Kafka 分割區
一、副本機制
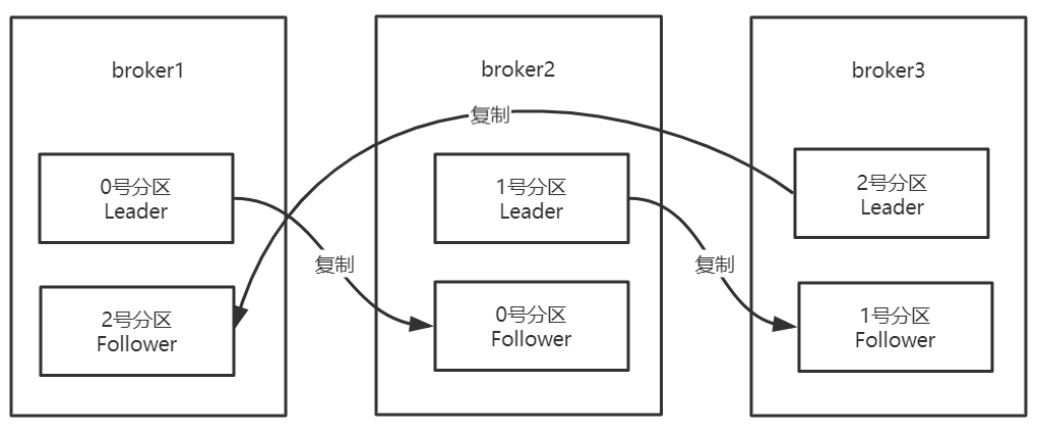
Kafka在⼀定數量的伺服器上對主題分割區進⾏複製。
當叢集中的⼀個broker宕機後系統可以⾃動故障轉移到其他可⽤的副本上,不會造成資料丟失。
建立主題:
kafka-topics.sh --zookeeper localhost:2181/myKafka --create --topic tp_demo_02 --partitions 2 --replication-factor 3
上面建立主題中的 --replication-factor 3 表示有3個副本,1個Leader + 2個 Follower
- 將複製因⼦為1的未複製主題稱為複製主題。
- 主題的分割區是複製的最⼩單元。
- 在⾮故障情況下,Kafka中的每個分割區都有⼀個Leader副本和零個或多個Follower副本。
- 包括Leader副本在內的副本總數構成複製因⼦。
- 所有讀取和寫⼊都由Leader副本負責。
- 通常,分割區⽐broker多,並且Leader分割區在broker之間平均分配
Follower分割區像普通的Kafka消費者⼀樣,消費來⾃Leader分割區的訊息,並將其持久化到⾃⼰的⽇志中。
允許Follower對⽇志條⽬拉取進⾏批次處理。
同步節點定義:
- 節點必須能夠維持與ZooKeeper的對談(通過ZooKeeper的⼼跳機制)
- 對於Follower副本分割區,它複製在Leader分割區上的寫⼊,並且不要延遲太多
Kafka提供的保證是,只要有⾄少⼀個同步副本處於活動狀態,提交的訊息就不會丟失。
宕機如何恢復:
-
少部分副本宕機
當leader宕機了,會從follower選擇⼀個作為leader。當宕機的重新恢復時,會把之前commit的資料清空,重新從leader⾥pull資料。
-
全部副本宕機
當全部副本宕機了有兩種恢復⽅式
- 等待ISR中的⼀個恢復後,並選它作為leader。(等待時間較⻓,降低可⽤性)
- 選擇第⼀個恢復的副本作為新的leader,⽆論是否在ISR中。(並未包含之前leader commit的資料,因此造成資料丟失)
二、Leader 選舉
先看一張圖片,在這張圖片中:
- 分割區P1的Leader是0,ISR是0和1
- 分割區P2的Leader是2,ISR是1和2
- 分割區P3的Leader是1,ISR是0,1,2。
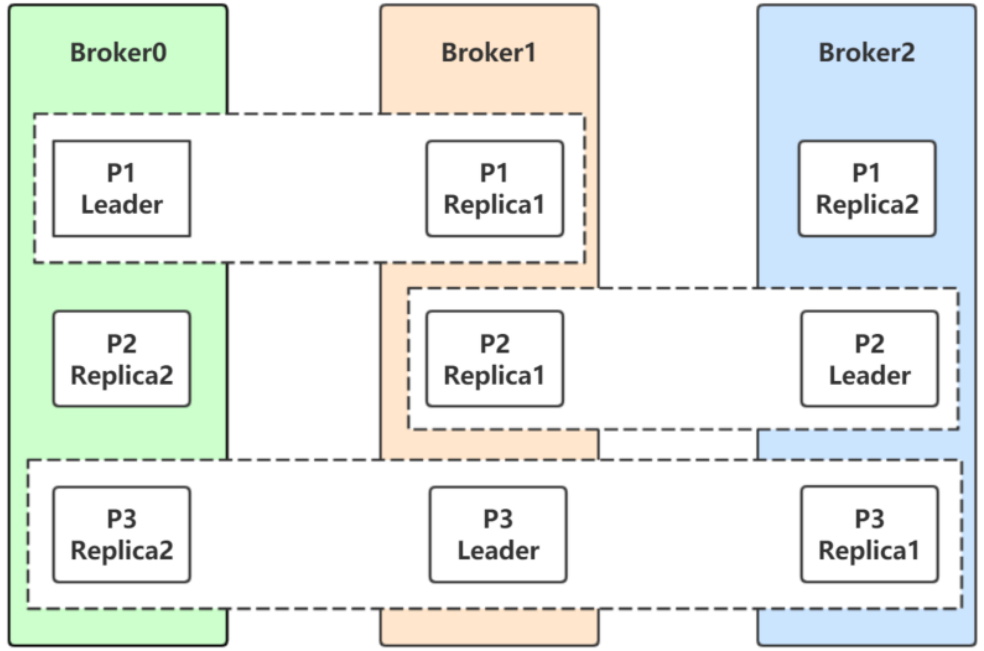
⽣產者和消費者的請求都由Leader副本來處理。Follower副本只負責消費Leader副本的資料和Leader保持同步。
對於P1,如果0宕機會發⽣什麼?
Leader副本和Follower副本之間的關係並不是固定不變的,在Leader所在的broker發⽣故障的時候,就需要進⾏分割區的Leader副本和Follower副本之間的切換,需要選舉Leader副本。
如何選舉?
