這個佇列的思路是真的好,現在它是我簡歷上的亮點了。
你好呀,我是歪歪。
前幾天在一個開源專案的 github 裡面看到這樣的一個 pr:

光是看這個名字,裡面有個 MemorySafe,我就有點陷進去了。
我先給你看看這個東西:

這個肯定很眼熟吧?我是從阿里巴巴開發規範中截的圖。
為什麼不建議使用 FixedThreadPool 和 SingleThreadPool 呢?
因為佇列太長了,請求會堆積,請求一堆積,容易造成 OOM。
那麼問題又來了:前面提到的執行緒池用的佇列是什麼佇列呢?
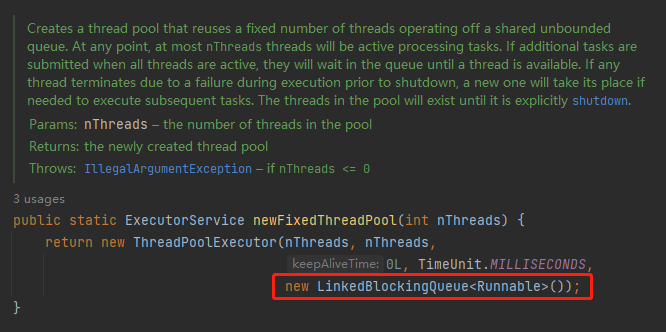
用的是沒有指定長度的 LinkedBlockingQueue。
沒有指定長度,預設長度是 Integer.MAX_VALUE,可以理解為無界佇列了:
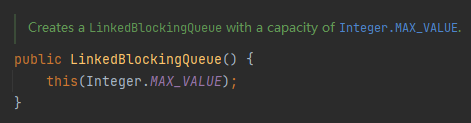
所以,在我的認知裡面,使用 LinkedBlockingQueue 是可能會導致 OOM 的。
如果想避免這個 OOM 就需要在初始化的時候指定一個合理的值。
「合理的值」,聽起來輕描淡寫的四個字,但是這個值到底是多少呢,你說的準嗎?
基本上說不準。
所以,當我看到 pr 上的 MemorySafeLinkedBlockingQueue 這個名字的時候,我就陷進去了。
在 LinkedBlockingQueue 前面加上了 MemorySafe 這個限定詞。
表示這是一個記憶體安全的 LinkedBlockingQueue。
於是,我想要研究一下到底是怎麼樣來實現「安全」的,所以啪的一下就點進去了,很快啊。

MemorySafeLBQ
在這個 pr 裡面我們看一下它主要是想幹個什麼事兒:
https://github.com/apache/dubbo/pull/10021
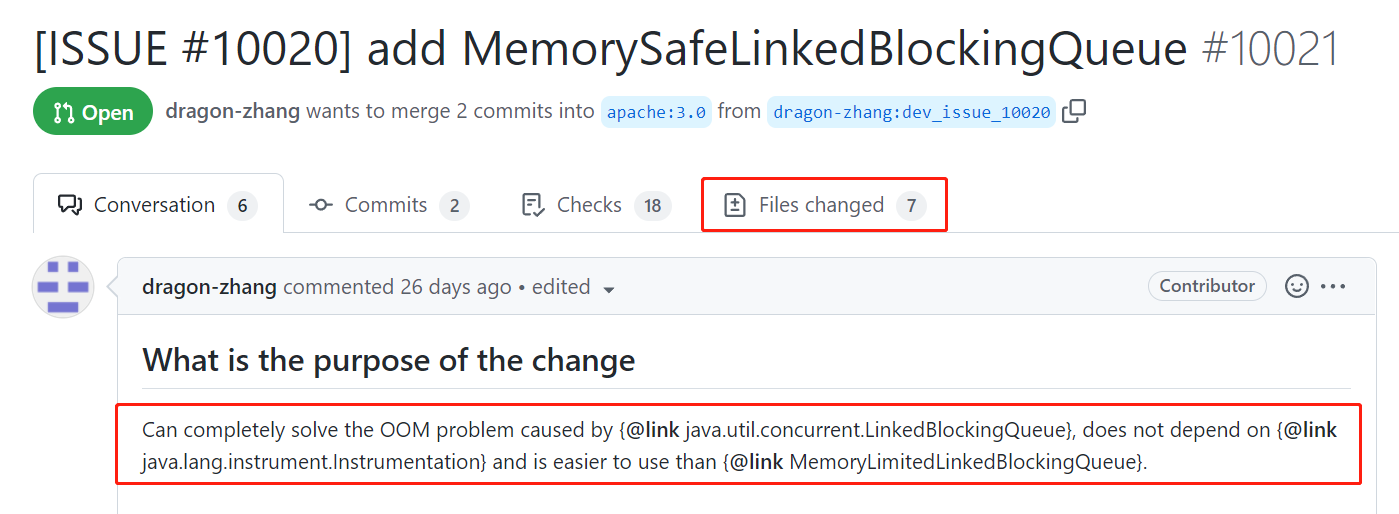
提供程式碼的哥們是這樣描述它的功能的:
可以完全解決因為 LinkedBlockingQueue 造成的 OOM 問題,而且不依賴 instrumentation,比 MemoryLimitedLinkedBlockingQueue 更好用。
然後可以看到這次提交涉及到 7 個檔案。
實際上真正核心的程式碼是這兩個:
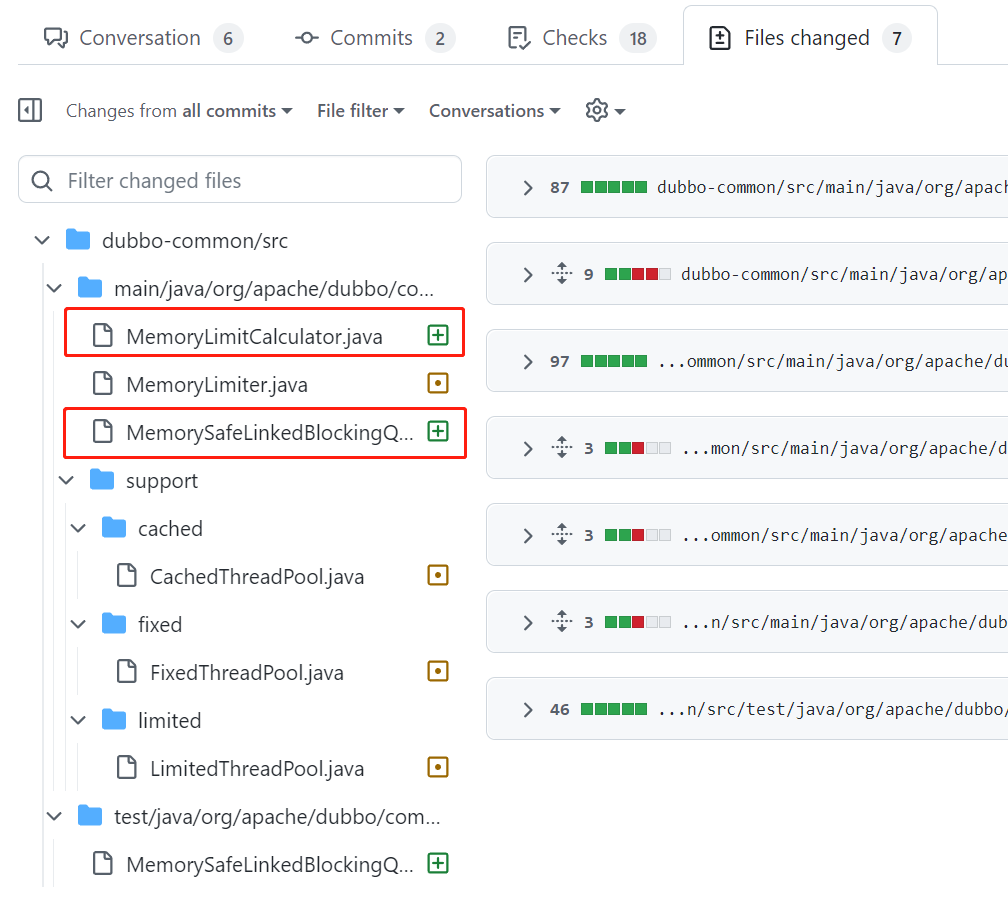
