cuda在ubuntu的安裝使用分享
前言
之前給大家分享過opencv在jetson nano 2gb和ubuntu裝置中使用並且展示了一些臉部辨識等的小demo。但是對於影象處理,使用gpu加速是很常見 .(以下概念介紹內容來自百科和網路其他博主文章)
GPU介紹(從GPU誕生之日起,GPU的設計邏輯與CPU的設計邏輯相差很多。GPU從誕生之日起,它的定位是3D圖形渲染裝置。在設計GPU時從其功能出發,把更多的電晶體用於資料處理。這使得GPU相比CPU有更強的單精度浮點運算能力。人們為了充分利用GPU的效能,使用了很多方法。這)加速處理是比較常見的。
在而GPU加速的軟體實現中我們可能會聽到 opengl opencl cuda這些名詞。下面再給大家分別介紹一下這幾種區別:
OpenGL(英語:Open Graphics Library,譯名:開放圖形庫或者「開放式圖形庫」)是用於渲染2D、3D向量圖形的跨語言、跨平臺的應用程式程式設計介面(API)。這個介面由近350個不同的函數呼叫組成,用來繪製從簡單的圖形位元到複雜的三維景象。而另一種程式介面系統是僅用於Microsoft Windows上的Direct3D。OpenGL常用於CAD、虛擬現實、科學視覺化程式和電子遊戲開發。
OpenCl(是由蘋果(Apple)公司發起,業界眾多著名廠商共同製作的面向異構系統通用目的並行程式設計的開放式、免費標準,也是一個統一的程式設計環境。便於軟體開發人員為高效能運算伺服器、桌面計算系統、手持裝置編寫高效輕便的程式碼,而且廣泛適用於多核心處理器(CPU)、圖形處理器(GPU)、Cell型別架構以及數位訊號處理器(DSP)等其他並行處理器,在遊戲、娛樂、科研、醫療等各種領域都有廣闊的發展前景。)
從2007年以後,基於CUDA和OpenCL這些被設計成具有近似於高階語言的語法特性的新GPGPU語言,降低了人們使用GPGPU的難度,平緩了開始時的學習曲線。使得在GPGPU領域,OpenGL中的GLSL逐漸退出了人們的視線。來源:
簡單說OpenCL與OpenGL一樣,都是基於硬體API的程式設計。OpenGL是針對圖形的,而OpenCL則是針對平行計算的API,而針對平行計算下面還有一個cuda。
CUDA(Compute Unified Device Architecture,統一計算架構)是由英偉達NVIDIA所推出的一種整合技術,是該公司對於GPGPU的正式名稱。透過這個技術,使用者可利用NVIDIA的GeForce 8以後的GPU和較新的Quadro GPU進行計算。亦是首次可以利用GPU作為C-編譯器的開發環境。NVIDIA行銷的時候,往往將編譯器與架構混合推廣,造成混亂。實際上,CUDA可以相容OpenCL或者自家的C-編譯器。無論是CUDA C-語言或是OpenCL,指令最終都會被驅動程式轉換成PTX程式碼,交由顯示核心計算。
通俗的介紹,cuda是nvidia公司的生態,它前者是配備完整工具包、針對單一供應商(NVIDIA)的成熟的開發平臺,opencl是一個開源的標準。
CUDA是NVIDIA GPU程式語言, OpenCL是異構計算庫。CUDA和C++雖然都可以用nvcc編譯,但C++只能在CPU上跑,CUDA只能在GPU上跑;而OpenCL並不侷限於某個計算裝置,旨在將同樣的任務通過其提供的抽象介面在多種硬體上執行(CPU,GPU,FPGA,etc)
跨平臺性和通用性上OpenCL佔有很大優勢(這也是很多National Laboratory使用OpenCL進行科學計算的最主要原因)。OpenCL支援包括ATI,NVIDIA,Intel,ARM在內的多類處理器,並能支援執行在CPU的並行程式碼,同時還獨有Task-Parallel Execution Mode,能夠更好的支援Heterogeneous Computing。這一點是僅僅支援資料級並行並僅能在NVIDIA眾核處理器上執行的CUDA無法做到的。
在開發者友好程度CUDA在這方面顯然受更多開發者青睞。原因在於其統一的開發套件(CUDA Toolkit, NVIDIA GPU Computing SDK以及NSight等等)、非常豐富的庫(cuFFT, cuBLAS, cuSPARSE, cuRAND, NPP, Thrust)以及NVCC(NVIDIA的CUDA編譯器)所具備的PTX(一種SSA中間表示,為不同的NVIDIA GPU裝置提供一套統一的靜態ISA)程式碼生成、離線編譯等更成熟的編譯器特性。相比之下,使用OpenCL進行開發,只有AMD對OpenCL的驅動相對成熟。 來源
今天的主題來自介紹cuda的使用,前面這部分概念性的介紹(來源都是網路,只有一小部分是自己寫的)只是幫助大家好理解今天要使用的cuda,那麼開始進入正題。(自己本身的電腦帶NVIDIA的顯示卡,以及手裡面有jetson nano的NVIDIA板卡,所以才使用cuda,其他朋友使用請注意自己手中的硬體是否有NVIDIA的顯示卡)。
接下來,我大致分為三個部分介紹,一、cuda平行計算原理介紹 ,二、cuda環境安裝和直接使用,三、opencv中cuda安裝和使用
作者:良知猶存
轉載授權以及圍觀:歡迎關注微信公眾號:羽林君
或者新增作者個人微信:become_me
cuda平行計算原理介紹
GPU背景介紹
GPU裡有很多Compute Unit(計算單元), 這些單元是由專門的處理邏輯, 很多register, 和L1 cache 組成. Memory access subsystem 把GPU 和RAM 連起來(通常是個L2 cache). Threads 以SIMT的形式執行: 多個thread共用一個instruction unit. 對NV GPU來說, 32 thread 組成一個warps, 對AMD GPU 來說, 64 threads 叫做一個wave fronts. 本文只使用warp的定義. 想達到最高速度, 一定要討論SIMT, 因為它影響著memory access 也會造成code的序列化(serialization, parallelism的反面)
kernel function裡會指出哪些code由一條thread處理, host program會決定多少條thread來處理一個kernel. 一個work group 裡的thread可以通過barrier synchronization, 共用L1 cache 來互相協力. 再由compute unit處理這些work group. 能同時被conpute unit 執行的work group數量有限, 所以很多得等到其他完成之後再執行. 需要處理的work group的size和數量還有最大並行數量被稱為kernel的execution configuration(執行設定).
