小樣本利器1.半監督一致性正則 Temporal Ensemble & Mean Teacher程式碼實現
這個系列我們用現實中經常碰到的小樣本問題來串聯半監督,文字對抗,文字增強等模型優化方案。小樣本的核心在於如何在有限的標註樣本上,最大化模型的泛化能力,讓模型對unseen的樣本擁有很好的預測效果。之前在NER系列中我們已經介紹過Data Augmentation,不熟悉的童鞋看過來 中文NER的那些事兒4. 資料增強在NER的嘗試。樣本增強是通過提高標註樣本的豐富度來提升模型泛化性,另一個方向半監督方案則是通過利用大量的相同領域未標註資料來提升模型的樣本外預測能力。這一章我們來聊聊半監督方案中的一致性正則~
一致性正則~一個好的分類器應該對相似的樣本點給出一致的預測,於是在訓練中通過約束樣本和注入噪聲的樣本要擁有相對一致的模型預測,來降低模型對區域性擾動的敏感性,為模型引數擬合提供更多的約束。施工中的SimpleClassifcation提供了Temporal Ensemble的相關實現,可以支援多種預訓練或者詞袋模型作為backbone,歡迎來一起Debug >(*^3^)<
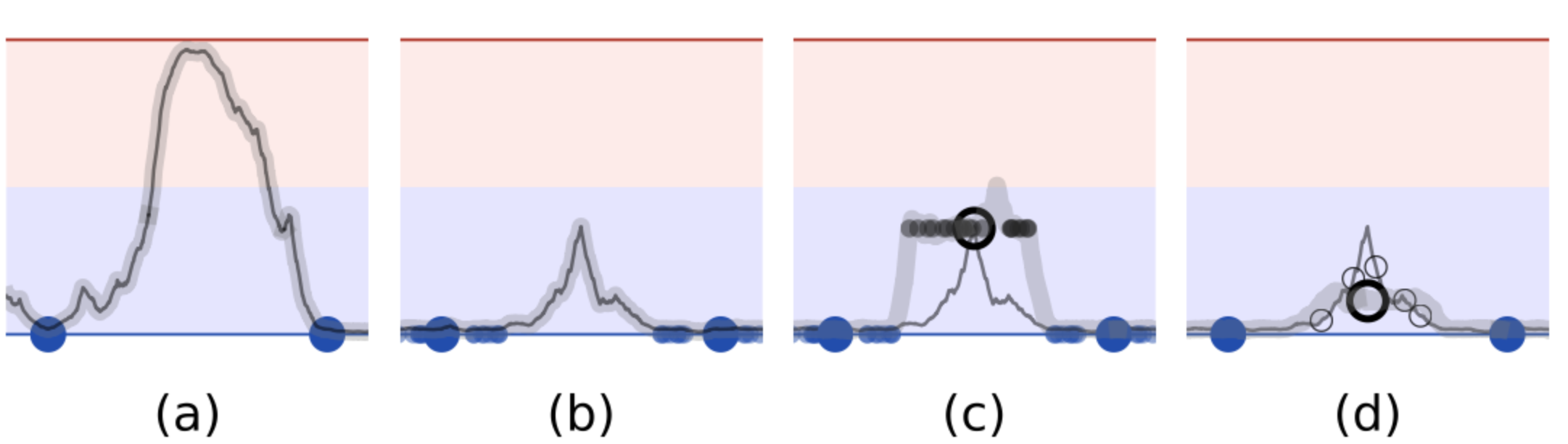
上圖很形象的描述了一致性正則是如何利用標註和未標註資料來約束曲線擬合
a. 指用兩個標註樣本訓練(大藍點),因為樣本少所以對模型擬合缺乏約束
b. 對標註樣本注入噪音(小藍點),並約束噪聲樣本和原始樣本預測一致,通過拓展標註樣本覆蓋的空間,對模型擬合施加了更多的約束