但是不要慌,先眼熟一下這兩個類,然後我先按下不表。先追根溯源,從源頭上講。
這兩個類的名字太長了,所以先約定一下,在本文中,我用 MemoryLimitedLBQ 來代替 MemoryLimitedLinkedBlockingQueue。用 MemorySafeLBQ 來代替 MemorySafeLinkedBlockingQueue。

可以看到,在 pr 裡面它還提到了「比 MemoryLimitedLBQ 更好用」。
也就是說,它是用來替代 MemoryLimitedLBQ 這個類的。
這個類從命名上也看得出來,也是一個 LinkedBlockingQueue,但是它的限定詞是 MemoryLimited,可以限制記憶體的。
我找了一下,這個類對應的 pr 是這個:
https://github.com/apache/dubbo/pull/9722
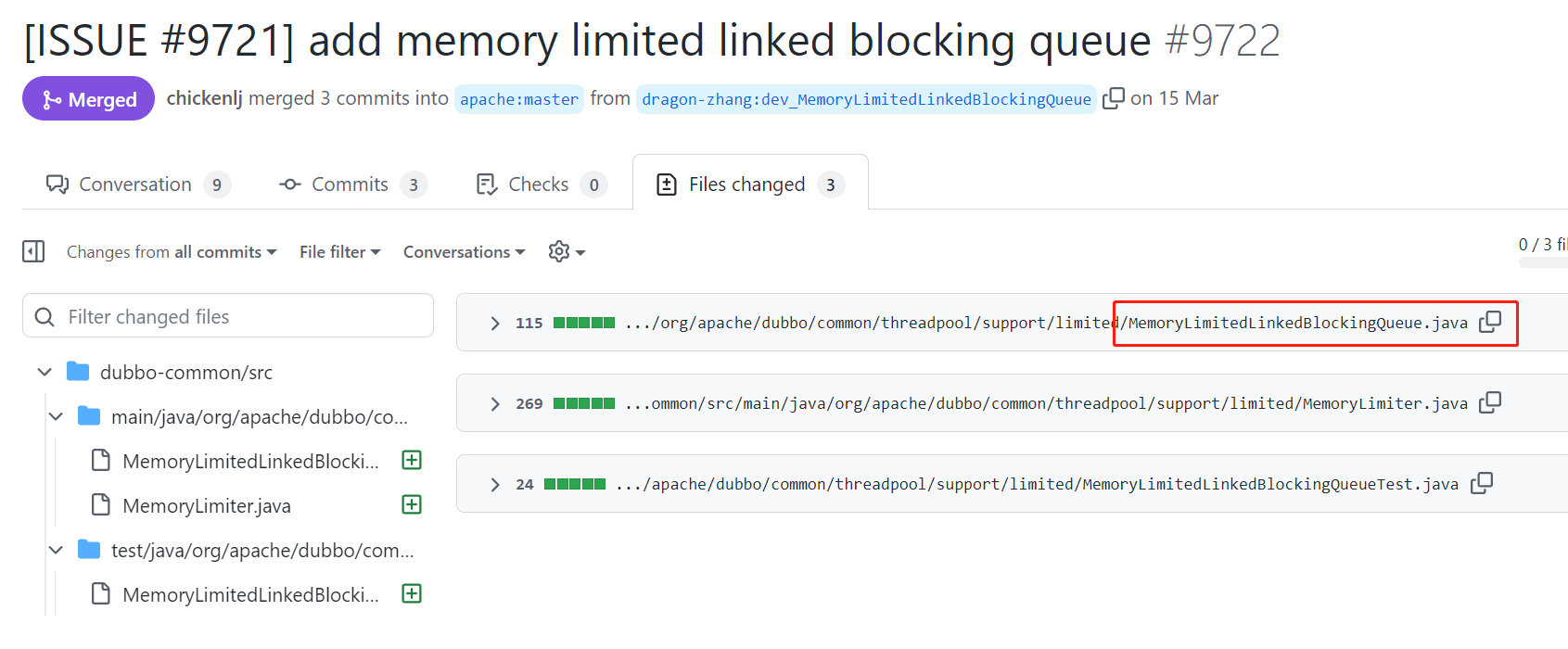
在這個 pr 裡面,有大佬問他:

你這個新佇列實現的意義或目的是什麼?你能不能說出當前版本庫中需要被這個佇列取代的佇列?這樣我們才好決定是否使用這個佇列。
也就是說他只是提交了一個新的佇列,但是並沒有說到應用場景是什麼,導致官方不知道該不該接受這個 pr。
於是,他補充了一個回覆:
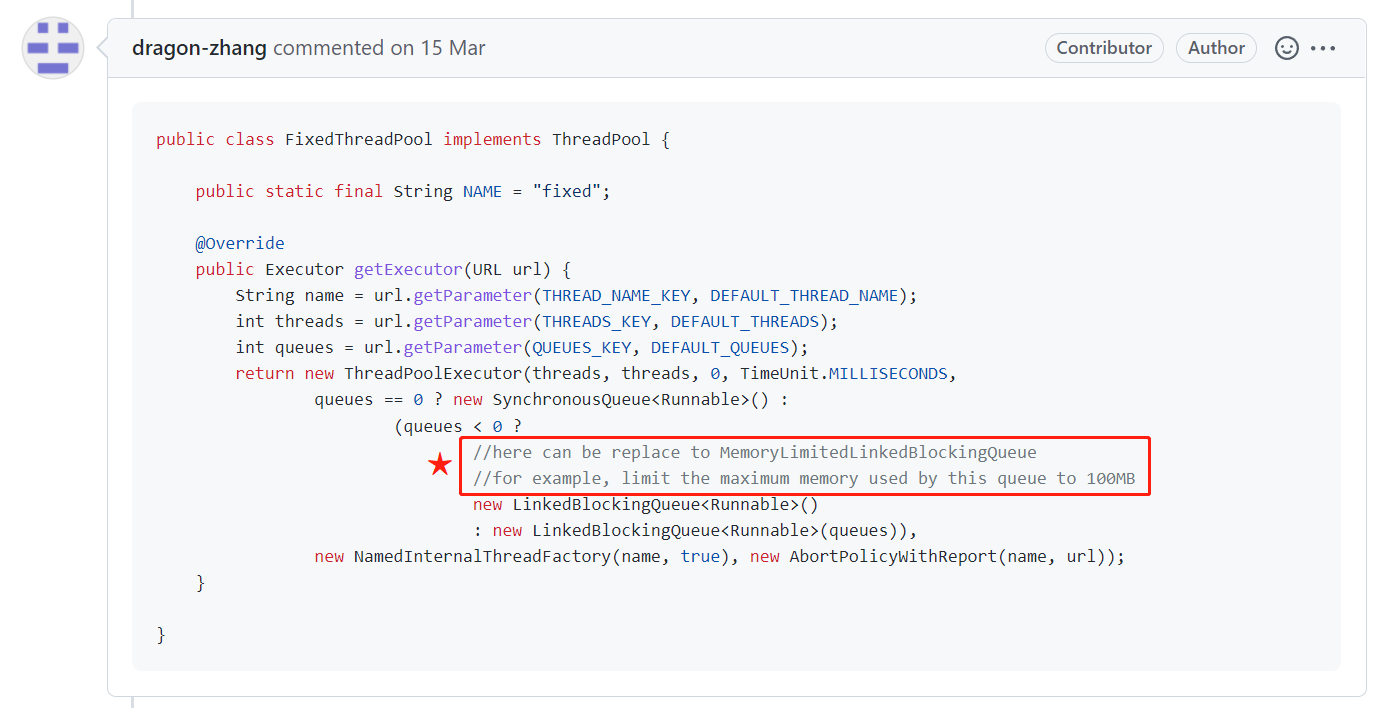
就是拿的 FixedThreadPool 做的範例。
在這個裡面,就使用了無參的 LinkedBlockingQueue,所以會有 OOM 的風險。
那麼就可以使用 MemoryLimitedLBQ 來代替這個佇列。
比如,我可以限制這個佇列可以使用的最大記憶體為 100M,通過限制記憶體的方式來達到避免 OOM 的目的。
好,到這裡我先給你梳理一下。
首先應該是有一個叫 MemoryLimitedLBQ 的佇列,它可以限制這個佇列最大可以佔用的記憶體。
然後,由於某些原因,又出現了一個叫做 MemorySafeLBQ 的佇列,宣稱比它更好用,所以來取代它。
所以,接下來我就要梳理清楚三個問題:
MemoryLimitedLBQ 的實現原理是什麼? MemorySafeLBQ 的實現原理是什麼? MemorySafeLBQ 為什麼比 MemoryLimitedLBQ 更好用?