kernel 的佔用率就是指同時執行的thread數量除以最大數量. 傳統建議就是提升這個佔用率來獲得更好的效能, 但也有一些其他因素比如ILP, MLP, instruction latencies, 也很關鍵.內容來源
- GPU架構特點
首先我們先談一談序列計算和平行計算。我們知道,高效能運算的關鍵利用多核處理器進行平行計算。
當我們求解一個計算機程式任務時,我們很自然的想法就是將該任務分解成一系列小任務,把這些小任務一一完成。在序列計算時,我們的想法就是讓我們的處理器每次處理一個計算任務,處理完一個計算任務後再計算下一個任務,直到所有小任務都完成了,那麼這個大的程式任務也就完成了。
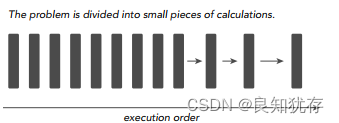
序列計算的缺點非常明顯,如果我們擁有多核處理器,我們可以利用多核處理器同時處理多個任務時,而且這些小任務並沒有關聯關係(不需要相互依賴,比如我的計算任務不需要用到你的計算結果),那我們為什麼還要使用序列程式設計呢?為了進一步加快大任務的計算速度,我們可以把一些獨立的模組分配到不同的處理器上進行同時計算(這就是並行),最後再將這些結果進行整合,完成一次任務計算。下圖就是將一個大的計算任務分解為小任務,然後將獨立的小任務分配到不同處理器進行平行計算,最後再通過序列程式把結果彙總完成這次的總的計算任務。
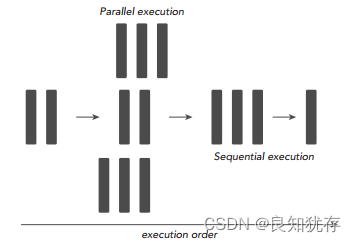
所以,一個程式可不可以進行平行計算,關鍵就在於我們要分析出該程式可以拆分出哪幾個執行模組,這些執行模組哪些是獨立的,哪些又是強依賴強耦合的,獨立的模組我們可以試著設計平行計算,充分利用多核處理器的優勢進一步加速我們的計算任務,強耦合模組我們就使用序列程式設計,利用序列+並行的程式設計思路完成一次高效能運算。
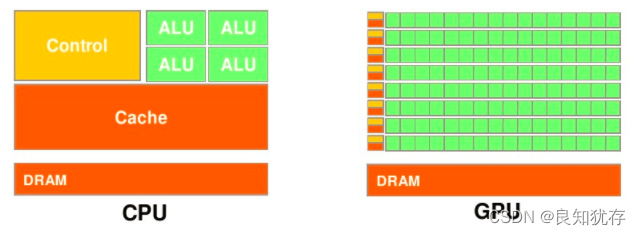
接下來我們談談CPU和GPU有什麼區別,他們倆各自有什麼特點,我們在談並行、序列計算時多次談到「多核」的概念,現在我們先從「核」的角度開始這個話題。首先CPU是專為順序序列處理而優化的幾個核心組成。而GPU則由數以千計的更小、更高效的核心組成,這些核心專門為同時處理多工而設計,可高效地處理並行任務。也就是,CPU雖然每個核心自身能力極強,處理任務上非常強悍,無奈他核心少,在平行計算上表現不佳;反觀GPU,雖然他的每個核心的計算能力不算強,但他勝在核心非常多,可以同時處理多個計算任務,在平行計算的支援上做得很好。
GPU和CPU的不同硬體特點決定了他們的應用場景,CPU是計算機的運算和控制的核心,GPU主要用作圖形影象處理。影象在計算機呈現的形式就是矩陣,我們對影象的處理其實就是操作各種矩陣進行計算,而很多矩陣的運算其實可以做並行化,這使得影象處理可以做得很快,因此GPU在圖形影象領域也有了大展拳腳的機會。下圖表示的就是一個多GPU計算機硬體系統,可以看出,一個GPU記憶體就有很多個SP和各類記憶體,這些硬體都是GPU進行高效平行計算的基礎。
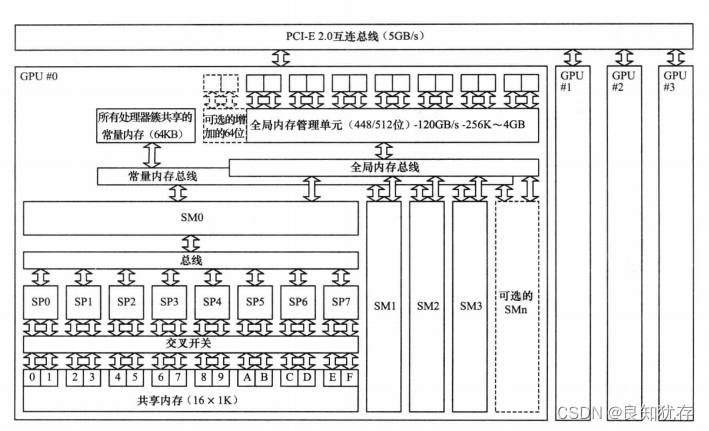
現在再從資料處理的角度來對比CPU和GPU的特點。CPU需要很強的通用性來處理各種不同的資料型別,比如整型、浮點數等,同時它又必須擅長處理邏輯判斷所導致的大量分支跳轉和中斷處理,所以CPU其實就是一個能力很強的夥計,他能把很多事處理得妥妥當當,當然啦我們需要給他很多資源供他使用(各種硬體),這也導致了CPU不可能有太多核心(核心總數不超過16)。而GPU面對的則是型別高度統一的、相互無依賴的大規模資料和不需要被打斷的純淨的計算環境,GPU有非常多核心(費米架構就有512核),雖然其核心的能力遠沒有CPU的核心強,但是勝在多, 在處理簡單計算任務時呈現出「人多力量大」的優勢,這就是平行計算的魅力。內容來源
整理一下兩者特點就是:
- 1.CPU:擅長流程控制和邏輯處理,不規則資料結構,不可預測儲存結構,單執行緒程式,分支密集型演演算法
- 2.GPU:擅長資料平行計算,規則資料結構,可預測儲存模式
CUDA記憶體型別:
每個執行緒擁有自己的 register暫存器 and loacal memory 區域性記憶體
每個執行緒塊擁有一塊 shared memory 共用記憶體
所有執行緒都可以存取 global memory 全域性記憶體
還有,可以被所有執行緒存取的
唯讀記憶體:
constant memory (常數內容) and texture memory
a. 暫存器Register
暫存器是GPU上的快取記憶體器,其基本單元是暫存器檔案,每個暫存器檔案大小為32bit.
