深度學習與CV教學(6) | 神經網路訓練技巧 (上)

- 作者:韓信子@ShowMeAI
- 教學地址:http://www.showmeai.tech/tutorials/37
- 本文地址:http://www.showmeai.tech/article-detail/265
- 宣告:版權所有,轉載請聯絡平臺與作者並註明出處
- 收藏ShowMeAI檢視更多精彩內容

本系列為 斯坦福CS231n 《深度學習與計算機視覺(Deep Learning for Computer Vision)》的全套學習筆記,對應的課程視訊可以在 這裡 檢視。更多資料獲取方式見文末。
引言
通過ShowMeAI前序文章 深度學習與CV教學(3) | 損失函數與最佳化 ,深度學習與CV教學(4) | 神經網路與反向傳播,深度學習與CV教學(5) | 折積神經網路 我們已經學習掌握了以下內容:
- 計算圖:計算前向傳播、反向傳播
- 神經網路:神經網路的層結構、非線性函數、損失函數
- 優化策略:梯度下降使損失最小
- 批梯度下降:小批次梯度下降,每次迭代只用訓練資料中的一個小批次計算損失和梯度
- 折積神經網路:多個濾波器與原影象獨立折積得到多個獨立的啟用圖
【本篇】和【下篇】 ShowMeAI講解訓練神經網路的核心方法與關鍵點,主要包括:
- 初始化:啟用函數選擇、資料預處理、權重初始化、正則化、梯度檢查
- 訓練動態:監控學習過程、引數更新、超引數優化
- 模型評估:模型整合(model ensembles)
本篇重點
- 啟用函數
- 資料預處理
- 權重初始化
- 批次歸一化
- 監控學習過程
- 超引數調優
1.啟用函數
關於啟用函數的詳細知識也可以參考閱讀ShowMeAI的 深度學習教學 | 吳恩達專項課程 · 全套筆記解讀 中的文章 淺層神經網路 裡【啟用函數】板塊內容。
在全連線層或者折積層,輸入資料與權重相乘後累加的結果送給一個非線性函數,即啟用函數(activation function)。每個啟用函數的輸入都是一個數位,然後對其進行某種固定的數學操作。
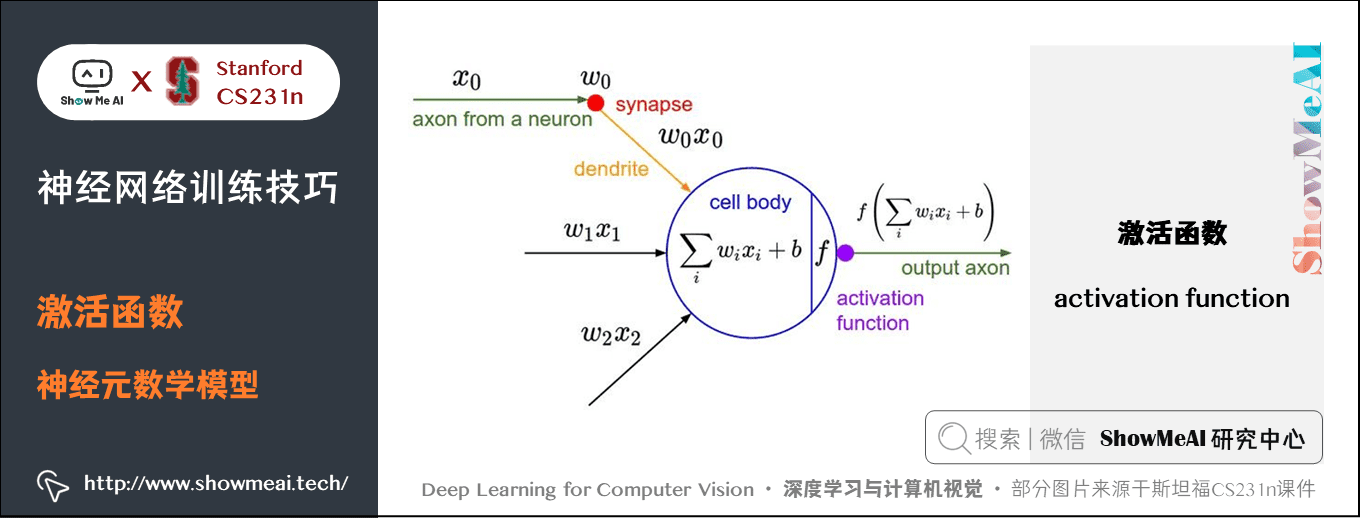
下面是在實踐中可能遇到的幾種啟用函數:
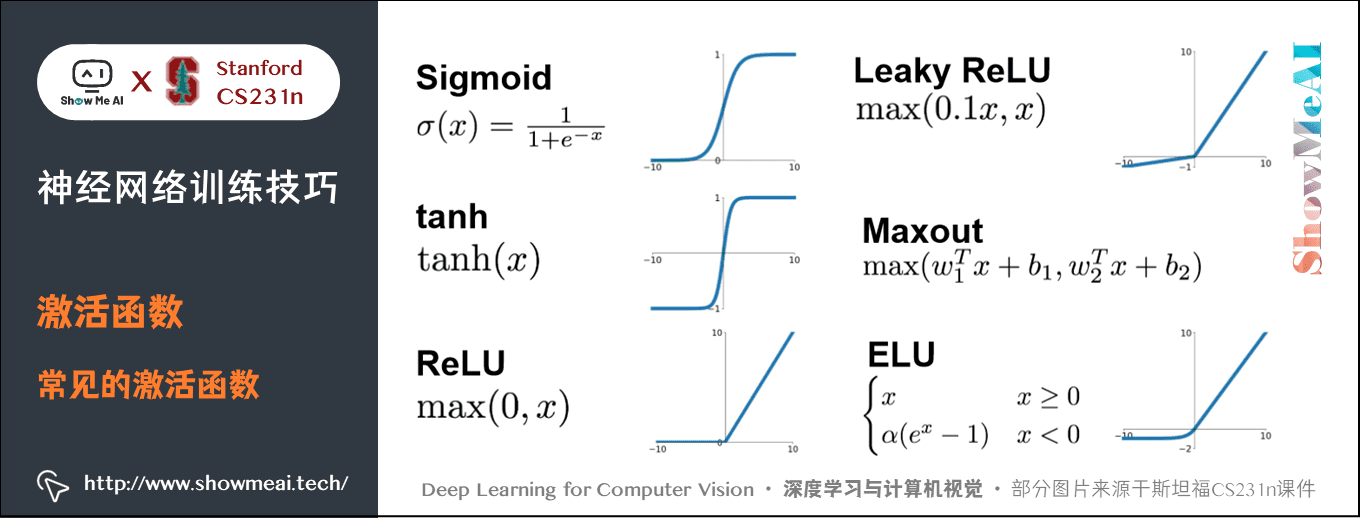
1.1 Sigmoid函數
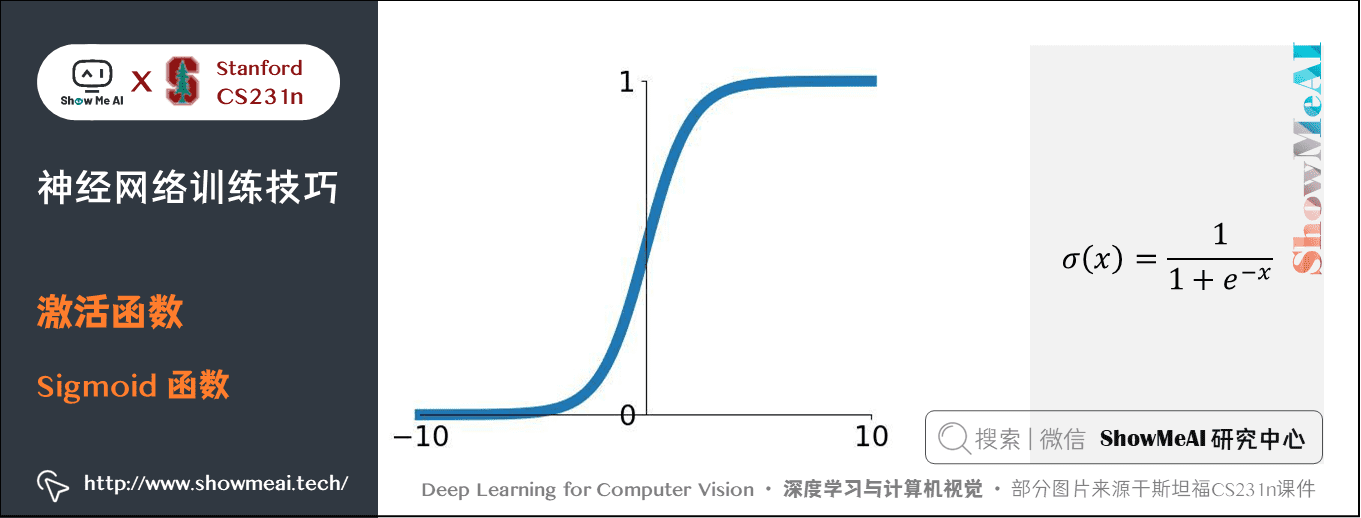
數學公式:\(\sigma(x) = 1 / (1 + e^{-x})\)
求導公式:\(\frac{d\sigma(x)}{dx} = \left( 1 - \sigma(x) \right) \sigma(x)\) (不小於 \(0\) )
特點:把輸入值「擠壓」到 \(0\) 到 \(1\) 範圍內。Sigmoid 函數把輸入的實數值「擠壓」到 \(0\) 到 \(1\) 範圍內,很大的負數變成 \(0\),很大的正數變成 \(1\),在歷史神經網路中,Sigmoid 函數很常用,因為它對神經元的啟用頻率有良好的解釋:從完全不啟用(\(0\))到假定最大頻率處的完全飽和(saturated)的啟用(\(1\)) 。
然而現在 Sigmoid 函數已經很少使用了,因為它有三個主要缺點:
缺點①:Sigmoid 函數飽和時使梯度消失
- 當神經元的啟用在接近 \(0\) 或 \(1\) 處時(即門單元的輸入過或過大時)會飽和:在這些區域,梯度幾乎為 \(0\)。
- 在反向傳播的時候,這個區域性梯度要與損失函數關於這個門單元輸出的梯度相乘。因此,如果區域性梯度非常小,那麼相乘的結果也會接近零,這會「殺死」梯度,幾乎就有沒有訊號通過神經元傳到權重再到資料了。
- 還有,為了防止飽和,必須對於權重矩陣初始化特別留意。比如,如果初始權重過大,那麼大多數神經元將會飽和,導致網路就幾乎不學習了。
缺點②:Sigmoid 函數的輸出不是零中心的
- 這個性質會導致神經網路後面層中的神經元得到的資料不是零中心的。
- 這一情況將影響梯度下降的運作,因為如果輸入神經元的資料總是正數(比如在 \(\sigma(\sum_{i}w_ix_i+b)\) )中每個輸入 \(x\) 都有 \(x > 0\)),那麼關於 \(w\) 的梯度在反向傳播的過程中,將會要麼全部是正數,要麼全部是負數(根據該 Sigmoid 門單元的回傳梯度來定,回傳梯度可正可負,而 \(\frac{d\sigma}{dW}=X^T \cdot\sigma'\) 在 \(X\) 為正時恆為非負數)。
- 這將會導致梯度下降權重更新時出現 \(z\) 字型的下降。該問題相對於上面的神經元飽和問題來說只是個小麻煩,沒有那麼嚴重。
缺點③: 指數型計算量比較大。
1.2 tanh函數
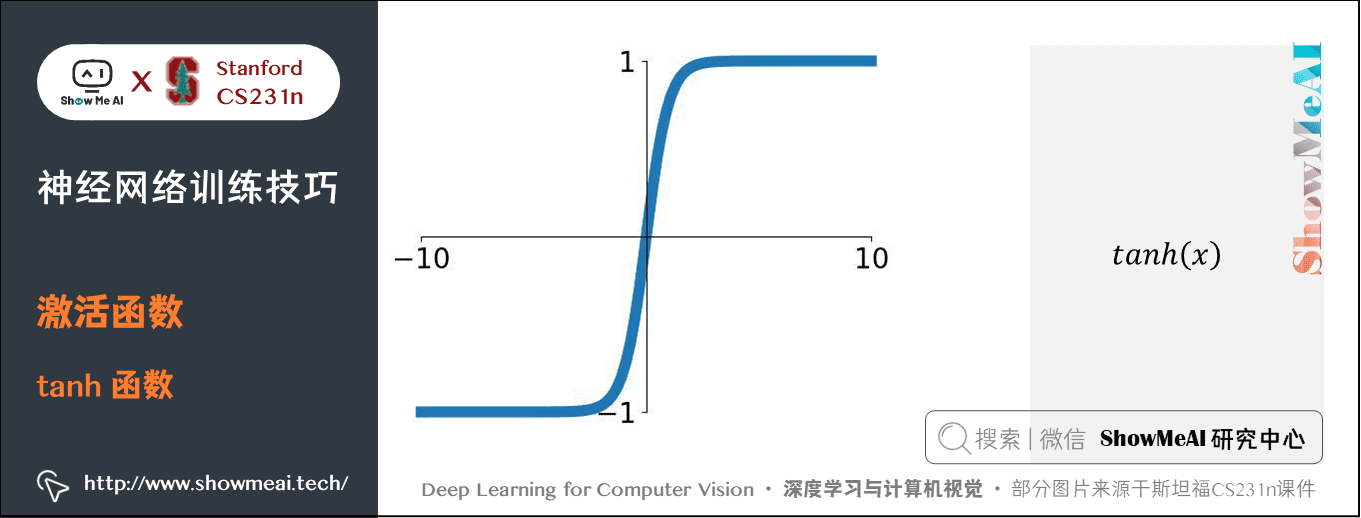
數學公式:\(\tanh(x) = 2 \sigma(2x) -1\)
特點:將實數值壓縮到 \([-1,1]\) 之間
和 \(Sigmoid\) 神經元一樣,它也存在飽和問題,但是和 \(Sigmoid\) 神經元不同的是,它的輸出是零中心的。因此,在實際操作中,\(tanh\) 非線性函數比 \(Sigmoid\) 非線性函數更受歡迎。注意 \(tanh\) 神經元是一個簡單放大的 \(Sigmoid\) 神經元。
1.3 ReLU 函數
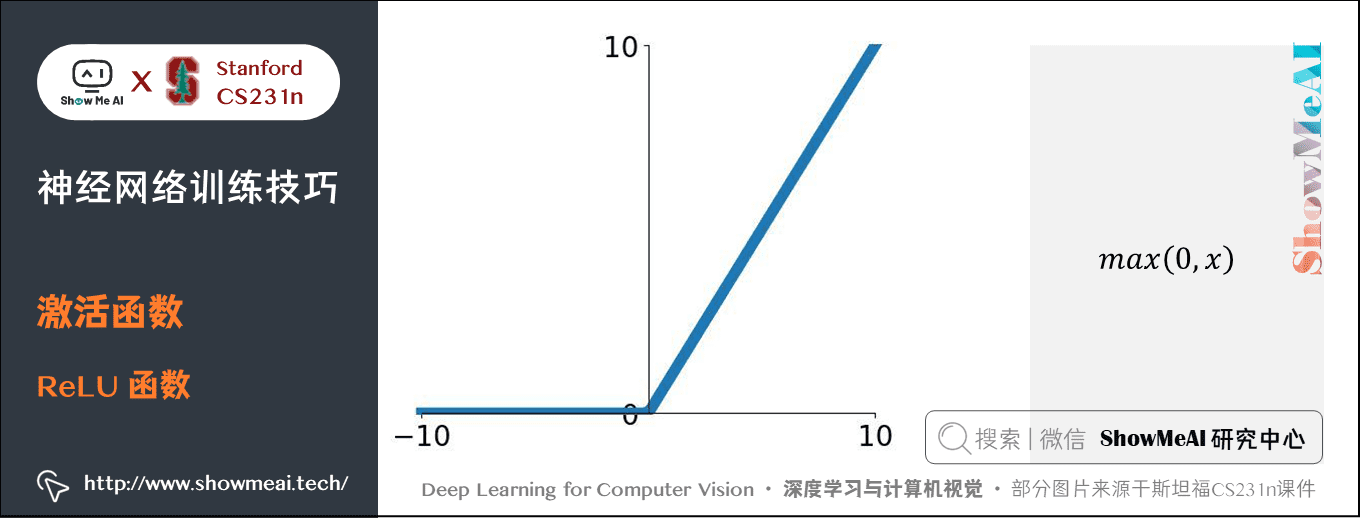
數學公式:\(f(x) = \max(0, x)\)
特點:一個關於 \(0\) 的閾值
優點:
- ReLU 只有負半軸會飽和;節省計算資源,不含指數運算,只對一個矩陣進行閾值計算;更符合生物學觀念;加速隨機梯度下降的收斂。
- Krizhevsky 論文指出比 Sigmoid 和 tanh 函數快6倍之多,據稱這是由它的線性,非飽和的公式導致的。
缺點:
- 仍有一半會飽和;非零中心;
- 訓練時,ReLU 單元比較脆弱並且可能「死掉」。
- 舉例來說,當一個很大的梯度流過 ReLU 的神經元的時候,由於梯度下降,可能會導致權重更新到一種特別的狀態(比如大多數的 \(w\) 都小於 \(0\) ),在這種狀態下神經元將無法被其他任何資料點再次啟用。如果這種情況發生,那麼從此所有流過這個神經元的梯度將都變成 \(0\),也就是說,這個 ReLU 單元在訓練中將不可逆轉的死亡,因為這導致了資料多樣化的丟失。
- 例如,如果學習率設定得太高(本來大多數大於 \(0\) 的 \(w\) 更新後都小於 \(0\) 了),可能會發現網路中40%的神經元都會死掉(在整個訓練集中這些神經元都不會被啟用)。
- 通過合理設定學習率,這種情況的發生概率會降低。
1.4 Leaky ReLU
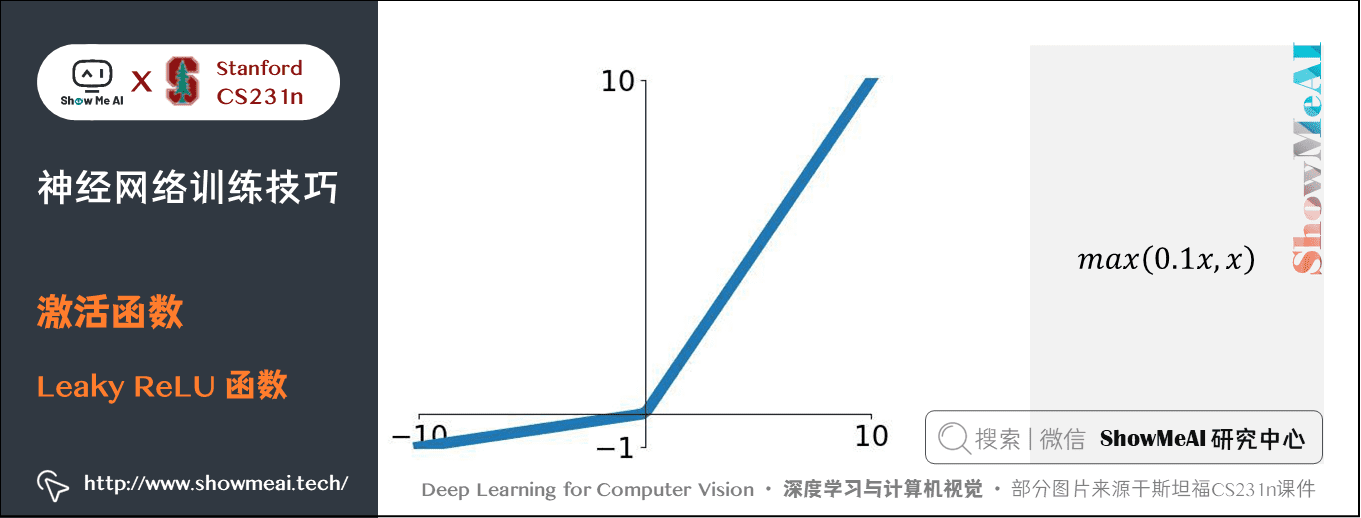
公式:\(f(x) = \mathbb{1}(x < 0) (\alpha x) + \mathbb{1}(x>=0) (x)\),\(\alpha\) 是小常數
特點:解決「 ReLU 死亡」問題,\(x<0\) 時給出一個很小的梯度值,比如 \(0.01\)。
Leaky ReLU 修正了 \(x<0\) 時 ReLU 的問題,有研究指出這個啟用函數表現很不錯,但是其效果並不是很穩定。Kaiming He等人在2015年釋出的論文 Delving Deep into Rectifiers 中介紹了一種新方法 PReLU,把負區間上的斜率當做每個神經元中的一個引數,然而無法確定該啟用函數在不同任務中均有益處。
