list, ndmin=2).T
targets = np.array(targets_list, ndmin=2).T
# 資料由輸入層向中間層(隱藏層)進行層間傳遞,按照加權求和的規則計算
hidden_inputs = np.dot(self.wih, inputs)
# 資料在中間層(隱藏層)的接收端向輸出端進行層內傳遞,經過啟用函數後形成的輸出資料矩陣
hidden_outputs = self.activation_function(hidden_inputs)
# 資料由中間層(隱藏層)向輸出層進行層間傳遞,按照加權求和的規則計算
final_inputs = np.dot(self.who, hidden_outputs)
# 資料在輸出層的接收端向輸出端進行層內傳遞,經過啟用函數後形成最終的輸出資料矩陣
final_outputs = self.activation_function(final_inputs)
pass
--snip--
可以發現與query()極其相似。
4.2 反向傳播過程
這裡注意,如下反向傳播計算式的形式是由我們使用的損失函數為MSE函數,以及上文提到啟用函數為sigmoid函數共同決定的,某些資料裡省略了。
class NeuralNetWork:
"""一個全連結神經網路"""
--snip--
def train(self, inputs_list, targets_list):
"""
完成訓練過程
:param inputs_list: 輸入的訓練資料
:param targets_list: 訓練資料對應的正確結果
"""
inputs = np.array(inputs_list, ndmin=2).T
targets = np.array(targets_list, ndmin=2).T
# 資料由輸入層向中間層(隱藏層)進行層間傳遞,按照加權求和的規則計算
hidden_inputs = np.dot(self.wih, inputs)
# 資料在中間層(隱藏層)的接收端向輸出端進行層內傳遞,經過啟用函數後形成的輸出資料矩陣
hidden_outputs = self.activation_function(hidden_inputs)
# 資料由中間層(隱藏層)向輸出層進行層間傳遞,按照加權求和的規則計算
final_inputs = np.dot(self.who, hidden_outputs)
# 資料在輸出層的接收端向輸出端進行層內傳遞,經過啟用函數後形成最終的輸出資料矩陣
final_outputs = self.activation_function(final_inputs)
# (↓反向傳播過程)
# 計算正向傳播輸出結果與標籤的誤差
output_errors = targets - final_outputs
hidden_errors = np.dot(self.who.T, output_errors * final_outputs * (1 - final_outputs))
# 按照鏈式求導法則求出損失函數MSE對各個權重w的偏導數,依據梯度下降法更新各權重
self.who += self.lr * np.dot((output_errors * final_outputs * (1 - final_outputs)), np.transpose(hidden_outputs))
self.wih += self.lr * np.dot((hidden_errors * hidden_outputs * (1 - hidden_outputs)), np.transpose(inputs)) # self.wih更新算式中,np.dot()的第一個參數列達式應用了「陣列乘法」
pass
--snip--
想要看懂上述權重更新程式碼的提示:
- 要在數學上實現反向傳播過程的推導,得到損失函數MSE對各權重wi的偏導數表示式;
- 根據」輸入→中間層「和」中間層→輸出層「,將偏導數分為兩組∂MSE/∂[w1,w2,w3,w4]和∂MSE/∂[w5,w6,w7,w8];
- 將偏導數的多項式表示式形式,轉換成矩陣乘法表示式形式;
- 轉換時儘量做到矩陣形式中每一項的樣子與資料在變數中儲存形式一致,這樣更容易理解和編寫程式碼。
- 將某些步驟中「對角陣與列向量乘法」變成了更加容易用程式碼實現的「陣列乘法」