MemoryLimitedLBQ
別看這個玩意我是在 Dubbo 的 pr 裡面看到的,但是它本質上是一個佇列的實現方式。
所以,完全可以脫離於框架而存在。
也就是說,你開啟下面這個連結,然後直接把相關的兩個類粘出來,就可以跑起來,為你所用:
https://github.com/apache/dubbo/pull/9722/files
我先給你看看 MemoryLimitedLBQ 這個類,它就是繼承自 LinkedBlockingQueue,然後重寫了它的幾個核心方法。
只是自定義了一個 memoryLimiter 的物件,然後每個核心方法裡面都操作了 memoryLimiter 物件:
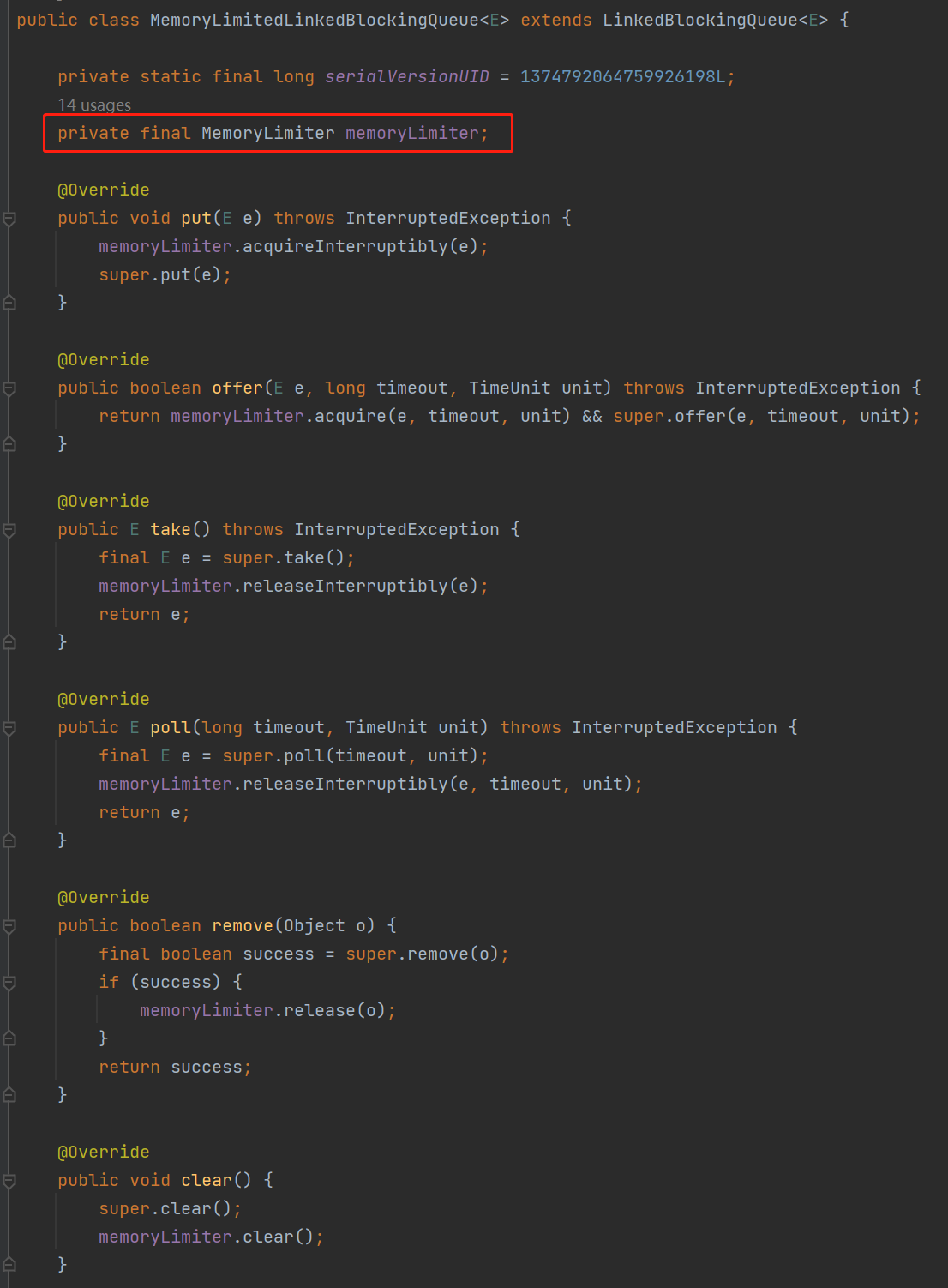
所以真正的祕密就藏在 memoryLimiter 物件裡面。
比如,我帶你看看這個 put 方法:
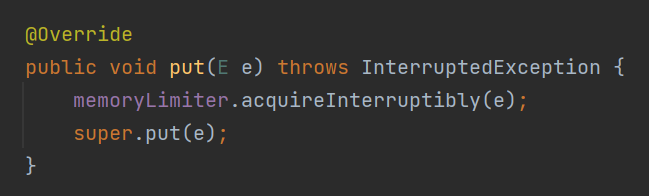
這裡面呼叫了 memoryLimiter 物件的 acquireInterruptibly 方法。
在解讀 acquireInterruptibly 方法之前,我們先關注一下它的幾個成員變數:
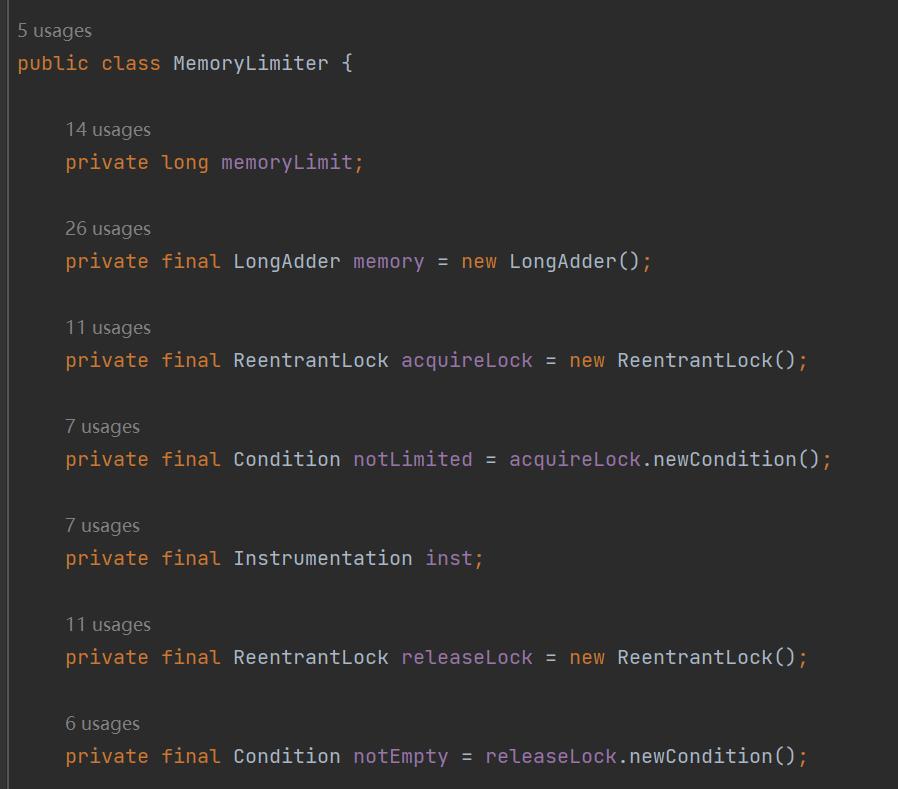
memoryLimit 就是表示這個佇列最大所能容納的大小。 memory 是 LongAdder 型別,表示的是當前已經使用的大小。 acquireLock、notLimited、releaseLock、notEmpty 是鎖相關的引數,從名字上可以知道,往佇列裡面放元素和釋放佇列裡面的元素都需要獲取對應的鎖。 inst 這個引數是 Instrumentation 型別的。
前面幾個引數至少我還很眼熟的,但是這個 inst 就有點奇怪了。

