探究Presto SQL引擎(3)-程式碼生成
vivo 網際網路伺服器團隊- Shuai Guangying
探究Presto SQL引擎 系列:第1篇《探究Presto SQL引擎(1)-巧用Antlr》介紹了Antlr的基本用法以及如何使用Antlr4實現解析SQL查詢CSV資料,在第2篇《探究Presto SQL引擎(2)-淺析Join》結合了Join的原理,以及Join的原理,在Presto中的思路。
本文是系列第3篇,介紹基於 Antlr 實現where條件的解析原理,並對比了直接解析與程式碼生成實現兩種實現思路的效能,經實驗基於程式碼生成的實現相比直接解析有 3 倍的效能提升。
一、背景問題
業務開發過程中,使用SQL進行資料篩選(where關鍵詞)和關聯(join關鍵詞)是編寫SQL語句實現業務需求最常見、最基礎的能力。
在海量資料和響應時間雙重壓力下,看似簡單的資料篩選和關聯在實現過程中面臨非常多技術細節問題,在研究解決這些問題過程中也誕生了非常有趣的資料結構和優化思想。比如B樹、LSM樹、列式儲存、動態程式碼生成等。
對於Presto SQL引擎,布林表示式的判斷是實現where和join處理邏輯中非常基礎的能力。
本文旨在探究 where 關鍵詞的實現思路,探究where語句內部實現的基本思路以及效能優化的基本思想。以where語句為例:where篩選支援and 、or 和 not 三種基礎邏輯,在三種基礎邏輯的基礎上,支援基於括號自定義優先順序、表示式內部支援欄位、函數呼叫。看似簡單,實則別有洞天。值得深入挖掘學習。
二、使用 Antlr 實現 where 條件過濾
對於Presto查詢引擎,其整體架構如下:
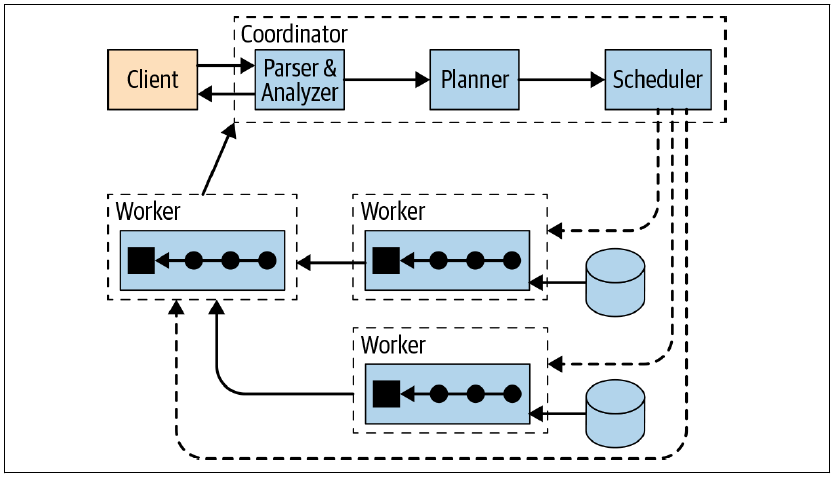
其中,Parser&Analyzer就是Antlr的用武之地。任何的SQL語句,必須經過Parser&Analyzer這一步,所謂一夫當關萬夫莫開。關於Antlr的背景及基礎操作等內容,在《探究Antlr在Presto 引擎的應用》一文已有描述,不再贅述。
本文依然採用驅動Antlr的三板斧來實現SQL語句對where條件的支援。
對於where條件,首先拆解where條件最簡單的結構:
and 和or作為組合條件篩選的基本結構。
6大比較運運算元(大於,小於,等於,不等於,大於或等於,小於或等於)作為基本表示式。
接下來就是使用 Antlr 的標準流程。
2.1 定義語法規則
使用antlr定義語法規則如下 (該規則基於presto SQL語法裁剪,完整定義可參考presto SelectBase.g4檔案):
querySpecification
: SELECT selectItem (',' selectItem)*
(FROM relation (',' relation)*)?
(WHERE where=booleanExpression)?