c. 在對標註樣本擬合之後,凍結模型,對未標註樣本(空心點)進行一致性約束。因為一致性約束並不需要用到label因此可以充分利用未標註資料
d. 用未標註樣本上一致性約束的loss來更新模型,使得模型對噪聲更加魯棒
以下三種方案採用了不同的噪聲注入和Ensemble方式,前兩個方案來自【REF1】Temporal Ensemble,第三個方案來自【REF2】Mean Teacher。因為合併了2篇paper,所以我們先整體過一下3種訓練框架,再說訓練技巧和一致性正則的一些insights。
Π-MODEL

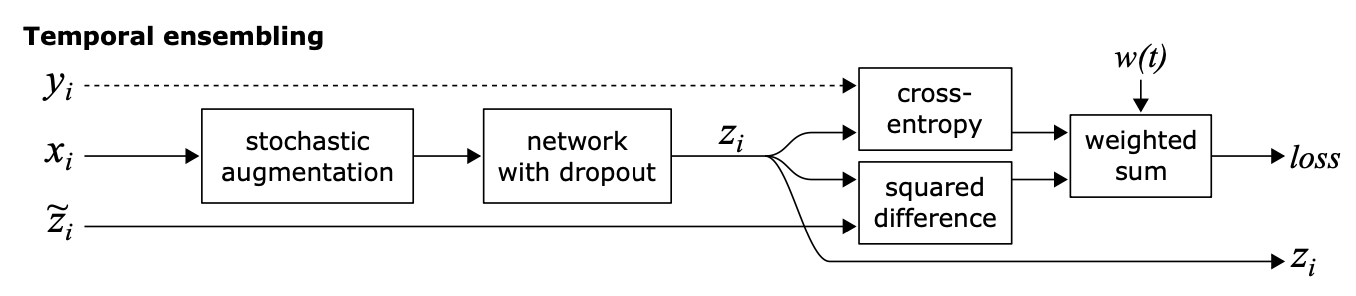
如上圖,針對每個樣本,Π-MODEL會進行兩次不同的增強,以及網路本身的隨機drop out得到兩個預測結果,一致性正則loss使用了MSE來計算兩次預測結果的差異,既約束模型對輸入樣本的區域性擾動要更加魯棒。模型目標是有標註樣本的cross- entropy,結合全樣本的一致性正則loss
Π-MODEL的訓練效率較低,因為每個樣本都要計算兩遍。
Temporal Ensemble
以上Π-MODEL在同一個epoch內對樣本注入不同噪音的預測值進行約束,這部分約束會存在噪聲較大,以及在epoch之間相對割裂的問題。因此作者引入Ensemble的思路在時間維度(epoch)做移動平均,來降低一致性loss的波動性。Temporal Ensemble通過約束各個epoch預測值的加權移動平均值\(Z\),和當前epoch預測值\(z\)的相對一致,來實現一致性正則,當\(\alpha=0\)的時候Temporal就退化成了Π-MODEL。
