KNN演演算法推理與實現
Overview
K近鄰值演演算法 KNN (K — Nearest Neighbors) 是一種機器學習中的分類演演算法;K-NN是一種非引數的惰性學習演演算法。非引數意味著沒有對基礎資料分佈的假設,即模型結構是從資料集確定的。
它被稱為惰性演演算法的原因是,因為它不需要任何訓練資料點來生成模型。所有訓練資料都用於測試階段,這使得訓練更快,測試階段更慢且成本更高。
如何工作
KNN 演演算法是通過計算新物件與訓練資料集中所有物件之間的距離,對新範例進行分類或迴歸預測。然後選擇訓練資料集中距離最小的 K 個範例,並通過平均結果進行預測。
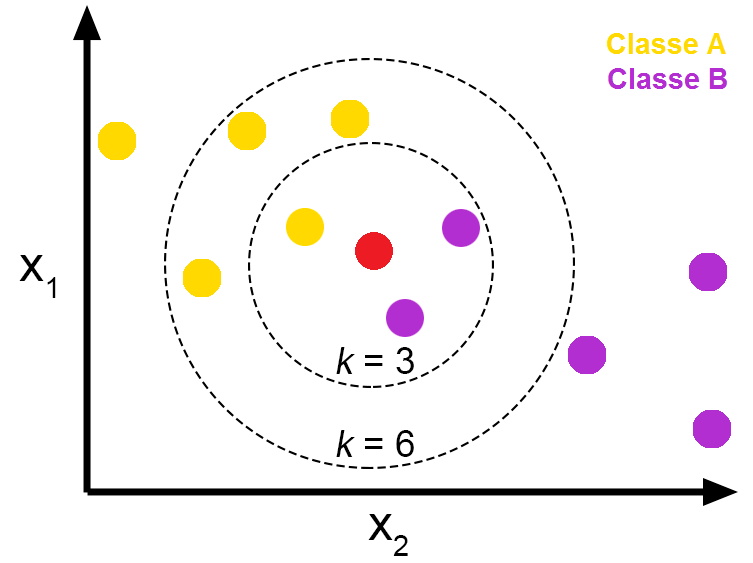
如圖所示:一個未分類的資料(紅色)和所有其他已分類的資料(黃色和紫色),每個資料都屬於一個類別。因此,計算未分類資料與所有其他資料的距離,以瞭解哪些距離最小,因此當K= 3 (或K= 6 )最接近的資料並檢查出現最多的類,如下圖所示,與新資料最接近的資料是在第一個圓圈內(圓圈內)的資料,在這個圓圈內還有 3 個其他資料(已經用黃色分類),我們將檢查其中的主要類別,會被歸類為紫色,因為有2個紫色球,1個黃色球。
圖中: 紅、藍與黃線分別表示所有曼哈頓距離都擁有一樣長度(12),綠線表示歐幾里得距離 \(6×\sqrt2 ≈ 8.48\)
對於整數特徵空間中的兩個向量,應該計算曼哈頓距離而不是歐幾里得距離
曼哈頓距離在二維平面的計算公式是,在X軸的亮點
\(Manhattandistance\ d(x,y)=\left|x_{1}-x_{2}\right|+\left|y_{1}-y_{2}\right|\)
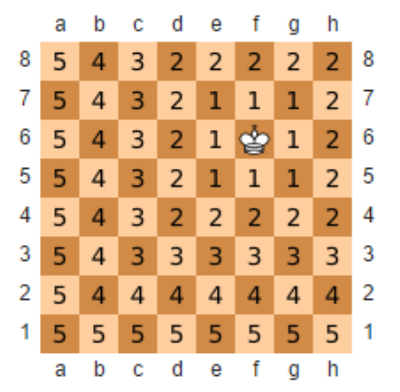
如果所示,描述格子和格子之間的距離可以用曼哈頓距離,如國王移動到右下角的距離是?