1.5 指數線性單元(Exponential Linear Units,ELU)
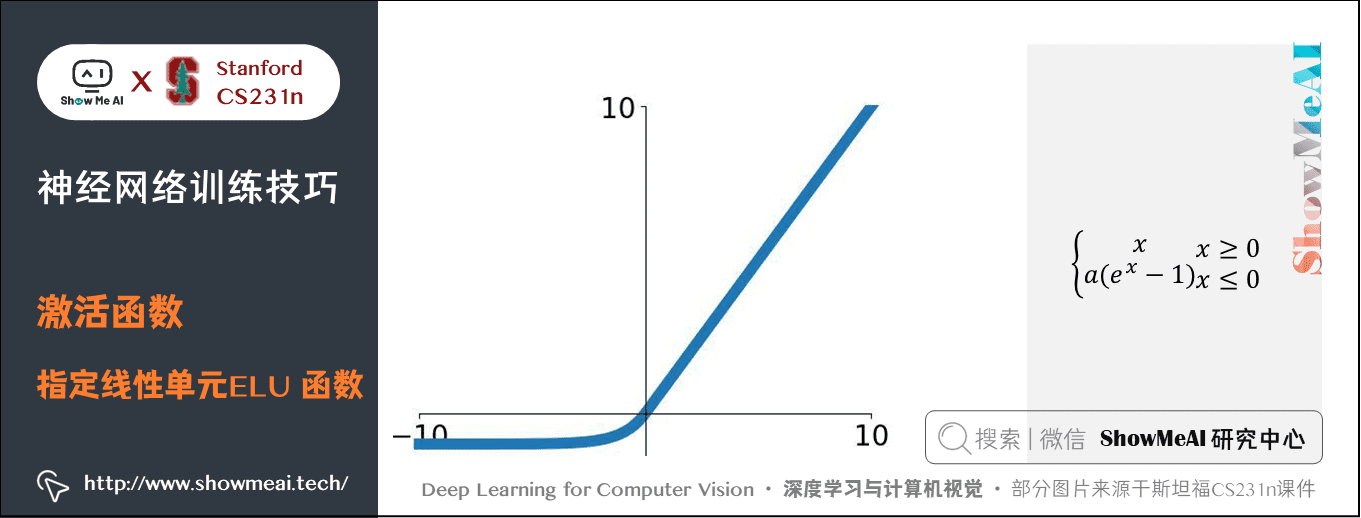
公式:\(f(x)=\begin{cases} x & if \space\space x>0 \\ \alpha(exp(x)-1) & otherwise \end{cases}\)
特點:介於 ReLU 和Leaky ReLU 之間
具有 ReLU 的所有優點,但是不包括計算量;介於 ReLU 和 Leaky ReLU 之間,有負飽和的問題,但是對噪聲有較強的魯棒性。
1.6 Maxout
公式:\(max(w_1^Tx+b_1, w_2^Tx + b_2)\)
特點:是對 ReLU 和 leaky ReLU 的一般化歸納
對於權重和資料的內積結果不再使用非線性函數,直接比較兩個線性函數。ReLU 和 Leaky ReLU 都是這個公式的特殊情況,比如 ReLU 就是當 \(w_1=1\),\(b_1=0\) 的時候。
Maxout 擁有 ReLU 單元的所有優點(線性操作和不飽和),而沒有它的缺點(死亡的 ReLU 單元)。然而和 ReLU 對比,它每個神經元的引數數量增加了一倍,這就導致整體引數量激增。
實際應用Tips :
- 用 ReLU 函數。注意設定好學習率,你可以監控你的網路中死亡的神經元佔的比例。
- 如果單元死亡問題困擾你,就試試Leaky ReLU 或者 Maxout,不要再用 Sigmoid 了。也可以試試 tanh,但是其效果應該不如 ReLU 或者 Maxout。
2.資料預處理
關於深度學習資料預處理的知識也可以對比閱讀ShowMeAI的深度學習教學 | 吳恩達專項課程 · 全套筆記解讀中的文章深度學習的實用層面裡【標準化輸入】板塊內容。
關於資料預處理有 3 個常用的符號,資料矩陣 \(X\),假設其尺寸是 \([N \times D]\)(\(N\) 是資料樣本的數量,\(D\) 是資料的維度)。
2.1 減均值(Mean Subtraction)
減均值法是資料預處理最常用的形式。它對資料中每個獨立特徵減去平均值,在每個維度上都將資料的中心都遷移到原點。
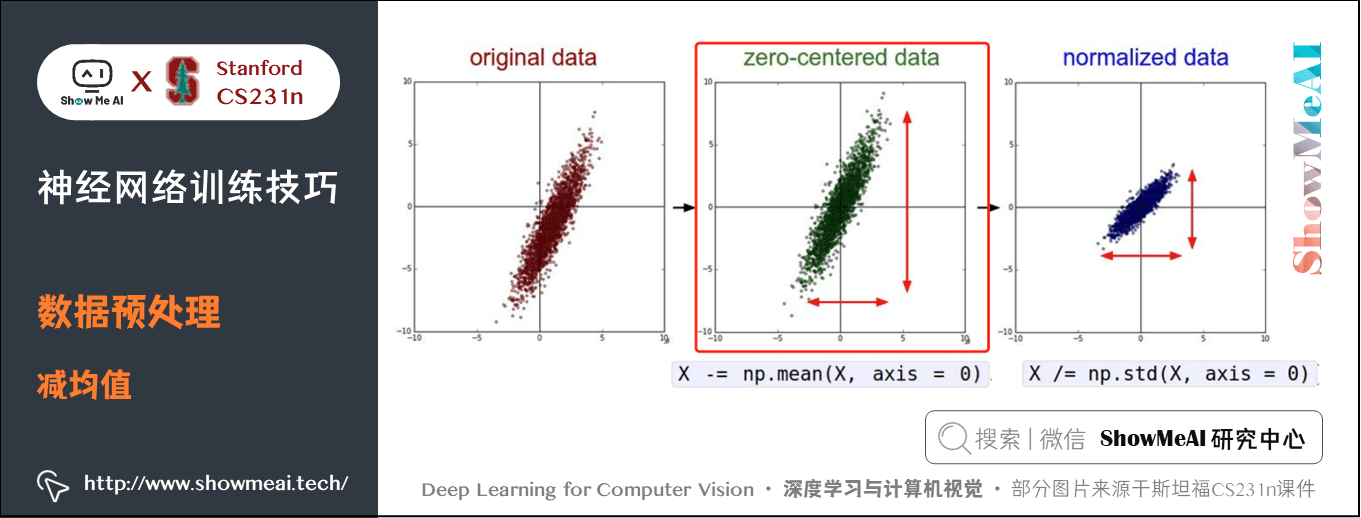
在 numpy 中,該操作可以通過程式碼 X -= np.mean(X, axis=0) 實現。而對於影象,更常用的是對所有畫素都減去一個值,可以用 X -= np.mean(X) 實現,也可以在 3 個顏色通道上分別操作。
具體來講,假如訓練資料是 \(50000\) 張 \(32 \times 32 \times 3\) 的圖片:
- 第一種做法是減去均值影象,即將每張圖片拉成長為 \(3072\) 的向量,\(50000 \times 3072\) 的矩陣按列求平均,得到一個含有 \(3072\) 個數的均值影象,訓練集測試集驗證集都要減去這個均值,AlexNet 是這種方式;
- 第二種做法是按照通道求平均,RGB三個通道每個通道一個均值,即每張圖片的 \(3072\) 個數中,RGB各有 \(32 \times 32\) 個數,要在 \(50000 \times 32 \times 32\) 個數中求一個通道的均值,最終的均值有 \(3\) 個數位,然後所有圖片每個通道都要減去對應的通道均值,VGGNet是這種方式。
之所以執行減均值操作,是因為解決輸入資料大多數都是正或者負的問題。雖然經過這種操作,資料變成零中心的,但是仍然只能第一層解決 Sigmoid 非零均值的問題,後面會有更嚴重的問題。
2.2 歸一化(Normalization)
歸一化是指將資料的所有維度都歸一化,使其數值範圍都近似相等。
有兩種常用方法可以實現歸一化。
- 第一種是先對資料做零中心化(zero-centered)處理,然後每個維度都除以其標準差,實現程式碼為
X /= np.std(X, axis=0)。 - 第二種是對每個維度都做歸一化,使得每個維度的最大和最小值是 \(1\) 和 \(-1\)。這個預處理操作只有在確信不同的輸入特徵有不同的數值範圍(或計量單位)時才有意義,但要注意預處理操作的重要性幾乎等同於學習演演算法本身。
在影象處理中,由於畫素的數值範圍幾乎是一致的(都在0-255之間),所以進行這個額外的預處理步驟並不是很必要。
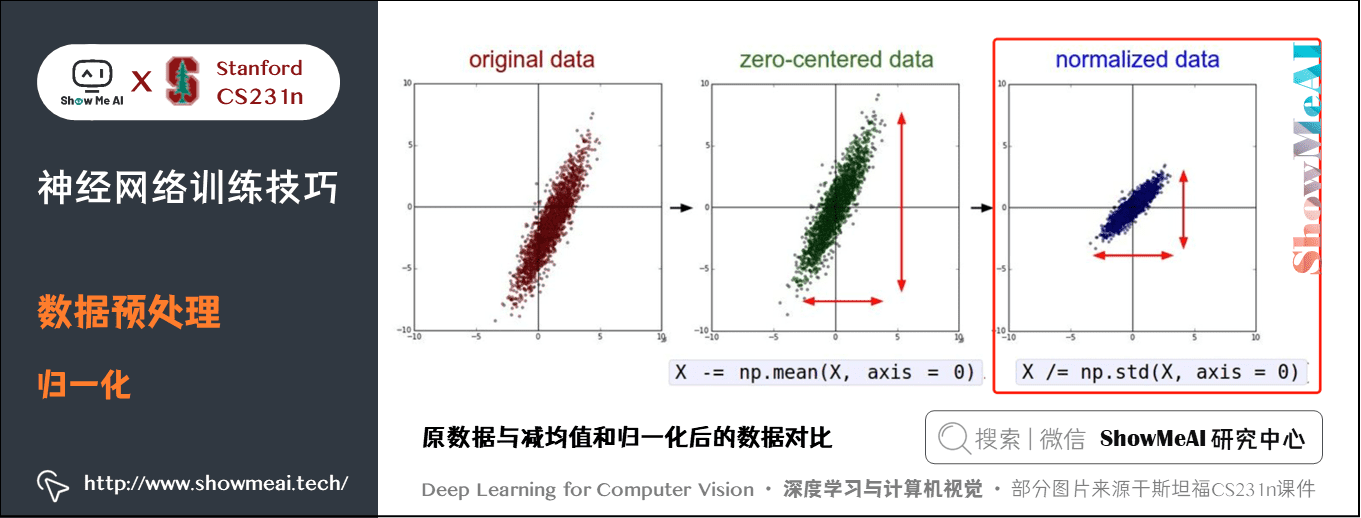
- 左邊:原始的 2 維輸入資料。
- 中間:在每個維度上都減去平均值後得到零中心化資料,現在資料雲是以原點為中心的。
- 右邊:每個維度都除以其標準差來調整其數值範圍,紅色的線指出了資料各維度的數值範圍。
在中間的零中心化資料的數值範圍不同,但在右邊歸一化資料中數值範圍相同。
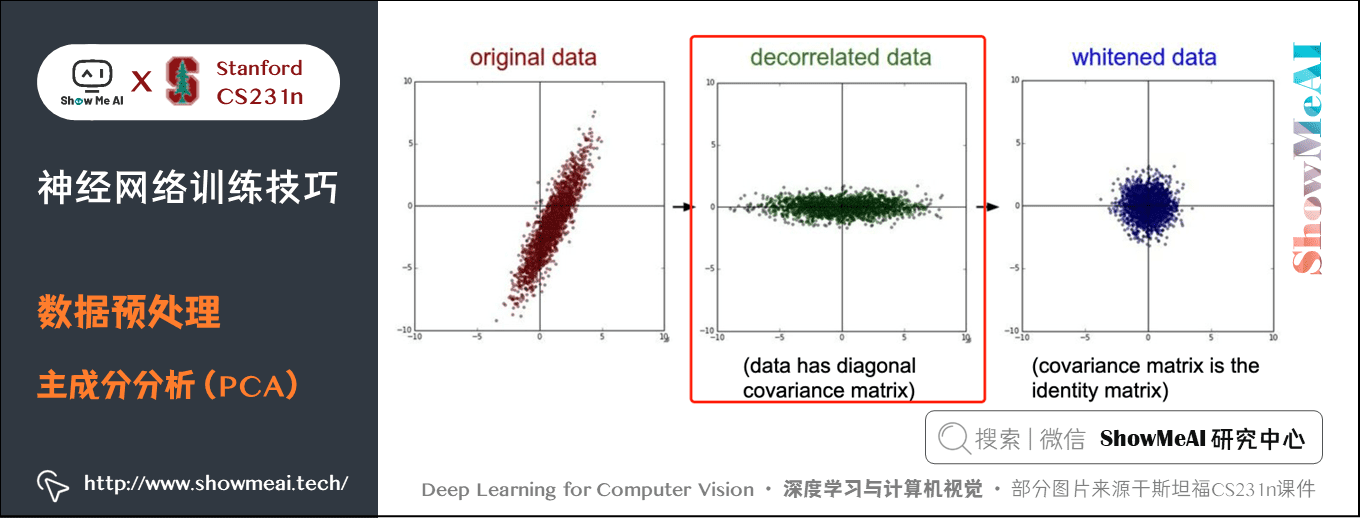
2.3 主成分分析(PCA)
這是另一種機器學習中比較常用的預處理形式,但在影象處理中基本不用。在這種處理中,先對資料進行零中心化處理,然後計算協方差矩陣,它展示了資料中的相關性結構。
# 假設輸入資料矩陣X的尺寸為[N x D]
X -= np.mean(X, axis = 0) # 對資料進行零中心化(重要)
cov = np.dot(X.T, X) / X.shape[0] # 得到資料的協方差矩陣,DxD
資料協方差矩陣的第 \((i, j)\) 個元素是資料第 \(i\) 個和第 \(j\) 個維度的協方差。具體來說,該矩陣的對角線上的元素是方差。還有,協方差矩陣是對稱和半正定的。我們可以對資料協方差矩陣進行 SVD(奇異值分解)運算。
U,S,V = np.linalg.svd(cov)
\(U\) 的列是特徵向量,\(S\) 是裝有奇異值的1維陣列(因為 cov 是對稱且半正定的,所以S中元素是特徵值的平方)。為了去除資料相關性,將已經零中心化處理過的原始資料投影到特徵基準上:
Xrot = np.dot(X,U) # 對資料去相關性
np.linalg.svd 的一個良好性質是在它的返回值U中,特徵向量是按照特徵值的大小排列的。我們可以利用這個性質來對資料降維,只要使用前面的小部分特徵向量,丟棄掉那些包含的資料沒有方差的維度,這個操作也被稱為 主成分分析(Principal Component Analysis 簡稱PCA) 降維:
Xrot_reduced = np.dot(X, U[:,:100]) # Xrot_reduced 變成 [N x 100]
經過上面的操作,將原始的資料集的大小由 \([N \times D]\) 降到了 \([N \times 100]\),留下了資料中包含最大方差的的 100 個維度。通常使用 PCA 降維過的資料訓練線性分類器和神經網路會達到非常好的效能效果,同時還能節省時間和記憶體空間。
有一問題是為什麼使用協方差矩陣進行 SVD 分解而不是使用原 \(X\) 矩陣進行?
其實都是可以的,只對資料 \(X\)(可以不是方陣)進行 SVD 分解,做 PCA 降維(避免了求協方差矩陣)的話一般用到的是右奇異向量 \(V\),即 \(V\) 的前幾列是需要的特徵向量(注意
np.linalg.svd返回的是V.T)。\(X\) 是\(N \times D\),則 \(U\) 是 \(N \times N\),\(V\) 是 \(D \times D\);而對協方差矩陣(\(D \times D\))做 SVD 分解用於 PCA 降維的話,可以隨意取左右奇異向量\(U\)、\(V\)(都是 \(D \times D\))之一,因為兩個向量是一樣的。