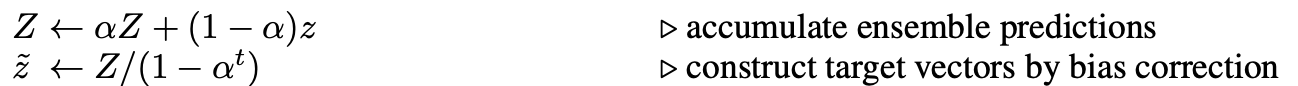
因此Temporal需要引入Sample_size * label_size的額外變數\(Z\),來儲存每個樣本在各個epoch上預測值的加權移動平均,如果你的樣本非常大,則Temporal額外儲存預測的變數會是很大的記憶體開銷,以下為temporal部分的相關實現~
with tf.variable_scope('temporal_ensemble'):
temporal_ensemble = tf.get_variable(initializer=tf.zeros_initializer,
shape=(self.params['sample_size'], self.params['label_size']),
dtype=tf.float32, name='temporal_ensemble', trainable=False)
self.Z = tf.nn.embedding_lookup(temporal_ensemble, features['idx']) # batch_size * label_size
self.Z = self.alpha * self.Z + (1 - self.alpha) * preds
self.assign_op = tf.scatter_update(temporal_ensemble, features['idx'], self.Z)