這玩意日常開發中基本上用不上,但是用好了,這就是個黑科技了。很多工具都是基於這個玩意來實現的,比如大名鼎鼎的 Arthas。
它可以更加方便的做位元組碼增強操作,允許我們對已經載入甚至還沒有被載入的類進行修改的操作,實現類似於效能監控的功能。
可以說 Instrumentation 就是 memoryLimiter 的關鍵點:
比如在 memoryLimiter 的 acquireInterruptibly 方法裡面,它是這樣的用的:
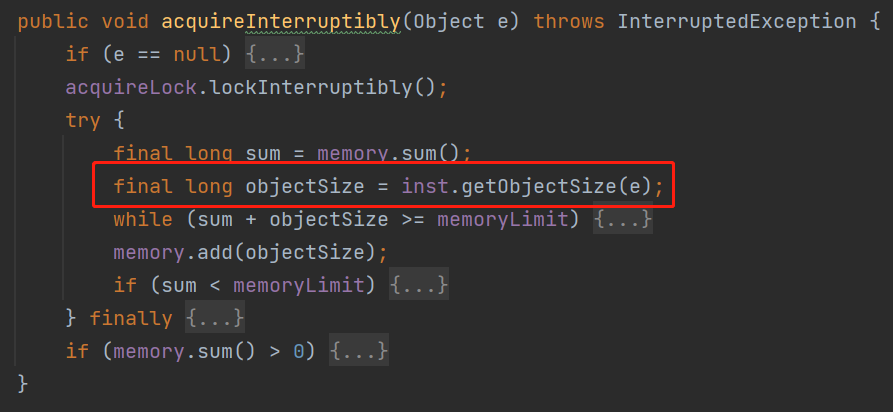
看方法名稱你也知道了,get 這個 object 的 size,這個 object 就是方法的入參,也就是要放入到佇列裡面的元素。
為了證明我沒有亂說,我帶你看看這個方法上的註釋:
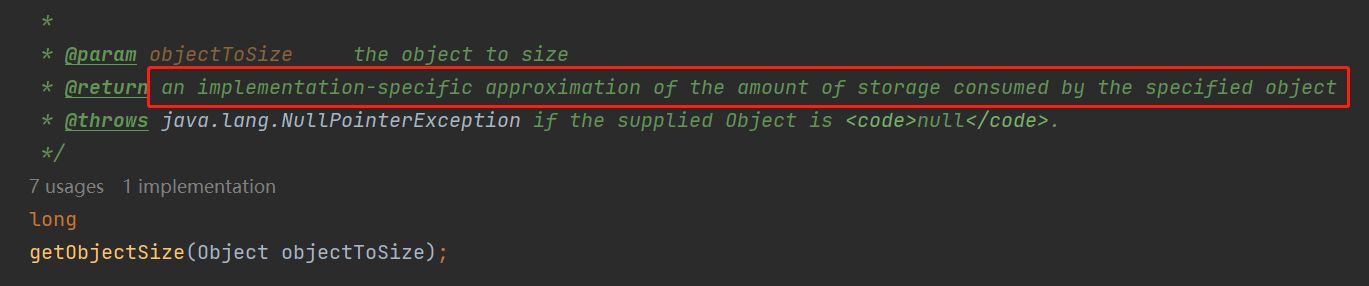
an implementation-specific approximation of the amount of storage consumed by the specified object
注意這個單詞:approximation.
這可是正兒八經的四級詞彙,還是 a 開頭的,你要是不眼熟的話可是要挨板子的。

整句話翻譯過來就是:返回指定物件所消耗的儲存量的一個特定實現的近似值。
再說的直白點就是你傳進來的這個物件,在記憶體裡面到底佔用了多長的長度,這個長度不是一個非常精確的值。
所以,理解了 inst.getObjectSize(e) 這行程式碼,我們再仔細看看 acquireInterruptibly 是怎麼樣的:
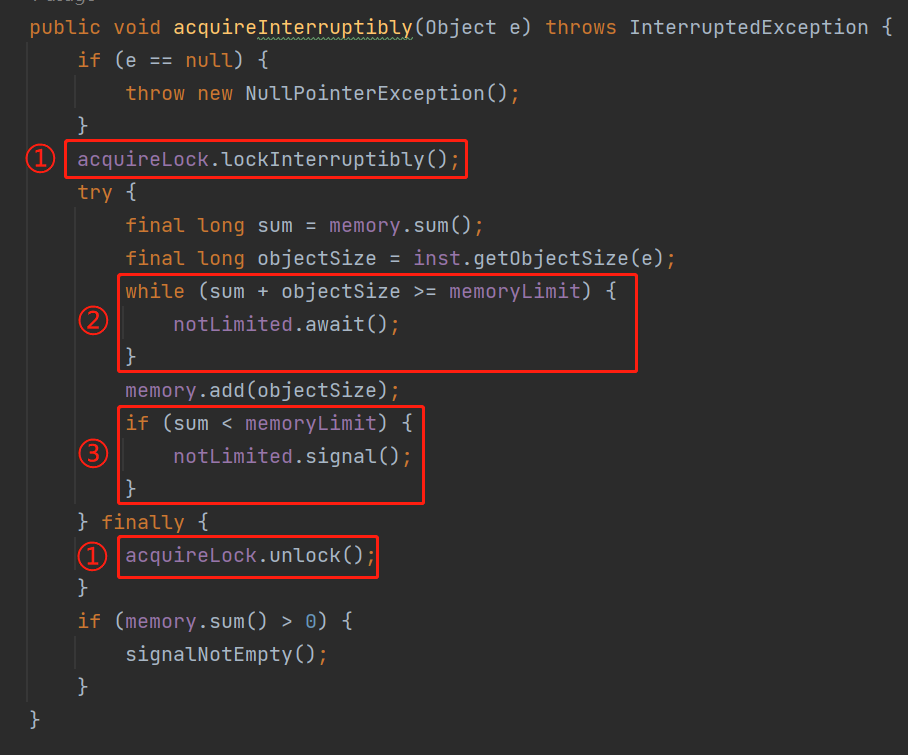
首先,兩個標號為 ① 的地方,表示操作這個方法是要上鎖的,整個 try 裡面的方法是執行緒安全的。
然後標號為 ② 的裡面幹了什麼事兒?
