『忘了再學』Shell基礎 — 24、Shell正規表示式的使用
1、正規表示式說明
正規表示式和萬用字元的區別
- 正規表示式用來在檔案中匹配符合條件的字串。
- 萬用字元用來匹配符合條件的檔名。
在Shell中,使用在檔案當中搜尋字串的命令,如grep,awk,sed等命令(文字操作三劍客),可以支援正規表示式。
而在系統當中搜尋檔案的命令,如ls,find,cp這些命令不支援正規表示式,所以只能使用萬用字元來進行匹配了。
- 在Shell中只要是匹配字串,都適用於正則匹配。
- 正規表示式匹配的是以一行為單位進行包含匹配的,匹配上就顯示輸出該行文字,否則不顯示。
2、基礎正規表示式
| 元字元 | 作用 |
|---|---|
* |
匹配前一個字元匹配0次或任意多次。 |
. |
匹配除了換行符外任意一個字元。 |
^ |
匹配行首。例如:^hello會匹配以hello開頭的行。 |
$ |
匹配行尾。例如:hello$會匹配以hello結尾的行。 |
[] |
匹配中括號中指定的任意一個字元,只匹配一個字元。 例如: [aoeiu]匹配意一個母音字母,[0-9]匹配任意一位數位,[a-z][0-9]匹配小寫字和一位數位構成的兩位字元。 |
[^] |
匹配除中括號的字元以外的任意一個字元。 例如: [^0-9]匹配任意一位非數位字元,[^a-z]表示任意一位非小寫字母。 |
\ |
跳脫符。用於取消將特殊符號的含義取消。 |
\{n\} |
表示其前面的字元恰好出現n次。 例如: [0-9]\{4\}匹配4位元數位,[1][3-8][0-9]\{9\}匹配手機號碼。 |
\{n,\} |
表示其前面的字元出現不小於n次。 例如: [0-9]\{2,\}表示兩位及以上的數位。 |
\{n,m\} |
表示其前面的字元至少出現n次,最多出現m次。 例如: [a-z]\{6,8\}匹配6到8位元的小寫字母。 |
注意:Shell語言不是一個標準的完整語言,在其他語言中的正規表示式中,是不分基礎正則和擴充套件正則的。而Shell認為你不需要拿正則寫太過複雜的字串篩選格式,所以Shell建議把正規表示式分成基礎正則和擴充套件正則兩種。
3、練習
(1)準備工作
建立一個測試檔案test.txt
Seven times have I despised my soul:
——Kahlil Gibran
The first time when I saw her being meek that she might attain height.
The second time when I saw her limping before the crippled.
The third time when she was given to choose between the hard and the easy, and she chose the easy.
The fourth time when she committed a wrong, and comforted herself that others also commit wrong.
The fifth time when she forbore for weakness, and attributed her patience to strength.
The sixth time when she despised the ugliness of a face, and knew not that it was one of her own masks.
And the seventh time when she sang a song of praise, and deemed it a virtue.
(內容為紀伯倫——我曾七次鄙視自己的靈魂)
還有,為了方便檢視,我們可以給grep命令設定帶有顏色輸出,也就是給grep命令定義一個別名。
在當前使用者家目錄中的~/.bashrc檔案中設定grep命令別名:
# 我們當前的使用者是root使用者
# 執行命令
[root@localhost ~]# vim /root/.bashrc
# 新增內容
alias grep='grep --color=auto'
# 或者
# 針對所有使用者
# echo "alias grep='grep --color=auto'" >>/etc/bashrc
# 針對單個使用者
# echo "alias grep='grep --color=auto'" >>~/.bashrc
這樣在grep命令執行後的標準輸出中,就會將檔案中匹配的內容標識彩色。
注意:如果在XShell終端修改的~/.bashrc組態檔,需要關閉當前遠端視窗,重新開啟就可以實現了。
(2)*練習
我們執行如下命令,進行*匹配練習。
[root@localhost tmp]# grep "k*" test.txt
結果如下:

說明:(重點)
任何字母加上*,或者說任何符號加上*,都沒有任何含義,這樣會匹配所有內容,包括空白行。
因為*的作用是重複前一個字元0次或任意多次。
所以在Shell中的正則中,任何符號加上*是沒有任何含義的,所有的內容都會被匹配出來。
如果你需要匹配至少包含一個k字母的行,就需要這樣寫"kk*",代表匹配至少包含有一個K的行,也可以有多個k。(這行字串一定要有一個k,但是後面有沒有k都可以。)
如下圖:

我們可以看到,沒有k的行,和空行都被過濾掉了。
如果我們需要匹配至少兩個連續的ss字元,需要執行如下命令:
grep "sss*" test.txt

以此類推。
注意:
正則是包含匹配,只要含有就會列出,所以單獨搜尋一個k,執行grep "k" test.txt 命令,也能獲得和上面一樣的匹配結果。如下圖:

