R資料分析:如何簡潔高效地展示統計結果
之前給大家寫過一篇資料淨化的文章,解決的問題是你拿到原始資料後如何快速地對資料進行處理,處理到你基本上可以拿來分析的地步,其中介紹瞭如何選變數如何篩選個案,變數重新編碼,如何去重,如何替換缺失值,如何計算變數等等------R資料分析:資料淨化的思路和核心函數介紹
今天呢,就更進一步,對於一個處理好的資料,我們就可以進行統計分析了,本文的思路就是對照期刊論文的一般流程寫寫如何快速的實現一篇論文的統計過程並簡潔高效地展示結果。依然提醒大家,請先收藏本文再往下讀哈。
先做描述統計
基本上文章結果部分一上來首先展示的就是描述統計,就是你有多少樣本,樣本特徵是啥樣的----連續變數的均值標準差是多少,分類變數的頻數百分比是多少等等,這些都是描述統計
做法1:
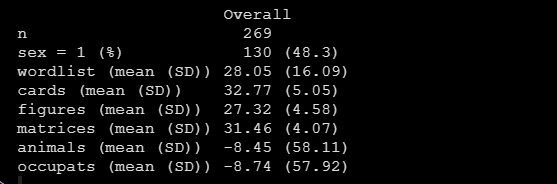
比如我現在拿到手的處理好的資料是這樣:
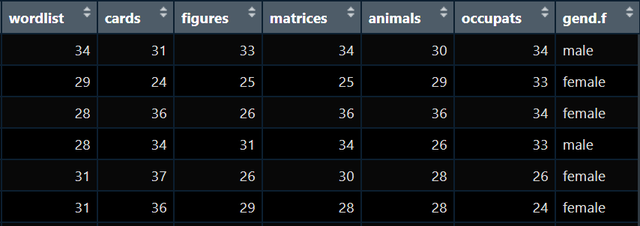
圖1
比如我想看看男女之間它們每個變數的均值是多少,我就可以寫出如下程式碼:
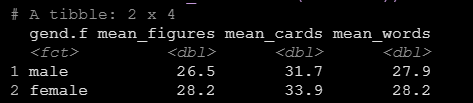
data %>%
group_by(gend.f) %>%
summarize(mean_figures=mean(figures),
mean_cards=mean(cards),
mean_words=mean(wordlist))執行之後可以看到輸出中就按照性別輸出了三個變數的均值。
如果我們想要描述的變數很多,可以用summarize_at函數進一步簡化程式碼如下:
data %>%
group_by(gend.f) %>%
summarize_at(vars("figures","cards","wordlist"), mean)執行後得到結果如下:
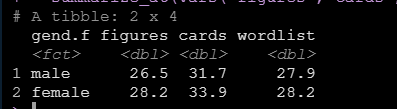
上面是均值的例子,其餘的比如標準差只需要將mean函數一換就可以。
方法2:
方法1感覺還是有點呆哈,給大家介紹方法2:我們還可以直接用psych包中的describe函數也可以得到連續變數常用的描述統計量,比如執行下面的程式碼:
describe(data, fast = T)就可以得到資料的描述統計,包括個數,均值,標準差,極值極差標準誤,比方法1要方便一丟丟的:
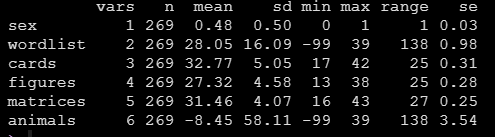
