遊戲架構設計——高效能並行程式設計
這次的主題主要是利用執行緒級並行減少 CPU-bound,從多執行緒的角度出發
CPU-bound 與 memory-bound
float 型別的計算類耗時:
- 1次float乘法 ≈ 1次float減法 ≈ 1次float加法≈ 4次float加法(SIMD優化成功)≈ 32次float加法(CPU有8核心且SIMD優化成功)
- 1次float除法 ≥ 2次float加法
float 型別的記憶體存取耗時:
- 1次float讀寫 ≈ 8次float加法
我們知道,得益於CPU的流水線,CPU可以一邊計算一邊存取下一次即將要用到的記憶體。那麼就區分清楚 瓶頸到底是計算量還是記憶體讀寫,因為這意味著CPU的時間到底是哪個部分在等待另一個部分的完成
- 計算瓶頸(CPU-bound):當計算量(如float的加減乘除)耗時大於記憶體讀寫的耗時,那麼就稱遇到了CPU-bound
- 記憶體瓶頸(memory-bound):當記憶體讀寫的耗時大於計算量(如float的加減乘除)耗時,那麼就稱遇到了memory-bound
切記,並行只能加速計算的部分,不能加速記憶體讀寫的部分,因此並行能減輕 CPU-bound,但不減輕 memory-bound
// cpu-bound
// 利用平行計算會有較好的加速效果,因為瓶頸在於計算量
for(int i = 0; i<1024; i++){
a[i] = std::sin(i);
}
// memory-bound
// 利用平行計算的加速效果並不明顯,因為瓶頸在於記憶體存取
for(int i = 0; i<1024; i++){
a[i] = 1;
}
對於 a[i] = func(a[i]),1次讀1次寫,那麼 func 裡應當包含 16 次加法,才能和記憶體的延遲相抵消;如果有 8 個核心,則需要 16*8=128 次加法,才能避免 memory-bound ,否則加速比會達不到 8
為什麼有時候使用 SIMD、多執行緒的平行計算會沒什麼效果甚至效能更差?很大可能是因為程式碼遇到 memory-bound 了,而不是 CPU-bound。也就是CPU計算耗時少於記憶體存取耗時,導致 CPU 大部分時間浪費在等記憶體延遲,這時候計算得再快也沒有用。此外多執行緒排程也有一定額外開銷。
利用 CPU 多核
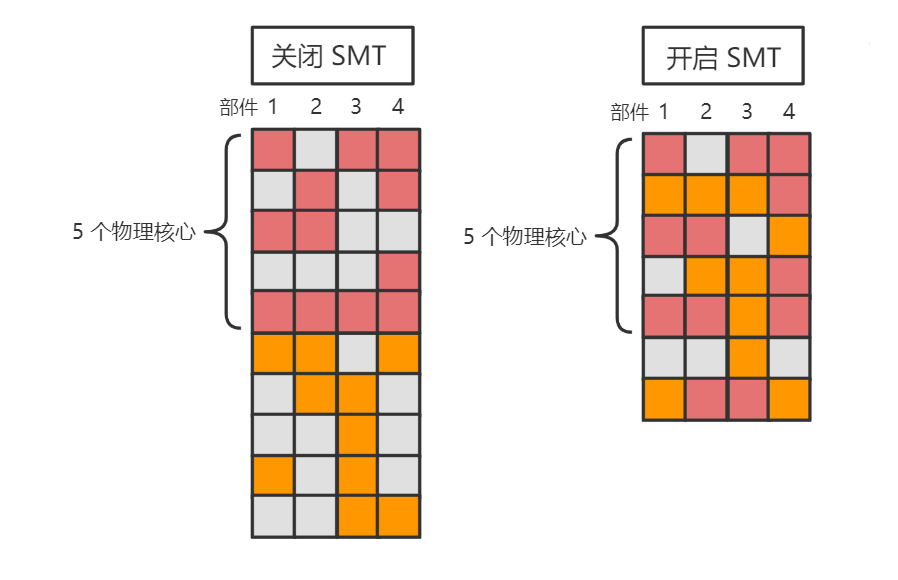
物理核心、邏輯核心
現代 PC 端 CPU 都是標榜著例如 「4核8執行緒」,其中的 「8執行緒」 並不是 OS 概念中的執行緒,而是邏輯核心。這其中涉及到了 CPU 的一種技術,即 SMT(同時多執行緒)技術。在這種技術下,就需要分清楚物理核心和邏輯核心的概念,以便後面知道該利用 CPU 的多少核心
物理核心:實打實的物理 CPU,多個物理核心可以真正並行(而非並行)執行任務,因此理想狀態的程式中,應該開啟與物理核心數量一致的執行緒,這樣理論上就能把 CPU 的所有核心都充分利用上
邏輯核心:在物理核心的前端上增加一小部分資源,對上層偽裝成多個核心
為什麼要提供多個邏輯核心,而不是從 OS 層面開多幾個執行緒?因為一個執行緒佔用一個物理核心時,實際上該物理核心很大概率仍然有相當資源沒有利用到(例如一些暫存器、ALU部件),而多個邏輯核心可以儘量讓物理核心的所有資源更進一步利用。
實際上,更多人知道的是 OpenMP 而非 TBB 庫,因為 OpenMP 的使用比較方便嵌入,而且整合到編譯器中,只需要編譯器開啟
-fopenmp選項便可使用。但是相比於 OpenMP,TBB 庫支援更多方便於並行程式設計的 API,例如提供了並行容器;又可以為並行程式培養出更好的並行程式設計風格和更高的抽象層,從而更容易維護並行程式設計程式碼。
任務排程
正如前面說到,我們可以只關心並行任務,而不關心執行緒的管理。
TBB 就提供了一個用於任務排程的 API,即 任務組 tbb::task_group:
- 通過