如果某個分割區所在的伺服器除了問題,不可⽤,kafka會從該分割區的其他的副本中選擇⼀個作為新的Leader。之後所有的讀寫就會轉移到這個新的Leader上。現在的問題是應當選擇哪個作為新的Leader。
只有那些跟Leader保持同步的Follower才應該被選作新的Leader。
Kafka會在Zookeeper上針對每個Topic維護⼀個稱為ISR(in-sync replica,已同步的副本)的集合,該集合中是⼀些分割區的副本。
只有當這些副本都跟Leader中的副本同步了之後,kafka才會認為訊息已提交,並反饋給訊息的⽣產者。
如果這個集合有增減,kafka會更新zookeeper上的記錄。
如果某個分割區的Leader不可⽤,Kafka就會從ISR集合中選擇⼀個副本作為新的Leader。
顯然通過ISR,kafka需要的冗餘度較低,可以容忍的失敗數⽐較⾼。
假設某個topic有N+1個副本,kafka可以容忍N個伺服器不可⽤。
為什麼不⽤少數服從多數的⽅法
少數服從多數是⼀種⽐較常⻅的⼀致性算髮和Leader選舉法。
它的含義是隻有超過半數的副本同步了,系統才會認為資料已同步;
選擇Leader時也是從超過半數的同步的副本中選擇。
這種演演算法需要較⾼的冗餘度,跟Kafka⽐起來,浪費資源。
譬如只允許⼀臺機器失敗,需要有三個副本;⽽如果只容忍兩臺機器失敗,則需要五個副本。
⽽kafka的ISR集合⽅法,分別只需要兩個和三個副本。
如果所有的ISR副本都失敗了怎麼辦?
此時有兩種⽅法可選:
- 等待ISR集合中的副本復活,
- 選擇任何⼀個⽴即可⽤的副本,⽽這個副本不⼀定是在ISR集合中。
- 需要設定
unclean.leader.election.enable=true
- 需要設定
這兩種⽅法各有利弊,實際⽣產中按需選擇。
如果要等待ISR副本復活,雖然可以保證⼀致性,但可能需要很⻓時間。⽽如果選擇⽴即可⽤的副本,則很可能該副本並不⼀致。
總結:
Kafka中Leader分割區選舉,通過維護⼀個動態變化的ISR集合來實現,⼀旦Leader分割區丟掉,則從ISR中隨機挑選⼀個副本做新的Leader分割區。
如果ISR中的副本都丟失了,則:
- 可以等待ISR中的副本任何⼀個恢復,接著對外提供服務,需要時間等待。
- 從OSR中選出⼀個副本做Leader副本,此時會造成資料丟失
三、分割區重新分配
向已經部署好的Kafka叢集⾥⾯新增機器,我們需要從已經部署好的Kafka節點中複製相應的設定⽂件,然後把⾥⾯的broker id修改成全域性唯⼀的,最後啟動這個節點即可將它加⼊到現有Kafka叢集中。
問題:新新增的Kafka節點並不會⾃動地分配資料,⽆法分擔叢集的負載,除⾮我們新建⼀個topic。
需要⼿動將部分分割區移到新新增的Kafka節點上,Kafka內部提供了相關的⼯具來重新分佈某個topic的分割區。
在重新分佈topic分割區之前,我們先來看看現在topic的各個分割區的分佈位置:
建立主題:
[root@node1 ~]# kafka-topics.sh --zookeeper node1:2181/myKafka --create --topic tp_re_01 --partitions 5 --replication-factor 1
檢視主題資訊:
[root@node1 ~]# kafka-topics.sh --zookeeper node1:2181/myKafka --describe --topic tp_re_01
Topic:tp_re_01 PartitionCount:5 ReplicationFactor:1 Configs:
Topic: tp_re_01 Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic: tp_re_01 Partition: 1 Leader: 0 Replicas: 0 Isr: 0
Topic: tp_re_01 Partition: 2 Leader: 0 Replicas: 0 Isr: 0
Topic: tp_re_01 Partition: 3 Leader: 0 Replicas: 0 Isr: 0
Topic: tp_re_01 Partition: 4 Leader: 0 Replicas: 0 Isr: 0
在node11搭建Kafka:
安裝 JDK、Kafka,這裡不需要安裝Zookeeper
修改 Kafka 的設定config/server.properties
broker.id=1
zookeeper.connect=node1:2181/myKafka
啟動 kafka
[root@node11 ~]# kafka-server-start.sh /usr/src/kafka_2.12-1.0.2/config/server.properties
注意觀察node11上節點啟動的時候的ClusterId,看和zookeeper節點上的ClusterId是否⼀致,如果是,證明node11和node1在同⼀個叢集中。
node11啟動的Cluster ID:
zookeeper節點上的Cluster ID:

在node1上檢視zookeeper的節點資訊(node11的節點已經加⼊叢集了):

現在我們在現有叢集的基礎上再新增⼀個Kafka節點,然後使⽤Kafka⾃帶的kafka-reassign-partitions.sh ⼯具來重新分佈分割區。該⼯具有三種使⽤模式:
- generate模式,給定需要重新分配的Topic,⾃動⽣成reassign plan(並不執⾏)
- execute模式,根據指定的reassign plan重新分配Partition
- verify模式,驗證重新分配Partition是否成功
我們將分割區3和4重新分佈到broker1上,藉助kafka-reassign-partitions.sh⼯具⽣成reassign plan,不過我們先得按照要求定義⼀個⽂件,⾥⾯說明哪些topic需要重新分割區,⽂件內容如下
[root@node1 ~]# cat topics-to-move.json
{
"topics": [
{ "topic":"tp_re_01" }
],
"version":1
}
然後使⽤kafka-reassign-partitions.sh⼯具⽣成reassign plan

[root@node1 ~]# kafka-reassign-partitions.sh --zookeeper node1:2181/myKafka --topicsto-move-json-file topics-to-move.json --broker-list "0,1" --generate
Current partition replica assignment
{"version":1,"partitions":[{"topic":"tp_re_01","partition":4,"replicas":[0],"log_dirs":["any"]},{"topic":"tp_re_01","partition":1,"replicas":[0],"log_dirs":["any"]},{"topic":"tp_re_01","partition":2,"replicas":[0],"log_dirs":["any"]},{"topic":"tp_re_01","partition":3,"replicas":[0],"log_dirs":["any"]},{"topic":"tp_re_01","partition":0,"replicas":[0],"log_dirs":["any"]}]}
Proposed partition reassignment configuration
{"version":1,"partitions":[{"topic":"tp_re_01","partition":4,"replicas":[0],"log_dirs":["any"]},{"topic":"tp_re_01","partition":1,"replicas":[1],"log_dirs":["any"]},{"topic":"tp_re_01","partition":2,"replicas":[0],"log_dirs":["any"]},{"topic":"tp_re_01","partition":3,"replicas":[1],"log_dirs":["any"]},{"topic":"tp_re_01","partition":0,"replicas":[0],"log_dirs":["any"]}]}
Proposed partition reassignment configuration下⾯⽣成的就是將分割區重新分佈到broker 1上的結果。我們將這些內容儲存到名為result.json⽂件⾥⾯(⽂件名不重要,⽂件格式也不⼀定要以json為結尾,只要保證內容是json即可),然後執⾏這些reassign plan:

執⾏計劃:
[root@node1 ~]# kafka-reassign-partitions.sh --zookeeper node1:2181/myKafka --reassignment-json-file topics-to-execute.json --execute
Current partition replica assignment
{"version":1,"partitions":[{"topic":"tp_re_01","partition":4,"replicas":[0],"log_dirs":["any"]},{"topic":"tp_re_01","partition":1,"replicas":[0],"log_dirs":["any"]},{"topic":"tp_re_01","partition":2,"replicas":[0],"log_dirs":["any"]},{"topic":"tp_re_01","partition":3,"replicas":[0],"log_dirs":["any"]},{"topic":"tp_re_01","partition":0,"replicas":[0],"log_dirs":["any"]}]}
Save this to use as the --reassignment-json-file option during rollback
Successfully started reassignment of partitions.
