ClickHouse(01)什麼是ClickHouse,ClickHouse適用於什麼場景
ClickHouse的由來
ClickHouse是什麼資料庫?ClickHouse速度有多快?應用場景是怎麼樣的?ClickHouse是關係型資料庫嗎?ClickHouse目前是很火爆的一款面向OLAP的資料,可以提供秒級的巨量資料查詢。
Google於2003~2006年相繼發表了三篇論文「Google File System」「Google MapReduce」和「Google Bigtable」,將巨量資料的處理技術帶進了大眾視野。2006年開源專案Hadoop的出現,標誌著巨量資料技術普及的開始,巨量資料技術真正開始走向普羅大眾。長期以來受限於資料庫處理能力的巨量資料技術,開始了波瀾壯闊的技術革新浪潮席捲而來。Hadoop最初指代的是分散式檔案系統HDFS和MapReduce計算框架,但是它一路高歌猛進,在此基礎之上像搭積木一般快速發展成為一個龐大的生態,包括Yarn、Hive、HBase、Spark等數十種之多元件相繼開源。Hadoop全家桶很快成為了主流。傳統關係型資料庫所構建的資料倉儲,被以Hive為代表的巨量資料技術所取代,資料查詢分析的查詢計算引擎Spark、Impala、Kylin等都出來了。Hadoop成為巨量資料的代名詞。
Hadoop雖然帶來了諸多便利性,隨著時代的發展,但是也帶來了一些新的問題。
- Hadoop生態化的兩面性:臃腫和複雜。Hadoop生態下的每種元件都自成一體、相互獨立,強強組合的技術元件有些時候顯得過於笨重了。
- 隨著現代化終端系統對實效性的要求越來越高,Hadoop在海量資料和高時效性的雙重壓力下,速度有點更不上了。
當然這是hadoop生態的確定,但是目前最普及的方案還是hadoop莫屬,但是hadoop生態在巨量資料量的查詢和元件的笨重確實存在,在日常的資料開發中,資料分析,BI等都需要查詢資料,目前的hadoop查詢引擎提供的查詢速度,相對於ClickHouse,會慢很多。
所以,這款非Hadoop生態、簡單、自成一體的技術元件ClickHouse橫空出世。
ClickHouse背後的研發團隊是一家俄羅斯本土的網際網路企業Yandex公司,2011年在納斯達克上市,它是現今世界上最大的俄語搜尋引擎,佔據了本國47%以上的搜尋市場,Google是它的直接競爭對手。 ClickHouse的前身是一款線上流量分析的產品Yandex.Metrica,類似Google Analytics,隨著Yandex.Metrica業務的發展,其底層架構歷經四個階段,最終形成了大家現在所看到的ClickHouse。
ClickHouse的定義及其優缺點
ClickHouse是一款高效能、MPP架構、列式儲存、具有完備DBMS功能的OLAP資料庫。
ClickHouse可以在儲存資料超過20萬億行的情況下,做到了90%的查詢能夠在1秒內返回。它基本能夠滿足各種資料分析類的場景,並且隨著資料體量的增大,它與Spark、Impala、Kylin對比,優勢也會變得越為明顯。
ClickHouse適用於商業智慧領域(BI),也能夠被廣泛應用於廣告流量、Web、App流量、電信、金融、電子商務、資訊保安、網路遊戲、物聯網等眾多其他領域。應該說它適合的場景,就是OLAP。
ClickHouse不是萬能的。它對於OLTP事務性操作的場景支援有限,它有以下幾點不足。
- 不支援事務。
- 不擅長根據主鍵按行粒度進行查詢(雖然支援),故不應該把ClickHouse當作Key-Value資料庫使用。
- 不擅長按行刪除資料(雖然支援)。
這些弱點並不能視為ClickHouse的缺點,事實上其他同類高效能的OLAP資料庫同樣也不擅長上述的這些方面。因為對於一款OLAP資料庫而言,上述這些能力並不是重點,只能說這是為了極致查詢效能所做的權衡。
ClickHouse為何這麼快的原因
