決策樹演演算法的推理與實現
決策樹的概念 略
熵和基尼指數
資訊增益
資訊增益 information gain 是用於訓練決策樹的指標。具體來說,是指這些指標衡量拆分的質量。通俗來說是通過根據隨機變數的給定值拆分資料集來衡量熵。
通過描述一個事件是否"驚訝",通常低概率事件更令人驚訝,因此具有更大的資訊量。而具有相同可能性的事件的概率分佈更"驚訝"並且具有更大的熵。
定義:熵 entropy是一組例子中雜質、無序或不確定性的度量。熵控制決策樹如何決定拆分資料。它實際上影響了決策樹如何繪製邊界。
熵
熵的計算公式為:\(E=-\sum^i_{i=1}(p_i\times\log_2(p_i))\) ;\(P_i\) 是類別 \(i\) 的概率。我們來舉一個例子來更好地理解熵及其計算。假設有一個由三種顏色組成的資料集,紅色、紫色和黃色。如果我們的集合中有一個紅色、三個紫色和四個黃色的觀測值,我們的方程變為:\(E=-(p_r \times \log_2(p_r) + p_p \times \log_2(p_p) + p_y \times \log_2(p_y)\)
其中 \(p_r\) 、\(p_p\) 和 \(p_y\) 分別是選擇紅色、紫色和黃色的概率。假設 \(p_r=\frac{1}{8}\),\(p_p=\frac{3}{8}\) ,\(p_y=\frac{4}{8}\) 現在等式變為變為:
- \(E=-(\frac{1}{8} \times \log_2(\frac{1}{8}) + \frac{3}{8} \times \log_2(\frac{3}{8}) + \frac{4}{8} \times \log_2(\frac{4}{8}))\)
- $0.125 \times log_2(0.125) + 0.375 \times log_2(0.375) + 0.5 \times log_2(0.375) $
- \(0.125 \times -3 + 0.375 \times -1.415 + 0.5 \times -1 = -0.375+-0.425 +-0.5 = 1.41\)
當所有觀測值都屬於同一類時會發生什麼? 在這種情況下,熵將始終為零。\(E=-(1log_21)=0\) ;這種情況下的資料集沒有雜質,這就意味著沒有資料集沒有意義。又如果有兩類資料集,一半是黃色,一半是紫色,那麼熵為1,推導過程是:\(E=−(\ (0.5\log_2(0.5))+(0.5\times \log_2(0.5))\ ) = 1\)
基尼指數
基尼指數 Gini index 和熵 entropy 是計算資訊增益的標準。決策樹演演算法使用資訊增益來拆分節點。
基尼指數計算特定變數在隨機選擇時被錯誤分類的概率程度以及基尼係數的變化。它適用於分類變數,提供「成功」或「失敗」的結果,因此僅進行二元拆分(二元樹結構)。基尼指數在 0 和 1 之間變化,其中,1 表示元素在各個類別中的隨機分佈。基尼指數為 0.5 表示元素在某些類別中分佈均勻。:
- 0 表示為所有元素都與某個類相關聯,或只存在一個類。
- 1 表示所有元素隨機分佈在各個類中,並且0.5 表示元素均勻分佈到某些類中
基尼指數公式:\(1− \sum_n^{i=1}(p_i)^2\) ; \(P_i\) 為分類到特定類別的概率。在構建決策樹時,更願意選擇具有最小基尼指數的屬性作為根節點。
通過範例瞭解公式
| Past Trend | Open Interest | Trading Volume | Return |
|---|---|---|---|
| Positive | Low | High | Up |
| Negative | High | Low | Down |
| Positive | Low | High | Up |
| Positive | High | High | Up |
| Negative | Low | High | Down |
| Positive | Low | Low | Down |
| Negative | High | High | Down |
| Negative | Low | High | Down |
| Positive | Low | Low | Down |
| Positive | High | High | Up |
計算基尼指數
已知條件
-
\(P(Past\ Trend=Positive) = \frac{6}{10}\)
-
\(P(Past\ Trend=Negative) = \frac{4}{10}\)
過去趨勢基尼指數計算
如果過去趨勢為正面,回報為上漲,概率為:\(P(Past\ Trend=Positive\ \&\ Return=Up) = \frac{4}{6}\)
如果過去趨勢為正面,回報為下降,概率為:\(P(Past\ Trend=Positive\ \&\ Return=Down) = \frac{2}{6}\)
- 那麼這個基尼指數為:\(gini(Past\ Trend) = 1-(\frac{4}{6}^2+\frac{2}{6}^2) = 0.45\)
如果過去趨勢為負面,回報為上漲,概率為:\(P(Past\ Trend=Negative\ \&\ Return=Up) = 0\)
如果過去趨勢為負面,回報為下降,概率為:\(P(Past\ Trend=Negative\ \&\ Return=Down) = \frac{4}{4}\)
- 那麼這個基尼指數為:\(gini(Past\ Trend=Negative) = 1-(0^2+\frac{4}{4}^2) = 1-(0+1)=0\)
那麼過去交易量的的基尼指數加權 = \(\frac{6}{10} \times 0.45 + \frac{4}{10}\times 0 = 0.27\)
未平倉量基尼指數計算
已知條件
- \(P(Open\ Interest=High): \frac{4}{10}\)
- \(P(Open\ Interest=Low): \frac{6}{10}\)
如果未平倉量為 high 並且回報為上漲,概率為:\(P(Open\ Interest = High\ \&\ Return\ = Up)=\frac{2}{4}\)
如果未平倉量為 high 並且回報為下降,概率為:\(P(Open\ Interest = High\ \&\ Return\ = Down)=\frac{2}{4}\)
- 那麼這個基尼指數為:\(gini(Open\ Interest=High) = 1-(\frac{2}{4}^2+\frac{2}{4}^2) = 0.5\)
如果未平倉量為 low 並且回報為上漲,概率為:\(P(Open\ Interest = High\ \&\ Return\ = Up)=\frac{2}{6}\)
如果未平倉量為 low 並且回報為下降,概率為:\(P(Open\ Interest = High\ \&\ Return\ = Down)=\frac{4}{6}\)
- 那麼這個基尼指數為:\(gini(Open\ Interest=Low) = 1-(\frac{2}{6}^2+\frac{4}{6}^2) = 0.45\)
那麼未平倉量基尼指數加權 = \(\frac{4}{10} \times 0.5 + \frac{6}{10}\times 0.45 = 0.47\)
計算交易量基尼指數
已知條件
- \(P(Trading\ Volume=High): \frac{7}{10}\)
- \(P(Trading\ Volume=Low): \frac{3}{10}\)
如果交易量為 high 並且回報為上漲,概率為:\(P(Trading\ Volume=High\ \&\ Return\ = Up)=\frac{4}{7}\)
