論文解讀(LA-GNN)《Local Augmentation for Graph Neural Networks》
論文資訊
論文標題:Local Augmentation for Graph Neural Networks
論文作者:Songtao Liu, Hanze Dong, Lanqing Li, Tingyang Xu, Yu Rong, Peilin Zhao, Junzhou Huang, Dinghao Wu
論文來源:2021, arXiv
論文地址:download
論文程式碼:download
1 Introduction
現有的方法側重於從全域性的角度來增強圖形資料,主要分為兩種型別:
-
- structural manipulation
- adversarial training with feature noise injection
最近工作忽略了區域性資訊對GNN 訊息傳遞機制的重要性。在本文種,引入區域性資料增強,通過子圖結構增強節點表示的區域性性。具體來說,將資料增強建模為一個特徵生成過程。給定一個節點的特徵,本文的區域性增強方法學習其鄰居特徵的條件分佈,並生成更多的鄰居特徵,以提高下游任務的效能。
基於區域性增強,進一步設計了一個新的框架:LA-GNN,它可以以隨插即用的方式應用於任何GNN模型。
2 Local Augmentation
框架如下:
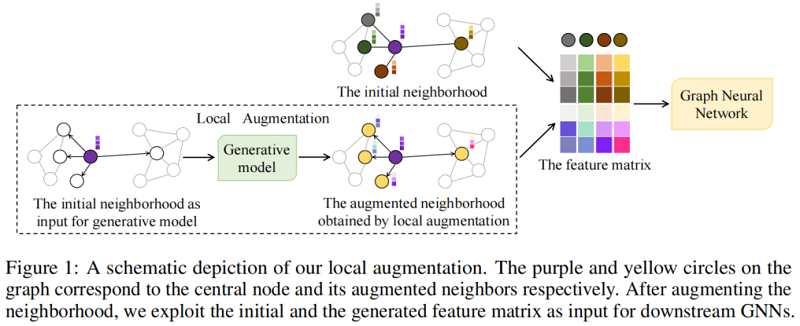
Local augmentation framework 包括三個模組:
-
- learning the conditional distribution via a generative model;
- the active learning trick;
- the downstream GNN models;
需要注意的是,該演演算法生成的是 1-hop 鄰居來增強節點的區域性性。
2.1 Learning The Conditional Distribution
利用 GNN 來建模標籤的條件概率分佈 $P_{\theta}(\mathbf{Y} \mid \mathbf{A}, \mathbf{X})$ , 其中引數 $\theta$ 可通過以下似然函數進行訓練:
$\text{max}\prod\limits _{k \in \mathbf{K}} P_{\theta}\left(\mathbf{Y}_{k} \mid \mathbf{A}, \mathbf{X}\right) \quad\quad\quad(2)$
為提升 GNN 效能,引入由特徵級資料增強生成的特徵 $\overline{\mathbf{X}}$ ,則似然函數為:
基於貝葉斯公式,將 $\text{Eq.3}$ 分解成由GNN近似的概率分佈 $P_{\theta}\left(\mathbf{Y}_{k} \mid \mathbf{A}, \mathbf{X}, \overline{\mathbf{X}}\right)$ 和特徵增強生成器 $Q_{\phi}(\overline{\mathbf{X}} \mid \mathbf{A}, \mathbf{X})$ 共同控制的兩個部分:
$P_{\theta, \phi}\left(\mathbf{Y}_{k}, \overline{\mathbf{X}} \mid \mathbf{A}, \mathbf{X}\right):=P_{\theta}\left(\mathbf{Y}_{k} \mid \mathbf{A}, \mathbf{X}, \overline{\mathbf{X}}\right) Q_{\phi}(\overline{\mathbf{X}} \mid \mathbf{A}, \mathbf{X})\quad\quad\quad(4)$
上述分解的兩個好處:
-
- 首先,允許解耦下游預測器 $P_{\theta}$ 和生成器 $Q_{\phi}$ 的訓練,使生成器能夠很容易地推廣到其他下游任務。
- 此外,$\text{Eq.4}$ 的表示能力優於沒有資料增強的 $P_{\theta}\left(\mathbf{Y}_{k} \mid \mathbf{A}, \mathbf{X}\right)$。
