揭祕華為雲GaussDB(for Influx)最佳實踐:hint查詢
摘要:GaussDB(for Influx)通過提供hint功能,在單時間線的查詢場景下,效能有大幅度的提升,能有效滿足客戶某些特定場景的查詢需求。
本文分享自華為雲社群《華為雲GaussDB(for Influx)揭祕第十期:最佳實踐之hint查詢》,作者:高斯Influx官方部落格。
「怎麼感覺查詢越來越慢了?」隨著業務資料量的不斷增大,很多客戶都反饋同樣的查詢語句變得越來越慢。接到客戶的反饋後,我們分析了客戶的查詢執行各個階段的耗時,發現隨著資料量的增加,耗在倒排索引階段的時間越來越長,那麼倒排索引到底是幹什麼用的呢?能不能跳過倒排索引呢?
倒排索引,顧名思義,是一種索引結構,該索引避免了多維查詢時進行大量的資料掃描。其本身就是用於提高查詢效能的,顯然不能簡單地跳過倒排索引。但是隨著資料量的不斷增大,確實引起了查詢的時延變大。那麼倒排索引的原理是什麼?適合於哪種業務場景?有沒有可能跳過倒排索引,來進一步降低查詢時延呢?本文基於GaussDB(for Influx)的實現,給您一一解答上述問題。
1. 為什麼要使用倒排索引?
用以下資料作為範例進行說明,其中
Tag:region,service,host;
Field:cpu,mem;
資料來源(SeriesKey):region+service+host;
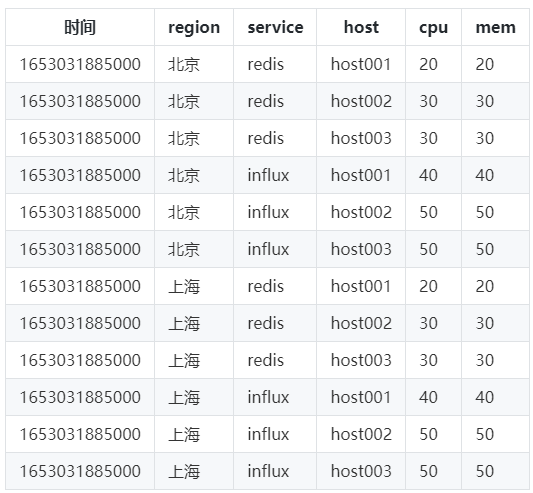
一般涉及的查詢有兩種:
1)要查詢某個資料來源在某個時間點的cpu使用情況,例如:
select max(cpu) from mst where region=’北京’ and service=’influx’ and host=’host001’ and time>now()-30s
所有的tag都指定了相應的值。
2)給定部分維度,查詢某些資訊:例如要查詢北京(region)的Influx(service)服務的cpu使用情況:
select max(cpu) from mst where region=’北京’ and service=’influx’ and time>now()-30s
只指定了部分tag值。
對於第一種查詢方案,可以直接根據tag值來確定資料來源,但是對於第二種場景,查詢沒有直接給出具體的資料來源,僅指定了兩個維度(region和service)以及查詢的指標cpu,這種查詢就需要根據部分維度組合(region=北京,service=influx)找到所有對應的資料來源,例如在資料中北京的Influx服務有3臺主機(host001, host002, host003),就需要查詢到這3臺主機資料來源,這就需要倒排索引,否則就需要進行大量的資料掃描。
有了倒排索引,Influx的查詢能力得到了很大的提升,但是隨著資料量的不斷增長,消耗在倒排索引的時間也越來越長;倒排索引的作用就是通過部分維度來找到對應所有的資料來源,那麼如果我們可以通過其他方式更快地找到資料來源,就可以跳過倒排索引了。資料來源是由tag set的value組成的,即由region,service,host三個tag的值組成,例如region=「北京」,service=「influx」,host=「host001」三個tag值就組成一個資料來源。那麼當業務要查詢的查詢裡帶了所有tag的值時,我們就可以根據查詢語句來確定資料來源,例如:
select max(cpu) from mst where region=’北京’ and service=’influx’ and host=’host001’ and time>now()-30s