這樣Kafka就在執⾏reassign plan,我們可以校驗reassign plan是否執⾏完成:
[root@node1 ~]# kafka-reassign-partitions.sh --zookeeper node1:2181/myKafka --reassignment-json-file topics-to-execute.json --verify
Status of partition reassignment:
Reassignment of partition tp_re_01-1 completed successfully
Reassignment of partition tp_re_01-4 completed successfully
Reassignment of partition tp_re_01-2 completed successfully
Reassignment of partition tp_re_01-3 completed successfully
Reassignment of partition tp_re_01-0 completed successfully
檢視主題的細節:
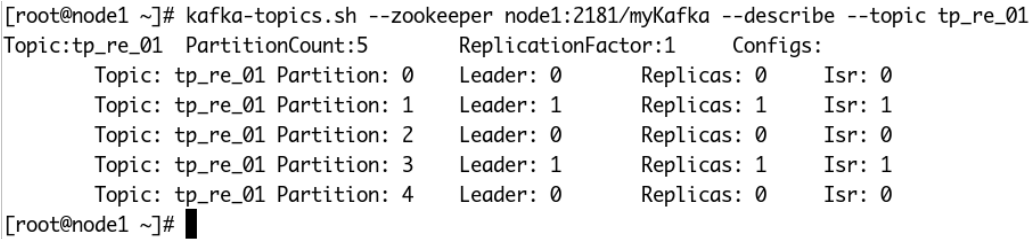
分割區的分佈的確和操作之前不⼀樣了,broker 1上已經有分割區分佈上去了。使⽤ kafka-reassign-partitions.sh⼯具⽣成的reassign plan只是⼀個建議,⽅便⼤家⽽已。其實我們⾃⼰完全可以編輯⼀個reassign plan,然後執⾏它,如下:
{
"version": 1,
"partitions": [{
"topic": "tp_re_01",
"partition": 4,
"replicas": [1],
"log_dirs": ["any"]
}, {
"topic": "tp_re_01",
"partition": 1,
"replicas": [0],
"log_dirs": ["any"]
}, {
"topic": "tp_re_01",
"partition": 2,
"replicas": [0],
"log_dirs": ["any"]
}, {
"topic": "tp_re_01",
"partition": 3,
"replicas": [1],
"log_dirs": ["any"]
}, {
"topic": "tp_re_01",
"partition": 0,
"replicas": [0],
"log_dirs": ["any"]
}]
}
將上⾯的json資料⽂件儲存到my-topics-to-execute.json⽂件中,然後也是執⾏它:
[root@node1 ~]# kafka-reassign-partitions.sh --zookeeper node1:2181/myKafka --reassignment-json-file my-topics-to-execute.json --execute
Current partition replica assignment
{"version":1,"partitions":[{"topic":"tp_re_01","partition":4,"replicas":[0],"log_dirs":["any"]},{"topic":"tp_re_01","partition":1,"replicas":[1],"log_dirs":["any"]},{"topic":"tp_re_01","partition":2,"replicas":[0],"log_dirs":["any"]},{"topic":"tp_re_01","partition":3,"replicas":[1],"log_dirs":["any"]},{"topic":"tp_re_01","partition":0,"replicas":[0],"log_dirs":["any"]}]}
Save this to use as the --reassignment-json-file option during rollback
Successfully started reassignment of partitions.