如果交易量為 high 並且回報為下降,概率為:\(P(Trading\ Volume = High\ \&\ Return\ = Down)=\frac{3}{7}\)
- 那麼這個基尼指數為:\(gini(Trading\ Volume=High) = 1-(\frac{4}{7}^2+\frac{3}{7}^2) = 0.49\)
如果交易量為 low 並且回報為上漲,概率為:\(P(Trading\ Volume = Low\ \&\ Return\ = Up)=0\)
如果交易量為 low 並且回報為下降,概率為:\(P(Trading\ Volume = Low\ \&\ Return\ = Down)=\frac{3}{3}\)
- 那麼這個基尼指數為:\(gini(Trading\ Volume=Low) = 1-(0^2+1^2) = 0\)
那麼交易量基尼指數加權 = \(\frac{7}{10} \times 0.49 + \frac{3}{10}\times 0 = 0.34\)
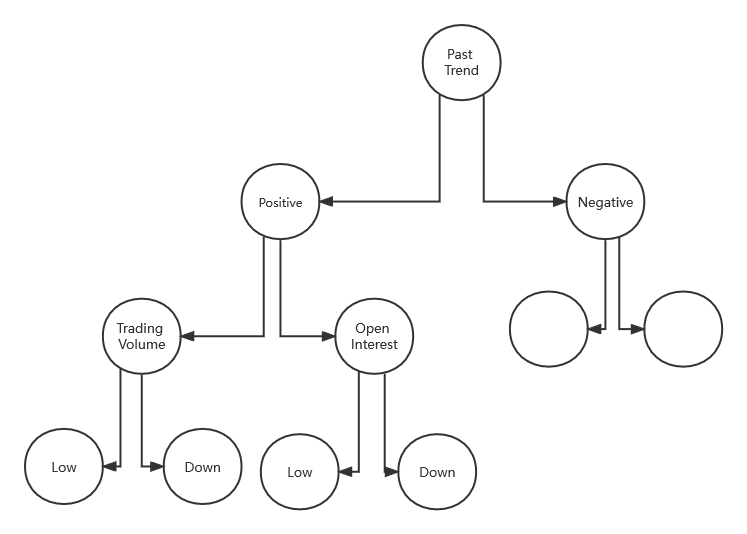
最終計算出的基尼指數列表如下,在表中可以觀察到「Past Trend」的基尼指數最低,因此它將被選為決策樹的根節點。
| Attributes | Gini Index |
|---|---|
| Past Trend | 0.27 |
| Open Interest | 0.47 |
| Trading Volume | 0.34 |
這裡將重複的過程來確定決策樹的子節點或分支。將通過計算」Past Trend「的「Positive」分支的基尼指數如下:
| Past Trend | Open Interest | Trading Volume | Return |
|---|---|---|---|
| Positive | Low | High | Up |
| Positive | Low | High | Up |
| Positive | High | High | Up |
| Positive | Low | Low | Down |
| Positive | Low | Low | Down |
| Positive | High | High | Up |
針對過去正面趨勢計算未平倉量的基尼指數
已知條件
- \(P(Open\ Interest=High): \frac{2}{6}\)
- \(P(Open\ Interest=Low): \frac{4}{6}\)
如果未平倉量為 high 並且回報為上漲,概率為:\(P(Open\ Interest = High\ \&\ Return\ = Up)=\frac{2}{2}\)
如果未平倉量為 high 並且回報為下降,概率為:\(P(Open\ Interest = High\ \&\ Return\ = Down)=0\)
- 那麼這個基尼指數為:\(gini(Open\ Interest=High) = 1-(\frac{2}{2}^2+0^2) = 0\)
如果未平倉量為 low 並且回報為上漲,概率為:\(P(Open\ Interest = Low\ \&\ Return\ = Up)=\frac{2}{4}\)
如果未平倉量為 low 並且回報為下降,概率為:\(P(Open\ Interest = Low\ \&\ Return\ = Down)=\frac{2}{4}\)
- 那麼這個基尼指數為:\(gini(Open\ Interest=Low) = 1-(\frac{2}{4}^2+\frac{2}{4}^2) = 0.5\)
那麼未平倉量基尼指數加權 = \(\frac{2}{6} \times 0 + \frac{4}{6}\times 0.5 = 0.33\)
計算交易量基尼指數
已知條件
- \(P(Trading\ Volume=High): \frac{4}{6}\)
- \(P(Trading\ Volume=Low): \frac{2}{6}\)
如果交易量為 high 並且回報為上漲,概率為:\(P(Trading\ Volume=High\ \&\ Return\ = Up)=\frac{4}{4}\)
如果交易量為 high 並且回報為下降,概率為:\(P(Trading\ Volume = High\ \&\ Return\ = Down)=0\)
- 那麼這個基尼指數為:\(gini(Trading\ Volume=High) = 1-(\frac{4}{4}^2+0^2) = 0\)
如果交易量為 low 並且回報為上漲,概率為:\(P(Trading\ Volume = Low\ \&\ Return\ = Up)=0\)
如果交易量為 low 並且回報為下降,概率為:\(P(Trading\ Volume = Low\ \&\ Return\ = Down)=\frac{2}{2}\)
- 那麼這個基尼指數為:\(gini(Trading\ Volume=Low) = 1-(0^2+\frac{2}{2}^2) = 0\)
那麼交易量基尼指數加權 = \(\frac{4}{6} \times 0 + \frac{2}{6}\times 0 = 0\)
最終計算出的基尼指數列表如下,這裡將使用「Trading Volume」進一步拆分節點,因為它具有最小的基尼指數。
| Attributes/Features | Gini Index |
|---|---|
| Open Interest | 0.33 |
| Trading Volume | 0 |
最終的模型就如圖所示
計算資訊增益範例
我們可以根據屬於一類資料的概率分佈來考慮資料集的熵,例如,在二進位制分類資料集的情況下為兩個類。計算樣本的熵如 \(Entropy = -(P_0 \times log(P_0) + P_1 \times log(P_1)\) 。
兩類的樣本拆分為 50/50 的資料集將具最大熵(最驚訝),而拆分為 10/90 的不平衡資料集將具有較小的熵。可以通過在 Python 中計算這個不平衡資料集的熵的例子來證明這一點。
from math import log2
# 概率
class0 = 10/100
class1 = 90/100
# entropy formula
entropy = -(class0 * log2(class0) + class1 * log2(class1))
# print the result
print('entropy: %.3f bits' % entropy)
執行範例,可以看到用於二分類的資料集的熵小於 1 。也就是說,對來自資料集中的任意範例類進行編碼所需的資訊不到1。通過這種方式,熵可以用作資料集純度的計算,例如類別分佈的平衡程度。
熵為 0 位表示資料集包含一個類;1或更大位的熵表示平衡資料集的最大熵(取決於類別的數量),介於兩者之間的值表示這些極端之間的水平。
計算資訊增益範例
要求:定義一個函數來根據屬於 0 類和 1 類的樣本的比率來計算一組樣本的熵。
假設有一個20 個範例的資料集,13 個為0 類,7 個為1 類。我們可以計算該資料集的熵,它的熵小於 1 位。
from math import log2
# calculate the entropy for the split in the dataset
def entropy(class0, class1):
return -(class0 * log2(class0) + class1 * log2(class1))
# split of the main dataset
class0 = 13 / 20
class1 = 7 / 20
# calculate entropy before the change
s_entropy = entropy(class0, class1)