2.4 白化(Whitening)
最後一個在實踐中會看見的變換是白化(whitening)。白化操作的輸入是特徵基準上的資料,然後對每個維度除以其特徵值來對數值範圍進行歸一化。
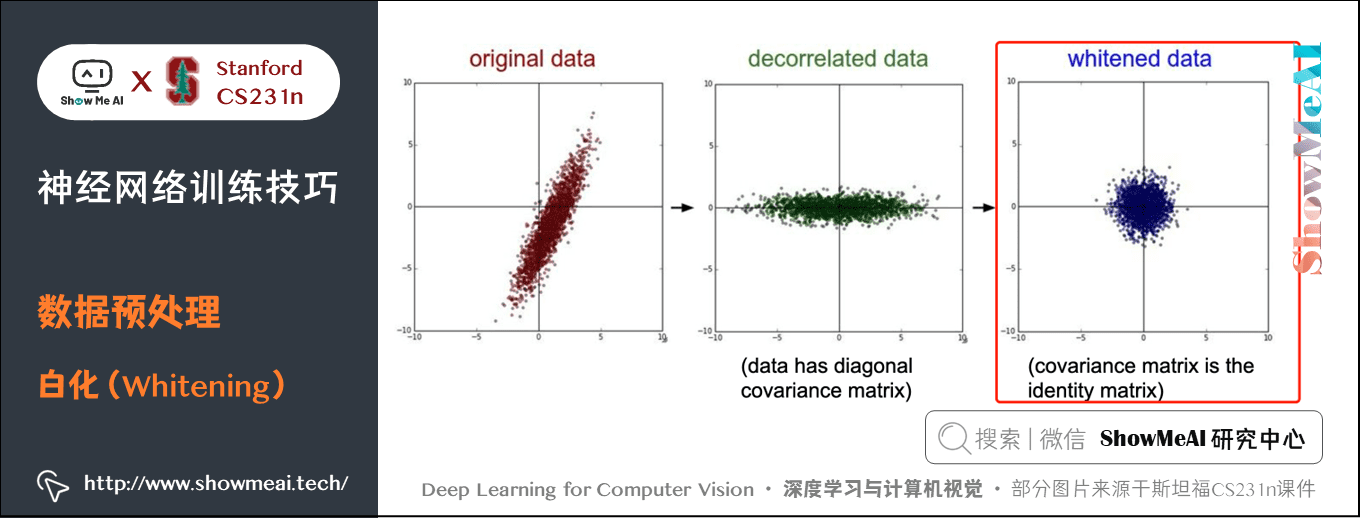
白化變換的幾何解釋是:如果資料服從多變數的高斯分佈,那麼經過白化後,資料的分佈將會是一個均值為零,且協方差相等的矩陣。
該操作的程式碼如下:
# 對資料進行白化操作:
# 除以特徵值
Xwhite = Xrot / np.sqrt(S + 1e-5)
注意分母中新增了 1e-5(或一個更小的常數)來防止分母為 \(0\),該變換的一個缺陷是在變換的過程中可能會誇巨量資料中的噪聲,這是因為它將所有維度都拉伸到相同的數值範圍,這些維度中也包含了那些只有極少差異性(方差小)而大多是噪聲的維度。
在實際操作中,這個問題可以用更強的平滑來解決(例如:採用比 1e-5 更大的值)。
下圖為 CIFAR-10 資料集上的 PCA、白化等操作結果視覺化。

從左往右4張子圖:
- 第1張:一個用於演示的圖片集合,含 49 張圖片。
- 第2張:3072 個特徵向量中的前 144 個。靠前面的特徵向量解釋了資料中大部分的方差。
- 第3張:49 張經過了PCA降維處理的圖片,只使用這裡展示的這 144 個特徵向量。為了讓圖片能夠正常顯示,需要將 144 維度重新變成基於畫素基準的 3072 個數值。因為U是一個旋轉,可以通過乘以
U.transpose()[:144,:]來實現,然後將得到的 3072 個數值視覺化。可以看見影象變得有點模糊了,然而,大多數資訊還是保留了下來。 - 第4張:將「白化」後的資料進行顯示。其中 144個 維度中的方差都被壓縮到了相同的數值範圍。然後 144 個白化後的數值通過乘以
U.transpose()[:144,:]轉換到影象畫素基準上。
2.5 實際應用
實際上在折積神經網路中並不會採用PCA和白化,對資料進行零中心化操作還是非常重要的,對每個畫素進行歸一化也很常見。
補充說明:
進行預處理很重要的一點是:任何預處理策略(比如資料均值)都只能在訓練集資料上進行計算,然後再應用到驗證集或者測試集上。
- 一個常見的錯誤做法是先計算整個資料集影象的平均值然後每張圖片都減去平均值,最後將整個資料集分成訓練/驗證/測試集。正確的做法是先分成訓練/驗證/測試集,只是從訓練集中求圖片平均值,然後各個集(訓練/驗證/測試集)中的影象再減去這個平均值。
3.權重初始化
關於神經網路權重初始化的知識也可以對比閱讀ShowMeAI的深度學習教學 | 吳恩達專項課程 · 全套筆記解讀中的文章深度學習的實用層面裡【權重初始化緩解梯度消失和爆炸】板塊內容。
初始化網路引數是訓練神經網路里非常重要的一步,有不同的初始化方式,我們來看看他們各自的特點。
3.1 全零初始化
對一個兩層的全連線網路,如果輸入給網路的所有引數初始化為 \(0\) 會怎樣?
這種做法是錯誤的。 因為如果網路中的每個神經元都計算出同樣的輸出,然後它們就會在反向傳播中計算出同樣的梯度,從而進行同樣的引數更新。換句話說,如果權重被初始化為同樣的值,神經元之間就失去了不對稱性的源頭。
3.2 小亂數初始化
現在權重初始值要非常接近 \(0\) 又不能等於 \(0\),解決方法就是將權重初始化為很小的數值,以此來打破對稱性。
其思路是:如果神經元剛開始的時候是隨機且不相等的,那麼它們將計算出不同的更新,並將自身變成整個網路的不同部分。
實現方法是:W = 0.01 * np.random.randn(D,H)。其中 randn 函數是基於零均值和標準差的一個高斯分佈來生成亂數的。
小亂數初始化在簡單的網路中效果比較好,但是網路結構比較深的情況不一定會得到好的結果。比如一個 10 層的全連線網路,每層 500 個神經元,使用 \(tanh\) 啟用函數,用小亂數初始化。
程式碼與輸出影象如下:
import numpy as np
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
# 假設一些高斯分佈單元
D = np.random.randn(1000, 500)
hidden_layer_sizes = [500]*10 # 隱藏層尺寸都是500,10層
nonlinearities = ['tanh']*len(hidden_layer_sizes) # 非線性函數都是用tanh函數
act = {'relu': lambda x: np.maximum(0, x), 'tanh': lambda x: np.tanh(x)}
Hs = {}
for i in range(len(hidden_layer_sizes)):
X = D if i == 0 else Hs[i-1] # 當前隱藏層的輸入
fan_in = X.shape[1]
fan_out = hidden_layer_sizes[i]
W = np.random.randn(fan_in, fan_out) * 0.01 # 權重初始化
H = np.dot(X, W) # 得到當前層輸出
H = act[nonlinearities[i]](H) # 啟用函數
Hs[i] = H # 儲存當前層的結果並作為下層的輸入
# 觀察每一層的分佈
print('輸入層的均值:%f 方差:%f'% (np.mean(D), np.std(D)))
layer_means = [np.mean(H) for i,H in Hs.items()]
layer_stds = [np.std(H) for i,H in Hs.items()]
for i,H in Hs.items():
print('隱藏層%d的均值:%f 方差:%f' % (i+1, layer_means[i], layer_stds[i]))
# 畫圖
plt.figure()
plt.subplot(121)
plt.plot(list(Hs.keys()), layer_means, 'ob-')
plt.title('layer mean')
plt.subplot(122)
plt.plot(Hs.keys(), layer_stds, 'or-')
plt.title('layer std')
# 繪製分佈圖
plt.figure()
for i,H in Hs.items():
plt.subplot(1, len(Hs), i+1)
plt.hist(H.ravel(), 30, range=(-1,1))
plt.show()
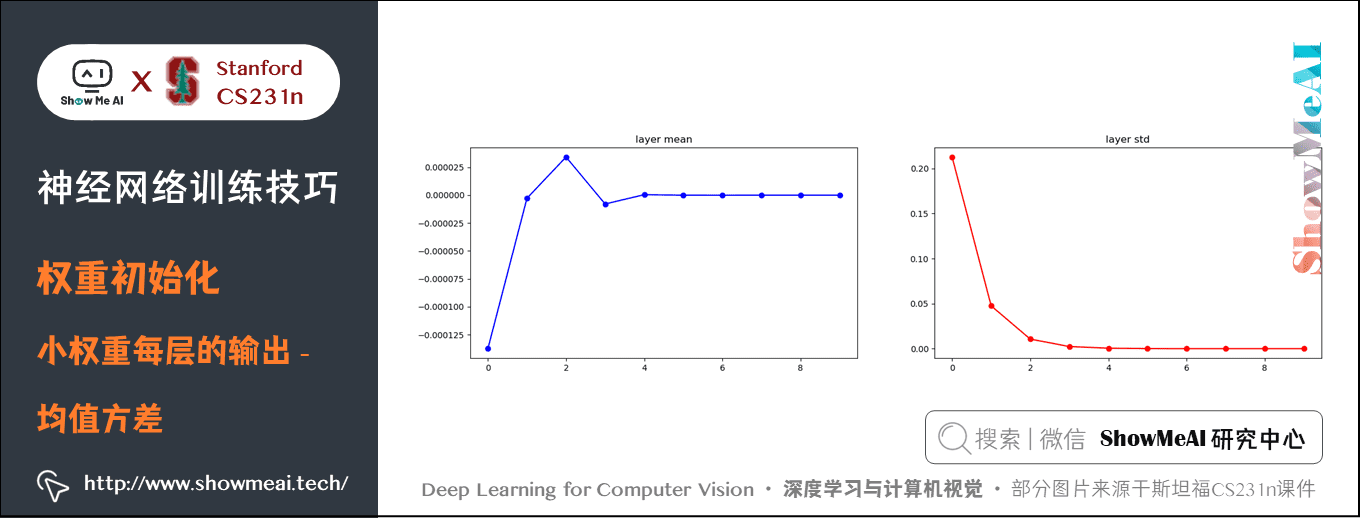
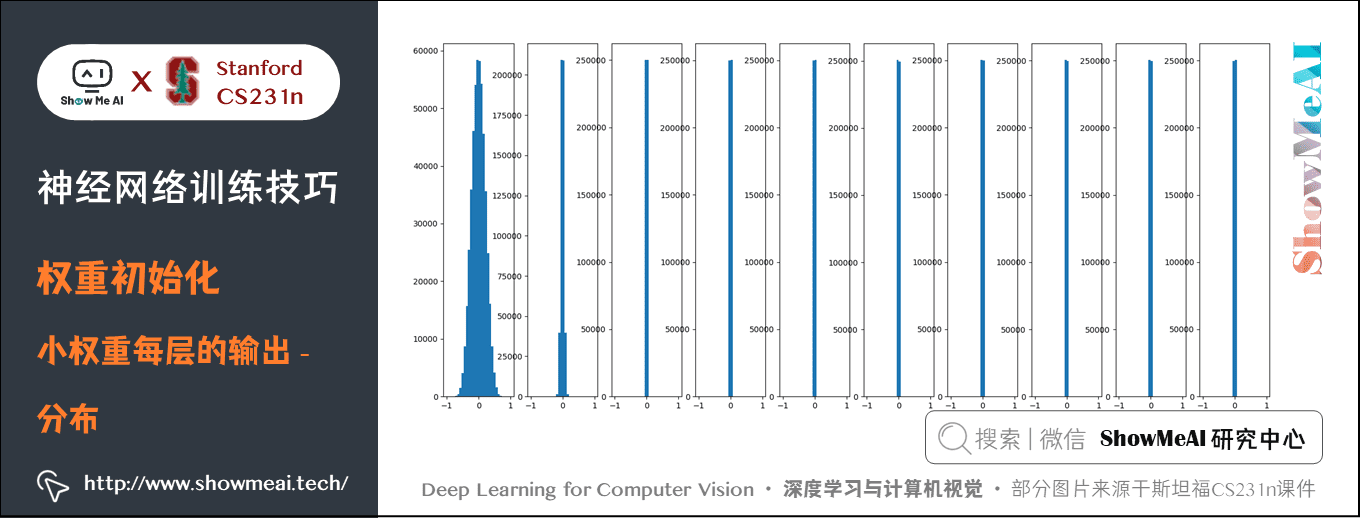
可以看到只有第一層的輸出均值方差比較好,輸出接近高斯分佈,後面幾層均值方差基本為 \(0\),這樣導致的後果是正向傳播的啟用值基本為 \(0\),反向傳播時就會計算出非常小的梯度(因權重的梯度就是層的輸入,輸入接近 \(0\),梯度接近 \(0\) ),引數基本不會更新。
如果上面的例子不用小亂數,即 W = np.random.randn(fan_in, fan_out) * 1,此時會怎樣呢?
