可靠的分散式KV儲存產品-ETCD-初見
Paxos
Paxos演演算法是萊斯利·蘭伯特於1990年提出的一種基於訊息傳遞的一致性演演算法。
Raft(Understandable Distributed Consensus)
論文:https://raft.github.io/raft.pdf
演演算法演示網址:http://thesecretlivesofdata.com/raft/
Raft是一種共識演演算法,旨在替代Paxos。
它通過邏輯分離比Paxos更容易理解,但它也被正式證明是安全的,並提供了一些額外的功能。
Raft提供了一種在計算系統叢集中 分佈狀態機 的通用方法,確保叢集中的每個節點都同意一系列相同的狀態轉換。
問題分解
問題分解是將 「複製集中節點一致性" 這個複雜的問題劃分為數個可以被獨立解釋、理解、解決的子問題。
在raft,子問題包括,leader election, log replication,safety,membership changes。
狀態簡化
對演演算法做出一些限制,減少需要考慮的狀態數,使得演演算法更加清晰。
raft會先選舉出leader,leader完全負責replicated log的管理。
leader負責接受所有使用者端更新請求,然後複製到follower節點,並在「安全」的時候執行這些請求。
名詞介紹
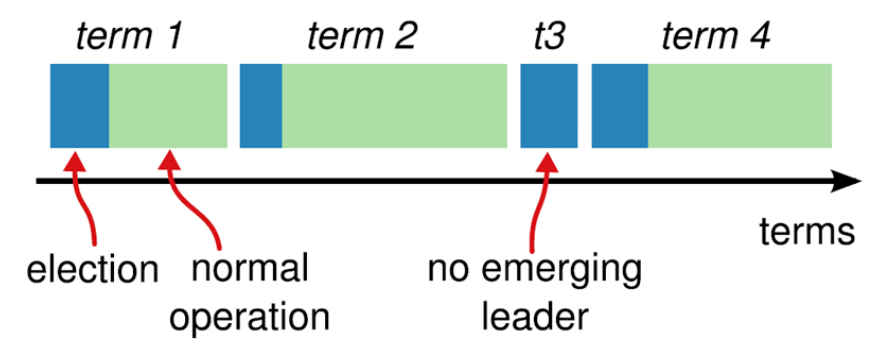
Raft將系統中的角色分為領導者(Leader)、跟從者(Follower)、候選人(Candidate)以及term( Raft演演算法將時間分為一個個的任期)。
Raft要求系統在任意時刻最多隻有一個Leader,正常工作期間只有Leader和Followers。
Raft演演算法角色狀態轉換如下:
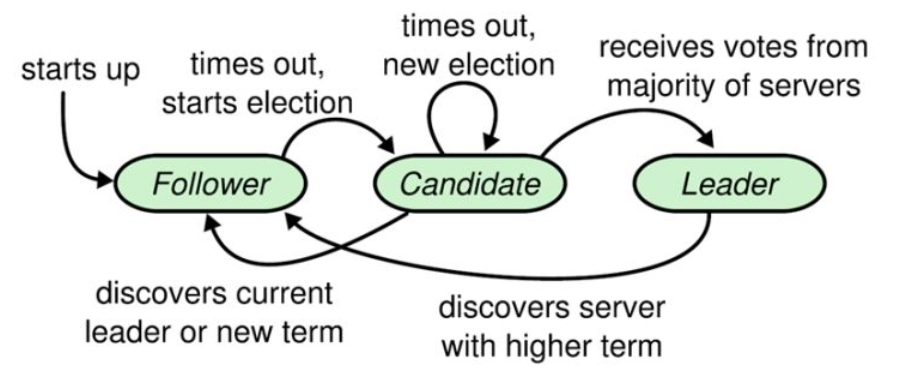
Leader Election
Raft 使用 heartbeat 觸發 Leader 選舉。
當伺服器啟動時,初始化為Follower。Leader向所有Followers週期性傳送heartbeat。
如果Follower在選舉超時時間內沒有收到Leader的heartbeat,就會等待一段隨機的時間後發起一次Leader選舉。
Follower將其當前term加一然後轉換為Candidate。它首先給自己投票並且給叢集中的其他伺服器傳送RequestVote RPC 。
結果有以下三種情況:
- 收到majority的投票(含自己的一票),則贏得選舉,成為leader。
贏得了選舉之後,新的leader會立刻給所有節點發訊息,廣而告之,避免其餘節點觸發新的選舉。
投票者的視角,投票者如何決定是否給一個選舉請求投票呢,有以下約束:
- 在任一任期內,單個節點最多隻能投一票。
- 候選人知道的資訊不能比自己的少(log replication和safety)。
- first-come-first-served 先來先得。
-
被告知別人已當選,那麼自行切換到follower。
-
一段時間內沒有收到majority投票,則保持candidate狀態,重新發出選舉。
平票 split vote 的情況。超時後重新發起選舉。
如果出現平票的情況,那麼就延長了系統不可用的時間(沒有leader是不能處理使用者端寫請求的),
因此raft引入了randomized election timeouts來儘量避免平票情況。
同時,leader-based 共識演演算法中,節點的數目都是奇數個,儘量保證majority的出現。
Log Replication
有了leader,系統應該進入對外工作期了。
使用者端的一切請求來傳送到leader,leader來排程這些並行請求的順序,並且保證leader與followers狀態的一致性。
將這些請求以及執行順序告知followers。leader和followers以相同的順序來執行這些請求,保證狀態一致。
為什麼是紀錄檔?