就是計算 memory 這個 LongAdder 型別的 sum 值加上當前這個物件的值之後,是不是大於或者等於 memoryLimit。
如果計算後的值真的超過了 memoryLimit,那麼說明需要阻塞一下下了,呼叫 notLimited.await() 方法。
如果沒有超過 memoryLimit,說明還能往佇列裡面放東西,那麼就更新 memory 的值。
接著到了標號為 ③ 的地方。
來到這裡,再次判斷一下當前已經使用的值是否沒有超過 memoryLimit,如果是的話,就呼叫 notLimited.signal() 方法,喚醒一下之前由於 memoryLimit 引數限制導致不能放入的物件。
整個邏輯非常的清晰。
而整個邏輯裡面的核心邏輯就是呼叫 Instrumentation 型別的 getObjectSize 方法獲得當前放入物件的一個 size,並判斷當前已經使用的值加上這個 size 之後,是否大於了我們設定的最大值。
所以,你用腳趾頭猜也能猜到了,在 release 方法裡面,肯定也是計算當前物件的 size,然後再從 memory 裡面減出去:
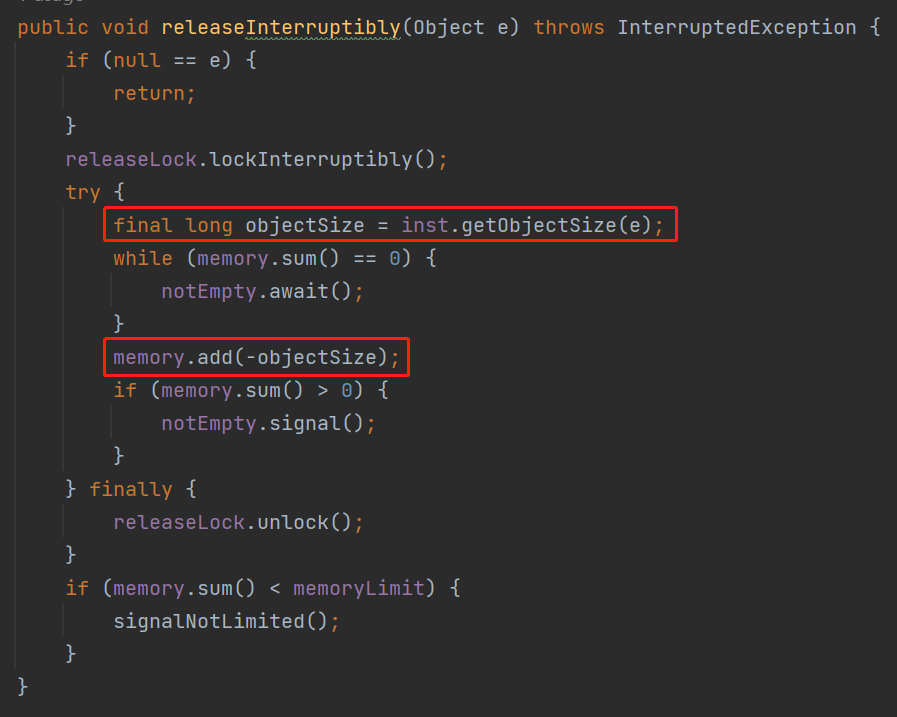
說穿了,也就這麼屁大點事兒。

然後,你再次審視一下這個 acquireInterruptibly 方法的 try 程式碼塊裡面的邏輯,你有沒有發現什麼 BUG:
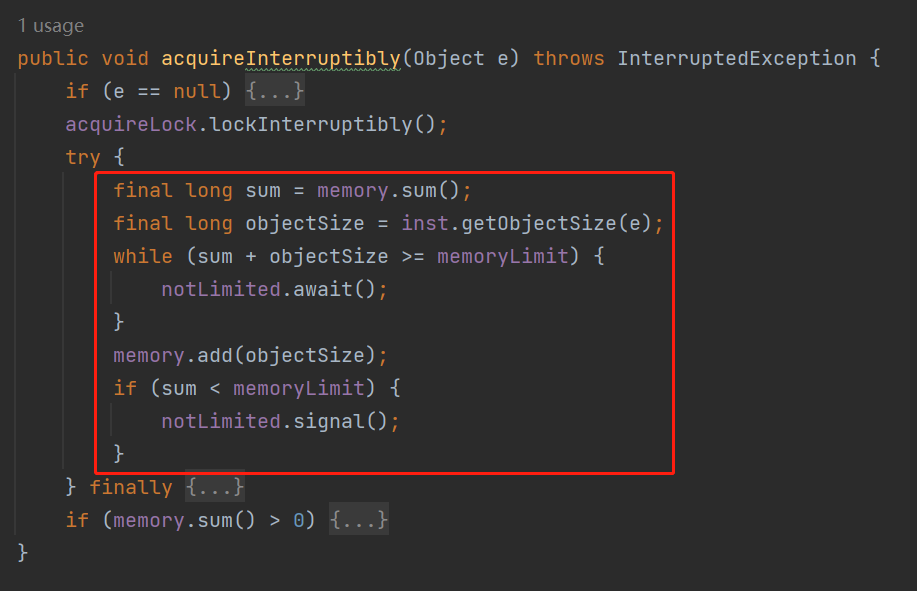
如果你沒反映過來,那我再提個醒:你認真的分析一下 sum 這個區域性變數是不是有點不妥?
你要是還沒反應過來,那我直接給你上個程式碼。後面有一次提交,是把 sum 修改為了 memory.sum() :
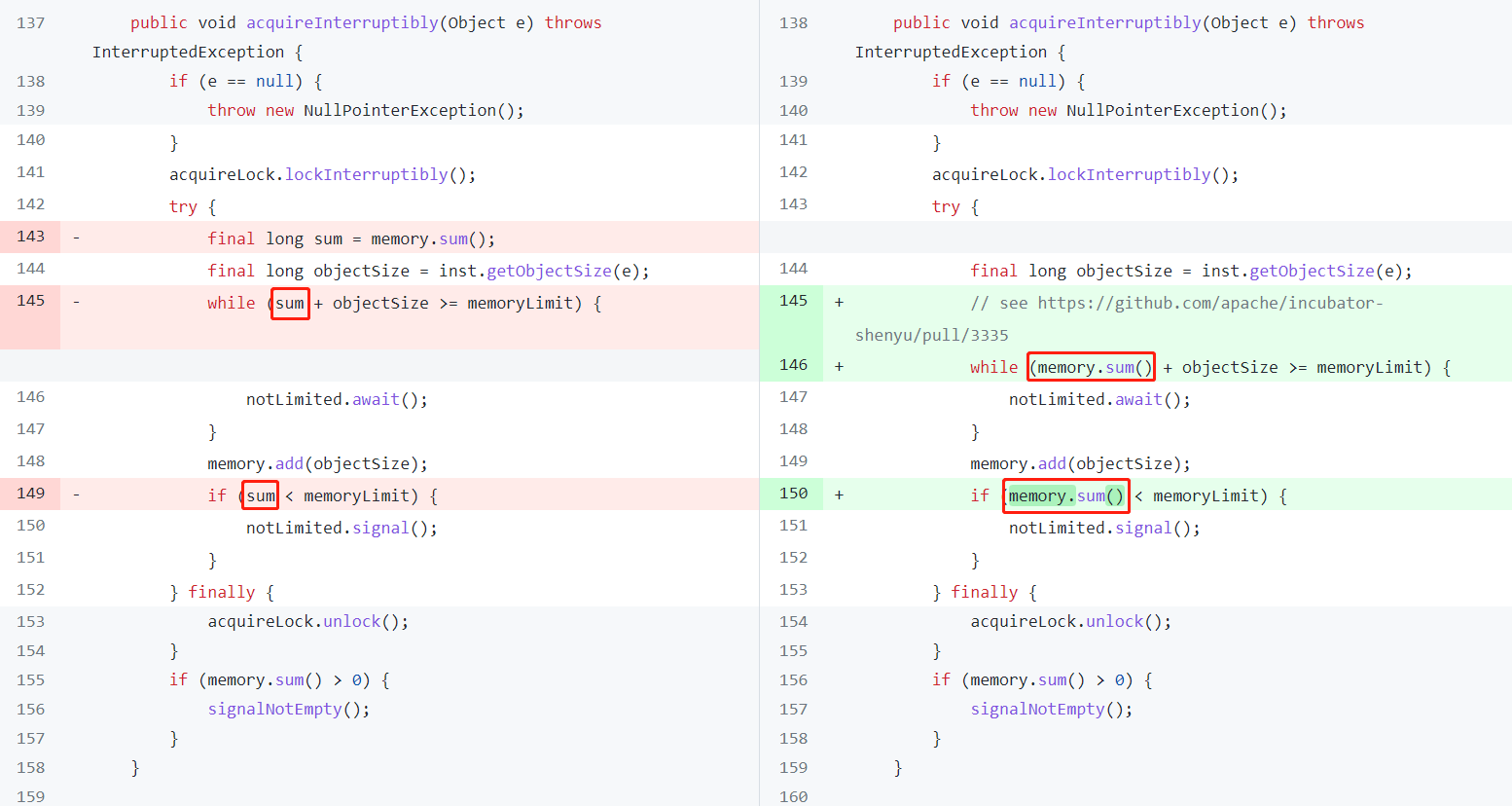
為什麼這樣改呢?