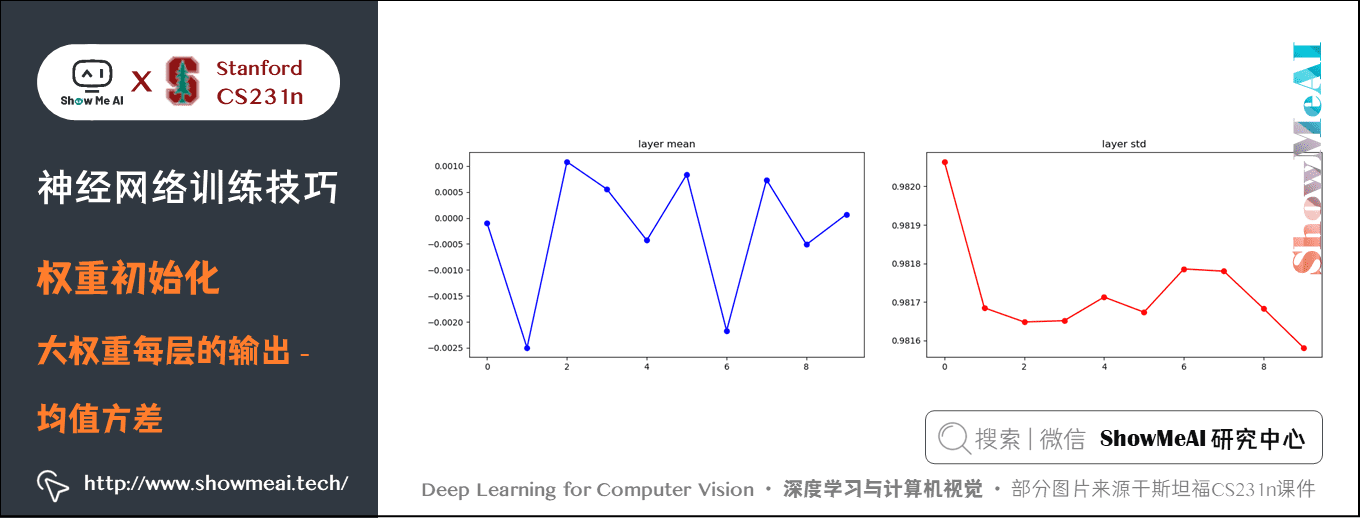
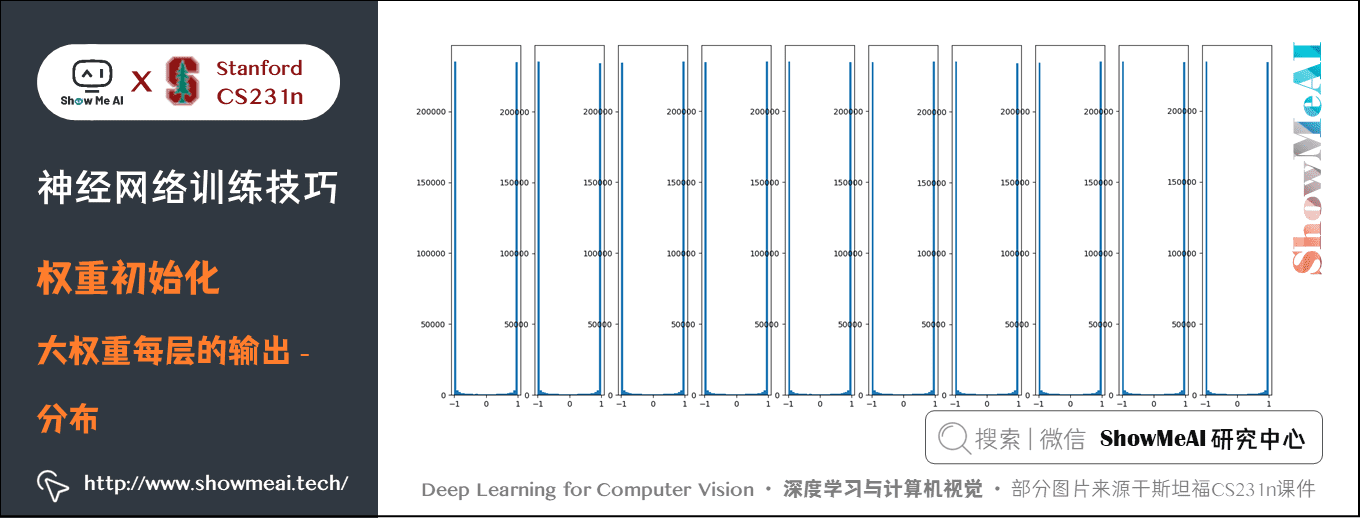
此時,由於權重較大並且使用的 tanh 函數,所有神經元都會飽和,輸出為 \(+1\) 或 \(-1\),梯度為 \(0\),如下圖所示,均值在 \(0\) 附近波動,方差較大在 \(0.98\) 附近波動,神經元輸出大多為 \(+1\) 或 \(-1\)。
3.3 Xavier/He初始化(校準方差)
上述分析可以看出,權重過小可能會導致網路崩潰,權重過大可能會導致網路飽和,所以都在研究出一種合理的初始化方式。一種很好的經驗是使用Xavier初始化:
W = np.random.randn(fan_in, fan_out) / np.sqrt(fan_in)
這是Glorot等在2010年發表的 論文。這樣就保證了網路中所有神經元起始時有近似同樣的輸出分佈。實踐經驗證明,這樣做可以提高收斂的速度。
原理:假設神經元的權重 \(w\) 與輸入 \(x\) 的內積為 \(s = \sum_i^n w_i x_i\),這是還沒有進行非線性啟用函數運算之前的原始數值。此時 \(s\) 的方差:
前三步使用的是方差的性質(累加性、獨立變數相乘);
第三步中,假設輸入和權重的均值都是 \(0\),即 \(E[x_i] = E[w_i] = 0\),但是 ReLU 函數中均值應該是正數。在最後一步,我們假設所有的 \(w_i,x_i\) 都服從同樣的分佈。從這個推導過程我們可以看見,如果想要 \(s\) 有和輸入 \(x\) 一樣的方差,那麼在初始化的時候必須保證每個權重 \(w\) 的方差是\(1/n\) 。
又因為對於一個隨機變數 \(X\) 和標量 \(a\),有 \(\text{Var}(aX) = a^2\text{Var}(X)\),這就說明可以讓 \(w\) 基於標準高斯分佈(方差為1)取樣,然後乘以 \(a = \sqrt{1/n}\),即 \(\text{Var}( \sqrt{1/n}\cdot w) = 1/n\text{Var}(w)=1/n\),此時就能保證 \(\text{Var}(s) =\text{Var}(x)\)。
程式碼為:W = np.random.randn(fan_in, fan_out) / np.sqrt(fan_in),其中fan_in就是上文的 \(n\)。
不過作者在論文中推薦的是:
W = np.random.randn(fan_in, fan_out) / np.sqrt(fan_in + fan_out),使 \(\text{Var}(w) = 2/(n_{in} + n_{out})\),其中 \(n_{in}, n_{out}\) 是前一層和後一層中單元的個數,這是基於妥協和對反向傳播中梯度的分析得出的結論)
輸出結果為:
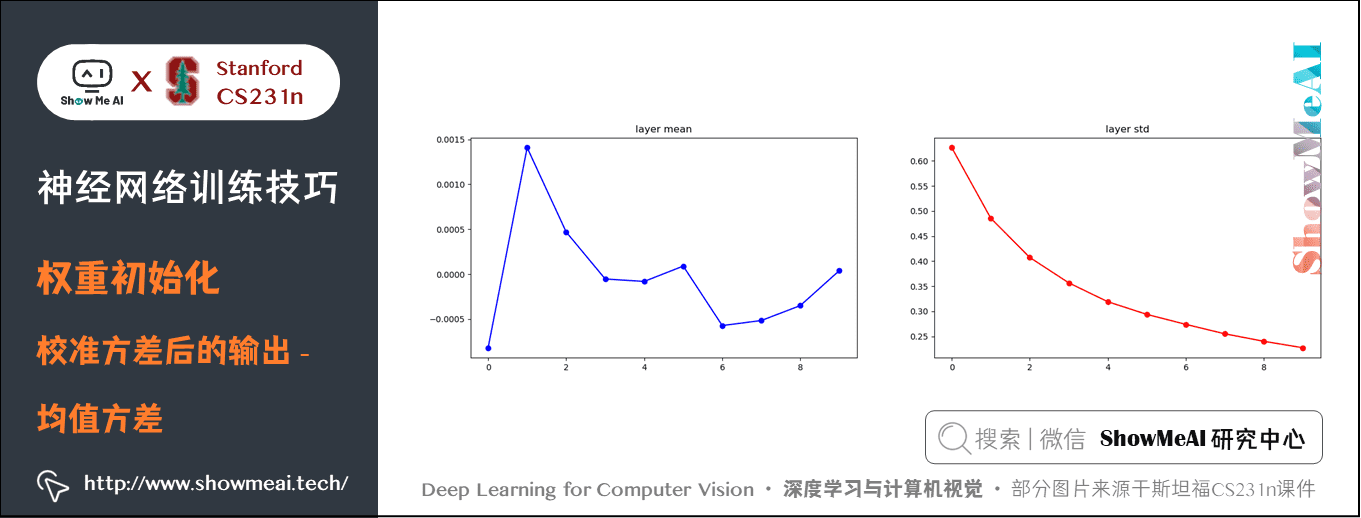
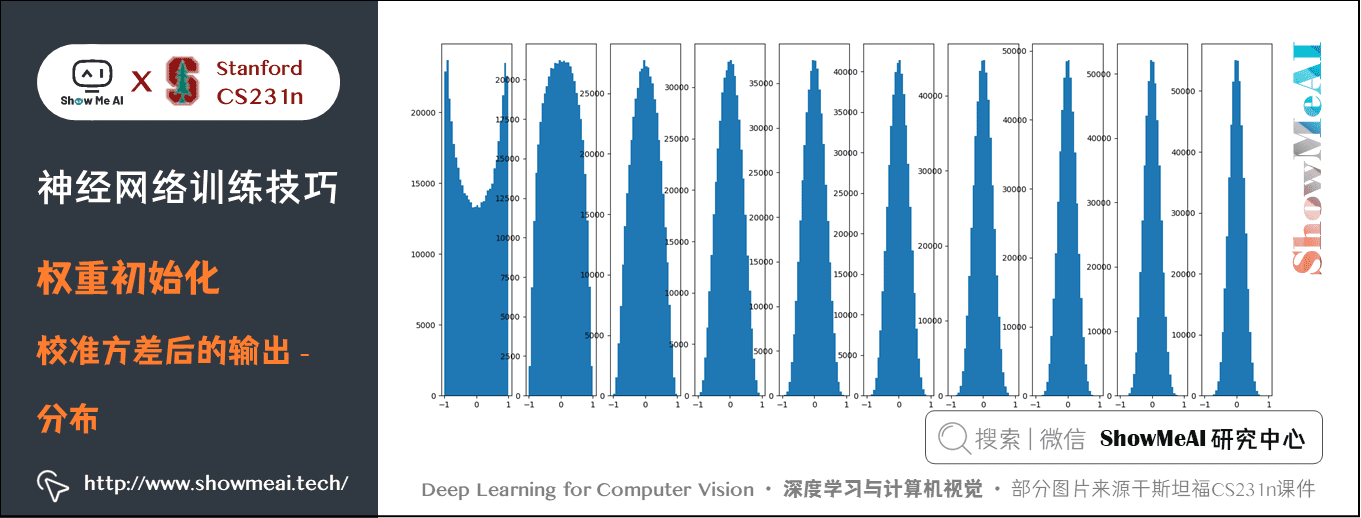
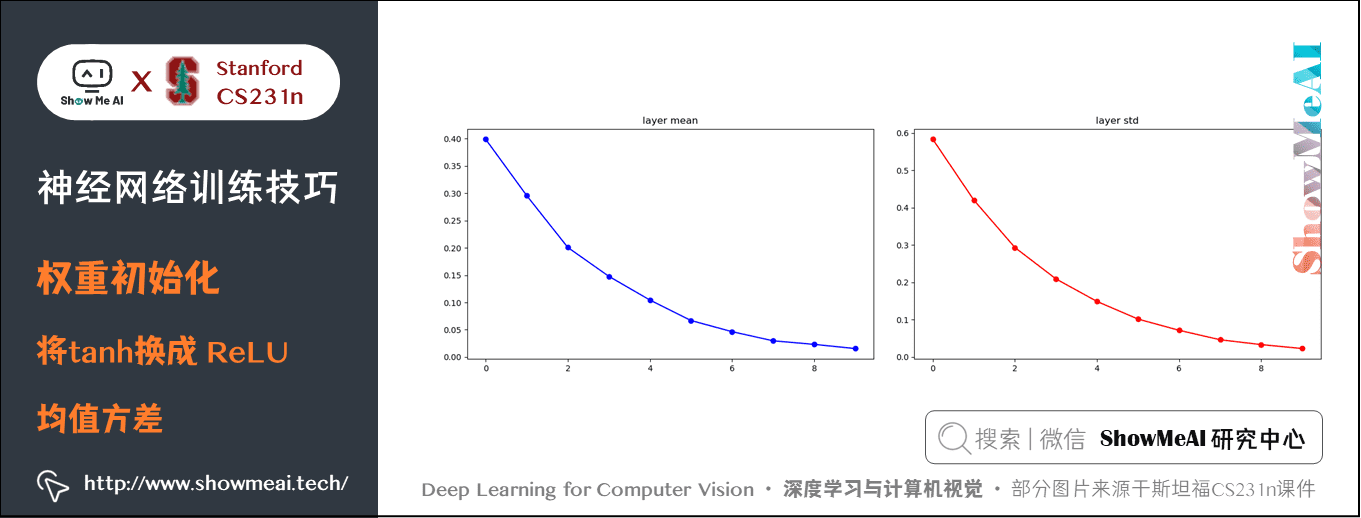
圖上可以看出,後面幾層的輸入輸出分佈很接近高斯分佈。
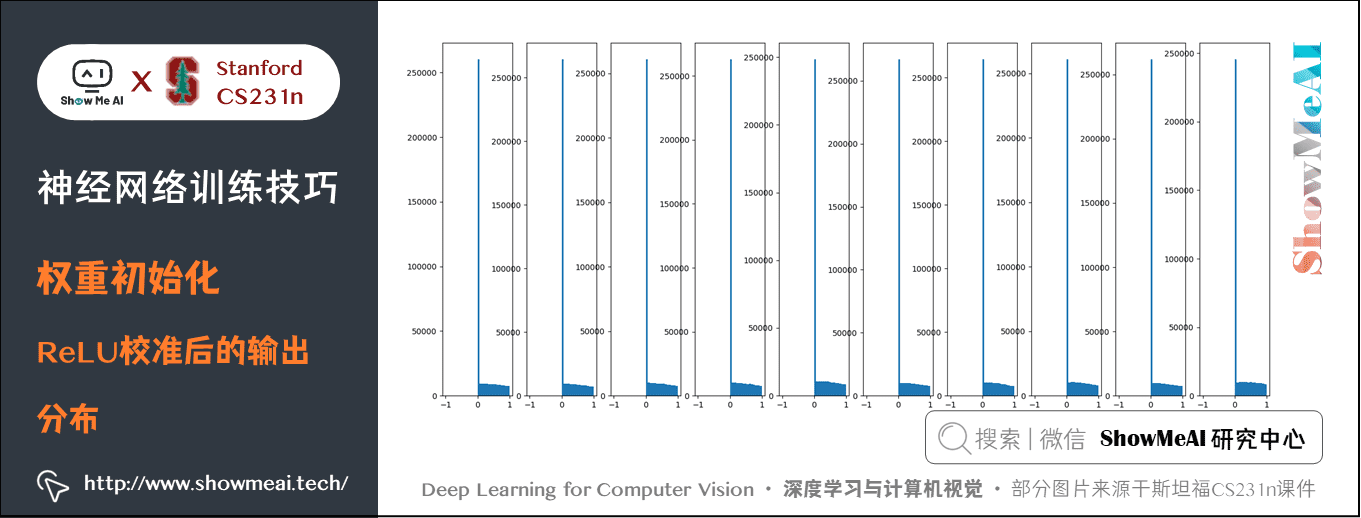
但是使用 ReLU 函數這種關係會被打破,同樣 \(w\) 使用單位高斯並且校準方差,然而使用 ReLU 函數後每層會消除一半的神經元(置 \(0\) ),結果會使方差每次減半,會有越來越多的神經元失活,輸出為 \(0\) 的神經元越來越多。如下圖所示:
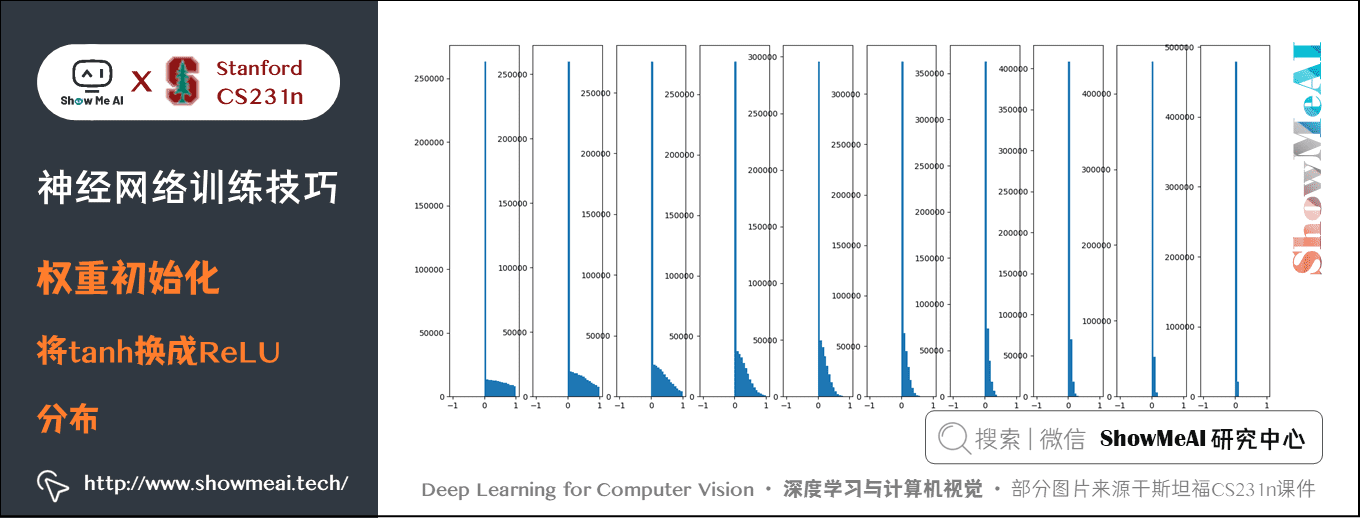
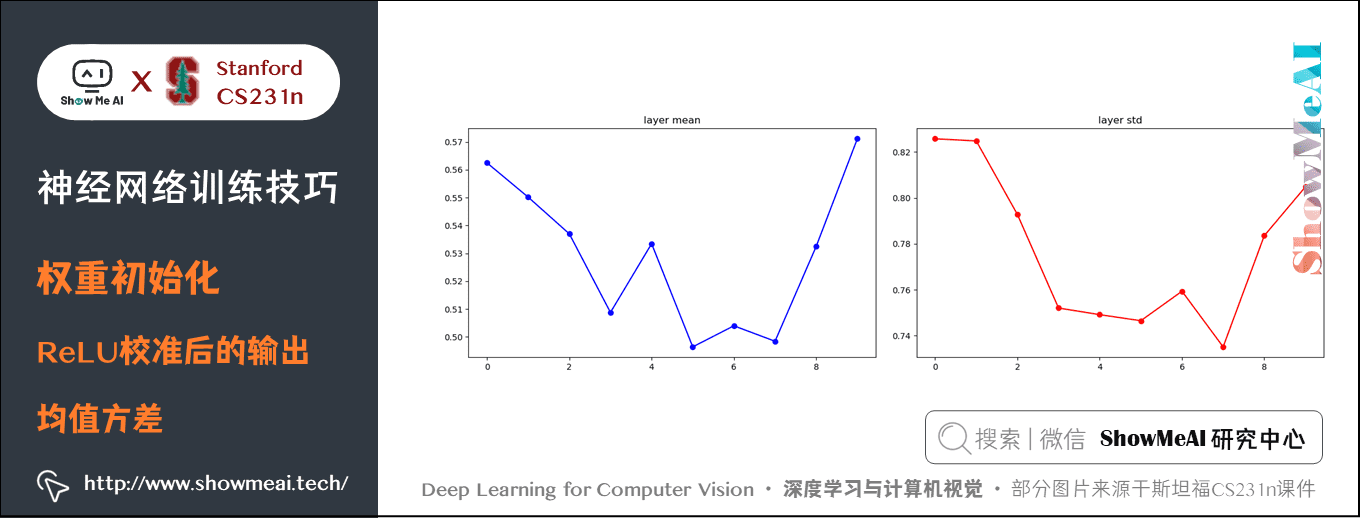
解決方法是 W = np.random.randn(fan_in, fan_out) / np.sqrt(fan_in/2)。因為每次有一半的神經元失活,校準時除2即可,這樣得到的結果會比較好。
這是2015年何凱明的論文 Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification 提到的方法,這個形式是神經網路演演算法使用 ReLU 神經元時的當前最佳推薦。結果如下:
3.4 稀疏初始化
另一個處理非標定方差的方法是將所有權重矩陣設為 \(0\),但是為了打破對稱性,每個神經元都同下一層固定數目的神經元隨機連線(其權重數值由一個小的高斯分佈生成)。一個比較典型的連線數目是10個。
偏置項(biases)的初始化:通常將偏置初始化為 \(0\)。
3.5 實際應用
合適的初始化設定仍然是現在比較活躍的研究領域,經典的論文有:
- Understanding the difficulty of training deep feedforward neural networks by Glorot and Bengio, 2010
- Exact solutions to the nonlinear dynamics of learning in deep linear neural networks by Saxe et al, 2013
- Random walk initialization for training very deep feedforward networks by Sussillo and Abbott, 2014
- Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification by He et al., 2015
- Data-dependent Initializations of Convolutional Neural Networks by Krähenbühl et al., 2015
- [All you need is a good init](https://arxiv.org/abs/1511.06856) by Mishkin and Matas, 2015
當前的推薦是使用 ReLU 啟用函數,並且使用 w = np.random.randn(n) * sqrt(2.0/n) 來進行權重初始化,n 是上一層神經元的個數,這是何凱明的論文得出的結論,也稱作 He初始化。
4.批次歸一化(Batch Normalization)
關於Batch Normalization的詳細圖示講解也可以對比閱讀ShowMeAI的深度學習教學 | 吳恩達專項課程 · 全套筆記解讀中的文章網路優化:超引數調優、正則化、批歸一化和程式框架裡【Batch Normalization】板塊內容。