因此,當生成器 $Q_{\phi}$ 被訓練得很好,便可從固定的條件分佈 $Q_{\phi}$ 中提取樣本 $\overline{\mathbf{X}}$ 來優化 $P_{\theta}\left(\mathbf{Y}_{k} \mid \mathbf{A}, \mathbf{X}, \overline{\mathbf{X}}\right)$。
接下來,將展示如何訓練生成器。
Generator
為學習特徵增強生成器,本文使用 MLE 方法學習所有鄰居的一個單一分佈,即:
$\underset{\psi}{\text{max}} \sum\limits _{j \in \mathcal{N}_{i}} \log p_{\psi}\left(\mathbf{X}_{j} \mid \mathbf{X}_{i}\right)=\underset{\psi}{\text{max}} \log \prod\limits_{j \in \mathcal{N}_{i}} p_{\psi}\left(\mathbf{X}_{j} \mid \mathbf{X}_{i}\right)\quad\quad\quad(5)$
其中 $\left\{\mathbf{X}_{j \mid j \in \mathcal{N}_{i}}, \mathbf{X}_{i}\right\}$。
顯然,$p_{\psi}$ 可用於增強所有鄰居的特徵,但是這種方法忽略了鄰居之間的差異,會引起嚴重的噪聲。
為克服這一限制,假設每個鄰居都滿足不同的條件分佈。具體地說,存在一個具有潛在隨機變數 $\mathbf{z}_{j}$ 的條件分佈 $p\left(\cdot \mid \mathbf{X}_{i}, \mathbf{z}_{j}\right)$,這樣可得對於 $\mathbf{X}_{j \mid j \in \mathcal{N}_{i}}$ 的 $\mathbf{X}_{j} \sim p\left(\mathbf{X} \mid \mathbf{X}_{i}, \mathbf{z}_{j}\right)$。當獲得 $p\left(\cdot \mid \mathbf{X}_{i}, \mathbf{z}_{j}\right)$,便可以生成增強特徵 $\overline{\mathbf{X}}$,然後便可訓練 $P_{\theta}\left(\mathbf{Y}_{k} \mid \mathbf{A}, \mathbf{X}, \overline{\mathbf{X}}\right)$,來提高 $P_{\theta}$ 的最終效能。
下面,將介紹如何找到 $p\left(\cdot \mid \mathbf{X}_{i}, \mathbf{z}_{j}\right)$,從而產生生成器 $Q_{\phi}$。
一個合適的方法是條件變分自編碼器(CVAE)[20,45],它可以幫助學習潛在變數 $\mathbf{z}_{j}$ 的分佈,和條件分佈 $p\left(\cdot \mid \mathbf{X}_{i}, \mathbf{z}_{j}\right)$。因此,本文采用 CVAE 模型 $Q_{\phi}(\overline{\mathbf{X}} \mid \mathbf{A}, \mathbf{X})$ 作為本文的生成器,其中 $\phi=\{\varphi, \psi\}$,$\varphi $ 表示其中的變分引數, $\psi$ 表示生成器引數。[32,45] 為推匯出 CVAE 的優化問題,用潛變數 $\mathbf{z}$ 寫出 $\log p_{\psi}\left(\mathbf{X}_{j} \mid \mathbf{X}_{i}\right)$:
$\begin{aligned}\log p_{\psi}\left(\mathbf{X}_{j} \mid \mathbf{X}_{i}\right) &=\int q_{\varphi}\left(\mathbf{z} \mid \mathbf{X}_{j}, \mathbf{X}_{i}\right) \log \frac{p_{\psi}\left(\mathbf{X}_{j}, \mathbf{z} \mid \mathbf{X}_{i}\right)}{q_{\varphi}\left(\mathbf{z} \mid \mathbf{X}_{j}, \mathbf{X}_{i}\right)} \mathrm{d} \mathbf{z}+K L\left(q_{\varphi}\left(\mathbf{z} \mid \mathbf{X}_{j}, \mathbf{X}_{i}\right) \| p_{\psi}\left(\mathbf{z} \mid \mathbf{X}_{j}, \mathbf{X}_{i}\right)\right) \\& \geq \int q_{\varphi}\left(\mathbf{z} \mid \mathbf{X}_{j}, \mathbf{X}_{i}\right) \log \frac{p_{\psi}\left(\mathbf{X}_{j}, \mathbf{z} \mid \mathbf{X}_{i}\right)}{q_{\varphi}\left(\mathbf{z} \mid \mathbf{X}_{j}, \mathbf{X}_{i}\right)} \mathrm{d} \mathbf{z}\end{aligned}$
Evidence lower bound (ELBO) 可以寫成:
$\mathcal{L}\left(\mathbf{X}_{j}, \mathbf{X}_{i} ; \psi, \varphi\right)=-K L\left(q_{\varphi}\left(\mathbf{z} \mid \mathbf{X}_{j}, \mathbf{X}_{i}\right) \| p_{\psi}\left(\mathbf{z} \mid \mathbf{X}_{i}\right)\right)+\int q_{\varphi}\left(\mathbf{z} \mid \mathbf{X}_{j}, \mathbf{X}_{i}\right) \log p_{\psi}\left(\mathbf{X}_{j} \mid \mathbf{X}_{i}, \mathbf{z}\right) \mathrm{d} \mathbf{z}\quad\quad\quad(6)$
其中:
編碼器 $q_{\varphi}\left(\mathbf{z} \mid \mathbf{X}_{j}, \mathbf{X}_{i}\right)=\mathcal{N}\left(f\left(\mathbf{X}_{j}, \mathbf{X}_{i}\right), g\left(\mathbf{X}_{j}, \mathbf{X}_{i}\right)\right)$
解碼器 $p_{\psi}\left(\mathbf{X}_{j} \mid \mathbf{X}_{i}, \mathbf{z}\right)=\mathcal{N}\left(h\left(\mathbf{X}_{i}, \mathbf{z}\right), c I\right)$。
編碼器是一個兩層的MLP,$f$ 和 $g$ 共用第一層,第二層採用不同的引數。解碼器 $h$ 是兩層的MLP。為了易於處理,生成器 $Q(\overline{\mathbf{X}} \mid \mathbf{A}, \mathbf{X})$ 在所有節點上 $v_{i} \in V$ 使用同樣的引數。
Optimization of the MLE
首先,引數 $\phi=\{\psi, \varphi\}$ 可以通過最大化生成器的 $\text{ELBO}$ ($\text{Eq.6}$) 來進行優化,即對生成器進行訓練。
其次,通過最大化 $\text{Eq.4}$,在固定 $\phi$ 的條件下對引數 $\theta$ 進行優化,即給定 $\mathbf{Y}_{k}$ 關於 $\mathbf{A}$、$\mathbf{X}$、$\overline{\mathbf{X}}$ 的條件分佈,訓練下游的GNN模型:
$P_{\theta}\left(\mathbf{Y}_{k} \mid \mathbf{A}, \mathbf{X}, \overline{\mathbf{X}}\right) \propto-\overline{\mathcal{L}}(\theta \mid \mathbf{A}, \mathbf{X}, \overline{\mathbf{X}}, \phi)\quad\quad\quad(7)$
其中:
$\overline{\mathcal{L}}(\theta \mid \mathbf{A}, \mathbf{X}, \overline{\mathbf{X}}, \phi)=-\sum_{k \in \mathbf{T}} \sum_{f=1}^{C} \mathbf{Y}_{k f} \ln \left(\operatorname{softmax}(\operatorname{GNN}(\mathbf{A}, \mathbf{X}, \overline{\mathbf{X}}))_{k f}\right)$