;
...
booleanExpression
: valueExpression predicate[$valueExpression.ctx]? #predicated
| NOT booleanExpression #logicalNot
| left=booleanExpression operator=AND right=booleanExpression #logicalBinary
| left=booleanExpression operator=OR right=booleanExpression #logicalBinary
;
predicate[ParserRuleContext value]
: comparisonOperator right=valueExpression #comparison
;
即where條件後面附帶一個booleanExpression表示式規則,booleanExpression表示式規則支援基礎的valueExpression預測、and和or以及not條件組合。本文的目的是探索核心思路,而非實現一個完成的SQL篩選能力,所以只處理and和or條件即可,以實現刪繁就簡,聚焦核心問題的目的。
2.2 生成語法解析程式碼
參照 Antlr 的官方檔案,使用預處理好的 Antlr命令處理g4檔案,生成程式碼即可。
antlr4 -package org.example.antlr -no-listener -visitor .\SqlBase.g4
2.3 開發業務程式碼處理 AST
2.3.1 定義語法樹節點
在瞭解了表示式構成後,先定義兩個基礎的SQL語法樹節點,類圖如下:
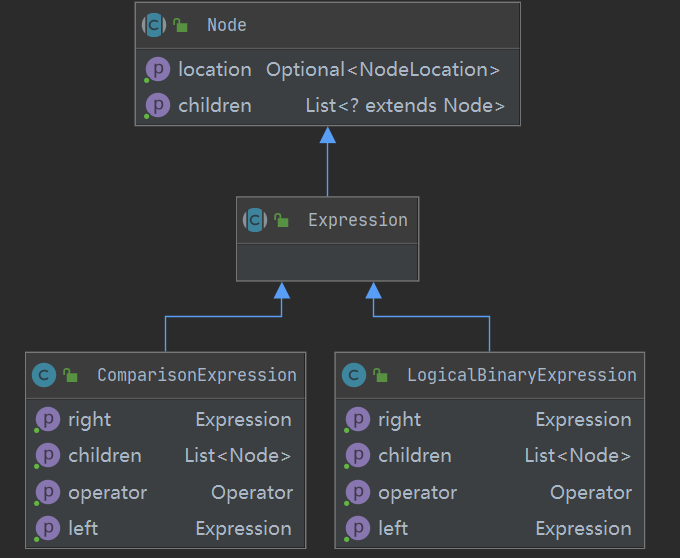
這兩個類從結構上是同構的:左右各一個分支表示式,中間一個運運算元。
2.3.2 構建語法樹
在AstBuilder實現中,新增對logicalBinary, comparison相關語法的解析實現。這些工作都是依樣畫葫蘆,沒有什麼難度。
@Override
public Node visitComparison(Select1Parser.ComparisonContext context)
{
return new ComparisonExpression(
getLocation(context.comparisonOperator()),
getComparisonOperator(((TerminalNode) context.comparisonOperator().getChild(0)).getSymbol()),
(Expression) visit(context.value),
(Expression) visit(context.right));
}
@Override
public Node visitLogicalBinary(Select1Parser.LogicalBinaryContext context)
{
return new LogicalBinaryExpression(
getLocation(context.operator),
getLogicalBinaryOperator(context.operator),
(Expression) visit(context.left),
(Expression) visit(context.right));
}
通過上面的兩步,一個SQL表示式就能轉化成一個SQL語法樹了。
2.3.3 遍歷語法樹
有了SQL語法樹後,問題就自然而然浮現出來了:
a) 這個SQL語法樹結構有什麼用?
b) 這個SQL語法樹結構該怎麼用?
其實對於SQL語法樹的應用場景,排除SQL引擎內部的邏輯,在我們日常開發中也是很常見的。比如:SQL語句的格式化,SQL的拼寫檢查。
對於SQL語法樹該怎麼用的問題,可以通過一個簡單的例子來說說明:SQL語句格式化。
在《探究Antlr在Presto 引擎的應用》一文中,為了簡化問題採取了直接拆解antlr生成的AST獲取SQL語句中的表名稱和欄位名稱,處理方式非常簡單粗暴。實際上presto中有一種更為優雅的處理思路:AstVisitor。也就是設計模式中的存取者模式。
存取者模式定義如下:
封裝一些作用於某種資料結構中的各元素的操作,它可以在不改變這個資料結構的前提下定義作用於這些元素的新的操作。
這個定義落實到SQL語法樹結構實現要點如下:即SQL語法樹節點定義一個accept方法作為節點操作的入口(參考Node.accept()方法)。定義個AstVisitor類用於規範存取節點樹的操作,具體的實現類繼承AstVisitor即可。基礎結構定義好過後,後面就是萬變不離其宗了。
兩個類核心框架程式碼如下:
public abstract class Node
{
/**
* Accessible for {@link AstVisitor}, use {@link AstVisitor#process(Node, Object)} instead.
*/
protected <R, C> R accept(AstVisitor<R, C> visitor, C context)
{
return visitor.visitNode(this, context);
}
}
public abstract class AstVisitor<R, C>
{
protected R visitStatement(Statement node, C context)
{
return visitNode(node, context);
}
protected R visitQuery(Query node, C context)
{
return visitStatement(node, context);
}
....