前面我們說了ClickHouse以在儲存資料超過20萬億行的情況下,在1秒內返回查詢,那它是怎麼做到的?主要有下面的原因。
-
列式儲存與資料壓縮
列式儲存和資料壓縮,對於一款高效能資料庫來說是必不可少的。如果你想讓查詢變得更快,那麼最簡單且有效的方法是減少資料掃描範圍和資料傳輸時的大小,列式儲存和資料壓縮就可以做到這兩點。 -
向量化執行
能升級硬體解決的問題,千萬別優化程式。能用錢解決的問題,那都不是問題。
向量化執行,可以簡單地看作一項消除程式中迴圈的優化,是基於底層硬體實現的優化。這裡用一個形象的例子比喻。小胡經營了一家果汁店,雖然店裡的鮮榨蘋果汁深受大家喜愛,但客戶總是抱怨製作果汁的速度太慢。小胡的店裡只有一臺榨汁機,每次他都會從籃子裡拿出一個蘋果,放到榨汁機內等待出汁。如果有8個客戶,每個客戶都點了一杯蘋果汁,那麼小胡需要重複迴圈8次上述的榨汁流程,才能榨出8杯蘋果汁。如果製作一杯果汁需要5分鐘,那麼全部製作完畢則需要40分鐘。為了提升果汁的製作速度,小胡想出了一個辦法。他將榨汁機的數量從1臺增加到了8臺,這麼一來,他就可以從籃子裡一次性拿出8個蘋果,分別放入8臺榨汁機同時榨汁。此時,小胡只需要5分鐘就能夠製作出8杯蘋果汁。為了製作n杯果汁,非向量化執行的方式是用1臺榨汁機重複迴圈製作n次,而向量化執行的方式是用n臺榨汁機只執行1次。
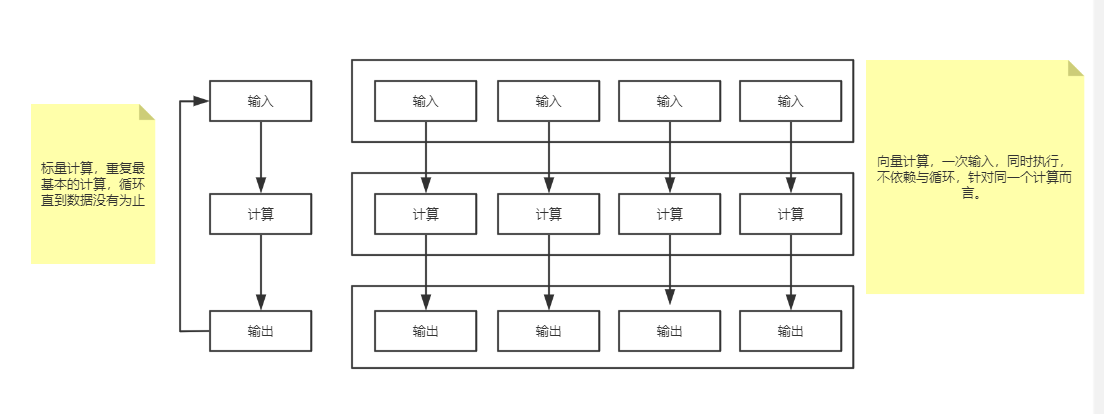
上圖中,右側為vectorization(向量化計算),左側為經典的標量計算。將多次for迴圈計算變成一次計算完全仰仗於CPU的SIMD指令集,SIMD指令可以在一條cpu指令上處理2、4、8或者更多份的資料。在Intel處理器上,這個稱之為SSE以及後來的AVX;在ARM處理器上,這個稱之為NEON。
因此簡單來說,向量化計算就是將一個loop——處理一個array的時候每次處理1個資料共處理N次,轉化為vectorization——處理一個array的時候每次同時處理8個資料共處理N/4次,假如cpu指令上可以處理更多份的資料,設為M,那就是N/M次。
為了實現向量化執行,需要利用CPU的SIMD指令。SIMD的全稱是Single Instruction Multiple Data,即用單條指令操作多條資料。現代計算機系統概念中,它是通過資料並行以提高效能的一種實現方式,它的原理是在CPU暫存器層面實現資料的並行操作。ClickHouse目前利用SSE4.2指令集實現向量化執行。
-
多樣化的表引擎
與MySQL類似,ClickHouse也將儲存部分進行了抽象,把儲存引擎作為一層獨立的介面。目前ClickHouse共擁有合併樹、記憶體、檔案、介面和其他6大類20多種表引擎。每一種表引擎都有著各自的特點,使用者可以根據實際業務場景的要求,選擇合適的表引擎使用。 -
多執行緒與分散式
多執行緒處理就是通過執行緒級並行的方式實現了效能的提升,ClickHouse將資料劃分為多個partition,每個partition再進一步劃分為多個index granularity,然後通過多個CPU核心分別處理其中的一部分來實現並行資料處理。這種設計下,可以使得ClickHouse單條Query就能利用整機所有CPU,極致的並行處理能力,極大的降低了查詢延時。
而分散式資料屬於基於分而治之的基本思想,實現的優化,如果一臺伺服器效能吃緊,那麼就利用多臺服務的資源協同處理。這個前提是需要在資料層面實現資料的分散式,因為計算移動比資料移動更加划算,在各伺服器之間,通過網路傳輸資料的成本是高昂的,所以預先將資料分佈到各臺伺服器,將資料的計算查詢直接下推到資料所在的伺服器。
ClickHouse相關資料分享
如果還想了解更多關於ClickHouse,可以看看這個檔案,也可以看看ClickHouse官方網站的檔案
本文來自部落格園,作者:張飛的豬,轉載請註明原文連結:https://www.cnblogs.com/the-pig-of-zf/p/16328854.html