\(King=|6-8|+|6-1| = 7\)
兩個向量間的距離可以表示為 \(MD\ =\ Σ|Ai – Bi|\)
python中的公式可以表示為 :sum(abs(val1-val2) for val1, val2 in zip(a,b))
from scipy.spatial.distance import cityblock
# calculate manhattan distance
def manhattan_distance(a, b):
return sum(abs(e1-e2) for e1, e2 in zip(a,b))
# define data
row1 = [10, 20, 15, 10, 5]
row2 = [12, 24, 18, 8, 7]
# calculate distance
dist = manhattan_distance(row1, row2)
print(dist)
print(cityblock(row1, row2))
閔可夫斯基距離
閔可夫斯基距離(Minkowski distance)並不是一種距離而是對是歐幾里得距離和曼哈頓距離的概括,用來計算兩個向量之間的距離。
閔可夫斯基增並新增了一個引數,稱為「階數」或 p:\(d(x,y) = (\sum(|x-y|)^p)^\frac{1}{p}\)
在python中的公式:
(sum for i to N (abs(v1[i] – v2[i]))^p)^(1/p)
p 是一個有序的引數,當 \(p=1\) 時,計算的是曼哈頓距離。當 \(p=2\) 時,計算的是歐幾里得距離。
在實現使用距離度量的機器學習演演算法時,通常會使用閔可夫斯基距離,因為可以通過調整引數「 p 」控制用於向量的距離度量演演算法的型別。
# calculating minkowski distance between vectors
from scipy.spatial import minkowski_distance
# calculate minkowski distance
def minkowski_distance(a, b, p):
return sum(abs(e1-e2)**p for e1, e2 in zip(a,b))**(1/p)
# define data
row1 = [10, 20, 15, 10, 5]
row2 = [12, 24, 18, 8, 7]
# 手動實現的演演算法用來使用閔可夫斯基計算距離
dist = minkowski_distance(row1, row2, 1)
# 1為曼哈頓
print(dist)
# 1為歐幾里得
dist = minkowski_distance(row1, row2, 2)
print(dist)
# 使用包 scipy.spatial來計算
print(minkowski_distance(row1, row2, 1))
print(minkowski_distance(row1, row2, 2))
KNN演演算法實現
Prerequisite
首先會用範例來實現KNN演演算法的每個步驟,並加以分析,然後將所有步驟關聯在在一起,形成一個適用於真實資料集的實現。
KNN在實現起來主要有三個步驟:
- 計算距離(這裡選擇歐幾里得距離)
- 獲得臨近鄰居
- 做出預測
這三個步驟是KNN演演算法用以解決分類和迴歸預測建模問題的基礎知識
計算距離
第一步計算資料集中兩行之間的距離。在資料集中的資料行主要由數位組成,計算兩行或數位向量之間的距離的一種簡單方法是畫一條直線。這在 2D 或 3D 平面中都是很好地選擇,並且可以很好地擴充套件到更高的維度。
這裡使用的是比較流行的計算距離的演演算法,歐幾里得距離來計算兩個向量之間的直線距離。歐幾里得距離的公式是,兩個向量的平方差的平方根,\(Euclidean\ Distance=\sqrt[]{\sum(a-b)^2}\) ;在python中可以表示為:sqrt(sum i to N (x1 – x2)^2) ;其中 x1 是第一行資料,x2 是第二行資料,i 表示特定列的索引,因為可能需要對所有行進行計算。
在歐幾里得距離中,值越小,兩條記錄就越相似; 0 表示兩條記錄之間沒有差異。
那麼使用python實現一個計算歐幾里得距離的演演算法
def euclidean_distance(row1, row2):
distance = 0.0
for i in range(len(row1)-1):
distance += (row1[i] - row2[i])**2
return sqrt(distance)
準備一部分測試資料,來對測試距離演演算法
X1 X2 Y
2.7810836 2.550537003 0
1.465489372 2.362125076 0
3.396561688 4.400293529 0
1.38807019 1.850220317 0
3.06407232 3.005305973 0
7.627531214 2.759262235 1
5.332441248 2.088626775 1
6.922596716 1.77106367 1
8.675418651 -0.242068655 1
7.673756466 3.508563011 1
那麼來測試這些資料,需要做到的是第一行與所有行之間的距離,對於第一行與自己的距離應該為0
from math import sqrt
# 歐幾里得距離,計算兩個向量間距離的演演算法
def euclidean_distance(row1, row2):
distance = 0.0
for i in range(len(row1)-1):
distance += (row1[i] - row2[i])**2 # 平方差
return sqrt(distance) # 平方根
# 測試資料集
dataset = [
[2.7810836,2.550537003,0],
[1.465489372,2.362125076,0],
[3.396561688,4.400293529,0],
[1.38807019,1.850220317,0],
[3.06407232,3.005305973,0],
[7.627531214,2.759262235,1],
[5.332441248,2.088626775,1],
[6.922596716,1.77106367,1],
[8.675418651,-0.242068655,1],
[7.673756466,3.508563011,1]
]
row0 = dataset[0]
for row in dataset:
distance = euclidean_distance(row0, row)
print(distance)
# 0.0
# 1.3290173915275787
# 1.9494646655653247
# 1.5591439385540549
# 0.5356280721938492
# 4.850940186986411
# 2.592833759950511
# 4.214227042632867
# 6.522409988228337
# 4.985585382449795
獲取最近鄰居
資料集中新資料的鄰居是k個最接近的範例(行),這個範例由距離定義。現在誕生的問題:如何找到最近的鄰居?以及怎麼找到最近的鄰居?