}
例如最常見的select * from table where 這類SQL語法,在SelectBase.g4檔案中定義查詢的核心結構如下:
querySpecification
: SELECT setQuantifier? selectItem (',' selectItem)*
(FROM relation (',' relation)*)?
(WHERE where=booleanExpression)?
(GROUP BY groupBy)?
(HAVING having=booleanExpression)?
;
以格式化SQL語句為例,Presto實現了SqlFormatter和ExpressionFormatter兩個實現類。格式化這個語句的程式碼如下:
@Override
protected Void visitQuerySpecification(QuerySpecification node, Integer indent)
{
process(node.getSelect(), indent);
if (node.getFrom().isPresent()) {
append(indent, "FROM");
builder.append('\n');
append(indent, " ");
process(node.getFrom().get(), indent);
}
builder.append('\n');
if (node.getWhere().isPresent()) {
append(indent, "WHERE " + formatExpression(node.getWhere().get(), parameters))
.append('\n');
}
if (node.getGroupBy().isPresent()) {
append(indent, "GROUP BY " + (node.getGroupBy().get().isDistinct() ? " DISTINCT " : "") + formatGroupBy(node.getGroupBy().get().getGroupingElements())).append('\n');
}
if (node.getHaving().isPresent()) {
append(indent, "HAVING " + formatExpression(node.getHaving().get(), parameters))
.append('\n');
}
if (node.getOrderBy().isPresent()) {
process(node.getOrderBy().get(), indent);
}
if (node.getLimit().isPresent()) {
append(indent, "LIMIT " + node.getLimit().get())
.append('\n');
}
return null;
}
程式碼實現邏輯清晰明瞭,可讀性極強。
同理, 實現where條件解析的核心在於比較條件表示式的處理(visitComparisonExpression)和邏輯條件表示式的處理(visitLogicalBinaryExpression)。同樣出於聚焦核心流程的考慮,我們只實現類似於a > 0 or b < 10 這種整型欄位的過濾。
對於and和or結構,由於是樹形結構,所以會用到遞迴,即優先處理葉子節點再以層層向上彙總。處理處理邏輯如下程式碼所示:
/**
* 處理比較表示式
* @param node
* @param context
* @return
*/
@Override
protected Void visitComparisonExpression(ComparisonExpression node, Map<String,Long> context) {
Expression left = node.getLeft();
Expression right = node.getRight();
String leftKey = ((Identifier) left).getValue();
Long rightKey = ((LongLiteral) right).getValue();
Long leftVal = context.get(leftKey);
if(leftVal == null){
stack.push(false);
}
ComparisonExpression.Operator op = node.getOperator();
switch (op){
case EQUAL:
stack.push(leftVal.equals(rightKey));break;
case LESS_THAN:
stack.push( leftVal < rightKey);;break;
case NOT_EQUAL:
stack.push( !leftVal.equals(rightKey));break;
case GREATER_THAN:
stack.push( leftVal>rightKey);break;
case LESS_THAN_OR_EQUAL:
stack.push( leftVal<=rightKey);break;
case GREATER_THAN_OR_EQUAL:
stack.push( leftVal>=rightKey);break;
case IS_DISTINCT_FROM:
default:
throw new UnsupportedOperationException("not supported");
}
return null;
}
這裡的實現非常簡單,基於棧儲存葉子節點(ComparisonExpression )計算的結果,遞迴回溯非葉子節點(LogicalBinaryExpression )時從棧中取出棧頂的值,進行and和or的運算。說明一下:其實遞迴的實現方式是可以不使用棧,直接返回值即可。這裡基於棧實現是為了跟下文程式碼生成的邏輯從結構上保持一致,方便對比效能。
2.4 驗證表示式執行
為了驗證上述方案執行結果,定義一個簡單的過濾規則,生成亂數驗證能否實現對錶示式邏輯的判斷。
// antlr處理表示式語句,生成Expression物件
SqlParser sqlParser = new SqlParser();
Expression expression = sqlParser.createExpression("a>1 and b<2");
// 基於AstVisitor實現
WhereExpFilter rowFilter = new WhereExpFilter(expression);
Random r = new Random();
for(int i=0;i<10;i++){
Map<String,Long> row = new HashMap<>();
row.put("a", (long) r.nextInt(10));
row.put("b", (long) r.nextInt(10));
System.out.println("exp: a>1 and b<2, param:"+row+", ret:"+rowFilter.filter(row));
}
// ====== 執行結果如下
/**
exp: a>1 and b<2, param:{a=9, b=8}, ret:false
exp: a>1 and b<2, param:{a=7, b=3}, ret:false
exp: a>1 and b<2, param:{a=0, b=7}, ret:false
exp: a>1 and b<2, param:{a=6, b=0}, ret:true
exp: a>1 and b<2, param:{a=2, b=0}, ret:true
exp: a>1 and b<2, param:{a=9, b=0}, ret:true
exp: a>1 and b<2, param:{a=3, b=6}, ret:false
exp: a>1 and b<2, param:{a=8, b=7}, ret:false
exp: a>1 and b<2, param:{a=6, b=1}, ret:true
exp: a>1 and b<2, param:{a=4, b=6}, ret:false
*/
通過上述的處理流程以及執行結果的驗證,可以確定基於Antlr可以非常簡單實現where條件的過濾,這跟antlr實現四則運算能力有異曲同工之妙。但是通過對Presto原始碼及相關檔案閱讀,卻發現實際上對於條件過濾及JOIN的實現是另闢蹊徑。這是為什麼呢?