換句話說,上面這兩種寫法是一個意思,都是搜尋含有k字母的行,一行中有一個k字母就可以,有無數個k字母也可以,都會被匹配出來。
限位(制)符:
如果是上面描述的這種簡單匹配需求,使用哪種方式都可以。
但是有限位(制)符出現的匹配情況,帶*的方式,處理匹配的情況更豐富。
如下面一段文字:
Stay hungry, stay foolish. ——Steve Jobs
求知若飢,虛心若愚。——喬布斯
Stay hungry, stay folish. ——Steve Jobs
Stay hungry, stay fooolish. ——Steve Jobs
Stay hungry, stay foooolish. ——Steve Jobs
Stay hungry, stay fooooolish. ——Steve Jobs
我們可以看到上端文字中foolish中有不同數量的o。(自己隨意錯寫的)
如果我的需求是搜尋foolish單詞中有三個以上數量o的行,這個時候就需要限位(制)符了,
其中foolish單詞中的f和l就是限位(制)符的用法。
執行命令如下:
[root@192 tmp]# grep "foooo*lish" test2.txt
結果如下:
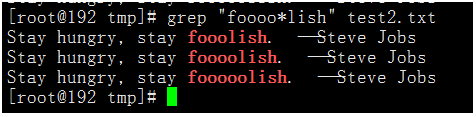
說明:其中前三個o代表固定有三個連續的o字母出現,最後一個o*代表可以匹配0次到任意多次個o字母。
在這種需要有限位(制)符情況下的匹配,加上*就非常好處理了。
(3).練習
正規表示式.匹配除了換行符外任意一個字元。
舉個例子:
文字test2.txt內容如下:
abc adapt 適應 xyz
abc adopt 採用 xyz
xyz adept 內行 abc
xyz floor 地板 abc
xyz flour 麵粉 abc
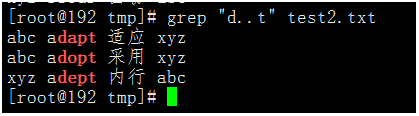
- 匹配在
d和t這兩個字母之間一定有兩個字元的單詞。
執行命令:grep "d..t" test2.txt
- 結合
*使用。
執行命令:grep "z.*a" test2.txt
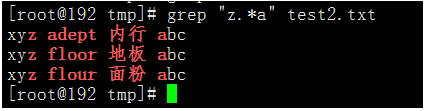
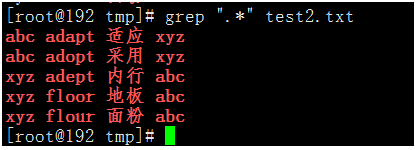
設定的是a和z兩個字母之間有任何字元的內容。 - 如果想匹配所有內容,標準寫法為
.*。
執行命令:grep ".*" test2.txt
(4)^和$練習
正規表示式^匹配行首,$匹配行尾。
文字test2.txt內容如下:
abc adapt 適應 xyz
abc adopt 採用 xyz
xyz adept 內行 abc.
xyz floor 地板 abc
xyz flour 麵粉 abc
^代表匹配行首,比如^a會匹配以小寫a開頭的行。
執行命令:grep "^a" test2.txt
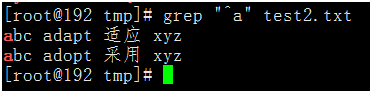
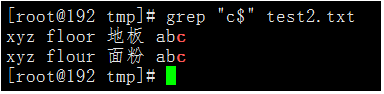
$代表匹配行尾,如果c$會匹配以小寫c結尾的行。
執行命令:grep "c$" test2.txt
^$則會匹配空白行。
執行命令:grep "^$" test2.txt

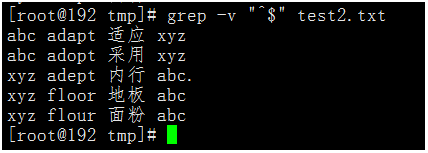
在實際的應用中,我們很少這樣使用,一般使用grep命令的-v選項進行取反,來過濾掉空白行。(標準方式)
執行命令:grep -v "^$" test2.txt
$結合.使用。
如果我們要匹配以句號.結果的行,那是否用.$來進行匹配呢?
我們先來執行一下命令:rep ".$" test2.txt
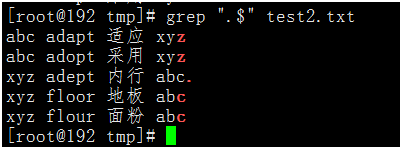
我們看到是匹配了任意字元結尾的行,只是過濾的空白行。
也就是說正規表示式.$中的.是正則符號的意思,表示匹配除了換行符外任意一個字元。
如果我們想匹配以句號.結束的行,我們需要在.前加入跳脫符,把.變成普通字串,如:\.$。
執行命令:grep "\.$" test2.txt