如何保證所有節點 get the same inputs in the same order,使用replicated log是一個很不錯的注意。
log具有持久化、保序的特點,是大多數分散式系統的基石。
Replicated state machines
共識演演算法的實現一般是基於複製狀態機(Replicated state machines),
何為複製狀態機:相同的初識狀態 + 相同的輸入 = 相同的結束狀態。
因此,可以這麼說,在raft中,leader將使用者端請求(command)封裝到一個個log entry,將這些log entries複製到所有follower節點,然後大家按相同順序應用log entry中的command,則狀態肯定是一致的。
下圖展示了這種log-based replicated state machine
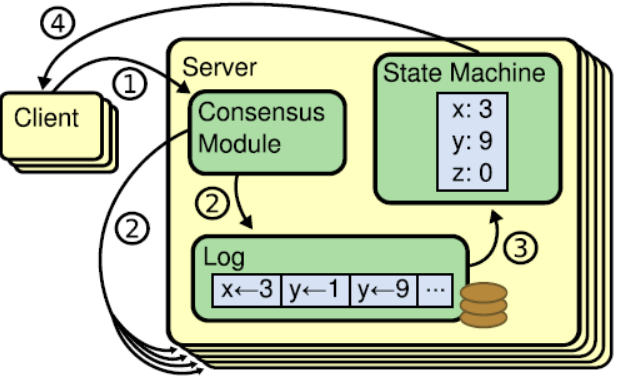
請求完整流程
當系統(leader)收到一個來自使用者端的寫請求,到返回給使用者端,整個過程從leader的視角來看會經歷以下步驟:
- leader append log entry
- leader issue AppendEntries RPC in parallel
- leader wait for majority response
- leader apply entry to state machine
- leader reply to client
- leader notify follower apply log
leader只需要大多數(majority)節點的回覆即可,這樣只要超過一半節點處於工作狀態則系統就是可用的。
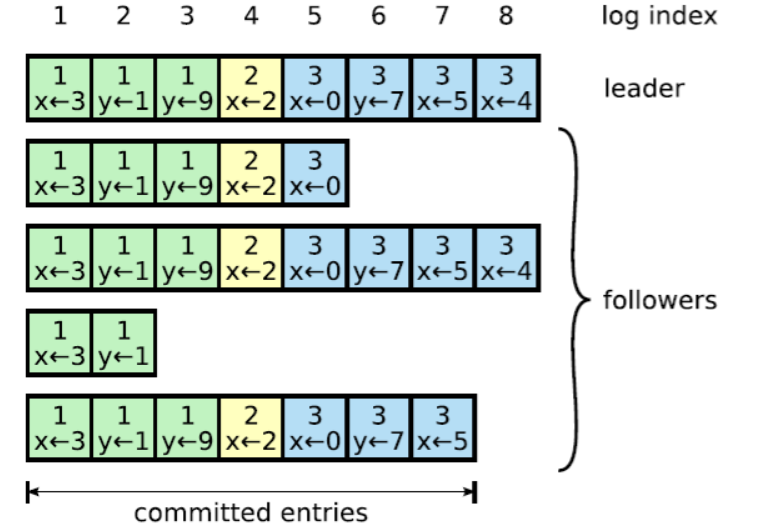
logs由順序編號的log entry組成 ,每個log entry除了包含command,還包含產生該log entry時的leader term。
raft演演算法為了保證高可用,並不是強一致性,而是最終一致性。
leader會不斷嘗試給follower發log entries,直到所有節點的log entries都相同。
在上面的流程中,leader只需要紀錄檔被複制到大多數節點即可向使用者端返回,一旦向用戶端返回成功訊息,那麼系統就必須保證log(其實是log所包含的command)在任何異常的情況下都不會發生回滾。
commit(committed)是指紀錄檔被複制到了大多數節點後紀錄檔的狀態
apply(applied) 是節點將紀錄檔應用到狀態機,真正影響到節點狀態。
…………
etcd
etcd 是 CoreOS 團隊發起的開源專案,目標是構建一個高可用的分散式鍵值(key-value)資料庫。
etcd 內部採用raft協定作為一致性演演算法,etcd 基於 Go 語言實現。
總體架構
Blotddb:BoltDB是相當出名的純Go實現的KV讀寫引擎。
Wal: WAL(Write Ahead Log)預寫紀錄檔,是資料庫系統中常見的一種手段,用於保證資料操作的原子性和永續性。
Snapshot:磁碟快照 (Snapshot)是針對整個磁碟卷冊進行快速的檔案系統備份。
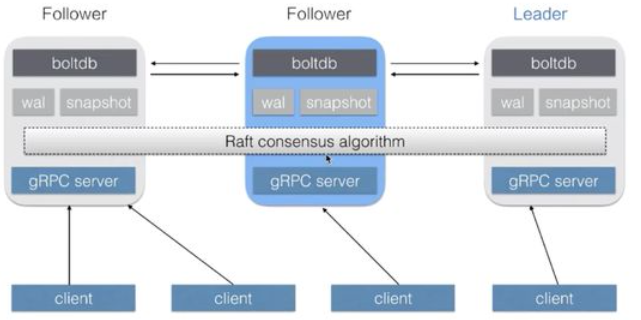