三、基於 AstVisitor 直接解析 SQL 條件問題
在解答Presto的實現思路之前,需要先鋪墊兩個基礎的知識。一個是CPU的流水線和分支預測,另一個是JVM的方法內聯優化。
3.1 CPU流水線和分支預測
計算機組成原理中關於CPU指令的執行,如下圖所示:
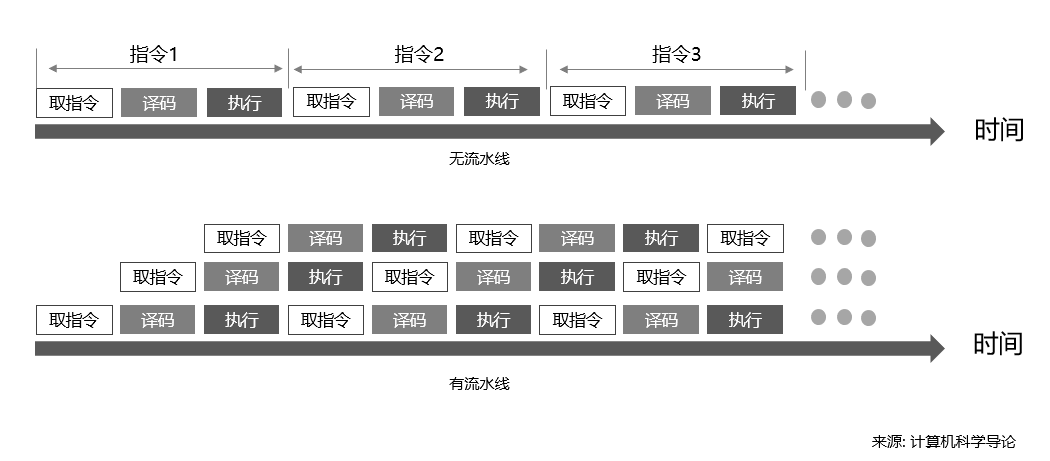
即在早期CPU執行指令採用序列的方式,為了提升CPU的吞吐量,在RISC的架構中通過流水線的方式實現了多條指令重疊進行操作的一種準並行處理實現技術。通過上面的圖示,可以看出:增加一條流水後,單位時間執行的指令數量就翻倍,即效能提升了1倍。
當然這是理想的情況,現實中會遇到兩類問題:
1)下一條指令的執行依賴上一條指令執行的結果。
2)遇到分支必須等條件計算完成才知道分支是否執行。
對於問題1,通過亂序執行的方法能夠將效能提升20%~30%。對於問題2,則是通過分支預測的方法來應對。
關於利用分支預測原理提升效能,有兩個有意思的案例。
案例1:
stackoverflow上有個著名的問題:why-is-processing-a-sorted-array-faster-than-processing-an-unsorted-array。即對於有序陣列和無序陣列的遍歷,執行時間差不多有2~3倍的差距。
在筆者的計算機上,執行案例結果符合描述。需要注意的是用system.nanotime()來衡量,system.currenttimemillis()精度不夠。
案例2:
Dubbo原始碼ChannelEventRunnable中通過將switch程式碼優化成if獲得了近似2倍的效率提升。
簡單總結一下,程式碼中的分支邏輯會影響效能,通過一些優化處理(比如資料排序/熱點程式碼前置)能夠提升分支預測的成功率,從而提升程式執行的效率。
3.2 JVM 方法內聯優化
JVM是基於棧的指令執行策略。一個函數呼叫除了執行自身邏輯的開銷外,還有函數執行上下文資訊維護的額外開銷,例如:棧幀的生成、引數欄位入棧、棧幀的彈出、指令執行地址的跳轉。JVM內聯優化對於效能的影響非常大。
這裡有一個小實驗,對於同一段程式碼正常執行和禁用內聯優化(-XX:CompileCommand=dontinline,
test/TestInline.addOp), 其效能差距差不多有6倍。
程式碼樣例及資料如下:
public class TestInline {
public int addOp(int a,int b){
return a+b;
}
@Benchmark
public int testAdd(){
int sum=0;
for(int i=0;i<100000;i++){
sum=addOp(sum,i);
}
return sum;
}
public static void main(String[] args) throws RunnerException {
Options options = new OptionsBuilder()
.warmupIterations(2).measurementIterations(2)
.forks(1).build();
new Runner(options).run();
}
}
// 執行結果如下:
/**
Benchmark Mode Cnt Score Error Units
TestInline.testAdd thrpt 2 18588.318 ops/s(正常執行)
TestInline.testAdd thrpt 2 3131.466 ops/s(禁用內聯)
**/
對於Java語言,方法內聯優化也是有成本的。所以,通常熱點程式碼/方法體較小的程式碼/用private、static、final修飾的程式碼才可能內聯。過大的方法體和物件導向的繼承和多型都會影響方法的內聯,從而影響效能。
對於SQL 執行引擎中最常見的where和join語句來說,由於執行過程中需要判斷資料型別、操作符型別,幾乎每行資料的處理都是在影響CPU的分支預測,而且每個資料型別,每種操作符都都需要封裝獨立的處理邏輯。如果採用直接解析SQL語句的方式,勢必對分支預測和方法內聯影響極大。為了提升效能,降低分支預測失敗和方法呼叫的開銷,動態程式碼生成的方案就橫空出世了。
四、基於動態程式碼生成實現 where 條件過濾
在介紹使用動態程式碼生成實現where條件過濾前,有必要對位元組碼生成技術的產生背景,Java語言特有的優勢以及相關的基本操作進行介紹。
4.1 位元組碼生成的方法
Java虛擬機器器規範有兩個關鍵點:平臺無關性和語言無關性。
平臺無關性實現了一次編寫,到處執行的目標,。即不受限於作業系統是Windows還是Linux。
語言無關性使得JVM上面執行的語言不限於Java, 像Groovy, Scala,JRuby 都成為了JVM生態的一部分。而能夠實現平臺無關性和語言無關性的的基礎就是基於棧執行指令的虛擬機器器和位元組碼儲存技術。

對於任意一門程式語言:程式分析、程式生成、程式轉換技術在開發中應用廣泛,通常應用在如下的場景中:
- 程式分析:基於語法和語意分析,識別潛在的bug和無用程式碼,或者進行逆向工程,研究軟體內部原理(比如軟體破解或開發爬蟲)
- 程式生成:比如傳統的編譯器、用於分散式系統的stub或skeleton編譯器或者JIT編譯器等。
- 程式轉換: 優化或者混淆程式碼、插入偵錯程式碼、效能監控等。
對於Java程式語言,由於有Java原始碼-位元組碼-機器碼三個層級,所以程式分析、程式生成、程式轉換的技術落地可以有兩個切入點:Java原始碼或者編譯後的Class。選擇編譯後的Class位元組碼有如下的優勢:
- 無需原始碼。這對於閉源的商業軟體也能非常方便實現跨平臺的效能監控等需求。
- 執行時分析、生成、轉換。只要在class位元組碼被載入到虛擬機器器之前處理完就可以了,這樣整個處理流程就對使用者透明瞭。