該語句查詢過去30s內北京region,Influx服務,host001主機的CPU的最大值。上面的查詢帶了需要確定資料來源的所有tag的值,因此我們在這種查詢中就可以跳過倒排索引的階段,類似的查詢我們也叫做單時間線查詢。
2. GaussDB(for Influx)的實現方案
上一章節講到,如果業務的查詢是單時間線查詢,我們就可以根據查詢語句來確認資料來源,而不用再去倒排索引中找。基於這個思路,GaussDB(for Influx)實現了hint特性,hint特性允許客戶指定查詢跳過倒排索引模組,直接去查詢資料,從而進一步提高查詢效能。
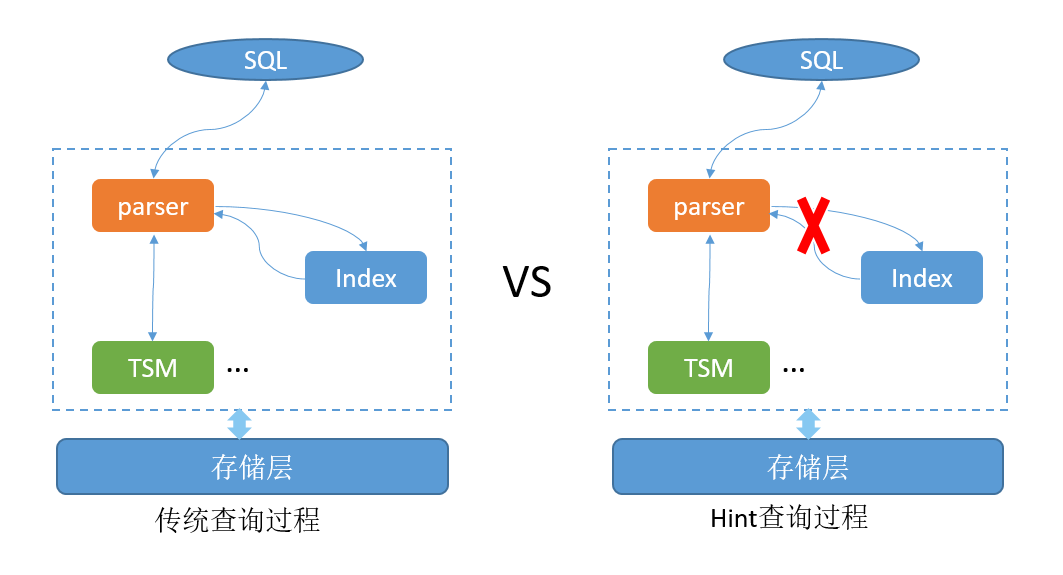
GaussDB(for Influx)通過定義特殊的hint語法來識別查詢語句是否走倒排索引,系統解析業務查詢語句時,如果識別到查詢帶有hint語法,就會跳過倒排索引查詢的步驟,直接根據查詢語句中tagset資訊,找到資料來源,去儲存層查詢對應的資料,其邏輯對比如下圖:
3. Hint查詢的效能
針對單時間線查詢的場景下,我們測試了使用hint功能和不適用hint功能之間的效能。
測試條件為:300萬時間線,單時間線查詢;執行查詢1000次取平均時延。下圖為hint查詢和非hint查詢的測試結果對比:
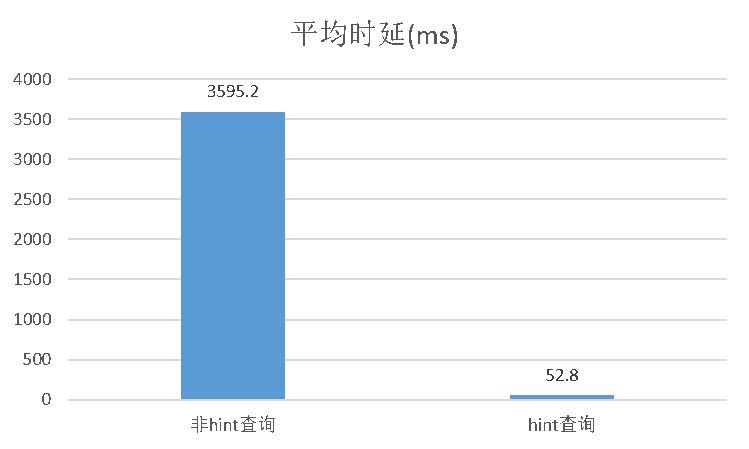
從圖中可以看出,在相同的查詢語句和測試環境下,hint查詢時延明顯優於非hint查詢。
4. Hint查詢的使用
使用hint查詢的方法也很簡單,業務只需要少量的改動即可,在查詢時新增hint查詢標識/*+ full_series */。例如,常規查詢語句為:
select max(cpu) from mst where region=’北京’ and service=’influx’ and host=’host001’ and time>now()-30s
改為用hint的方式,查詢語句為:
select /*+ full_series */ max(cpu) from mst where region=’北京’ and service=’influx’ and host=’host001’ and time>now()-30s
在使用hint方式查詢時,一定要確定是單時間線的查詢,否則可能會出現查不出來資料的問題。
5. 總結
GaussDB(for Influx)通過提供hint功能,在單時間線的查詢場景下,效能有大幅度的提升,能有效滿足客戶某些特定場景的查詢需求。
除了以上優勢外,GaussDB(for Influx)還在叢集化、冷熱分級儲存、高可用方面也做了深度優化,能更好地滿足時序應用的各種場景。
6. 結束
本文作者:華為 雲資料庫創新Lab & 華為雲時空資料庫團隊
更多技術文章,關注GaussDB(for Influx)官方部落格:
https://bbs.huaweicloud.com/community/usersnew/id_1586596796288328
Lab官網:https://www.huaweicloud.com/lab/clouddb/home.html
產品首頁:https://www.huaweicloud.com/product/gaussdbforinflux.html
華為夥伴暨開發者大會2022火熱來襲,重磅內容不容錯過!
【精彩活動】
勇往直前·做全能開發者→12場技術直播前瞻,8大技術寶典高能輸出,還有程式碼密室、知識競賽等多輪神祕任務等你來挑戰。即刻闖關,開啟終極大獎!點選踏上全能開發者晉級之路吧!
【技術專題】
未來已來,2022技術探祕→華為各領域的前沿技術、重磅開源專案、創新的應用實踐,站在智慧世界的入口,探索未來如何照進現實,乾貨滿滿點選瞭解