資料庫系列:高並行下的資料欄位變更
1 背景
經常會遇到這種情況,我們的業務已經穩定地執行一段時間了,並且流量漸漸已經上去了。這時候,卻因為某些原因(比如功能調整或者業務擴充套件),你需要對資料表進行調整,加欄位 or 修改表結構。
可能很多人說 alter table add column ... / alter table modify ...,輕輕鬆鬆就解決了。 這樣其實是有風險的
,對於複雜度比較高、資料量比較大的表。調整表結構、建立或刪除索引、觸發器,都可能引起鎖表,而鎖表的時長依你的資料表實際情況而定。 本人有過慘痛的教訓,在一次業務上線過程中沒有評估好資料規模,導致長時間業務資料寫入不進來。
那麼有什麼辦法對資料庫的業務表進行無縫升級,讓該表對使用者透明無感呢?下面我們一個個來討論。
2 新增關聯表
最簡單的一種辦法,把新增的欄位儲存在另外一張輔表上,用外來鍵關聯到主表的主鍵。達到動態擴充套件的目標。後續功能上線之後,新增的資料會儲存到輔表中,主表無需調整,透明、無失真。
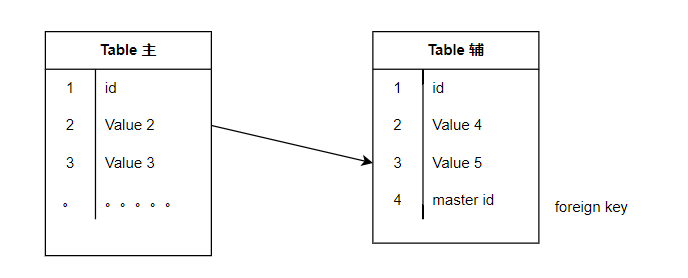
存在的問題:
- 讀取資料時,聯表查詢效率低下,資料量越大,資料越複雜,劣勢越明顯。
- 並沒有徹底的解決問題,之後有新增欄位,照樣面臨是新增表還是修改原表的問題。即使後續新增的欄位都加在輔表上,同樣面臨鎖表的問題。
- 輔表的作用僅僅是解決欄位新增的問題,並未解決欄位更新的問題(如修改欄位名、資料型別等)。
3 新增通用列
假設我們原有表結構如下,為了保障業務的持續發展,後續不間斷的會有欄位擴充套件。這時候就需要考慮增加一個可自動擴縮的通用欄位。
以MySQL為例子,5.7版本版本之後提供了Json欄位型別,方便我們儲存複雜的Json物件資料。
use test;
DROP TABLE IF EXISTS `t_user`;
CREATE TABLE "t_user" (
"id" bigint(20) NOT NULL AUTO_INCREMENT,
"name" varchar(20) NOT NULL,
"age" int(11) DEFAULT NULL,
"address" varchar(255) DEFAULT NULL,
"sex" int(11) DEFAULT '1',
"ext_data" json DEFAULT NULL COMMENT 'json字串',
PRIMARY KEY ("id")
) ENGINE=InnoDB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of t_user
-- ----------------------------
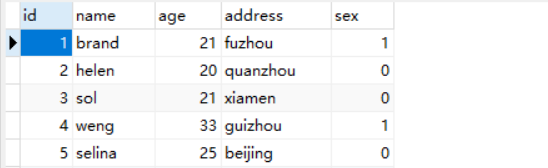
INSERT INTO `t_user` VALUES ('1', 'brand', '21', 'fuzhou', '1', '{"tel": "13212345678", "name": "brand", "address": "fuzhou"}');
程式碼中 ext_data 採用Json資料型別,是一種可延伸的物件載體,存放被查詢資料的資訊補充。
同樣的,MySQL提供的這種資料型別,也提供了很強大的Json函數進行操作。
SELECT id,`name`,age,address FROM `t_user` WHERE json_extract(ext_data,'$.tel') = '13212345678';
結果如下:

之前寫MySQL系列的時候,部落格園的一位讀者留言要我歸納一下MySQL Json 的用法,一直沒時間,大家可以看一下官網的檔案,還是比較清晰的。
Json結構一般來說是向下相容的,所以你在設計欄位擴充套件的時候,一般建議往前增,不建議刪除舊屬性。但是這也有個問題,就是業務越複雜,Json複雜度也越高,冗餘屬性也越多。
比如上文中我們的json包含三個屬性,tel、name、address,之後的業務調整中,發現tel沒用了,加了個age屬性,那tel要不要刪除?
