SpringBoot+Mybatis-Plus整合Sharding-JDBC5.1.1實現單庫分表【全網最新】
一、前言
小編最近一直在研究關於分庫分表的東西,前幾天docker安裝了mycat實現了分庫分表,但是都在說mycat的bug很多。很多人還是傾向於shardingsphere,其實他是一個全家桶,有JDBC、Proxy 和 Sidecar組成,小編今天以最簡單的JDBC來簡單整合一下!
現在最新版已經是5.1.1,經過一天的研究用於解決了所有問題,完成了單庫分表!!
想了解4.0.0版本的可以看一下小編剛剛寫的:SpringBoot+Mybatis-Plus整合Sharding-JDBC4.0.0實現單庫分表
如果想看mycat的可以看一下小編之前寫的文章哈:Docker安裝Mycat和Mysql進行水平分庫分表實戰
二、踩過的坑
1. 資料來源問題
不要使用druid-spring-boot-starter這個依賴,啟動會有問題
<dependency>-->
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.21</version>
/dependency>
報錯資訊:
Caused by: org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'userMapper' defined in file
[D:\jiawayun\demo\target\classes\com\example\demo\mapper\UserMapper.class]:
Invocation of init method failed; nested exception is
java.lang.IllegalArgumentException: Property 'sqlSessionFactory'
or 'sqlSessionTemplate' are required
解決方案:
使用單獨的druid
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.8</version>
</dependency>
建議使用預設的資料來源,sharding-jdbc也是使用的預設的資料來源,小編使用的自帶的,忘記druid後面會不會有問題了!!
type: com.zaxxer.hikari.HikariDataSource
2. Insert 語句不支援分表路由到多個資料節點
報錯資訊:
Insert statement does not support sharding table routing to multiple data nodes.
解決方案:
看小編文章:解決不支援分表路由問題
三、匯入maven依賴
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.1.1</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.10</version>
</dependency>
<!--jdbc-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<!-- mysql -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<!-- mybatis-plus -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.1</version>
</dependency>
四、新建表
1. 新建二張表
命名為:user_0、user_1
CREATE TABLE `user_0` (
`cid` bigint(25) NOT NULL,
`name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`gender` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`data` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`cid`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
SET FOREIGN_KEY_CHECKS = 1;
2. 資料庫結構
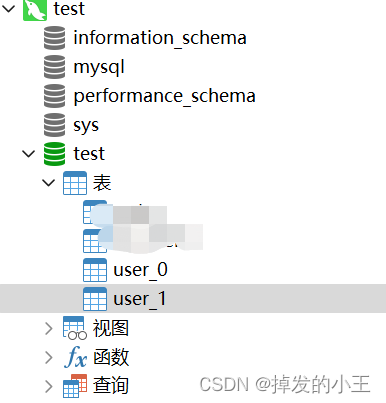
五、框架全域性展示
1. User實體類
@Data
public class User implements Serializable {
private static final long serialVersionUID = 337361630075002456L;
private Long cid;
private String name;