[root@node1 ~]# kafka-reassign-partitions.sh --zookeeper node1:2181/myKafka --reassignment-json-file my-topics-to-execute.json --verify
Status of partition reassignment:
Reassignment of partition tp_re_01-1 completed successfully
Reassignment of partition tp_re_01-4 completed successfully
Reassignment of partition tp_re_01-2 completed successfully
Reassignment of partition tp_re_01-3 completed successfully
Reassignment of partition tp_re_01-0 completed successfully
等這個reassign plan執⾏完,我們再來看看分割區的分佈:
[root@node1 ~]# kafka-topics.sh --zookeeper node1:2181/myKafka --describe --topic tp_re_01
Topic:tp_re_01 PartitionCount:5 ReplicationFactor:1 Configs:
Topic: tp_re_01 Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic: tp_re_01 Partition: 1 Leader: 0 Replicas: 0 Isr: 0
Topic: tp_re_01 Partition: 2 Leader: 0 Replicas: 0 Isr: 0
Topic: tp_re_01 Partition: 3 Leader: 1 Replicas: 1 Isr: 1
Topic: tp_re_01 Partition: 4 Leader: 1 Replicas: 1 Isr: 1
[root@node1 ~]#
四、自動再平衡
我們可以在新建主題的時候,⼿動指定主題各個Leader分割區以及Follower分割區的分配情況,即什麼分割區副本在哪個broker節點上。
隨著系統的運⾏,broker的宕機重啟,會引發Leader分割區和Follower分割區的⻆⾊轉換,最後可能Leader⼤部分都集中在少數⼏臺broker上,由於Leader負責使用者端的讀寫操作,此時集中Leader分割區的少數⼏臺伺服器的⽹絡I/O,CPU,以及記憶體都會很緊張。
Leader和Follower的⻆⾊轉換會引起Leader副本在叢集中分佈的不均衡,此時我們需要⼀種⼿段,讓Leader的分佈重新恢復到⼀個均衡的狀態。
執⾏指令碼:
[root@node11 ~]# kafka-topics.sh --zookeeper node1:2181/myKafka --create --topic tp_demo_03 --replica-assignment "0:1,1:0,0:1"
上述指令碼執⾏的結果是:建立了主題tp_demo_03,有三個分割區,每個分割區兩個副本,Leader副本在列表中第⼀個指定的brokerId上,Follower副本在隨後指定的brokerId上。

然後模擬broker0宕機的情況:
# 通過jps找到Kafka程序PID
[root@node1 ~]# jps
54912 Jps
1699 QuorumPeerMain
1965 Kafka
# 直接殺死程序
[root@node1 ~]# kill -9 1965
[root@node1 ~]# jps
1699 QuorumPeerMain
54936 Jps
[root@node1 ~]#
# 檢視主題分割區資訊:
[root@node1 ~]# kafka-topics.sh --zookeeper node1:2181/myKafka --describe --topic tp_demo_03
Topic:tp_demo_03 PartitionCount:3 ReplicationFactor:2 Configs:
Topic: tp_demo_03 Partition: 0 Leader: 1 Replicas: 0,1 Isr: 1
Topic: tp_demo_03 Partition: 1 Leader: 1 Replicas: 1,0 Isr: 1
Topic: tp_demo_03 Partition: 2 Leader: 1 Replicas: 0,1 Isr: 1
[root@node1 ~]#
# 重新啟動node1上的Kafka
[root@node1 ~]# kafka-server-start.sh -daemon /opt/kafka_2.12-1.0.2/config/server.properties
[root@node1 ~]# jps
1699 QuorumPeerMain
55525 Kafka
55557 Jps
[root@node1 ~]#
# 檢視主題的分割區資訊:
[root@node1 ~]# kafka-topics.sh --zookeeper node1:2181/myKafka --describe --topic tp_demo_03
Topic:tp_demo_03 PartitionCount:3 ReplicationFactor:2 Configs:
Topic: tp_demo_03 Partition: 0 Leader: 1 Replicas: 0,1 Isr: 1,0
Topic: tp_demo_03 Partition: 1 Leader: 1 Replicas: 1,0 Isr: 1,0
Topic: tp_demo_03 Partition: 2 Leader: 1 Replicas: 0,1 Isr: 1,0
[root@node1 ~]#
# broker恢復了,但是Leader的分配並沒有變化,還是處於Leader切換後的分配情況。
是否有⼀種⽅式,可以讓Kafka⾃動幫我們進⾏修改?改為初始的副本分配?
此時,⽤到了Kafka提供的⾃動再均衡指令碼:kafka-preferred-replica-election.sh
先看介紹:

該⼯具會讓每個分割區的Leader副本分配在合適的位置,讓Leader分割區和Follower分割區在伺服器之間均衡分配。
如果該指令碼僅指定zookeeper地址,則會對叢集中所有的主題進⾏操作,⾃動再平衡。
具體操作:
-
建立preferred-replica.json,內容如下:
{ "partitions": [ { "topic":"tp_demo_03", "partition":0 }, { "topic":"tp_demo_03", "partition":1 }, { "topic":"tp_demo_03", "partition":2 } ] } -
執⾏操作:
[root@node1 ~]# kafka-preferred-replica-election.sh --zookeeper node1:2181/myKafka --path-to-json-file preferred-replicas.json Created preferred replica election path with {"version":1,"partitions":[{"topic":"tp_demo_03","partition":0},{"topic":"tp_demo_03","partition":1},{"topic":"tp_demo_03","partition":2}]} Successfully started preferred replica election for partitions Set(tp_demo_03-0, tp_demo_03-1, tp_demo_03-2) [root@node1 ~]# -
檢視操作的結果
[root@node1 ~]# kafka-topics.sh --zookeeper node1:2181/myKafka --describe --topic tp_demo_03 Topic:tp_demo_03 PartitionCount:3 ReplicationFactor:2 Configs: Topic: tp_demo_03 Partition: 0 Leader: 0 Replicas: 0,1 Isr: 1,0 Topic: tp_demo_03 Partition: 1 Leader: 1 Replicas: 1,0 Isr: 1,0 Topic: tp_demo_03 Partition: 2 Leader: 0 Replicas: 0,1 Isr: 1,0 [root@node1 ~]#
恢復到最初的分配情況。
之所以是這樣的分配,是因為我們在建立主題的時候:
--replica-assignment "0:1,1:0,0:1"
在逗號分割的每個數值對中排在前⾯的是Leader分割區,後⾯的是副本分割區。那麼所謂的preferred replica,就是排在前⾯的數位就是Leader副本應該在的brokerId。
五、修改分割區副本
實際項⽬中,我們可能由於主題的副本因⼦設定的問題,需要重新設定副本因⼦
或者由於叢集的擴充套件,需要重新設定副本因⼦。
topic⼀旦使⽤⼜不能輕易刪除重建,因此動態增加副本因⼦就成為最終的選擇。
說明:kafka 1.0版本設定⽂件預設沒有default.replication.factor=x, 因此如果建立topic時,不指定–replication-factor 想, 預設副本因⼦為1. 我們可以在⾃⼰的server.properties中設定上常⽤的副本因⼦,省去⼿動調整。例如設定default.replication.factor=3, 詳細內容可參考官⽅⽂檔https://kafka.apache.org/documentation/#replication
原因分析:
假設我們有2個kafka broker分別broker0,broker1。
-
當我們建立的topic有2個分割區partition時並且replication-factor為1,基本上⼀個broker上⼀個分割區。當⼀個broker宕機了,該topic就⽆法使⽤了,因為兩個個分割區只有⼀個能⽤。
-
當我們建立的topic有3個分割區partition時並且replication-factor為2時,可能分割區資料分佈情況是
broker0, partiton0,partiton1,partiton2,
broker1, partiton1,partiton0,partiton2,
每個分割區有⼀個副本,當其中⼀個broker宕機了,kafka叢集還能完整湊出該topic的兩個分割區,例如當broker0宕機了,可以通過broker1組合出topic的兩個分割區。
-
建立主題
[root@node1 ~]# kafka-topics.sh --zookeeper node1:2181/myKafka --create --topic tp_re_02 --partitions 3 --replication-factor 1 -
檢視主題細節
[root@node1 ~]# kafka-topics.sh --zookeeper node1:2181/myKafka --describe --topic tp_re_02 Topic:tp_re_02 PartitionCount:3 ReplicationFactor:1 Configs: Topic: tp_re_02 Partition: 0 Leader: 1 Replicas: 1 Isr: 1 Topic: tp_re_02 Partition: 1 Leader: 0 Replicas: 0 Isr: 0 Topic: tp_re_02 Partition: 2 Leader: 1 Replicas: 1 Isr: 1 [root@node1 ~]# -
修改副本因⼦:錯誤

-
使⽤
kafka-reassign-partitions.sh修改副本因⼦:
建立increment-replication-factor.json{ "version":1, "partitions":[ {"topic":"tp_re_02","partition":0,"replicas":[0,1]}, {"topic":"tp_re_02","partition":1,"replicas":[0,1]}, {"topic":"tp_re_02","partition":2,"replicas":[1,0]} ] } -
執⾏分配
[root@node1 ~]# kafka-reassign-partitions.sh --zookeeper node1:2181/myKafka --reassignment-json-file increase-replication-factor.json --execute Current partition replica assignment {"version":1,"partitions":[{"topic":"tp_re_02","partition":2,"replicas":[1,0],"log_dirs":["any","any"]},{"topic":"tp_re_02","partition":1,"replicas":[0,1],"log_dirs":["any","any"]},{"topic":"tp_re_02","partition":0,"replicas":[0,1],"log_dirs":["any","any"]}]} Save this to use as the --reassignment-json-file option during rollbackSuccessfully started reassignment of partitions. -