print('Dataset Entropy: %.3f bits' % s_entropy)
# Dataset Entropy: 0.934 bits
假設按照 value1 分割資料集,有一組 8 個樣本的資料集,7 個為第 0 類,1 個用於第 1 類。然後我們可以計算這組樣本的熵。
from math import log2
# calculate the entropy for the split in the dataset
def entropy(class0, class1):
return -(class0 * log2(class0) + class1 * log2(class1))
# split of the main dataset
s1_class0 = 7 / 8
s1_class1 = 1 / 8
# calculate entropy before the change
s_entropy = entropy(s1_class0, s1_class1)
print('Dataset Entropy: %.3f bits' % s_entropy)
# Dataset Entropy: 0.544 bits
假設現在按 value2 分割資料集;一組 12 個樣本資料集,每組 6 個。我們希望這個組的熵為 1。
from math import log2
# calculate the entropy for the split in the dataset
def entropy(class0, class1):
return -(class0 * log2(class0) + class1 * log2(class1))
# split of the main dataset
s1_class0 = 6 / 12
s1_class1 = 6 / 12
# calculate entropy before the change
s_entropy = entropy(s1_class0, s1_class1)
print('Dataset Entropy: %.3f bits' % s_entropy)
# Dataset Entropy: 1.000 bits
最後,可以根據為變數的每個值建立的組和計算的熵來計算該變數的資訊增益。例如:
第一個變數從資料集中產生一組 8 個樣本,第二組在資料集中有12 個樣本。在這種情況下,資訊增益計算:
- \(Entropy(Dataset) – (\frac{(Count(Group1)}{Count(Dataset)} \times Entropy(Group1) + \frac{Count(Group2)}{Count(Dataset)} \times Entropy(Group2)))\)
這裡是因為在每個子節點重複這個分裂過程直到空葉節點。這意味著每個節點的樣本都屬於同一類。但是,這種情況下會導致具有許多節點使非常深的樹,這很容易導致過度擬合。因此,我們通常希望通過設定樹的最大深度來修剪樹。IG就是我們想確定給定訓練特徵向的量集中的哪個屬性最有用,那麼上面的公式推理就為:
- \(IG(D_p) = I(D_p) − \frac{N_{left}}{N_p}I(D_{left})−\frac{N_{right}}{N_p}I(D_{right})\)
- \(IG(D_P)\):資料集的資訊增益
- \(I(D)\):葉子的熵或基尼指數
- \(\frac{N}{N_P}\) :頁資料集佔總資料集的比例
我們將使用它來決定決策樹 節點中屬性的順序。該行為在python中表示為:
from math import log2
# calculate the entropy for the split in the dataset
def entropy(class0, class1):
return -(class0 * log2(class0) + class1 * log2(class1))
# split of the main dataset
class0 = 13 / 20
class1 = 7 / 20
# calculate entropy before the change
s_entropy = entropy(class0, class1)
print('Dataset Entropy: %.3f bits' % s_entropy)
# split 1 (split via value1)
s1_class0 = 7 / 8
s1_class1 = 1 / 8
# calculate the entropy of the first group
s1_entropy = entropy(s1_class0, s1_class1)
print('Group1 Entropy: %.3f bits' % s1_entropy)
# split 2 (split via value2)
s2_class0 = 6 / 12
s2_class1 = 6 / 12
# calculate the entropy of the second group
s2_entropy = entropy(s2_class0, s2_class1)
print('Group2 Entropy: %.3f bits' % s2_entropy)
# calculate the information gain
gain = s_entropy - (8/20 * s1_entropy + 12/20 * s2_entropy)
print('Information Gain: %.3f bits' % gain)
# Dataset Entropy: 0.934 bits
# Group1 Entropy: 0.544 bits
# Group2 Entropy: 1.000 bits
# Information Gain: 0.117 bits
通過範例,就可以很清楚的明白了,資訊增益的概念:資訊熵-條件熵,換句話來說就是資訊增益代表了在一個條件下,資訊複雜度(不確定性)減少的程度。
python計算決策樹範例
基於基尼指數的決策樹
鈔票資料集涉及根據從照片中採取的一系列措施來預測給定鈔票是否是真實的。資料是取自真鈔和偽鈔樣樣本的影象中提取的。對於數位化,使用了通常用於印刷檢查的工業相機,從影象中提取特徵。
該資料集包含 1372 行和 5 個數值變數。這是一個二元分類的問題。
基尼指數
假設有兩組資料,每組有 2 行。第一組的行都屬於 0 類,第二組的行都屬於 1 類,所以這是一個完美的拆分。
首先需要計算每個組中類的比例。
proportion = count(class_value) / count(rows)
這個比例是
group_1_class_0 = 2 / 2 = 1
group_1_class_1 = 0 / 2 = 0
group_2_class_0 = 0 / 2 = 0
group_2_class_1 = 2 / 2 = 1
為每個子節點計算 Gini index
gini_index = sum(proportion * (1.0 - proportion))
gini_index = 1.0 - sum(proportion * proportion)
然後對每組的基尼指數按組的大小加權,例如當前正在分組的所有樣本。我們可以將此權重新增到組的基尼指數計算中,如下所示:
gini_index = (1.0 - sum(proportion * proportion)) * (group_size/total_samples)
在該案例中,每個組的基尼指數為:
Gini(group_1) = (1 - (1*1 + 0*0)) * 2/4
Gini(group_1) = 0.0 * 0.5