Kernel中的區域性(簡單型別)變數第一選擇是被分配到Register中。
特點:每個執行緒私有,速度快。
b. 區域性記憶體 local memory
當register耗盡時,資料將被儲存到local memory。
如果每個執行緒中使用了過多的暫存器,或宣告了大型結構體或陣列,
或編譯器無法確定陣列大小,執行緒的私有資料就會被分配到local memory中。
特點:每個執行緒私有;沒有快取,慢。
注:在宣告區域性變數時,儘量使變數可以分配到register。如:
unsigned int mt[3];
改為: unsigned int mt0, mt1, mt2;
c. 共用記憶體 shared memory
可以被同一block中的所有執行緒讀寫
特點:block中的執行緒共有;存取共用記憶體幾乎與register一樣快.
d. 全域性記憶體 global memory
特點:所有執行緒都可以存取;沒有快取
e. 常數記憶體constant memory
用於儲存存取頻繁的唯讀引數
特點:唯讀;有快取;空間小(64KB)
注:定義常數記憶體時,需要將其定義在所有函數之外,作用於整個檔案
f. 紋理記憶體 texture memory
是一種唯讀記憶體,其中的資料以一維、二維或者三維陣列的形式儲存在視訊記憶體中。
在通用計算中,其適合實現影象處理和查詢,對大量資料的隨機存取和非對齊存取也有良好的加速效果。
特點:具有紋理快取,唯讀。
threadIdx,blockIdx, blockDim, gridDim之間的區別與聯絡
在啟動kernel的時候,要通過指定gridsize和blocksize才行
dim3 gridsize(2,2); // 2行*2列*1頁 形狀的執行緒格,也就是說 4個執行緒塊
gridDim.x,gridDim.y,gridDim.z相當於這個dim3的x,y,z方向的維度,這裡是2*2*1。
序號從0到3,且是從上到下的順序,就是說是下面的情況:
具體到 執行緒格 中每一個 執行緒塊的 id索引為:
grid 中的 blockidx 序號標註情況為: 0 2
1 3
dim3 blocksize(4,4); // 執行緒塊的形狀,4行*4列*1頁,一個執行緒塊內部共有 16個執行緒
blockDim.x,blockDim.y,blockDim.z相當於這個dim3的x,y,z方向的維度,
這裡是4*4*1.序號是0-15,也是從上到下的標註:
block中的 threadidx 序號標註情況 0 4 8 12
1 5 9 13
2 6 10 14
3 7 11 15
1. 1維格子,1維執行緒塊,N個執行緒======
實際的執行緒id tid = blockidx.x * blockDim.x + threadidx.x
塊id 0 1 2 3
執行緒id 0 1 2 3 4
2. 1維格子,2D維執行緒塊
塊id 1 2 3
執行緒id 0 2
1 3
塊id 塊執行緒總數
實際的執行緒id tid = blockidx.x * blockDim.x * blockDim.y +
當前執行緒行數 每行執行緒數
threadidx.y * blockDim.x +
當前執行緒列數
threadidx.x
更加詳細資訊,大家可以參考這兩篇文章:
https://www.cnblogs.com/skyfsm/p/9673960.html
https://github.com/Ewenwan/ShiYanLou/tree/master/CUDA
安裝cuda使用環境
cuda使用中 首先我們直接安裝CUDA toolkit (cuDNN是用於設定深度學習使用,本次我沒有使用到,就是下載cuDNN的庫放置到對應的連結庫目錄,大家可以自行去搜尋安裝),然後直接呼叫cuda的api進行一些計算的測試,還有是可以安裝opencv中的cuda介面,通過opencv中的cuda使用。
直接使用cuda
直接安裝CUDA ,首先需要下載安裝包
- CUDA toolkit(toolkit就是指工具包)
- cuDNN 注:cuDNN 是用於設定深度學習使用(這次我沒有使用就沒有下載)
官方教學
CUDA:Installation Guide Windows :: CUDA Toolkit Documentation(連結)