如果將fast引數去掉,則偏度峰度,中位數等等也會出現:

以上兩種方法都是針對連續變數的部分處理方法,適用性沒有那麼好,再接著看下面的做法
做法3:使用tableone包
做描述統計第三個方法就是用tableone包,依然是對於圖1中的資料,我現在想做一個描述統計,連續變數用均值±標準差,分類變數用頻數百分比表示,我就可以寫出如下程式碼:
(tab_nhanes <- CreateTableOne(data = data))執行後得到如下描述統計結果:
可以看到,sex變數是用頻數百分比進行描述的,其餘的連續變數都是以均值標準差呈現的。
在使用tableone包的時候如果你通過正態性檢驗發現某個變數不是正態分佈的,這個時候需要用中位數和四分位數間距進行描述,此時在列印tableone物件的時候加上nonnormal = "變數名"引數就好了,比如我現在知道我的資料中年齡是不服從正態分佈的,我就可以寫出如下程式碼:
print(tab_nhanes,
showAllLevels = TRUE,
nonnormal = "Age"
)大家肯定見過這樣的表格展示的描述統計,就是分組描述統計:
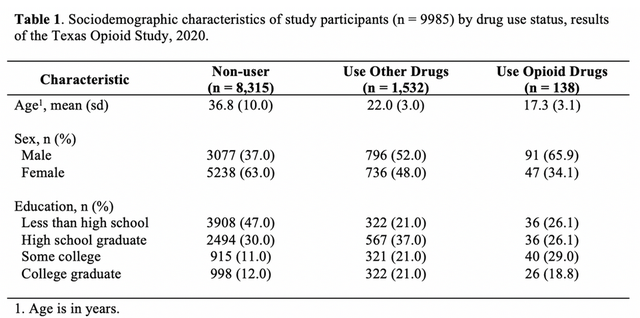
比如干預實驗中對照組和干預組的特徵比較,兩組隨訪資料的基線特徵比較等等。
這樣的表格用tableone也是非常容易實現的,比如我的原始資料長這樣:
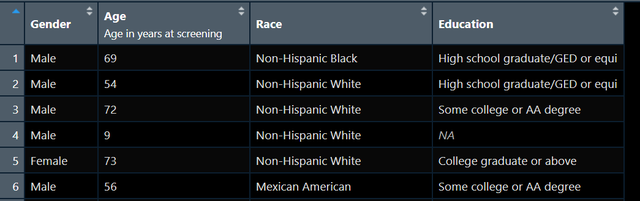
圖2
我現在想以Gender這個變數進行分組描述統計,我便可以寫出如下程式碼:
strata <- CreateTableOne(data = data,
vars = c("Age", "Race", "Education"),
factorVars = c("Race","Education"),
strata = "Gender"
)
print(strata,
nonnormal = "Age",
cramVars = "Gender")上面的程式碼中,strata引數設定分組變數,factorVars指定變數型別為因子,vars引數指定我們要進行統計描述的變數,執行後出來的結果如下:
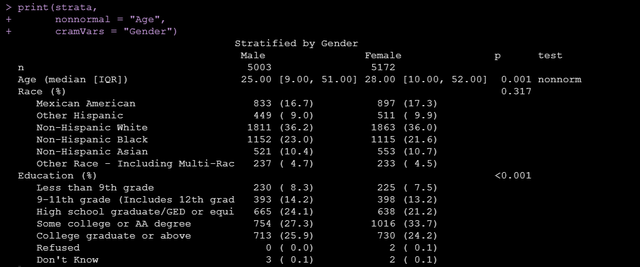
可以看到既有所有變數的統計描述還有組間比較的p值,另外我們可以很方便地通過以下程式碼將做出來的tableone輸出成csv:
tab_csv <- print(strata,
nonnormal = "Age",
printToggle = FALSE)
write.csv(tab_csv, file = "Summary.csv")執行後即可在目錄中找到相應的csv檔案,然後直接複製貼上到論文中。
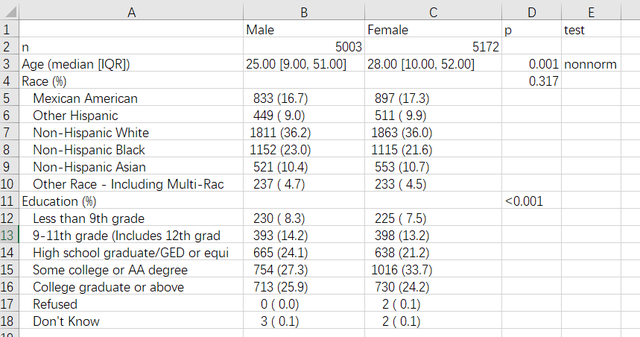
圖3
方法4:gtsummary
最後要給大家介紹的方法就是使用gtsummary中的tbl_summary函數,比如依然是上面的資料(圖1中的資料),我使用gtsummary函數寫出程式碼如下:
data %>% tbl_summary(
by=Gender,statistic = all_continuous() ~ "{mean} ({sd})",
) %>% add_p() %>% modify_caption("**Table 1. Please follow Wechat Channel--Codewar**")
可以看到,程式碼基本就1行,add_p是新增分組比較的p值(按需使用),modify_caption是更改表的標題,執行上面的程式碼,即可得到又一張出版級的表格如下(內容和圖3也是一樣的):
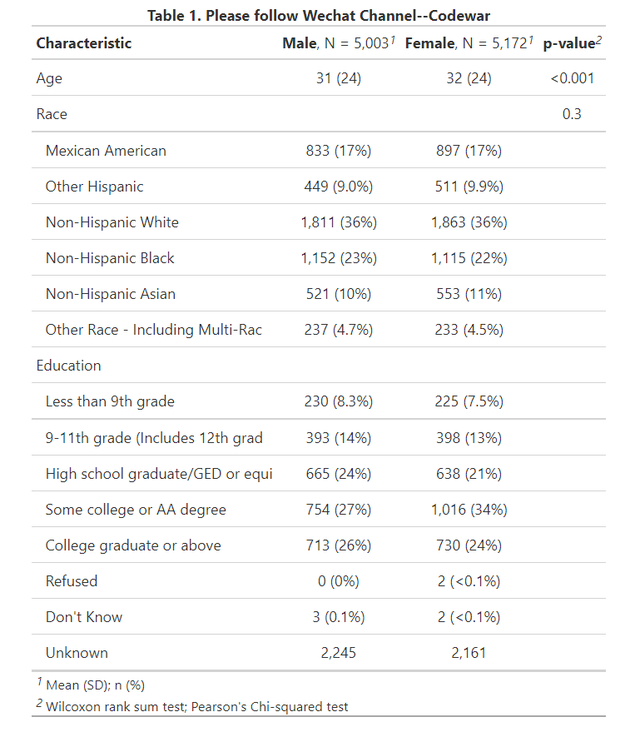
圖3
真棒!這個表格也可以通過write.csv輸出為excel然後直接貼到你的論文中。
再做相關分析
描述統計做完了之後我們有可能會需要做一下各個變數間的兩兩相關,期刊中常見的比較標準的相關結果表示方法如下,變數均值和標準差佔兩列,然後相關矩陣放後面:
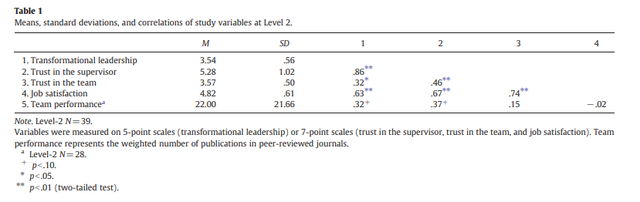
這樣的表格也有十分簡單的做法,大家可以直接使用mlmCorrs這個包,比如對於圖1中的資料,我想拉一個和上圖一樣佈局的結果表格,我只需要直接執行下面的程式碼:
data %>%
select(wordlist:occupats) %>%
mlmCorrs::corstars()便可以得到結果如下,真的是很方便呀:
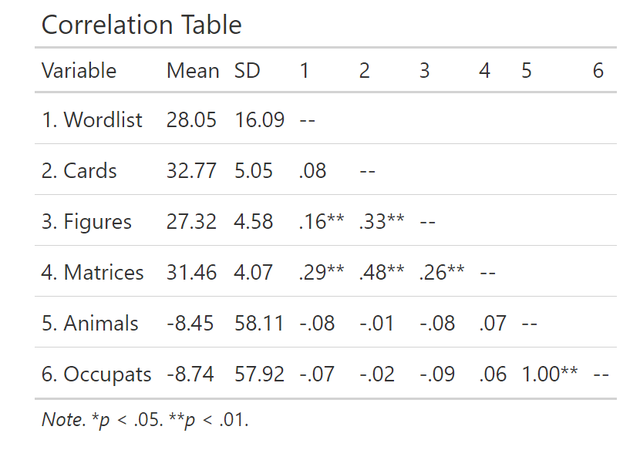
其實在R語言中拉相關的方法很多,但是就是這個好用,最好用。其它的還有ggpairs,還有corrr::correlate()還有Hmisc::rcorr都可以,有興趣的同學可以自己取探索一番!
