深度學習與CV教學(8) | 常見深度學習框架介紹

- 作者:韓信子@ShowMeAI
- 教學地址:http://www.showmeai.tech/tutorials/37
- 本文地址:http://www.showmeai.tech/article-detail/267
- 宣告:版權所有,轉載請聯絡平臺與作者並註明出處
- 收藏ShowMeAI檢視更多精彩內容

本系列為 斯坦福CS231n 《深度學習與計算機視覺(Deep Learning for Computer Vision)》的全套學習筆記,對應的課程視訊可以在 這裡 檢視。更多資料獲取方式見文末。
引言
大家在前序文章中學習了很多關於神經網路的原理知識和實戰技巧,在本篇內容中ShowMeAI給大家展開介紹深度學習硬體知識,以及目前主流的深度學習框架TensorFlow和pytorch相關知識,藉助於工具大家可以實際搭建與訓練神經網路。
本篇重點
- 深度學習硬體
- CPU、GPU、TPU
- 深度學習框架
- PyTorch / TensorFlow
- 靜態與動態計算圖
1.深度學習硬體
GPU(Graphics Processing Unit)是圖形處理單元(又稱顯示卡),在物理尺寸上就比 CPU(Central Processing Unit)大得多,有自己的冷卻系統。最初用於渲染計算機圖形,尤其是遊戲。在深度學習上選擇 NVIDIA(英偉達)的顯示卡,如果使用AMD的顯示卡會遇到很多問題。TPU(Tensor Processing Units)是專用的深度學習硬體。
1.1 CPU / GPU / TPU
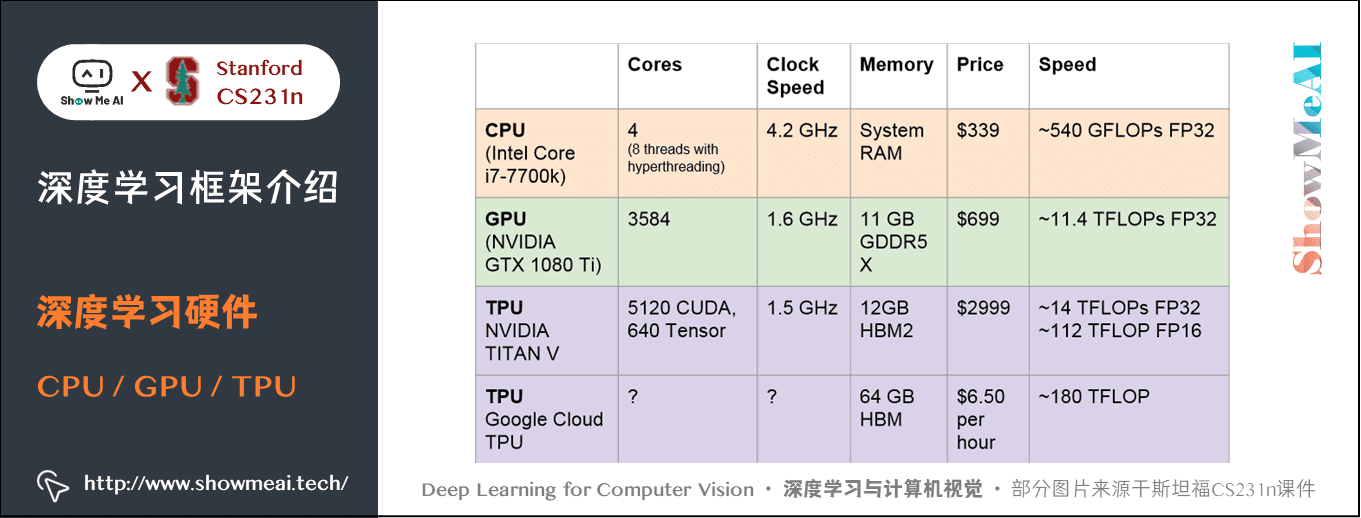
- CPU一般有多個核心,每個核心速度都很快都可以獨立工作,可同時進行多個程序,記憶體與系統共用,完成序列任務時很有用。圖上CPU的執行速度是每秒約 540 GFLOPs 浮點數運算,使用 32 位浮點數(注:一個 GFLOPS(gigaFLOPS)等於每秒十億(\(=10^9\))次的浮點運算)。
- GPU有上千個核心數,但每個核心執行速度很慢,也不能獨立工作,適合大量的並行完成類似的工作。GPU一般自帶記憶體,也有自己的快取系統。圖上GPU的執行速度是CPU的20多倍。
- TPU是專門的深度學習硬體,執行速度非常快。TITANV 在技術上並不是一個「TPU」,因為這是一個谷歌術語,但兩者都有專門用於深度學習的硬體。執行速度非常快。
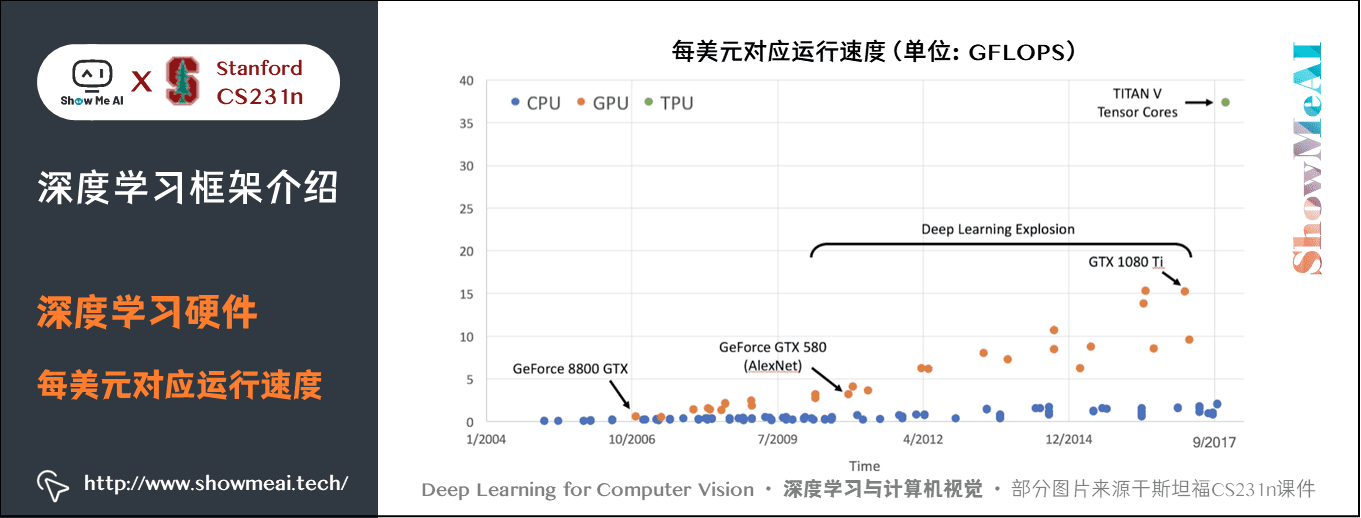
若是將這些執行速度除以對應的價格,可得到下圖:
1.2 GPU的優勢與應用
GPU 在大矩陣的乘法運算中有很明顯的優勢。
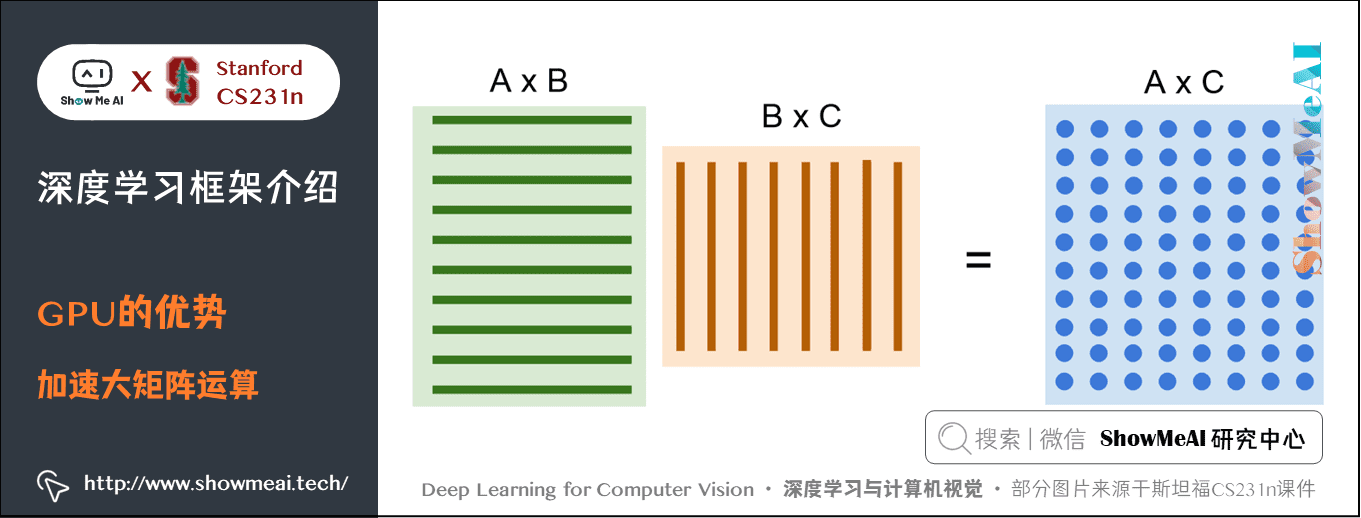
由於結果中的每一個元素都是相乘的兩個矩陣的每一行和每一列的點積,所以並行的同時進行這些點積運算速度會非常快。折積神經網路也類似,折積核和圖片的每個區域進行點積也是並行運算。
CPU 雖然也有多個核心,但是在大矩陣運算時只能序列運算,速度很慢。
可以寫出在 GPU 上直接執行的程式碼,方法是使用NVIDIA自帶的抽象程式碼 CUDA ,可以寫出類似 C 的程式碼,並可以在 GPU 直接執行。
但是直接寫 CUDA 程式碼是一件非常困難的事,好在可以直接使用 NVIDIA 已經高度優化並且開源的API,比如 cuBLAS 包含很多矩陣運算, cuDNN 包含 CNN 前向傳播、反向傳播、批次歸一化等操作;還有一種語言是 OpenCL,可以在 CPU、AMD 上通用,但是沒人做優化,速度很慢;HIP可以將CUDA 程式碼自動轉換成可以在 AMD 上執行的語言。以後可能會有跨平臺的標準,但是現在來看 CUDA 是最好的選擇。
在實際應用中,同樣的計算任務,GPU 比 CPU 要快得多,當然 CPU 還能進一步優化。使用 cuDNN 也比不使用要快接近三倍。
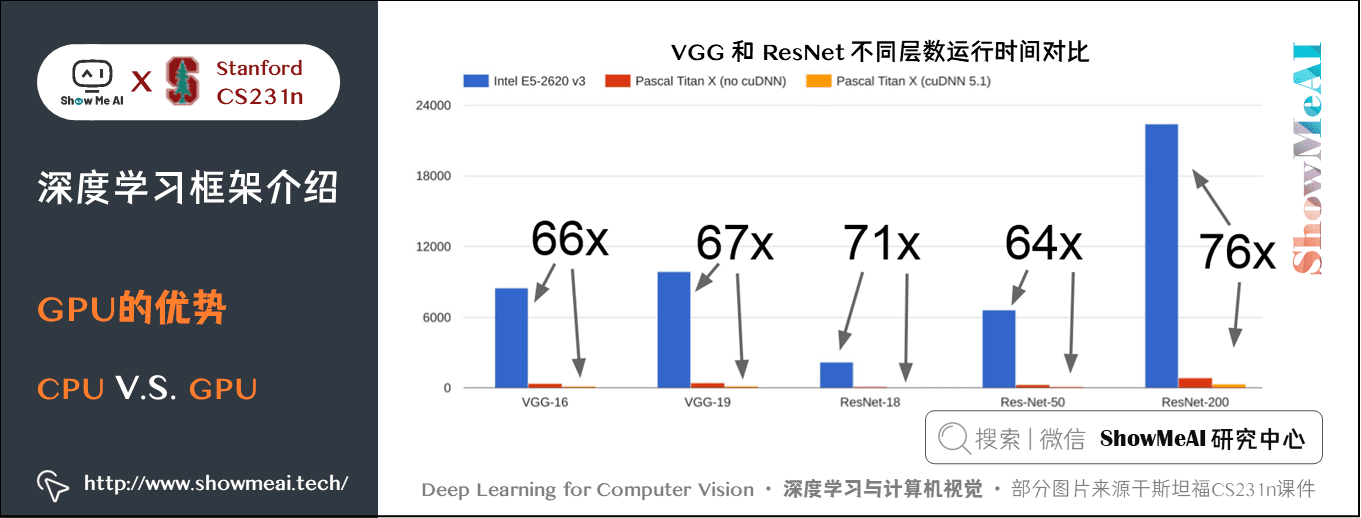
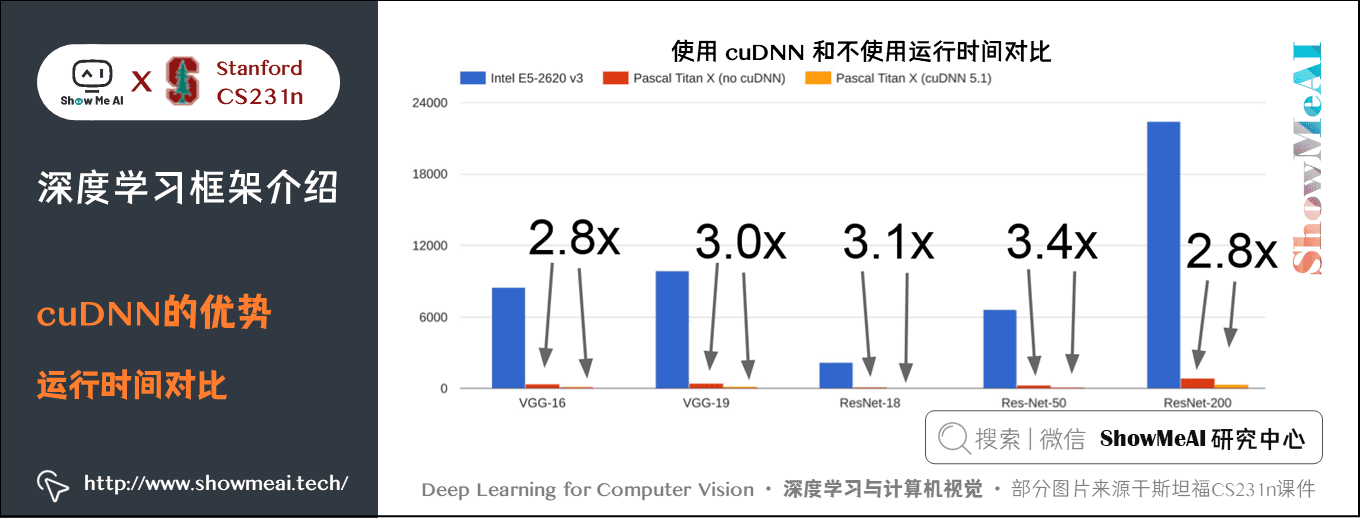
實際應用 GPU 還有一個問題是訓練的模型一般存放在 GPU,而用於訓練的資料存放在硬碟裡,由於 GPU 執行快,而機械硬碟讀取慢,就會拖累整個模型的訓練速度。有多種解決方法:
- 如果訓練資料數量較小,可以把所有資料放到 GPU 的 RAM 中;
- 用固態硬碟代替機械硬碟;
- 使用多個 CPU 執行緒預讀取資料,放到快取供 GPU 使用。
2.深度學習軟體
2.1 DL軟體概述
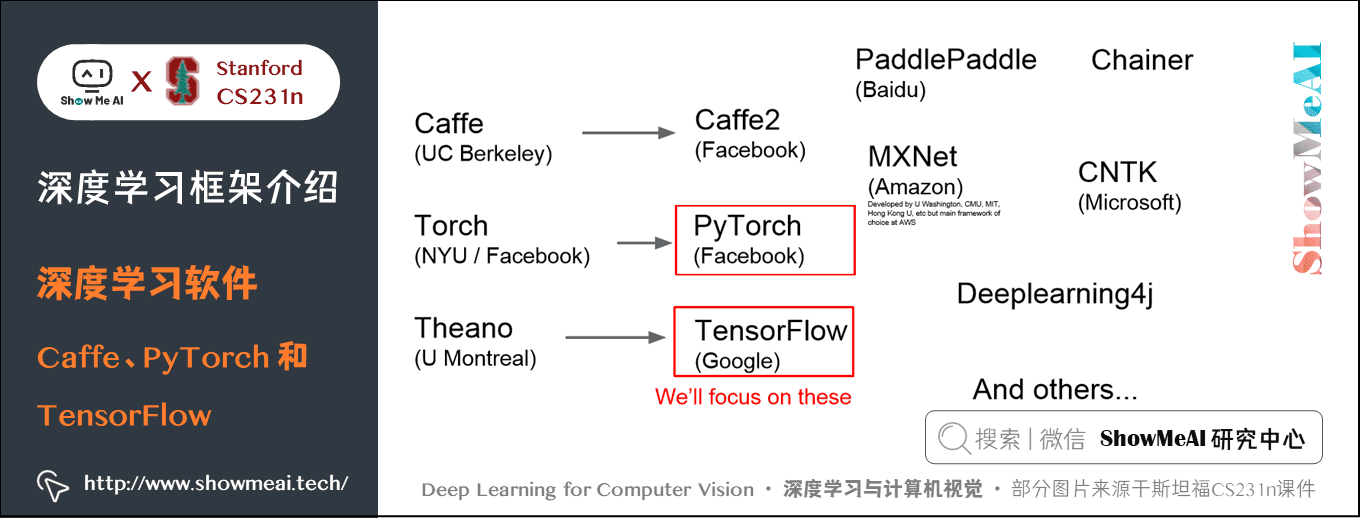
現在有很多種深度學習框架,目前最流行的是 TensorFlow。
第一代框架大多由學術界編寫的,比如 Caffe 就是伯克利大學開發的。
第二代往往由工業界主導,比如 Caffe2 是由 Facebook 開發。這裡主要講解 PyTorch 和 TensorFlow。
回顧之前計算圖的概念,一個線性分類器可以用計算圖表示,網路越複雜,計算圖也越複雜。之所以使用這些深度學習框架有三個原因:
- 構建大的計算圖很容易,可以快速的開發和測試新想法;
- 這些框架都可以自動計算梯度只需寫出前向傳播的程式碼;
- 可以在 GPU 上高效的執行,已經擴充套件了 cuDNN 等包以及處理好資料如何在 CPU 和 GPU 中流動。
這樣我們就不用從頭開始完成這些工作了。
比如下面的一個計算圖:
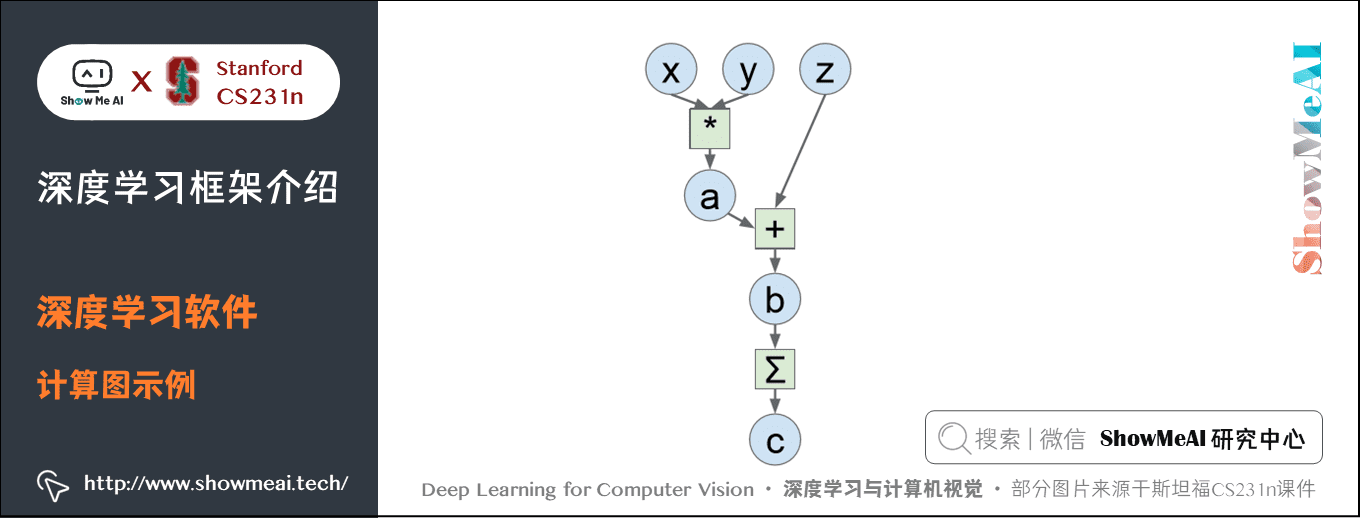
我們以前的做法是使用 Numpy 寫出前向傳播,然後計算梯度,程式碼如下:
import numpy as np
np.random.seed(0) # 保證每次的亂數一致