- 注:按照自己版本去檢視資料,開啟連結後,右上角處有一個older選項,大家可以選擇自己對應的版本檔案。
cuDNN:Installation Guide :: NVIDIA Deep Learning cuDNN Documentation(連結)
安裝cuda要注意一個版本匹配問題,就是我們不同的顯示卡是對應不同的驅動。所以第一步就是檢視顯示卡驅動版本,我使用的是Ubuntu,和window安裝有些區別。第一如果我們安裝過自己的顯示卡驅動, 使用 nvidia-smi命令檢視支援的cuda版本 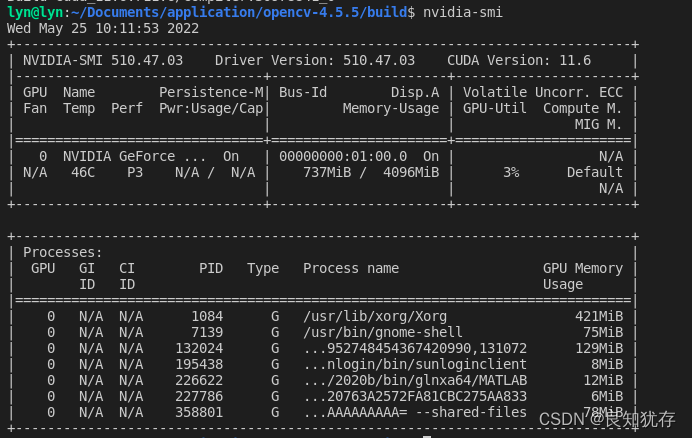
如果沒有安裝可以選擇ubuntu的bash介面搜尋附加驅動,然後進行安裝。參考
當然由於ubuntu本身也有不同的版本支援,大家也可以直接到驅動的官網進行查詢,裡面有專門的ubuntu20適配版本選項,其中由於我使用的是ubuntu20,而CUDA11.0以上版本才支援Ubuntu20.04,所以直接就選擇了最新的。
官方地址:https://developer.nvidia.com/cuda-toolkit-archive

選擇CUDA Toolkit 11.6.0之後,裡面有幾種選項,分別是本地deb安裝、網路下載安裝和可執行檔案安裝,我因為網路不太順暢原因選擇了第一個選項,最後下載下載下來的deb檔案有2.7G,大家做好下載大檔案的準備。
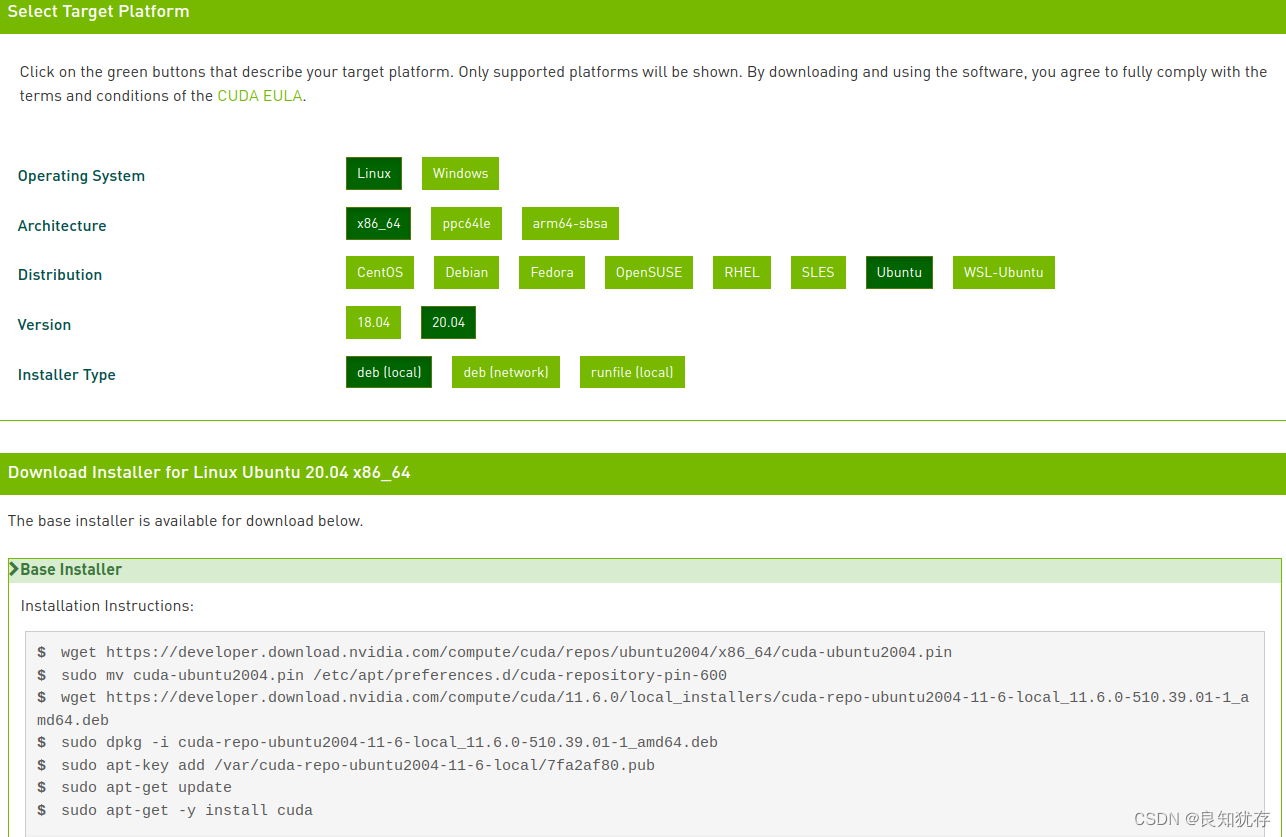
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-ubuntu2004.pin
sudo mv cuda-ubuntu2004.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/11.6.0/local_installers/cuda-repo-ubuntu2004-11-6-local_11.6.0-510.39.01-1_amd64.deb
sudo dpkg -i cuda-repo-ubuntu2004-11-6-local_11.6.0-510.39.01-1_amd64.deb
sudo apt-key add /var/cuda-repo-ubuntu2004-11-6-local/7fa2af80.pub
sudo apt-get update
sudo apt-get -y install cuda
這時候cuda就安裝好了,接下來就是使用了。
大家可以使用cuda命令,tab就可以出現對應的命令,或者使用nvcc編譯對應的cuda的.cu檔案進行驗證。 
大家可以通過以下連結裡面的檔案指導寫符合自己需要的功能: https://docs.nvidia.com/cuda/archive/11.6.0/cuda-c-programming-guide/index.html
下面官網API檔案目錄:
Versioned Online Documentation

官方範例: 
接下來開始進行cuda的使用:輸出hello world
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include <iostream>
using namespace std;
__global__ void kernel(void) { //帶有了__global__這個標籤,表示這個函數是在GPU上執行
printf("hello world gpu \n");
}
int main() {
kernel<<<1, 1>>>();//呼叫除了常規的引數之外,還增加了<<<>>>修飾,其中第一個1,代表執行緒格里只有一個執行緒塊;第二個1,代表一個執行緒塊裡只有一個執行緒。
cudaError_t cudaStatus;
cudaStatus = cudaDeviceSynchronize();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceSynchronize returned error code %d after launching addKernel!\n", cudaStatus);
}
return 0;
}