- 權重更新語句是「+=」,是因為偏導數和梯度下降法均有「-」負負得正
如果上述程式碼和提示對你來說仍然過於「抽象」,那麼請繼續參考我之前寫過的:練習推導一個最簡單的BP神經網路訓練過程【個人作業/數學推導】
其中對本文最重要結論如下圖中展示的算式:
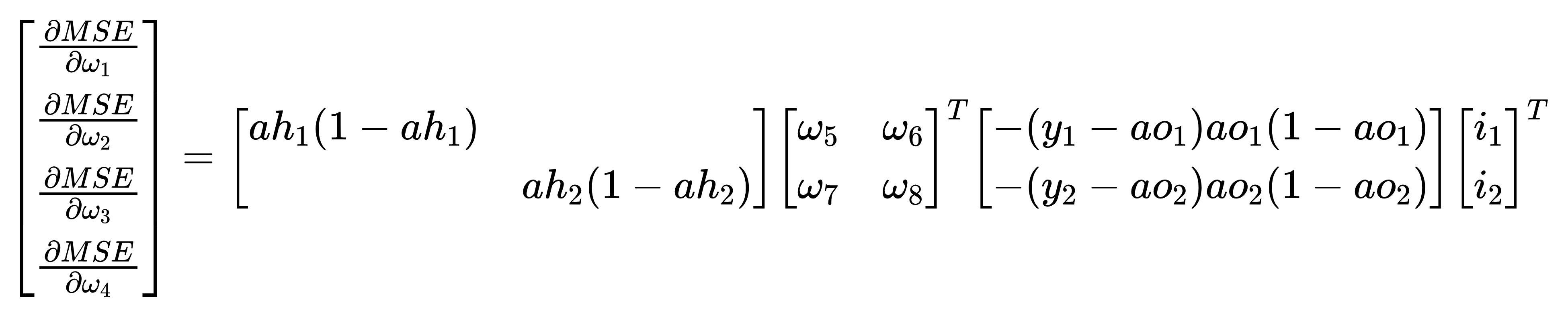
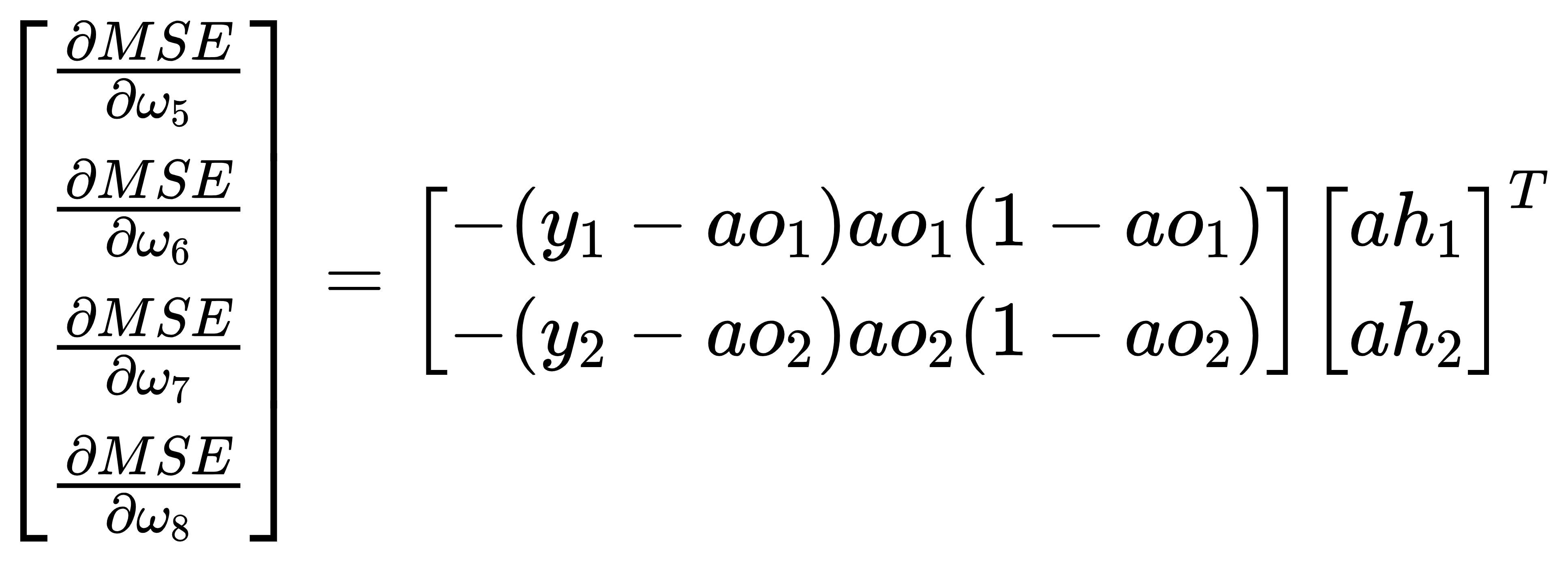
五、匯入資料訓練神經網路
使用實際資料來訓練我們的神經網路
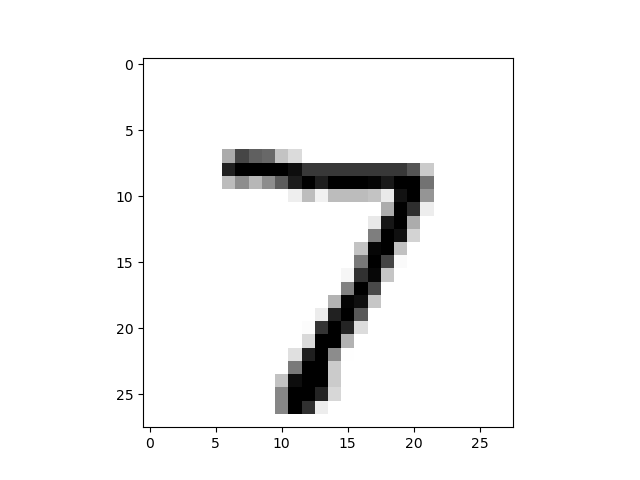
5.1 「看」一下資料集(可選)
class NeuralNetWork:
--snip--
data_file = open(".../mnist_test.csv") # 各位可以使用自己的資料集,這裡.csv檔案中儲存的是10張(28,28)的手寫數點陣圖片,每張圖片和其標籤資料以一維陣列(長度1+28*28)形式存在.csv的某行中。
data_list = data_file.readlines()
data_file.close()
print(len(data_list))
print(data_list[0])
# 把資料依靠','區分,並分別讀入
all_values = data_list[0].split(',')
# 第一個值對應的是圖片的標籤,所以我們讀取圖片資料時要去掉第一個數值
image_array = np.asfarray(all_values[1:]).reshape((28, 28))
plt.imshow(image_array, cmap='Greys', interpolation='None')
plt.show()
Out:
5.2 初始化神經網路
有了神經網路,我們就能利用它將輸入圖片和對應的正確數位之間的聯絡,通過訓練讓神經網路「學會」它。
由於一張圖片總共有28*28 = 784個數值,因此我們需要讓網路的輸入層具備784個輸入節點。
這裡需要注意的是,中間層的節點我們選擇了100個神經元,這個選擇是經驗值。中間層的節點數沒有專門的辦法去規定,其數量會根據不同的問題而變化。
確定中間層神經元節點數最好的辦法是實驗,不停的選取各種數量,看看那種數量能使得網路的表現最好。
class NeuralNetWork:
--snip--
inputnodes = 784 # 28*28=784,是一個圖片資料的畫素個數
hiddennodes = 100 # 100:經驗值
outputnodes = 10 # 一共10個數位,用10個節點即可輸出one-hot編碼對應格式的結果供判斷
learningrate = 0.3
n = NeuralNetWork(inputnodes, hiddennodes, outputnodes, learningrate) # 範例化
5.3 載入訓練資料集
--snip--
training_data_file = open(".../mnist_test.csv", 'r') # 唯讀模式載入資料,注意檢查檔案儲存路徑
training_data_list = training_data_file.readlines() # 將每一行資料作為一個元素,儲存在一個list中
training_data_file.close() # 關閉檔案
5.4 訓練神經網路
該步驟包含了訓練截止條件設定(epoch),資料的歸一化處理,資料標籤的one-hot編碼等過程。為保證程式碼不過於零碎,說明解釋性文字採用程式碼註釋的形式給出。
--snip--
epochs = 5 # 每個資料被遍歷5次
for e in range(epochs):
for record in training_data_list:
all_values = record.split(',') # 把資料靠','分割,並分別讀入
"""
接下來可以將資料「歸一化」,也就是把所有數值全部轉換到0.01到1.0之間。
由於表示圖片的二維陣列中,每個數大小不超過255,由此我們只要把所有陣列除以255,就能讓資料全部落入到0和1之間。
有些數值很小,除以255後會變為0,這樣「有可能」導致鏈路權重更新出意想不到的問題。
