Crane-scheduler:基於真實負載進行排程
作者
邱天,騰訊雲高階工程師,負責騰訊雲 TKE 動態排程器與重排程器產品。
背景
原生 kubernetes 排程器只能基於資源的 resource request 進行排程,然而 Pod 的真實資源使用率,往往與其所申請資源的 request/limit 差異很大,這直接導致了叢集負載不均的問題:
-
叢集中的部分節點,資源的真實使用率遠低於 resource request,卻沒有被排程更多的 Pod,這造成了比較大的資源浪費;
-
而叢集中的另外一些節點,其資源的真實使用率事實上已經過載,卻無法為排程器所感知到,這極大可能影響到業務的穩定性。
這些無疑都與企業上雲的最初目的相悖,為業務投入了足夠的資源,卻沒有達到理想的效果。
既然問題的根源在於 resource request 與真實使用率之間的「鴻溝」,那為什麼不能讓排程器直接基於真實使用率進行排程呢?這就是 Crane-scheduler 設計的初衷。Crane-scheduler 基於叢集的真實負載資料構造了一個簡單卻有效的模型,作用於排程過程中的 Filter 與 Score 階段,並提供了一種靈活的排程策略設定方式,從而有效緩解了 kubernetes 叢集中各種資源的負載不均問題。換句話說,Crane-scheduler 著力於排程層面,讓叢集資源使用最大化的同時排除了穩定性的後顧之憂,真正實現「降本增效」。
整體架構
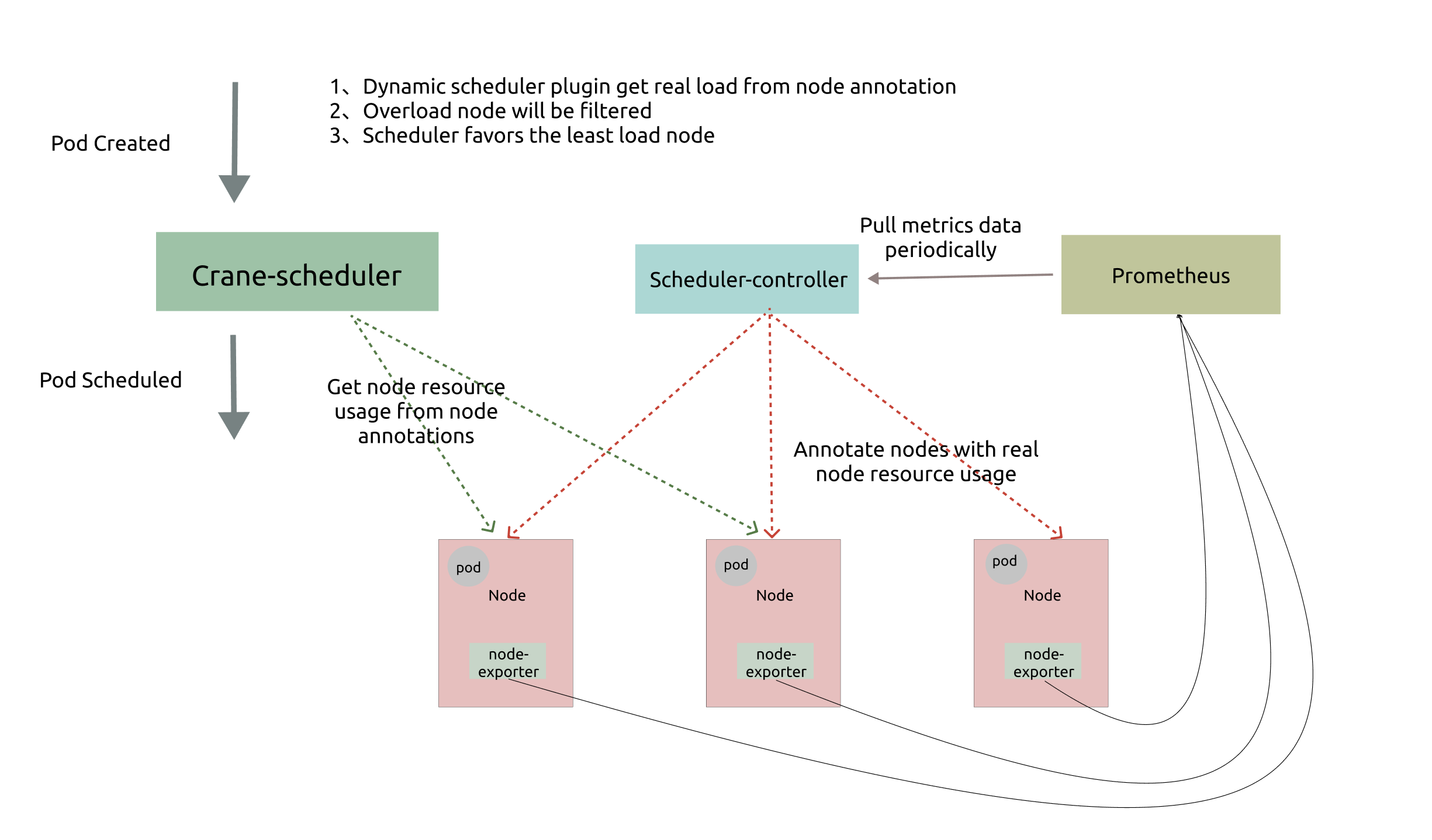
如上圖所示,Crane-scheduler 依賴於 Node-exporter 與 Prometheus 兩個元件,前者從節點收集負載資料,後者則對資料進行聚合。而 Crane-scheduler 本身也包含兩個部分:
-
