GO GMP協程排程實現原理 5w字長文史上最全
2022-06-06 12:04:39
1 Runtime簡介
Go語言是網際網路時代的C,因為其語法簡潔易學,對高並行擁有語言級別的親和性。而且不同於虛擬機器器的方案。Go通過在編譯時嵌入平臺相關的系統指令可直接編譯為對應平臺的機器碼,同時嵌入Go Runtime,在執行時實現自身的排程演演算法和各種並行控制方案,避免進入作業系統級別的程序/執行緒上下文切換,以及通過原子操作、自旋、號誌、全域性雜湊表、等待佇列多種技術避免進入作業系統級別鎖,以此來提升整體效能。
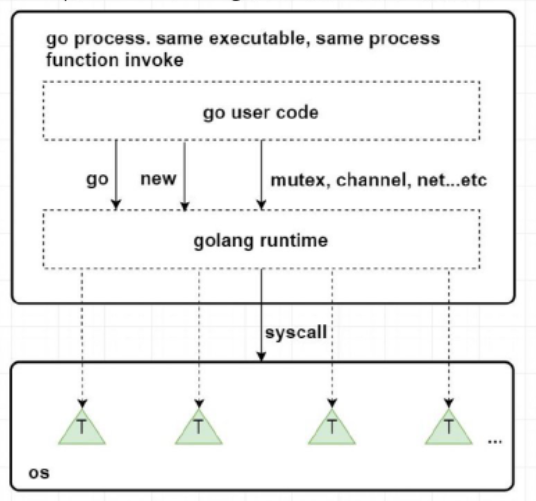
Go的runtime是與使用者程式碼一起打包在一個可執行檔案中,是程式的一部分,而不是向Java需要單獨安裝,與程式獨立。所以使用者程式碼與runtime程式碼在執行時沒有界限都是函數呼叫。在Go語言中的關鍵字編譯時會變成runtime中的函數呼叫。
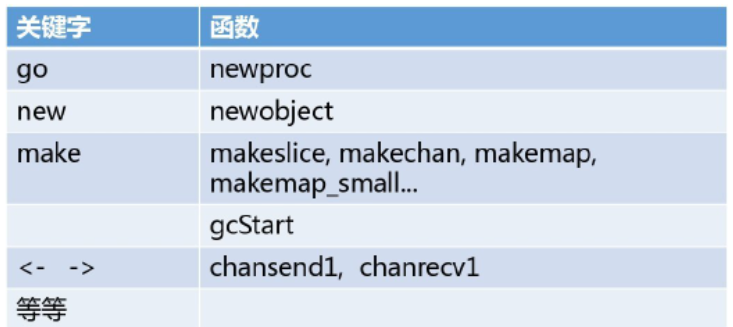
Go Runtime核心主要涉及三大部分:記憶體分配、排程演演算法、垃圾回收;本篇文章我們主要介紹GMP排程原理。關於具體應該叫GPM還是GMP,我更傾向於成為GMP,因為在runtime程式碼中經常看到如下呼叫:
1 buf := &getg().m.p.ptr().wbBuf
其中getg代表獲取當前正在執行的g即goroutine,m代表對應的邏輯處理器,p是邏輯排程器;所以我們還是稱為GMP。
(以上部分圖文來自:https://zhuanlan.zhihu.com/p/95056679)
2 GMP概覽
下面這個圖雖然有些抽象(不如花花綠綠的圖片),確是目前我看到對整個排程演演算法設計的重要概念覆蓋最全的。
1 +-------------------- sysmon ---------------//------+ 2 | | 3 | | 4 +---+ +---+-------+ +--------+ +---+---+ 5 go func() ---> | G | ---> | P | local | <=== balance ===> | global | <--//--- | P | M | 6 +---+ +---+-------+ +--------+ +---+---+ 7 | | | 8 | +---+ | | 9 +----> | M | <--- findrunnable ---+--- steal <--//--+ 10 +---+ 11 | 12 mstart 13 | 14 +--- execute <----- schedule 15 | | 16 | | 17 +--> G.fn --> goexit --+
我們來看下其中的三大主要概念:
- G:Groutine協程,擁有執行函數的指標、棧、上下文(指的是sp、bp、pc等暫存器上下文以及垃圾回收的標記上下文),在整個程式執行過程中可以有無數個,代表一個使用者級程式碼執行流(使用者輕量級執行緒);
- P:Processor,排程邏輯處理器,同樣也是Go中代表資源的分配主體(記憶體資源、協程佇列等),預設為機器核數,可以通過GOMAXPROCS環境變數調整
- M:Machine,代表實際工作的執行者,對應到作業系統級別的執行緒;M的數量會比P多,但不會太多,最大為1w個。
其中G分為三類:
- 主協程,用來執行使用者main函數的協程
- 主協程建立的協程,也是P排程的主要成員
- G0,每個M都有一個G0協程,他是runtime的一部分,G0是跟M繫結的,主要用來執行排程邏輯的程式碼,所以不能被搶佔也不會被排程(普通G也可以執行runtime_procPin禁止搶佔),G0的棧是系統分配的,比普通的G棧(2KB)要大,不能擴容也不能縮容
- sysmon協程,sysmon協程也是runtime的一部分,sysmon協程直接執行在M不需要P,主要做一些檢查工作如:檢查死鎖、檢查計時器獲取下一個要被觸發的計時任務、檢查是否有ready的網路呼叫以恢復使用者G的工作、檢查一個G是否執行時間太長進行搶佔式排程。
M分為兩類:
- 普通M,用來與P繫結執行G中任務
- m0:Go程式是一個程序,程序都有一個主執行緒,m0就是Go程式的主執行緒,通過一個與其繫結的G0來執行runtime啟動載入程式碼;一個Go程式只有一個m0
- 執行sysmon的M,主要用來執行sysmon協程。
剛才說道P是用來排程G的執行,所以每個P都有自己的一個G的佇列,當G佇列都執行完畢後,會從global佇列中獲取一批G放到自己的本地佇列中,如果全域性佇列也沒有待執行的G,則P會再從其他P中竊取一部分G放到自己的佇列中。而排程的時機一般有三種:
- 主動排程,協程通過呼叫`runtime.Goshed`方法主動讓渡自己的執行權利,之後這個協程會被放到全域性佇列中,等待後續被執行
- 被動排程,協程在休眠、channel通道阻塞、網路I/O堵塞、執行垃圾回收時被暫停,被動式讓渡自己的執行權利。大部分場景都是被動排程,這是Go高效能的一個原因,讓M永遠不停歇,不處於等待的協程讓出CPU資源執行其他任務。
- 搶佔式排程,這個主要是sysmon協程上的排程,當發現G處於系統呼叫(如呼叫網路io)超過20微秒或者G執行時間過長(超過10ms),會搶佔G的執行CPU資源,讓渡給其他協程;防止其他協程沒有執行的機會;(系統呼叫會進入核心態,由核心執行緒完成,可以把當前CPU資源讓渡給其他使用者協程)
Go的協程排程與作業系統執行緒排程區別主要存在四個方面:
- 排程發生地點:Go中協程的排程發生在runtime,屬於使用者態,不涉及與核心態的切換;一個協程可以被切換到多個執行緒執行
- 上下文切換速度:協程的切換速度遠快於執行緒,不需要經過核心與使用者態切換,同時需要儲存的狀態和暫存器非常少;執行緒切換速度為1-2微秒,協程切換速度為0.2微秒左右
- 排程策略:執行緒排程大部分都是搶佔式排程,作業系統通過發出中斷訊號強制執行緒切換上下文;Go的協程基本是主動和被動式排程,排程時機可預期
- 棧大小:執行緒棧一般是2MB,而且執行時不能更改大小;Go的協程棧只有2kb,而且可以動態擴容(64位元機最大為1G)
以上基本是整個排程器的概括,不想看原理的同學可以不用往下看了,下面會進行原始碼級介紹;
3 GMP的原始碼結構
原始碼部分主要涉及三個檔案:
1 runtime/amd_64.s 涉及到程序啟動以及對CPU執行指令進行控制的組合程式碼,程序的初始化部分也在這裡面 2 runtime/runtime2.go 這裡主要是執行時中一些重要資料結構的定義,比如g、m、p以及涉及到介面、defer、panic、map、slice等核心型別 3 runtime/proc.go 一些核心方法的實現,涉及gmp排程等核心程式碼在這裡
這裡我們主要關心gmp中與排程相關的程式碼;
3.1 G原始碼部分
3.1.1 G的結構
先來看下g的結構定義:
1 // runtime/runtime2.go 2 type g struct { 3 // 記錄協程棧的棧頂和棧底位置 4 stack stack // offset known to runtime/cgo 5 // 主要作用是參與一些比較計算,當發現容量要超過棧分配空間後,可以進行擴容或者收縮 6 stackguard0 uintptr // offset known to liblink 7 stackguard1 uintptr // offset known to liblink 8 9 // 當前與g繫結的m 10 m *m // current m; offset known to arm liblink 11 // 這是一個比較重要的欄位,裡面儲存的一些與goroutine執行位置相關的暫存器和指標,如rsp、rbp、rpc等暫存器 12 sched gobuf 13 syscallsp uintptr // if status==Gsyscall, syscallsp = sched.sp to use during gc 14 syscallpc uintptr // if status==Gsyscall, syscallpc = sched.pc to use during gc 15 stktopsp uintptr // expected sp at top of stack, to check in traceback 16 17 // 用於做引數傳遞,睡眠時其他goroutine可以設定param,喚醒時該g可以讀取這些param 18 param unsafe.Pointer 19 // 記錄當前goroutine的狀態 20 atomicstatus uint32 21 stackLock uint32 // sigprof/scang lock; TODO: fold in to atomicstatus 22 // goroutine的唯一id 23 goid int64 24 schedlink guintptr 25 26 // 標記是否可以被搶佔 27 preempt bool // preemption signal, duplicates stackguard0 = stackpreempt 28 preemptStop bool // transition to _Gpreempted on preemption; otherwise, just deschedule 29 preemptShrink bool // shrink stack at synchronous safe point 30 31 // 如果呼叫了LockOsThread方法,則g會繫結到某個m上,只在這個m上執行 32 lockedm muintptr 33 sig uint32 34 writebuf []byte 35 sigcode0 uintptr 36 sigcode1 uintptr 37 sigpc uintptr 38 // 建立該goroutine的語句的指令地址 39 gopc uintptr // pc of go statement that created this goroutine 40 ancestors *[]ancestorInfo // ancestor information goroutine(s) that created this goroutine (only used if debug.tracebackancestors) 41 // goroutine函數的指令地址 42 startpc uintptr // pc of goroutine function 43 racectx uintptr 44 waiting *sudog // sudog structures this g is waiting on (that have a valid elem ptr); in lock order 45 cgoCtxt []uintptr // cgo traceback context 46 labels unsafe.Pointer // profiler labels 47 timer *timer // cached timer for time.Sleep 48 selectDone uint32 // are we participating in a select and did someone win the race? 49 }
跟g相關的還有兩個資料結構比較重要:
stack是協程棧的地址資訊,需要注意的是m0繫結的g0是在程序被分配的系統棧上分配協程棧的,而其他協程棧都是在堆上進行分配的。
gobuf中儲存了協程執行的上下文資訊,這裡也可以看到協程切換的上下文資訊極少;sp代表cpu的rsp暫存器的值,pc代表CPU的rip暫存器值、bp代表CPU的rbp暫存器值;ret用來儲存系統呼叫的返回值,ctxt在gc的時候使用。
其中幾個暫存器作用如下:
- SP:永遠指向棧頂位置
- BP:某一時刻的棧頂位置,當新函數呼叫時,把當前SP地址賦值給BP、SP指向新的棧頂位置
- PC:代表程式碼經過編譯為機器碼後,當前執行的機器指令(可以理解為當前語句)
1 // Stack describes a Go execution stack. 2 // The bounds of the stack are exactly [lo, hi), 3 // with no implicit data structures on either side. 4 // goroutine協程棧的棧頂和棧底 5 type stack struct { 6 lo uintptr // 棧頂,低地址 7 hi uintptr // 棧底,高地址 8 } 9 10 // gobuf中儲存了非常重要的上下文執行資訊, 11 type gobuf struct { 12 // 代表cpu的rsp暫存器的值,永遠指向棧頂位置 13 sp uintptr 14 // 代表程式碼經過編譯為機器碼後,當前執行的機器指令(可以理解為當前語句) 15 pc uintptr 16 // 指向所儲存執行上下文的goroutine 17 g guintptr 18 // gc時候使用 19 ctxt unsafe.Pointer 20 // 用來儲存系統呼叫的返回值 21 ret uintptr 22 lr uintptr 23 // 某一時刻的棧頂位置,當新函數呼叫時,把當前SP地址賦值給BP、SP指向新的棧頂位置 24 bp uintptr // for framepointer-enabled architectures 25 }