N, D = 3, 4
x = np.random.randn(N, D)
y = np.random.randn(N, D)
z = np.random.randn(N, D)
a = x * y
b = a + z
c = np.sum(b)
grad_c = 1.0
grad_b = grad_c * np.ones((N, D))
grad_a = grad_b.copy()
grad_z = grad_b.copy()
grad_x = grad_a * y
grad_y = grad_a * x
這種做法 API 乾淨,易於編寫程式碼,但問題是沒辦法在 GPU 上執行,並且需要自己計算梯度。所以現在大部分深度學習框架的主要目標是自己寫好前向傳播程式碼,類似 Numpy,但能在 GPU 上執行且可以自動計算梯度。
TensorFlow 版本,前向傳播構建計算圖,梯度可以自動計算:
import numpy as np
np.random.seed(0)
import tensorflow as tf
N, D = 3, 4
# 建立前向計算圖
x = tf.placeholder(tf.float32)
y = tf.placeholder(tf.float32)
z = tf.placeholder(tf.float32)
a = x * y
b = a + z
c = tf.reduce_sum(b)
# 計算梯度
grad_x, grad_y, grad_z = tf.gradients(c, [x, y, z])
with tf.Session() as sess:
values = {
x: np.random.randn(N, D),
y: np.random.randn(N, D),
z: np.random.randn(N, D),
}
out = sess.run([c, grad_x, grad_y, grad_z], feed_dict=values)
c_val, grad_x_val, grad_y_val, grad_z_val = out
print(c_val)
print(grad_x_val)
PyTorch版本,前向傳播與Numpy非常類似,但反向傳播可以自動計算梯度,不用再去實現。
import torch
device = 'cuda:0' # 在GPU上執行,即構建GPU版本的矩陣
# 前向傳播與Numpy類似
N, D = 3, 4
x = torch.randn(N, D, requires_grad=True, device=device)
# requires_grad要求自動計算梯度,預設為True
y = torch.randn(N, D, device=device)
z = torch.randn(N, D, device=device)
a = x * y
b = a + z
c = torch.sum(b)
c.backward() # 反向傳播可以自動計算梯度
print(x.grad)
print(y.grad)
print(z.grad)
可見這些框架都能自動計算梯度並且可以自動在 GPU 上執行。
2.2 TensoFlow
關於TensorFlow的用法也可以閱讀ShowMeAI的製作的 TensorFlow 速查表,對應文章AI 建模工具速查 | TensorFlow使用指南和AI建模工具速查 | Keras使用指南。
下面以一個兩層的神經網路為例,非線性函數使用 ReLU 函數、損失函數使用 L2 正規化(當然僅僅是一個學習範例)。
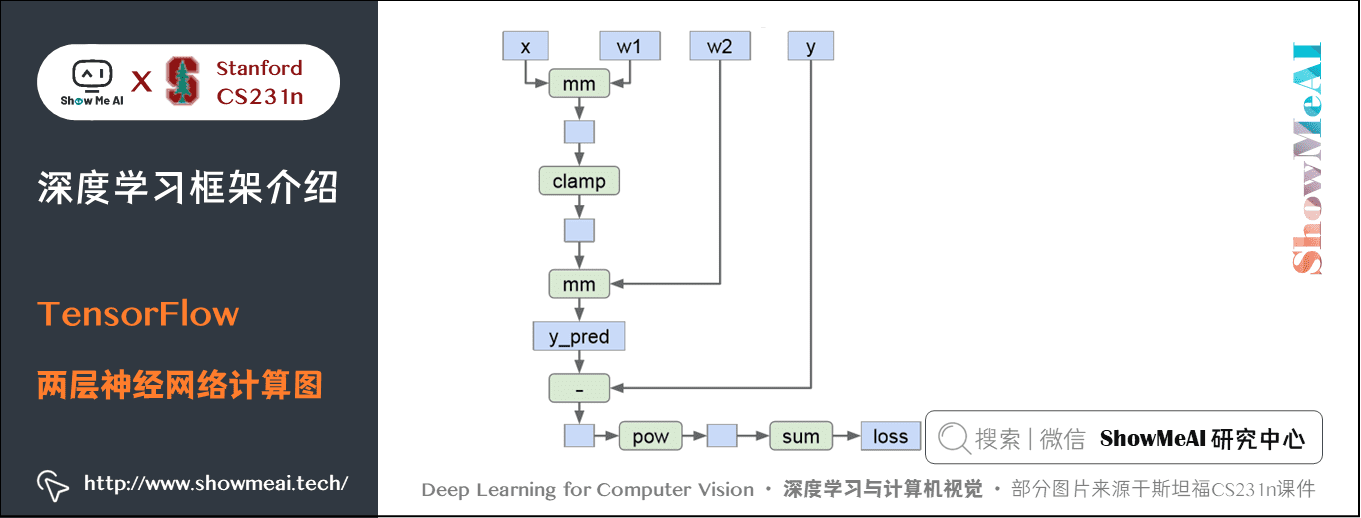
實現程式碼如下:
1) 神經網路
import numpy as np
import tensorflow as tf
N, D , H = 64, 1000, 100
# 建立前向計算圖
x = tf.placeholder(tf.float32, shape=(N, D))
y = tf.placeholder(tf.float32, shape=(N, D))
w1 = tf.placeholder(tf.float32, shape=(D, H))
w2 = tf.placeholder(tf.float32, shape=(H, D))
h = tf.maximum(tf.matmul(x, w1), 0) # 隱藏層使用折葉函數
y_pred = tf.matmul(h, w2)
diff = y_pred - y # 差值矩陣
loss = tf.reduce_mean(tf.reduce_sum(diff ** 2, axis=1)) # 損失函數使用L2範數
# 計算梯度
grad_w1, grad_w2 = tf.gradients(loss, [w1, w2])
# 多次執行計算圖
with tf.Session() as sess:
values = {
x: np.random.randn(N, D),
y: np.random.randn(N, D),
w1: np.random.randn(D, H),
w2: np.random.randn(H, D),
}
out = sess.run([loss, grad_w1, grad_w2], feed_dict=values)
loss_val, grad_w1_val, grad_w2_val = out
整個過程可以分成兩部分,with 之前部分定義計算圖,with 部分多次執行計算圖。這種模式在TensorFlow 中很常見。
- 首先,我們建立了
x,y,w1,w2四個tf.placeholder物件,這四個變數作為「輸入槽」,下面再輸入資料。 - 然後使用這四個變數建立計算圖,使用矩陣乘法