檢視主題細節
[root@node1 ~]# kafka-topics.sh --zookeeper node1:2181/myKafka --describe --topic tp_re_02 Topic:tp_re_02 PartitionCount:3 ReplicationFactor:2 Configs: Topic: tp_re_02 Partition: 0 Leader: 1 Replicas: 0,1 Isr: 1,0 Topic: tp_re_02 Partition: 1 Leader: 0 Replicas: 0,1 Isr: 0,1 Topic: tp_re_02 Partition: 2 Leader: 1 Replicas: 1,0 Isr: 1,0 [root@node1 ~]#
六、分割區分配策略
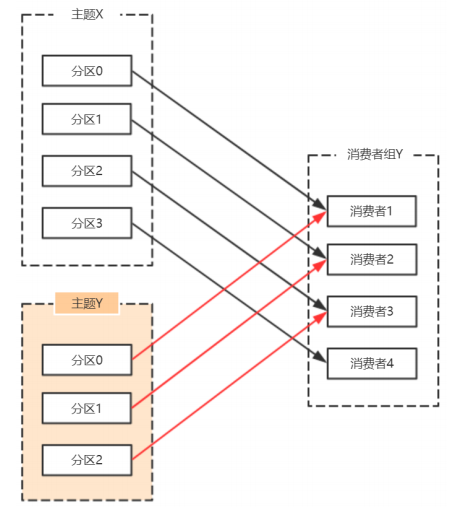
在Kafka中,每個Topic會包含多個分割區,預設情況下⼀個分割區只能被⼀個消費組下⾯的⼀個消費者消費,這⾥就產⽣了分割區分配的問題。Kafka中提供了多重分割區分配演演算法(PartitionAssignor)的實現:RangeAssignor、RoundRobinAssignor、StickyAssignor。
6.1 RangeAssignor
PartitionAssignor接⼝⽤於⽤戶定義實現分割區分配演演算法,以實現Consumer之間的分割區分配。
消費組的成員訂閱它們感興趣的Topic並將這種訂閱關係傳遞給作為訂閱組協調者的Broker。協調者選擇其中的⼀個消費者來執⾏這個消費組的分割區分配並將分配結果轉發給消費組內所有的消費者。Kafka預設採⽤RangeAssignor的分配演演算法。
RangeAssignor對每個Topic進⾏獨⽴的分割區分配。對於每⼀個Topic,⾸先對分割區按照分割區ID進⾏數值排序,然後訂閱這個Topic的消費組的消費者再進⾏字典排序,之後儘量均衡的將分割區分配給消費者。這⾥只能是儘量均衡,因為分割區數可能⽆法被消費者數量整除,那麼有⼀些消費者就會多分配到⼀些分割區。
⼤致演演算法如下:
assign(topic, consumers) {
// 對分割區和Consumer進⾏排序
List<Partition> partitions = topic.getPartitions();
sort(partitions);
sort(consumers);
// 計算每個Consumer分配的分割區數
int numPartitionsPerConsumer = partition.size() / consumers.size();
// 額外有⼀些Consumer會多分配到分割區
int consumersWithExtraPartition = partition.size() % consumers.size();
// 計算分配結果
for (int i = 0, n = consumers.size(); i < n; i++) {
// 第i個Consumer分配到的分割區的index
int start = numPartitionsPerConsumer * i + Math.min(i, consumersWithExtraPartition);
// 第i個Consumer分配到的分割區數
int length = numPartitionsPerConsumer + (i + 1 > consumersWithExtraPartition ? 0 : 1);
// 分裝分配結果
assignment.get(consumersForTopic.get(i)).addAll(partitions.subList(start, start + length));
}
}
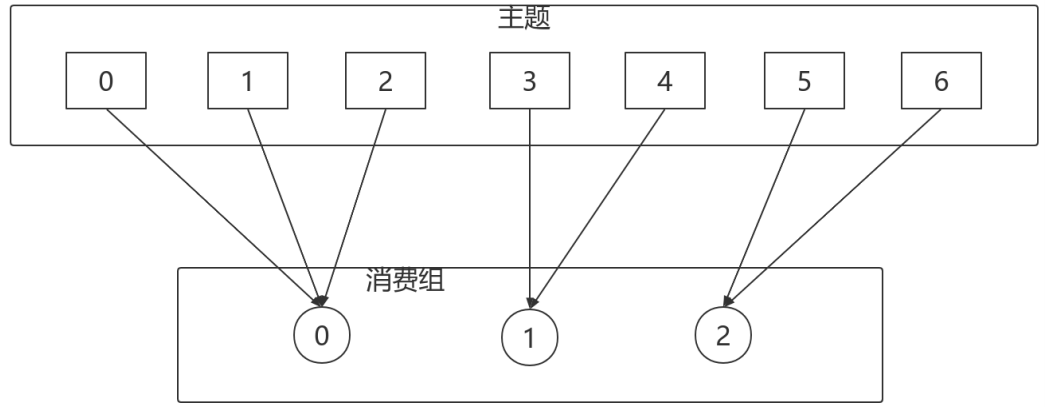
RangeAssignor策略的原理是按照消費者總數和分割區總數進⾏整除運算來獲得⼀個跨度,然後將分割區按照跨度進⾏平均分配,以保證分割區儘可能均勻地分配給所有的消費者。對於每⼀個Topic,RangeAssignor策略會將消費組內所有訂閱這個Topic的消費者按照名稱的字典序排序,然後為每個消費者劃分固定的分割區範圍,如果不夠平均分配,那麼字典序靠前的消費者會被多分配⼀個分割區。
這種分配⽅式明顯的⼀個問題是隨著消費者訂閱的Topic的數量的增加,不均衡的問題會越來越嚴重,⽐如上圖中4個分割區3個消費者的場景,C0會多分配⼀個分割區。如果此時再訂閱⼀個分割區數為4的Topic,那麼C0⼜會⽐C1、C2多分配⼀個分割區,這樣C0總共就⽐C1、C2多分配兩個分割區了,⽽且隨著Topic的增加,這個情況會越來越嚴重。
字典序靠前的消費組中的消費者⽐較「貪婪」。
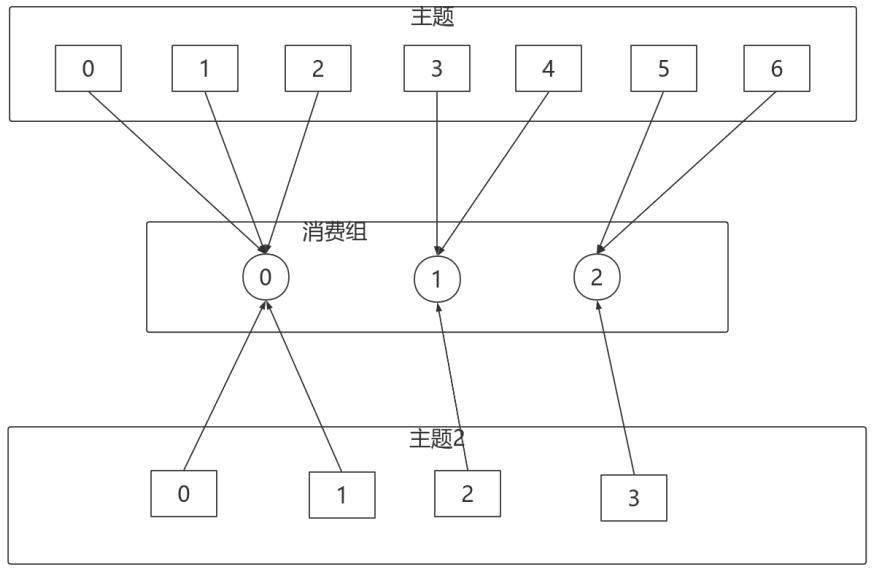
6.2 RoundRobinAssignor
RoundRobinAssignor的分配策略是將消費組內訂閱的所有Topic的分割區及所有消費者進⾏排序後儘量均衡的分配(RangeAssignor是針對單個Topic的分割區進⾏排序分配的)。如果消費組內,消費者訂閱的Topic列表是相同的(每個消費者都訂閱了相同的Topic),那麼分配結果是儘量均衡的(消費者之間分配到的分割區數的差值不會超過1)。如果訂閱的Topic列表是不同的,那麼分配結果是不保證「儘量均衡」的,因為某些消費者不參與⼀些Topic的分配。
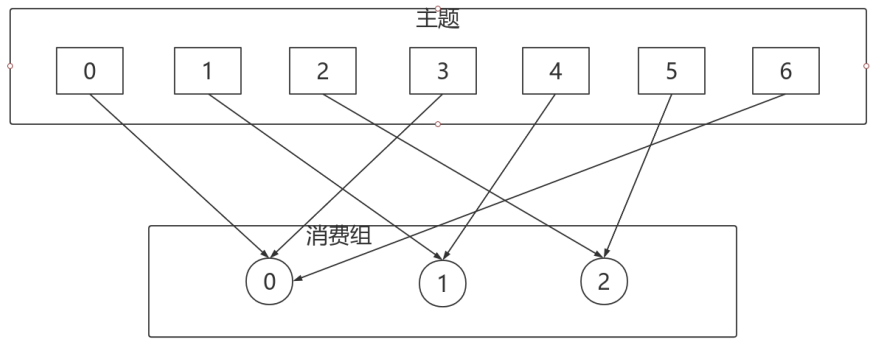
相對於RangeAssignor,在訂閱多個Topic的情況下,RoundRobinAssignor的⽅式能消費者之間儘量均衡的分配到分割區(分配到的分割區數的差值不會超過1——RangeAssignor的分配策略可能隨著訂閱的Topic越來越多,差值越來越⼤)。
對於消費組內消費者訂閱Topic不⼀致的情況:假設有兩個個消費者分別為C0和C1,有2個Topic T1、T2,分別擁有3和2個分割區,並且C0訂閱T1和T2,C1訂閱T2,那麼RoundRobinAssignor的分配結果如下:
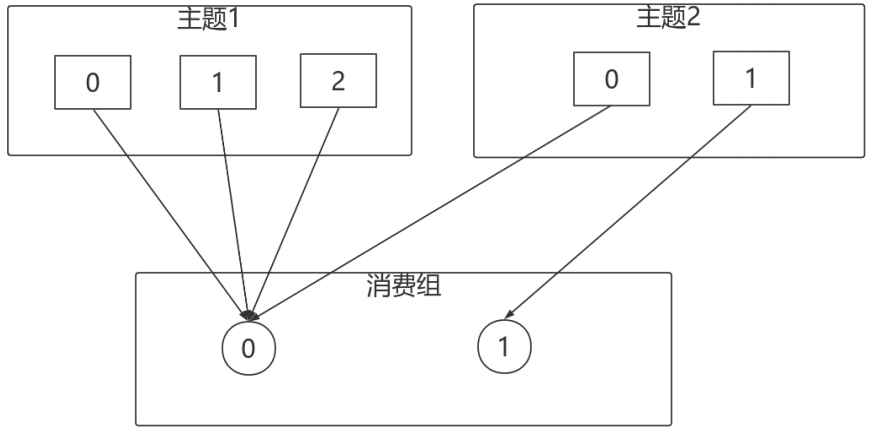
看上去分配已經儘量的保證均衡了,不過可以發現C0承擔了4個分割區的消費⽽C1訂閱了T2⼀個分割區,是不是把T2P0交給C1消費能更加的均衡呢?