有一種比較好的辦法,是給表加上version屬性,每個時期的業務對應一個version,每個version對應的Json資料結構也不一樣。
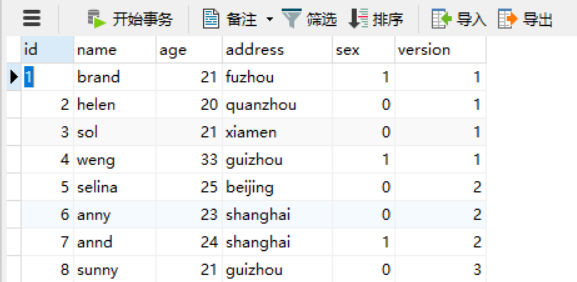
優點:
- 可以隨時動態擴充套件屬性
- 新舊兩種資料可以同時存在
- 遷移資料方便,寫個程式將舊版本ext的改為新版本的ext,並修改version
不足:
- ext_data裡的欄位無法建立索引
- ext_data裡的key會有大量空間佔用,建議key簡短一些
- 從json中去統計某個欄位資料之類的很麻煩,而且效率低。
- 查詢相對效率較低,操作複雜。
- 更新Json中的某個欄位效率較低,不適合儲存業務邏輯複雜的資料。
- 統計資料複雜,建議需要做報表的資料不要存json。
改進:
- 如果ext裡的屬性有索引之類的需求,可能NoSql(如MongoDB)會更適合
4 新表+資料遷移
4.1 利用觸發器進行資料遷移
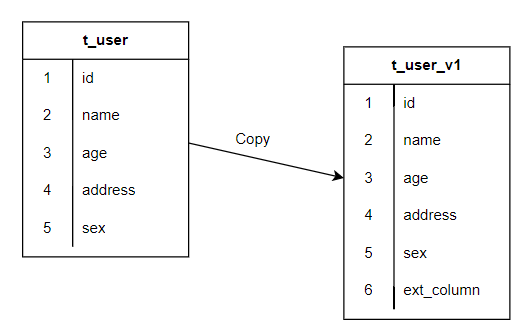
整個步驟如下:
- 新建一個表t_user_v1 (id, name, age, address, sex, ext_column),包含了擴充套件欄位 ext_column
- 在原有表上新增觸發器,原表的DML操作(主要INSERT、UPDATE、DELETE),都會觸發操作,把資料轉存到新表t_user_v1中
- 對於舊錶中原有的資料,逐步的遷移直至完成
- 刪掉觸發器,把原表移走(預設是drop掉)
- 把新表t_user_v1重新命名(rename)成原表t_user
通過上述步驟,逐漸的將資料遷移到新表,並替換舊錶,整個操作無需停服維護,對用業務無失真
4.2 利用Binlog 進行資料遷移