Gini(group_1) = 0.0 # 分類1的基尼指數
Gini(group_2) = (1 - (0*0 + 1*1)) * 2/4
Gini(group_2) = 0.0 * 0.5
Gini(group_2) = 0.0 # 分類2的基尼指數
然後在分割點的每個子節點上新增分數,以給出分割點的最終 Gini 分數,該分數可以與其他候選分割點進行比較。如該分割點的基尼係數為 \(0.0 + 0.0\) 或完美的基尼係數 0.0。
編寫一個 gini_index() 的函數,用於計算組列表和已知類值列表的基尼指數。
def gini_index(groups, classes):
print("------------")
# 計算所有樣本的分割點,計算樣本的總長度
n_instances = float(sum([len(group) for group in groups]))
# 計算每個組的總基尼指數
gini = 0.0
for group in groups:
size = float(len(group))
if size == 0: # avoid divide by zero
continue
score = 0.0
# score the group based on the score for each class
for class_val in classes:
# row[-1] 代表每個樣本的最後一個值,是否存在分類 class_val
p = [row[-1] for row in group]
p1 = p.count(class_val) / size
score += p1 * p1
# 按照對應的樣本分割點,加權重
gini += (1.0 - score) * (size / n_instances)
return gini
print(gini_index([[[1, 1], [1, 0]], [[1, 1], [1, 0]]], [0, 1]))
print(gini_index([[[1, 0], [1, 0]], [[1, 1], [1, 1]]], [0, 1]))
執行該範例會列印兩組的Gini index,最差情況的為 0.5,最少情況的指數為 0.0。

拆分
資料拆分
拆分是由資料集中的一個屬性和一個值組成。可以將其總結為要拆分的屬性的索引和拆分該屬性上的行的值。這只是索引資料行的有用簡寫。
建立拆分涉及三個部分,我們已經看過的第一個部分是計算基尼分數。剩下的兩部分是:
- 拆分資料集。
- 評估所有拆分。
拆分資料是給定資料集索引和拆分值,將資料集拆分為兩個行列表形成一個分類。具體是拆分資料集涉及遍歷每一行,檢查屬性值是否低於或高於拆分值,並將其分別分配給左組或右組。當存在兩個組時,可以按照基尼指數進行評估
編寫一個test_split()函數,它實現了拆分。
def test_split(index, value, dataset):
left, right = list(), list()
for row in dataset:
if row[index] < value:
left.append(row)
else:
right.append(row)
return left, right
評估拆分的資料
給定一個資料集,必須檢查每個屬性上的每個值作為候選拆分,評估拆分的成本並找到我們可以進行的最佳拆分。一旦找到最佳值,就可以將其用作決策樹中的節點。
這裡使用 dict 作為決策樹中的節點,因為這樣可以按名稱儲存資料。選擇最佳基尼指數並將其用作樹的新節點。
每組資料都是其小資料集,其中僅包含通過拆分過程分配給左組或右組的那些行。可以想象我們如何在構建決策樹時遞迴地再次拆分每個組。
def get_split(dataset):
class_values = list(set(row[-1] for row in dataset))
b_index, b_value, b_score, b_groups = 999, 999, 999, None
for index in range(len(dataset[0])-1):
for row in dataset:
groups = test_split(index, row[index], dataset)
gini = gini_index(groups, class_values)
if gini < b_score:
b_index, b_value, b_score, b_groups = index, row[index], gini, groups
return {'index':b_index, 'value':b_value, 'groups':b_groups}
之後準備一些測試資料集進行測試,其中 \(Y\) 是測試集的分類
X1 X2 Y
2.771244718 1.784783929 0
1.728571309 1.169761413 0
3.678319846 2.81281357 0
3.961043357 2.61995032 0
2.999208922 2.209014212 0
7.497545867 3.162953546 1
9.00220326 3.339047188 1
7.444542326 0.476683375 1
10.12493903 3.234550982 1
6.642287351 3.319983761 1
將上述程式碼整合為一起,執行該程式碼後會列印所有基尼指數,基尼指數為 0.0 或完美分割。
# Split a dataset based on an attribute and an attribute value
def test_split(index, value, dataset):
left, right = list(), list()
for row in dataset:
if row[index] < value:
left.append(row)
else:
right.append(row)
return left, right
# Calculate the Gini index for a split dataset
def gini_index(groups, classes):
# 計算兩組資料集的總數每個種類的列表數量和
n_instances = float(sum([len(group) for group in groups]))
# 計算每組的基尼值
gini = 0.0
for group in groups:
size = float(len(group))
# avoid divide by zero
if size == 0:
continue
score = 0.0
# score the group based on the score for each class
for class_val in classes:
# 拿出資料集中每行的型別,拆開是為了更好的瞭解結構
p = [row[-1] for row in group]
# print("%f / %f = %f" % (p.count(class_val), size, p.count(class_val) / size ))
# 這裡計算的是當前的分類在總資料集中佔比
p1 = p.count(class_val) / size
score += p1 * p1 # gini index formula = 1 - sum(p_i^2)
# 計算總的基尼指數,權重:當前分組佔總資料集中的數量
gini += (1.0 - score) * (size / n_instances)
return gini
# Select the best split point for a dataset
def get_split(dataset):