這裡面記得使用cudaDeviceSynchronize函數,等待GPU完成運算。如果不加的話,你將看不到printf的輸出
編譯選項 nvcc test_cuda_hello.cu
這個程式中GPU呼叫的函數和普通的C程式函數的區別
- 函數的呼叫除了常規的引數之外,還增加了<<<>>>修飾。
- 呼叫通過<<<引數1,引數2>>>,用於說明核心函數中的執行緒數量,以及執行緒是如何組織的。
- 以執行緒格(Grid)的形式組織,每個 執行緒格 由若干個 執行緒塊(block)組成,
- 而每個執行緒塊又由若干個執行緒(thread)組成。
- 是以block為單位執行的。
接下來,我們再來使用一個demo,使用一個簡單的計算,將其放置於GPU進行計算
// 輸入變數 以指標方式傳遞===================================
#include <iostream>
#include <cuda.h>
#include <cuda_runtime.h>
#include <stdio.h>
// 輸入變數 全部為指標 類似資料的參照
__global__ void gpuAdd(int *d_a, int *d_b, int *d_c)
{
*d_c = *d_a + *d_b;
}
int main(void)
{
// CPU變數
int h_a,h_b, h_c;
// CPU 指標 變數 指向 GPU資料地址
int *d_a,*d_b,*d_c;
// 初始化CPU變數
h_a = 1;
h_b = 4;
// 分配GPU 變數記憶體
cudaMalloc((void**)&d_a, sizeof(int));
cudaMalloc((void**)&d_b, sizeof(int));
cudaMalloc((void**)&d_c, sizeof(int));
// 輸入變數 CPU 拷貝到 GPU 右 到 左
cudaMemcpy(d_a, &h_a, sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(d_b, &h_b, sizeof(int), cudaMemcpyHostToDevice);
// 呼叫核函數
gpuAdd << <1, 1 >> > (d_a, d_b, d_c);
// 拷貝GPU資料結果 d_c 到 CPU變數
cudaMemcpy(&h_c, d_c, sizeof(int), cudaMemcpyDeviceToHost);
printf("Passing Parameter by Reference Output: %d + %d = %d\n", h_a, h_b, h_c);
// 清理GPU記憶體 Free up memory
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
return 0;
}
CUDA程式碼中比較重要的函數:
cudaMalloc 與C語言中的malloc函數一樣,只是此函數在GPU的記憶體你分配記憶體。
addKernel<<<1, size>>>
這裡就涉及了GPU和主機之間的記憶體交換了,cudaMalloc是在GPU的記憶體裡開闢一片空間, 然後通過操作之後,這個記憶體裡有了計算出來內容,再通過cudaMemcpy這個函數把內容從GPU複製出來。可以在裝置程式碼中使用cudaMalloc()分配的指標進行裝置記憶體讀寫操作;cudaMalloc()分配的指標傳遞給在裝置上執行的函數;但是不可以在主機程式碼中使用cudaMalloc()分配的指標進行主機記憶體讀寫操作(即不能進行解除參照)。 cudaFree 與c語言中的free()函數一樣,只是此函數釋放的是cudaMalloc()分配的記憶體。
cudaMemcpy 與c語言中的memcpy函數一樣,只是此函數可以在主機記憶體和GPU記憶體之間互相拷貝資料。此外與C中的memcpy()一樣,以同步方式執行,即當函數返回時,複製操作就已經完成了,並且在輸出緩衝區中包含了複製進去的內容。 相應的有個非同步方式執行的函數cudaMemcpyAsync().
該函數第一個引數是目的指標,第二個引數是源指標,第三個引數是複製記憶體的大小,第四個引數告訴執行時源指標,這是一個什麼型別的指標,即把記憶體從哪裡複製到哪裡。第四個引數可以選用以下的形式:參考