再做主分析
變數間的相關關係做完之後,大家要做多因素分析了,比如你要做個多元線性迴歸,比如你要做個邏輯斯蒂迴歸,或者做個生存分析,這些分析是你論文中最重要的部分,也是你的主要研究結論的體現。
這兒也給大家展示幾個例子,首先寫個簡單的多元線性迴歸,其餘的直接改相應的主分析函數就行。
方法1:tab_model
依然是圖1中的資料,我現在隨意跑了兩個線性迴歸模型,程式碼如下:
model1 <- lm(cards ~ wordlist, data=data_txt)
model2 <- lm(cards ~ figures, data=data_txt)我想要展示模型的資訊,只需要執行下面的程式碼就可以:
sjPlot::tab_model(model1, model2)得到的結果:
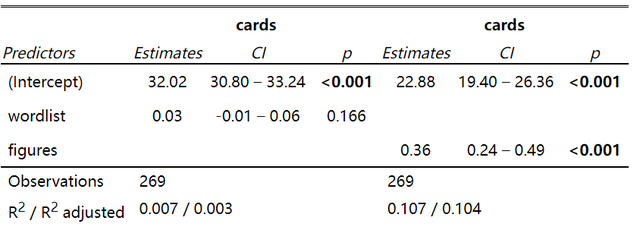
可以看到兩個線性迴歸模型的結果被並列地展示出來了,結果還是挺好的,這裡用到的tab_model當然不止可以可以用到普通的線性迴歸中,像廣義線性模型和混合模型都是可以的。
方法2:gtsummary
剛剛寫了線性迴歸的例子,再給大家看看logistics迴歸和cox迴歸的模型展示,我先用同一批資料擬合一個logistics模型和一個cox模型:
glm(response ~ trt + age + grade, trial, family = binomial) %>%
tbl_regression(exponentiate = TRUE)