Scheduler-Controller 週期性地從 Prometheus 拉取各個節點的真實負載資料, 再以 Annotation 的形式標記在各個節點上;
-
Scheduler 則直接在從候選節點的 Annotation 讀取負載資訊,並基於這些負載資訊在 Filter 階段對節點進行過濾以及在 Score 階段對節點進行打分;
基於上述架構,最終實現了基於真實負載對 Pod 進行有效排程。
排程策略
下圖是官方提供的 Pod 的排程上下文以及排程框架公開的擴充套件點:
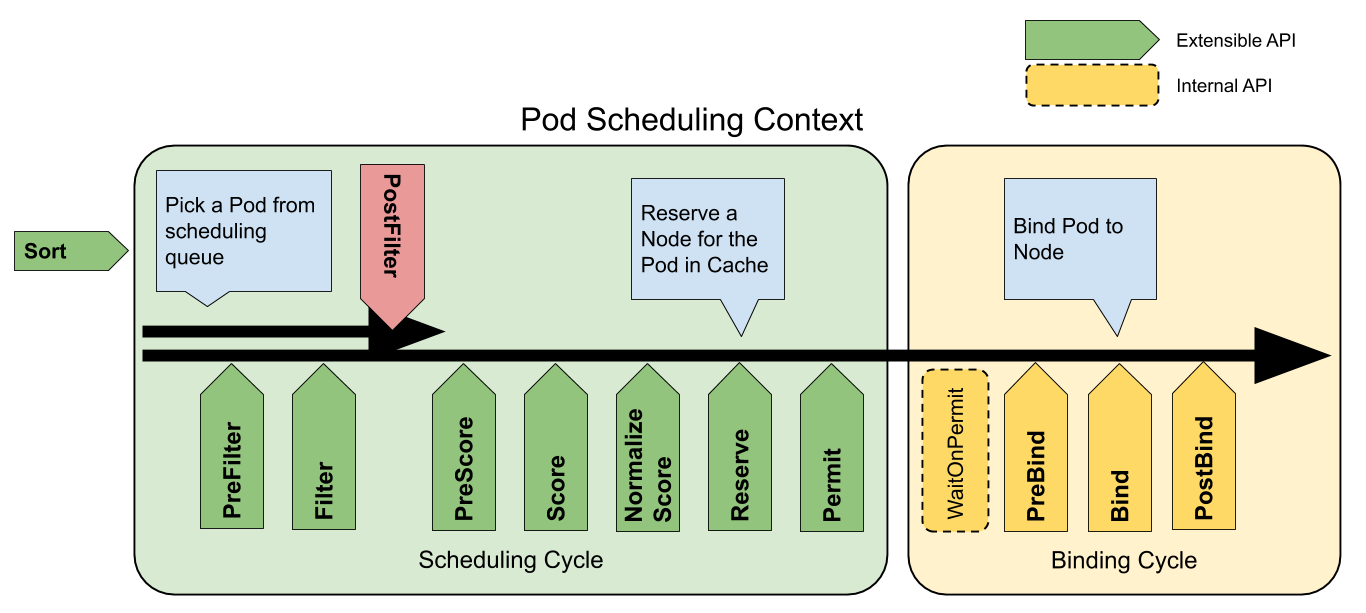
Crane-scheduler 主要作用於圖中的 Filter 與 Score 階段,並對使用者提供了一個非常開放的策略設定。這也是 Crane-Scheduler 與社群同型別的排程器最大的區別之一:
- 前者提供了一個泛化的排程策略設定介面,給予了使用者極大的靈活性;
- 後者往往只能支援 cpu/memory 等少數幾種指標的感知排程,且指標聚合方式,打分策略均受限。
在 Crane-scheduler 中,使用者可以為候選節點設定任意的評價指標型別(只要從 Prometheus 能拉到相關資料),不論是常用到的 CPU/Memory 使用率,還是 IO、Network Bandwidth 或者 GPU 使用率,均可以生效,並且支援相關策略的自定義設定。
資料拉取
如「整體架構」中所述,Crane-scheduler 所需的負載資料均是通過 Controller 非同步拉取。這種資料拉取方式:
-
一方面,保證了排程器本身的效能;
-
另一方面,有效減輕了 Prometheus 的壓力,防止了業務突增時元件被打爆的情況發生。
此外,使用者可以直接 Describe 節點,檢視到節點的負載資訊,方便問題定位:
[root@test01 ~]# kubectl describe node test01
Name: test01
...