3.1.2 G的狀態
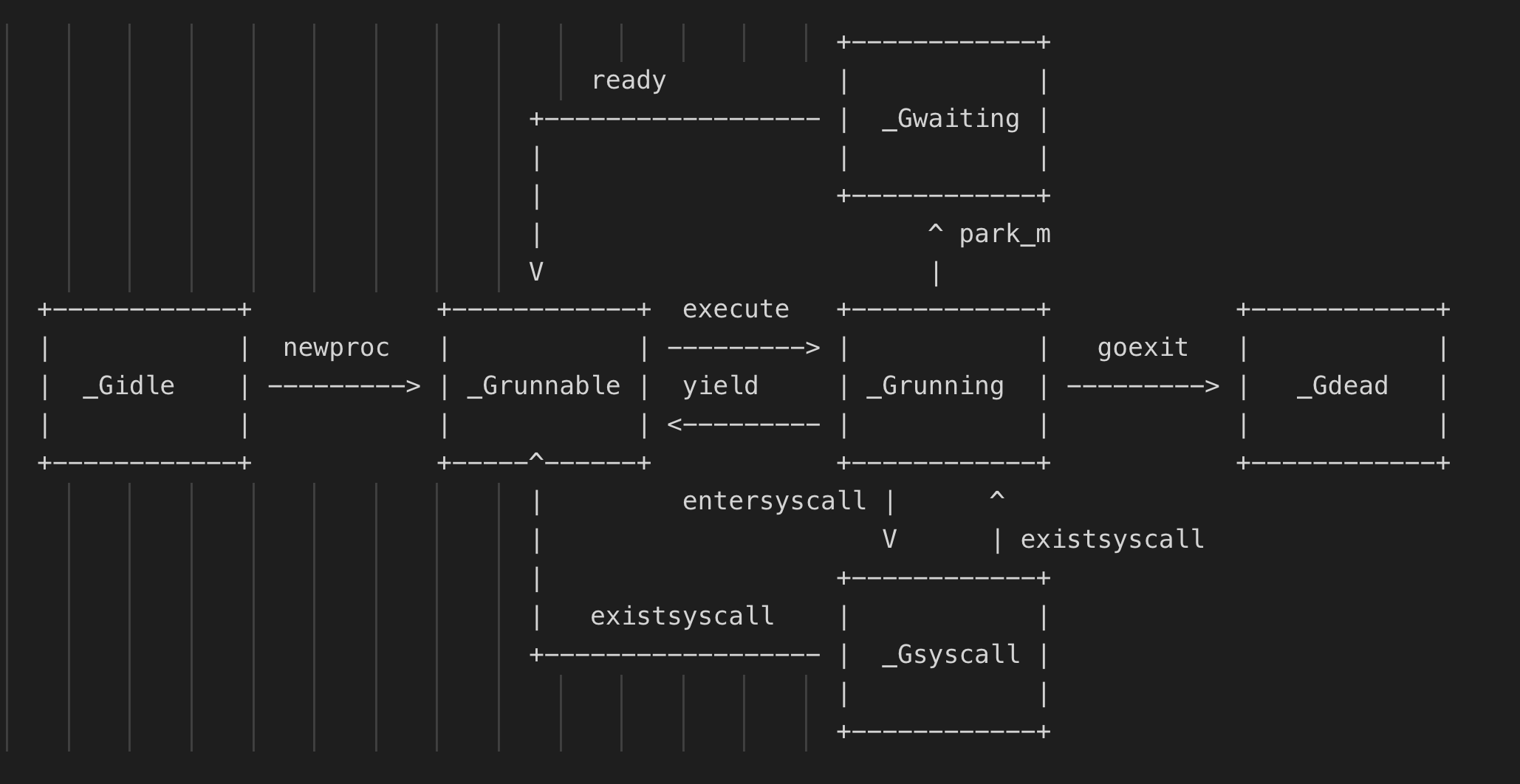
就像執行緒有自己的狀態一樣,goroutine也有自己的狀態,主要記錄在atomicstatus欄位上:
1 // defined constants 2 const ( 3 // 代表協程剛開始建立時的狀態,當新建立的協程初始化後,為變為_Gdead狀態,_Gdread也是協程被銷燬時的狀態; 4 // 剛建立時也被會置為_Gdead主要是考慮GC可以去用去掃描dead狀態下的協程棧 5 _Gidle = iota // 0 6 // 代表協程正在執行佇列中,等待被執行 7 _Grunnable // 1 8 // 代表當前協程正在被執行,已經被分配了邏輯處理的執行緒,即p和m 9 _Grunning // 2 10 // 代表當前協程正在執行系統呼叫 11 _Gsyscall // 3 12 // 表示當前協程在執行時被鎖定,陷入阻塞,不能執行使用者程式碼 13 _Gwaiting // 4 14 15 _Gmoribund_unused // 5 16 // 新建立的協程初始化後,或者協程被銷燬後的狀態 17 _Gdead // 6 18 19 // _Genqueue_unused is currently unused. 20 _Genqueue_unused // 7 21 // 代表在進行協程棧掃描時發現需要擴容或者縮容,將協程中的棧轉移到新棧時的狀態;這個時候不執行使用者程式碼,也不在p的runq中 22 _Gcopystack // 8 23 24 // 代表g被搶佔後的狀態 25 _Gpreempted // 9 26 27 // 這幾個狀態是垃圾回收時涉及,後續文章進行介紹 28 _Gscan = 0x1000 29 _Gscanrunnable = _Gscan + _Grunnable // 0x1001 30 _Gscanrunning = _Gscan + _Grunning // 0x1002 31 _Gscansyscall = _Gscan + _Gsyscall // 0x1003 32 _Gscanwaiting = _Gscan + _Gwaiting // 0x1004 33 _Gscanpreempted = _Gscan + _Gpreempted // 0x1009 34 )
這裡是利用常數定義的列舉。
Go的狀態變更可以看下圖:
3.1.3 G的建立
當我們使用go關鍵字新建一個goroutine時,編譯器會編譯為runtime中對應的函數呼叫(newproc,而go 關鍵字後面的函數成為協程的任務函數),進行建立,整體步驟如下:
1. 用 systemstack 切換到系統堆疊,呼叫 newproc1 ,newproc1 實現g的獲取。
2. 嘗試從p的本地g空閒連結串列和全域性g空閒連結串列找到一個g的範例。
3. 如果上面未找到,則呼叫 malg 生成新的g的範例,且分配好g的棧和設定好棧的邊界,接著新增到 allgs 陣列裡面,allgs儲存了所有的g。
4. 儲存g切換的上下文,這裡很關鍵,g的切換依賴 sched 欄位。
5. 生成唯一的goid,賦值給該g。
6. 呼叫 runqput 將g插入佇列中,如果本地佇列還有剩餘的位置,將G插入本地佇列的尾部,若本地佇列已滿,插入全域性佇列。
7. 如果有空閒的p 且 m沒有處於自旋狀態 且 main goroutine已經啟動,那麼喚醒或新建某個m來執行任務。
這裡對應的是newproc函數:
1 func newproc(siz int32, fn *funcval) { 2 argp := add(unsafe.Pointer(&fn), sys.PtrSize) 3 gp := getg() 4 // 獲取呼叫者的指令地址,也就是呼叫newproc時又call指令壓棧的函數返回地址 5 pc := getcallerpc() 6 // systemstack的作用是切換到m0對應的g0所屬的系統棧 7 // 使用g0所在的系統棧建立goroutine物件 8 // 傳遞引數包括goroutine的任務函數、argp引數起始地址、siz是引數長度、呼叫方的pc指標 9 systemstack(func() { 10 newg := newproc1(fn, argp, siz, gp, pc) 11 // 建立完成後將g放到建立者(某個g,如果是程序初始化啟動階段則為g0)所在的p的佇列中 12 _p_ := getg().m.p.ptr() 13 runqput(_p_, newg, true) 14 15 if mainStarted { 16 wakep() 17 } 18 }) 19 }
其中systemstack是一段組合程式碼,位於asm_amd64.s檔案中,主要是暫存器指令的操作,筆者不懂組合這裡先不做介紹。
newproc1是獲取newg的函數,主要步驟:
1、首先防止當前g被搶佔,繫結m
2、對傳入的引數佔用的記憶體空間進行對齊處理
3、從p的空閒佇列中獲取一個空閒的g,如果麼有就建立一個g,並在堆上建立協程棧,並設定狀態為_Gdead新增到全域性allgs中
4、計算整體協程任務函數的引數空間大小,並設定sp指標
5、執行引數從getg的堆疊到newg堆疊的複製
6、設定newg的sched和startpc、gopc等跟上下文相關的欄位值
7、設定newg狀態為runable並設定goid
8、接觸getg與m的防搶佔狀態
程式碼註釋如下:
1 func newproc1(fn *funcval, argp unsafe.Pointer, narg int32, callergp *g, callerpc uintptr) *g { 2 ..... 3 // 如果是初始化時候這個代表g0 4 _g_ := getg() 5 6 if fn == nil { 7 _g_.m.throwing = -1 // do not dump full stacks 8 throw("go of nil func value") 9 } 10 // 使_g_.m.locks++,來防止這個時候g對應的m被搶佔 11 acquirem() // disable preemption because it can be holding p in a local var 12 // 引數的地址,下面一句目的是為了做到記憶體對齊 13 siz := narg 14 siz = (siz + 7) &^ 7 15 16 // We could allocate a larger initial stack if necessary. 17 // Not worth it: this is almost always an error. 18 // 4*PtrSize: extra space added below 19 // PtrSize: caller's LR (arm) or return address (x86, in gostartcall). 20 if siz >= _StackMin-4*sys.PtrSize-sys.PtrSize { 21 throw("newproc: function arguments too large for new goroutine") 22 } 23 24 _p_ := _g_.m.p.ptr() 25 newg := gfget(_p_) // 首先從p的gfree佇列中看看有沒有空閒的g,有則使用 26 if newg == nil { 27 // 如果沒找到就使用new關鍵字來建立一個g並在堆上分配棧空間 28 newg = malg(_StackMin) 29 // 將newg的狀態設定為_Gdead,因為這樣GC就不會去掃描一個沒有初始化的協程棧 30 casgstatus(newg, _Gidle, _Gdead) 31 // 新增到全域性的allg切片中(需要加鎖存取) 32 allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack. 33 } 34 // 下面是檢查協程棧的建立情況和狀態 35 if newg.stack.hi == 0 { 36 throw("newproc1: newg missing stack") 37 } 38 39 if readgstatus(newg) != _Gdead { 40 throw("newproc1: new g is not Gdead") 41 } 42 // 計算執行空間大小並進行記憶體對齊 43 totalSize := 4*sys.PtrSize + uintptr(siz) + sys.MinFrameSize // extra space in case of reads slightly beyond frame 44 totalSize += -totalSize & (sys.StackAlign - 1) // align to StackAlign 45 // 計算sp暫存器指標的位置 46 sp := newg.stack.hi - totalSize 47 // 確定引數入棧位置 48 spArg := sp 49 ......... 50 if narg > 0 { 51 // 將引數從newproc函數的棧複製到新的協程的棧中,memove是一段組合程式碼 52 // 從argp位置挪動narg大小的記憶體到sparg位置 53 memmove(unsafe.Pointer(spArg), argp, uintptr(narg)) 54 // 因為涉及到從棧到堆疊上的複製,go在垃圾回收中使用了三色標記和寫入屏障等手段,所以這裡要考慮屏障複製 55 // 目標棧可能會有垃圾存在,所以設定屏障並且標記為灰色 56 if writeBarrier.needed && !_g_.m.curg.gcscandone { // 如果啟用了寫入屏障並且源堆疊為灰色(目標始終為黑色),則執行屏障複製。 57 f := findfunc(fn.fn) 58 stkmap := (*stackmap)(funcdata(f, _FUNCDATA_ArgsPointerMaps)) 59 if stkmap.nbit > 0 { 60 // We're in the prologue, so it's always stack map index 0. 61 bv := stackmapdata(stkmap, 0) 62 bulkBarrierBitmap(spArg, spArg, uintptr(bv.n)*sys.PtrSize, 0, bv.bytedata) 63 } 64 } 65 } 66 // 把newg的sched結構體成員的所有欄位都設定為0,其實就是初始化 67 memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched)) 68 newg.sched.sp = sp 69 newg.stktopsp = sp 70 // pc指標表示當newg被排程起來時從這個位置開始執行 71 // 這裡是先設定為goexit,在gostartcallfn中會進行處理,更改sp為這裡的pc,將pc改為真正的協程任務函數fn的指令位置 72 // 這樣使得任務函數執行完畢後,會繼續執行goexit中相關的清理工作 73 newg.sched.pc = abi.FuncPCABI0(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same function 74 newg.sched.g = guintptr(unsafe.Pointer(newg)) // 儲存當前的g 75 gostartcallfn(&newg.sched, fn) // 在這裡完成g啟動時所有相關上下文指標的設定,主要為sp、pc和ctxt,ctxt被設定為fn 76 newg.gopc = callerpc // 儲存newproc的pc,即呼叫者建立時的指令位置 77 newg.ancestors = saveAncestors(callergp) 78 // 設定startpc為任務函數,主要用於函數呼叫棧的trackback和棧收縮工作 79 // newg的執行開始位置並不依賴這個欄位,而是通過sched.pc確定 80 newg.startpc = fn.fn 81 if _g_.m.curg != nil { 82 newg.labels = _g_.m.curg.labels 83 } 84 // 判斷newg的任務函數是不是runtime系統的任務函數,是則sched.ngsys+1; 85 // 主協程則代表runtime.main函數,在這裡就為判斷為真 86 if isSystemGoroutine(newg, false) { 87 atomic.Xadd(&sched.ngsys, +1) 88 } 89 // Track initial transition? 