coxph(Surv(ttdeath, death) ~ trt + grade + age, trial) %>%
tbl_regression(exponentiate = TRUE)logistics模型的結果輸出如下:
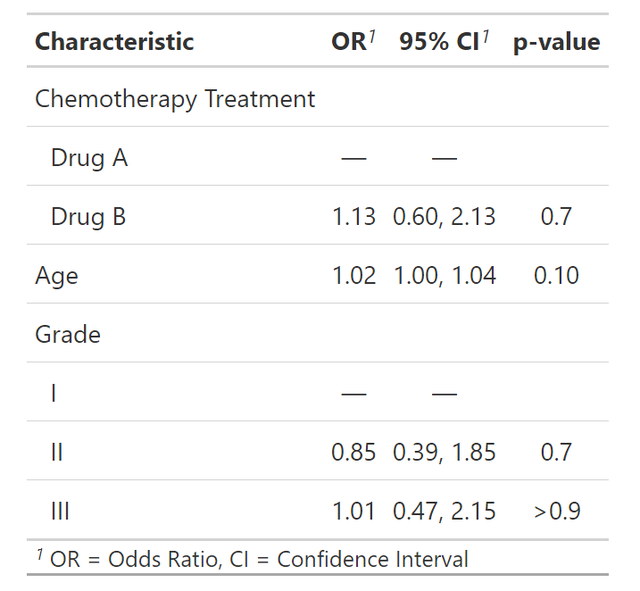
cox模型的結果如下:
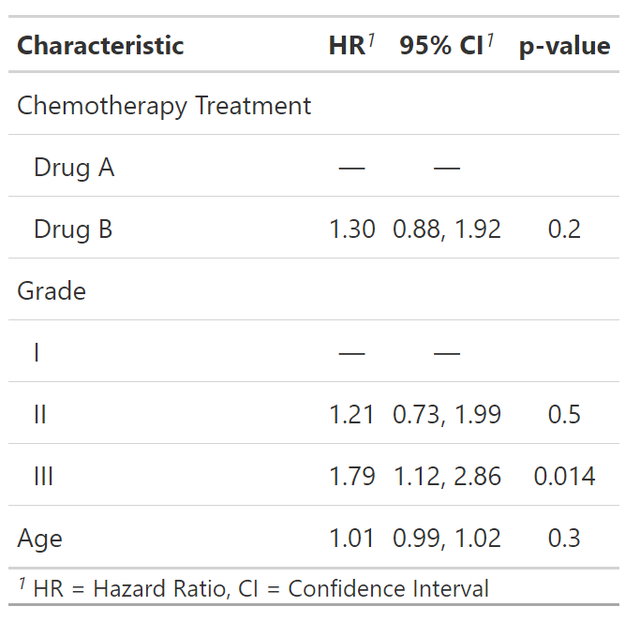
此時我可以用tbl_merge函數將兩個模型合併起來展示(這也是多個模型時的常規展示方法),程式碼如下:
tbl_merge_ex1 <-
tbl_merge(
tbls = list(t1, t2),
tab_spanner = c("**Tumor Response**", "**Time to Death**")
) %>% modify_caption("**關注公眾號喲-Please follow Wechat Channel--Codewar**")執行後輸出結果如下:
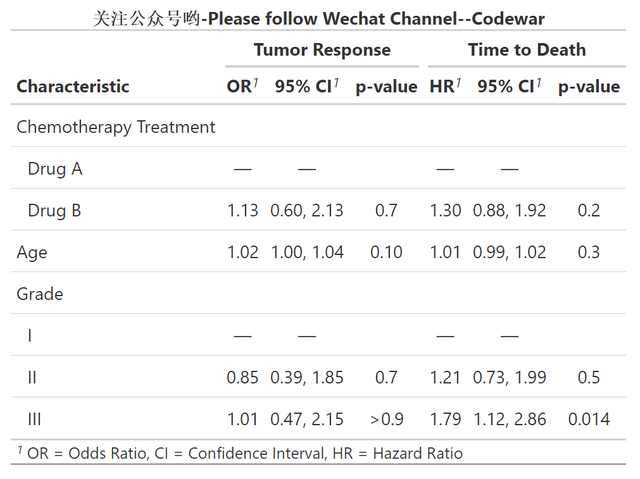
可以看到,同樣的變數,跑了兩個不同的模型,依然可以通過tbl_merge恰當地合併展示出來,很清晰,當然論文中肯定不會這麼用,一般都是模型變數依次新增從而形成幾個模型並排展示,這樣的情況用tbl_merge也是可以的,可以動手試試哈。
小結
今天以假設的資料分析的流程為線,寫了常規流程中的描述統計,相關,迴歸的做法,重點在如何快速地呈現出版級的結果,因為涉及的比較多,寫的例子就比較淺顯了,不過這裡面提到的每一個包都值得大家細細探索。