class_values = list(set(row[-1] for row in dataset))
b_index, b_value, b_score, b_groups = 999, 999, 999, None
for index in range(len(dataset[0])-1): # 最後分類不計算
for row in dataset:
# 根據每個值分類計算出最優基尼值,這個值就作為決策樹的節點
groups = test_split(index, row[index], dataset)
gini = gini_index(groups, class_values)
print('X%d < %.3f Gini=%.3f' % ((index+1), row[index], gini))
if gini < b_score:
b_index, b_value, b_score, b_groups = index, row[index], gini, groups
return {'index':b_index, 'value':b_value, 'groups':b_groups}
dataset = [
[2.771244718,1.784783929,0],
[1.728571309,1.169761413,0],
[3.678319846,2.81281357,0],
[3.961043357,2.61995032,0],
[2.999208922,2.209014212,0],
[7.497545867,3.162953546,1],
[9.00220326,3.339047188,1],
[7.444542326,0.476683375,1],
[10.12493903,3.234550982,1],
[6.642287351,3.319983761,1]
]
split = get_split(dataset)
print('Split: [X%d < %.3f]' % ((split['index']+1), split['value']))
通過執行結果可以看出,X1 < 6.642 Gini=0.000 基尼指數為 0.0 為完美分割。
如何構建樹
構建樹主要分為 3 個部分
- 終端節點
Terminal Nodes零度節點稱為終端節點或葉節點 - 遞迴拆分
- 建造一棵樹
終端節點
需要決定何時停止種植樹,這裡可以使用節點在訓練資料集中負責的深度和行數來做到。
- 樹的最大深度:從樹的根節點開始的最大節點數。一旦達到樹的最大深度,停止拆分新節點。
- 最小節點:對一個節點的要訓練的最小值。一旦達到或低於此最小值,則停止拆分和新增新節點。
這兩種方法將是構建樹的過程時使用者的指定引數。當在給定點停止增長時,該節點稱為終端節點,用於進行最終預測。
編寫一個函數to_terminal(),這個函數將為一組行選擇一類。它返回行列表中最常見的輸出值。
def to_terminal(group):
outcomes = [row[-1] for row in group]
return max(set(outcomes), key=outcomes.count)
遞迴拆分
構建決策樹會在為每個節點建立的組上一遍又一遍地呼叫 get_split() 函數。
新增到現有節點的新節點稱為子節點。一個節點可能有零個子節點(一個終端節點)、一個子節點或兩個子節點,這裡將在給定節點的字典表示中將子節點稱為左和右。當一旦建立出一個節點,則通過再次呼叫相同的函數來遞迴地從拆分的每組資料以建立子節點。
下面需要實現這個過程(遞迴函數)。函數接受一個節點作為引數,以及節點中的最大深度、最小模式數、節點的當前深度。
呼叫的過程分步為。設定,傳入根節點和深度1:
- 首先,將拆分後的兩組資料提取出來使用,當處理過這些組時,節點不再需要存取這些資料。
- 接下來,我們檢查左或右兩組是否為空,如果是,則使用我們擁有的記錄建立一個終端節點。
- 不為空的情況下,檢查是否達到了最大深度,如果是,則建立一個終端節點。
- 然後我們處理左子節點,如果行組太小,則建立一個終端節點,否則以深度優先的方式建立並新增左節點,直到在該分支上到達樹的底部。最後再以相同的方式處理右側。
# 建立子拆分或者終端節點
def split(node, max_depth, min_size, depth):
"""
:param node: {},分割好的的{'index':b_index, 'value':b_value, 'groups':b_groups}
:param max_depth: int, 最大深度
:param min_size:int,最小模式數
:param depth:int, 當前深度
:return: None
"""
left, right = node['groups']
del(node['groups'])
# 檢查兩邊的分割問題
if not left or not right:
node['left'] = node['right'] = to_terminal(left + right)
return
# 檢查最大的深度
if depth >= max_depth:
node['left'], node['right'] = to_terminal(left), to_terminal(right)
return
# 處理左分支,數量要小於最小模式數為terminal node
if len(left) <= min_size:
node['left'] = to_terminal(left)
else:
node['left'] = get_split(left)
split(node['left'], max_depth, min_size, depth+1) # 否則遞迴
# 處理左右支,數量要小於最小模式數為terminal node
if len(right) <= min_size:
node['right'] = to_terminal(right)
else:
node['right'] = get_split(right)
split(node['right'], max_depth, min_size, depth+1)
建立樹
構建一個樹就是一個上面的步驟的合併,通過split()函數打分並確定樹的根節點,然後通過遞回來構建出整個樹;下面程式碼是實現此過程的函數 build_tree()。
# Build a decision tree
def build_tree(train, max_depth, min_size):
"""
:param train: list, 資料集,可以是訓練集
:param max_depth: int, 最大深度
:param min_size:int,最小模式數
:return: None
"""
root = get_split(train) # 對整個資料集進行打分
split(root, max_depth, min_size, 1)
return root
整合
將全部程式碼整合為一個
# Split a dataset based on an attribute and an attribute value
def test_split(index, value, dataset):
left, right = list(), list()
for row in dataset:
if row[index] < value:
left.append(row)
else:
right.append(row)
return left, right
# Calculate the Gini index for a split dataset
def gini_index(groups, classes):