在 etcd 架構中,有一個關鍵的概念叫做 quorum,quorum 的定義是 (n+1)/2,也就是說超過叢集中半數節點組成的一個團體。
3個節點容忍1個故障,5個節點容忍2個故障。
允許部分節點故障之後繼續提供服務,怎麼解決分散式一致性?
分散式一致性演演算法由 Raft 一致性演演算法完成。
-
任意兩個 quorum 的成員之間一定會有一個交集(公共成員),也就是說只要有任意一個 quorum 存活,其中一定存在某一個節點(公共成員),它包含著叢集中所有的被確認提交的資料。
-
基於這一原理,Raft 一致性演演算法設計了一套資料同步機制,在 Leader 任期切換後能夠重新同步上一個quorum 被提交的所有資料,從而保證整個叢集狀態向前推進的過程中保持資料的一致。
怎樣獲取資料呢?
- 通過 etcd 提供的使用者端去存取叢集的資料。
- 直接通過 http 的方式(類似 curl 命令)直接存取 etcd。
- 在 etcd 內部,把 etcd 的資料儲存理解為一個有序的 map,它儲存著 key-value 資料。
- etcd 支援訂閱資料的變更,提供 watch 機制,通過 watch 實時地拿到 etcd 中資料的增量更新,從而實現與etcd 中的資料同步等業務邏輯。
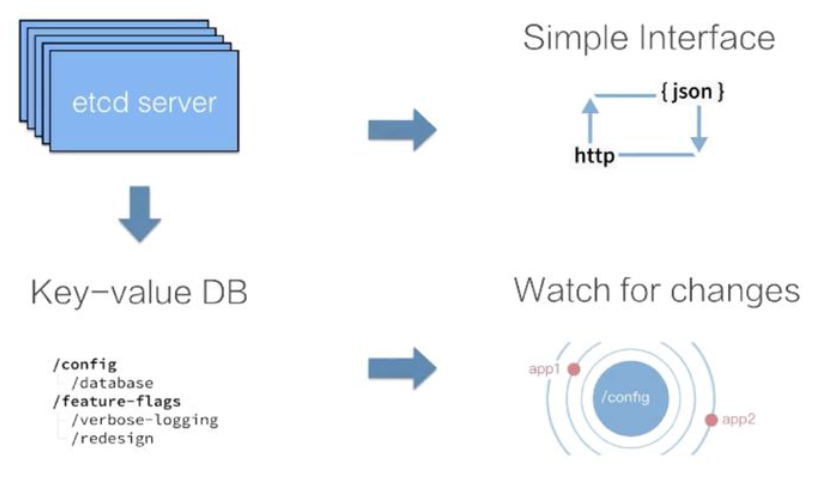
API 介紹
API檔案: https://github.com/coreos/etcd/blob/6acb3d67fbe131b3b2d5d010e00ec80182be4628/Documentation
設定項:https://github.com/coreos/etcd/blob/master/Documentation/op-guide/configuration.md
大致分為五組:

- 第一組是 Put 與 Delete。類似Map的使用。
- 第二組是查詢操作:
- 第一種是指定單個 key 的查詢。
- 第二種是指定的一個 key 的範圍。
- 第三組是資料訂閱:
- Watch 支援指定單個 key。
- 指定一個 key 的字首,在實際應用場景中的通常會採用第二種形勢;
- 第四組事務操作。etcd 提供了一個簡單的事務支援,類似於程式碼中的 if else 語句,etcd 確保整個操作的原子性。
- 第五組是 Leases 介面。
分散式系統理論之租約機制
在分散式系統中,往往會有一箇中心伺服器節點。
該節點負責儲存、維護系統中的後設資料。
如果系統中的各種操作都依賴於中心伺服器上的後設資料,那麼中心伺服器很容易成為效能瓶頸及存在單點故障。
而通過租約機制,可以將中心伺服器的「權力」下放給其他機器,就可以減輕中心伺服器的壓力。
資料版本機制
要正確使用 etcd 的 API,必須要知道內部對應資料版本號的基本原理。
term:代表的是整個叢集 Leader 的任期。
revision:代表的是全域性資料的版本。
在叢集中跨 Leader 任期之間,revision 都會保持全域性單調遞增。
正是 revision 的這一特性,使得叢集中任意一次的修改都對應著一個唯一的 revision,
因此我們可以通過 revision 來支援資料的 MVCC,也可以支援資料的 Watch。
MVVC (Multi-Version Concurrency Control)