說明:
在使用
^匹配行首,$匹配行尾的時候,如果使用的是特殊符號開頭或者結尾,我們需要使用跳脫符進行跳脫,再進行匹配。
(5)[]練習
正規表示式[]匹配中括號中指定的任意一個字元,只匹配一個字元。(注意只能匹配一個字元。)
比如[abc]要麼會匹配一個a字元,要麼會匹配一個b字元,或者要麼會匹配一個c字元。
文字test.txt內容如下:
abc adapt 適應 abc
ABC adopt 採用 xyz
abc adept 內行 XYZ
123 floor 地板 ABC
123 flour 麵粉 123
- 設定
adapt、adopt、adept這三個近似的單詞。
執行命令:grep "ad[ae]pt" test2.txt
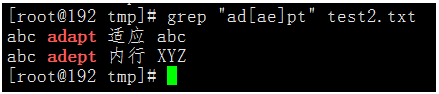
可以看出[]比.的匹配範圍更精準,請根據實際情況,按需使用。 [0-9]會匹配任意一個數位。
執行命令:grep "[0-9]" test2.txt
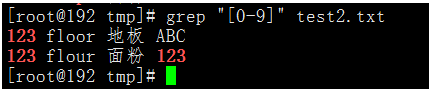
[A-Z]會匹配一個大寫字母。
執行命令:grep "[A-Z]" test2.txt
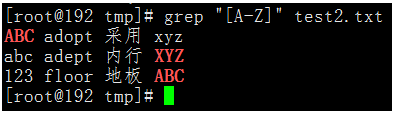
^[a-z]代表匹配用小寫字母開頭的行。
執行命令:grep "^[a-z]" test2.txt
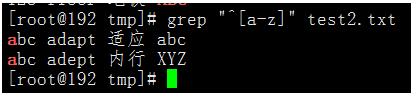
(6)[^]練習
正規表示式[^]匹配除中括號的字元以外的任意一個字元。
就相當於在[]中的內容進行取反。
文字test.txt內容如下:
abc adapt 適應 abc
ABC adopt 採用 xyz
abc adept 內行 XYZ
123 floor 地板 ABC
123 flour 麵粉 123
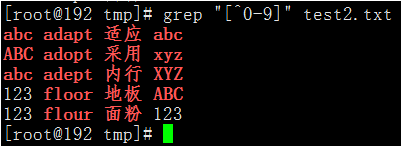
- 不匹配數位。
執行命令:grep "[^0-9]" test2.txt
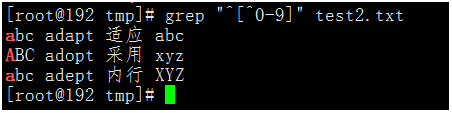
- 不匹配以數位開頭的行。
執行命令:grep "^[^0-9]" test2.txt
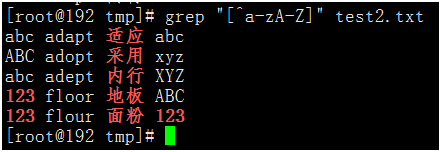
- 不匹配英文。
執行命令:rep "[^a-zA-Z]" test2.txt
- 匹配不以英文結尾的行。
執行命令:rep "[^a-zA-Z]$" test2.txt