我給你說個場景,假設我們的 memoryLimit 是 1000,當前已經使用的 memory 是 800,也就是 sum 是 800。這個時候我要放的元素計算出來的 size 是 300,也就是 objectSize 是 300。
sum+objectSize=1100,比 memoryLimit 的值大,是不是在這個 while 判斷的時候被攔截住了:
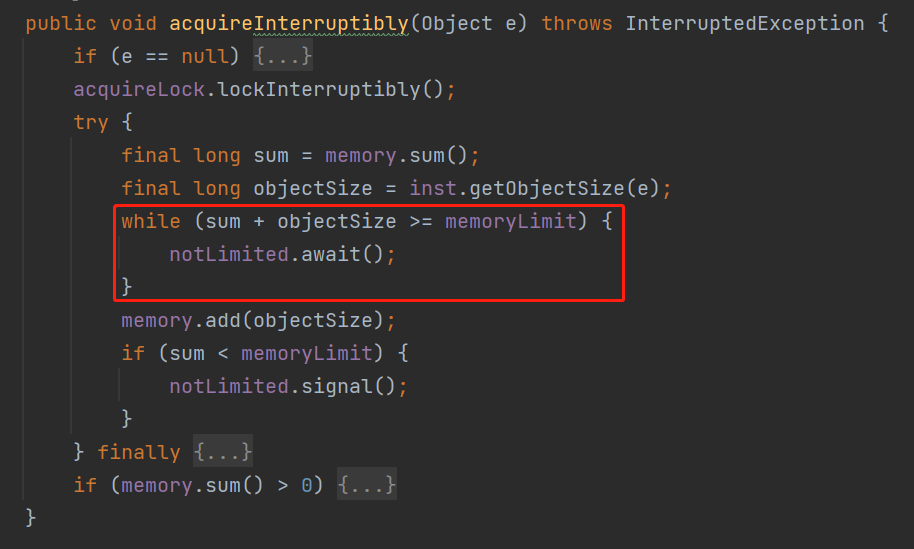
之後,假設佇列裡面又釋放了一個 size 為 600 的物件。
這個時候執行 memory.add(-objectSize) 方法,memory 變為 200:
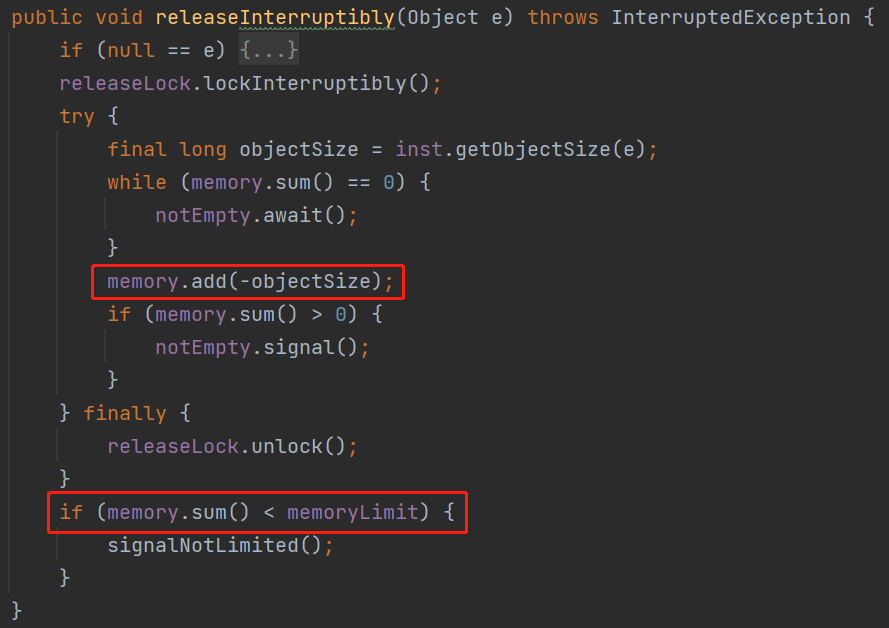
那麼會呼叫 signalNotLimited 方法,喚醒這個被攔截的這個哥們:
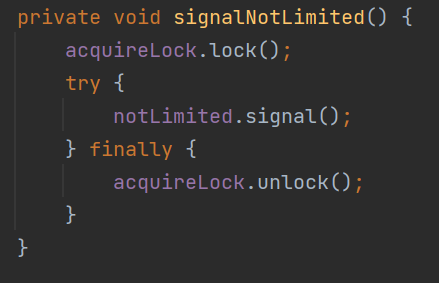
這個哥們一被喚醒,一看程式碼:
while (sum + objectSize >= memoryLimit) {
notLimited.await();
}
心裡想:我這裡的 sum 是 800,objectSize 是 300,還是大於 memoryLimit 啊,把我喚醒幹啥玩意,傻逼嗎?
那麼你說,它罵的是誰?

這個地方的程式碼肯定得這樣,每次都檢視最新的 memory 值才行:
while (memory.sum() + objectSize >= memoryLimit) {
notLimited.await();
}
所以,這個地方是個 BUG,還是個死迴圈的 BUG。
前面程式碼截圖中還出現了一個連結,就是說的這個 BUG:
https://github.com/apache/incubator-shenyu/pull/3335
另外,你可以看到連結中的專案名稱是 incubator-shenyu,這是一個開源的 API 閘道器:

本文中的 MemoryLimitedLBQ 和 MemorySafeLBQ 最先都是出自這個開源專案。
MemorySafeLBQ
前面瞭解了 MemoryLimitedLBQ 的基本原理。
接下來我帶你看看 MemorySafeLBQ 這個玩意。
它的原始碼可以通過這個連結直接獲取到:
https://github.com/apache/dubbo/pull/10021/files
也是拿出來就可以放到自己的專案跑,把檔案作者修改為自己的名字的那種。
讓我們回到最開始的地方:
這個 pr 裡面說了,我搞 MemorySafeLBQ 出來,就是為了替代 MemoryLimitedLBQ 的,因為我比它好用,而且我還不依賴於 Instrumentation。
但是看了原始碼之後,會發現其實思路都是差不多的。只不過 MemorySafeLBQ 屬於是反其道而行之。
怎麼個「反其道」法呢?