所以我們需要把除以255後的結果先乘以0.99,然後再加上0.01,這樣所有資料就處於0.01到1之間。
"""
inputs = (np.asfarray(all_values[1:])) / 255.0 * 0.99 + 0.01 # 首個元素是標籤,在inputs讀取時要去掉。進行「資料分割」。
# 設定圖片與數值的對應關係,ont-hot編碼
targets = np.zeros(outputnodes) + 0.01 # 建立一個10個元素的陣列,各元素均為0.01
targets[int(all_values[0])] = 0.99 # 在陣列中,將等同於數位值的索引的元素替換為0.99。假設數位7,就把索引7(第8個)數位更換為0.99
n.train(inputs, targets) # 啟用訓練過程
如果你覺得這個部分的功能應該在程式碼編寫的時候作為class NeuralNetWork中train和query一樣的一個方法,也可以自行改寫或重寫這段程式碼。
悄悄話:改寫好的程式碼我已經放在文末的附錄了~
六,測試神經網路訓練效果
6.1 載入測試資料
--snip--
test_data_file = open(".../mnist_test.csv")
test_data_list = test_data_file.readlines()
test_data_file.close()
6.2 測試正確率
運用測試資料,通過query()函數讓神經網路做出判斷,正確得1分,錯誤得0分。
最後通過的分數佔總次數的比值作為評估神經網路訓練的指標。
--snip--
scores = [] # 設定一個列表記錄每次判斷的得分情況,判斷正確存入1,錯誤存入0
for record in test_data_list:
all_values = record.split(',')
correct_number = int(all_values[0]) # 提取標籤值
print("該圖片對應的數位為:", correct_number)
inputs = (np.asfarray(all_values[1:])) / 255.0 * 0.99 + 0.01 # 歸一化
outputs = n.query(inputs) # 讓訓練好的神經網路判斷圖片對應的數位並輸出結果
label = np.argmax(outputs) # 應用numpy.argmax()函數找到數值最大的神經元對應的編號
print("網路認為圖片的數位是:", label)
if label == correct_number:
scores.append(1)
else:
scores.append(0)
print(f"得分記錄:\n{scores}")
# 計算圖片判斷的成功率
scores_array = np.asarray(scores)
print(f"perfermance = {scores_array.sum() / scores_array.size * 100}%")
執行一下,博主執行了四五次,正確率大概在80%~100%之間,如下分享部分執行紀錄檔:
某一次測試:
該圖片對應的數位為: 7
神經網路判斷輸出結果:[0.04490563 0.1442118 0.01057779 0.03840048 0.10869915 0.10087318
0.02624607 0.50353098 0.01978388 0.3832254 ]
網路認為圖片的數位是: 7
該圖片對應的數位為: 2
神經網路判斷輸出結果:[0.03350826 0.19402964 0.8244046 0.03923834 0.10463468 0.11580433
0.0219085 0.01078036 0.03336618 0.20670527]
網路認為圖片的數位是: 2
該圖片對應的數位為: 1
神經網路判斷輸出結果:[0.05772382 0.82646153 0.08554279 0.026443 0.10922416 0.10826541
0.06526364 0.03217652 0.05343728 0.41798268]
網路認為圖片的數位是: 1
該圖片對應的數位為: 0
神經網路判斷輸出結果:[0.75354885 0.00469123 0.10610267 0.04624908 0.06654835 0.25189698