程式生成技術在Java中通常有另一個名字:位元組碼生成技術。這也表明了Java語言選擇的切入點是編譯後的Class位元組碼。
位元組碼生成技術在Java技術棧中應用也非常廣泛,比如:Spring專案的AOP,各種ORM框架,Tomcat的熱部署等場景。Java有許多位元組碼操作框架,典型的有asm和javassist、bytebuddy、jnif等。
通常出於效能的考量asm用得更為廣泛。直接使用asm需要理解JVM的指令,對使用者來說學習門檻比較高。Facebook基於asm進行了一層封裝,就是airlift.bytecode工具了。基於該工具提供的動態程式碼生成也是presto效能保障的一大利器。使用者使用airlift.bytecode可以避免直接寫JVM指令。但是該框架檔案較少,通常操作只能從其TestCase和presto的原始碼中學習,本小節簡單總結使用airlift.bytecode生成程式碼的基本用法。
通常,我們理解了變數、陣列、控制邏輯、迴圈邏輯、呼叫外部方法這幾個點,就可以操作一門程式語言了。至於核心庫,其作用是輔助我們更高效地開發。對於使用airlift.bytecode框架,理解定義類、定義方法(分支、迴圈和方法呼叫)、方法執行這些常用操作就能夠滿足大部分業務需求:
Case 1: 定義類
private static final AtomicLong CLASS_ID = new AtomicLong();
private static final DateTimeFormatter TIMESTAMP_FORMAT = DateTimeFormatter.ofPattern("YYYYMMdd_HHmmss");
private String clazzName;
private ClassDefinition classDefinition;
public ByteCodeGenDemo(String clazzName){
this.clazzName=clazzName;
}
public static ParameterizedType makeClassName(String baseName, Optional<String> suffix)
{
String className = baseName
+ "_" + suffix.orElseGet(() -> Instant.now().atZone(UTC).format(TIMESTAMP_FORMAT))
+ "_" + CLASS_ID.incrementAndGet();
return typeFromJavaClassName("org.shgy.demo.$gen." + toJavaIdentifierString(className));
}
public void buildClass(){
ClassDefinition classDefinition = new ClassDefinition(
a(PUBLIC, FINAL),
makeClassName(clazzName,Optional.empty()),
type(Object.class));
this.classDefinition=classDefinition;
}
通過上面的程式碼,就定義了一個public final修飾的類,而且確保程式執行彙總類名不會重複。
Case 2: 定義方法--IF控制邏輯
/**
* 生成if分支程式碼
* if(a<0){
* System.out.println(a +" a<0");
* }else{
* System.out.println(a +" a>=0");
* }
* @param methodName
*/
public void buildMethod1(String methodName){
Parameter argA = arg("a", int.class);
MethodDefinition method = classDefinition.declareMethod(
a(PUBLIC, STATIC),
methodName,
type(void.class),
ImmutableList.of(argA));
BytecodeExpression out = getStatic(System.class, "out");
IfStatement ifStatement = new IfStatement();
ifStatement.condition(lessThan(argA,constantInt(0)))
.ifTrue(new BytecodeBlock()
.append(out.invoke("print", void.class, argA))
.append(out.invoke("println", void.class, constantString(" a<0")))
)
.ifFalse(new BytecodeBlock()
.append(out.invoke("print", void.class, argA))
.append(out.invoke("println", void.class, constantString(" a>=0")))
);
method.getBody().append(ifStatement).ret();
}
Case 3: 定義方法–Switch控制邏輯
/**
* 生成switch分支程式碼
* switch (a){
* case 1:
* System.out.println("a=1");
* break;
* case 2:
* System.out.println("a=2");
* break;
* default:
* System.out.println("a=others");
* }
* @param methodName
*/
public void buildMethod2(String methodName){