4.1 概述
批次歸一化 是 loffe 和 Szegedy 最近才提出的方法,該方法一定程度解決了如何合理初始化神經網路這個棘手問題,其做法是讓啟用資料在訓練開始前通過一個網路,網路處理資料使其服從標準高斯分佈。
歸一化是一個簡單可求導的操作,所以上述思路是可行的。在實現層面,應用這個技巧通常意味著全連線層(或者是折積層,後續會講)與啟用函數之間新增一個BatchNorm層。在神經網路中使用批次歸一化已經變得非常常見,在實踐中使用了批次歸一化的網路對於不好的初始值有更強的魯棒性。
4.2 原理
具體來說,我們希望每一層網路的輸入都近似符合標準高斯分佈,考慮有 \(N\) 個啟用資料的小批次輸入,每個輸入 \(x\) 有 \(D\) 維,即 \(x = (x^{(1)} \cdots x^{(d)})\),那麼對這個小批次資料的每個維度進行歸一化,使符合單位高斯分佈,應用下面的公式:
- 其中的均值和方差是根據整個訓練集計算出來的;
- 這個公式其實就是隨機變數轉化為標準高斯分佈的公式,是可微的;
- 前向傳播與反向傳播也是利用小批次梯度下降(SGD),也可以利用這個小批次進行歸一化;
- 在訓練開始前進行歸一化,而不是在初始化時;
- 折積層每個啟用圖都有一個均值和方差;
- 對每個神經元分別進行批次歸一化。
批次歸一化會把輸入限制在非線性函數的線性區域,有時候我們並不想沒有一點飽和,所以希望能控制飽和程度,即在歸一化完成後,我們在下一步新增兩個引數去縮放和平移歸一化後的啟用資料:
這兩個引數可以在網路中學習,並且能實現我們想要的效果。的確,通過設定:\(\gamma ^{(k)}=\sqrt{\text{Var}[x^{(k)}]}\),\(\beta ^{(k)}=\text{E}[x^{(k)}]\) 可以恢復原始啟用資料,如果這樣做的確最優的話。現在網路有了為了讓網路達到較好的訓練效果而去學習控制讓 tanh 具有更高或更低飽和程度的能力。
當使用隨機優化時,我們不能基於整個訓練集去計算。我們會做一個簡化:由於我們在 SGD 中使用小批次,每個小批次都可以得到啟用資料的均值和方差的估計。這樣,用於歸一化的資料完全可以參與梯度反向傳播。
批次歸一化的思想:考慮一個尺寸為 \(m\) 的小批次B。由於歸一化被獨立地應用於啟用資料 \(x\) 的每個維度,因此讓我們關注特定啟用資料維度 \(x(k)\) 並且為了清楚起見省略 \(k\)。在小批次中共有 \(m\) 個這種啟用資料維度 \(x(k)\):\(\text{B} ={x_{1 \cdots m}}\)
歸一化後的值為:\(\hat{x}_{1 \cdots m}\)
線性轉化後的值為:\(y_{1 \cdots m}\)
這種線性轉化是批次歸一化轉化:\(\text{BN}_{\gamma, \beta} : x_{1 \cdots m} → y_{1 \cdots m}\)
於是,我們的小批次啟用資料 \(\text{B} ={x_{1 \cdots m}}\) 通過BN層,有兩個引數需要學習:\(\gamma\),\(\beta\) (\(\varepsilon\) 是為了維持數值穩定在小批次方差上新增的小常數)。
該BN層的輸出為:\({y_i=\text{BN}_{\gamma, \beta}(x_i)},i=1 \cdots m\),該層的計算有:
-
小批次均值:\(\mu _B\leftarrow \frac{1}{m} \sum_{i=1}^m x_i\)
-
小批次方差:\(\sigma^2 _B\leftarrow \frac{1}{m} \sum_{i=1}^m (x_i-\mu _B)^2\)
-
歸一化:\(\hat{x} _i\leftarrow \frac{x_i-\mu _B}{\sqrt{\sigma^2 _B+\varepsilon } }\)
-
縮放和平移:\(y_i\leftarrow \gamma \hat{x} _i+\beta \equiv \text{BN}_{\gamma,\beta }(x_i)\)

4.3 優勢
- 改善通過網路的梯度流
- 具有更高的魯棒性:允許更大的學習速率範圍、減少對初始化的依賴
- 加快學習速率衰減,更容易訓練
- 可以看作是一種正則方式,在原始輸入 \(X\) 上抖動
- 可以不使用Dropout,加快訓練
補充說明:測試時不使用小批次中計算的均值和方差,相反,使用訓練期間啟用資料的一個固定的經驗均值,例如可以使用在訓練期間的平均值作為估計。
總結:批次歸一化可以理解為在網路的每一層之前都做預處理,將輸入資料轉化為單位高斯資料或者進行平移伸縮,只是這種操作以另一種方式與網路整合在了一起。
5.層歸一化(Layer Normalization)
事實證明,批次歸一化能使網路更容易訓練,但是對批次的大小有依賴性,批次太小效果不好,批次太大又受到硬體的限制。所以在對輸入批次大小具有上限的複雜網路中不太有用。
目前已經提出了幾種批次歸一化的替代方案來緩解這個問題,其中一個就是層歸一化。我們不再對這個小批次進行歸一化,而是對特徵向量進行歸一化。換句話說,當使用層歸一化時,基於該特徵向量內的所有項的總和來歸一化對應於單個資料點。
層歸一化測試與訓練的行為相同,都是計算每個樣本的歸一。可用於迴圈神經網路。

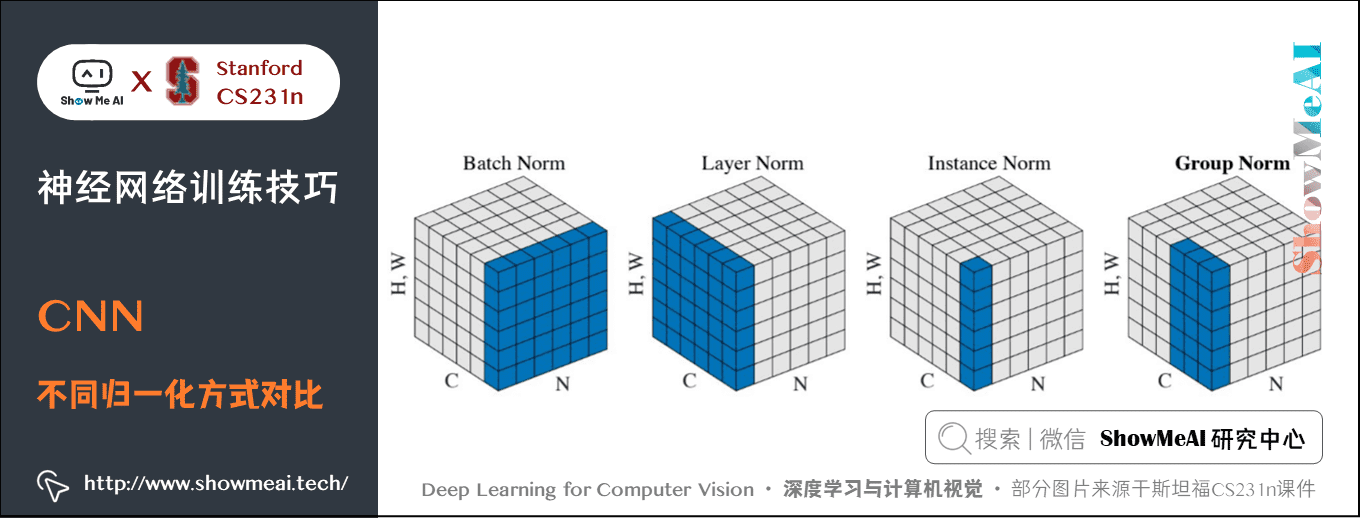
6.折積神經網路中歸一化
空間批次歸一化(Spatial Batch Normalization)是對深度進行歸一化。
- 全連線網路中的批次歸一化輸入尺寸為 \((N,D)\) 輸出是 \((N,D)\),其中我們在小批次維度 \(N\) 上計算統計資料用於歸一化 \(N\) 個特徵點。
- 折積層輸入的資料,批次歸一化的輸入尺寸是 \((N,C,H,W)\) 併產生尺寸為 \((N,C,H,W)\) 的輸出,其中N是小批次大小,\((H,W)\) 是輸出特徵圖的空間大小。
- 如果使用折積生成特徵圖,我們期望每個特徵通道的統計在不同影象和同一影象內的不同位置之間相對一致。因此,空間批次歸一化通過計算小批次維度N和空間維度 \(H\) 和 \(W\) 的統計量來計算每個 \(C\) 特徵通道的均值和方差。

折積神經網路中的層歸一化是對每張圖片進行歸一化。
- 然而在折積神經網路中,層歸一化效果不好。因為對於全連線層,層中的所有隱藏單元傾向於對最終預測做出類似的貢獻,並且對層的求和輸入重新定中心和重新縮放效果很好;而對於折積神經網路,貢獻類似的假設不再適用。其感受野位於影象邊界附近的大量隱藏單元很少開啟,因此與同一層內其餘隱藏單元的統計資料非常不同(圖片中間的位置貢獻比較大,邊緣的位置可能是背景或噪聲)。