add_layer_summary('ensemble', self.Z)
所以對比Π-MODEL,Temporal的一致性約束更加平滑,整體效果更好,以及計算效率更高因為每個樣本只需要做一次預測,不過因為移動平均的引入會佔用更多的記憶體~
Mean Teacher
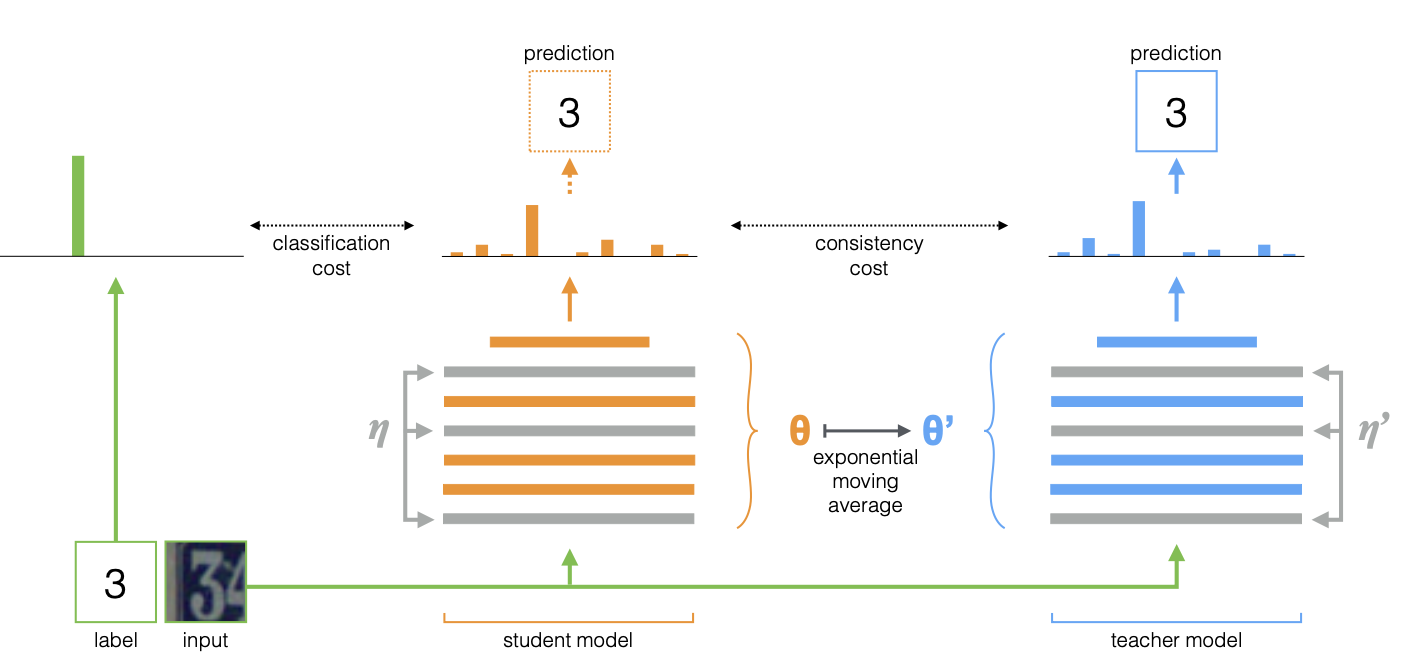
Mean Teacher是在Temporal的基礎上調整了Ensemble實現的方案。Temporal是對每個樣本的模型預測做Ensemble,所以每個epoch每個樣本的移動平均才被更新一次,而Mean Teacher是對模型引數做Ensemble,這樣每個step,student模型的更新都會反應在當前teacher模型上。
和Temporal無比相似的公式,差異只在於上面的Z是模型輸出,下面的\(\theta\)是模型引數, 同樣當\(\alpha=0\)的時候,Mean Teacher也退化成Π-MODEL。
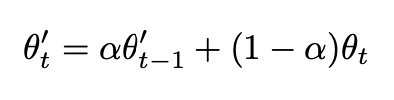
所以訓練過程如下
- student模型對每個隨機增強後的樣本計算輸出
- 每個step,student模型權重會移動更新teacher模型的權重
- 更新後的teacher模型對相同樣本隨機增強後計算輸出
- 計算teacher和student模型預測結果的一致性loss,這裡同樣選用了MSE
- 監督loss + 一致性loss共同更新student模型引數