run(const Function & f)新增並執行一個並行任務 - 通過
wait()來等待該任務組的所有並行任務的完成
tbb::task_group tg;
// 一邊下載東西,一邊播放音樂,一邊也接受互動
tg.run([&](){download("hello.zip");});
tg.run([&](){playSound("waiting.mp3");});
tg.run([&](){interact();});
// 阻塞等待至該任務組的所有任務都完成
tg.wait();
也可以繞過任務組 API ,直接簡單的非同步執行一個或多個任務 tbb::parallel_invoke(const Function & f,...):
tbb::parallel_invoke(
[&](){download("hello.zip");},
[&](){playSound("waiting.mp3");},
[&](){interact();},
);
C++11 也有類似的API
std::asycn(cosnt Func& f),含義為非同步執行一個任務,不過它沒有任務分組的概念。更多關於 C++11 多執行緒語法的可以看看我 以前總結的筆記
並行迴圈
在大部分的迴圈程式碼中,其實是可以用多執行緒來進行並行迴圈的(例如理想情況下,可以讓4個執行緒分別進行1/4的迴圈次數,從而讓迴圈加速八倍)
for (i = 0; i < 1024; i++) a[i] = std::sin(i);
// 期望利用利用多執行緒變成類似如下行為:
// 執行緒1:for (i = 0; i < 256; i++) a[i] = std::sin(i);
// 執行緒2:for (i = 256; i < 512; i++) a[i] = std::sin(i);
// 執行緒3:for (i = 512; i < 768; i++) a[i] = std::sin(i);
// 執行緒4:for (i = 768; i < 1024; i++) a[i] = std::sin(i);
OpenMP 並行迴圈 :
我們可以直接開啟編譯器的 -fopenmp 選項,並且在迴圈語句前加上#pragma omp parallel for 來方便地進行並行迴圈
#pragma omp parallel for num_threads(N):指定使用 N 個執行緒來進行並行迴圈
#pragma omp parallel for
for (i = 0; i < 1024; i++)
{
a[i] = std::sin(i);
}
TBB 並行迴圈:
-
void parallel_for(Index first, Index last, const Function & f) -
void parallel_for_each(Iterator first, Iterator last, const Body& body) -
void parallel_for(const Range& range, const Body & body)
// 面向初學者的最簡單的 parallel for
tbb::parallel_for((size_t)0, (size_t)n, [&](size_t i){
a[i] = std::sin(i);
});
// 基於迭代器區間的 parallel for
std::vector<float> a(1024);
tbb::parallel_for_each(a.begin(), a.end(), [&](float& f){
f = 233.f;
});
// 一維區間的 parallel for
tbb::parallel_for(tbb::blocked_range<size_t>(0,n),
[&](tbb::blocked_range<size_t> r){
for(size_t i = r.begin(); u < r.end(); i++){