看一下原始碼:
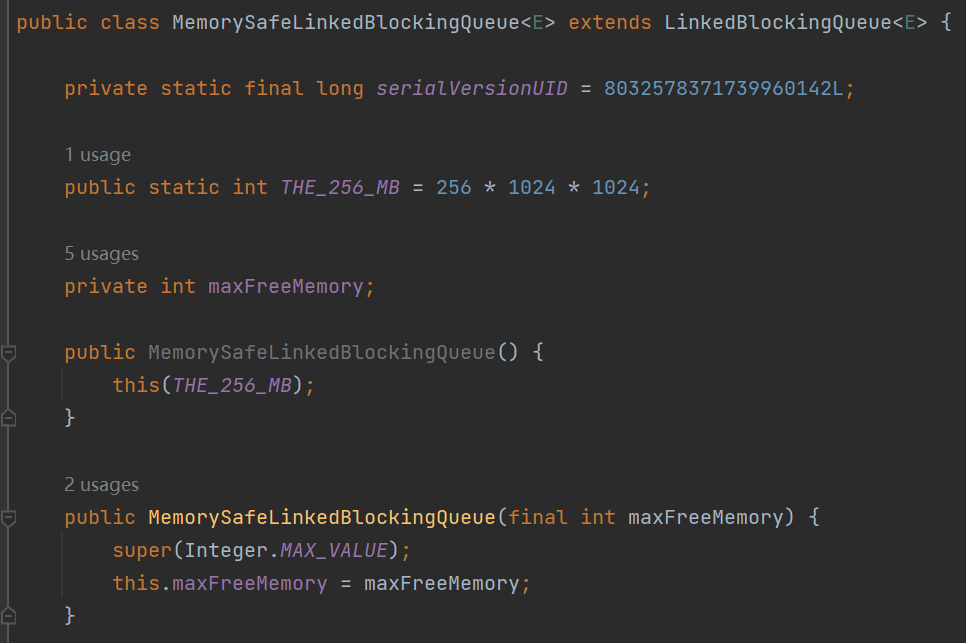
MemorySafeLBQ 還是繼承自 LinkedBlockingQueue,只是多了一個自定義的成員變數,叫做 maxFreeMemory,初始值是 256 * 1024 * 1024。
這個變數的名字就非常值得注意,你再細細品品。maxFreeMemory,最大的剩餘記憶體,預設是 256M。
前面一節講的 MemoryLimitedLBQ 限制的是這個佇列最多能使用多少空間,是站在佇列的角度。
而 MemorySafeLBQ 限制的是 JVM 裡面的剩餘空間。比如預設就是當整個 JVM 只剩下 256M 可用記憶體的時候,再往佇列裡面加元素我就不讓你加了。
因為整個記憶體都比較吃緊了,佇列就不能無限制的繼續新增了,從這個角度來規避了 OOM 的風險。
這樣的一個反其道而行之。
另外,它說它不依賴 Instrumentation 了,那麼它怎麼檢測記憶體的使用情況呢?

使用的是 ManagementFactory 裡面的 MemoryMXBean。
這個 MemoryMXBean 其實你一點也不陌生。
JConsole 你用過吧?
下面這個介面進去過吧?
這些資訊就是從 ManagementFactory 裡面拿出來的:
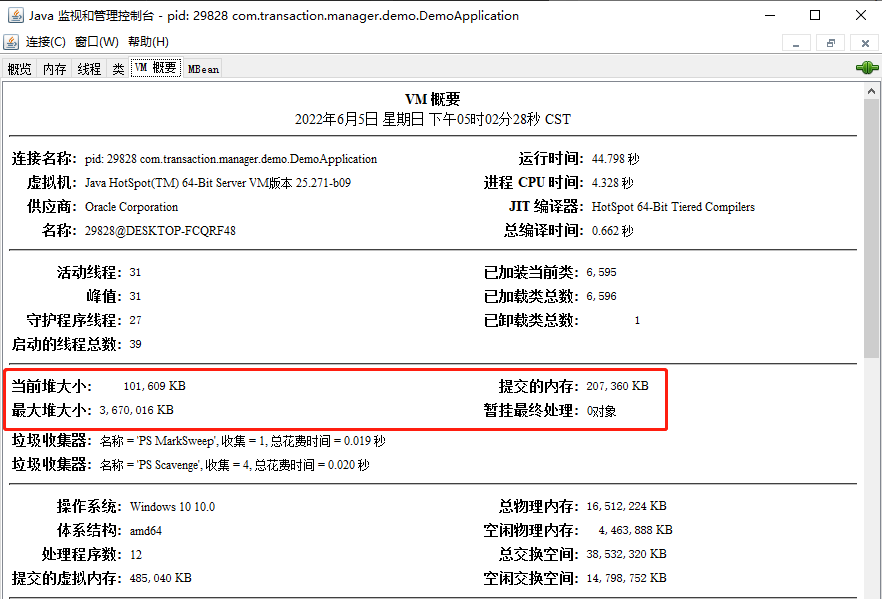
所以,確實它沒有使用 Instrumentation,但是它使用了 ManagementFactory。
目的都是為了獲取記憶體的執行狀態。
那麼怎麼看出來它比 MemoryLimitedLBQ 更好用呢?
我看了,關鍵方法就是這個 hasRemainedMemory,在呼叫 put、offer 方法之前就要先呼叫這個方法:
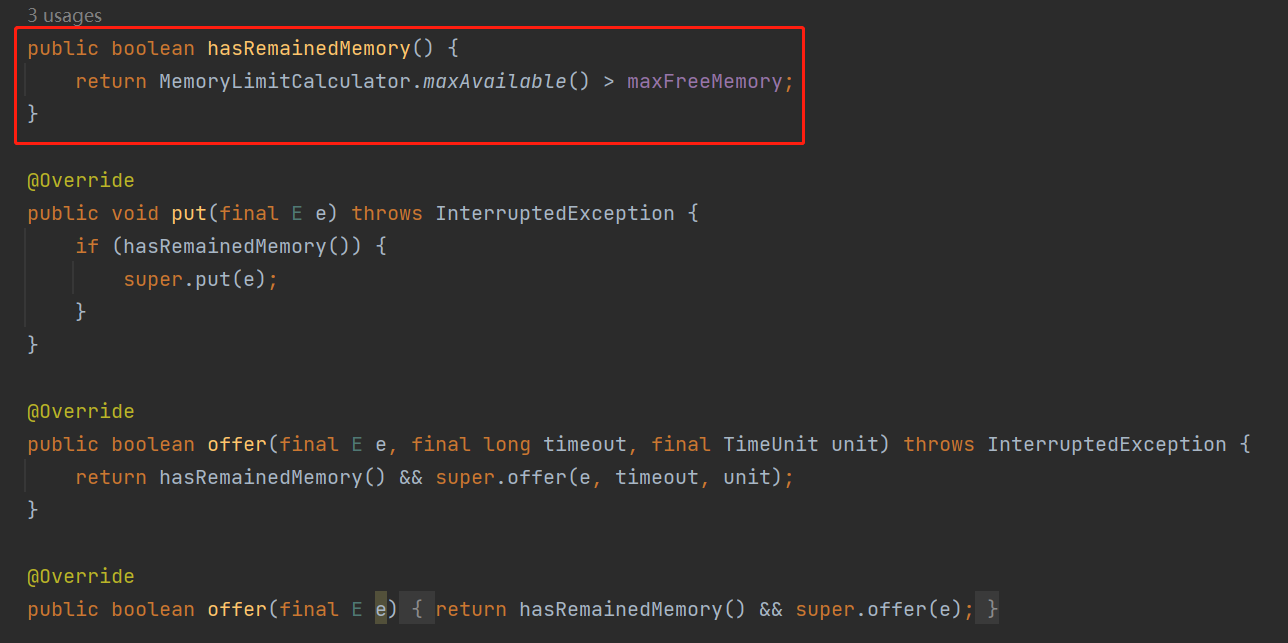
而且你看 MemorySafeLBQ 只是重寫了放入元素的 put、offer 方法,並不關注移除元素。
為什麼呢?