2.2 The Architecture of LA-GNN
本節使用 GCN、GAT、GCNII 和 GRAND 作為骨幹,並在半監督節點分類任務上進行測試。將修改後的 GNN 架構命名為 LA-GNN,其中 LA 的意思是區域性增強。
LA-GCNA
2 層 LA-GCN 的定義如下:
$\mathbf{H}^{(2)}=\sigma\left(\hat{\mathbf{A}}\left(\sigma\left(\hat{\mathbf{A}} \mathbf{X} \mathbf{W}_{1}^{(1)}\right)\left\|\sigma\left(\hat{\mathbf{A}} \overline{\mathbf{X}}_{1} \mathbf{W}_{2}^{(1)}\right)\right\| \cdots \| \sigma\left(\hat{\mathbf{A}} \overline{\mathbf{X}}_{n} \mathbf{W}_{n+1}^{(1)}\right)\right) \mathbf{W}^{(2)}\right) \quad\quad\quad(8)$
GCNII[6] 在 $\mathbf{X}$ 上應用全連線神經網路,在前向傳播前獲得低維初始表示 $\mathbf{H}^{(0)}$,因此本文在 $\mathbf{X}$ 和 $\overline{\mathbf{X}}$ 上應用全連線神經網路,獲得 $\mathbf{H}^{(0)}$,如下:
$\mathbf{H}^{(0)}=\sigma\left(\mathbf{X} \mathbf{W}_{1}^{(0)}\right)\left\|\sigma\left(\overline{\mathbf{X}}_{1} \mathbf{W}_{2}^{(0)}\right)\right\| \cdots \| \sigma\left(\overline{\mathbf{X}}_{n} \mathbf{W}_{n+1}^{(0)}\right)\quad\quad\quad(9)$
$\mathbf{H}^{(0)}$ 被送入下一個正向傳播層。
此外,我們不需要修改GAT和GRAND 的體系結構,只需要將生成的特徵矩陣新增到輸入中。
2.3 Active Learning
在本節中,我們將介紹整個訓練框架的一個技巧。在生成器的訓練完成後,它包含了一個使用 $Q_{\phi}(\overline{\mathbf{X}} \mid \mathbf{A}, \mathbf{X})$ ($Eq. 4$) 用於推斷的問題,因為 $Q$ 可能從分佈的側面生成一些樣本。這個關鍵的問題使推論效率低下。受[30]的啟發,我們引入了主動學習來捕獲合適的生成的特徵矩陣和相應的生成器,這提高了推理效率,並有助於MLE的優化。在主動學習過程中,每個特徵的概率與獲取函數評估的不確定性成正比。我們採用 Bayesian Active Learning by Disagreement (BALD) acquisition function[17],對 Monte Carlo (MC) dropout samples 中最重要的推斷進行取樣:
$U(\overline{\mathbf{X}}) \approx H\left[\frac{1}{N} \sum_{n=1}^{N} P\left(\mathbf{Y}_{k} \mid \overline{\mathbf{X}}, \boldsymbol{\omega}_{n}\right)\right]-\frac{1}{N} \sum_{n=1}^{N} H\left[P\left(\mathbf{Y}_{k} \mid \overline{\mathbf{X}}, \boldsymbol{\omega}_{n}\right)\right]\quad\quad\quad(10)$
其中,$N$ 為MC樣本數,$\boldsymbol{\omega}_{n}$ 為第 $N$ 個 MC dropout sample 的網路取樣引數。較高的BLAD得分表示網路對所生成的特徵矩陣具有較高的不確定性。因此,人們傾向於選擇它來改進 GNN 模型。最後,在 Algorithm 1 中總結了整個演演算法框架,顯示了 $Eq.4$ 的優化.