a[i] = std::sin(i);
}
});
// 二維區間的 parallel for
tbb::parallel_for(tbb::blocked_range2d<size_t>(0, n, 0, n),
[&](tbb::blocked_range2d<size_t> r){
for(size_t i = r.cols().begin(); i < r.cols().end(); i++)
for(size_t j = r.rows().begin(); j < r.rows().end(); j++)
{
a[i*n+j] = std::sin(i) * std::sin(j);
}
});
// 三維區間的 parallel for
tbb::parallel_for(tbb::blocked_range3d<size_t>(0, n, 0, n, 0, n),
[&](tbb::blocked_range3d<size_t> r){
for(size_t i = r.pages().begin(); i < r.pages().end(); i++)
for(size_t j = r.cols().begin(); j < r.cols().end(); j++)
for(size_t k = r.rows().begin(); k < r.rows().end(); k++)
{
a[(i*n+j)*n+k] = std::sin(i) * std::sin(j) * std::sin(k);
}
});
但是不是所有的迴圈都是可以直接進行並行化,在遇到資料依賴的情況下,我們還需要做一些額外處理來避免存取衝突
常見基本並行演演算法
Map(對映)
將每個元素通過計算對映成某個值
- 序列對映:時間複雜度 \(O(n)\),工作複雜度 \(O(n)\)
- 並行對映:時間複雜度 \(O(n/c)\),工作複雜度 \(O(n)\)
注:\(c\) 為執行緒數
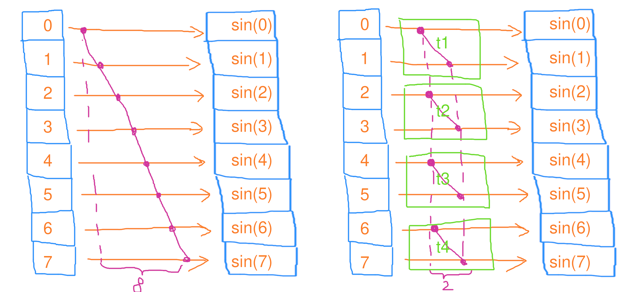
void mapping(std::vector<float>& a)
{
for(size_t i = 0; i < n; i++)
a[i] = std::sin(i);
}
void mapping(std::vector<float>& a)
{
tbb::task_group tg;
for (size_t t = 0; t < c; t++)
{
size_t begin = t * n / c;
size_t end = std::min(n, (t+1) * n / c);
tg.run([&, begin, end](){
for(size_t i = begin; i < end; i++)
a[i] = std::sin(i);
});
}
tg.wait();
}
Reduce(縮並)
對每個元素的對映結果以某種演演算法結合起來(例如,求總和)
- 序列縮並:時間複雜度 \(O(n)\),工作複雜度 \(O(n)\)
- 並行縮並:時間複雜度 \(O(n/c+c)\),工作複雜度 \(O(n)\)
- 將所有元素均分成 \(c\) 份,分別讓 \(c\) 個執行緒去做縮並;等所有執行緒完成後,再把序列地這 \(c\) 個結果縮並起來
其實,TBB 已經提供了封裝好的 API:
Value parallel_reduce(const Range& range, const Value& identity, const RealBody& real_body, const Reduction& reduction)
- GPU 並行縮並:時間複雜度 \(O(logn)\),工作複雜度 \(O(n)\)
由於 GPU 的執行緒數往往成千上萬,因此 GPU 的演演算法可以視為擁有無限多個執行緒的並行演演算法;此外,GPU 並行縮並演演算法並不適合 CPU 多核,因為 CPU 核心數有限,過多的執行緒反而會導致頻繁的上下文切換開銷,造成效能下降