6.3 StickyAssignor
動機
儘管RoundRobinAssignor已經在RangeAssignor上做了⼀些優化來更均衡的分配分割區,但是在⼀些情況下依舊會產⽣嚴重的分配偏差,⽐如消費組中訂閱的Topic列表不相同的情況下。
更核⼼的問題是⽆論是RangeAssignor,還是RoundRobinAssignor,當前的分割區分配演演算法都沒有考慮上⼀次的分配結果。顯然,在執⾏⼀次新的分配之前,如果能考慮到上⼀次分配的結果,儘量少的調整分割區分配的變動,顯然是能節省很多開銷的。
目標
從字⾯意義上看,Sticky是「粘性的」,可以理解為分配結果是帶「粘性的」:
- 分割區的分配儘量的均衡
- 每⼀次重分配的結果儘量與上⼀次分配結果保持⼀致
當這兩個⽬標發⽣衝突時,優先保證第⼀個⽬標。第⼀個⽬標是每個分配演演算法都儘量嘗試去完成的,⽽第⼆個⽬標才真正體現出StickyAssignor特性的。
我們先來看預期分配的結構,後續再具體分析StickyAssignor的演演算法實現。
例如:
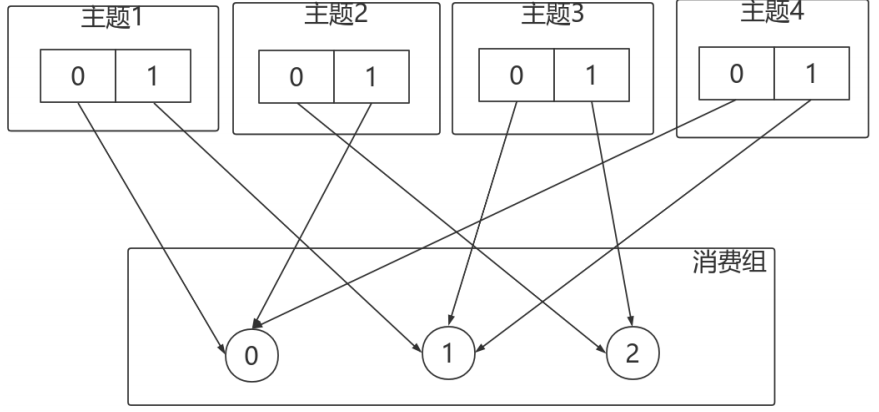
- 有3個Consumer:C0、C1、C2
- 有4個Topic:T0、T1、T2、T3,每個Topic有2個分割區
- 所有Consumer都訂閱了這4個分割區
StickyAssignor的分配結果如下圖所示(增加RoundRobinAssignor分配作為對⽐):
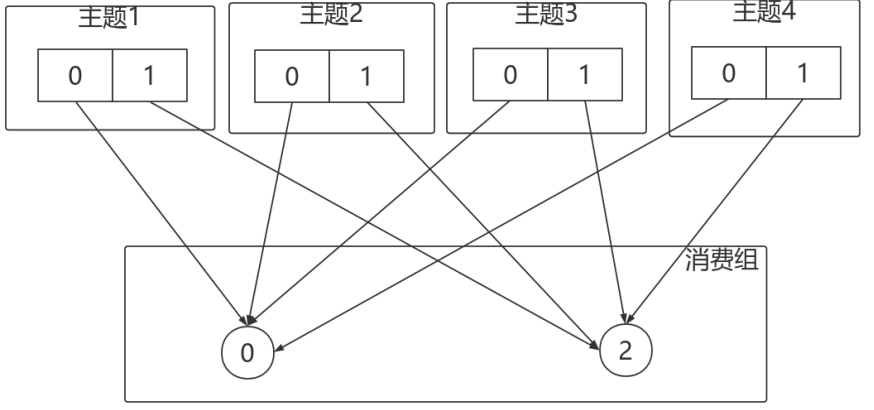
如果消費者1宕機,則按照RoundRobin的⽅式分配結果如下。打亂從新來過,輪詢分配:
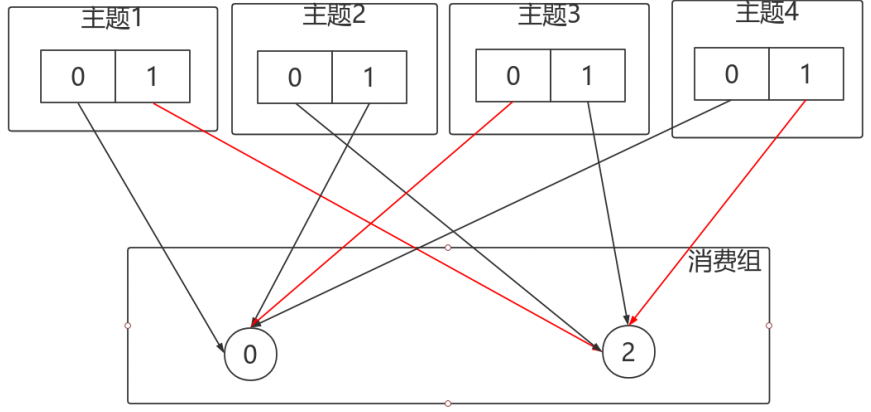
按照Sticky的⽅式。僅對消費者1分配的分割區進⾏重分配,紅線部分。最終達到均衡的⽬的:
再舉⼀個例⼦:
- 有3個Consumer:C0、C1、C2
- 3個Topic:T0、T1、T2,它們分別有1、2、3個分割區
- C0訂閱T0;C1訂閱T0、T1;C2訂閱T0、T1、T2
分配結果如下圖所示:
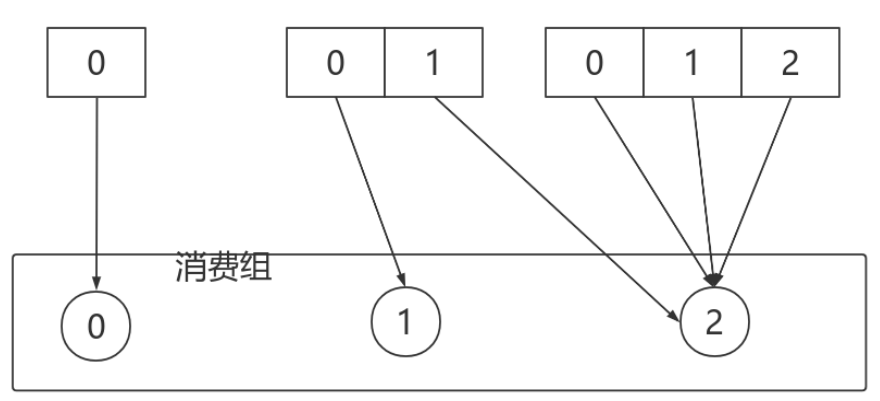
消費者0下線,則按照輪詢的⽅式分配:
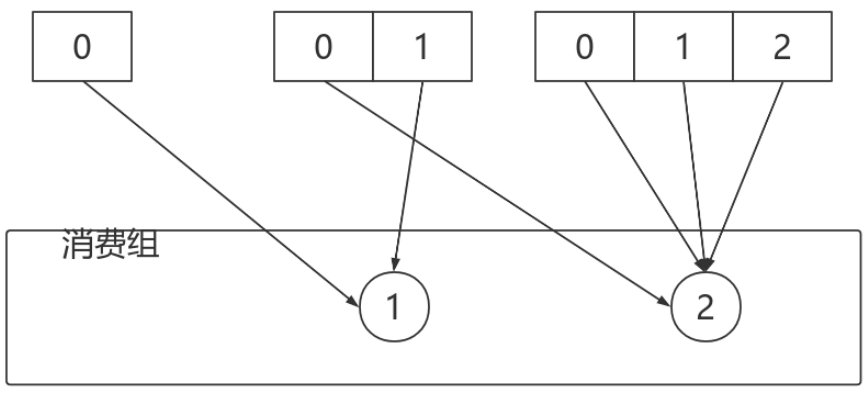
按照Sticky⽅式分配分割區,僅僅需要動的就是紅線部分,其他部分不動。
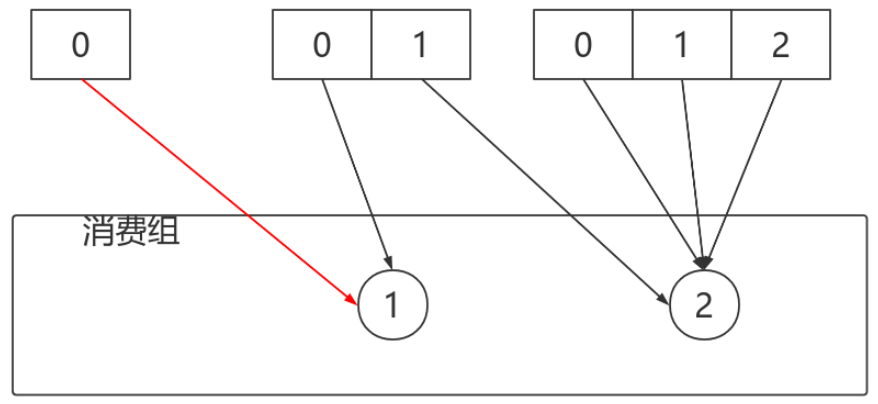
StickyAssignor分配⽅式的實現稍微複雜點⼉,我們可以先理解圖示部分即可。感興趣的同學可以研究⼀下。
6.4 自定義分割區策略
⾃定義的分配策略必須要實現org.apache.kafka.clients.consumer.internals.PartitionAssignor接⼝。PartitionAssignor接⼝的定義如下:
Subscription subscription(Set<String> topics);
String name();
Map<String, Assignment> assign(Cluster metadata, Map<String, Subscription> subscriptions);
void onAssignment(Assignment assignment);
class Subscription {
private final List<String> topics;
private final ByteBuffer userData;
}
class Assignment {
private final List<TopicPartition> partitions;
private final ByteBuffer userData;