tf.matmul和折葉函數tf.maximum計算y_pred,使用 L2 距離計算 s 損失。但是目前並沒有實際的計算,因為只是構建了計算圖並沒有輸入任何資料。 - 然後通過一行神奇的程式碼計算損失值關於
w1和w2的梯度。此時仍然沒有實際的運算,只是構建計算圖,找到 loss 關於w1和w2的路徑,在原先的計算圖上增加額外的關於梯度的計算。 - 完成計算圖後,建立一個對談 Session 來執行計算圖和輸入資料。進入到 Session 後,需要提供 Numpy 陣列給上面建立的「輸入槽」。
- 最後兩行程式碼才是真正的執行,執行
sess.run需要提供 Numpy 陣列字典feed_dict和需要輸出的計算值 loss ,grad_w1,grad_w2` ,最後通過解包獲取 Numpy 陣列。
上面的程式碼只是執行了一次,我們需要迭代多次,並設定超引數、引數更新方式等:
with tf.Session() as sess:
values = {
x: np.random.randn(N, D),
y: np.random.randn(N, D),
w1: np.random.randn(D, H),
w2: np.random.randn(H, D),
}
learning_rate = 1e-5
for t in range(50):
out = sess.run([loss, grad_w1, grad_w2], feed_dict=values)
loss_val, grad_w1_val, grad_w2_val = out
values[w1] -= learning_rate * grad_w1_val
values[w2] -= learning_rate * grad_w2_val
這種迭代方式有一個問題是每一步需要將Numpy和陣列提供給GPU,GPU計算完成後再解包成Numpy陣列,但由於CPU與GPU之間的傳輸瓶頸,非常不方便。
解決方法是將 w1 和 w2 作為變數而不再是「輸入槽」,變數可以一直存在於計算圖上。
由於現在 w1 和 w2 變成了變數,所以就不能從外部輸入 Numpy 陣列來初始化,需要由 TensorFlow 來初始化,需要指明初始化方式。此時仍然沒有具體的計算。
w1 = tf.Variable(tf.random_normal((D, H)))
w2 = tf.Variable(tf.random_normal((H, D)))
現在需要將引數更新操作也新增到計算圖中,使用賦值操作 assign 更新 w1 和 w2,並儲存在計算圖中(位於計算梯度後面):
learning_rate = 1e-5
new_w1 = w1.assign(w1 - learning_rate * grad_w1)
new_w2 = w2.assign(w2 - learning_rate * grad_w2)
現在執行這個網路,需要先執行一步引數的初始化 tf.global_variables_initializer(),然後執行多次程式碼計算損失值:
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
values = {
x: np.random.randn(N, D),
y: np.random.randn(N, D),
}
for t in range(50):
loss_val, = sess.run([loss], feed_dict=values)
2) 優化器
上面的程式碼,實際訓練過程中損失值不會變。
原因是我們執行的 sess.run([loss], feed_dict=values) 語句只會計算 loss,TensorFlow 非常高效,與損失值無關的計算一律不會進行,所以引數就無法更新。
一個解決辦法是在執行 run 時加入計算兩個引數,這樣就會強制執行引數更新,但是又會產生CPU 與 GPU 的通訊問題。
一個技巧是在計算圖中加入兩個引數的依賴,在執行時需要計算這個依賴,這樣就會讓引數更新。這個技巧是 group 操作,執行完引數賦值操作後,執行 updates = tf.group(new_w1, new_w2),這個操作會在計算圖上建立一個節點;然後執行的程式碼修改為 loss_val, _ = sess.run([loss, updates], feed_dict=values),在實際運算時,updates 返回值為空。
這種方式仍然不夠方便,好在 TensorFlow 提供了更便捷的操作,使用自帶的優化器。優化器需要提供學習率引數,然後進行引數更新。有很多優化器可供選擇,比如梯度下降、Adam等。
optimizer = tf.train.GradientDescentOptimizer(1e-5) # 使用優化器
updates = optimizer.minimize(loss) # 更新方式是使loss下降,內部其實使用了group
執行的程式碼也是:loss_val, _ = sess.run([loss, updates], feed_dict=values)
3) 損失
計算損失的程式碼也可以使用 TensorFlow 自帶的函數:
loss = tf.losses.mean_squared_error(y_pred, y) # 損失函數使用L2範數
4) 層
目前仍有一個很大的問題是 x,y,w1,w2 的形狀需要我們自己去定義,還要保證它們能正確連線在一起,此外還有偏差。如果使用折積層、批次歸一化等層後,這些定義會更加麻煩。
TensorFlow可以解決這些麻煩:
N, D , H = 64, 1000, 100
x = tf.placeholder(tf.float32, shape=(N, D))