# 計算兩組資料集的總數每個種類的列表數量和
n_instances = float(sum([len(group) for group in groups]))
# 計算每組的基尼值
gini = 0.0
for group in groups:
size = float(len(group))
# avoid divide by zero
if size == 0:
continue
score = 0.0
# score the group based on the score for each class
for class_val in classes:
# 拿出資料集中每行的型別,拆開是為了更好的瞭解結構
p = [row[-1] for row in group]
# print("%f / %f = %f" % (p.count(class_val), size, p.count(class_val) / size ))
# 這裡計算的是當前的分類在總資料集中佔比
p1 = p.count(class_val) / size
score += p1 * p1 # gini index formula = 1 - sum(p_i^2)
# 計算總的基尼指數,權重:當前分組佔總資料集中的數量
gini += (1.0 - score) * (size / n_instances)
return gini
# Select the best split point for a dataset
def get_split(dataset):
class_values = list(set(row[-1] for row in dataset))
b_index, b_value, b_score, b_groups = 999, 999, 999, None
for index in range(len(dataset[0])-1): # 最後分類不計算
for row in dataset:
# 根據每個值分類計算出最優基尼值,這個值就作為決策樹的節點
groups = test_split(index, row[index], dataset)
gini = gini_index(groups, class_values)
# print('X%d < %.3f Gini=%.3f' % ((index+1), row[index], gini))
if gini < b_score: # 拿到最小的gini index那列
b_index, b_value, b_score, b_groups = index, row[index], gini, groups
return {'index':b_index, 'value':b_value, 'groups':b_groups}
# 建立子拆分或者終端節點
def split(node, max_depth, min_size, depth):
"""
:param node: {},分割好的的{'index':b_index, 'value':b_value, 'groups':b_groups}
:param max_depth: int, 最大深度
:param min_size:int,最小模式數
:param depth:int, 當前深度
:return: None
"""
left, right = node['groups']
del(node['groups'])
# 檢查兩邊的分割問題
if not left or not right:
node['left'] = node['right'] = to_terminal(left + right)
return
# 檢查最大的深度
if depth >= max_depth:
node['left'], node['right'] = to_terminal(left), to_terminal(right)
return
# 處理左分支,數量要小於最小模式數為terminal node
if len(left) <= min_size:
node['left'] = to_terminal(left)
else:
node['left'] = get_split(left)
split(node['left'], max_depth, min_size, depth+1) # 否則遞迴
# 處理左右支,數量要小於最小模式數為terminal node
if len(right) <= min_size:
node['right'] = to_terminal(right)
else:
node['right'] = get_split(right)
split(node['right'], max_depth, min_size, depth+1)
# Build a decision tree
def build_tree(train, max_depth, min_size):
"""
:param train: list, 資料集,可以是訓練集
:param max_depth: int, 最大深度
:param min_size:int,最小模式數
:return: None
"""
root = get_split(train) # 對整個資料集進行打分
split(root, max_depth, min_size, 1)
return root
# 列印樹
def print_tree(node, depth=0):
if isinstance(node, dict):
print('%s[X%d < %.3f]' % ( (depth*' ', (node['index']+1), node['value']) ))
print_tree(node['left'], depth+1) # 遞迴列印左右
print_tree(node['right'], depth+1)
else:
print('%s[%s]' % ((depth*' ', node))) # 不是物件就是terminal node
# 建立一個terminal node
def to_terminal(group):
outcomes = [row[-1] for row in group]
return max(set(outcomes), key=outcomes.count)
dataset = [
[2.771244718,1.784783929,0],
[1.728571309,1.169761413,0],
[3.678319846,2.81281357,0],
[3.961043357,2.61995032,0],
[2.999208922,2.209014212,0],
[7.497545867,3.162953546,1],
[9.00220326,3.339047188,1],
[7.444542326,0.476683375,1],
[10.12493903,3.234550982,1],
[6.642287351,3.319983761,1]
]
if __name__=='__main__':
tree = build_tree(dataset, 4, 2)
print_tree(tree)
可以看到列印結果是一個類似二元樹的
[X1 < 6.642]
[X1 < 2.771]
[0]
[X1 < 2.771]
[0]
[0]
[X1 < 7.498]
[X1 < 7.445]
[1]
[1]
[X1 < 7.498]
[1]
[1]
預測
預測是預測資料是該向右還是向左,是作為對資料進行導航的方式。這裡可以使用遞回來實現,其中使用左側或右側子節點再次呼叫相同的預測,具體取決於拆分如何影響提供的資料。
我們必須檢查子節點是否是要作為預測返回的終端值,或者它是否是包含要考慮的樹的另一個級別的字典節點。