- cudaMemcpyHostToDevice:從主機複製到裝置;
- cudaMemcpyDeviceToHost:從裝置複製到主機;
- cudaMemcpyDeviceToDevice:從裝置複製到裝置;
- cudaMemcpyHostToHost:從主機複製到主機;
呼叫的核函數前面已經介紹過,此處不再贅述。還有其他函數大家可以自行參考官網的API介紹。
大家也可以看《GPU高效能程式設計CUDA實戰》這本書
opencv中cuda庫安裝與使用
除了直接使用cuda,opencv也有相應的cuda的庫,呼叫cuda從而在opencv實現gpu加速功能。這就需要安裝CUDA,並從OpenCV編譯安裝時候安裝好對應cv::cuda庫。
首先要使用cv::cuda裡面對應的cv::cuda::add 、cv::cuda::multiply,我們需要安裝opencv要配合OpenCV Contrib庫。
OpenCV Contrib庫是非官方的第三方開發擴充庫。通過這個庫,我們能使用如dnn、相機標註、3D成像、ArUco、物體追蹤,甚至是需付費的SURF、SIFT特徵點提取演演算法
安裝OpenCV Contrib也是需要和opencv進行版本匹配的。大家可以在下面位置進行對應版本下載: 
- contrib庫:https://github.com/opencv/opencv_contrib/tags
- opencv版本:https://opencv.org/releases.html
對與我個人而言,opencv版本是 4.4.5
$ pkg-config opencv4 --modversion
4.4.5
下載好對應的opencv和opencv_contrib庫,開始進行編譯,和之前單獨opencv編譯類似,解壓下載好的檔案,然後在opencv建立一個build目錄,在裡面進行cmake 編譯。
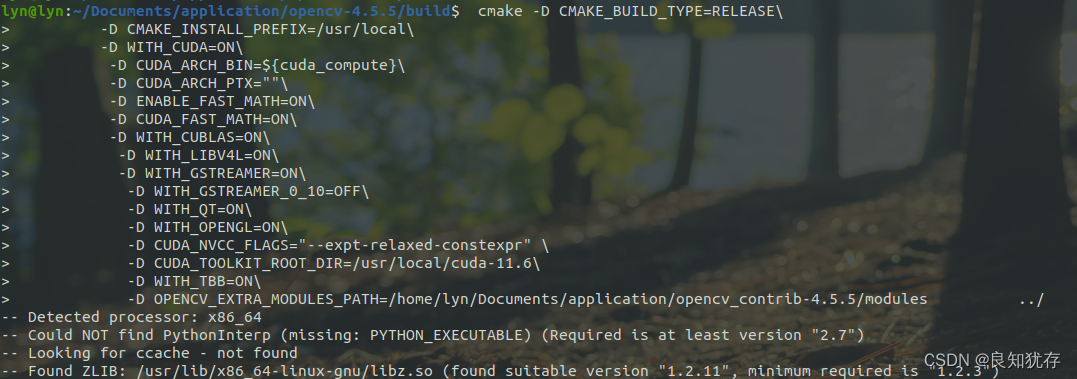
在這裡給大家在註解一些相關選項的含義:
cmake -D CMAKE_BUILD_TYPE=Release\
-D ENABLE_CXX11=ON\
-D CMAKE_INSTALL_PREFIX=/usr/local\
-D WITH_CUDA=ON\
-D CUDA_ARCH_BIN=${cuda_compute}\
-D CUDA_ARCH_PTX=""\
-D ENABLE_FAST_MATH=ON\
-D CUDA_FAST_MATH=ON\
-D WITH_CUBLAS=ON\
-D WITH_LIBV4L=ON\
-D WITH_GSTREAMER=ON\
-D WITH_GSTREAMER_0_10=OFF\
-D WITH_QT=ON\
-D WITH_OPENGL=ON\
-D CUDA_NVCC_FLAGS="--expt-relaxed-constexpr" \
-D CUDA_TOOLKIT_ROOT_DIR=/usr/local/cuda-11.6\
-D WITH_TBB=ON\
-D OPENCV_EXTRA_MODULES_PATH=/home/lyn/Documents/application/opencv_contrib-4.5.5/modules ../
-
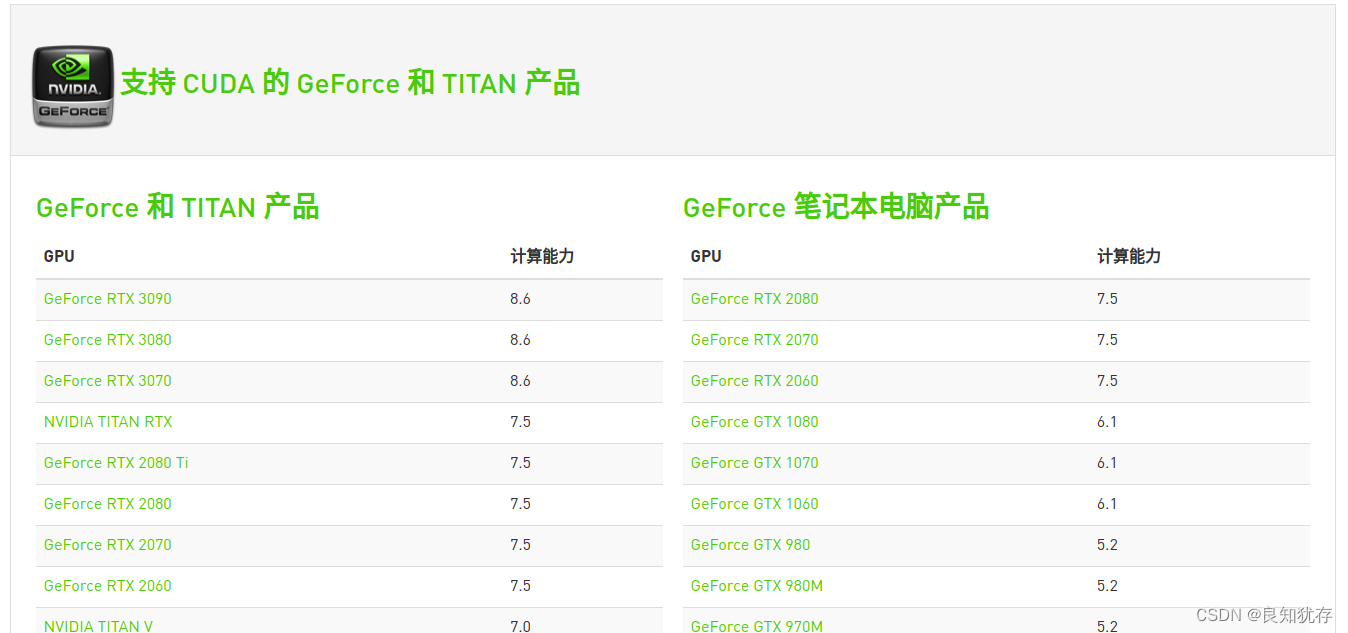
CUDA_ARCH_BIN=${cuda_compute} 顯示卡算力,大家可以對照我最後給算力查詢自行查詢,也可以進行系統自己查詢匹配版本。
-
WITH_QT=ON\ 這是是QT的編譯選項 大家可以按照自己需要選擇是否用QT進行編譯開與關。
-
CUDA_TOOLKIT_ROOT_DIR 這是自己電腦安裝的cuda 版本
-
OPENCV_EXTRA_MODULES_PATH=/home/lyn/Documents/application/opencv_contrib-4.5.5/modules 這是解壓好後的opencv_contrib目錄
安裝時候可能會遇到如下問題:
In file included from /home/lyn/Documents/application/opencv-4.5.5/build/modules/python_bindings_generator/pyopencv_custom_headers.h:7,