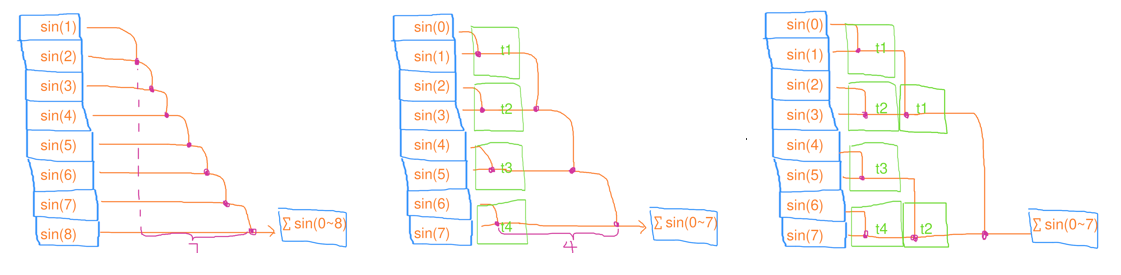
// 序列縮並
float reduce()
{
float res = 0;
for(size_t i = 0; i < n; i++)
res += std::sin(i);
return res;
}
// 並行縮並
float reduce()
{
float res = 0;
tbb::task_group tg;
std::vector<float> tmp_res(c);
for(size t = 0; t < c; t++)
{
size_t begin = t * n / c;
size_t end = std::min(n, (t+1) * n / c);
tg.run([&, t, begin, end](){
float local_res = 0;
for(size_t i = begin; i < end; i++)
local_res += std::sin(i);
tmp_res[t] = local_res;
});
}
tg.wait();
for(size_t t = 0; t < c; t++)
{
res += tmp_res[t];
}
return res;
}
Scan(掃描)
在縮並的基礎上,還把中間結果也存到陣列裡(例如,字首和陣列)
- 序列掃描:時間複雜度 \(O(n)\),工作複雜度 \(O(n)\)
- 並行掃描:時間複雜度 \(O(n/c+c)\),工作複雜度 \(O(n+c)\)
- PART1:將所有元素均分成 \(c\) 份,分別讓 \(c\) 個執行緒去做掃描
- PART2:等所有執行緒完成後,再把序列地這 \(c\) 個結果去做掃描
- PART3:將 \([n/c-1, n)\) 的元素均分成 \(c-1\) 份,分別讓 \(c-1\) 個執行緒去做掃描
其實,TBB 已經提供了封裝好的 API:
Value parallel_scan(const Range& range, const Value& identity, const Scan& scan, const ReverseJoin &reverse_join)
- GPU 並行掃描:時間複雜度 \(O(logn)\),工作複雜度 \(O(nlogn)\)
在一些演演算法中,改成並行演演算法可能帶來時間複雜度的降低,但是也可能會導致工作複雜度的提升(工作額外乾的事情變多了,耗電量也變得更多)
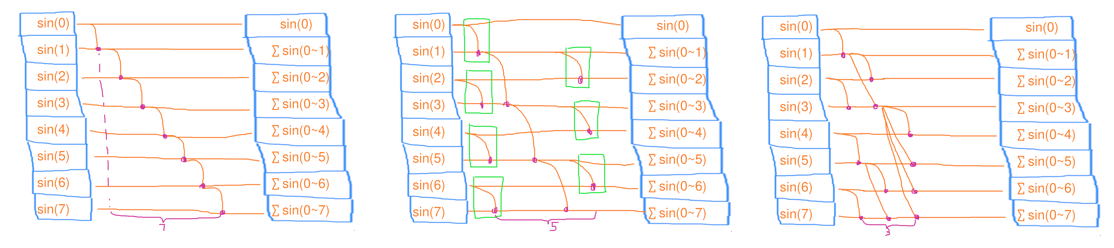
// 序列掃描
void scan(std::vector<float>& a)
{
float res = 0;
for(size_t i = 0; i < n; i++)
{
res += std::sin(i);
a[i] = res;
}
}
// 並行掃描
void scan(std::vector<float>& a)
{
float res = 0;
// PART 1
tbb::task_group tg1;
std::vector<float> tmp_res(c);
for (size_t t = 0; t < c; t++)
{
size_t begin = t * n / c;
size_t end = std::min(n, (t+1) * n / c);
tg1.run([&, t, begin, end](){
float local_res = 0;
for(size_t i = begin; i < end; i++)
local_res += std::sin(i);
tmp_res[t] = local_res;
})
}
tg1.wait();
// PART 2
for (size_t t = 0; t< c; t++)
{
tmp_res[t] += res;
res = tmp_res[t];