}
PartitionAssignor接⼝中定義了兩個內部類:Subscription和Assignment。
Subscription類⽤來表示消費者的訂閱資訊,類中有兩個屬性:topics和userData,分別表示消費者所訂閱topic列表和⽤戶⾃定義資訊。PartitionAssignor接⼝通過subscription()⽅法來設定消費者⾃身相關的Subscription資訊,注意到此⽅法中只有⼀個引數topics,與Subscription類中的topics的相互呼應,但是並沒有有關userData的引數體現。為了增強⽤戶對分配結果的控制,可以在subscription()⽅法內部新增⼀些影響分配的⽤戶⾃定義資訊賦予userData,⽐如:權重、ip地址、host或者機架(rack)等等。
再來說⼀下Assignment類,它是⽤來表示分配結果資訊的,類中也有兩個屬性:partitions和userData,分別表示所分配到的分割區集合和⽤戶⾃定義的資料。可以通過PartitionAssignor接⼝中的onAssignment()⽅法是在每個消費者收到消費組leader分配結果時的回撥函數,例如在StickyAssignor策略中就是通過這個⽅法儲存當前的分配⽅案,以備在下次消費組再平衡(rebalance)時可以提供分配參考依據。
接⼝中的name()⽅法⽤來提供分配策略的名稱,對於Kafka提供的3種分配策略⽽⾔,RangeAssignor對應的protocol_name為「range」,RoundRobinAssignor對應的protocol_name為「roundrobin」,StickyAssignor對應的protocol_name為「sticky」,所以⾃定義的分配策略中要注意命名的時候不要與已存在的分配策略發⽣衝突。這個命名⽤來標識分配策略的名稱,在後⾯所描述的加⼊消費組以及選舉消費組leader的時候會有涉及。
真正的分割區分配⽅案的實現是在assign()⽅法中,⽅法中的引數metadata表示叢集的後設資料資訊,⽽subscriptions表示消費組內各個消費者成員的訂閱資訊,最終⽅法返回各個消費者的分配資訊。
Kafka中還提供了⼀個抽象類org.apache.kafka.clients.consumer.internals.AbstractPartitionAssignor,它可以簡化PartitionAssignor接⼝的實現,對assign()⽅法進⾏了實現,其中會將Subscription中的userData資訊去掉後,在進⾏分配。Kafka提供的3種分配策略都是繼承⾃這個抽象類。如果開發⼈員在⾃定義分割區分配策略時需要使⽤userData資訊來控制分割區分配的結果,那麼就不能直接繼承AbstractPartitionAssignor這個抽象類,⽽需要直接實現PartitionAssignor接⼝。
自定義分割區策略
package org.apache.kafka.clients.consumer;
import org.apache.kafka.clients.consumer.internals.AbstractPartitionAssignor;
import org.apache.kafka.common.TopicPartition;
import java.util.*;
public class MyAssignor extends AbstractPartitionAssignor {
}
在使⽤時,消費者使用者端需要新增相應的Properties引數,範例如下:
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, MyAssignor.class.getName());