y = tf.placeholder(tf.float32, shape=(N, D))
init = tf.variance_scaling_initializer(2.0) # 權重初始化使用He初始化
h = tf.layers.dense(inputs=x, units=H, activation=tf.nn.relu, kernel_initializer=init)
# 隱藏層使用折葉函數
y_pred = tf.layers.dense(inputs=h, units=D, kernel_initializer=init)
loss = tf.losses.mean_squared_error(y_pred, y) # 損失函數使用L2範數
optimizer = tf.train.GradientDescentOptimizer(1e-5)
updates = optimizer.minimize(loss)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
values = {
x: np.random.randn(N, D),
y: np.random.randn(N, D),
}
for t in range(50):
loss_val, _ = sess.run([loss, updates], feed_dict=values)
上面的程式碼,x,y 的初始化沒有變化,但是引數 w1,w2 隱藏起來了,初始化使用 He初始化。
前向傳播的計算使用了全連線層 tf.layers.dense,該函數需要提供輸入資料 inputs、該層的神經元數目 units、啟用函數 activation、折積核(權重)初始化方式 kernel_initializer 等引數,可以自動設定權重和偏差。
5) High level API:tensorflow.keras
Keras 是基於 TensorFlow 的更高層次的封裝,會讓整個過程變得簡單,曾經是第三方庫,現在已經被內建到了 TensorFlow。
使用 Keras 的部分程式碼如下,其他與上文一致:
N, D , H = 64, 1000, 100
x = tf.placeholder(tf.float32, shape=(N, D))
y = tf.placeholder(tf.float32, shape=(N, D))
model = tf.keras.Sequential() # 使用一系列層的組合方式
# 新增一系列的層
model.add(tf.keras.layers.Dense(units=H, input_shape=(D,), activation=tf.nn.relu))
model.add(tf.keras.layers.Dense(D))
# 呼叫模型獲取結果
y_pred = model(x)
loss = tf.losses.mean_squared_error(y_pred, y)
這種模型已經簡化了很多工作,最終版本程式碼如下:
import numpy as np
import tensorflow as tf
N, D , H = 64, 1000, 100
# 建立模型,新增層
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(units=H, input_shape=(D,), activation=tf.nn.relu))
model.add(tf.keras.layers.Dense(D))
# 設定模型:損失函數、引數更新方式
model.compile(optimizer=tf.keras.optimizers.SGD(lr=1e-5), loss=tf.keras.losses.mean_squared_error)
x = np.random.randn(N, D)
y = np.random.randn(N, D)
# 訓練
history = model.fit(x, y, epochs=50, batch_size=N)
程式碼非常簡潔:
- 定義模型:
tf.keras.Sequential()表明模型是一系列的層,然後新增兩個全連線層,並設定啟用函數、每層的神經元數目等; - 設定模型:用
model.compile方法設定模型的優化器、損失函數等; - 基於資料訓練模型:使用
model.fit,需要設定迭代週期次數、批次數等,可以直接用原始資料訓練模型。
6) 其他知識
① 常見的拓展包
- Keras (https://keras.io/)
- TensorFlow內建:
- tf.keras (https://www.tensorflow.org/api_docs/python/tf/keras)
- tf.layers (https://www.tensorflow.org/api_docs/python/tf/layers)
- tf.estimator (https://www.tensorflow.org/api_docs/python/tf/estimator)
- tf.contrib.estimator (https://www.tensorflow.org/api_docs/python/tf/contrib/estimator)
- tf.contrib.layers (https://www.tensorflow.org/api_docs/python/tf/contrib/layers)
- tf.contrib.slim (https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/slim)
- tf.contrib.learn (https://www.tensorflow.org/api_docs/python/tf/contrib/learn) (棄用)