Annotations: cpu_usage_avg_5m: 0.33142,2022-04-18T00:45:18Z
cpu_usage_max_avg_1d: 0.33495,2022-04-17T23:33:18Z
cpu_usage_max_avg_1h: 0.33295,2022-04-18T00:33:18Z
mem_usage_avg_5m: 0.03401,2022-04-18T00:45:18Z
mem_usage_max_avg_1d: 0.03461,2022-04-17T23:33:20Z
mem_usage_max_avg_1h: 0.03425,2022-04-18T00:33:18Z
node.alpha.kubernetes.io/ttl: 0
node_hot_value: 0,2022-04-18T00:45:18Z
volumes.kubernetes.io/controller-managed-attach-detach: true
...
使用者可以自定義負載資料的型別與拉取週期,預設情況下,資料拉取的設定如下:
syncPolicy:
## cpu usage
- name: cpu_usage_avg_5m
period: 3m
- name: cpu_usage_max_avg_1h
period: 15m
- name: cpu_usage_max_avg_1d
period: 3h
## memory usage
- name: mem_usage_avg_5m
period: 3m
- name: mem_usage_max_avg_1h
period: 15m
- name: mem_usage_max_avg_1d
period: 3h
Filter 策略
使用者可以在 Filter 策略中設定相關指標的閾值,若候選節點的當前負載資料超過了任一所設定的指標閾值,則這個節點將會被過濾,預設設定如下:
predicate:
## cpu usage
- name: cpu_usage_avg_5m
maxLimitPecent: 0.65
- name: cpu_usage_max_avg_1h
maxLimitPecent: 0.75
## memory usage
- name: mem_usage_avg_5m
maxLimitPecent: 0.65