下面是實現此過程的函數 predict()。
# Make a prediction with a decision tree
def predict(node, row):
if row[node['index']] < node['value']:
if isinstance(node['left'], dict):
return predict(node['left'], row)
else:
return node['left']
else:
if isinstance(node['right'], dict):
return predict(node['right'], row)
else:
return node['right']
下面是一個使用寫死決策樹的範例,該決策樹具有一個最好地分割資料的節點(決策樹樁,這個就是gini index的最優質值)。通過對上面的測試資料集例來對每一行進行預測。
def predict(node, row):
# 如果gini index與對應屬性的值小於則向左,
if row[node['index']] < node['value']:
if isinstance(node['left'], dict):
return predict(node['left'], row) # 遞迴處理完整個樹
else:
return node['left']
else: # 否則的話,則為右
if isinstance(node['right'], dict):
return predict(node['right'], row)
else:
return node['right']
dataset = [[2.771244718,1.784783929,0],
[1.728571309,1.169761413,0],
[3.678319846,2.81281357,0],
[3.961043357,2.61995032,0],
[2.999208922,2.209014212,0],
[7.497545867,3.162953546,1],
[9.00220326,3.339047188,1],
[7.444542326,0.476683375,1],
[10.12493903,3.234550982,1],
[6.642287351,3.319983761,1]]
# 這是之前用於計算出最優的gini index
stump = {'index': 0, 'right': 1, 'value': 6.642287351, 'left': 0}
for row in dataset:
prediction = predict(stump, row)
print('Expected=%d, Got=%d' % (row[-1], prediction))
通過觀察可以看出預測結果和實際結果一樣
Expected=0, Got=0
Expected=0, Got=0
Expected=0, Got=0
Expected=0, Got=0
Expected=0, Got=0
Expected=1, Got=1
Expected=1, Got=1
Expected=1, Got=1
Expected=1, Got=1
Expected=1, Got=1
套用真實資料集來測試
這裡將使用 CART 演演算法對銀行鈔票資料集進行預測。大概的流程為:
- 載入資料集並轉換格式。
- 編寫拆分演演算法與準確度計算演演算法;這裡使用 5折的k折交叉驗證(
k-fold cross validation)用於評估演演算法 - 編寫 CART 演演算法,從訓練資料集,建立樹,對測試資料集進行預測操作
什麼是 K折交叉驗證
K折較差驗證(K-Fold CV)是將給定的資料集分成K個部分,其中每個摺疊在某時用作測試集。以 5 折(K=5)為例。這種情況下,資料集被分成5份。在第一次迭代中,第一份用於測試模型,其餘用於訓練模型。在第二次迭代中,第 2 份用作測試集,其餘用作訓練集。重複這個過程,直到 5 個摺疊中的每個摺疊都被用作測試集。
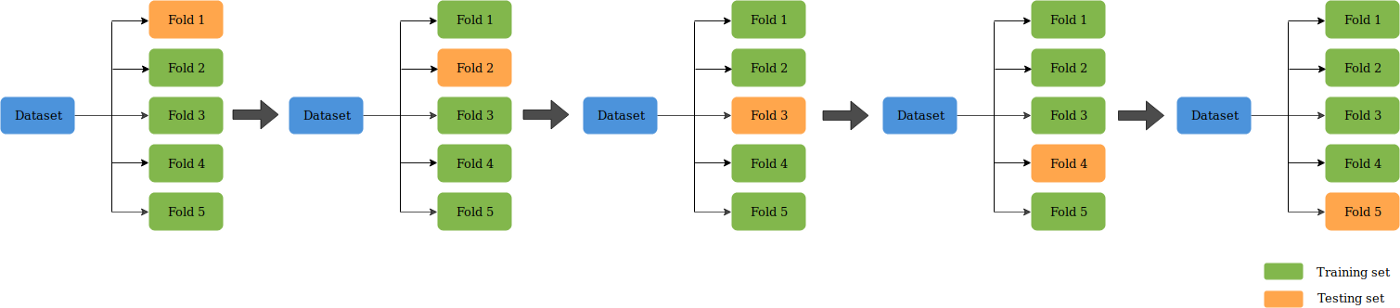
下面來開始編寫函數,函數的整個過程為
evaluate_algorithm()作為最外層呼叫- 使用五折交叉進行評估
cross_validation_split() - 使用決策樹演演算法作為演演算法根據
decision_tree() - 構建樹:
build_tree()- 拿到最優基尼指數作為葉子
get_split()
- 拿到最優基尼指數作為葉子
- 使用五折交叉進行評估
from random import seed
from random import randrange
from csv import reader
# 載入csv檔案
def load_csv(filename):
file = open(filename, "rt")
lines = reader(file)
dataset = list(lines)
return dataset
# 將所有欄位轉換為float型別便於計算
def str_column_to_float(dataset, column):
for row in dataset:
row[column] = float(row[column].strip())
# k-folds CV函數
def cross_validation_split(dataset, n_folds):
dataset_split = list()
dataset_copy = list(dataset)
# 平均分位折數n_folds
fold_size = int(len(dataset) / n_folds)
for i in range(n_folds):
fold = list()
while len(fold) < fold_size:
index = randrange(len(dataset_copy)) # 隨機
fold.append(dataset_copy.pop(index))
dataset_split.append(fold)
return dataset_split
# 計算精確度
def accuracy_metric(actual, predicted):
correct = 0
for i in range(len(actual)):
if actual[i] == predicted[i]:
correct += 1
return correct / float(len(actual)) * 100.0
# Evaluate an algorithm using a cross validation split
def evaluate_algorithm(dataset, algorithm, n_folds, *args):
folds = cross_validation_split(dataset, n_folds)
scores = list()
for fold in folds:
train_set = list(folds)
train_set.remove(fold)
train_set = sum(train_set, [])
test_set = list()
for row in fold:
row_copy = list(row)
test_set.append(row_copy)
row_copy[-1] = None
predicted = algorithm(train_set, test_set, *args)
actual = [row[-1] for row in fold]
accuracy = accuracy_metric(actual, predicted)
scores.append(accuracy)