from /home/lyn/Documents/application/opencv-4.5.5/modules/python/src2/cv2.cpp:88:
/home/lyn/Documents/application/opencv_contrib-4.5.5/modules/phase_unwrapping/misc/python/pyopencv_phase_unwrapping.hpp:2:13: error: ‘phase_unwrapping’ in namespace ‘cv’ does not name a type
2 | typedef cv::phase_unwrapping::HistogramPhaseUnwrapping::Params HistogramPhaseUnwrapping_Params;

開啟-D ENABLE_CXX11=ON 開啟C++11的選項 (這就是上面命令使用C++11的原因)
最後編譯成功:
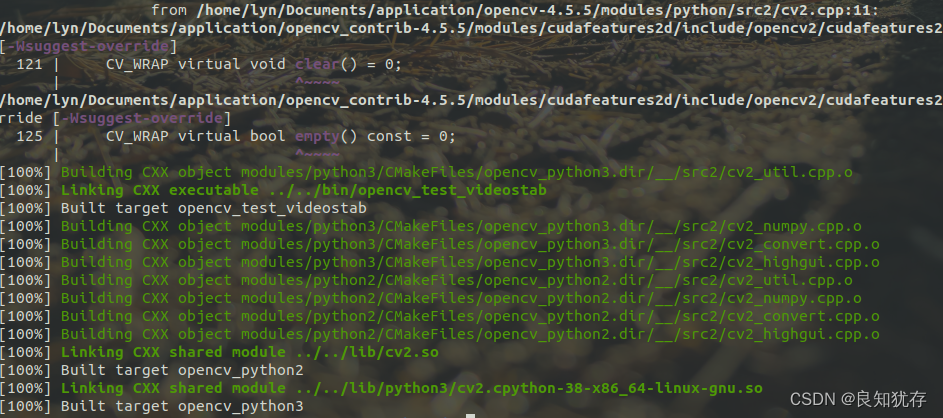
sudo make install這個時候opencv中的cuda庫就安裝好了
介紹一個簡單例子:
CMakeLists.txt檔案
# 宣告要求的 cmake 最低版本
cmake_minimum_required( VERSION 2.8 )
# 宣告一個 cmake 工程
project(opencv_cuda)
# 設定編譯模式
set( CMAKE_BUILD_TYPE "Debug" )
set( CMAKE_CXX_FLAGS "-std=c++11")
#新增OPENCV庫
find_package(OpenCV REQUIRED)
#新增OpenCV標頭檔案
include_directories(${OpenCV_INCLUDE_DIRS})
#顯示OpenCV_INCLUDE_DIRS的值
message(${OpenCV_INCLUDE_DIRS})
add_executable(target test_cuda_cv.cpp)
# 將庫檔案連結到可執行程式上
target_link_libraries(target ${OpenCV_LIBS} )
test_cuda_cv.cpp檔案
#include <iostream>
#include "opencv2/opencv.hpp"
#include <opencv2/core/cuda.hpp>
#include <opencv2/cudaarithm.hpp>
#include <opencv2/core/version.hpp>
int main (int argc, char* argv[])
{
//Read Two Images
cv::Mat h_img1 = cv::imread( "/home/lyn/Documents/work-data/test_code/opencv/learn_code/"
"opencv_tutorial_data-master/images/sp_noise.png");
cv::Mat h_img2 = cv::imread( "/home/lyn/Documents/work-data/test_code/opencv/learn_code/"
"opencv_tutorial_data-master/images/sp_noise.png");
// cv::Mat h_img2 = cv::imread("/home/lyn/Documents/work-data/test_code/opencv/learn_code/c++/build/filter_line.png");
// cv::namedWindow( "1", cv::WINDOW_FREERATIO);
// cv::imshow("1",h_img1);
// cv::namedWindow( "2", cv::WINDOW_FREERATIO);
// cv::imshow("2",h_img2);
cv::Mat h_result1;
#if 0
// cv::add(h_img1, h_img2,h_result1);//加法操作 api