-
為了在資料集中找到 K 的鄰居,首先必須計算資料集中每條記錄與新資料之間的距離。
-
有了距離之後,必須按照 K 的距離對訓練集中的所有範例排序。然後選擇前 k 個作為最近的鄰居。
這裡實現起來是通過將資料集中每條記錄的距離作為一個元組來跟蹤,通過對元組列表進行排序(距離降序),然後檢索最近鄰居。下面是一個實現這些步驟的函數
# 找到最近的鄰居
def get_neighbors(train, test_row, num_neighbors):
"""
計算訓練集train中所有元素到test_row的距離
:param train: list, 資料集,可以是訓練集
:param test_row: list, 新的範例,也就是K
:param num_neighbors:int,需要多少個鄰居
:return: None
"""
distances = list()
for train_row in train:
# 計算出每一行的距離,把他新增到元組中
dist = euclidean_distance(test_row, train_row)
distances.append((train_row, dist))
distances.sort(key=lambda knn: knn[1]) # 根據元素哪個欄位進行排序
neighbors = list()
for i in range(num_neighbors):
neighbors.append(distances[i][0])
return neighbors
下面是完整的範例
from math import sqrt
# 歐幾里得距離,計算兩個向量間距離的演演算法
def euclidean_distance(row1, row2):
distance = 0.0
for i in range(len(row1)-1):
distance += (row1[i] - row2[i])**2 # 平方差
return sqrt(distance) # 平方根
# 找到最近的鄰居
def get_neighbors(train, test_row, num_neighbors):
"""
計算訓練集train中所有元素到test_row的距離
:param train: list, 資料集,可以是訓練集
:param test_row: list, 新的範例,也就是K
:param num_neighbors:int,需要多少個鄰居
:return: None
"""
distances = list()
for train_row in train:
# 計算出每一行的距離,把他新增到元組中
dist = euclidean_distance(test_row, train_row)
distances.append((train_row, dist))
distances.sort(key=lambda knn: knn[1]) # 根據元素哪個欄位進行排序
neighbors = list()
for i in range(num_neighbors):
neighbors.append(distances[i][0])
return neighbors
# 測試資料集
dataset = [
[2.7810836,2.550537003,0],
[1.465489372,2.362125076,0],
[3.396561688,4.400293529,0],
[1.38807019,1.850220317,0],
[3.06407232,3.005305973,0],
[7.627531214,2.759262235,1],
[5.332441248,2.088626775,1],
[6.922596716,1.77106367,1],
[8.675418651,-0.242068655,1],
[7.673756466,3.508563011,1]
]
neighbors = get_neighbors(dataset, dataset[0], 3)
for neighbor in neighbors:
print(neighbor)
# [2.7810836, 2.550537003, 0]
# [3.06407232, 3.005305973, 0]
# [1.465489372, 2.362125076, 0]
可以看到,執行後會將資料集中最相似的 3 條記錄按相似度順序列印。和預測的一樣,第一個記錄與其本身最相似,並且位於列表的頂部。
預測結果
預測結果在這裡指定是,通過分類拿到了最近的鄰居的範例,對鄰居進行分類,找到鄰居中最大類別的一類,作為預測值。這裡使用的是對鄰居值執行 max() 來實現這一點,下面是實現方式
# 預測值
def predict_classification(train, test_row, num_neighbors):
"""
計算訓練集train中所有元素到test_row的距離
:param train: list, 資料集,可以是訓練集
:param test_row: list, 新的範例,也就是K
:param num_neighbors:int,需要多少個鄰居
:return: None
"""
neighbors = get_neighbors(train, test_row, num_neighbors)
output_values = [row[-1] for row in neighbors] # 拿到所屬類的真實類別
prediction = max(set(output_values), key=output_values.count) #算出鄰居類別最大的數量
return prediction
下面是完整的範例
from math import sqrt
# 歐幾里得距離,計算兩個向量間距離的演演算法
def euclidean_distance(row1, row2):
distance = 0.0
for i in range(len(row1)-1):
distance += (row1[i] - row2[i])**2 # 平方差
return sqrt(distance) # 平方根
# 找到最近的鄰居
def get_neighbors(train, test_row, num_neighbors):
"""
計算訓練集train中所有元素到test_row的距離
:param train: list, 資料集,可以是訓練集
:param test_row: list, 新的範例,也就是K
:param num_neighbors:int,需要多少個鄰居
:return: None
"""
distances = list()
for train_row in train:
# 計算出每一行的距離,把他新增到元組中
dist = euclidean_distance(test_row, train_row)
