『忘了再學』Shell基礎 — 25、擴充套件正規表示式
2022-06-06 12:04:11
1、擴充套件正規表示式說明
熟悉正規表示式的童鞋應該很疑惑,在其他的語言中是沒有擴充套件正規表示式說法的,在Shell的正規表示式中還可以支援一些元字元,比如+、?、|、()。
其實Linux系統是支援這些字元的,只是grep命令預設不支援而已(grep命令無法識別擴充套件正規表示式)。
如果要想支援這些字元,必須使用egrep命令或grep -E選項,才能識別擴充套件正規表示式的字元,所以我們又把這些字元稱作擴充套件字元。
egrep命令和grep -E命令是一樣的,所以我們可以把兩個命令當做別名來對待。
擴充套件正規表示式符號如下:
| 擴充套件元字元 | 作用 |
|---|---|
+ |
前一個字元匹配1次或任意多次。 如 go+gle會匹配gogle、google或gooogle,當然如果o有更多個,也能匹配。 |
? |
前一個字元匹配0次或1次。 如 colou?r可以匹配colour或color。 |
| ` | ` |
() |
匹配其整體為一個字元,即模式單元。可以理解為由多個單字元組成的大字元。 如 (dog)+會匹配dog、dogdog、dogdogdog等,因為被()包含的字元會當成一個整體。但`hello (world |
2、練習
(1)+和?練習
如下文字:
Stay hungry, stay foolish. ——Steve Jobs
求知若飢,虛心若愚。——喬布斯
Stay hungry, stay flish. ——Steve Jobs
Stay hungry, stay folish. ——Steve Jobs
Stay hungry, stay fooolish. ——Steve Jobs
Stay hungry, stay foooolish. ——Steve Jobs
Stay hungry, stay fooooolish. ——Steve Jobs
+
+表示匹配前一個字元1次或任意多次。
執行命令:grep -E "fo+l" test2.txt
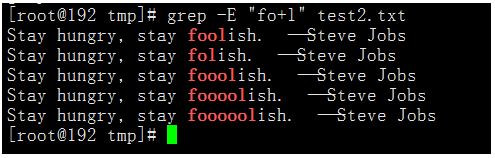
我們可以看到foolish單詞中,有o的全部匹配到了,而flish被過濾掉。?
?表示匹配前一個字元0次或1次。
執行命令:grep -E "fo?l" test2.txt
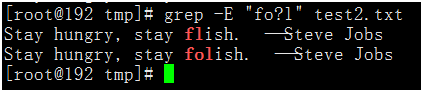
- 最後我們再來看一下
*。
*表示匹配前一個字元匹配0次或任意多次。
執行命令:grep -E "fo*l" test2.txt
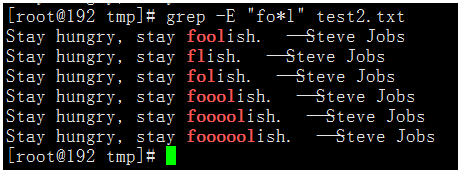
可以看出,+和?就相當於把*從1的位置分成了兩部分,?是匹配前一個字元0次或1次,+是匹配前一個字元1次或任意多次。
(2)|和()練習
這兩個符號經常會聯合使用。
|匹配兩個或多個分支選擇,表示或者的意思。
()匹配其整體為一個字元,表示整體的意思。
練習:匹配IP地址。
文字內容如下:
192.168.1.222
6666666666666
執行命令:grep -E "^(([0-9]\.)|([1-9][0-9]\.)|(1[0-9][0-9]\.)|(2[0-4][0-9]\.)|(25[0-5]\.)){3}(([0-9])|([1-9][0-9])|(1[0-9][0-9])|(2[0-4][0-9])|(25[0-5]))$" text3.txt

在Shell中能識別的正規表示式就是這些了。
3、注意(重點)
通過正規表示式匹配郵箱來說明:
匹配郵箱正則如下:
[0-9a-zA-Z_]+@[0-9a-zA-Z_]+(\.[0-9a-zA-Z_]+){1,3}
說明:
[0-9a-zA-Z_]+(郵箱名稱):表示數位、小寫字母、大寫字母、下劃線可以重複最少1次。[0-9a-zA-Z_]+(郵箱域名):表示數位、小寫字母、大寫字母、下劃線可以重複最少1次。(\.[0-9a-zA-Z_]+){1,3}:表示數位、小寫字母、大寫字母、下劃線可以重複最少1次,整體可重複1到3次。比如:處理com.cn格式等。
特別注意:
我們可以看到上邊
{1,3},並沒有寫成基礎正規表示式\{1,3\}的樣式。是因為
grep -E命令支援標準的正規表示式格式,不再需要對{}進行跳脫,如果加上跳脫符,還會報錯。這點需要特別注意一下。