效果上Mean Teacher要優於Temporal,不過在計算效率上和Π-MODEL一樣都需要預測兩遍,所以要比Temporal慢不少,以及因為要儲存模型引數的移動平均,所以記憶體佔用也讓人很頭疼,所以Mean Teacher這塊並沒做相關的實現,對大模型並不太友好~
訓練技巧
以上的噪聲注入和Ensemble需要搭配一些特定的訓練技巧。
- ramp up weight
在訓練初期,模型應該以有監督目標為主,逐步增加一致性loss的權重,在temporal ensemble上更容易解釋,因為當epoch=0時,\(\hat{z}\)是拿不到前一個epoch的預測結果的,因此一致性loss權重為0。程式碼中支援了線性,cosine,sigmoid等三種權重預熱方案,原文中使用的是sigmoid
def ramp_up(cur_epoch, max_epoch, method):
"""
根據訓練epoch來調整無標註loss部分的權重,初始epoch無標註loss權重為0
"""
def linear(cur_epoch, max_epoch):
return cur_epoch / max_epoch
def sigmoid(cur_epoch, max_epoch):
p = 1.0 - cur_epoch / max_epoch
return tf.exp(-5.0 * p ** 2)
def cosine(cur_epoch, max_epoch):
p = cur_epoch / max_epoch
return 0.5 * (tf.cos(np.pi * p) + 1)