Parameter argA = arg("a", int.class);
MethodDefinition method = classDefinition.declareMethod(
a(PUBLIC, STATIC),
methodName,
type(void.class),
ImmutableList.of(argA));
SwitchStatement.SwitchBuilder switchBuilder = new SwitchStatement.SwitchBuilder().expression(argA);
switchBuilder.addCase(1, BytecodeExpressions.print(BytecodeExpressions.constantString("a=1")));
switchBuilder.addCase(2,BytecodeExpressions.print(BytecodeExpressions.constantString("a=2")));
switchBuilder.defaultCase(invokeStatic(ByteCodeGenDemo.class,"defaultCase", void.class));
method.getBody().append(switchBuilder.build()).ret();
}
public static void defaultCase(){
System.out.println("a=others");
}
Case 4: 定義方法-ForLoop邏輯
/**
* 生成迴圈邏輯程式碼
* int sum=0;
* for(int i=s;i<=e;i++){
* sum+=i;
* System.out.println("i="+i+",sum="+sum);
* }
* @param methodName
*/
public void buildMethodLoop(String methodName){
Parameter argS = arg("s", int.class);
Parameter argE = arg("e", int.class);
MethodDefinition method = classDefinition.declareMethod(
a(PUBLIC, STATIC),
methodName,
type(int.class),
ImmutableList.of(argS, argE));
Scope scope = method.getScope();
Variable i = scope.declareVariable(int.class,"i");
Variable sum = scope.declareVariable(int.class,"sum");
BytecodeExpression out = getStatic(System.class, "out");
ForLoop loop = new ForLoop()
.initialize(i.set(argS))
.condition(lessThanOrEqual(i, argE))
.update(incrementVariable(i,(byte)1))
.body(new BytecodeBlock()
.append(sum.set(add(sum,i)))
.append(out.invoke("print", void.class, constantString("i=")))
.append(out.invoke("print", void.class, i))
.append(out.invoke("print", void.class, constantString(",sum=")))
.append(out.invoke("println", void.class,sum))
);
method.getBody().initializeVariable(i).putVariable(sum,0).append(loop).append(sum).retInt();
}
Case 5: 生成類並執行方法
public void executeLoop(String methodName) throws NoSuchMethodException, InvocationTargetException, IllegalAccessException {
// invoke
Class<?> clazz = classGenerator(new DynamicClassLoader(this.getClass().getClassLoader())).defineClass(this.classDefinition,Object.class);
Method loopMethod = clazz.getMethod(methodName, int.class,int.class);
loopMethod.invoke(null,1,10);
}
Case 6: 運算元據結構-從Map資料結構取值
public void buildMapGetter(String methodName){
Parameter argRow = arg("row", Map.class);
MethodDefinition method = classDefinition.declareMethod(
a(PUBLIC, STATIC),
methodName,
type(void.class),
of(argRow));
BytecodeExpression out = getStatic(System.class, "out");
Scope scope = method.getScope();
Variable a = scope.declareVariable(int.class,"a");