3 Discussion
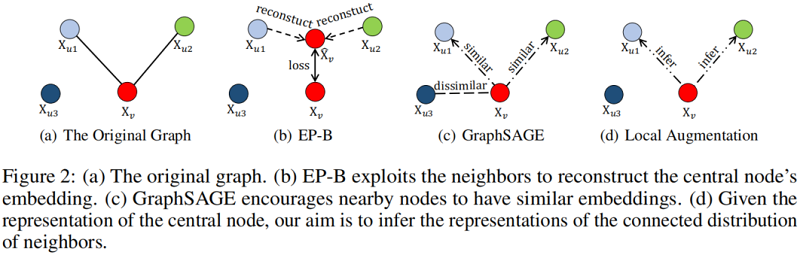
Connection to EP-B and GraphSAGE
討論本文提出的模型如何區別於經典的圖上的表示學習模型。以往的方法如 EP-B[13] 和 GraphSAGE[16] 依賴於中心節點與其鄰居嵌入之間的重構損失函數。
EP-B 的目的是通過優化目標來最小化重建誤差:
$\min \sum_{u \in V \backslash\{v\}}\left[\gamma+d\left(\underset{\mathbf{X}_{v}}{ }, \mathbf{X}_{v}\right)-d\left(\tilde{\mathbf{X}}_{v}, \mathbf{X}_{u}\right)\right]$
其中,$\mathbf{X}_{v}$ 表示目標節點,$\mathbf{X}_{u}$ 表示鄰居節點;$\tilde{\mathbf{X}}_{v}=\operatorname{AGG}\left(\mathbf{X}_{l} \mid l \in \mathcal{N}(v)\right)$ 表示來自鄰居的重建;$\gamma$ 指的是偏置。
GraphSAGE利用負取樣來區分遠端節點對的表示,強制附近的節點具有相似的表示形式,並通過最小化以下目標函數,強制不同的節點變得不同。
$-E_{u \sim \mathcal{N}(v)} \log \left(\left(\sigma\left(\mathbf{X}_{u}^{T} \mathbf{X}_{v}\right)\right)\right)-\lambda E_{v_{n} \sim P_{n}(v)} \log \left(\left(\sigma\left(-\mathbf{X}_{v_{n}}^{T} \mathbf{X}_{v}\right)\right)\right)$
其中,$\mathbf{X}_{v}$ 表示目標節點,$\mathbf{X}_{u}$ 表示的是遠離的節點,$P_{n}(v)$ 是負取樣。
這些方法建立在相鄰節點共用相似屬性的假設之上。相比之下,本文的模型並不依賴於這種假設,而是從中心節點表示的條件分佈中生成相鄰節點的特徵。給定目標節點 $\mathbf{X}_{v}$,本文的目標是學習鄰居節點 $\mathbf{X}_{u}$ 的條件分佈。Figure 2 說明了基於重建的圖表示學習與我們提出的框架之間的比較。而我們的區域性增強方法是以生成的方式利用鄰居的第三種正規化。