if cur_epoch == 0:
weight = tf.constant(0.0)
else:
if method == 'linear':
weight = linear(cur_epoch, max_epoch)
elif method == 'sigmoid':
weight = sigmoid(cur_epoch, max_epoch)
elif method == 'cosine':
weight = cosine(cur_epoch, max_epoch)
else:
raise ValueError('Only linear, sigmoid, cosine method are supported')
return tf.cast(weight, tf.float32)
- 有標註樣本權重
因為以上方案多用於半監督任務,因此需要根據無標註樣本的佔比來調整一致性正則部分的權重。最簡單的就是直接用有標註樣本佔比來對以上的weight做rescale,有標註佔比越高,一致性loss的權重約高,避免模型過度關注正則項。
- 損失函數選擇
針對一致性正則的損失函數到底使用MSE還是KL,兩篇paper都進行了對比,雖然從理論上KL更合邏輯,因為是對預測的概率分佈進行一致性約束,但整體上MSE的效果更好。我猜測和NN傾向於給出over confident的預測相關,尤其是Bert一類的大模型會集中給出0.9999這種預測概率,在KL計算時容易出現極端值
Insights
以上兩種ensemble的策略除了能提升半標註樣本的效果之外,還有以下的額外效果加成
-
模糊標籤:作者在全標註的樣本上也嘗試了self-ensemble的效果,對預測結果也有提升,猜測這源於一致性正則在一定程度上可能改進邊緣/模糊label的樣本效果
-
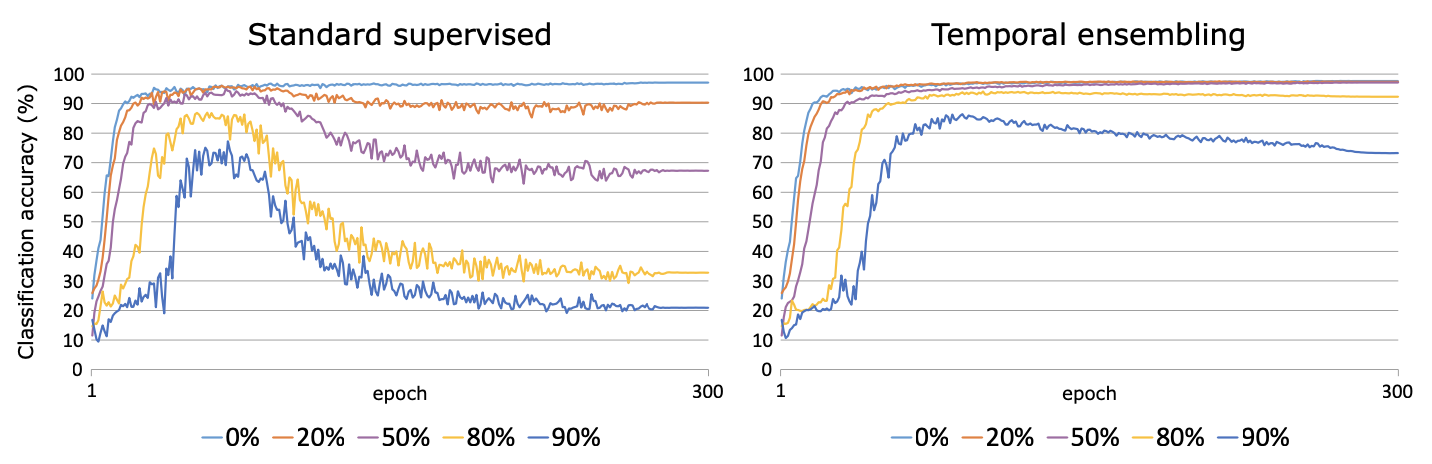
降噪:作者把x%的訓練樣本賦予隨機label,然後對比常規訓練和temporarl ensemble的效果。結果如下temporal對區域性的標註噪音有很好的降噪效果。正確樣本的監督loss幫助模型學習文字表徵到label的mapping,而在正確樣本附近的誤標註樣本會被一致性正則約束,從而降低錯誤標籤對模型的影響。
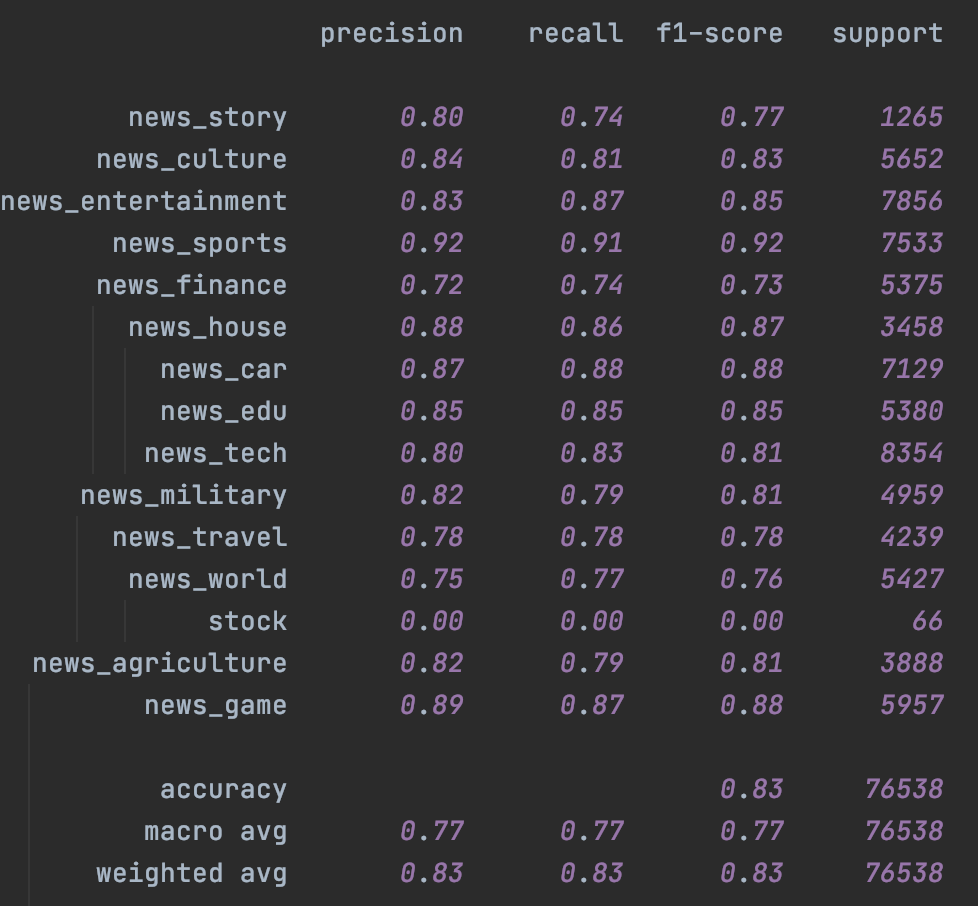
分類效果
這裡在頭條15分類的資料集上進行了測試。分別在Fasttext和Bert上進行了測試,左是原始模型,右加入Temporal Ensemble。考慮NLP的樣本層面的增強效果對比CV相對有限,這裡的隨機增強只用了Encoder層的Drop out,原論文是CV領域所以增強還包括crop/flip這類影象增強。
首先是Fasttext,受限於詞袋模型本身的能力,即便是不加入未標註樣本,只是加入Temporal一致性損失都帶來了整體效果上的提升,具體引數設定詳見checkpoint裡面的train.log
 |
 |
|---|
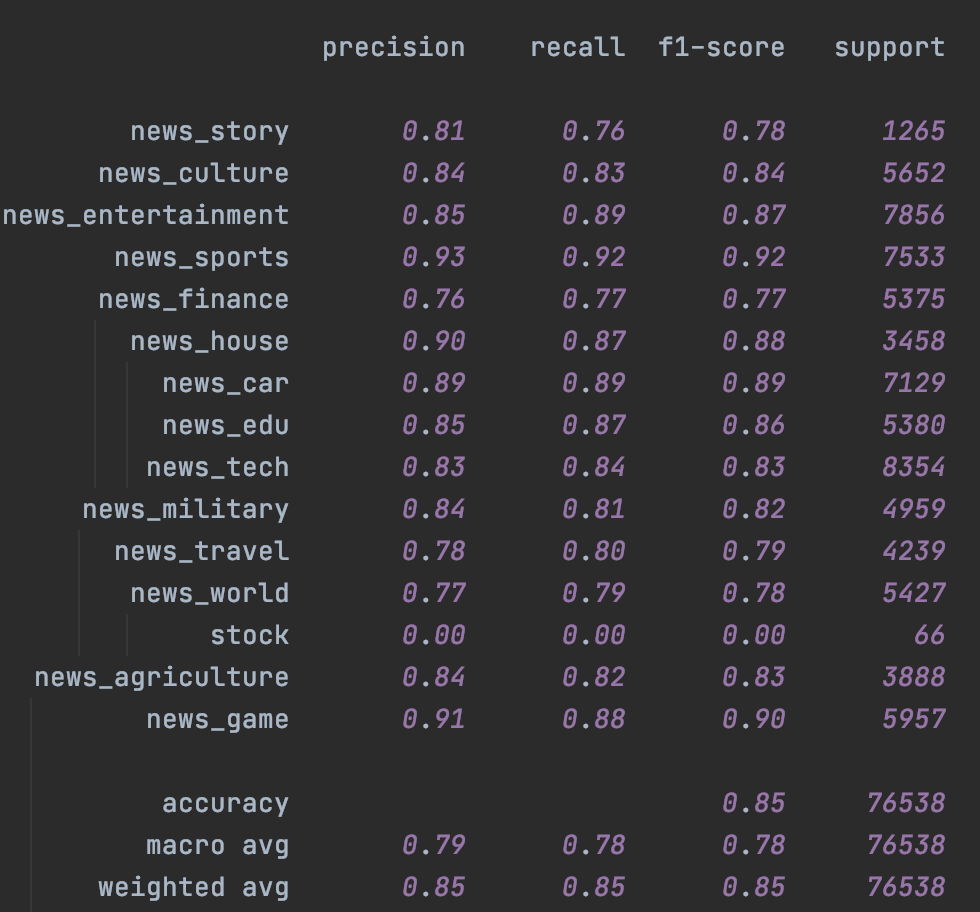