- Sonnet (https://github.com/deepmind/sonnet) (by DeepMind)
- 第三方包:
- TFLearn (http://tflearn.org/)
- TensorLayer (http://tensorlayer.readthedocs.io/en/latest/) TensorFlow: High-Level
② 預訓練模型
TensorFlow已經有一些預訓練好的模型可以直接拿來用,利用遷移學習,微調引數。
- tf.keras: (https://www.tensorflow.org/api_docs/python/tf/keras/applications)
- TF-Slim: (https://github.com/tensorflow/models/tree/master/slim/nets)
③ Tensorboard
- 增加紀錄檔記錄損失值和狀態
- 繪製影象
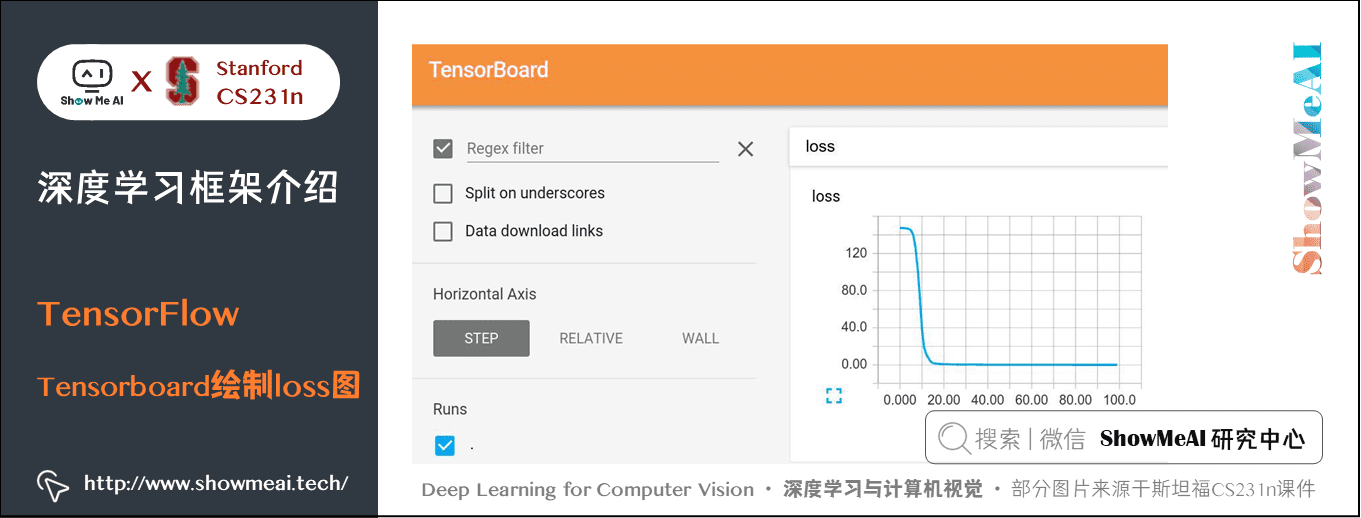
④ 分散式操作
可以在多臺機器上執行,谷歌比較擅長。
⑤ TPU(Tensor Processing Units)
TPU是專用的深度學習硬體,執行速度非常快。Google Cloud TPU 算力為180 TFLOPs ,NVIDIA Tesla V100算力為125 TFLOPs。

⑥Theano
TensorFlow的前身,二者許多地方都很相似。
2.3 PyTorch
關於PyTorch的用法也可以閱讀ShowMeAI的製作的PyTorch速查表,對應文章AI 建模工具速查 | Pytorch使用指南
1) 基本概念
- Tensor:與Numpy陣列很相似,只是可以在GPU上執行;
- Autograd:使用Tensors構建計算圖並自動計算梯度的包;
- Module:神經網路的層,可以儲存狀態和可學習的權重。
下面的程式碼使用的是v0.4版本。
2) Tensors
下面使用Tensors訓練一個兩層的神經網路,啟用函數使用ReLU、損失使用L2損失。
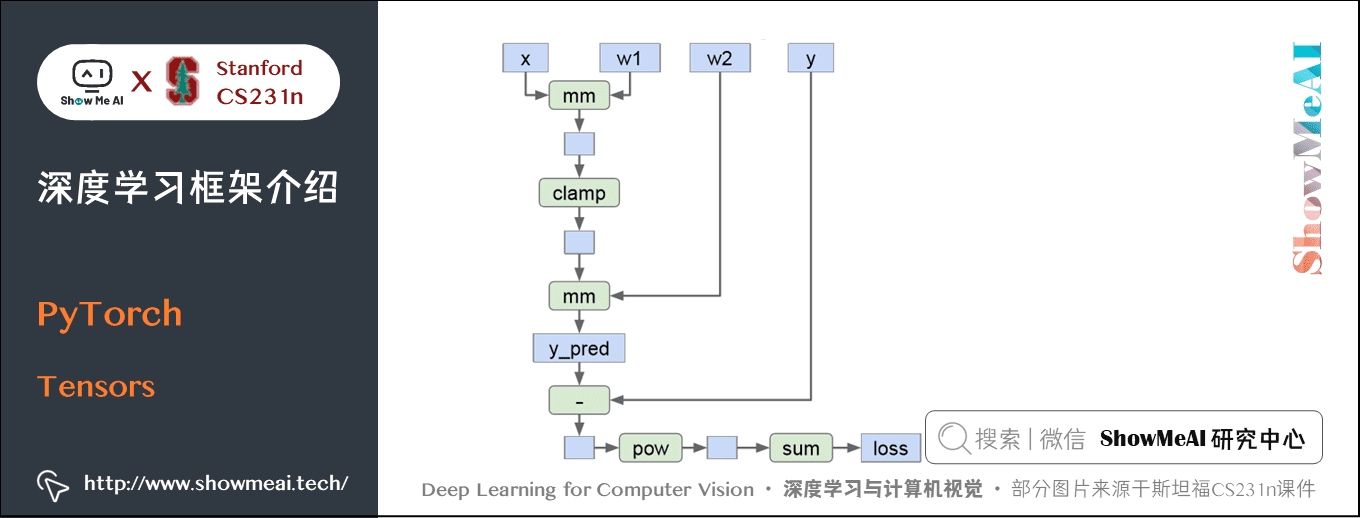
程式碼如下:
import torch
# cpu版本
device = torch.device('cpu')
#device = torch.device('cuda:0') # 使用gpu
# 為資料和引數建立隨機的Tensors
N, D_in, H, D_out = 64, 1000, 100, 10
x = torch.randn(N, D_in, device=device)
y = torch.randn(N, D_out, device=device)
w1 = torch.randn(D_in, H, device=device)
w2 = torch.randn(H, D_out, device=device)
learning_rate = 1e-6
for t in range(500):
# 前向傳播,計算預測值和損失
h = x.mm(w1)
h_relu = h.clamp(min=0)
y_pred = h_relu.mm(w2)
loss = (y_pred - y).pow(2).sum()
# 反向傳播手動計算梯度
grad_y_pred = 2.0 * (y_pred - y)
grad_w2 = h_relu.t().mm(grad_y_pred)
grad_h_relu = grad_y_pred.mm(w2.t())
grad_h = grad_h_relu.clone()
grad_h[h < 0] = 0
grad_w1 = x.t().mm(grad_h)
# 梯度下降,引數更新
w1 -= learning_rate * grad_w1
w2 -= learning_rate * grad_w2
- 首先建立
x,y,w1,w2的隨機 tensor,與 Numpy 陣列的形式一致 - 然後前向傳播計算損失值和預測值
- 然後手動計算梯度
- 最後更新引數
上述程式碼很簡單,和 Numpy 版本的寫法很接近。但是需要手動計算梯度。
3) Autograd自動梯度計算
PyTorch 可以自動計算梯度:
import torch
# 建立隨機tensors
N, D_in, H, D_out = 64, 1000, 100, 10
x = torch.randn(N, D_in)
y = torch.randn(N, D_out)
w1 = torch.randn(D_in, H, requires_grad=True)
w2 = torch.randn(H, D_out, requires_grad=True)
learning_rate = 1e-6
for t in range(500):
# 前向傳播
y_pred = x.mm(w1).clamp(min=0).mm(w2)
loss = (y_pred - y).pow(2).sum()
# 反向傳播
loss.backward()
# 引數更新
with torch.no_grad():
w1 -= learning_rate * w1.grad
w2 -= learning_rate * w2.grad
w1.grad.zero_()
w2.grad.zero_()
與上一版程式碼的主要區別是:
- 建立
w1,w2時要求requires_grad=True,這樣會自動計算梯度,並建立計算圖。x1,x2不需要計算梯度。 - 前向傳播與之前的類似,但現在不用儲存節點,PyTorch 可以幫助我們跟蹤計算圖。
- 使用