90 newg.trackingSeq = uint8(fastrand()) 91 if newg.trackingSeq%gTrackingPeriod == 0 { 92 newg.tracking = true 93 } 94 // 更改當前g的狀態為_Grunnable 95 casgstatus(newg, _Gdead, _Grunnable) 96 // 設定g的goid,因為p會每次批次生成16個id,每次newproc如果新建一個g,id就會加1 97 // 所以這裡m0的g0的id為0,而主協程的goid為1,其他的依次遞增 98 if _p_.goidcache == _p_.goidcacheend { 99 // Sched.goidgen is the last allocated id, 100 // this batch must be [sched.goidgen+1, sched.goidgen+GoidCacheBatch]. 101 // At startup sched.goidgen=0, so main goroutine receives goid=1. 102 // 使用原子操作修改全域性變數,這裡的sched是在runtime2.go中的一個全域性變數型別為schedt 103 // 原子操作具有多執行緒可見性,同時比加鎖效能更高 104 _p_.goidcache = atomic.Xadd64(&sched.goidgen, _GoidCacheBatch) 105 _p_.goidcache -= _GoidCacheBatch - 1 106 _p_.goidcacheend = _p_.goidcache + _GoidCacheBatch 107 } 108 newg.goid = int64(_p_.goidcache) 109 _p_.goidcache++ 110 if raceenabled { 111 newg.racectx = racegostart(callerpc) 112 } 113 if trace.enabled { 114 traceGoCreate(newg, newg.startpc) 115 } 116 // 釋放getg與m的繫結 117 releasem(_g_.m) 118 119 return newg 120 }
其中有幾個關鍵地方需要強調
3.1.4 協程棧在堆空間的分配
malg函數,用來建立一個新g和對應的棧空間分配,這個函數主要強調的是棧空間分配部分,通過切換到系統棧上進行空間分配,分配完後設定棧底和棧頂的兩個位置的保護欄位,當棧上進行分配變數空間發現超過stackguard1時,會進行擴容,同時在某些條件下也會進行縮容
1 // Allocate a new g, with a stack big enough for stacksize bytes. 2 func malg(stacksize int32) *g { 3 newg := new(g) 4 if stacksize >= 0 { 5 stacksize = round2(_StackSystem + stacksize) 6 systemstack(func() { 7 newg.stack = stackalloc(uint32(stacksize)) 8 }) 9 newg.stackguard0 = newg.stack.lo + _StackGuard 10 newg.stackguard1 = ^uintptr(0) 11 // Clear the bottom word of the stack. We record g 12 // there on gsignal stack during VDSO on ARM and ARM64. 13 *(*uintptr)(unsafe.Pointer(newg.stack.lo)) = 0 14 } 15 return newg 16 }
stackalloc程式碼位於runtime/stack.go檔案中;
協程棧首先在程序初始化時會建立棧的管理結構:
1、棧池stackpool,這個棧池主要用來對大小為2、4、8kb的小棧做快取使用,使用的同樣是mspan這種結構來儲存;
2、為大棧分配的stackLarge
1 OS | FixedStack | NumStackOrders 2 -----------------+------------+--------------- 3 linux/darwin/bsd | 2KB | 4 4 windows/32 | 4KB | 3 5 windows/64 | 8KB | 2 6 plan9 | 4KB | 3 7 8 // Global pool of spans that have free stacks. 9 // Stacks are assigned an order according to size. 10 // order = log_2(size/FixedStack) 11 // There is a free list for each order. 12 var stackpool [_NumStackOrders]struct { 13 item stackpoolItem 14 _ [cpu.CacheLinePadSize - unsafe.Sizeof(stackpoolItem{})%cpu.CacheLinePadSize]byte 15 } 16 17 //go:notinheap 18 type stackpoolItem struct { 19 mu mutex 20 span mSpanList 21 } 22 23 // Global pool of large stack spans. 24 var stackLarge struct { 25 lock mutex 26 free [heapAddrBits - pageShift]mSpanList // free lists by log_2(s.npages) 27 } 28 29 func stackinit() { 30 if _StackCacheSize&_PageMask != 0 { 31 throw("cache size must be a multiple of page size") 32 } 33 for i := range stackpool { 34 stackpool[i].item.span.init() 35 lockInit(&stackpool[i].item.mu, lockRankStackpool) 36 } 37 for i := range stackLarge.free { 38 stackLarge.free[i].init() 39 lockInit(&stackLarge.lock, lockRankStackLarge) 40 } 41 }
stackalloc會首先判斷棧空間大小,是大棧還是固定空間的小棧,
1、對於小棧,如果是還沒有分配棧快取空間,則進入stackpoolalloc函數進行分配空間(需要加鎖),這裡最終是從全域性的mheap也就是堆空間中獲取記憶體空間;如果有棧快取空間,則從g對應的mcache中的stackcache上獲取記憶體空間(無鎖),如果stackcache上沒有足夠空間則呼叫stackcacherefill方法為stackpool進行擴容(也是從mheap中拿取,加鎖)然後分配給協程
2、對於大棧,先從stackLarge中獲取,如果沒有則從mheap中獲取,兩個步驟都需要載入存取;
3、最後建立stack結構返回給newg
1 func stackalloc(n uint32) stack { 2 // Stackalloc must be called on scheduler stack, so that we 3 // never try to grow the stack during the code that stackalloc runs. 4 // Doing so would cause a deadlock (issue 1547). 5 thisg := getg() 6 ......... 7 8 // Small stacks are allocated with a fixed-size free-list allocator. 9 // If we need a stack of a bigger size, we fall back on allocating 10 // a dedicated span. 11 var v unsafe.Pointer 12 if n < _FixedStack<<_NumStackOrders && n < _StackCacheSize { 13 order := uint8(0) 14 n2 := n 15 for n2 > _FixedStack { 16 order++ 17 n2 >>= 1 18 } 19 var x gclinkptr 20 if stackNoCache != 0 || thisg.m.p == 0 || thisg.m.preemptoff != "" { 21 // thisg.m.p == 0 can happen in the guts of exitsyscall 22 // or procresize. Just get a stack from the global pool. 23 // Also don't touch stackcache during gc 24 // as it's flushed concurrently. 25 lock(&stackpool[order].item.mu) 26 x = stackpoolalloc(order) 27 unlock(&stackpool[order].item.mu) 28 } else { 29 c := thisg.m.p.ptr().mcache 30 x = c.stackcache[order].list 31 if x.ptr() == nil { 32 stackcacherefill(c, order) 33 x = c.stackcache[order].list 34 } 35 c.stackcache[order].list = x.ptr().next 36 c.stackcache[order].size -= uintptr(n) 37 } 38 v = unsafe.Pointer(x) 39 } else { 40 var s *mspan 41 npage := uintptr(n) >> _PageShift 42 log2npage := stacklog2(npage) 43 44 // Try to get a stack from the large stack cache. 45 lock(&stackLarge.lock) 46 if !stackLarge.free[log2npage].isEmpty() { 47 s = stackLarge.free[log2npage].first 48 stackLarge.free[log2npage].remove(s) 49 } 50 unlock(&stackLarge.lock) 51 52 lockWithRankMayAcquire(&mheap_.lock, lockRankMheap) 53 54 if s == nil { 55 // Allocate a new stack from the heap. 56 s = mheap_.allocManual(npage, spanAllocStack) 57 if s == nil { 58 throw("out of memory") 59 } 60 osStackAlloc(s) 61 s.elemsize = uintptr(n) 62 } 63 v = unsafe.Pointer(s.base()) 64 } 65 66 if raceenabled { 67 racemalloc(v, uintptr(n)) 68 } 69 if msanenabled { 70 msanmalloc(v, uintptr(n)) 71 } 72 if stackDebug >= 1 { 73 print(" allocated ", v, "\n") 74 } 75 return stack{uintptr(v), uintptr(v) + uintptr(n)} 76 }
非g0的g為什麼要在堆上分配空間?