- name: mem_usage_max_avg_1h
maxLimitPecent: 0.75
Score 策略
使用者可以在 Score 策略中設定相關指標的權重,候選節點的最終得分為不同指標得分的加權和,預設設定如下:
priority:
### score = sum((1 - usage) * weight) * MaxScore / sum(weight)
## cpu usage
- name: cpu_usage_avg_5m
weight: 0.2
- name: cpu_usage_max_avg_1h
weight: 0.3
- name: cpu_usage_max_avg_1d
weight: 0.5
## memory usage
- name: mem_usage_avg_5m
weight: 0.2
- name: mem_usage_max_avg_1h
weight: 0.3
- name: mem_usage_max_avg_1d
weight: 0.5
排程熱點
在實際生產環境中,由於 Pod 建立成功以後,其負載並不會立馬上升,這就導致了一個問題:如果完全基於節點實時負載對 Pod 排程,常常會出現排程熱點(短時間大量 pod 被排程到同一個節點上)。為了解決這個問題,我們設定了一個單列指標 Hot Vaule,用來評價某個節點在近段時間內被排程的頻繁程度,對節點實時負載進行對衝。最終節點的 Priority 為上一小節中的 Score 減去 Hot Value。Hot Value 預設設定如下:
hotValue:
- timeRange: 5m
count: 5
- timeRange: 1m
count: 2
注:該設定表示,節點在 5 分鐘內被排程 5 個 pod,或者 1 分鐘內被排程 2 個 pod,HotValue 加 10 分。
案例分享
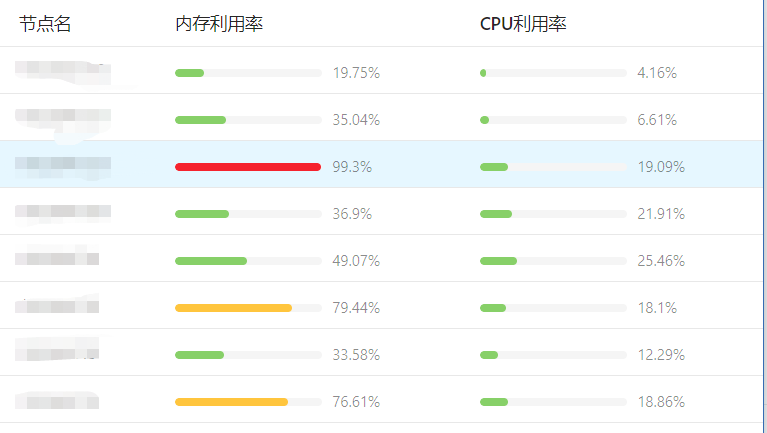
Crane-scheduler 目前有眾多公有云使用者,包括鬥魚直播、酷狗、一汽大眾、獵豹移動等公司均在使用,並給予了產品不錯的反饋。這裡我們先分享一個某公有云使用者的真實案例。該客戶叢集中的業務大多是記憶體消耗型的,因此極易出現記憶體利用率很高的節點,並且各個節點的記憶體利用率分佈也很不平均,如下圖所示:
瞭解到使用者的情況後,我們推薦其使用 Crane-scheduler,元件執行一段時間後,該使用者叢集內各節點的記憶體利用率資料分佈發生了顯著變化,如下圖 :
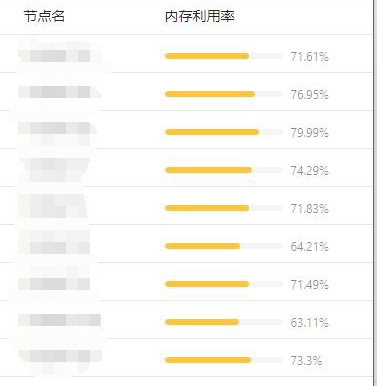
可見,使用者叢集的記憶體使用率更加趨於均衡。
另外, Crane-scheduler 也在公司內部各個 BG 的自研上雲環境中,也得到了廣泛的使用。下面是內部自研上雲平臺 TKEx-CSIG 的兩個生產叢集的 CPU 使用率分佈情況,其中叢集 A 未部署 Crane-scheduler:
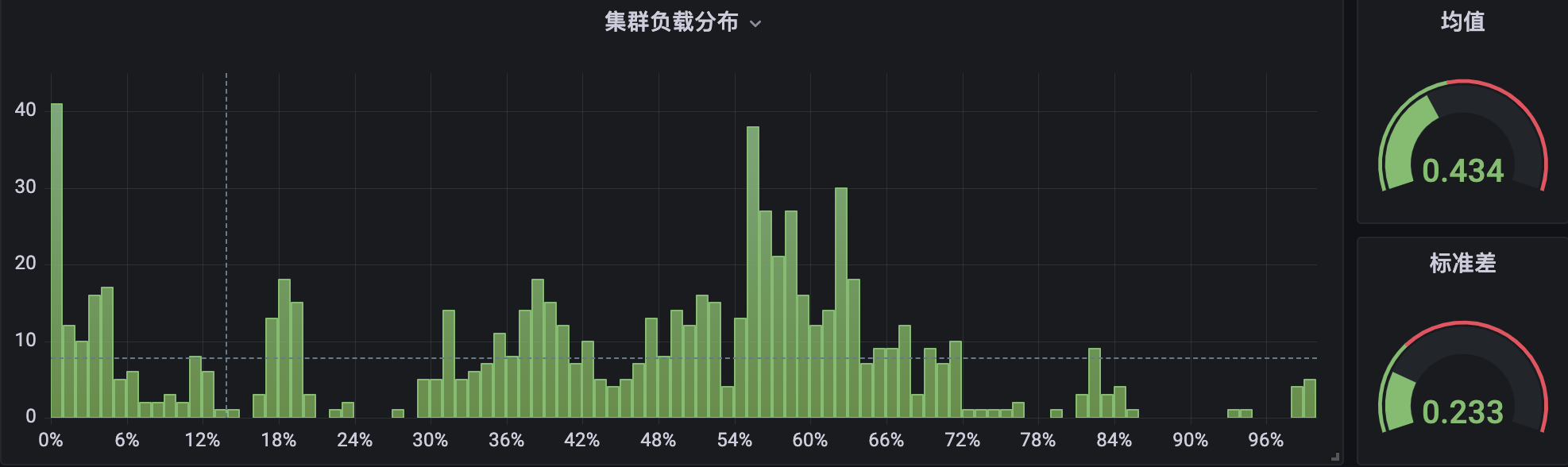
叢集 B 部署了元件並執行過一段時間:
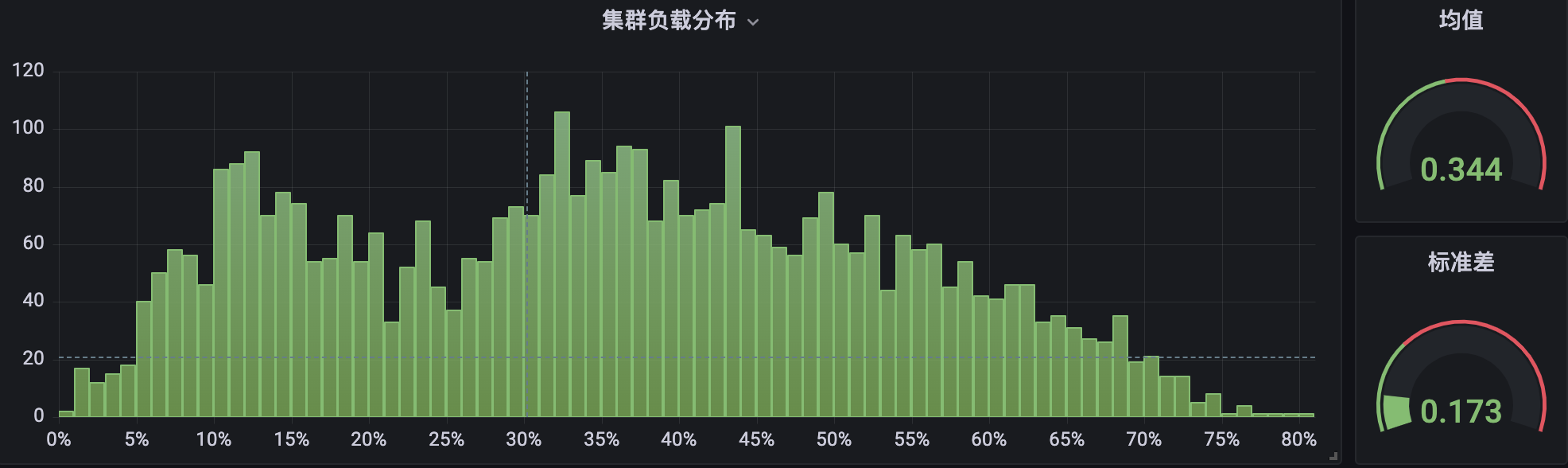
很明顯,在叢集 B 中,節點 CPU 使用率分佈在兩端( < 10% 與 > 80%)所佔的比例,要顯著小於叢集 A,並且整體分佈也更加緊湊,相對而言更加均衡與健康。
衍生閱讀:什麼是 Crane
為推進雲原生使用者在確保業務穩定性的基礎上做到真正的極致降本,騰訊推出了業界第一個基於雲原生技術的成本優化開源專案 Crane( Cloud Resource Analytics and Economics )。Crane 遵循 FinOps 標準,旨在為雲原生使用者提供雲成本優化一站式解決方案。
Crane-scheduler 作為 Crane 的排程外掛實現了基於真實負載的排程功能,旨在從排程層面幫助業務降本增效。
近期,Crane 成功加入 CNCF Landscape,歡迎關注專案:https://github.com/gocrane/crane。
關於我們
更多關於雲原生的案例和知識,可關注同名【騰訊雲原生】公眾號~
福利:
①公眾號後臺回覆【手冊】,可獲得《騰訊雲原生路線圖手冊》&《騰訊雲原生最佳實踐》~
②公眾號後臺回覆【系列】,可獲得《15個系列100+篇超實用雲原生原創乾貨合集》,包含Kubernetes 降本增效、K8s 效能優化實踐、最佳實踐等系列。
③公眾號後臺回覆【白皮書】,可獲得《騰訊雲容器安全白皮書》&《降本之源-雲原生成本管理白皮書v1.0》
④公眾號後臺回覆【光速入門】,可獲得騰訊雲專家5萬字精華教學,光速入門Prometheus和Grafana。
【騰訊雲原生】雲說新品、雲研新術、雲遊新活、雲賞資訊,掃碼關注同名公眾號,及時獲取更多幹貨!!