loss.backward()自動計算要求的梯度。 - 按步對權重進行更新,然後將梯度歸零。
Torch.no_grad的意思是「不要為這部分構建計算圖」。以下劃線結尾的 PyTorch 方法是就地修改 Tensor,不返回新的 Tensor。
TensorFlow 與 PyTorch 的區別是 TensorFlow 需要先顯式的構造一個計算圖,然後重複執行;PyTorch 每次做前向傳播時都要構建一個新的圖,使程式看起來更加簡潔。
PyTorch 支援定義自己的自動計算梯度函數,需要編寫 forward,backward 函數。與作業中很相似。可以直接用到計算圖上,但是實際上自己定義的時候並不多。
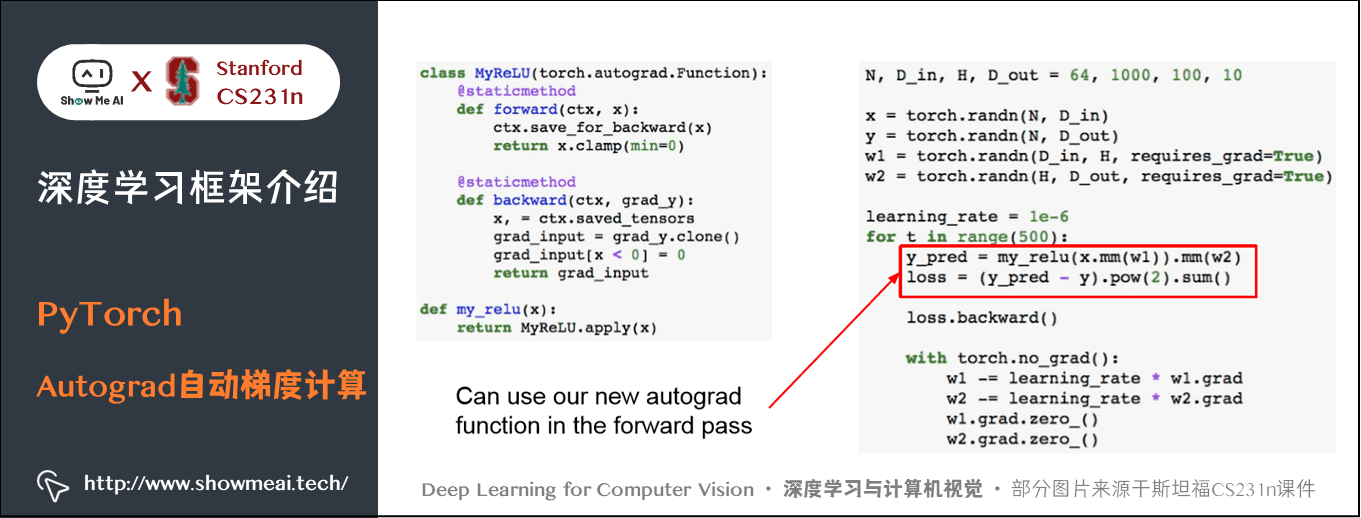
4) NN
與 Keras 類似的高層次封裝,會使整個程式碼變得簡單。
import torch
N, D_in, H, D_out = 64, 1000, 100, 10
x = torch.randn(N, D_in)
y = torch.randn(N, D_out)
# 定義模型
model = torch.nn.Sequential(torch.nn.Linear(D_in, H),
torch.nn.ReLu(),
torch.nn.Linear(H, D_out))
learning_rate = 1e-2
for t in range(500):
# 前向傳播
y_pred = model(x)
loss = torch.nn.functional.mse_loss(y_pred, y)
# 計算梯度
loss.backward()
with torch.no_grad():
for param in model.parameters():
param -= learning_rate * param.grad
model.zero_grad()
- 定義模型是一系列的層組合,在模型中定義了層物件比如全連線層、折葉層等,裡面包含可學習的權重;
- 前向傳播將資料給模型就可以直接計算預測值,進而計算損失;
torch.nn.functional含有很多有用的函數,比如損失函數; - 反向傳播會計算模型中所有權重的梯度;
- 最後每一步都更新模型的引數。
5) Optimizer
PyTorch 同樣有自己的優化器:
import torch
N, D_in, H, D_out = 64, 1000, 100, 10
x = torch.randn(N, D_in)
y = torch.randn(N, D_out)
# 定義模型
model = torch.nn.Sequential(torch.nn.Linear(D_in, H),
torch.nn.ReLu(),
torch.nn.Linear(H, D_out))
# 定義優化器
learning_rate = 1e-4
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# 迭代
for t in range(500):
y_pred = model(x)
loss = torch.nn.functional.mse_loss(y_pred, y)
loss.backward()
# 更新引數
optimizer.step()
optimizer.zero_grad()
- 使用不同規則的優化器,這裡使用Adam;
- 計算完梯度後,使用優化器更新引數,再置零梯度。
6) 定義新的模組
PyTorch 中一個模組就是一個神經網路層,輸入和輸出都是 tensors。模組中可以包含權重和其他模組,可以使用 Autograd 定義自己的模組。
比如可以把上面程式碼中的兩層神經網路改成一個模組:
import torch
# 定義上文的整個模組為單個模組
class TwoLayerNet(torch.nn.Module):
# 初始化兩個子模組,都是線性層
def __init__(self, D_in, H, D_out):
super(TwoLayerNet, self).__init__()
self.linear1 = torch.nn.Linear(D_in, H)
self.linear2 = torch.nn.Linear(H, D_out)
# 使用子模組定義前向傳播,不需要定義反向傳播,autograd會自動處理
def forward(self, x):
h_relu = self.linear1(x).clamp(min=0)
y_pred = self.linear2(h_relu)
return y_pred
N, D_in, H, D_out = 64, 1000, 100, 10
x = torch.randn(N, D_in)
y = torch.randn(N, D_out)
# 構建模型與訓練和之前類似
model = TwoLayerNet(D_in, H, D_out)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
for t in range(500):
y_pred = model(x)
loss = torch.nn.functional.mse_loss(y_pred, y)
loss.backward()
optimizer.step()
optimizer.zero_grad()
這種混合自定義模組非常常見,定義一個模組子類,然後作為作為整個模型的一部分新增到模組序列中。
比如用定義一個下面這樣的模組,輸入資料先經過兩個並列的全連線層得到的結果相乘後經過 ReLU:
class ParallelBlock(torch.nn.Module):
def __init__(self, D_in, D_out):