}
// PART 3
tbb::task_group tg2;
for (size_t t= 1; t < c; t++)
{
size_t begin = t * n / c - 1;
size_t end = std::min(n, (t+1) * n / c) - 1;
tg2.run([&, t, begin, end](){
float local_res = tmp_res[t];
for(size_t i = begin; i < end; i++)
{
local_res += std::sin(i);
a[i] = local_res;
}
})
}
tg2.wait();
}
Filter(篩選)
將集合中的一部分元素篩選出來形成新的集合
- 序列篩選:依次將篩選結果推入到集合中
- 並行篩選(使用中間結果集合):先將篩選結果推入到 執行緒區域性(thread-local)的中間結果集合,最後再將中間結果集合的資料推入到最終結果集合裡
- GPU 並行篩選:算出每個元素需要往 vector 推播的資料數量(本例只能是0或1);再對算出的結果進行並行掃描,得出每個 i 要寫入的索引;最後對每個元素進行並行迴圈,根據索引來寫入資料
如果每個執行緒直接將篩選結果推入到集合中時還需要進行互斥操作(例如上鎖、解鎖),會導致大量時間浪費在等待互斥上
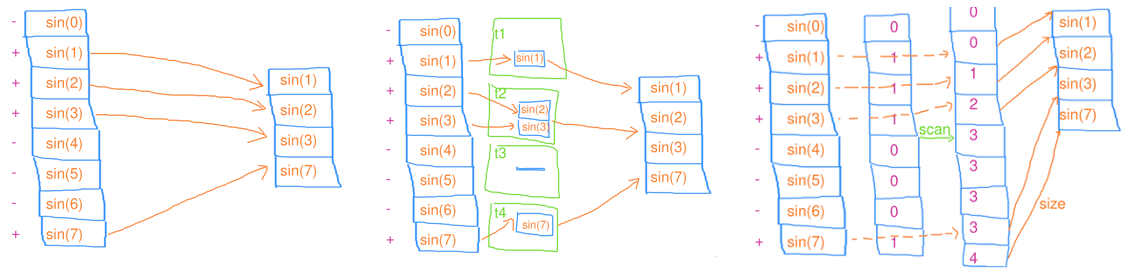
// 序列篩選
void filter(std::vector<float>& a)
{
for(size_t i = 0; i < n; i++)
{
float val = std::sin(i);
if(val > 0) a.push_back(val);
}
}
// 並行篩選
void filter(std::vector<float>& a)
{
tbb::parallel_for(
tbb::blocked_range<size_t>(0, n),
[&](tbb::blocked_range<size_t> r)
{
std::vector<float> local_a;
local_a.reserve(r.size());
for(size_t i = r.begin(); i < r.end(); i++)
{
float val = std::sin(i);
if(val > 0) local_a.push_back(val);
}
std::lock_guard lck(mtx);
std::copy(local_a.begin(), local_a.end(), std::back_inserter(a));
}
);
}
並行分治
很多分治演演算法是可以通過平行計算去加速的,舉一個並行快排的例子
並行快速排序
其實,TBB 已經提供了封裝好的 API:
void parallel_sort(Iterator first, Iterator last)
- 為了避免細分的並行任務過多,需要在資料足夠小時,改用序列排序
- 選取樞紐元時不選擇第一個元素,而是隨機選擇一個元素,避免基本有序情況
- 採用並行分治
void quick_sort(int* data, size_t size)
{
if(size <= 0)
return;
// 資料足夠小時,改用序列排序
if(size < (1<<16))
{
std::sort(data+left, data+right);
return;
}
// 隨機選取一個樞紐元,避免基本有序情況
size_t mid = std::hash<size_t>{}(size);
mid ^= std::hash(void*){}(static_cast<void*>(data));
mid %= size;
std::swap(data[0], data[mid]);
int pivot = data[0];
// 劃分
size_t left = 0