因為它的設計理念是隻關心新增元素時候的剩餘空間大小,它甚至都不會去關注當前這個元素的大小。
而還記得前面講的 MemoryLimitedLBQ 嗎?它裡面還計算了每個元素的大小,然後搞了一個變數來累加。
MemoryLimitedLBQ 的 hasRemainedMemory 方法裡面也只有一行程式碼,其中 maxFreeMemory 是類初始化的時候就指定好了。那麼關鍵的程式碼就是 MemoryLimitCalculator.maxAvailable()。
所以我們看看 MemoryLimitCalculator 的原始碼。
這個類的原始碼寫的非常的簡單,我全部截完都只有這麼一點內容,全部加起來也就是 20 多行程式碼:
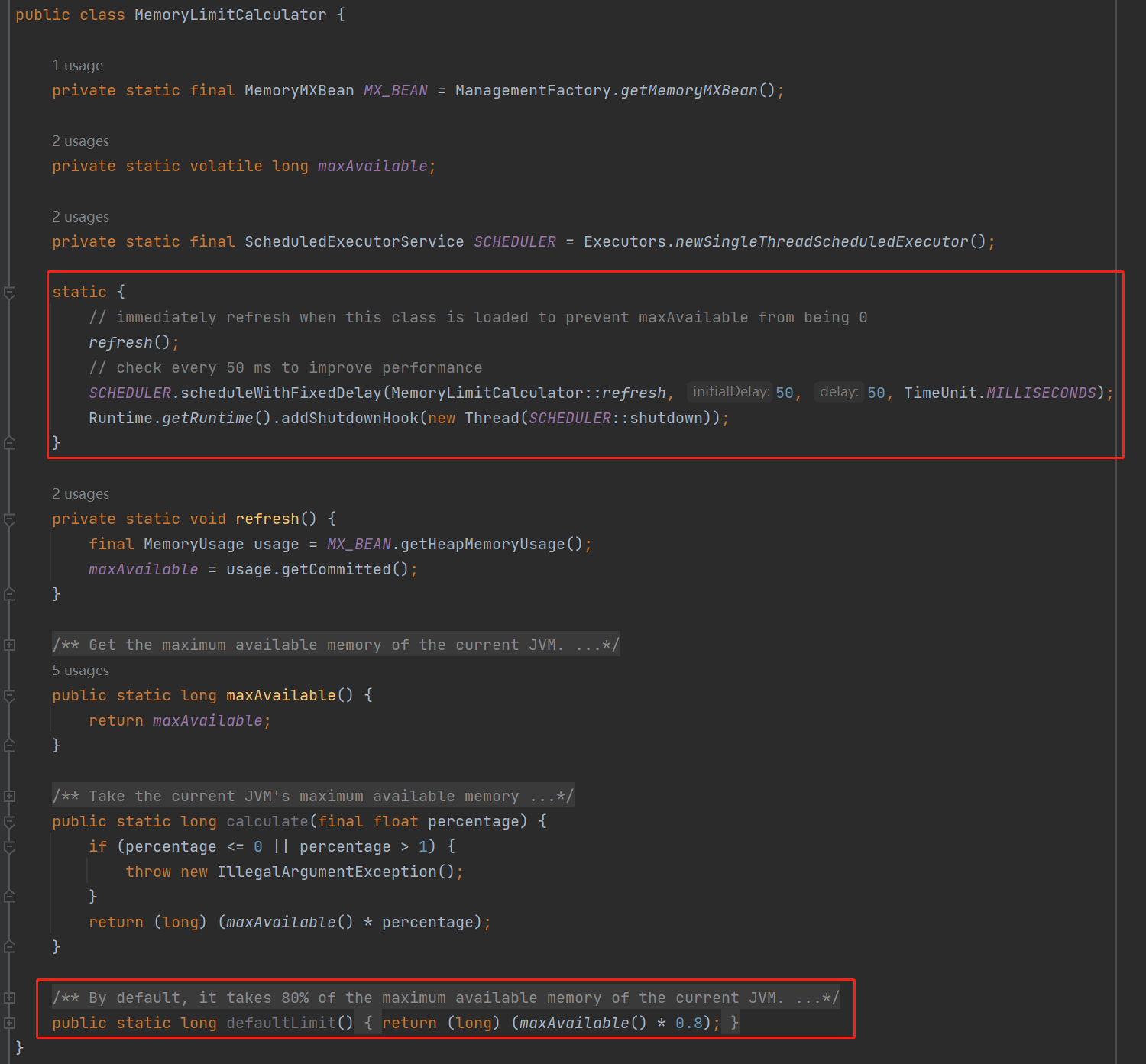
而整個方法的核心就是我框起來的 static 程式碼塊,裡面一共有三行程式碼。
第一行是呼叫 refresh 方法,也就是對 maxAvilable 這個引數進行重新賦值,這個引數代表的意思是當前還可以使用的 JVM 記憶體。
第二行是注入了一個每 50ms 執行一次的定時任務。到點了,就觸發一下 refresh 方法,保證 maxAvilable 引數的準實時性。
第三行是加入了 JVM 的 ShutdownHook,停服務的時候需要把這個定時任務給停了,達到優雅停機的目的。
核心邏輯就這麼點。
從我的角度來說,確實是比 MemoryLimitedLBQ 使用起來更簡單,更好用。
最後,再看看作者提供的 MemorySafeLBQ 測試用例,我補充了一點註釋,很好理解,自己去品,不再多說:
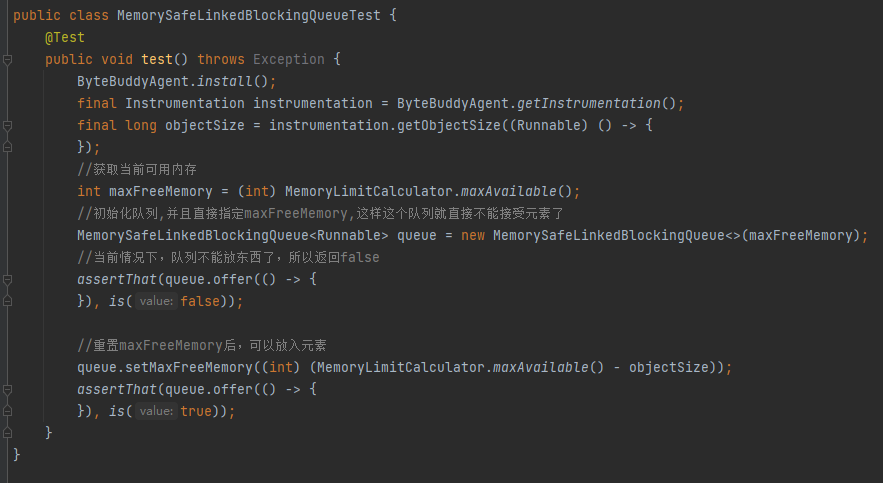
它是你的了
文章裡面提到的 MemoryLimitedLBQ 和 MemorySafeLBQ,我說了,這兩個玩意是完全獨立於框架的,程式碼直接粘過來就可以用。
程式碼也沒幾行,不管是用 Instrumentation 還是 ManagementFactory,核心思想都是限制記憶體。
思路擴充套件一下,比如我們有的專案裡面用 Map 來做本地快取,就會放很多元素進去,也會有 OOM 的風險,那麼通過前面說的思路,是不是就找到了一個問題的解決方案?
所以,思路是很重要的,掌握到了這個思路,面試的時候也能多掰扯幾句嘛。
再比如,我看到這個玩意的時候,聯想到了之前寫過的執行緒池引數動態調整。
就拿 MemorySafeLBQ 這個佇列來說,它裡面的 maxFreeMemory 這個引數,可不可以做成動態調整的?

不外乎就是把之前的佇列長度可調整修改為了佇列佔用的記憶體空間可調整。一個引數的變化而已,實現方案可以直接套用。
這些都是我從開源專案裡面看到的,但是在我看到的那一刻,它就是我的。
現在,我把它寫出來,分享給你,它就是你的了。
不客氣,來個三連就行。