範例歸一化既對圖片又對資料進行歸一化;

組歸一化(Group Normalization)2018年何凱明的論文 Group Normalization 提出了一種中間技術。
- 與層歸一化在每個資料點的整個特徵上進行標準化相比,建議將每個資料點特徵拆分為相同的 \(G\) 組,然後對每個資料點的每個資料組的標準化(簡單來說,相對於層歸一化將整張圖片歸一,這個將整張圖片裁成 \(G\) 組,然後對每個組進行歸一)。
- 這樣就可以假設每個組仍然做出相同的貢獻,因為分組就是根據視覺識別的特徵。比如將傳統計算機視覺中的許多高效能人為特徵在一起。其中一個定向梯度直方圖就是在計算每個空間區域性塊的直方圖之後,每個直方圖塊在被連線在一起形成最終特徵向量之前被歸一化。
7.監控學習過程
7.1 監控學習過程的步驟
1) 資料預處理,減均值
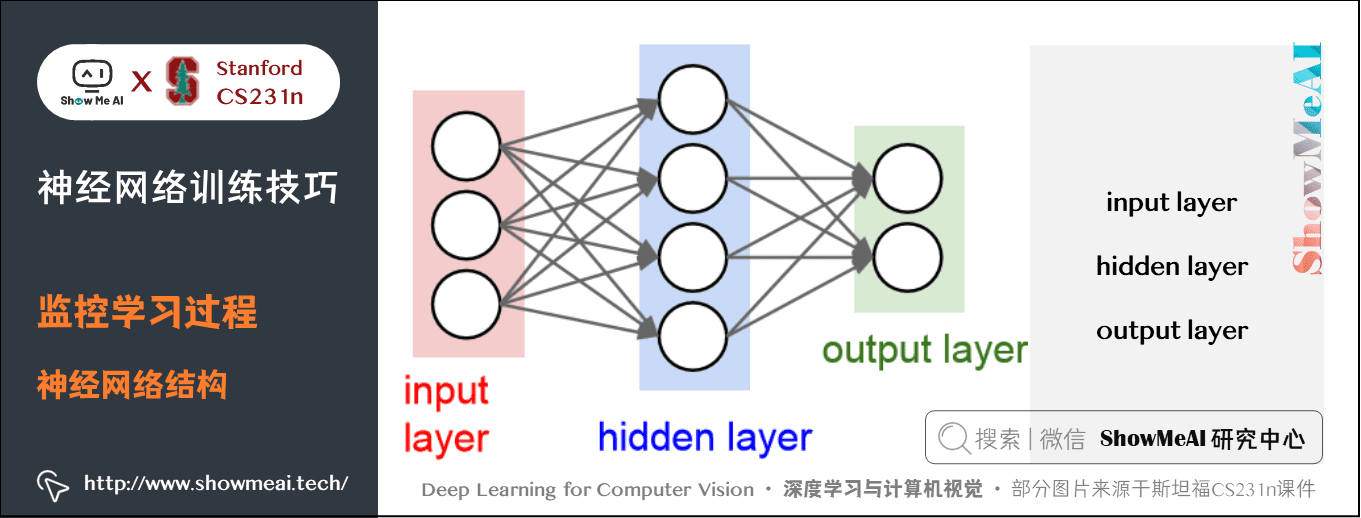
2) 選擇網路結構
兩層神經網路,一個隱藏層有 50 個神經元,輸入影象是 3072 維的向量,輸出層有 10 個神經元,代表10種分類。
3) 合理性(Sanity)檢查
使用小引數進行初始化,使正則損失為 \(0\),確保得到的損失值與期望一致。
例如,輸入資料集為CIFAR-10的影象分類
- 對於Softmax分類器,一般期望它的初始損失值是 \(2.302\),這是因為初始時預計每個類別的概率是 \(0.1\)(因為有10個類別),然後Softmax損失值正確分類的負對數概率 \(-ln(0.1) = 2.302\)。
- 對於多類 SVM,假設所有的邊界都被越過(因為所有的分值都近似為零),所以損失值是9(因為對於每個錯誤分類,邊界值是1)。
- 如果沒看到這些損失值,那麼初始化中就可能有問題。
提高正則化強度,損失值會變大。
def init_two_layer_model(input_size, hidden_size, output_size):
model = {}
model["W1"] = 0.0001 * np.random.randn(input_size, hidden_size)
model['b1'] = np.zeros(hidden_size)
model['W2'] = 0.0001 * np.random.randn(hidden_size, output_size)
model['b2'] = np.zeros(output_size)
return model
model = init_two_layer_model(32*32*3, 50, 10)
loss, grad = two_layer_net(X_train, model, y_train, 0) # 0沒有正則損失
print(loss)
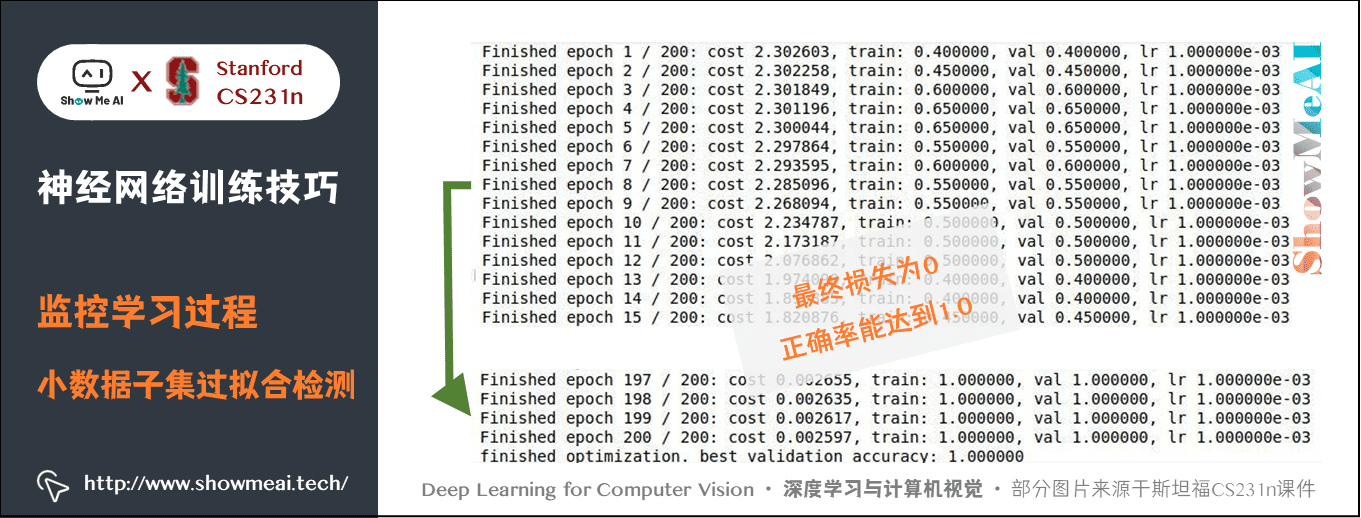
對小資料子集過擬合。
- 這一步很重要,在整個資料集進行訓練之前,嘗試在一個很小的資料集上進行訓練(比如20個資料),然後確保能到達0的損失值。此時讓正則化強度為0,不然它會阻止得到0的損失。除非能通過這一個正常性檢查,不然進行整個資料集訓練是沒有意義的。
- 但是注意,能對小資料集進行過擬合依然有可能存在不正確的實現。比如,因為某些錯誤,資料點的特徵是隨機的,這樣演演算法也可能對小資料進行過擬合,但是在整個資料集上跑演演算法的時候,就沒有任何泛化能力。
model = init_two_layer_model(32*32*3, 50, 10)
trainer = ClassifierTrainer()
X_tiny = X_train[:20] # 選前20個作為樣本
y_tiny = y_train[:20]
best_model, stats = trainer.train(X_tiny, y_tiny, X_tiny, y_tiny,
model, two_layer_net, verbose=True,
num_epochs=200, reg=0.0, update='sgd',
learning_rate=1e-3, learning_rate_decay=1,
sample_batchs=False)
4) 梯度檢查(Gradient Checks)
理論上將進行梯度檢查很簡單,就是簡單地把解析梯度和數值計算梯度進行比較。然而從實際操作層面上來說,這個過程更加複雜且容易出錯。下面是一些常用的技巧:
① 使用中心化公式。
在使用有限差值近似來計算數值梯度的時候,常見的公式是:\(\frac{df(x)}{dx} = \frac{f(x + h) - f(x)}{h}\) 其中 \(h\) 是一個很小的數位,在實踐中近似為 1e-5。但是在實踐中證明,使用中心化公式效果更好:\(\frac{df(x)}{dx} = \frac{f(x + h) - f(x - h)}{2h}\) 該公式在檢查梯度的每個維度的時候,會要求計算兩次損失函數(所以計算資源的耗費也是兩倍),但是梯度的近似值會準確很多。
② 使用相對誤差來比較。
數值梯度 \(f'_n\) 和解析梯度 \(f'_a\) 的絕對誤差並不能準確的表明二者的差距,應當使用相對誤差。\(\frac{\mid f'_a - f'_n \mid}{\max(\mid f'_a \mid, \mid f'_n \mid)}\) 在實踐中:相對誤差大於 1e-2 通常就意味著梯度可能出錯;小於 1e-7 才是比較好的結果。但是網路的深度越深,相對誤差就越高。所以對於一個10層網路,1e-2的相對誤差值可能就行,因為誤差一直在累積。相反,如果一個可微函數的相對誤差值是 1e-2,那麼通常說明梯度實現不正確。
③ 使用雙精度。
一個常見的錯誤是使用單精度浮點數來進行梯度檢查,這樣會導致即使梯度實現正確,相對誤差值也會很高(比如1e-2)。保持在浮點數的有效範圍。把原始的解析梯度和數值梯度資料列印出來,確保用來比較的數位的值不是過小。
④ 注意目標函數的不可導點(kinks) 。
在進行梯度檢查時,一個導致不準確的原因是不可導點問題。不可導點是指目標函數不可導的部分,由 ReLU 函數、SVM損失、Maxout神經元等引入。考慮當 x=-1e-6 時,對 ReLU 函數進行梯度檢查。因為 \(x<0\),所以解析梯度在該點的梯度為0。然而,在這裡數值梯度會突然計算出一個非零的梯度值,因為 \(f(x+h)\) 可能越過了不可導點(例如:如果 h>1e-6),導致了一個非零的結果。解決這個問題的有效方法是使用少量資料點。這樣不可導點會減少,並且如果梯度檢查對2-3個資料點都有效,那麼基本上對整個批次資料也是沒問題的。
⑤ 謹慎設定h。
並不是越小越好,如果無法進行梯度檢查,可以試試試試將 \(h\) 調到 1e-4 或者 1e-6。