4 Experiments
在本節中,我們將評估我們所提出的模型在各種公共圖資料集上的半監督節點分類任務上的效能,並將我們的模型與最先進的圖神經網路進行比較。我們還進行了額外的實驗,以展示我們的設計的必要性和它對缺失資訊的魯棒性。
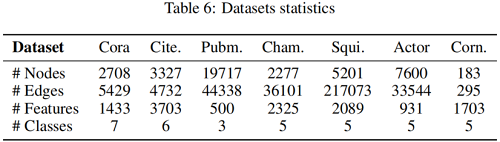
資料集
半監督節點分類
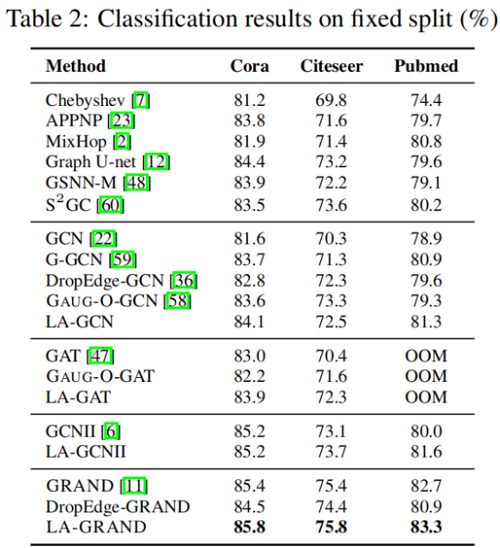
我們在三個資料集Cora、Citeseer和Pubmed上應用標準的固定分割[55],每個類有20個節點用於訓練,500個節點用於驗證,1000個節點用於測試。
對於 Squirrel, Actor, Chameleon 和 Cornell 資料集,我們取10個隨機分割[41],其中 10%、30% 和 60% 進行訓練、驗證、測試;測量GCN、GAT、GCNII和相應的修改模型的效能。
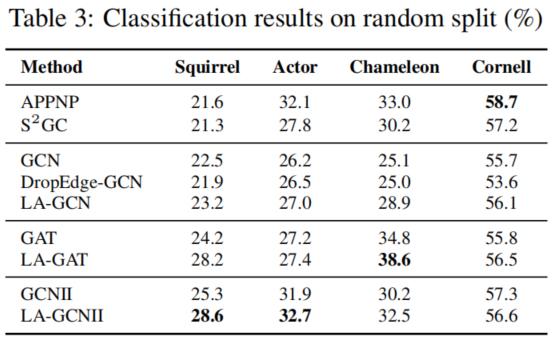
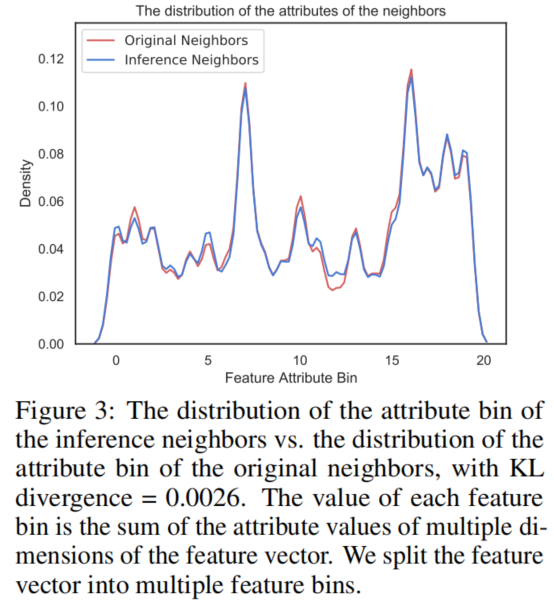
屬性分佈
我們還提供了我們生成的特徵矩陣分佈的分析。Figure 3 顯示了原始鄰居和推理鄰居的屬性分佈,這可以證明我們的推理特徵矩陣遵循初始特徵矩陣的分佈。
消融研究
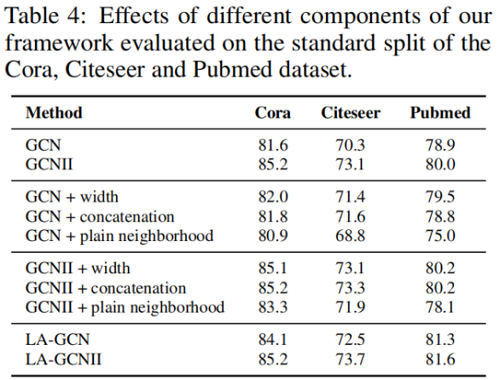
在本節中,為了證明我們提出的生成框架的有效性,我們進行了實驗,將LA-GNN與其幾個沒有生成建模的消融變體進行了比較。結果如表4所示。「GCN+width」只增加了GCN和GCNII的第一個網路層寬度來匹配LAGNN,而不提供生成的樣本作為輸入。「+連線「只將生成的LA-GNN的特徵矩陣替換為中心節點的原始特徵矩陣」。「「+平原鄰域」將生成的特徵矩陣替換為鄰域特徵矩陣,其中每一行對應於隨機取樣鄰域的特徵向量。結果表明,前兩個變體對主幹模型沒有明顯的改進,第三種變體甚至導致退化。通過消除這些與我們的核心方法無關的混雜因素可能有助於最終效能的可能性,很明顯,表2和表3中的效能增益是由於我們提出的生成式區域性增強框架。
5 Conclusion
References
因上求緣,果上努力~~~~ 作者:Learner-,轉載請註明原文連結:https://www.cnblogs.com/BlairGrowing/p/16332590.html