while (left < right)
{
while (left < right && !(data[right] < pivot))
right--;
if (left < right)
data[left++] = data[right];
while (left < right && data[left] < pivot)
left++;
if (left < right)
data[right--] = data[left];
}
data[left] = pivot;
// 並行分治
tbb::parallel_invoke(
[&](){quick_sort(data, left);},
[&](){quick_sort(data + left + 1, size - left - 1);}
);
}
並行容器
TBB 提供瞭如下用於並行程式設計的並行容器,對標於 C++ STL,它可以保證這些並行容器操作的多執行緒安全性:
tbb::concurrent_vectortbb::concurrent_unordered_maptbb::concurrent_unordered_settbb::concurrent_maptbb::concurrent_settbb::concurrent_queuetbb::concurrent_priority_queue- ...
tbb::concurrent_vector
舉個並行容器的例子
擁有以下特點:
-
記憶體不連續,但指標和迭代器不失效:
std::vector<int>擴容時需要重新 malloc 一段更大的記憶體然後把每個元素移動過去,並釋放掉舊記憶體。這就導致了陣列種每個元素的地址改變了,從而之前儲存的指標和迭代器便失效了(這就意味著某個執行緒在push_back的時候,其它執行緒都不可以讀取該陣列的元素)tbb::concurrent_vector不保證所有元素在記憶體中時連續的,但是換來的好處是:每次擴容時,新 malloc 出的記憶體只會存放新增的元素,而不會動舊記憶體上的元素,從而讓之前儲存的指標和迭代器不會失效
-
可以被多個執行緒同時
push_back而不出錯;在某個執行緒在push_back的時候,其它執行緒都可以讀取該陣列的元素而不出錯 -
建議按迭代器順序存取,而不建議通過索引隨機存取(由於記憶體不連續,隨機存取效率會低些)
應用
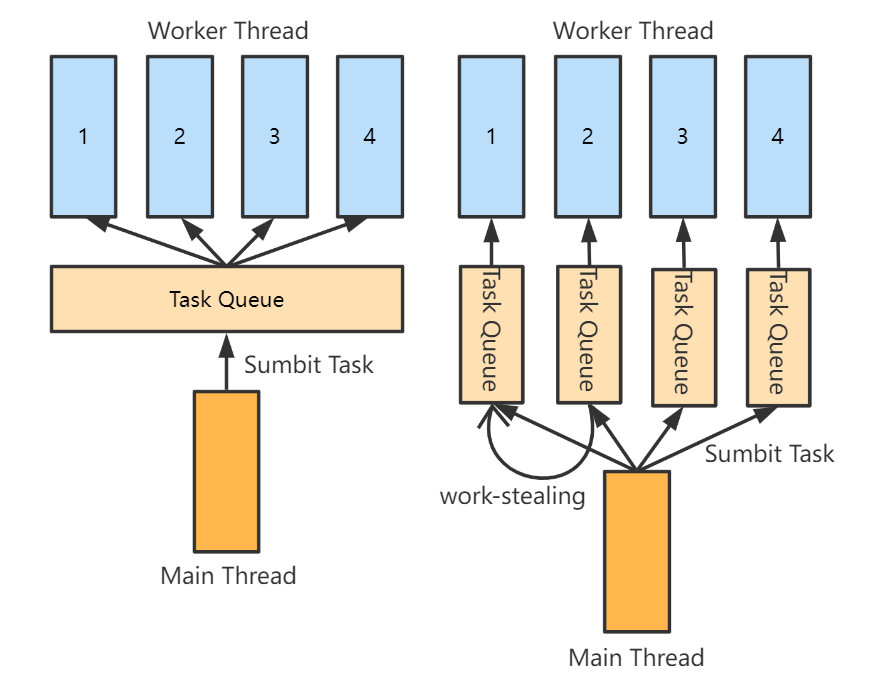
執行緒池
執行緒池簡單來說,就是提前建立若干個 Worker Thread,讓它們各自跑一個包含了無限迴圈的 work 函數
當然這個迴圈並不是真正意義上的無限迴圈,而是用一個 running 標記作為迴圈條件,如果需要停止執行緒池工作,只需要將該標記置 false 即可
而這個 work 函數做的事情,便是重複迴圈地從任務佇列中取出任務並執行之;如果任務佇列沒有任務時,則當前執行緒需要等待直到任務列表被提交了新的任務
void ThreadPool::work()
{
while (_is_running)
{
// 從 Task Queue 中取出一個 task
Task task = takeOneTask();
if(task) task(); // do the task
}
}
工作竊取法(Work Stealing)
// 出隊
Task LockFree_Queue::pop()
{ unsigned int len_old = len.fetch_sub(1);
// 非空時,取出一個隊首 task
if (len_old > 0)
return arr[head.fetch_add(1) % MAX_QUEUE_SIZE];
// 為空時,恢復原長度
len.fetch_add(1);
return nullptr;
}
那麼執行緒池的 takeOneTask 函數還得改成:
// 從 Task Queue 中取出隊首的 task