MVCC是為了實現事務的隔離性,通過版本號,避免同一資料在不同事務間的競爭,
可以把它當成基於多版本號的一種樂觀鎖。
當然,這種樂觀鎖只在事務級別提交讀和可重複讀有效。
MVCC最大的好處,相信也是耳熟能詳:讀不加鎖,讀寫不衝突。
在讀多寫少的OLTP應用中,讀寫不衝突是非常重要的,極大的增加了系統的並行效能。
對於每一個 KeyValue 資料節點,etcd 中都記錄了三個版本:
- 第一個版本叫做 create_revision,是 KeyValue 在建立時對應的 revision。
- 第二個叫做 mod_revision,是其資料被操作的時候對應的 revision。
- 第三個 version 就是一個計數器,代表了 KeyValue 被修改了多少次。

資料訂閱
使用 etcd 多版本號來實現並行控制以及資料訂閱(Watch)。
- 支援對同一個 Key 發起多次資料修改,每次資料修改都對應一個版本號。
- 在查詢資料的時候如果不指定版本號,etcd 會返回 Key 對應的最新版本.
- etcd 支援指定一個版本號來查詢歷史資料。

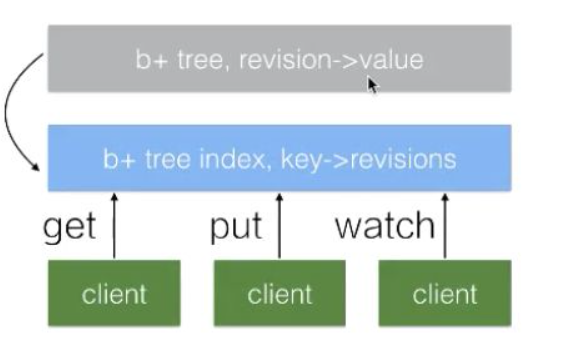
資料儲存
etcd 中所有的資料都儲存在一個 b+tree 中(灰色),該 b+tree 儲存在磁碟中,並通過 mmap 的方式對映到記憶體用來支援快速的存取。
灰色的 b+tree 中維護著 revision 到 value 的對映關係,支援通過 revision 查詢對應的資料。
revision 是單調遞增的,通過 watch 來訂閱指定 revision 之後的資料時,僅訂閱該 b+ tree 的資料變化即可。
在 etcd 內部還維護著另外一個 btree(藍色),它管理著 key 到 revision 的對映關係。當用戶端使用 key 查詢資料時,首先需要經過藍色的 btree 將 key 轉化為對應的 revision,再通過灰色的 btree 查詢到對應的資料。
問題
etcd 將每一次修改都記錄下來會導致資料持續增長。
這會帶來記憶體及磁碟的空間消耗,同時也會影響 b+tree 的查詢效率。
為了解決這一問題,在 etcd 中會執行一個週期性的 Compaction 的機制來清理歷史資料,將一段時間之前的同一個 Key 的多個歷史版本資料清理掉。
最終的結果是灰色的 b+tree 依舊保持單調遞增,但可能會出現一些空洞。
mini-transactions
etcd 的 事務機制比較簡單,基本可以理解為一段 if-else 程式。

在 etcd 內部會保證整個事務操作的原子性。
使用場景
- 後設資料儲存
- Server Discovery (Naming Service)
- Distributed Coordination: leader election
- Distributed Coordination 分散式系統並行控制
參考
Paxos:
Raft:
etcd:
- https://www.zhihu.com/question/283164721/answer/1953060665
- https://www.cnblogs.com/yogoup/p/12020477.html
- https://edu.aliyun.com/roadmap/cloudnative