雖然堆不如棧快,但是goroutine是go模擬的執行緒,具有動態擴容和縮容的能力,而系統棧是線性空間,在系統棧上發生縮容和擴容會存在空間不足或者棧空間碎片等問題;所以go這裡在堆上分配協程棧;因為是在堆空間也就意味著這部分空間也需要進行垃圾回收和釋放;所以Go的GC是多執行緒並行標記時,記憶體屏障是對整個協程棧標記灰色,來讓回收器進行掃描。
3.1.5 G的上下文設定和切換
協程棧的切換主要是在兩個地方,由執行排程邏輯的g0切換到執行使用者邏輯的g的過程,以及執行使用者邏輯的g退出或者被搶佔切換為g0執行排程的過程,搶佔在下文中介紹
上面程式碼中當newg被初始化時,會初始化sched中的pc和sp指標,其中會把pc先設定為goexit函數的第二條指令。
1 // 把newg的sched結構體成員的所有欄位都設定為0,其實就是初始化 2 memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched)) 3 newg.sched.sp = sp 4 newg.stktopsp = sp 5 // pc指標表示當newg被排程起來時從這個位置開始執行 6 // 這裡是先設定為goexit,在gostartcallfn中會進行處理,更改sp為這裡的pc,將pc改為真正的協程任務函數fn的指令位置 7 // 這樣使得任務函數執行完畢後,會繼續執行goexit中相關的清理工作 8 newg.sched.pc = abi.FuncPCABI0(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same function 9 newg.sched.g = guintptr(unsafe.Pointer(newg)) // 儲存當前的g 10 gostartcallfn(&newg.sched, fn) // 在這裡完成g啟動時所有相關上下文指標的設定,主要為sp、pc和ctxt,ctxt被設定為fn 11 newg.gopc = callerpc // 儲存newproc的pc,即呼叫者建立時的指令位置
然後進入gostartcallfn函數,最終是在gostartcall函數中進行處理
1 // gostartcallfn 位於runtime/stack.go中 2 3 func gostartcallfn(gobuf *gobuf, fv *funcval) { 4 var fn unsafe.Pointer 5 if fv != nil { 6 fn = unsafe.Pointer(fv.fn) 7 } else { 8 fn = unsafe.Pointer(funcPC(nilfunc)) 9 } 10 gostartcall(gobuf, fn, unsafe.Pointer(fv)) 11 } 12 13 // gostartcall 位於runtime/sys_x86.go中 14 15 func gostartcall(buf *gobuf, fn, ctxt unsafe.Pointer) { 16 // newg的棧頂,目前newg棧上只有fn函數的引數,sp指向的是fn的第一個引數 17 sp := buf.sp 18 // 為返回地址預留空間 19 sp -= sys.PtrSize 20 // buf.pc中設定的是goexit函數中的第二條指令 21 // 因為棧是自頂向下,先進後出,所以這裡偽裝fn是被goexit函數呼叫的,goexit在前fn在後 22 // 使得fn返回後到goexit繼續執行,以完成一些清理工作。 23 *(*uintptr)(unsafe.Pointer(sp)) = buf.pc 24 buf.sp = sp // 重新設定棧頂 25 // 將pc指向goroutine的任務函數fn,這樣當goroutine獲得執行權時,從任務函數入口開始執行 26 // 如果是主協程,那麼fn就是runtime.main,從這裡開始執行 27 buf.pc = uintptr(fn) 28 buf.ctxt = ctxt 29 }
可以看到在newg初始化時進行的一系列設定工作,將goexit先壓入棧頂,然後偽造sp位置,讓cpu看起來是從goexit中呼叫的協程任務函數,然後將pc指標指向任務函數,當協程被執行時,從pc處開始執行,任務函數執行完畢後執行goexit;
這裡是設定工作,具體的切換工作,需要經由schedule排程函數選中一個g,進入execute函數設定g的相關狀態和棧保護欄位等資訊,然後進入gogo函數,通過組合語言,將CPU暫存器以及函數呼叫棧切換為g的sched中相關指標和協程棧。gogo函數原始碼如下:
1 // gogo的具體組合程式碼位於asm_amd64.s中 2 3 // func gogo(buf *gobuf) 4 // restore state from Gobuf; longjmp 5 TEXT runtime·gogo(SB), NOSPLIT, $0-8 6 // 0(FP)表示第一個引數,即buf=&gp.sched 7 MOVQ buf+0(FP), BX // gobuf 8 // DX = gp.sched.g,DX代表資料暫存器 9 MOVQ gobuf_g(BX), DX 10 MOVQ 0(DX), CX // make sure g != nil 11 JMP gogo<>(SB) 12 13 TEXT gogo<>(SB), NOSPLIT, $0 14 // 將tls儲存到CX暫存器 15 get_tls(CX) 16 // 下面這條指令把當前要執行的g(上面第9行中已經把go_buf中的g放入到了DX中), 17 // 放入CX暫存器的g位置即tls[0]這個位置,也就是執行緒的本地儲存中, 18 // 這樣下次runtime中呼叫getg時獲取的就是這個g 19 MOVQ DX, g(CX) 20 MOVQ DX, R14 // set the g register 21 // 把CPU的SP暫存器設定為g.sched.sp這樣就完成了棧的切換,從g0切換為g 22 MOVQ gobuf_sp(BX), SP // restore SP 23 // 將ret、ctxt、bp分別存入對應的暫存器,完成了CPU上下文的切換 24 MOVQ gobuf_ret(BX), AX 25 MOVQ gobuf_ctxt(BX), DX 26 MOVQ gobuf_bp(BX), BP 27 // 清空sched的值,相關值已經存入到暫存器中,這裡清空後可以減少GC的工作量 28 MOVQ $0, gobuf_sp(BX) // clear to help garbage collector 29 MOVQ $0, gobuf_ret(BX) 30 MOVQ $0, gobuf_ctxt(BX) 31 MOVQ $0, gobuf_bp(BX) 32 // 把sched.pc放入BX暫存器 33 MOVQ gobuf_pc(BX), BX 34 // JMP把BX的值放入CPU的IP暫存器,所以這時候CPU從該地址開始繼續執行指令 35 JMP BX
AX、BX、CX、DX是8086處理器的4個資料暫存器,可以簡單認為相當於4個硬體的變數;
上文總體來說,將g存入到tls中(執行緒的本地儲存),設定SP和相關暫存器為g.sched中的欄位(SP、ret、ctxt、bp),然後跳轉到pc指標位置執行指令
3.1.6 G的退出處理
協程棧的退出需要分為兩種情況,即執行main函數的主協程和普通的使用者協程;
主協程的fn任務函數位於proc.go中的main函數中,對於主協程g.shched.pc指向的也是這個位置,這裡會呼叫使用者的mian函數(main_main),main_main執行完畢後,會呼叫exit(0)直接退出,而不會跑到goexit函數中。
1 // runtime/proc.go 中的main函數 2 // The main goroutine. 3 func main() { 4 g := getg() 5 6 ................. 7 fn := main_main // make an indirect call, as the linker doesn't know the address of the main package when laying down the runtime 8 fn() 9 .................. 10 .................. 11 exit(0) 12 .................. 13 }
使用者協程因為將goexit作為協程棧棧底,所以當執行完協程任務函數時,會執行goexit函數,goexit是一段組合指令:
1 // The top-most function running on a goroutine 2 // returns to goexit+PCQuantum. 3 TEXT runtime·goexit(SB),NOSPLIT|TOPFRAME,$0-0 4 BYTE $0x90 // NOP 5 CALL runtime·goexit1(SB) // does not return 6 // traceback from goexit1 must hit code range of goexit 7 BYTE $0x90 // NOP
這裡直接呼叫goexit1,goexit1位於runtime/proc.go中
1 // Finishes execution of the current goroutine. 2 func goexit1() { 3 if raceenabled { 4 racegoend() 5 } 6 if trace.enabled { 7 traceGoEnd() 8 } 9 mcall(goexit0) 10 }
通過mcall呼叫goexit0,mcall是一段組合程式碼它的作用是把執行的棧切換到g0的棧
1 TEXT runtime·mcall<ABIInternal>(SB), NOSPLIT, $0-8 2 MOVQ AX, DX // DX = fn 3 4 // save state in g->sched 5 // mcall返回地址放入BX中 6 MOVQ 0(SP), BX // caller's PC 7 // 下面部分是儲存g的執行上下文,pc、sp、bp 8 // g.shced.pc = BX 9 MOVQ BX, (g_sched+gobuf_pc)(R14) 10 LEAQ fn+0(FP), BX // caller's SP 11 MOVQ BX, (g_sched+gobuf_sp)(R14) 12 MOVQ BP, (g_sched+gobuf_bp)(R14) 13 14 // switch to m->g0 & its stack, call fn 15 // 將g.m儲存到BX暫存器中 16 MOVQ g_m(R14), BX 17 // 這段程式碼意思是從m結構體中獲取g0欄位儲存到SI中 18 MOVQ m_g0(BX), SI // SI = g.m.g0 19 CMPQ SI, R14 // if g == m->g0 call badmcall 20 // goodm中完成了從g的棧切換到g0的棧 21 JNE goodm 22 JMP runtime·badmcall(SB) 23 goodm: 24 MOVQ R14, AX // AX (and arg 0) = g 25 MOVQ SI, R14 // g = g.m.g0 26 get_tls(CX) // Set G in TLS 27 MOVQ R14, g(CX) 28 MOVQ (g_sched+gobuf_sp)(R14), SP // sp = g0.sched.sp 29 PUSHQ AX // open up space for fn's arg spill slot 30 MOVQ 0(DX), R12 31 // 這裡意思是呼叫goexit0(g) 32 CALL R12 // fn(g) 33 POPQ AX 34 JMP runtime·badmcall2(SB) 35 RET
goexit0程式碼位於runtime/proc.go中,他主要完成最後的清理工作:
1、把g的狀態從——Gruning變為Gdead
2、清空g的一些欄位
3、接觸g與m的繫結關係,即g.m = nil;m.currg = nil
4、把g放入p的freeg佇列中,下次建立g可以直接獲取,而不用從記憶體分配
5、呼叫schedule進入下一次排程迴圈
1 // 這段程式碼執行在g0的棧上,gp是我們要處理退出的g的結構體指標 2 // goexit continuation on g0. 3 func goexit0(gp *g) { 4 _g_ := getg() // 獲取g0 5 // 更改g的狀態為_Gdead 6 casgstatus(gp, _Grunning, _Gdead) 7 if isSystemGoroutine(gp, false) { 8 atomic.Xadd(&sched.ngsys, -1) 9 } 10 // 清空g的一些欄位 11 gp.m = nil 12 locked := gp.lockedm != 0 13 gp.lockedm = 0 14 _g_.m.lockedg = 0 15 gp.preemptStop = false 16 gp.paniconfault = false 17 gp._defer = nil // should be true already but just in case. 18 gp._panic = nil // non-nil for Goexit during panic. points at stack-allocated data. 19 gp.writebuf = nil 20 gp.waitreason = 0 21 gp.param = nil 22 gp.labels = nil 23 gp.timer = nil 24 25 if gcBlackenEnabled != 0 && gp.gcAssistBytes > 0 { 26 // Flush assist credit to the global pool. This gives 27 // better information to pacing if the application is 28 // rapidly creating an exiting goroutines. 29 assistWorkPerByte := float64frombits(atomic.Load64(&gcController.assistWorkPerByte)) 30 scanCredit := int64(assistWorkPerByte * float64(gp.gcAssistBytes)) 31 atomic.Xaddint64(&gcController.bgScanCredit, scanCredit) 32 gp.gcAssistBytes = 0 33 } 34 // 接觸g與m的繫結關係 35 dropg() 36 37 if GOARCH == "wasm" { // no threads yet on wasm 38 gfput(_g_.m.p.ptr(), gp) 39 schedule() // never returns 40 } 41 42 if _g_.m.lockedInt != 0 { 43 print("invalid m->lockedInt = ", _g_.m.lockedInt, "\n") 44 throw("internal lockOSThread error") 45 } 46 // 將g加入p的空閒佇列 47 gfput(_g_.m.p.ptr(), gp) 48 if locked { 49 // The goroutine may have locked this thread because 50 // it put it in an unusual kernel state. Kill it 51 // rather than returning it to the thread pool. 52 53 // Return to mstart, which will release the P and exit 54 // the thread. 55 if GOOS != "plan9" { // See golang.org/issue/22227. 56 gogo(&_g_.m.g0.sched) 57 } else { 58 // Clear lockedExt on plan9 since we may end up re-using 59 // this thread. 60 _g_.m.lockedExt = 0 61 } 62 } 63 // 執行下一輪排程 64 schedule() 65 }
3.2 P原始碼部分
3.2.1 P的結構
1 // runtime/runtime2.go 2 3 type p struct { 4 // 全域性變數allp中的索引位置 5 id int32 6 // p的狀態標識 7 status uint32 // one of pidle/prunning/... 8 link puintptr 9 // 呼叫schedule的次數,每次呼叫schedule這個值會加1 10 schedtick uint32 // incremented on every scheduler call 11 // 系統呼叫的次數,每次進行系統呼叫加1 12 syscalltick uint32 // incremented on every system call 13 // 用於sysmon協程記錄被監控的p的系統呼叫時間和執行時間 14 sysmontick sysmontick // last tick observed by sysmon 15 // 指向繫結的m,p如果是idle狀態這個值為nil 16 m muintptr // back-link to associated m (nil if idle) 17 // 用於分配微小物件和小物件的一個塊的快取空間,裡面有各種不同等級的span 18 mcache *mcache 19 // 一個chunk大小(512kb)的記憶體空間,用來對堆上記憶體分配的快取優化達到無鎖存取的目的 20 pcache pageCache 21 raceprocctx uintptr 22 23 deferpool [5][]*_defer // pool of available defer structs of different sizes (see panic.go) 24 deferpoolbuf [5][32]*_defer 25 26 // Cache of goroutine ids, amortizes accesses to runtime·sched.goidgen. 27 // 可以分配給g的id的快取,每次會一次性申請16個 28 goidcache uint64 29 goidcacheend uint64 30 31 // Queue of runnable goroutines. Accessed without lock. 32 // 本地可執行的G佇列的頭部和尾部,達到無鎖存取 33 runqhead uint32 34 runqtail uint32 35 // 本地可執行的g佇列,是一個使用陣列實現的迴圈佇列 36 runq [256]guintptr 37 // 下一個待執行的g,這個g的優先順序最高 38 // 如果當前g執行完後還有剩餘可用時間,那麼就應該執行這個runnext的g 39 runnext guintptr 40 41 // Available G's (status == Gdead) 42 // p上的空閒佇列列表 43 gFree struct { 44 gList 45 n int32 46 } 47 48 ............ 49 // 用於記憶體對齊 50 _ uint32 // Alignment for atomic fields below 51 ....................... 52 // 是否被搶佔 53 preempt bool 54 55 // Padding is no longer needed. False sharing is now not a worry because p is large enough 56 // that its size class is an integer multiple of the cache line size (for any of our architectures). 57 }
通過這裡的結構可以看出,雖然P叫做邏輯處理器Processor,實際上它更多是資源的管理者,其中包含了可執行的g佇列資源、記憶體分配的資源、以及對排程迴圈、系統呼叫、sysmon協程的相關記錄。通過P的資源管理來儘量實現無鎖存取,提升應用效能。
3.2.2 P的狀態
當程式剛開始執行進行初始化時,所有的P都處於_Pgcstop狀態,隨著的P的初始化(runtime.procresize),會被設定為_Pidle狀態。
當M需要執行時會呼叫runtime.acquirep來使P變為_Prunning狀態,並通過runtime.releasep來釋放,重新變為_Pidele。
當G執行時需要進入系統呼叫,P會被設定為_Psyscall,如果這個時候被系統監控搶奪(runtime.retake),則P會被重新修改為_Pidle。
如果在程式中發生GC,則P會被設定為_Pgcstop,並在runtime.startTheWorld時重新調整為_Prunning。
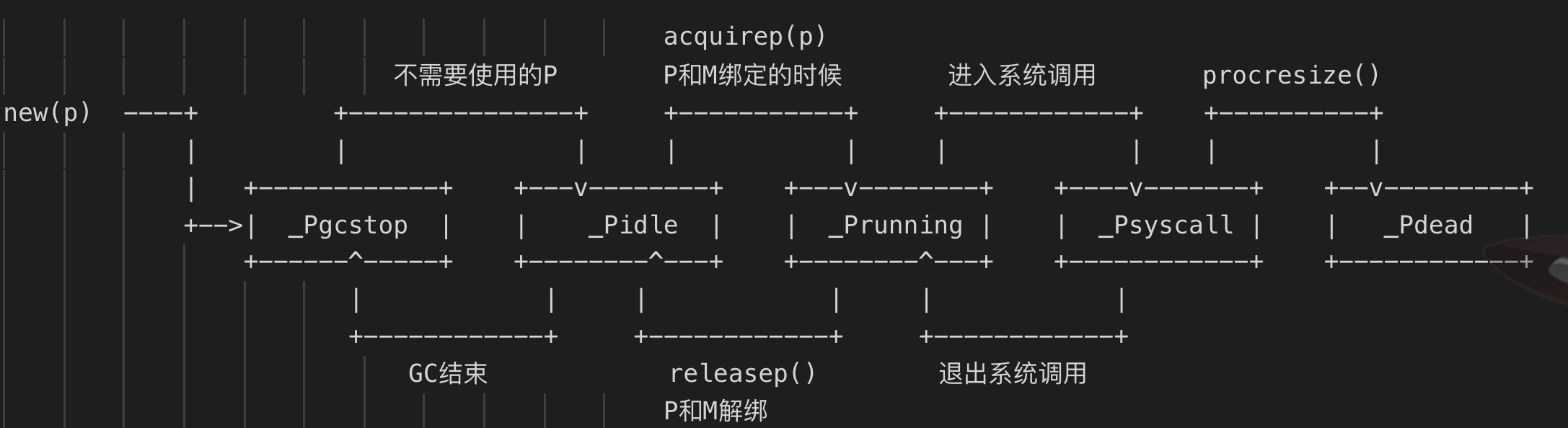
(這部分文字來自《Go程式設計師面試寶典》,圖片來自這裡)
3.2.3 P的建立
P的初始化是在schedinit函數中呼叫的,schedinit函數是在runtime的組合啟動程式碼裡呼叫的。
1 ........................... 2 CALL runtime·args(SB) 3 CALL runtime·osinit(SB) 4 CALL runtime·schedinit(SB) 5 ...........................