0.01219346 0.04163698 0.02263259 0.22938364]
網路認為圖片的數位是: 0
該圖片對應的數位為: 4
神經網路判斷輸出結果:[0.06560732 0.02923927 0.01173238 0.06191911 0.58371914 0.04675726
0.02078057 0.0478471 0.03739525 0.39723215]
網路認為圖片的數位是: 4
該圖片對應的數位為: 1
神經網路判斷輸出結果:[0.03902202 0.8389586 0.0657253 0.01908614 0.07016369 0.20796944
0.04493151 0.0493951 0.0317052 0.50017788]
網路認為圖片的數位是: 1
該圖片對應的數位為: 4
神經網路判斷輸出結果:[0.01736686 0.06961667 0.03573381 0.02303936 0.76090355 0.06674459
0.05125742 0.07640926 0.01028558 0.29533893]
網路認為圖片的數位是: 4
該圖片對應的數位為: 9
神經網路判斷輸出結果:[0.11019431 0.08369413 0.04207057 0.04246999 0.08058493 0.07806882
0.00777434 0.08662602 0.04694908 0.57857676]
網路認為圖片的數位是: 9
該圖片對應的數位為: 5
神經網路判斷輸出結果:[0.1498377 0.04490002 0.0911285 0.01397933 0.13341466 0.44113759
0.01476506 0.03469851 0.0448106 0.25640707]
網路認為圖片的數位是: 5
該圖片對應的數位為: 9
神經網路判斷輸出結果:[0.05914363 0.11508302 0.03964155 0.02739487 0.08430381 0.11847783
0.05053017 0.14199462 0.02186278 0.6277568 ]
網路認為圖片的數位是: 9
得分記錄:
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
perfermance = 100.0%
另一次測試
該圖片對應的數位為: 7
神經網路判斷輸出結果:[0.02265905 0.03422366 0.06430731 0.03609857 0.22654582 0.09591944
0.02100579 0.75224205 0.01851069 0.12818351]
網路認為圖片的數位是: 7
該圖片對應的數位為: 2
神經網路判斷輸出結果:[0.10963591 0.09466725 0.80127158 0.04624556 0.06273288 0.0108084
0.02432404 0.01778638 0.02363708 0.12300765]
網路認為圖片的數位是: 2
該圖片對應的數位為: 1
神經網路判斷輸出結果:[0.09640155 0.77838901 0.02933256 0.04210427 0.11360658 0.06766493
0.052675 0.03493176 0.03070893 0.28625836]
網路認為圖片的數位是: 1
該圖片對應的數位為: 0
神經網路判斷輸出結果:[0.7237887 0.03547681 0.07877899 0.05324199 0.17120737 0.0149062
0.02448635 0.0682549 0.0351064 0.23182087]
網路認為圖片的數位是: 0
該圖片對應的數位為: 4
神經網路判斷輸出結果:[0.05946789 0.02326259 0.05029738 0.03110391 0.3446047 0.05265512
0.05653835 0.07649995 0.06696382 0.27745743]
網路認為圖片的數位是: 4
該圖片對應的數位為: 1
神經網路判斷輸出結果:[0.06971733 0.84624108 0.03975012 0.05342429 0.09792431 0.06858301