Task ThreadPool::takeOneTask()
{
auto task = _tasks.pop();
if (task)
{
return task;
}
// 佇列為空時,等待 Main Thread 推播新的 task 後通知
if (_is_running)
{
std::unique_lock<std::mutex> lk(_mtx);
_cond.wait(lk);
}
return nullptr;
}
Job System
Job System 和執行緒池的概念有點相似,使用者僅需要關注提交 Job 到 Job Queue 中,然後讓各個執行緒來從 Job Queue 取 Job 來執行。
不過 Joby System 額外的特點是,可以處理具有依賴關係的 Job,即某些 Job 可能需要依賴另一些 Job 的完成。
因此我們可以提交 Job 到 Job System 先,然後在 Job System 層面處理依賴關係後,再由 Job System 將可執行的 Job 提交給執行緒池執行
依賴性
Job System 首先要考慮的是 Job 之間的依賴關係。
例如下圖,Job 4 依賴於 Job1,Job 6 依賴於 Job 1,2,3 ... 這將是一個多對多的結構
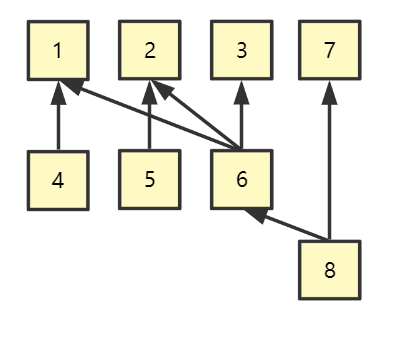
那麼一種可能的設計方式,將 Job 定義為以下結構:
struct Job{
int id; // Job ID
std::function<void()> task; // 任務
std::list<int> children; // 所有子 Job ID
std::atomic<int> dependece; // 依賴的父 Job 數量
};
-
一開始只將 dependece 為 0 (意味著無依賴)的 Jobs 提交執行緒池執行
-
每次做完一個 Job 後,需要對它所有 children 的 dependece 減去一(由於可能多個執行緒都同時對同一個 children 減去一,因此需要引入原子操作)
- 如果對某個 child 的 dependece 減去一後變成 0 (意味著依賴的 Job 都執行完了),那麼將該 Child Job 提交執行緒池執行
多執行緒渲染
傳統的舊圖形庫(如OpenGL)一般對多執行緒渲染的支援並不是很友好或者幾乎實現不了,而較新的圖形庫(如DX12和Vulkan)都很好的提供了方便支援多執行緒渲染的 API。因此目前大部分基於舊圖形庫的渲染都是單執行緒渲染,但是多執行緒渲染將會是未來的一個趨勢,畢竟連大部分手機都擁有多核心
單執行緒渲染框架
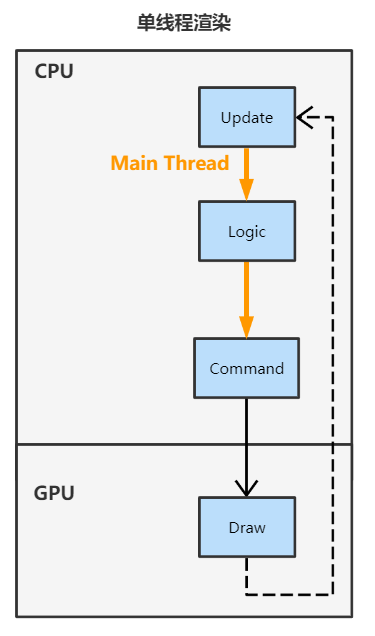
- Main Thread 先進行邏輯計算,然後算出需要何種渲染命令並提交(Draw Call),然後排程 GPU 進行渲染,在渲染完成前 Main Thread 是要一直阻塞等待的
- GPU 執行完渲染命令後,Main Thread 便停止阻塞,恢復執行新一幀的迴圈
多執行緒渲染框架(example)
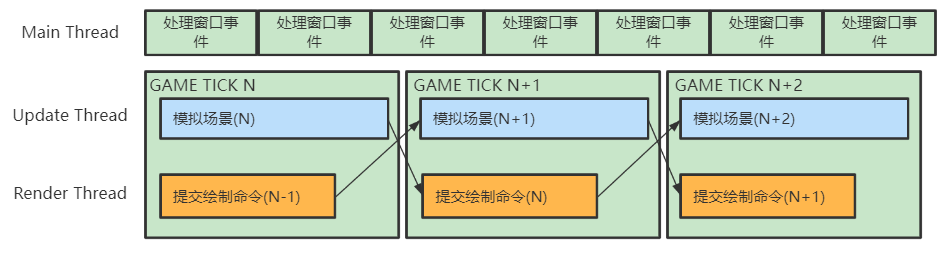
首先執行緒分為三大類:
- Main Thread : 處理 Windows 視窗事件和轉發事件給其它執行緒
- Update Thread(需要同步) : 每一幀模擬場景,為渲染執行緒準備資料
- Render Thread(需要同步):每一幀對上一幀模擬好的場景資料進行繪製命令的提交
例如,複雜場景下可能分成 4 個 Render Job,各自負責 25% 的場景物體繪製
不過需要注意的是,雖然這裡列的是執行緒種類,但仍應該以提交 Job 的形式來驅動多執行緒,而非直接使用執行緒
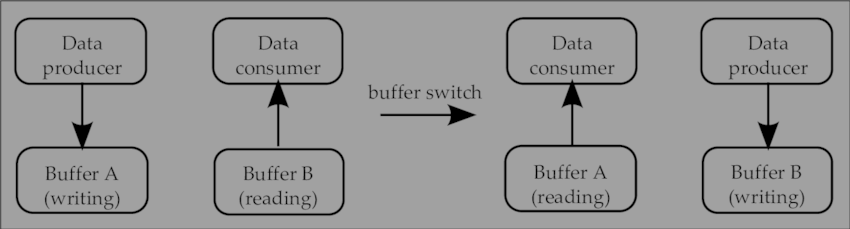
維護多份場景資料:
為了讓 Update Thread 寫入的場景狀態和 Render Thread 讀取的場景狀態不產生衝突,為此,需要準備多份場景狀態以便進行並行讀寫。例如使用 Double Buffering 技術,讓Update Thread 寫入當前幀的場景資料,讓 Render Thread 讀取上一幀的場景資料:
充分利用主執行緒:
由於在多執行緒框架裡,主執行緒乾的事情就是休眠等待所有分執行緒完成任務,最後提交指令。
為了充分利用主執行緒,MaxwellGeng 大佬在知乎提到的做法是使用了 Triple Buffering,即開 3 個 Frame Buffer,一個用於提交 Command List,一個用於提交 Command Queue,另一個用於給 GPU 執行的操作
Async Compute:
DirectX12 中的 Command Queue 有 3 種:
- Direct Command Queue(常用):用於 GPU 渲染圖形
- Compute Command Queue(常用):用於 GPU 通用計算,例如用到各種 Compute Shader
- Copy Command Queue:用於多顯示卡之間的資料拷貝
在現代渲染管線中,也常常需要用到 GPU 通用計算,例如可以把這麼一些操作提交給 Compute Queue 去做:
- 一些耗時的或者不要求本幀立即就用到的運算(例如:貼圖載入,計算 AO)
- 一些和圖形渲染無關的運算
如果分出兩條 Command Queue (Direct & Compute)的線路進行提交,可以互補顯示卡負載;例如,渲染 Shadow Map 的同時計算 AO,一個對頻寬負載大,一個對SM(流處理器)負載大。
基於上述,我們可以單獨對 Compute 相關的 Job 進行另一種時間軸(而非一定每幀提交)的非同步提交
只不過我們需要序列地提交 Command List,因此大致流程需要這麼做:
- 在每幀的末尾收集這一幀內提交的所有 Command List(包含 Compute 相關)
- 將 Compute 相關的 Command List 提交到 Compute Command Queue,GPU 執行完 Compute 後命中 Fence(圍欄) 訊號
- 等待 Fence 訊號,收到訊號後將 Graphics 相關的提交到 Direct Command Queue,提交完立即返回進行新一幀的迴圈
由於 Compute 的時間軸和 Graphics 的每幀時間軸不一定相同,所以有可能一幀內能收集到 0 個或多個 Compute Command List
渲染管線:
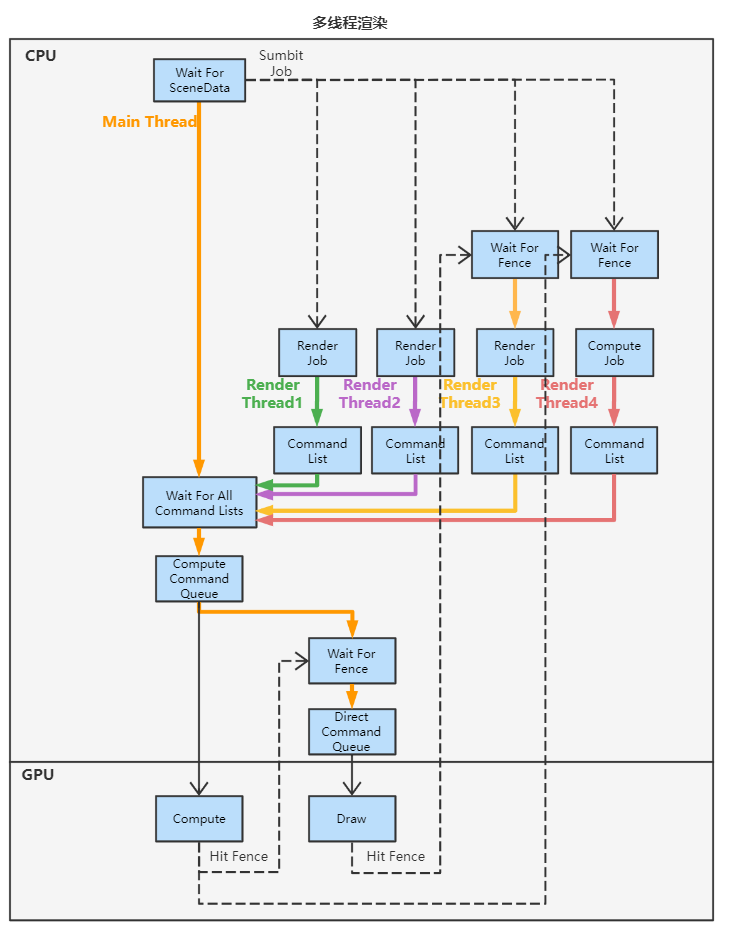
實際上多執行緒渲染的核心就是:
- 通過 Command List 解耦了 生成渲染命令 和 提交渲染命令 的行為
- 通過 Command Queue 解耦了 提交渲染命令 和 GPU執行渲染命令 的行為
參考
- [1] Intel | oneAPI Threading Building Blocks
- [2] 高效能並行程式設計課程 Parallel101 by 小彭老師
- [3] (CS149) 平行計算結構與程式設計
- [4] Modernizing a DirectX real-time renderer - Multi-threading the VQEngine
- [5] GDC2015 | Destiny's Multithreaded Rendering Architecture
- [6] Unity at GDC - Job System & Entity Component System
- [7] 面向DirectX 12的多執行緒渲染架構 | 知乎 MaxwellGeng
作者:KillerAery
出處:http://www.cnblogs.com/KillerAery/
本文版權歸作者和部落格園共有,歡迎轉載,但未經作者同意必須保留此段宣告,且在文章頁面明顯位置給出原文連線,否則保留追究法律責任的權利。