shcedinit中通過呼叫procresize進行P的分配。P的個數預設等於CPU核數,如果設定了GOMAXPROCS環境變數,則會採用設定的值來確定P的個數。所以runtime.GOMAXPROCS是限制的並行執行緒數量,而不是系統執行緒即M的總數,M是按需建立。
1 func schedinit() { 2 ................. 3 lock(&sched.lock) 4 sched.lastpoll = uint64(nanotime()) 5 procs := ncpu 6 if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 { 7 procs = n 8 } 9 if procresize(procs) != nil { 10 throw("unknown runnable goroutine during bootstrap") 11 } 12 unlock(&sched.lock) 13 14 // World is effectively started now, as P's can run. 15 worldStarted() 16 ..................... 17 }
上面獲取ncpu的個數,然後傳遞給procresize函數。
無論是初始化時的分配,還是後期調整,都是通過procresize來建立p以及初始化
1 func procresize(nprocs int32) *p { 2 ............................. 3 old := gomaxprocs 4 ...................... 5 if nprocs > int32(len(allp)) { 6 // Synchronize with retake, which could be running 7 // concurrently since it doesn't run on a P. 8 lock(&allpLock) 9 if nprocs <= int32(cap(allp)) { 10 // 如果需要的p小於allp這個全域性變數(切片)的cap能力,取其中的一部分 11 allp = allp[:nprocs] 12 } else { 13 // 否則建立nprocs數量的p,並把allp的中複製給nallp 14 nallp := make([]*p, nprocs) 15 // Copy everything up to allp's cap so we 16 // never lose old allocated Ps. 17 copy(nallp, allp[:cap(allp)]) 18 allp = nallp 19 } 20 .................................... 21 unlock(&allpLock) 22 } 23 24 // 進行p的初始化 25 for i := old; i < nprocs; i++ { 26 pp := allp[i] 27 if pp == nil { 28 pp = new(p) 29 } 30 pp.init(i) 31 atomicstorep(unsafe.Pointer(&allp[i]), unsafe.Pointer(pp)) 32 } 33 ............................... 34 return runnablePs 35 }
在啟動時候會根據CPU核數和runtime.GOMAXPROCS來設定p的個數,並由一個叫做allp的切片來為主,後期可以通過設定GOMAXPROCS來調整P的個數,但是效能消耗很大,會進行STW;
3.3 M原始碼部分
3.3.1 M的結構
M即Machine,代表一個程序中的工作執行緒,結構體m儲存了M自身使用的棧資訊、當前正在M上執行的G,以及繫結M的P資訊等。
我們來看下m的結構體:
1 type m struct { 2 // 每個m都有一個對應的g0執行緒,用來執行排程程式碼, 3 // 當需要執行使用者程式碼的時候,g0會與使用者goroutine發生協程棧切換 4 g0 *g // goroutine with scheduling stack 5 morebuf gobuf // gobuf arg to morestack 6 ........................ 7 // tls作為執行緒的本地儲存 8 // 其中可以在任意時刻獲取繫結到當前執行緒上的協程g、結構體m、邏輯處理器p、特殊協程g0等資訊 9 tls [tlsSlots]uintptr // thread-local storage (for x86 extern register) 10 mstartfn func() 11 // 指向正在執行的goroutine物件 12 curg *g // current running goroutine 13 caughtsig guintptr // goroutine running during fatal signal 14 // 與當前工作執行緒繫結的p 15 p puintptr // attached p for executing go code (nil if not executing go code) 16 nextp puintptr 17 oldp puintptr // the p that was attached before executing a syscall 18 id int64 19 mallocing int32 20 throwing int32 21 // 與禁止搶佔相關的欄位,如果該欄位不等於空字串,要保持curg一直在這個m上執行 22 preemptoff string // if != "", keep curg running on this m 23 // locks也是判斷g能否被搶佔的一個標識 24 locks int32 25 dying int32 26 profilehz int32 27 // spining為true標識當前m正在處於自己找工作的自旋狀態, 28 // 首先檢查全域性佇列看是否有工作,然後檢查network poller,嘗試執行GC任務 29 //或者偷一部分工作,如果都沒有則會進入休眠狀態 30 spinning bool // m is out of work and is actively looking for work 31 // 表示m正阻塞在note上 32 blocked bool // m is blocked on a note 33 ......................... 34 doesPark bool // non-P running threads: sysmon and newmHandoff never use .park 35 // 沒有goroutine需要執行時,工作執行緒睡眠在這個park成員上 36 park note 37 // 記錄所有工作執行緒的一個連結串列 38 alllink *m // on allm 39 schedlink muintptr 40 lockedg guintptr 41 createstack [32]uintptr // stack that created this thread. 42 ............................. 43 }
3.3.2 M的狀態
M的狀態並沒有向P和G那樣有多個狀態常數,它只有自旋和非自旋兩種狀態
1 mstart 2 | 3 v 4 +------+ 找不到可執行任務 +-------+ 5 |unspin| ----------------------------> |spining| 6 | | <---------------------------- | | 7 +------+ 找到可執行任務 +-------+ 8 ^ | stopm 9 | wakep v 10 notewakeup <------------------------- notesleep
當M沒有工作時,它會自旋的來找工作,首先檢查全域性佇列看是否有工作,然後檢查network poller,嘗試執行GC任務,或者偷一部分工作,如果都沒有則會進入休眠狀態。當被其他工作執行緒喚醒,又會進入自旋狀態。
3.3.3 M的建立
runtime/proc.go中的newm函數用來新建m,而最終是根據不同的系統,通過系統呼叫來建立執行緒。
1 // newm建立一個新的m,將從fn或者排程程式開始執行 2 func newm(fn func(), _p_ *p, id int64) { 3 // 這裡實現m的建立 4 mp := allocm(_p_, fn, id) 5 mp.doesPark = (_p_ != nil) 6 mp.nextp.set(_p_) 7 mp.sigmask = initSigmask 8 if gp := getg(); gp != nil && gp.m != nil && (gp.m.lockedExt != 0 || gp.m.incgo) && GOOS != "plan9" { 9 // 我們處於鎖定的M或可能由C啟動的執行緒。此執行緒的核心狀態可能很奇怪(使用者可能已將其鎖定為此目的)。 10 // 我們不想將其克隆到另一個執行緒中。相反,請求一個已知良好的執行緒為我們建立執行緒。 11 lock(&newmHandoff.lock) 12 if newmHandoff.haveTemplateThread == 0 { 13 throw("on a locked thread with no template thread") 14 } 15 mp.schedlink = newmHandoff.newm 16 newmHandoff.newm.set(mp) 17 if newmHandoff.waiting { 18 newmHandoff.waiting = false 19 notewakeup(&newmHandoff.wake) 20 } 21 unlock(&newmHandoff.lock) 22 return 23 } 24 // 這裡分配真正的的作業系統執行緒 25 newm1(mp) 26 }
allocm函數中實現m的建立,以及對應的g0協程的設定
1 func allocm(_p_ *p, fn func(), id int64) *m { 2 // 獲取當前執行的g 3 _g_ := getg() 4 // 將_g_對應的m的locks加1,防止被搶佔 5 acquirem() // disable GC because it can be called from sysmon 6 if _g_.m.p == 0 { 7 acquirep(_p_) // temporarily borrow p for mallocs in this function 8 } 9 10 // 檢查是有有空閒的m可以釋放,主要目的是釋放m上的g0佔用的系統棧 11 if sched.freem != nil { 12 lock(&sched.lock) 13 var newList *m 14 for freem := sched.freem; freem != nil; { 15 if freem.freeWait != 0 { 16 next := freem.freelink 17 freem.freelink = newList 18 newList = freem 19 freem = next 20 continue 21 } 22 // stackfree must be on the system stack, but allocm is 23 // reachable off the system stack transitively from 24 // startm. 25 systemstack(func() { 26 stackfree(freem.g0.stack) 27 }) 28 freem = freem.freelink 29 } 30 sched.freem = newList 31 unlock(&sched.lock) 32 } 33 // 建立一個m結構體 34 mp := new(m) 35 mp.mstartfn = fn // 將fn設定為m啟動後執行的函數 36 mcommoninit(mp, id) 37 38 // In case of cgo or Solaris or illumos or Darwin, pthread_create will make us a stack. 39 // Windows and Plan 9 will layout sched stack on OS stack. 40 if iscgo || mStackIsSystemAllocated() { 41 mp.g0 = malg(-1) 42 } else { 43 // 設定m對應的g0,並設定對應大小的g0協程棧,g0是8kb 44 mp.g0 = malg(8192 * sys.StackGuardMultiplier) 45 } 46 // 設定g0對應的m 47 mp.g0.m = mp 48 49 if _p_ == _g_.m.p.ptr() { 50 releasep() 51 } 52 // 解除_g_的m的禁止搶佔狀態。 53 releasem(_g_.m) 54 55 return mp 56 }
為什麼m.locks加1可以禁止搶佔,防止GC;因為判斷是否可以搶佔,其中一個因素就是要m.locks=0
1 func canPreemptM(mp *m) bool { 2 return mp.locks == 0 && mp.mallocing == 0 && mp.preemptoff == "" && mp.p.ptr().status == _Prunning 3 }
allocm函數實現了m的建立,但是這只是runtime層面的一個資料結構,還並沒有在系統中有真正的執行緒。再來看newm1函數:
1 func newm1(mp *m) { 2 .............. 3 execLock.rlock() // Prevent process clone. 4 // 建立一個系統執行緒,並且傳入該 mp 繫結的 g0 的棧頂指標 5 // 讓系統執行緒執行 mstart 函數,後面的邏輯都在 mstart 函數中 6 newosproc(mp) 7 execLock.runlock() 8 }
實際是通過newostproc來建立系統執行緒;
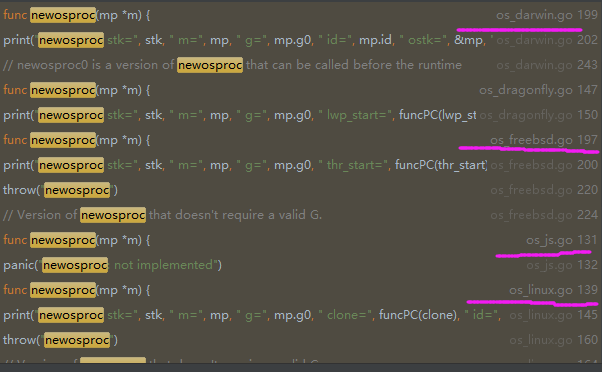
可以看到這個函數在不同的系統中有不同的實現,我們主要看linux系統,即os_linux.go檔案程式碼:
1 func newosproc(mp *m) { 2 stk := unsafe.Pointer(mp.g0.stack.hi) 3 ......................... 4 var oset sigset 5 sigprocmask(_SIG_SETMASK, &sigset_all, &oset) 6 ret := clone(cloneFlags, stk, unsafe.Pointer(mp), unsafe.Pointer(mp.g0), unsafe.Pointer(funcPC(mstart))) 7 sigprocmask(_SIG_SETMASK, &oset, nil) 8 ......................... 9 }
在linux平臺,是通過clone這個系統呼叫來建立的執行緒;值得注意的是,這個系統執行緒的棧是在堆上;因為其中的stk指向mp.go.stack.hi,所以g0的堆疊也就是這個系統執行緒的堆疊。
3.3.4 M的休眠
M的自旋指的是m.spining為true,這個時候它會在P的本地G佇列、全域性G佇列、nerpoller、偷其他P的G,一直迴圈找可執行的G的過程中。
自旋狀態用 m.spinning 和 sched.nmspinning 表示。其中 m.spinning 表示當前的M是否為自旋狀態,sched.nmspinning 表示runtime中一共有多少個M在自旋狀態。
當自旋了一段時間後,發現仍然找不到工作,就會進入stopm函數中,使M對應的執行緒進行休眠。
1 func stopm() { 2 _g_ := getg() 3 ..................... 4 lock(&sched.lock) 5 // 首先將m放到全域性空閒連結串列中,這裡要加鎖存取全域性連結串列 6 mput(_g_.m) 7 unlock(&sched.lock) 8 // 進入睡眠狀態 9 mPark() 10 // 將m與p解綁 11 acquirep(_g_.m.nextp.ptr()) 12 _g_.m.nextp = 0 13 } 14 15 func mPark() { 16 g := getg() 17 for { 18 // 使工作執行緒休眠在park欄位上 19 notesleep(&g.m.park) 20 noteclear(&g.m.park) 21 if !mDoFixup() { 22 return 23 } 24 } 25 }
實際將執行緒進行休眠的程式碼,是通過組合語言進行Futex系統呼叫來事項的。Futex機制是Linux提供的一種使用者態和核心態混合的同步機制。Linux底層也是使用futex機制實現的鎖。
1 //uaddr指向一個地址,val代表這個地址期待的值,當*uaddr==val時,才會進行wait 2 int futex_wait(int *uaddr, int val); 3 //喚醒n個在uaddr指向的鎖變數上掛起等待的程序 4 int futex_wake(int *uaddr, int n);
可以看到在futex_wait中當一個地址等於某個期待值時,就會進行wait;所以當m中的park的key等於某個值時則進入休眠狀態。
3.3.5 M的喚醒
M的喚醒是在wakep函數中處理的。當一個新的goroutine建立或者有多個goroutine進入_Grunnable狀態時,會先判斷是否有自旋的M,如果有則不會喚醒其他的M而使用自旋的M,當沒有自旋的M,但m空閒佇列中有空閒的M則會喚醒M,否則會建立一個新的M
1 // Tries to add one more P to execute G's. 2 // Called when a G is made runnable (newproc, ready). 3 func wakep() { 4 if atomic.Load(&sched.npidle) == 0 { 5 return 6 } 7 // be conservative about spinning threads 8 // 如果有其他的M處於自旋狀態,那麼就不管了,直接返回,因為自旋的M會拼命找G來執行的 9 if atomic.Load(&sched.nmspinning) != 0 || !atomic.Cas(&sched.nmspinning, 0, 1) { 10 return 11 } 12 startm(nil, true) 13 }
startm先判斷是否有空閒的P,如果沒有則返回,如果有空閒的P,在嘗試看看有沒有空閒的M,有則喚醒該M來工作。如果沒有空閒M,則新建一個M,然後也進入喚醒操作。
1 func startm(_p_ *p, spinning bool) { 2 // 禁止搶佔,防止GC垃圾回收 3 mp := acquirem() 4 lock(&sched.lock) 5 // 如果P為nil,則嘗試獲取一個空閒P 6 if _p_ == nil { 7 _p_ = pidleget() 8 if _p_ == nil { // 沒有空閒的P,則解除禁止搶佔,直接返回 9 unlock(&sched.lock) 10 if spinning { 11 if int32(atomic.Xadd(&sched.nmspinning, -1)) < 0 { 12 throw("startm: negative nmspinning") 13 } 14 } 15 releasem(mp) 16 return 17 } 18 } 19 // 獲取一個空閒的M 20 nmp := mget() 21 if nmp == nil { 22 // 如果沒有空閒的m則新建一個 23 id := mReserveID() 24 unlock(&sched.lock) 25 26 var fn func() 27 if spinning { 28 // The caller incremented nmspinning, so set m.spinning in the new M. 29 fn = mspinning 30 } 31 newm(fn, _p_, id) 32 // Ownership transfer of _p_ committed by start in newm. 33 // Preemption is now safe. 34 releasem(mp) 35 return 36 } 37 unlock(&sched.lock) 38 ...................... 39 //標記該M是否在自旋 40 nmp.spinning = spinning 41 // 暫存P 42 nmp.nextp.set(_p_) 43 // 喚醒M 44 notewakeup(&nmp.park) 45 // Ownership transfer of _p_ committed by wakeup. Preemption is now 46 // safe. 47 releasem(mp) 48 }
喚醒執行緒的底層操作同樣是依賴futex機制
1 //喚醒n個在uaddr指向的鎖變數上掛起等待的程序 2 int futex_wake(int *uaddr, int n);
4 啟動過程
4.1 Go scheduler結構
在runtime中全域性變數sched代表全域性排程器,資料結構為schedt結構體,儲存了排程器的狀態資訊、全域性可執行G佇列
1 type schedt struct { 2 // 用來為goroutine生成唯一id,需要以原子存取形式進行存取 3 // 放在struct頂部,以便在32位元系統上可以進行對齊 4 goidgen uint64 5 ................... 6 lock mutex 7 // 空閒的m組成的連結串列 8 midle muintptr // idle m's waiting for work 9 // 空閒的工作執行緒數量 10 nmidle int32 // number of idle m's waiting for work 11 // 空閒的且被lock的m的數量 12 nmidlelocked int32 // number of locked m's waiting for work 13 mnext int64 // number of m's that have been created and next M ID 14 // 表示最多能夠建立的工作執行緒數量 15 maxmcount int32 // maximum number of m's allowed (or die) 16 nmsys int32 // number of system m's not counted for deadlock 17 nmfreed int64 // cumulative number of freed m's 18 // 整個goroutine的數量,能夠自動保持更新 19 ngsys uint32 // number of system goroutines; updated atomically 20 // 由空閒的p結構體物件組成的連結串列 21 pidle puintptr // idle p's 22 // 空閒的p結構體物件的數量 23 npidle uint32 24 // 自旋的m的數量 25 nmspinning uint32 // See "Worker thread parking/unparking" comment in proc.go. 26 27 // Global runnable queue. 28 // 全域性的的g的佇列 29 runq gQueue 30 runqsize int32 31 32 disable struct { 33 // user disables scheduling of user goroutines. 34 user bool 35 runnable gQueue // pending runnable Gs 36 n int32 // length of runnable 37 } 38 39 // Global cache of dead G's. 40 // 空閒的g佇列,這裡面g的狀態為_Gdead 41 gFree struct { 42 lock mutex 43 stack gList // Gs with stacks 44 noStack gList // Gs without stacks 45 n int32 46 } 47 ................. 48 // 空閒的m佇列 49 freem *m 50 ..................... 51 // 上次修改gomaxprocs的時間 52 procresizetime int64 // nanotime() of last change to gomaxprocs 53 ...................... 54 }
這裡面大部分是記錄一些空閒的g、m、p等,在runtime2.go中還有很多相關的全域性變數:
1 // runtime/runtime2.go 2 var ( 3 // 儲存所有的m 4 allm *m 5 // p的最大個數,預設等於cpu核數 6 gomaxprocs int32 7 // cpu的核數,程式啟動時會呼叫osinit獲取ncpu值 8 ncpu int32 9 // 排程器結構體物件,記錄了排程器的工作狀態 10 sched schedt 11 newprocs int32 12 13 allpLock mutex 14 // 全域性的p佇列 15 allp []*p 16 ) 17 18 // runtime/proc.go 19 var ( 20 // 代表程序主執行緒的m0物件 21 m0 m 22 // m0的g0 23 g0 g 24 // 全域性的mcache物件,管理各種型別的span佇列 25 mcache0 *mcache 26 raceprocctx0 uintptr 27 )
4.2 啟動流程
排程器的初始化和啟動排程迴圈是在程序初始化是處理的,整個程序初始化流程如下:
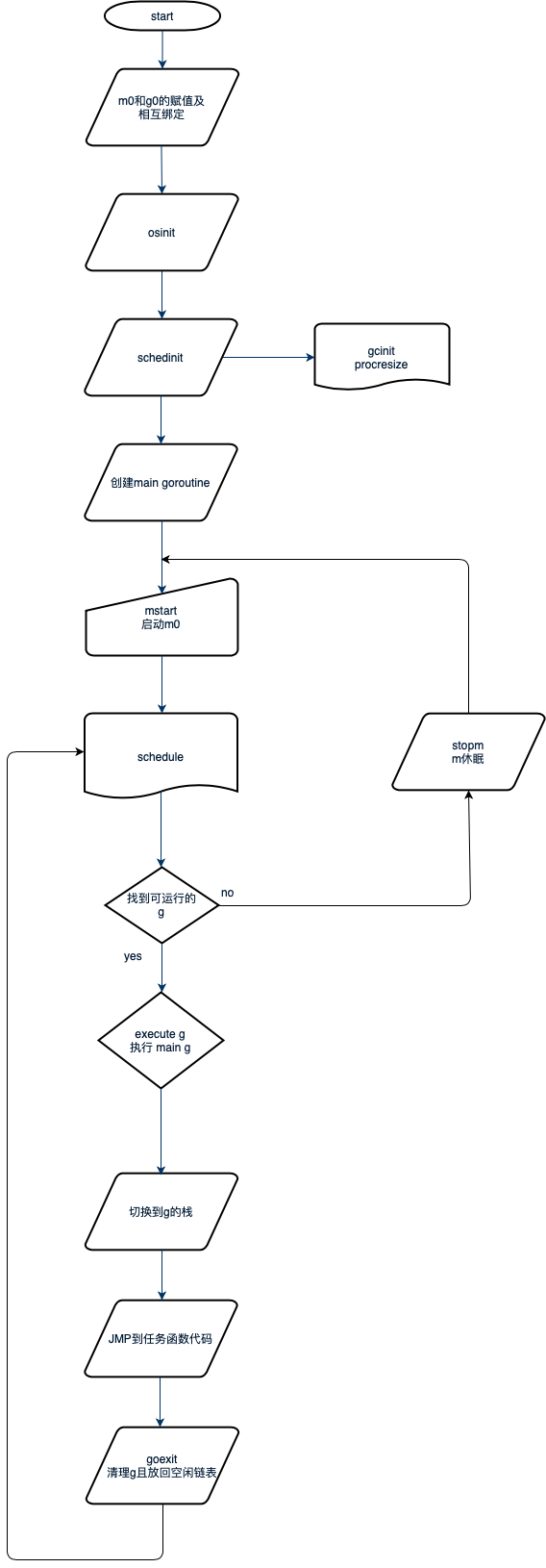
Go 程序的啟動是通過組合程式碼進行的,入口函數在asm_amd64.s這個檔案中的runtime.rt0_go部分程式碼;
1 // runtime·rt0_go 2 3 // 程式剛啟動的時候必定有一個執行緒啟動(主執行緒) 4 // 將當前的棧和資源儲存在g0 5 // 將該執行緒儲存在m0 6 // tls: Thread Local Storage 7 // set the per-goroutine and per-mach "registers" 8 get_tls(BX) 9 LEAQ runtime·g0(SB), CX 10 MOVQ CX, g(BX) 11 LEAQ runtime·m0(SB), AX 12 13 // m0和g0互相繫結 14 // save m->g0 = g0 15 MOVQ CX, m_g0(AX) 16 // save m0 to g0->m 17 MOVQ AX, g_m(CX) 18 // 處理args 19 CALL runtime·args(SB) 20 // os初始化, os_linux.go 21 CALL runtime·osinit(SB) 22 // 排程系統初始化, proc.go 23 CALL runtime·schedinit(SB) 24 25 // 建立一個goroutine,然後開啟執行程式 26 // create a new goroutine to start program 27 MOVQ $runtime·mainPC(SB), AX // entry 28 PUSHQ AX 29 PUSHQ $0 // arg size 30 CALL runtime·newproc(SB) 31 POPQ AX 32 POPQ AX 33 34 // start this M 35 // 啟動執行緒,並且啟動排程系統 36 CALL runtime·mstart(SB)