distances.append((train_row, dist))
distances.sort(key=lambda knn: knn[1]) # 根據元素哪個欄位進行排序
neighbors = list()
for i in range(num_neighbors):
neighbors.append(distances[i][0])
return neighbors
# 預測值
def predict_classification(train, test_row, num_neighbors):
"""
計算訓練集train中所有元素到test_row的距離
:param train: list, 資料集,可以是訓練集
:param test_row: list, 新的範例,也就是K
:param num_neighbors:int,需要多少個鄰居
:return: None
"""
neighbors = get_neighbors(train, test_row, num_neighbors)
output_values = [row[-1] for row in neighbors] # 拿到所屬類的真實類別
prediction = max(set(output_values), key=output_values.count) #算出鄰居類別最大的數量
return prediction
# 測試資料集
dataset = [
[2.7810836,2.550537003,0],
[1.465489372,2.362125076,0],
[3.396561688,4.400293529,0],
[1.38807019,1.850220317,0],
[3.06407232,3.005305973,0],
[7.627531214,2.759262235,1],
[5.332441248,2.088626775,1],
[6.922596716,1.77106367,1],
[8.675418651,-0.242068655,1],
[7.673756466,3.508563011,1]
]
for n in range(len(dataset)):
prediction = predict_classification(dataset, dataset[n], 5)
print('Expected %d, Got %d.' % (dataset[n][-1], prediction))
# Expected 0, Got 0.
# Expected 0, Got 0.
# Expected 0, Got 0.
# Expected 0, Got 0.
# Expected 0, Got 0.
# Expected 1, Got 1.
# Expected 1, Got 1.
# Expected 1, Got 1.
# Expected 1, Got 1.
# Expected 1, Got 1.
執行結果列印了預期分類與從資料集中 3 個相進鄰居預測結果是一直的。
鳶尾花種範例
這裡使用的是 Iris Flower Species 資料集。
鳶尾花資料集是根據鳶尾花的測量值預測花卉種類。這是一個多類分類問題。每個類的觀察數量是平衡的。有 150 個觀測值,有 4 個輸入變數和 1 個輸出變數。變數名稱如下:
- 萼片長度以釐米為單位。
- 萼片寬度以釐米為單位。
- 花瓣長度以釐米為單位。
- 花瓣寬度以釐米為單位。
- 真實型別
更多的關於資料集的說明可以參考:Iris-databases資料集的說明
Prerequisite
實驗的步驟大概分為如下:
- 載入資料集並將資料轉換為可用於均值和標準差計算的數位。將屬性轉為float,將類別轉換為int。
- 使 5折的K折較差驗證(K-Fold CV)評估該演演算法。
Start
from random import seed
from random import randrange
from csv import reader
from math import sqrt
# 載入CSV
def load_csv(filename):
dataset = list()
with open(filename, 'r') as file:
csv_reader = reader(file)
for row in csv_reader:
if not row:
continue
dataset.append(row)
return dataset
# 轉換所有的值為float方便運算
def str_column_to_float(dataset, column):
for row in dataset:
row[column] = float(row[column].strip())
# 轉換所有的型別為int
def str_column_to_int(dataset, column):
class_values = [row[column] for row in dataset]
unique = set(class_values)
lookup = dict()
for i, value in enumerate(unique):
lookup[value] = i
for row in dataset:
row[column] = lookup[row[column]]
return lookup
# # k-folds CV函數進行劃分
def cross_validation_split(dataset, n_folds):
dataset_split = list()
dataset_copy = list(dataset)
# 平均分成n_folds折數
fold_size = int(len(dataset) / n_folds)
for _ in range(n_folds):
fold = list()
while len(fold) < fold_size:
index = randrange(len(dataset_copy))
fold.append(dataset_copy.pop(index))
dataset_split.append(fold)
return dataset_split
# 計算精確度
def accuracy_metric(actual, predicted):
correct = 0
for i in range(len(actual)):
if actual[i] == predicted[i]:
correct += 1
return correct / float(len(actual)) * 100.0
# 評估演演算法
def evaluate_algorithm(dataset, algorithm, n_folds, *args):
"""
評估演演算法,計算演演算法的精確度
:param dataset: list, 資料集