// 從map中獲取key=aa對應的值
method.getBody().append(out.invoke("print", void.class, argRow.invoke("get",Object.class,constantString("aa").cast(Object.class)))).ret();
}
// 程式碼執行
public void executeMapOp(String methodName) throws NoSuchMethodException, InvocationTargetException, IllegalAccessException {
// invoke
Class<?> clazz = classGenerator(new DynamicClassLoader(this.getClass().getClassLoader())).defineClass(this.classDefinition,Object.class);
Method loopMethod = clazz.getMethod(methodName, Map.class);
Map<String,Integer> map = Maps.newHashMap();
map.put("aa",111);
loopMethod.invoke(null,map);
}
通過上述的幾個Case, 我們瞭解了airlift.bytecode框架的基本用法。如果想更深入研究,需要參考閱讀ASM相關的資料,畢竟airlift.bytecode是基於ASM構建的。但是在本文的研究中,到這裡就夠用了。
4.2 基於動態程式碼生成實現 where 條件過濾
在熟悉動態程式碼生成框架的基本使用方法後,我們就可以使用該工具實現具體的業務邏輯了。同樣地,我們基於AstVisitor實現生成where條件過濾的位元組碼。
整體程式碼框架跟前面的實現保持一致,需要解決問題的關鍵點在於位元組碼生成的邏輯。對於where條件的查詢語句,本質上是一個二元樹。對於二元樹的遍歷,用遞迴是最簡單的方法。遞迴從某種程度上,跟棧的操作是一致的。
對於實現where條件過濾程式碼生成,實現邏輯描述如下:
輸入:antlr生成的expression表示式
輸出:airlift.bytecode生成的class
s1:定義清晰生成類的基礎設定:類名、修飾符等資訊
s2:定義一個棧用於儲存比較運算(ComparisonExpression)計算結果
s3:使用遞迴方式遍歷expression
s4:對於葉子節點(ComparisonExpression),程式碼生成邏輯如下:從方法定義的引數中取出對應的值,根據比較符號生成計算程式碼,並將計算結果push到stack
s5:對於非葉子節點(LogicalBinaryExpression), 程式碼生成邏輯如下:取出棧頂的兩個值,進行and或or操作運算,將計算結果push到stack
s6:當遞迴回退到根節點時,取出棧頂的值作為計算的最終結果
s7:基於類和方法的定義生成Class
實現位元組碼生成程式碼如下:
/**
* 生成比較條件語句
**/
@Override
protected Void visitComparisonExpression(ComparisonExpression node, MethodDefinition context) {
ComparisonExpression.Operator op = node.getOperator();
Expression left = node.getLeft();
Expression right = node.getRight();
if(left instanceof Identifier && right instanceof LongLiteral){
String leftKey = ((Identifier) left).getValue();
Long rightKey = ((LongLiteral) right).getValue();
Parameter argRow = context.getParameters().get(0);
Variable stack = context.getScope().getVariable("stack");
BytecodeBlock body = context.getBody();
BytecodeExpression leftVal = argRow.invoke("get", Object.class,constantString(leftKey).cast(Object.class)).cast(long.class);
BytecodeExpression cResult;
switch (op){
case EQUAL:
cResult = equal(leftVal,constantLong(rightKey));
break;
case LESS_THAN:
cResult = lessThan(leftVal,constantLong(rightKey));
break;
case GREATER_THAN:
cResult =greaterThan(leftVal,constantLong(rightKey));
break;
case NOT_EQUAL:
cResult = notEqual(leftVal,constantLong(rightKey));
break;
case LESS_THAN_OR_EQUAL:
cResult = lessThanOrEqual(leftVal,constantLong(rightKey));
break;
case GREATER_THAN_OR_EQUAL:
cResult = greaterThanOrEqual(leftVal,constantLong(rightKey));
break;
default:
throw new UnsupportedOperationException("not implemented");
}
body.append(stack.invoke("push",Object.class, cResult.cast(Object.class)));
return null;
}else{
throw new UnsupportedOperationException("not implemented");
}
}
程式碼實現完成後,為了驗證處理邏輯是否正常,可以用兩種實現的方式執行同一個測試用例,確保同樣的where表示式在同樣的引數下執行結果一致。
為了驗證兩種實現方式執行的效能,這裡引入JMH框架,基於JMH框架生成效能驗證程式碼:
@BenchmarkMode(Mode.Throughput)
@Fork(1)
@State(value = Scope.Benchmark)
public class RowFilterBenchmark {
private RowFilter filter1;
private RowFilter filter2;
private List<Map<String,Long>> dataSet = Lists.newArrayListWithCapacity(100000);
@Setup
public void init(){
// antlr處理表示式語句,生成Expression物件
SqlParser sqlParser = new SqlParser();
Expression expression = sqlParser.createExpression("a>5 and b<5");
// 基於AstVisitor實現
this.filter1 = new WhereExpFilter(expression);
// 基於AstVisitor實現
ExpressionCodeCompiler compiler = new ExpressionCodeCompiler();
Class clazz = compiler.compile(expression);
try {
this.filter2 = (RowFilter) clazz.newInstance();
} catch (InstantiationException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
}
Random r = new Random();
for(int i=0;i<100000;i++){
Map<String,Long> row = new HashMap<>();
row.put("a", (long) r.nextInt(10));
row.put("b", (long) r.nextInt(10));
dataSet.add(row);
}
}
@Benchmark
public int testAstDirect() {
int cnt =0;
for(Map<String,Long> row:dataSet){
boolean ret = filter1.filter(row);
if(ret){
cnt++;
}
}
return cnt;
}
@Benchmark
public int testAstCompile() {
int cnt =0;
for(Map<String,Long> row:dataSet){
boolean ret = filter2.filter(row);
if(ret){
cnt++;
}
}
return cnt;
}
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder()
.include(RowFilterBenchmark.class.getSimpleName())
.build();
new Runner(opt).run();
}
}
使用10萬量級的資料集,效能驗證的結果如下:
Benchmark Mode Cnt Score Error Units
RowFilterBenchmark.testAstCompile thrpt 5 211.298 ± 30.832 ops/s
RowFilterBenchmark.testAstDirect thrpt 5 62.254 ± 8.269 ops/s
通過上述的驗證資料,可以得出初步的結論,對於簡單的比較表示式,基於程式碼生成的方式相比直接遍歷的方式大約有3倍左右的效能提升。對比直接基於AstVisitor實現where條件過濾,程式碼生成無需對錶示式中的操作符進行判斷,直接基於表示式動態生成程式碼,裁剪了許多判斷的分支。
五、總結
本文探索了SQL引擎中where表示式的實現思路,基於antlr實現了兩種方式:
其一是直接遍歷表示式生成的Expression;
其二是基於表示式生成的Expression通過airlift.bytecode動態生成位元組碼。
本文初步分析了Presto中應用程式碼生成實現相關業務邏輯的出發點及背景問題。並使用JMH進行了效能測試,測試結果表明對於同樣的實現思路,基於程式碼生成方式相比直接實現約有3倍的效能提升。
實際上Presto中使用程式碼生成的方式相比本文描述要複雜得多,跟文字實現的方式並不一樣。基於本文的探索更多在於探索研究基本的思路,而非再造一個Presto。
儘管使用動態程式碼生成對於效能的提升效果明顯,但是在業務實踐中,需要權衡使用程式碼生成的ROI,畢竟使用程式碼生成實現的邏輯,程式碼可讀性和可維護性相比直接編碼要複雜很多,開發複雜度也複雜很多。就像C語言嵌入組合一樣,程式碼生成技術在業務開發中使用同樣需要慎重考慮,使用得當能取得事半功倍的效果,使用不當或濫用則會為專案埋下不可預知的定時炸彈。
參考資料:
- 《電腦科學導論》
- 《深入理解Java虛擬機器器》
- 《asm4-guide》