super(ParallelBlock, self).__init__()
self.linear1 = torch.nn.Linear(D_in, D_out)
self.linear2 = torch.nn.Linear(D_in, D_out)
def forward(self, x):
h1 = self.linear1(x)
h2 = self.linear2(x)
return (h1 * h2).clamp(min=0)
然後在整個模型中應用:
model = torch.nn.Sequential(ParallelBlock(D_in, H),
ParallelBlock(H, H),
torch.nn.Linear(H, D_out))
使用 ParallelBlock 的新模型計算圖如下:
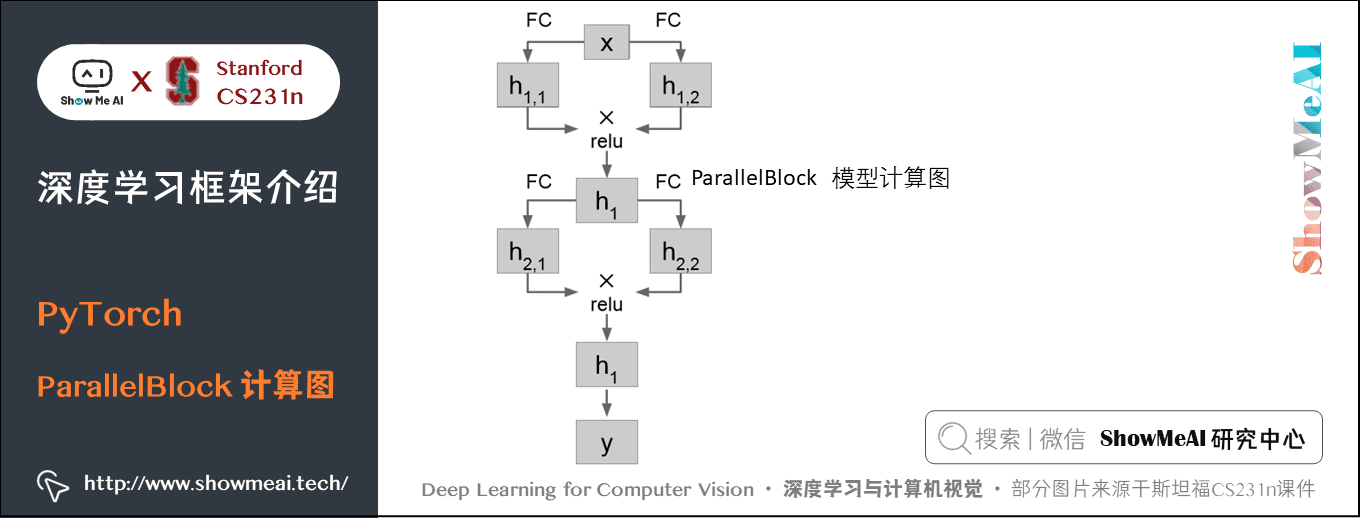
7) DataLoader
DataLoader 包裝資料集並提供獲取小批次資料,重新排列,多執行緒讀取等,當需要載入自定義資料時,只需編寫自己的資料集類:
import torch
from torch.utils.data import TensorDataset, DataLoader
N, D_in, H, D_out = 64, 1000, 100, 10
x = torch.randn(N, D_in)
y = torch.randn(N, D_out)
loader = DataLoader(TensorDataset(x, y), batch_size=8)
model = TwoLayerNet(D_in, H, D_out)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-2)
for epoch in range(20):
for x_batch, y_batch in loader:
y_pred = model(x_batch)
loss = torch.nn.functional.mse_loss(y_pred, y_batch)
loss.backward()
optimizer.step()
optimizer.zero_grad()
上面的程式碼仍然是兩層神經完網路,使用了自定義的模組。這次使用了 DataLoader 來處理資料。最後更新的時候在小批次上更新,一個週期會迭代所有的小批次資料。一般的 PyTorch 模型基本都長成這個樣子。
8) 預訓練模型
使用預訓練模型非常簡單:https://github.com/pytorch/vision
import torch
import torchvision
alexnet = torchvision.models.alexnet(pretrained=True)
vgg16 = torchvision.models.vggl6(pretrained=-True)
resnet101 = torchvision.models.resnet101(pretrained=True)
9) Visdom
視覺化的包,類似 TensorBoard,但是不能像 TensorBoard 一樣視覺化計算圖。
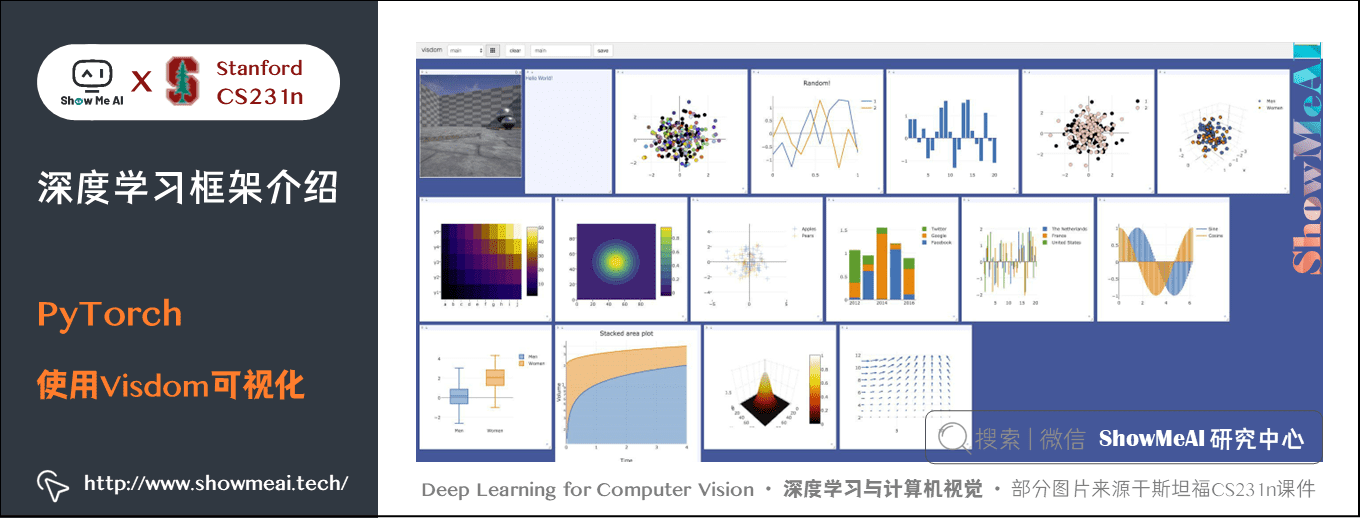
10) Torch
PyTorch 的前身,不能使用 Python,沒有 Autograd,但比較穩定,不推薦使用。
3.靜態與動態圖(Static vs Dynamic Graphs )
TensorFlow使用的是靜態圖(Static Graphs):
- 構建計算圖描述計算,包括找到反向傳播的路徑;
- 每次迭代執行計算,都使用同一張計算圖。
與靜態圖相對應的是PyTorch使用的動態圖(Dynamic Graphs),構建計算圖與計算同時進行:
- 建立tensor物件;
- 每一次迭代構建計算圖資料結構、尋找引數梯度路徑、執行計算;
- 每一次迭代丟擲計算圖,然後再重建。之後重複上一步。
3.1 靜態圖的優勢
使用靜態圖形,由於一張圖需要反覆執行很多次,這樣框架就有機會在計算圖上做優化。
- 比如下面的自己寫的計算圖可能經過多次執行後優化成右側,提高執行效率。
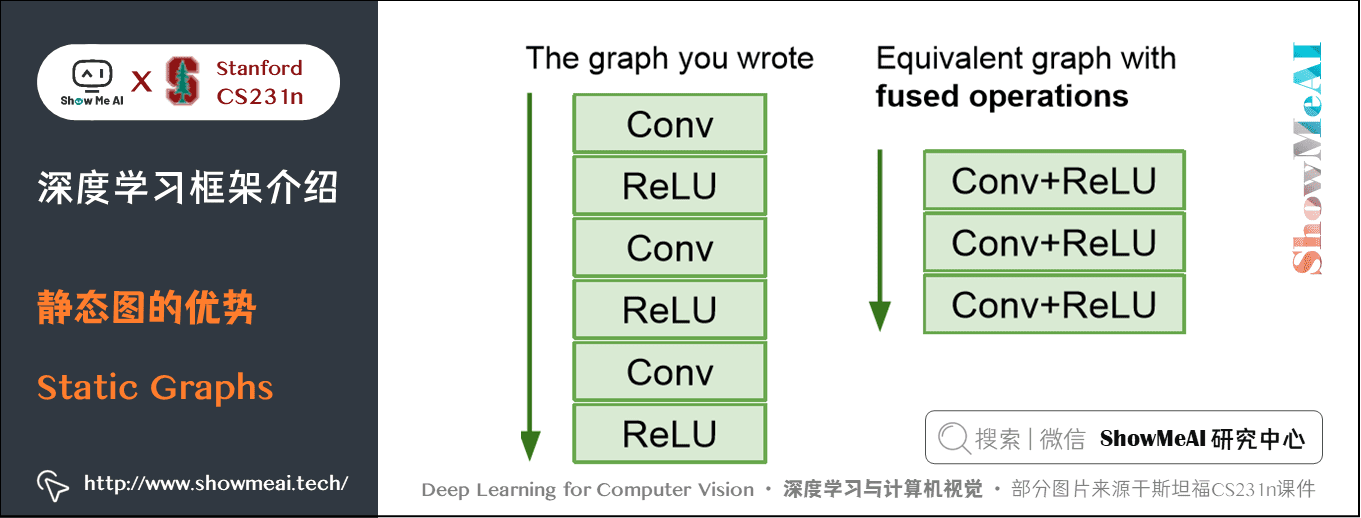
靜態圖只需要構建一次計算圖,所以一旦構建好了即使原始碼使用 Python 寫的,也可以部署在C++上,不用依賴原始碼;而動態圖每次迭代都要使用原始碼,構件圖和執行是交織在一起的。
3.2 動態圖的優勢
動態圖的程式碼比較簡潔,很像 Python 操作。
在條件判斷邏輯中,由於 PyTorch 可以動態構建圖,所以可以使用正常的 Python 流操作;而TensorFlow 只能一次性構建一個計算圖,所以需要考慮到所有情況,只能使用 TensorFlow 流操作,這裡使用的是和條件有關的。

在迴圈結構中,也是如此。
- PyTorch 只需按照 Python 的邏輯去寫,每次會更新計算圖而不用管最終的序列有多長;
- TensorFlow 由於使用靜態圖必須把這個迴圈結構顯示的作為節點新增到計算圖中,所以需要用到 TensorFlow 的迴圈流
tf.foldl。並且大多數情況下,為了保證只構建一次迴圈圖, TensorFlow 只能使用自己的控制流,比如迴圈流、條件流等,而不能使用 Python 語法,所以用起來需要學習 TensorFlow 特有的控制命令。

3.3 動態圖的應用
1) 迴圈網路(Recurrent Networks)
例如影象描述,需要使用迴圈網路在一個不同長度序列上執行,我們要生成的用於描述影象的語句是一個序列,依賴於輸入資料的序列,即動態的取決於輸入句子的長短。
2) 遞迴網路(Recursive Networks)