:param algorithm: function, 演演算法名
:param n_folds: int,折數
:param args: 用於algorithm的引數
:return: None
"""
folds = cross_validation_split(dataset, n_folds) # 分成5折
scores = list()
for fold in folds:
train_set = list(folds)
train_set.remove(fold) # 訓練集不包含本身
train_set = sum(train_set, [])
test_set = list() # 測試集
for row in fold:
row_copy = list(row)
test_set.append(row_copy)
row_copy[-1] = None
predicted = algorithm(train_set, test_set, *args)
actual = [row[-1] for row in fold]
accuracy = accuracy_metric(actual, predicted)
scores.append(accuracy)
return scores
# 歐幾里得距離,計算兩個向量間距離的演演算法
def euclidean_distance(row1, row2):
distance = 0.0
for i in range(len(row1)-1):
distance += (row1[i] - row2[i])**2
return sqrt(distance)
# 確定最鄰近的鄰居
def get_neighbors(train, test_row, num_neighbors):
"""
計算訓練集train中所有元素到test_row的距離
:param train: list, 資料集,可以是訓練集
:param test_row: list, 新的範例,也就是K
:param num_neighbors:int,需要多少個鄰居
:return: None
"""
distances = list()
for train_row in train:
dist = euclidean_distance(test_row, train_row)
distances.append((train_row, dist))
distances.sort(key=lambda tup: tup[1])
neighbors = list()
for i in range(num_neighbors):
neighbors.append(distances[i][0])
return neighbors
# 與臨近值進行比較並預測
def predict_classification(train, test_row, num_neighbors):
"""
計算訓練集train中所有元素到test_row的距離
:param train: list, 資料集,可以是訓練集
:param test_row: list, 新的範例,也就是K
:param num_neighbors:int,需要多少個鄰居
:return: None
"""
neighbors = get_neighbors(train, test_row, num_neighbors)
output_values = [row[-1] for row in neighbors]
prediction = max(set(output_values), key=output_values.count)
return prediction
# kNN Algorithm
def k_nearest_neighbors(train, test, num_neighbors):
predictions = list()
for row in test:
output = predict_classification(train, row, num_neighbors)
predictions.append(output)
return(predictions)
# 使用KNN演演算法計算鳶尾花資料集
seed(1)
filename = 'iris.csv'
dataset = load_csv(filename)
for i in range(len(dataset[0])-1):
str_column_to_float(dataset, i)
# 轉換型別為int
str_column_to_int(dataset, len(dataset[0])-1)
# 評估演演算法
n_folds = 5 # 5折
num_neighbors = 5 #取5個鄰居
scores = evaluate_algorithm(dataset, k_nearest_neighbors, n_folds, num_neighbors)
print('Scores: %s' % scores)
print('Mean Accuracy: %.3f%%' % (sum(scores)/float(len(scores))))
# Scores: [96.66666666666667, 96.66666666666667, 100.0, 90.0, 100.0]
# Mean Accuracy: 96.667%
上述是對整個資料集的預測百分比,也可以對對應的類的資訊進行輸出
首先在類別轉換函數 str_column_to_int 中增加列印方法
for i, value in enumerate(unique):
lookup[value] = i
print('[%s] => %d' % (value, i))
然後在定義一個新的範例,這個範例是用於預測的資訊 row = [5.7,2.9,4.2,1.3] ; 然後修改需要預測的資料,進行預測
# 原來的整個資料集打分不需要了
# scores = evaluate_algorithm(dataset, k_nearest_neighbors, n_folds, num_neighbors)
# print('Scores: %s' % scores)
# print('Mean Accuracy: %.3f%%' % (sum(scores)/float(len(scores))))
# 定義一個新資料
row = [5.7,2.9,4.2,1.3]
label = predict_classification(dataset, row, num_neighbors)
print('Data=%s, Predicted: %s' % (row, label))
# Data=[5.7, 2.9, 4.2, 1.3], Predicted: 1
通過預測,可以看出預測結果屬於第 1 類,就知道該花為 Iris-setosa 。
Reference