其次是Bert,這裡加入了chinanews的無標註樣本,不過效果比較有限,主要提升是在樣本很少的stock分類上。這裡一定程度和缺少有效的樣本增強有關,後面結合隱藏層增強我們會再試下temporal~
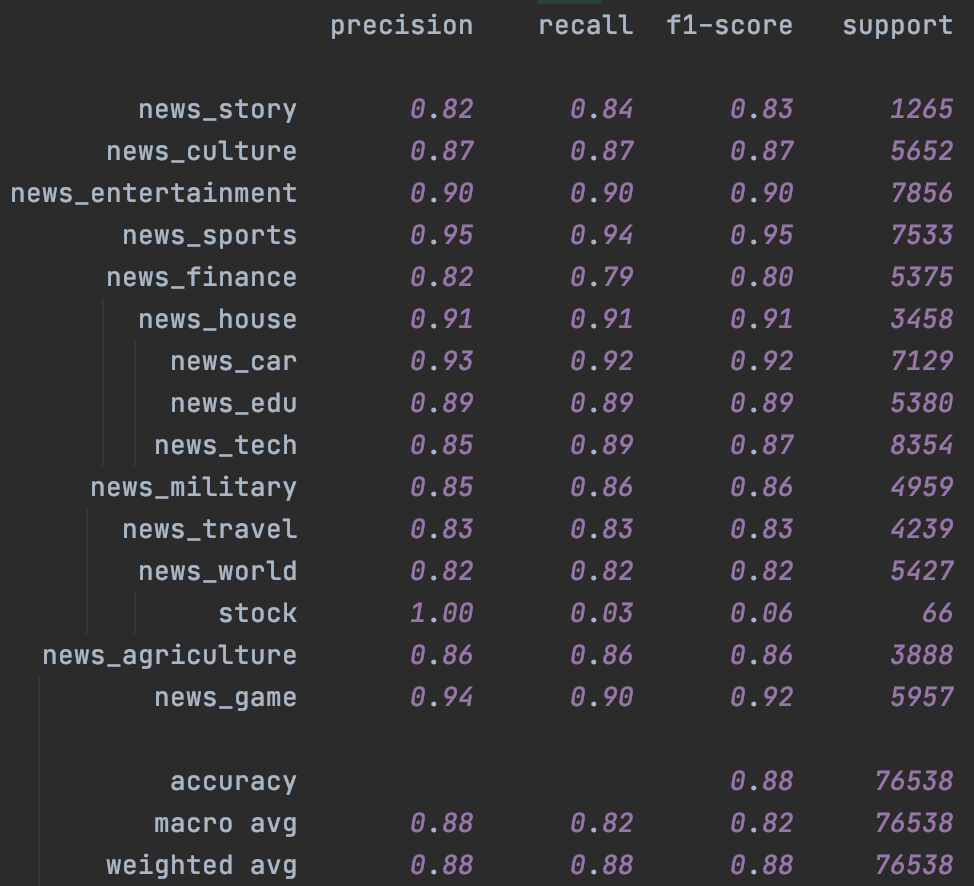 |
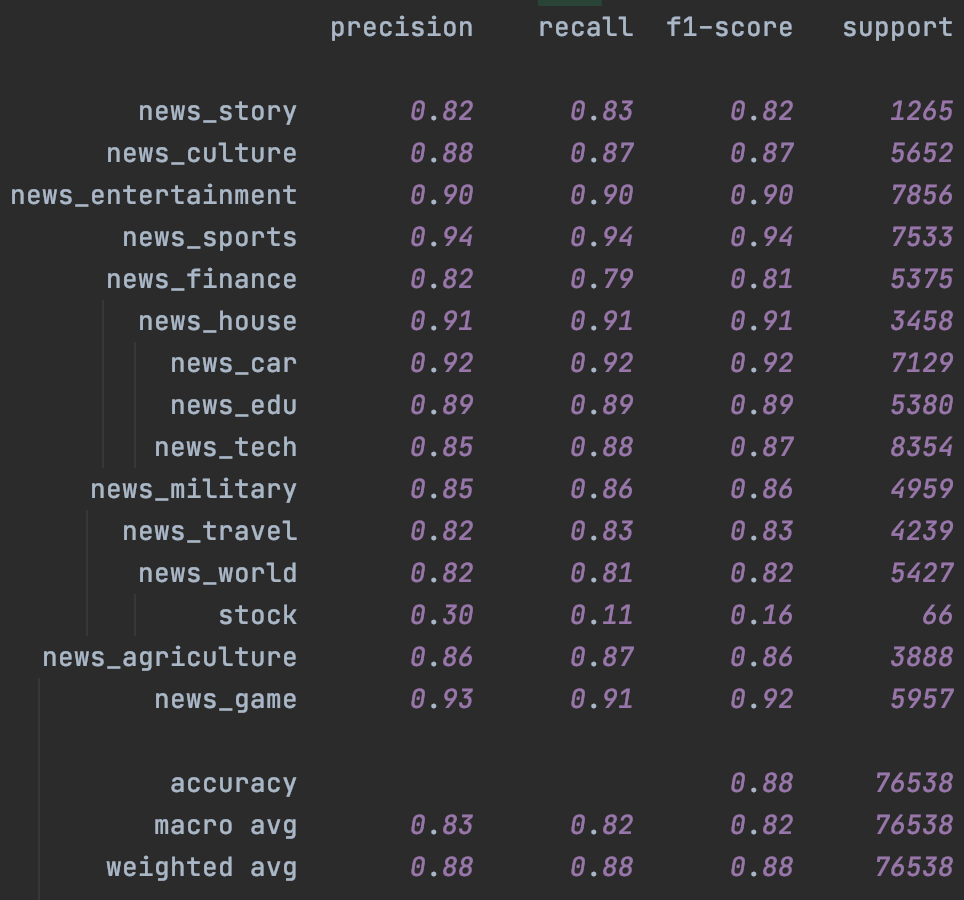 |
|---|
Reference
- Laine, S., Aila, T. (2016). Temporal Ensembling for Semi-Supervised Learning arXiv https://arxiv.org/abs/1610.02242
- Tarvainen, A., Valpola, H. (2017). Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results arXiv https://arxiv.org/abs/1703.01780
- https://tech.meituan.com/tags/半監督學習.html
- https://zhuanlan.zhihu.com/p/250278934
- https://zhuanlan.zhihu.com/p/128527256
- https://zhuanlan.zhihu.com/p/66389797
- https://github.com/diyiy/ACL2022_Limited_Data_Learning_Tutorial