在操作的特性模式中梯度檢查。為了安全起見,最好讓網路學習(「預熱」)一小段時間,等到損失函數開始下降的之後再進行梯度檢查。在第一次迭代就進行梯度檢查的危險就在於,此時可能正處在不正常的邊界情況,從而掩蓋了梯度沒有正確實現的事實。
⑥ 關閉正則損失。
推薦先關掉正則化對資料損失做單獨檢查,然後對正則化做單獨檢查,防止正則化損失吞沒掉資料損失。
5) 正式訓練,數值跟蹤,特徵視覺化。
設定一個較小的正則強度,找到使損失下降的學習率。
best_model, stats = trainer.train(X_tiny, y_tiny, X_tiny, y_tiny,
model, two_layer_net, verbose=True,
num_epochs=10, reg=0.000001, update='sgd',
learning_rate=1e-6, learning_rate_decay=1,
sample_batchs=False)
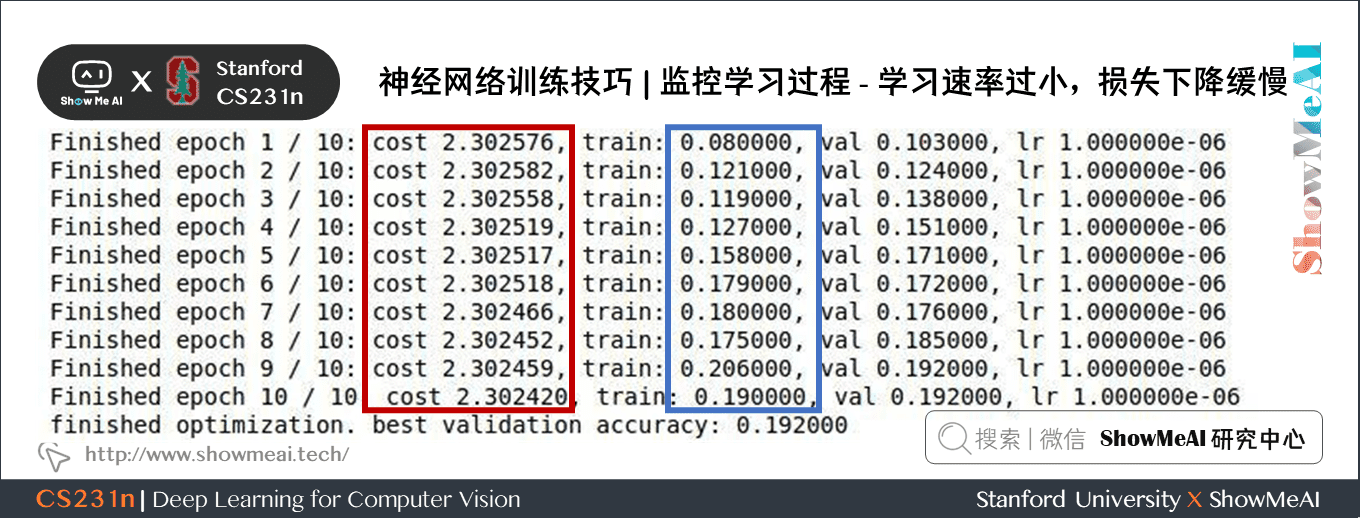
學習率為 \(10^{-6}\) 時,損失下降緩慢,說明學習速率過小。
如果把學習率設為另一個極端:\(10^{6}\),如下圖所示,會發生損失爆炸:
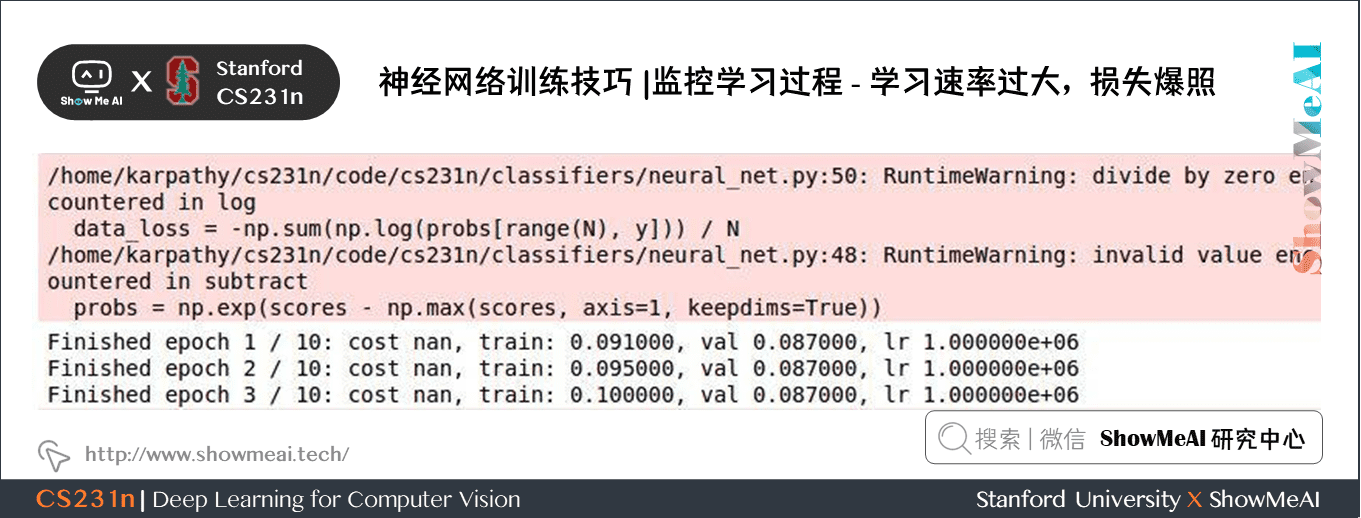
NaN通常意味著學習率過高,導致損失過大。設為 \(10^{-3}\) 時仍然爆炸,一個比較合理的範圍是 \([10^{-5}, 10^{-3}]\)。
7.2 訓練過程中的數值跟蹤
1) 跟蹤損失函數
訓練期間第一個要跟蹤的數值就是損失值,它在前向傳播時對每個獨立的批資料進行計算。
在下面的圖表中,\(x\) 軸通常都是表示週期(epochs)單位,該單位衡量了在訓練中每個樣本資料都被觀察過的次數的期望(一個 epoch 意味著每個樣本資料都被觀察過了一次)。相較於迭代次數(iterations) ,一般更傾向跟蹤 epoch,這是因為迭代次數與資料的批尺寸(batchsize)有關,而批尺寸的設定又可以是任意的。
比如一共有 1000個 訓練樣本,每次 SGD 使用的小批次是 10 個樣本,一次迭代指的是用這 10 個樣本訓練一次,而1000個樣本都被使用過一次才是一次 epoch,即這 1000 個樣本全部被訓練過一次需要 100 次 iterations,一次 epoch。
下圖展示的是損失值隨時間的變化,曲線形狀會給出學習率設定的情況:
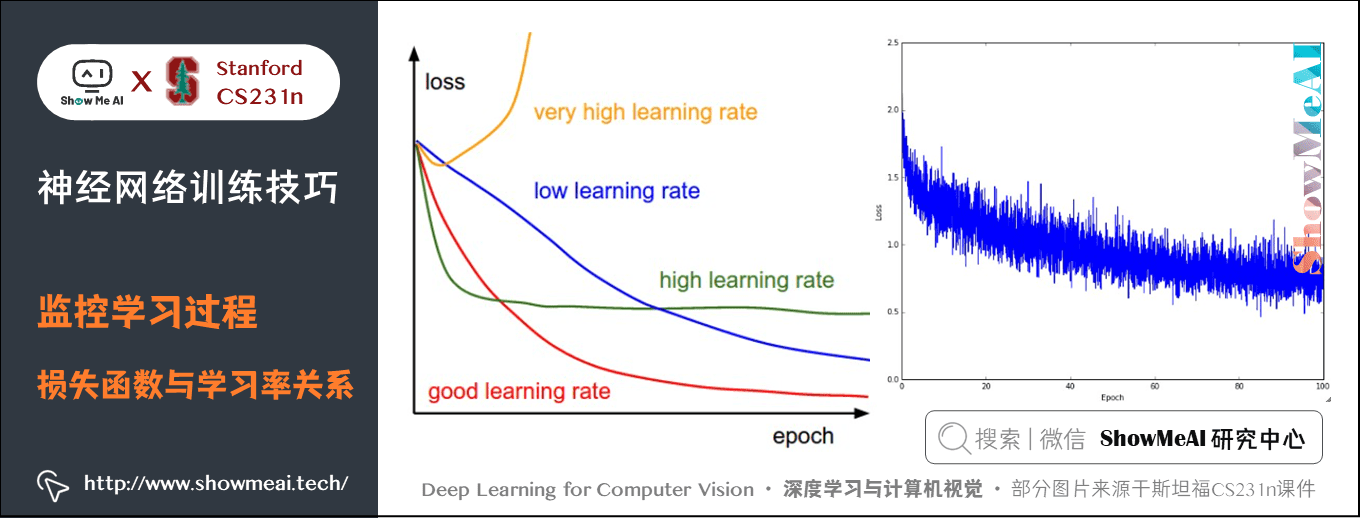
左圖展示了不同的學習率的效果。過低的學習率導致演演算法的改善是線性的。高一些的學習率會看起來呈幾何指數下降,更高的學習率會讓損失值很快下降,但是接著就停在一個不好的損失值上(綠線)。這是因為最佳化的「能量」太大,引數隨機震盪,不能最佳化到一個很好的點上。過高的學習率又會導致損失爆炸。
右圖顯示了一個典型的隨時間變化的損失函數值,在CIFAR-10資料集上面訓練了一個小的網路,這個損失函數值曲線看起來比較合理(雖然可能學習率有點小,但是很難說),而且指出了批資料的數量可能有點太小(因為損失值的噪音很大)。損失值的震盪程度和批尺寸(batch size)有關,當批尺寸為1,震盪會相對較大。當批尺寸就是整個資料集時震盪就會最小,因為每個梯度更新都是單調地優化損失函數(除非學習率設定得過高)。
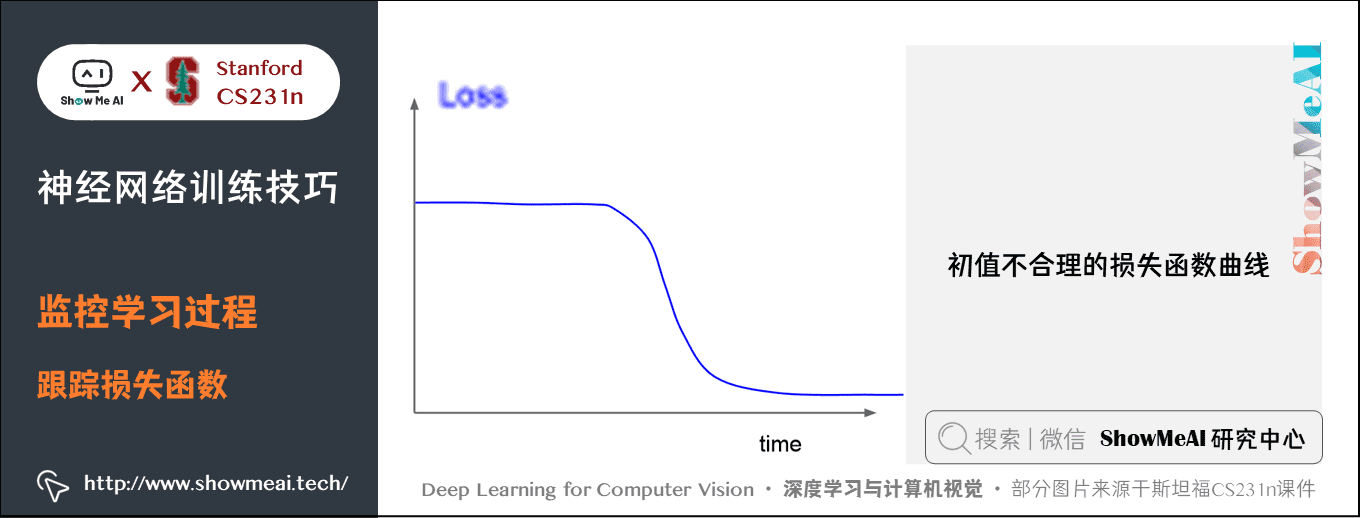
下圖這種開始損失不變,然後開始學習的情況,說明初始值設定的不合理。
2) 跟蹤訓練集和驗證集準確率
在訓練分類器的時候,需要跟蹤的第二重要的數值是驗證集和訓練集的準確率。這個圖表能夠展現知道模型過擬合的程度:
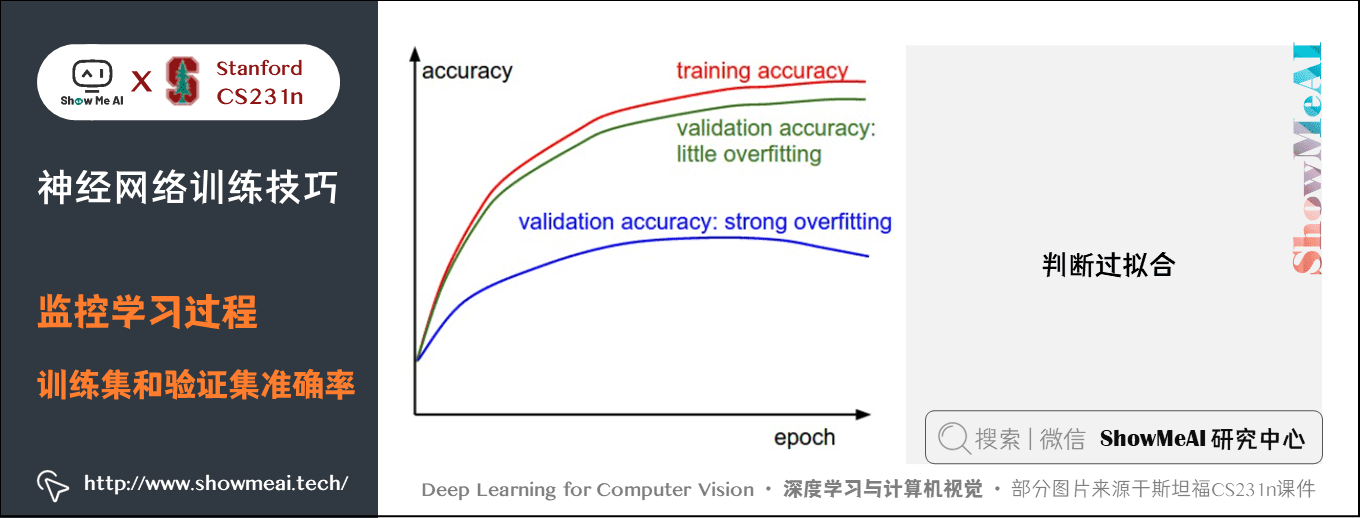
訓練集準確率和驗證集準確率間的間距指明瞭模型過擬合的程度。在圖中,藍色的驗證集曲線比訓練集準確率低了很多,這就說明模型有很強的過擬合。遇到這種情況,就應該增大正則化強度(更強的L2權重懲罰,更多的隨機失活等)或收集更多的資料。另一種可能就是驗證集曲線和訓練集曲線很接近,這種情況說明模型容量還不夠大:應該通過增加引數數量讓模型容量更大些。
3) 跟蹤權重更新比例
最後一個應該跟蹤的量是權重中更新值的數量和全部值的數量之間的比例。注意:是更新的,而不是原始梯度(比如,在普通sgd中就是梯度乘以學習率)。需要對每個引數集的更新比例進行單獨的計算和跟蹤。一個經驗性的結論是這個比例應該在 1e-3 左右。如果更低,說明學習率可能太小,如果更高,說明學習率可能太高。下面是具體例子:
# 假設引數向量為W,其梯度向量為dW
param_scale = np.linalg.norm(W.ravel()) # ravel將多維陣列轉化成一維;
# np.linalg.norm預設求L2正規化
update = -learning_rate*dW # 簡單SGD更新
update_scale = np.linalg.norm(update.ravel())
W += update # 實際更新
print update_scale / param_scale # 要得到1e-3左右
4) 第一層視覺化
如果資料是影象畫素資料,那麼把第一層特徵視覺化會有幫助:

左圖: 特徵充滿了噪音,這暗示了網路可能出現了問題:網路沒有收斂,學習率設定不恰當,正則化懲罰的權重過低。
右圖: 特徵不錯,平滑,乾淨而且種類繁多,說明訓練過程進行良好。
8.超引數調優
關於超引數調優的講解也可以對比閱讀ShowMeAI的深度學習教學 | 吳恩達專項課程 · 全套筆記解讀中的文章網路優化:超引數調優、正則化、批歸一化和程式框架裡【超引數調優】板塊內容。
如何進行超引數調優呢?常需要設定的超引數有三個:
- 學習率
- 學習率衰減方式(例如一個衰減常數)
- 正則化強度(L2 懲罰,隨機失活強度)
下面介紹幾個常用的策略:
1) 比起交叉驗證最好使用一個驗證集
在大多數情況下,一個尺寸合理的驗證集可以讓程式碼更簡單,不需要用幾個資料集來交叉驗證。
2) 分散初值,幾次週期(epoch)
選擇幾個非常分散的數值,然後使用幾次 epoch(完整資料集訓練一輪是1個epoch)去學習。經過幾次 epoch,基本就能發現哪些數值較好哪些不好。比如很快就 nan(往往超過初始損失 3 倍就可以認為是 nan,就可以結束訓練。),或者沒有反應,然後進行調整。
3) 過程搜尋:從粗到細
發現比較好的區間後,就可以精細搜尋,epoch 次數更多,執行時間更長。比如之前的網路,每次進行 5 次 epoch,對較好的區間進行搜尋,找到準確率比較高的值,然後進一步精確查詢。注意,需要在對數尺度上進行超引數搜尋。