(7)\{n\}練習
\{n\}表示其前面的字元恰好出現n次。
提示:\{n\}中的\表示跳脫符,下面同理。
如下面一段文字:
Stay hungry, stay foolish. ——Steve Jobs
求知若飢,虛心若愚。——喬布斯
Stay hungry, stay folish. ——Steve Jobs
Stay hungry, stay fooolish. ——Steve Jobs
Stay hungry, stay foooolish. ——Steve Jobs
Stay hungry, stay fooooolish. ——Steve Jobs
- 匹配包含三個連續的
o。
執行命令:grep "o\{3\}" test2.txt
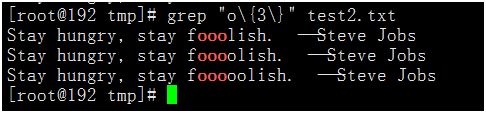
可以看到有三個連續的o,或者包含三個連續o,都會被匹配到。
那與直接正則匹配三個o有什麼區別?
執行命令:grep "ooo" test2.txt
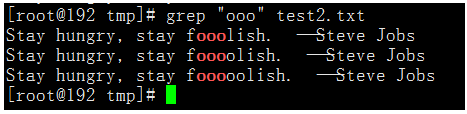
原因:
如果是想匹配一個重複的字母,直接匹配字母的方式更為方便。
而如果我想要匹配重複任意字母或者數位,則\{n\}方式更為便捷。
看下面練習。 - 匹配三個連續的數位。
文字內容如下:
執行命令:abc adapt 適應 abc 12a adopt 採用 12345 abc adept 內行 XYZ 1b3 floor 地板 7788999 123 flour 麵粉 123grep "[0-9]\{3\}" test2.txt
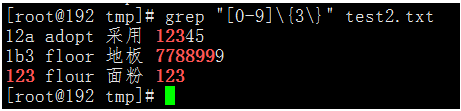
我們可以看到,有三個連續的數位,或者包含有三個連續數位的文字,都被匹配到了。
如果我們要是不用\{n\}的方式進行正則匹配的話,如下:
執行命令:grep "[0-9][0-9][0-9]" test2.txt
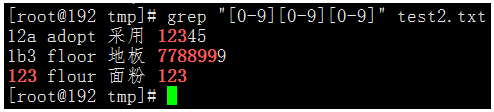
我們可以看到上邊的命令就會麻煩很多,如果要是匹配10個連續的數位,那命令就非常的冗餘了。
字母也是同理的。 - 只匹配三個連續的數位
雖然上面的12345和7788999是包含三個連續的數位,所以也是可以列出的。
可是這樣不能體現出來[0-9]\{3\}只能匹配三個連續的數位,而不是匹配四個連續的數位。
那麼正則中就應該加入限位(制)符(可以是前後有標識的字元或者是行尾行首等進行限位),如下:
執行命令,限制行首:grep "^[0-9]\{3\}" test2.txt

或者限制行尾,注意前邊要多加一個空格限位,才能符合該需求。
執行命令:grep " [0-9]\{3\}$" test2.txt

- 用上面一段文字,練習匹配只包含三個
o的文字。
執行命令:grep "fo\{3\}l" test2.txt

說明:f和l就是限位(制)符。
注意:
\{n\}匹配的方式一般不會用於匹配字母,多用於匹配數位,如電話號碼。還要再重複一遍,正規表示式是包含匹配,多注意限位(制)符的使用。
(8)\{n,\}練習
\{n,\}表示其前面的字元出現不小於n次。
如下面一段文字:
Stay hungry, stay foolish. ——Steve Jobs
求知若飢,虛心若愚。——喬布斯
Stay hungry, stay folish. ——Steve Jobs
Stay hungry, stay fooolish. ——Steve Jobs
Stay hungry, stay foooolish. ——Steve Jobs
Stay hungry, stay fooooolish. ——Steve Jobs
比如fo\{4,\}l這個正則就會匹配用f開頭,l結尾,中間最少有4個o的字串。
執行命令:grep "fo\{4,\}l" test2.txt
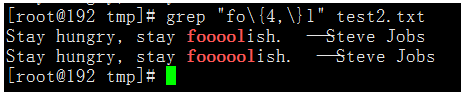
正則表達是fo\{4,\}l與ooooo*的區別同上邊(7)\{n\}同理。
練習:匹配至少連續5個字數的文字。
abc adapt 適應 abc
12a adopt 採用 12345
abc adept 內行 XYZ
1b3 floor 地板 7788999
123 flour 麵粉 123
執行命令:grep "[0-9]\{4,\}" test2.txt

(9)\{n,m\}練習
\{n,m\}匹配其前面的字元至少出現n次,最多出現m次。
下面一段文字:
Stay hungry, stay foolish. ——Steve Jobs
求知若飢,虛心若愚。——喬布斯
Stay hungry, stay folish. ——Steve Jobs
Stay hungry, stay fooolish. ——Steve Jobs
Stay hungry, stay foooolish. ——Steve Jobs
Stay hungry, stay fooooolish. ——Steve Jobs
Stay hungry, stay foooooolish. ——Steve Jobs
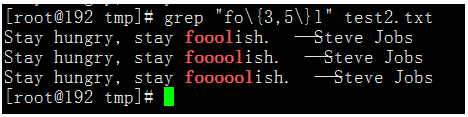
匹配在字母f和字母l之間有最少3個o,最多5個o。
執行命令:grep "fo\{3,5\}l" test2.txt
4、總結
我們學習Shell的正規表示式,實際的應用是什麼?
- 主要是做字串的模糊匹配,比如要求你輸入一個手機號,或者身份證號,再或者是一個郵箱地址等,做模糊匹配,進行錯略的過濾,來過濾掉一些不符合規則的輸入。(更細的驗證在後臺處理,如簡訊或者郵箱等驗證操作)
- 還有再Shell中我們也常常會讀取文字中的資料,這些文字中的資料也是字串,我們通過正規表示式來過濾出一些我們需要的資料資訊。
提示:要注意區分正規表示式和萬用字元中的符號功能的不同。