cv::multiply(h_img1,cv::Scalar(2, 2, 2),h_result1);//乘法操作 api
#else
// 定義GPU資料
cv::cuda::GpuMat d_result1,d_img1, d_img2;
// CPU 到 GPU
d_img1.upload(h_img1);
d_img2.upload(h_img2);
// 呼叫GPU接執行 mat substract
// cv::cuda::add(d_img1, d_img2,d_result1);
cv::cuda::multiply(d_img1,cv::Scalar(2, 2, 2),d_result1);//乘法操作 api
// gpu 結果 到 cpu
d_result1.download(h_result1);
#endif
// 顯示,儲存
// cv::namedWindow( "Image1", cv::WINDOW_FREERATIO);
cv::imshow("Image1 ", h_img1);
// cv::namedWindow( "Image2", cv::WINDOW_FREERATIO);
cv::imshow("Image2 ", h_img2);
// cv::namedWindow( "Result_Subtraction", cv::WINDOW_FREERATIO);
cv::imshow("Result_Subtraction ", h_result1);
cv::imwrite("/home/lyn/Documents/work-data/test_code/opencv/learn_code/c++/result_add.png", h_result1);
cv::waitKey();
return 0;
}
大家也可以使用opencv中的其他cuda庫,具體函數使用在下面
官方連結:https://docs.opencv.org/4.5.5/d1/d1e/group__cuda.html
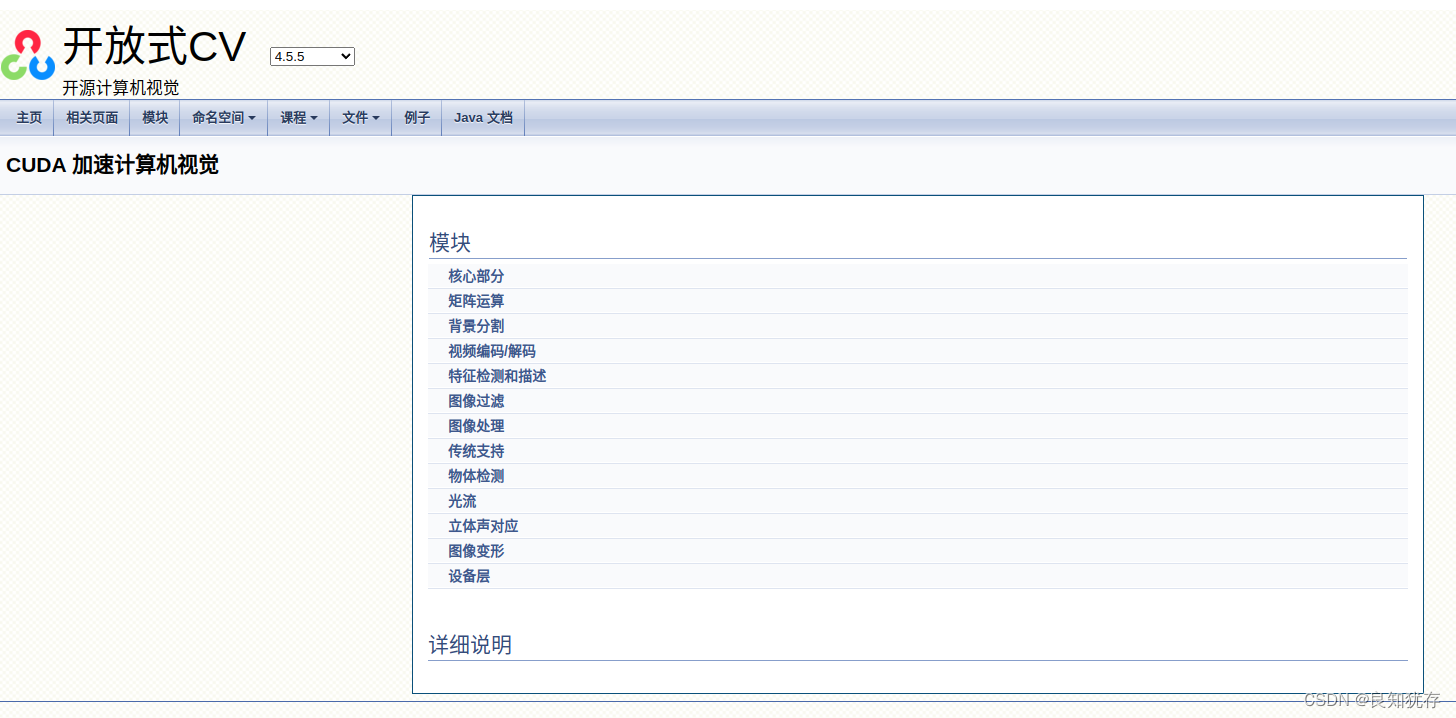
大家可以在當前頁面的版本選擇中,選擇和自己一致的opencv版本,進行參考:
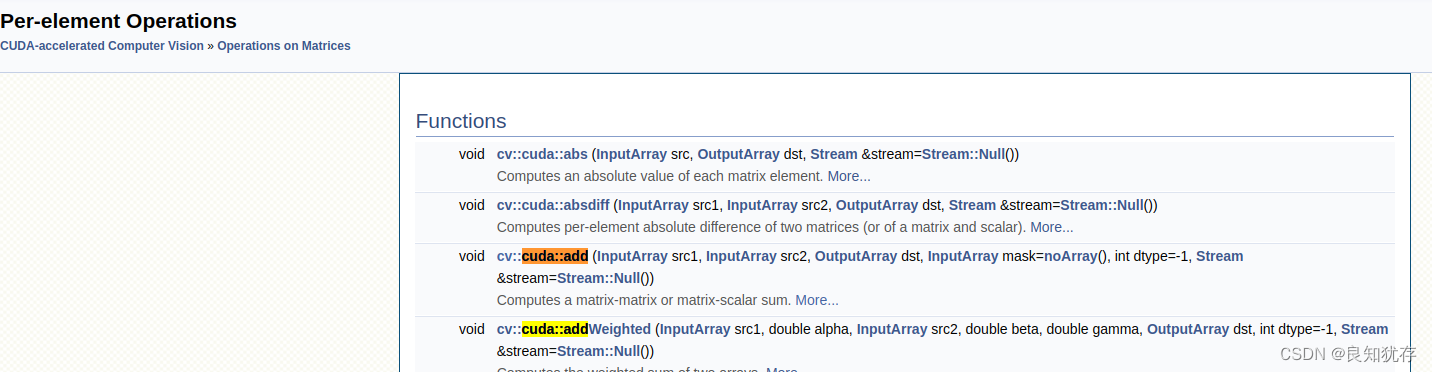
 例如我查詢cv::cuda::add函數,就在 Operations on Matrices -> Per-element Operations
例如我查詢cv::cuda::add函數,就在 Operations on Matrices -> Per-element Operations
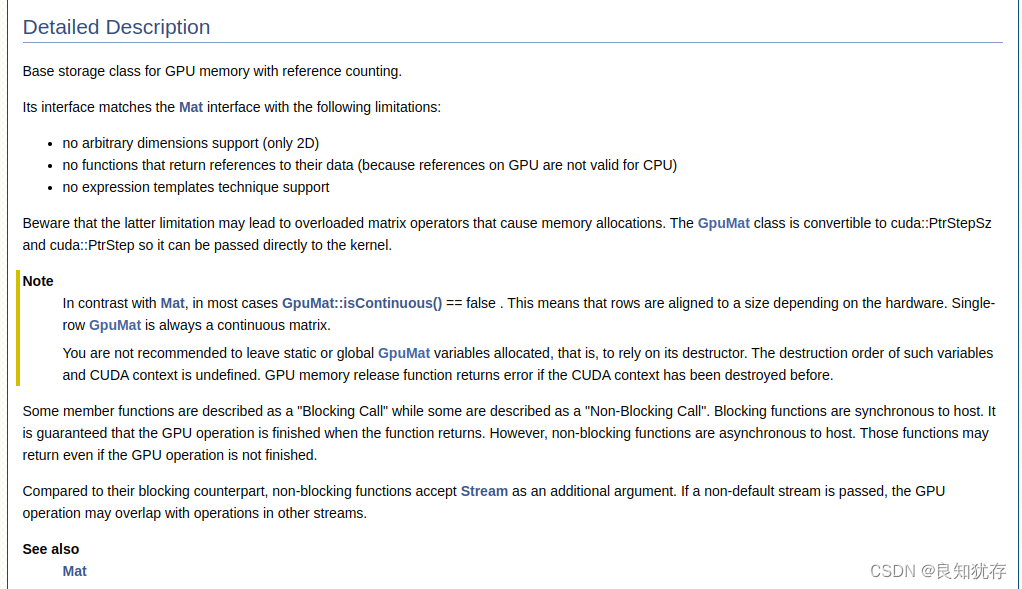
也可以看具體的資料結構含義:例如 cv::cuda::GpuMat
官方的解釋是:具有參照計數的 GPU 記憶體的基本儲存類。GpuMat類似於Mat,不過管理的是GPU記憶體,也就是視訊記憶體。GpuMat和Mat相比,存在以下限制:
- 不支援任意尺寸(只支援2D,也就是二維資料)
- 沒有返回對其資料的參照的函數(因為 GPU 上的參照對 CPU 無效)
- 不支援c++的模板技術。
總之是很方便的,大家可以按照自己需要進行查詢資訊。
附錄:這是官網提供算力表,大家可以參考選擇自己的要求算力的顯示卡。
https://developer.nvidia.com/zh-cn/cuda-gpus
結語
這就是我自己的一些cuda的使用分享,因為篇幅所限,下一篇,我們聊聊cuda實際使用gpu加速和cpu使用的對比,以及它兩使用場景分析。如果大家有更好的想法和需求,也歡迎大家加我好友交流分享哈。
作者:良知猶存,白天努力工作,晚上原創公號號主。公眾號內容除了技術還有些人生感悟,一個認真輸出內容的職場老司機,也是一個技術之外豐富生活的人,攝影、音樂 and 籃球。關注我,與我一起同行。
‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧ END ‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧
推薦閱讀
【3】CPU中的程式是怎麼執行起來的 必讀
本公眾號全部原創乾貨已整理成一個目錄,回覆[ 資源 ]即可獲得。