可以看到通過組合程式碼:
1、將m0與g0互相繫結,然後呼叫runtime.osinit函數,這個函數不同的作業系統有不同的實現;
2、然後呼叫runtime.schedinit進行排程系統的初始化;
3、然後建立主協程;主goroutine建立完成後被加入到p的執行佇列中,等待排程;
4、在g0上啟動呼叫runtime.mstart啟動排程迴圈,首先可以被排程執行的就是主goroutine,然後主協程獲得執行的cpu則執行runtime.main進而執行到使用者程式碼的main函數。
初始化過程和堆疊圖可以參考下圖:
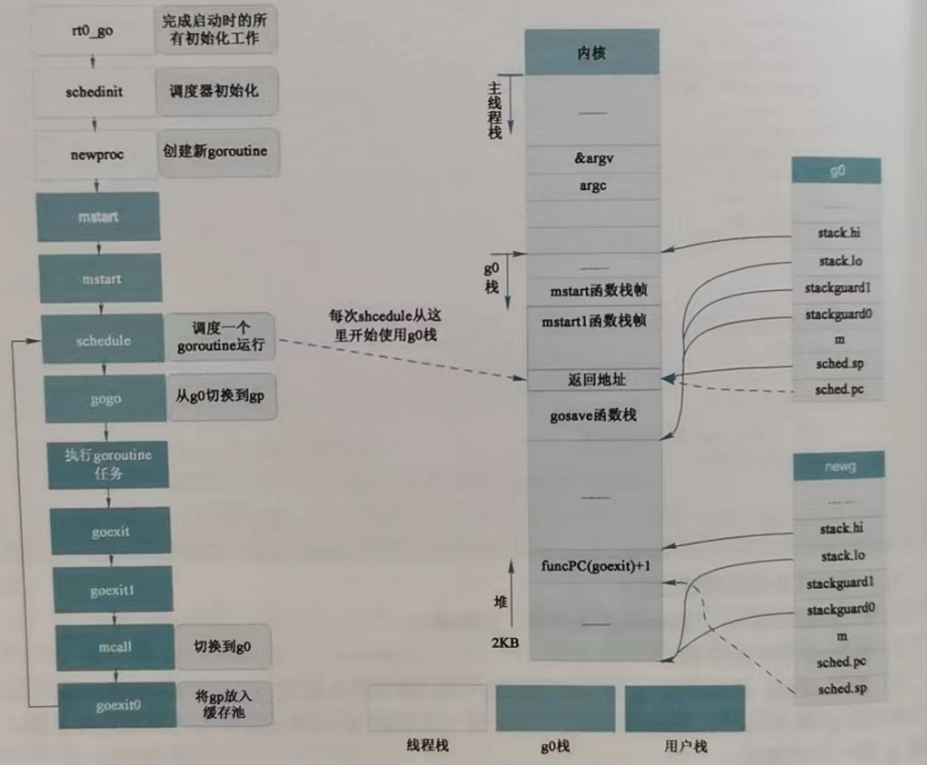
堆疊上,g0、m0、p0與主協程關係如圖所示:
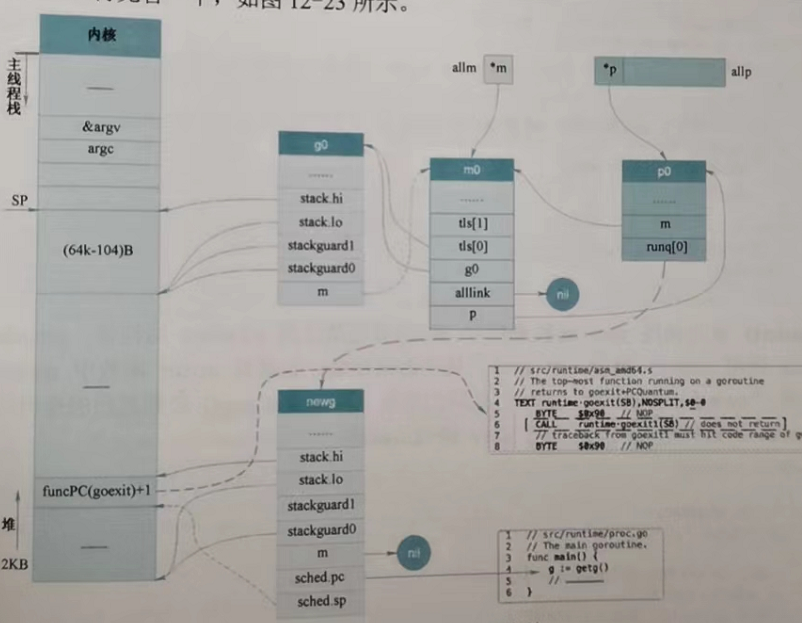
4.3 排程器初始化
排程器初始化
1 func schedinit() { 2 ................ 3 // g0 4 _g_ := getg() 5 if raceenabled { 6 _g_.racectx, raceprocctx0 = raceinit() 7 } 8 // 最多啟動10000個工作執行緒 9 sched.maxmcount = 10000 10 11 // The world starts stopped. 12 worldStopped() 13 14 moduledataverify() 15 // 初始化協程堆疊,包括專門分配小棧的stackpool和分配大棧的stackLarge 16 stackinit() 17 // 整個堆記憶體的初始化分配 18 mallocinit() 19 fastrandinit() // must run before mcommoninit 20 // 初始化m0 21 mcommoninit(_g_.m, -1) 22 cpuinit() // must run before alginit 23 alginit() // maps must not be used before this call 24 modulesinit() // provides activeModules 25 typelinksinit() // uses maps, activeModules 26 itabsinit() // uses activeModules 27 28 sigsave(&_g_.m.sigmask) 29 initSigmask = _g_.m.sigmask 30 31 if offset := unsafe.Offsetof(sched.timeToRun); offset%8 != 0 { 32 println(offset) 33 throw("sched.timeToRun not aligned to 8 bytes") 34 } 35 36 goargs() 37 goenvs() 38 parsedebugvars() 39 gcinit() 40 // 這部分是初始化p, 41 // cpu有多少個核數就初始化多少個p 42 lock(&sched.lock) 43 sched.lastpoll = uint64(nanotime()) 44 procs := ncpu 45 if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 { 46 procs = n 47 } 48 if procresize(procs) != nil { 49 throw("unknown runnable goroutine during bootstrap") 50 } 51 unlock(&sched.lock) 52 53 // World is effectively started now, as P's can run. 54 worldStarted() 55 }
4.4 啟動排程系統
排程系統時在runtime.mstart0函數中啟動的。這個函數是在m0的g0上執行的。
1 func mstart0() { 2 // 這裡獲取的是g0在系統棧上執行 3 _g_ := getg() 4 ............. 5 mstart1() 6 ............. 7 } 8 9 func mstart1(dummy int32) { 10 _g_ := getg() 11 // 確保g是系統棧上的g0 12 // 排程器只在g0上執行 13 if _g_ != _g_.m.g0 { 14 throw("bad runtime·mstart") 15 } 16 ... 17 // 初始化m,主要是設定執行緒的備用訊號堆疊和訊號掩碼 18 minit() 19 // 如果當前g的m是初始m0,執行mstartm0() 20 if _g_.m == &m0 { 21 // 對於初始m,需要一些特殊處理,主要是設定系統號誌的處理常式 22 mstartm0() 23 } 24 // 如果有m的起始任務函數,則執行,比如 sysmon 函數 25 // 對於m0來說,是沒有 mstartfn 的 26 if fn := _g_.m.mstartfn; fn != nil { 27 fn() 28 } 29 if _g_.m.helpgc != 0 { 30 _g_.m.helpgc = 0 31 stopm() 32 } else if _g_.m != &m0 { // 如果不是m0,需要繫結p 33 // 繫結p 34 acquirep(_g_.m.nextp.ptr()) 35 _g_.m.nextp = 0 36 } 37 // 進入排程迴圈,永不返回 38 schedule() 39 }
4.5 runtime.main函數
當經過初始的排程,主協程獲取執行權後,首先進入的就是runtime.main函數:
1 // The main goroutine. 2 func main() { 3 // 獲取 main goroutine 4 g := getg() 5 ... 6 // 在系統棧上執行 sysmon 7 systemstack(func() { 8 // 分配一個新的m,執行sysmon系統後臺監控 9 // (定期垃圾回收和排程搶佔) 10 newm(sysmon, nil) 11 }) 12 ... 13 // 確保是主執行緒 14 if g.m != &m0 { 15 throw("runtime.main not on m0") 16 } 17 // runtime 內部 init 函數的執行,編譯器動態生成的。 18 runtime_init() // must be before defer 19 ... 20 // gc 啟動一個goroutine進行gc清掃 21 gcenable() 22 ... 23 // 執行init函數,編譯器動態生成的, 24 // 包括使用者定義的所有的init函數。 25 // make an indirect call, 26 // as the linker doesn't know the address of 27 // the main package when laying down the runtime 28 fn := main_init 29 fn() 30 ... 31 // 真正的執行main func in package main 32 // make an indirect call, 33 // as the linker doesn't know the address of 34 // the main package when laying down the runtime 35 fn = main_main 36 fn() 37 ... 38 // 退出程式 39 exit(0) 40 // 為何這裡還需要for迴圈? 41 // 下面的for迴圈一定會導致程式崩掉,這樣就確保了程式一定會退出 42 for { 43 var x *int32 44 *x = 0 45 } 46 }
runtime.main函數中需要注意的是在系統棧上建立了一個新的m,來執行sysmon協程,這個協程是用來定期執行垃圾回收和排程搶佔。
其中可以看到首先獲取了main_init函數,來執行runtime包中的init函數,然後是獲取main_main來執行使用者的main函數。
接著main函數執行完成後,呼叫exit讓主程序退出,如果程序沒有退出,就讓for迴圈一直存取非法地址,讓作業系統把程序殺死,這樣來確保程序一定會退出。
5 協程的排程策略
排程迴圈啟動之後,便會進入一個無限迴圈中,不斷的執行schedule->execute->gogo->goroutine任務->goexit->goexit1->mcall->goexit0->schedule;
其中排程的過程是在m的g0上執行的,而goroutine任務->goexit->goexit1->mcall則是在goroutine的堆疊空間上執行的。
5.1 排程策略
其中schedule函數處理具體的排程策略;execute函數執行一些具體的狀態轉移、協程g與結構體m之間的繫結;gogo函數是與作業系統相關的函數,執行組合程式碼完成棧的切換以及CPU暫存器的恢復。
先來看下schedule的程式碼:
1 func schedule() { 2 _g_ := getg() 3 ... 4 top: 5 // 如果當前GC需要停止整個世界(STW), 則呼叫gcstopm休眠當前的M 6 if sched.gcwaiting != 0 { 7 // 為了STW,停止當前的M 8 gcstopm() 9 // STW結束後回到 top 10 goto top 11 } 12 ... 13 var gp *g 14 var inheritTime bool 15 ... 16 if gp == nil { 17 // 為了防止全域性佇列中的g永遠得不到執行,所以go語言讓p每執行61排程, 18 // 就需要優先從全域性佇列中獲取一個G到當前P中,並執行下一個要執行的G 19 if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 { 20 lock(&sched.lock) 21 gp = globrunqget(_g_.m.p.ptr(), 1) 22 unlock(&sched.lock) 23 } 24 } 25 if gp == nil { 26 // 從p的本地佇列中獲取 27 gp, inheritTime = runqget(_g_.m.p.ptr()) 28 if gp != nil && _g_.m.spinning { 29 throw("schedule: spinning with local work") 30 } 31 } 32 if gp == nil { 33 // 想盡辦法找到可執行的G,找不到就不用返回了 34 gp, inheritTime = findrunnable() // blocks until work is available 35 } 36 ... 37 // println("execute goroutine", gp.goid) 38 // 找到了g,那就執行g上的任務函數 39 execute(gp, inheritTime) 40 }
findrunnalbe中首先還是從本地佇列中檢查,然後從全域性佇列中尋找,再從就緒的網路協程,如果這幾個沒有就去其他p的本地佇列偷一些任務。
1 func findrunnable() (gp *g, inheritTime bool) { 2 _g_ := getg() 3 4 top: 5 ............................ 6 // 本地佇列中檢查 7 if gp, inheritTime := runqget(_p_); gp != nil { 8 return gp, inheritTime 9 } 10 // 從全域性佇列中尋找 11 if sched.runqsize != 0 { 12 lock(&sched.lock) 13 gp := globrunqget(_p_, 0) 14 unlock(&sched.lock) 15 if gp != nil { 16 return gp, false 17 } 18 } 19 // 從就緒的網路協程中查詢 20 if netpollinited() && atomic.Load(&netpollWaiters) > 0 && atomic.Load64(&sched.lastpoll) != 0 { 21 if list := netpoll(0); !list.empty() { // non-blocking 22 gp := list.pop() 23 injectglist(&list) 24 casgstatus(gp, _Gwaiting, _Grunnable) 25 if trace.enabled { 26 traceGoUnpark(gp, 0) 27 } 28 return gp, false 29 } 30 } 31 32 // 進入自旋狀態 33 procs := uint32(gomaxprocs) 34 if _g_.m.spinning || 2*atomic.Load(&sched.nmspinning) < procs-atomic.Load(&sched.npidle) { 35 if !_g_.m.spinning { 36 _g_.m.spinning = true 37 atomic.Xadd(&sched.nmspinning, 1) 38 } 39 // 從其他p的本地佇列中偷工作 40 gp, inheritTime, tnow, w, newWork := stealWork(now) 41 .............................. 42 } 43 }