0.03652602 0.03837132 0.04676739 0.23421643]
網路認為圖片的數位是: 1
該圖片對應的數位為: 4
神經網路判斷輸出結果:[0.06727082 0.02175992 0.09172235 0.01222416 0.7647925 0.0728403
0.04735842 0.08916765 0.03130962 0.28624597]
網路認為圖片的數位是: 4
該圖片對應的數位為: 9
神經網路判斷輸出結果:[0.08551987 0.07957313 0.10618406 0.0102303 0.07864775 0.01744719
0.00578813 0.06349602 0.04352108 0.44316604]
網路認為圖片的數位是: 9
該圖片對應的數位為: 5
神經網路判斷輸出結果:[0.1020314 0.10072958 0.05474097 0.04504972 0.09402001 0.037387
0.0326212 0.07542155 0.02800163 0.05423302]
網路認為圖片的數位是: 0
該圖片對應的數位為: 9
神經網路判斷輸出結果:[0.08643607 0.1041881 0.02615816 0.01081672 0.1368236 0.04170109
0.00848632 0.07306719 0.03210684 0.85766101]
網路認為圖片的數位是: 9
得分記錄:
[1, 1, 1, 1, 1, 1, 1, 1, 0, 1]
perfermance = 90.0%
七,結語
至此一個較為完整的神經網路的程式碼編寫、訓練和測試過程就完成了。不依託任何成熟的框架,使用常用的numpy等庫完成了對手寫數位的識別工作。
當然,我們要看到該神經網路並不是很「靈活」,例如:
- 啟用函數和損失函數也是固定在程式碼和計算式之中的;
- 不能像Keras中那樣增刪層;
- 權重更新演演算法部分是根據「輸入層→中間層(一層)→輸出層」結構推導的結果,二者繫結性強;
- 沒有根據損失函數的值來截止訓練的功能
- 不能圖形化輸出神經網路結構,需要發揮個人想象力
- ......
Appendix:
將訓練範例化的神經網路功能整合為class中的一個method的程式碼分享給大家。
注意整合後,後面實際訓練的程式碼也要修改,這個就交給各位自行完成。
class NeuralNetWork:
--snip--
def network_train(self, data, epoches=5):
"""
完成整個訓練網路的訓練過程(權重更新過程)部分
:param data: 訓練集,包含資料和標籤
:param epoches: 資料被遍歷次數
"""
for e in range(epoches):
for record_ in data:
all_values_ = record_.split(',') # 把資料依靠','分割,並分別讀入
"""
接下來可以將資料「歸一化」,也就是把所有數值全部轉換到0.01到1.0之間。
由於表示圖片的二維陣列中,每個數大小不超過255,由此我們只要把所有陣列除以255,就能讓資料全部落入到0和1之間。
有些數值很小,除以255後會變為0,這樣「有可能」導致鏈路權重更新出意想不到的問題。
所以我們需要把除以255後的結果先乘以0.99,然後再加上0.01,這樣所有資料就處於0.01到1之間。
"""
inputs_ = (np.asfarray(all_values_[1:])) / 255.0 * 0.99 + 0.01 # 首個元素是標籤,在inputs讀取時要去掉。進行「資料分割」
# 設定圖片與數值的對應關係,ont-hot編碼
targets_ = np.zeros(self.onodes) + 0.01 # 建立一個10個元素的陣列,各元素均為0.01
targets_[int(all_values_[0])] = 0.99 # 在陣列中,將等同於數位值的索引的元素替換為0.99。假設數位7,就把索引7(第8個)數位更換為0.99
self.train(inputs_, targets_) # 啟用訓練過程
--snip--
#TODO 實際訓練部分程式碼修改