如果是MySQL資料庫,可以通過複製binlog的操作進行資料遷移的,效果一樣,比起觸發器,更穩定一點。
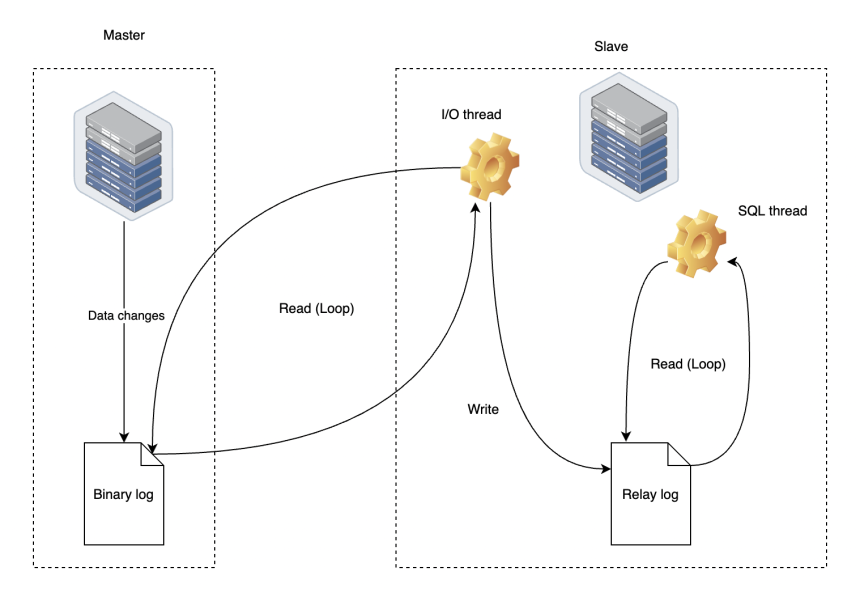
4.3 存在的問題
- 操作繁瑣,效率低下
- 資料遷移和資料表切換之間存在操作間隙,對於高並行、高頻操作的資料表,還是有風險的,會引起短暫連線失效 和 資料不一致。
- 對於巨量資料表,同步時間長
5 欄位預留
預留欄位 和 欄位與表格名稱對映的辦法。
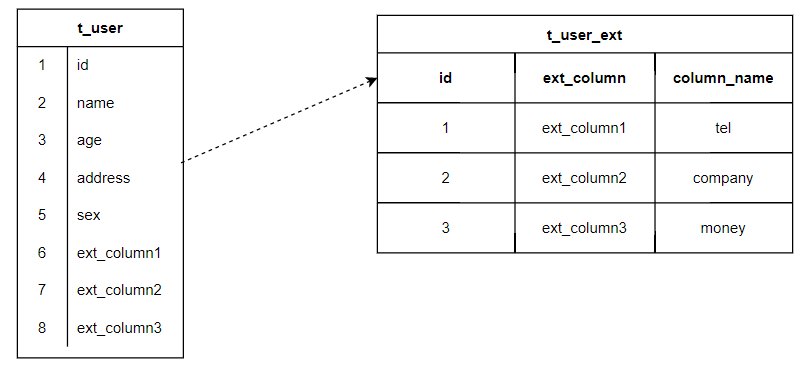
5.1 存在的問題
- 同樣的,查詢效率低
- 預設存在未知數,可能存在預設的欄位不夠,也可能存在空間冗餘
- 冗餘過多的空子欄位,對儲存空間的佔用和效能的提升存在阻礙。
- 該方法還是比較笨的,不適合程式設計師思維
6 多主模式和分級更新
如果業務流量比較小,可以直接在表上進行欄位新增或者修改,短暫的寫鎖是可以承受的。但如果是高並行、叢集化、分散式的系統,則從資料層面上就應該進行主從或者分庫分表治理。
以下是典型的的多主要模式下,進行資料庫表結構升級的過程。
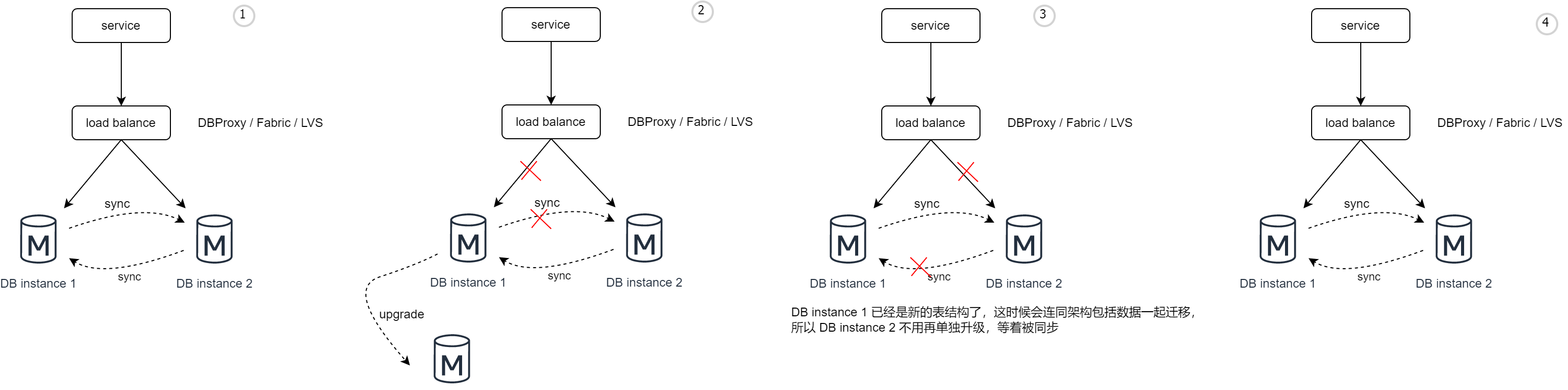
- 正常兩主模式下,主主同步,可以使用DBproxy、Fabric 等資料中介軟體做負載均衡,也可以自己定義一些負載策略,比如 Range、Hash。
- 修改設定,讓流量都切到其中一臺上,然後對另外一臺進行資料表升級(比如切DB1,只使用DB2)。切記在業務低峰期進行,避免流量過大導致另外一個資料庫範例負載過大而掛起。
- 輪流這個操作,但是這時候不需要再升級DB2了,因為是主主同步。DB instance 1 已經是新的表結構了,這時候會連同架構包括資料一起更新到 DB2 上。
- 等兩個資料庫範例都一致了,修改設定,重設兩個資料庫範例的負載,恢復到之前的狀態。