也就是說,我們從標準分佈中隨機生成了一個實數,然後讓它成為 10 的次數。對於正則化強度,可以採用同樣的策略。直觀地說,這是因為學習率和正則化強度都對於訓練的動態程序有乘的效果。
例如:當學習率是 0.001 的時候,如果對其固定地增加 0.01,那麼對於學習程序會有很大影響。然而當學習率是 10 的時候,影響就微乎其微了。這就是因為學習率乘以了計算出的梯度。
比起加上或者減少某些值,思考學習率的範圍是乘以或者除以某些值更加自然。但是有一些引數(比如隨機失活)還是在原始尺度上進行搜尋。
max_count = 100
for count in range(max_count):
reg = 10**uniform(-5, 5) # random模組的函數uniform,會在-5~5範圍內隨機選擇一個實數
# reg在10^-5~10^5之間取值,指數函數
lr = 10**uniform(-3, -6)
model = init_two_layer_model(32 * 32 * 3, 50, 10)
trainer = ClassifierTrainer()
best_model, stats = trainer.train(X_tiny, y_tiny, X_tiny, y_tiny,
model, two_layer_net, verbose=False,
num_epochs=5, reg=reg, update='momentum',
learning_rate=lr, learning_rate_decay=0.9,
sample_batchs=True, batch_size=100)
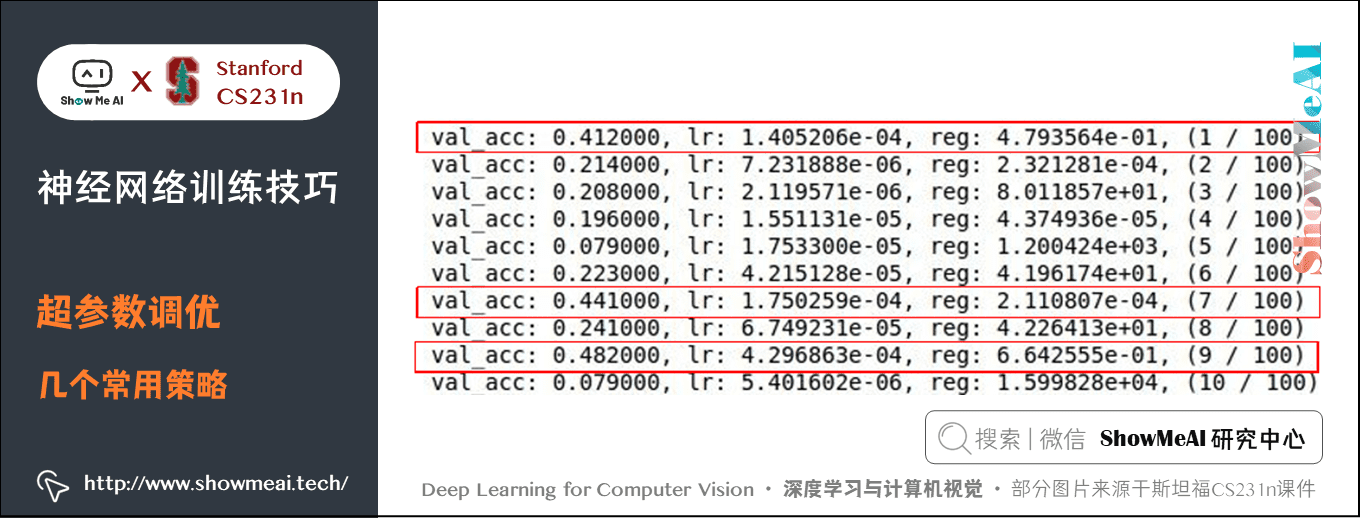
比較好的結果在紅框中,學習率在 10e-4 左右,正則強度在 10e-4~10e-1 左右,需要進一步精細搜尋。修改程式碼:
max_count = 100
for count in range(max_count):
reg = 10**uniform(-4, 0)
lr = 10**uniform(-3, -4)
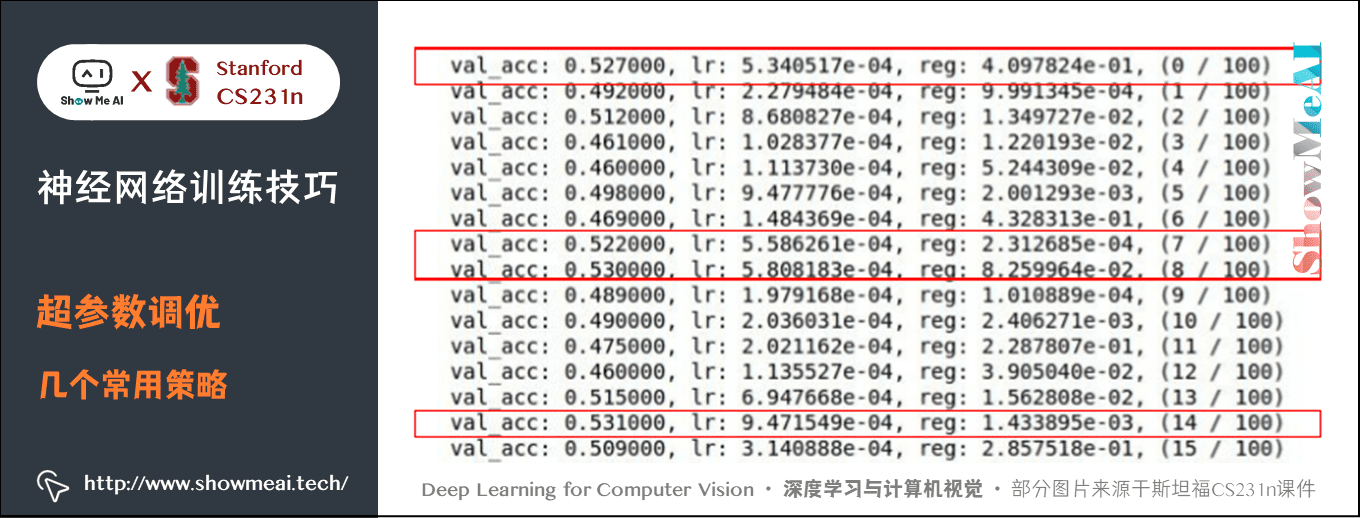
有一個相對較好的準確率:\(53\%\)。但是這裡卻有一個問題,這些比較高的準確率都是學習率在 10e-4附近,也就是說都在我們設定的區間邊緣,或許 10e-5 或 10e-6 有更好的結果。所以在設定區間的時候,要把較好的值放在區間中間,而不是區間邊緣。
隨機搜尋優於網格搜尋。Bergstra 和 Bengio 在文章 Random Search for Hyper-Parameter Optimization 中說「隨機選擇比網格化的選擇更加有效」,而且在實踐中也更容易實現。通常,有些超引數比其餘的更重要,通過隨機搜尋,而不是網格化的搜尋,可以讓你更精確地發現那些比較重要的超引數的好數值。
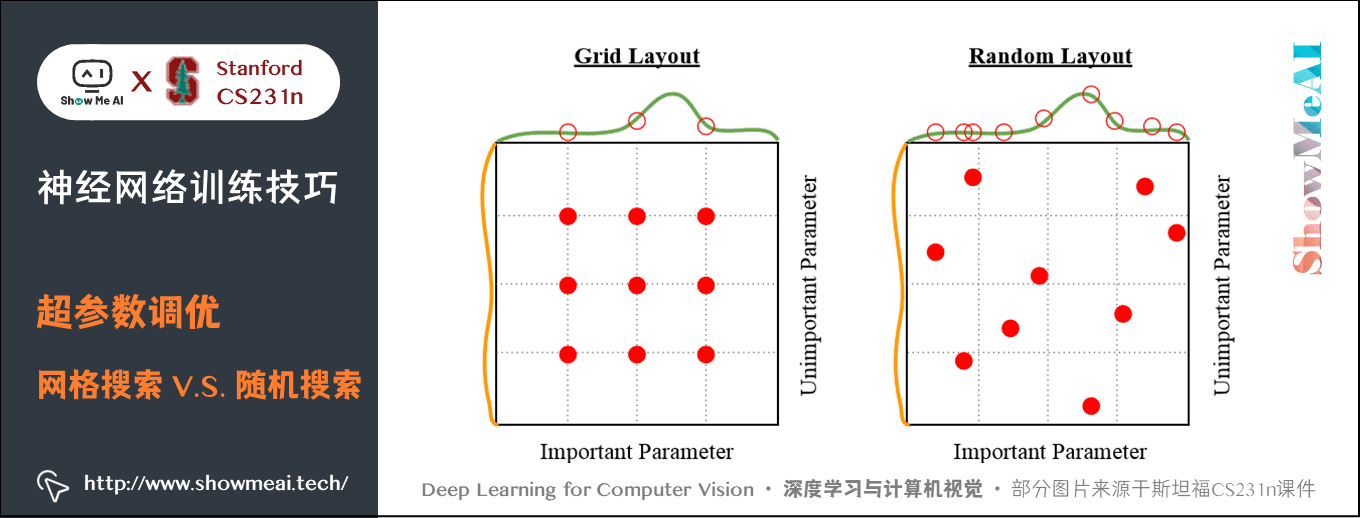
上圖中綠色函數部分是比較重要的引數影響,黃色是不重要的引數影響,同樣取9個點,如果採用均勻取樣就會錯過很多重要的點,隨機搜尋就不會。
下一篇 深度學習與CV教學(7) | 神經網路訓練技巧 (下) 會講到的學習率衰減方案、更新型別、正則化、以及網路結構(深度、尺寸)等都需要超引數調優。
9.拓展學習
可以點選 B站 檢視視訊的【雙語字幕】版本
- 【課程學習指南】斯坦福CS231n | 深度學習與計算機視覺
- 【字幕+資料下載】斯坦福CS231n | 深度學習與計算機視覺 (2017·全16講)
- 【CS231n進階課】密歇根EECS498 | 深度學習與計算機視覺
- 【深度學習教學】吳恩達專項課程 · 全套筆記解讀
- 【Stanford官網】CS231n: Deep Learning for Computer Vision
10.要點總結
- 啟用函數選擇折葉函數
- 資料預處理採用減均值
- 權重初始化採用 Xavier 或 He 初始化
- 使用批次歸一化
- 梯度檢查;合理性檢查;跟蹤損失函數、準確率、更新比例等
- 超引數調優採用隨機搜尋,對數間隔,不斷細化範圍,增加 epoch
斯坦福 CS231n 全套解讀
- 深度學習與CV教學(1) | CV引言與基礎
- 深度學習與CV教學(2) | 影象分類與機器學習基礎
- 深度學習與CV教學(3) | 損失函數與最佳化
- 深度學習與CV教學(4) | 神經網路與反向傳播
- 深度學習與CV教學(5) | 折積神經網路
- 深度學習與CV教學(6) | 神經網路訓練技巧 (上)
- 深度學習與CV教學(7) | 神經網路訓練技巧 (下)
- 深度學習與CV教學(8) | 常見深度學習框架介紹
- 深度學習與CV教學(9) | 典型CNN架構 (Alexnet, VGG, Googlenet, Restnet等)
- 深度學習與CV教學(10) | 輕量化CNN架構 (SqueezeNet, ShuffleNet, MobileNet等)
- 深度學習與CV教學(11) | 迴圈神經網路及視覺應用
- 深度學習與CV教學(12) | 目標檢測 (兩階段, R-CNN系列)
- 深度學習與CV教學(13) | 目標檢測 (SSD, YOLO系列)
- 深度學習與CV教學(14) | 影象分割 (FCN, SegNet, U-Net, PSPNet, DeepLab, RefineNet)
- 深度學習與CV教學(15) | 視覺模型視覺化與可解釋性
- 深度學習與CV教學(16) | 生成模型 (PixelRNN, PixelCNN, VAE, GAN)
- 深度學習與CV教學(17) | 深度強化學習 (馬爾可夫決策過程, Q-Learning, DQN)
- 深度學習與CV教學(18) | 深度強化學習 (梯度策略, Actor-Critic, DDPG, A3C)
ShowMeAI 系列教學推薦
- 大廠技術實現:推薦與廣告計算解決方案
- 大廠技術實現:計算機視覺解決方案
- 大廠技術實現:自然語言處理行業解決方案
- 圖解Python程式設計:從入門到精通系列教學
- 圖解資料分析:從入門到精通系列教學
- 圖解AI數學基礎:從入門到精通系列教學
- 圖解巨量資料技術:從入門到精通系列教學
- 圖解機器學習演演算法:從入門到精通系列教學
- 機器學習實戰:手把手教你玩轉機器學習系列
- 深度學習教學:吳恩達專項課程 · 全套筆記解讀
- 自然語言處理教學:斯坦福CS224n課程 · 課程帶學與全套筆記解讀
- 深度學習與計算機視覺教學:斯坦福CS231n · 全套筆記解讀