整個排程的優先順序如下:
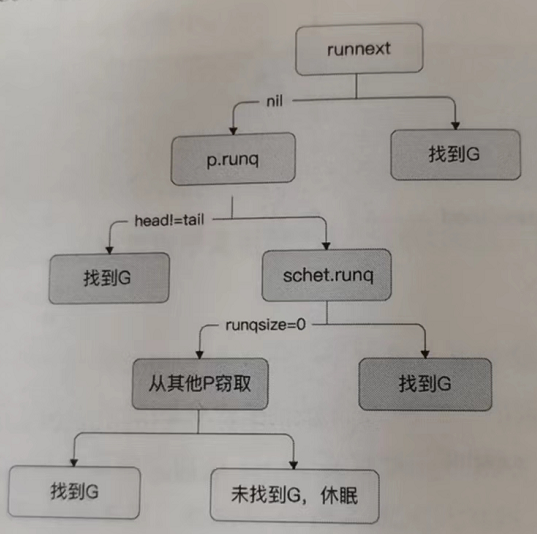
5.2 排程時機
5.1講了排程的策略,什麼時機發生排程呢,主要有三種方式,主動排程、被動排程、搶佔式排程。
5.2.1 主動排程
協程可以選擇主動讓渡自己的執行權利,大多數情況下不需要這麼做,但通過runtime.Goched可以做到主動讓渡。
1 func Gosched() { 2 checkTimeouts() 3 mcall(gosched_m) 4 } 5 6 // Gosched continuation on g0. 7 func gosched_m(gp *g) { 8 if trace.enabled { 9 traceGoSched() 10 } 11 goschedImpl(gp) 12 } 13 14 func goschedImpl(gp *g) { 15 status := readgstatus(gp) 16 if status&^_Gscan != _Grunning { 17 dumpgstatus(gp) 18 throw("bad g status") 19 } 20 // 更改g的執行狀態 21 casgstatus(gp, _Grunning, _Grunnable) 22 // 接觸g和m的繫結關係 23 dropg() 24 // 將g放入全域性佇列中 25 lock(&sched.lock) 26 globrunqput(gp) 27 unlock(&sched.lock) 28 29 schedule() 30 }
5.2.2 被動排程
大部分情況下的排程都是被動排程,當協程在休眠、channel通道阻塞、網路IO阻塞、執行垃圾回收時會暫停,被動排程可以保證最大化利用CPU資源。被動排程是協程發起的操作,所以排程時機相對明確。
首先從當前棧切換到g0協程,被動排程不會將G放入全域性執行佇列,所以被動排程需要一個額外的喚醒機制。
這裡面涉及的函數主要是gopark和ready函數。
gopark函數用來完成被動排程,有_Grunning變為_Gwaiting狀態;
1 func gopark(unlockf func(*g, unsafe.Pointer) bool, lock unsafe.Pointer, reason waitReason, traceEv byte, traceskip int) { 2 if reason != waitReasonSleep { 3 checkTimeouts() // timeouts may expire while two goroutines keep the scheduler busy 4 } 5 // 禁止搶佔和GC 6 mp := acquirem() 7 gp := mp.curg // 過去當前m上執行的g 8 status := readgstatus(gp) 9 if status != _Grunning && status != _Gscanrunning { 10 throw("gopark: bad g status") 11 } 12 // 設定相關的wait欄位 13 mp.waitlock = lock 14 mp.waitunlockf = unlockf 15 gp.waitreason = reason 16 mp.waittraceev = traceEv 17 mp.waittraceskip = traceskip 18 releasem(mp) 19 // can't do anything that might move the G between Ms here. 20 mcall(park_m) 21 } 22 23 // park continuation on g0. 24 func park_m(gp *g) { 25 _g_ := getg() 26 // 變更g的狀態 27 casgstatus(gp, _Grunning, _Gwaiting) 28 // 接觸g與m的繫結關係 29 dropg() 30 // 根據被動排程不同原因,執行不同的waitunlockf函數 31 if fn := _g_.m.waitunlockf; fn != nil { 32 ok := fn(gp, _g_.m.waitlock) 33 _g_.m.waitunlockf = nil 34 _g_.m.waitlock = nil 35 if !ok { 36 if trace.enabled { 37 traceGoUnpark(gp, 2) 38 } 39 casgstatus(gp, _Gwaiting, _Grunnable) 40 execute(gp, true) // Schedule it back, never returns. 41 } 42 } 43 // 進入下一輪排程 44 schedule() 45 }
當協程要被喚醒時,會進入ready函數中,更改協程狀態由_Gwaiting變更為_Grunnable,放入本地執行佇列等待被排程。
1 func ready(gp *g, traceskip int, next bool) { 2 .............. 3 status := readgstatus(gp) 4 5 // Mark runnable. 6 _g_ := getg() 7 mp := acquirem() // disable preemption because it can be holding p in a local var 8 ............... 9 // 變更狀態之後,放入p的區域性執行佇列中 10 casgstatus(gp, _Gwaiting, _Grunnable) 11 runqput(_g_.m.p.ptr(), gp, next) 12 wakep() 13 releasem(mp) 14 }
5.2.3 搶佔式排程
如果一個g執行時間過長就會導致其他g難以獲取執行機會,當進行系統呼叫時也存在會導致其他g無法執行情況;當出現這兩種情況時,為了讓其他g有執行機會,則會進行搶佔式排程。
是否進行搶佔式排程主要是在sysmon協程上判斷的。sysmon協程是一個不需要p的協程,它作用主要是執行後臺監控,進行netpool(獲取fd事件)、retake(搶佔式排程)、forcegc(按時間強制執行GC)、scavenge heap(強制釋放閒置堆記憶體,減少記憶體佔用)
其中與搶佔式排程相關的就是retake函數,
這裡我們需要知道的是連續執行10ms則認為時間過長,進行搶佔
發生系統呼叫時,當前正在工作的執行緒會陷入等待狀態,等待內部完成系統呼叫並返回,所以也需要讓渡執行權給其他g,但這裡當只有滿足幾種情況才會進行排程:
1、如果p的執行佇列中有等待執行的g則搶佔
2、如果沒有空閒的p則進行搶佔
3、系統呼叫時間超過10ms則進行搶佔
1 func retake(now int64) uint32 { 2 n := 0 3 lock(&allpLock) 4 // 遍歷所有的P 5 for i := 0; i < len(allp); i++ { 6 _p_ := allp[i] 7 if _p_ == nil { 8 // This can happen if procresize has grown 9 // allp but not yet created new Ps. 10 continue 11 } 12 pd := &_p_.sysmontick 13 s := _p_.status 14 sysretake := false 15 16 if s == _Prunning || s == _Psyscall { 17 // 判斷如果g的執行時間過長則搶佔 18 t := int64(_p_.schedtick) 19 if int64(pd.schedtick) != t { 20 pd.schedtick = uint32(t) 21 pd.schedwhen = now 22 } else if pd.schedwhen+forcePreemptNS <= now { 23 // 如果連續執行10ms則進行搶佔 24 preemptone(_p_) 25 sysretake = true 26 } 27 } 28 // 針對系統呼叫情況進行搶佔 29 // 如果p的執行佇列中有等待執行的g則搶佔 30 // 如果沒有空閒的p則進行搶佔 31 // 系統呼叫時間超過10ms則進行搶佔 32 if s == _Psyscall { 33 // Retake P from syscall if it's there for more than 1 sysmon tick (at least 20us). 34 t := int64(_p_.syscalltick) 35 if !sysretake && int64(pd.syscalltick) != t { 36 pd.syscalltick = uint32(t) 37 pd.syscallwhen = now 38 continue 39 } 40 // On the one hand we don't want to retake Ps if there is no other work to do, 41 // but on the other hand we want to retake them eventually 42 // because they can prevent the sysmon thread from deep sleep. 43 if runqempty(_p_) && atomic.Load(&sched.nmspinning)+atomic.Load(&sched.npidle) > 0 && pd.syscallwhen+10*1000*1000 > now { 44 continue 45 } 46 // Drop allpLock so we can take sched.lock. 47 unlock(&allpLock) 48 // Need to decrement number of idle locked M's 49 // (pretending that one more is running) before the CAS. 50 // Otherwise the M from which we retake can exit the syscall, 51 // increment nmidle and report deadlock. 52 incidlelocked(-1) 53 if atomic.Cas(&_p_.status, s, _Pidle) { 54 if trace.enabled { 55 traceGoSysBlock(_p_) 56 traceProcStop(_p_) 57 } 58 n++ 59 _p_.syscalltick++ 60 handoffp(_p_) 61 } 62 incidlelocked(1) 63 lock(&allpLock) 64 } 65 } 66 unlock(&allpLock) 67 return uint32(n) 68 }
在進行搶佔式排程,Go還涉及到利用作業系統訊號方式來進行搶佔,這裡就不在介紹,感興趣可以自己去研究。
另外,本文圖片沒有一張原創,畫圖非常耗費時間,我沒有那麼多時間,所以只能到處借用大家的圖片,侵權請聯絡。
6 參考資料
- Go語言的排程模型:https://www.cnblogs.com/lvpengbo/p/13973906.html
- 深度揭祕Go語言 sync.Pool:https://www.cnblogs.com/qcrao-2018/p/12736031.html
- https://toutiao.io/posts/2gic8x/preview
- 萬字長文深入淺出go runtime:https://zhuanlan.zhihu.com/p/95056679
- 深入go runtime的排程:https://zboya.github.io/post/go_scheduler/
- 位元組Go面試:https://leetcode-cn.com/circle/discuss/A0YstA/
- golang排程學習-排程過程:https://blog.csdn.net/diaosssss/article/details/93066804
- Go排程器中的三種結構:G、P、M:https://blog.csdn.net/chenxun_2010/article/details/103696394
- Go語言的排程模型:https://www.cnblogs.com/lvpengbo/p/13973906.html
- Go GMP的排程模型:https://zhuanlan.zhihu.com/p/413970952
- 詳細剖析Go語言排程模型的設計:https://www.elecfans.com/d/1670400.html
- Go的核心goroutine sysmon:https://blog.csdn.net/RA681t58CJxsgCkJ31/article/details/108633220
- 一文教你搞懂Go中棧操作:https://zhuanlan.zhihu.com/p/364813527
- 詳解Go語言排程迴圈程式碼實現:https://www.luozhiyun.com/archives/448
- goroutine的建立、休眠與恢復:https://zhuanlan.zhihu.com/p/386595432
您可以考慮給樹發個小額微信紅包以資鼓勵