用於自然語言處理,遞迴訓練整個語法解析樹,所以不僅僅是層次結構,而是一種圖或樹結構,在每個不同的資料點都有不同的結構,使用TensorFlow很難實現。在 PyTorch 中可以使用 Python 控制流,很容易實現。
3) Modular Networks
一種用於詢問圖片上的內容的網路,問題不一樣生成的動態圖也就不一樣。
3.4 TensorFlow與PyTorch的相互靠攏
TensorFlow 與 PyTorch 的界限越來越模糊,PyTorch 正在新增靜態功能,而 TensorFlow 正在新增動態功能。
- TensorFlow Fold 可以把靜態圖的程式碼自動轉化成靜態圖
- TensorFlow 1.7增加了Eager Execution,允許使用動態圖
import tensorflow as tf
import tensorflow.contrib.eager as tfe
tf.enable eager _execution()
N, D = 3, 4
x = tfe.Variable(tf.random_normal((N, D)))
y = tfe.Variable(tf.random_normal((N, D)))
z = tfe.Variable(tf.random_normal((N, D)))
with tfe.GradientTape() as tape:
a=x * 2
b=a + z
c = tf.reduce_sum(b)
grad_x, grad_y, grad_z = tape.gradient(c, [x, y, 2])
print(grad_x)
- 在程式開始時使用
tf.enable_eager_execution模式:它是一個全域性開關 tf.random_normal會產生具體的值,無需 placeholders / sessions,如果想要為它們計算梯度,要用tfe.Variable進行包裝- 在
GradientTape下操作將構建一個動態圖,類似於 PyTorch - 使用
tape計算梯度,類似 PyTorch 中的backward。並且可以直接列印出來 - 靜態的 PyTorch 有 [Caffe2](https://caffe2.ai/)、[ONNX Support](https://caffe2.ai/)
4.拓展學習
可以點選 B站 檢視視訊的【雙語字幕】版本
- 【課程學習指南】斯坦福CS231n | 深度學習與計算機視覺
- 【字幕+資料下載】斯坦福CS231n | 深度學習與計算機視覺 (2017·全16講)
- 【CS231n進階課】密歇根EECS498 | 深度學習與計算機視覺
- 【深度學習教學】吳恩達專項課程 · 全套筆記解讀
- 【Stanford官網】CS231n: Deep Learning for Computer Vision
5.要點總結
- 深度學習硬體最好使用 GPU,然後需要解決 CPU 與 GPU 的通訊問題。TPU 是專門用於深度學習的硬體,速度非常快。
- PyTorch 與 TensorFlow 都是非常好的深度學習框架,都有可以在 GPU 上直接執行的陣列,都可以自動計算梯度,都有很多已經寫好的函數、層等可以直接使用。前者使用動態圖,後者使用靜態圖,不過二者都在向對方發展。取捨取決於專案。
斯坦福 CS231n 全套解讀
- 深度學習與CV教學(1) | CV引言與基礎
- 深度學習與CV教學(2) | 影象分類與機器學習基礎
- 深度學習與CV教學(3) | 損失函數與最佳化
- 深度學習與CV教學(4) | 神經網路與反向傳播
- 深度學習與CV教學(5) | 折積神經網路
- 深度學習與CV教學(6) | 神經網路訓練技巧 (上)
- 深度學習與CV教學(7) | 神經網路訓練技巧 (下)
- 深度學習與CV教學(8) | 常見深度學習框架介紹
- 深度學習與CV教學(9) | 典型CNN架構 (Alexnet, VGG, Googlenet, Restnet等)
- 深度學習與CV教學(10) | 輕量化CNN架構 (SqueezeNet, ShuffleNet, MobileNet等)
- 深度學習與CV教學(11) | 迴圈神經網路及視覺應用
- 深度學習與CV教學(12) | 目標檢測 (兩階段, R-CNN系列)
- 深度學習與CV教學(13) | 目標檢測 (SSD, YOLO系列)
- 深度學習與CV教學(14) | 影象分割 (FCN, SegNet, U-Net, PSPNet, DeepLab, RefineNet)
- 深度學習與CV教學(15) | 視覺模型視覺化與可解釋性
- 深度學習與CV教學(16) | 生成模型 (PixelRNN, PixelCNN, VAE, GAN)
- 深度學習與CV教學(17) | 深度強化學習 (馬爾可夫決策過程, Q-Learning, DQN)
- 深度學習與CV教學(18) | 深度強化學習 (梯度策略, Actor-Critic, DDPG, A3C)
ShowMeAI 系列教學推薦
- 大廠技術實現:推薦與廣告計算解決方案
- 大廠技術實現:計算機視覺解決方案
- 大廠技術實現:自然語言處理行業解決方案
- 圖解Python程式設計:從入門到精通系列教學
- 圖解資料分析:從入門到精通系列教學
- 圖解AI數學基礎:從入門到精通系列教學
- 圖解巨量資料技術:從入門到精通系列教學
- 圖解機器學習演演算法:從入門到精通系列教學
- 機器學習實戰:手把手教你玩轉機器學習系列
- 深度學習教學:吳恩達專項課程 · 全套筆記解讀
- 自然語言處理教學:斯坦福CS224n課程 · 課程帶學與全套筆記解讀
- 深度學習與計算機視覺教學:斯坦福CS231n · 全套筆記解讀