return scores
# 根據基尼指數劃分value是應該在樹的哪邊?
def test_split(index, value, dataset):
left, right = list(), list()
for row in dataset:
if row[index] < value:
left.append(row)
else:
right.append(row)
return left, right
# 基尼指數打分
def gini_index(groups, classes):
# 計算資料集中的多組資料的總個數
n_instances = float(sum([len(group) for group in groups]))
# 計算每組中的最優基尼指數
gini = 0.0
for group in groups:
size = float(len(group))
if size == 0:
continue
score = 0.0
# 總基尼指數
for class_val in classes:
# 拿出資料集中每行的型別,拆開是為了更好的瞭解結構
# 計算的是當前的分類在總資料集中佔比
p = [row[-1] for row in group]
p1 = p.count(class_val) / size
score += p1 * p1
# 計算總的基尼指數,並根據相應大小增加權重。權重:當前分組佔總資料集中的數量
gini += (1.0 - score) * (size / n_instances)
return gini
# 從資料集中獲得基尼指數最佳的值
def get_split(dataset):
class_values = list(set(row[-1] for row in dataset))
b_index, b_value, b_score, b_groups = 999, 999, 999, None
for index in range(len(dataset[0])-1):
for row in dataset:
groups = test_split(index, row[index], dataset)
gini = gini_index(groups, class_values)
if gini < b_score:
b_index, b_value, b_score, b_groups = index, row[index], gini, groups
return {'index':b_index, 'value':b_value, 'groups':b_groups}
# 建立終端節點
def to_terminal(group):
outcomes = [row[-1] for row in group]
return max(set(outcomes), key=outcomes.count)
# 建立子節點,為終端節點或子節點
def split(node, max_depth, min_size, depth):
"""
:param node: {},分割好的的{'index':b_index, 'value':b_value, 'groups':b_groups}
:param max_depth: int, 最大深度
:param min_size:int,最小模式數
:param depth:int, 當前深度
:return: None
"""
left, right = node['groups']
del(node['groups'])
# check for a no split
if not left or not right:
node['left'] = node['right'] = to_terminal(left + right)
return
# check for max depth
if depth >= max_depth:
node['left'], node['right'] = to_terminal(left), to_terminal(right)
return
# process left child
if len(left) <= min_size:
node['left'] = to_terminal(left)
else:
node['left'] = get_split(left)
split(node['left'], max_depth, min_size, depth+1)
# process right child
if len(right) <= min_size:
node['right'] = to_terminal(right)
else:
node['right'] = get_split(right)
split(node['right'], max_depth, min_size, depth+1)
# 構建樹
def build_tree(train, max_depth, min_size):
"""
:param train: list, 資料集,可以是訓練集
:param max_depth: int, 最大深度
:param min_size:int,最小模式數
:ret
"""
root = get_split(train)
split(root, max_depth, min_size, 1)
return root
# 列印樹
def print_tree(node, depth=0):
if isinstance(node, dict):
print('%s[X%d < %.3f]' % ( (depth*' ', (node['index']+1), node['value']) ))
print_tree(node['left'], depth+1) # 遞迴列印左右
print_tree(node['right'], depth+1)
else:
print('%s[%s]' % ((depth*' ', node))) # 不是物件就是terminal node
# 預測,預測方式為當前基尼指數與最優基尼指數相比較,然後放入樹兩側
def predict(node, row):
"""
:param node: {} 葉子值
:param row: {}, 需要預測值
:ret
"""
if row[node['index']] < node['value']:
if isinstance(node['left'], dict):
return predict(node['left'], row)
else:
return node['left']
else:
if isinstance(node['right'], dict):
return predict(node['right'], row)
else:
return node['right']
def decision_tree(train, test, max_depth, min_size):
tree = build_tree(train, max_depth, min_size)
predictions = list()
for row in test:
prediction = predict(tree, row)
predictions.append(prediction)
return(predictions)
# Test CART on Bank Note dataset
seed(1)
# 載入資料
filename = 'data_banknote_authentication.csv'
dataset = load_csv(filename)
# 轉換格式
for i in range(len(dataset[0])):
str_column_to_float(dataset, i)
# 評估演演算法
n_folds = 5
max_depth = 5
min_size = 10
scores = evaluate_algorithm(dataset, decision_tree, n_folds, max_depth, min_size)
print('Scores: %s' % scores)
print('Mean Accuracy: %.3f%%' % (sum(scores)/float(len(scores))))
Reference