private String gender;
private String data;
}
2. controller
@RestController
@RequestMapping("/test")
public class UserController {
@Autowired
private UserMapper userMapper;
@GetMapping("/insertTest")
public void insertTest(){
for (int i = 1 ; i < 10; i++) {
User test = new User("王"+i,"男","資料" + i);
userMapper.insert(test);
}
}
}
3. mapper
我們直接省略了service,簡單一下哈!!
public interface UserMapper extends BaseMapper<User> {
}
4. application.yml設定
server:
port: 8089
spring:
shardingsphere:
mode:
type: memory
# 是否開啟
datasource:
# 資料來源(邏輯名字)
names: m1
# 設定資料來源
m1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/test?useSSL=false&autoReconnect=true&characterEncoding=UTF-8&serverTimezone=UTC
username: root
password: root
# 分片的設定
rules:
sharding:
# 表的分片策略
tables:
# 邏輯表的名稱
user:
# 資料節點設定,採用Groovy表示式
actual-data-nodes: m1.user_$->{0..1}
# 設定策略
table-strategy:
# 用於單分片鍵的標準分片場景
standard:
sharding-column: cid
# 分片演演算法名字
sharding-algorithm-name: user_inline
key-generate-strategy: # 主鍵生成策略
column: cid # 主鍵列
key-generator-name: snowflake # 策略演演算法名稱(推薦使用雪花演演算法)
key-generators:
snowflake:
type: SNOWFLAKE
sharding-algorithms:
user_inline:
type: inline
props:
algorithm-expression: user_$->{cid % 2}
props:
# 紀錄檔顯示具體的SQL
sql-show: true
logging:
level:
com.wang.test.demo: DEBUG
mybatis-plus:
mapper-locations: classpath:mapper/*.xml
type-aliases-package: com.example.demo.entity
configuration:
#在對映實體或者屬性時,將資料庫中表名和欄位名中的下劃線去掉,按照駝峰命名法對映 address_book ---> addressBook
map-underscore-to-camel-case: true
5. 啟動類
@MapperScan("com.example.demo.mapper")
@SpringBootApplication
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}
六、測試插入九條資料
本次測試策略是:行表示式分片策略:inline
1. 插入資料
輸入 :localhost:8089/test/insertTest
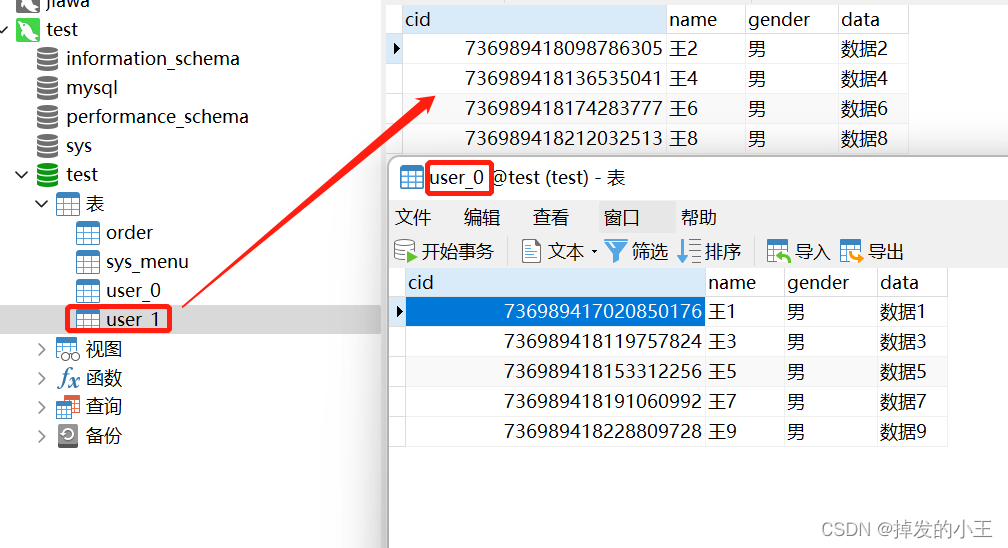
分片成功
2. 單個查詢
@GetMapping("/selectOneTest")
public void selectOneTest(){
User user = userMapper.selectOne(Wrappers.<User>lambdaQuery().eq(User::getCid,736989417020850176L));
System.out.println(user);
}
這時他會根據cid去自動獲取去那個表中獲取資料
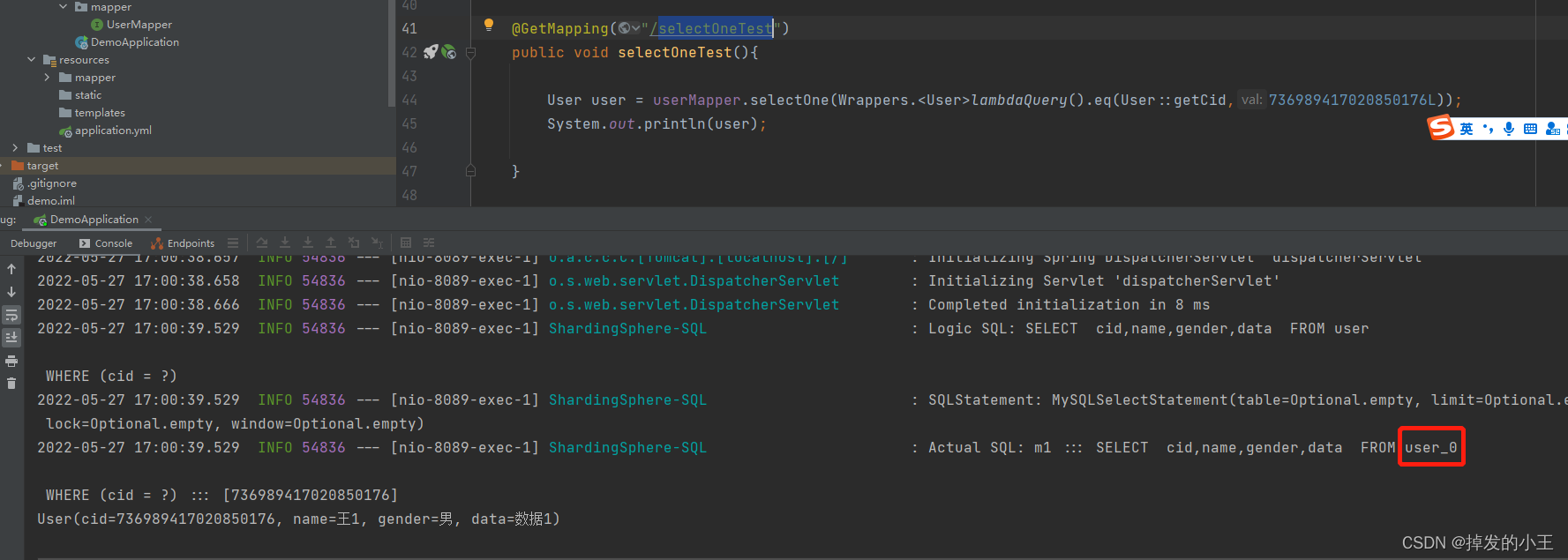
3. 全查詢
@GetMapping("/selectListTest")
public void selectListTest(){
List<User> list = userMapper.selectList(null);
System.out.println(list);
}
由於沒有條件,他會去把兩個表UNION ALL進行彙總
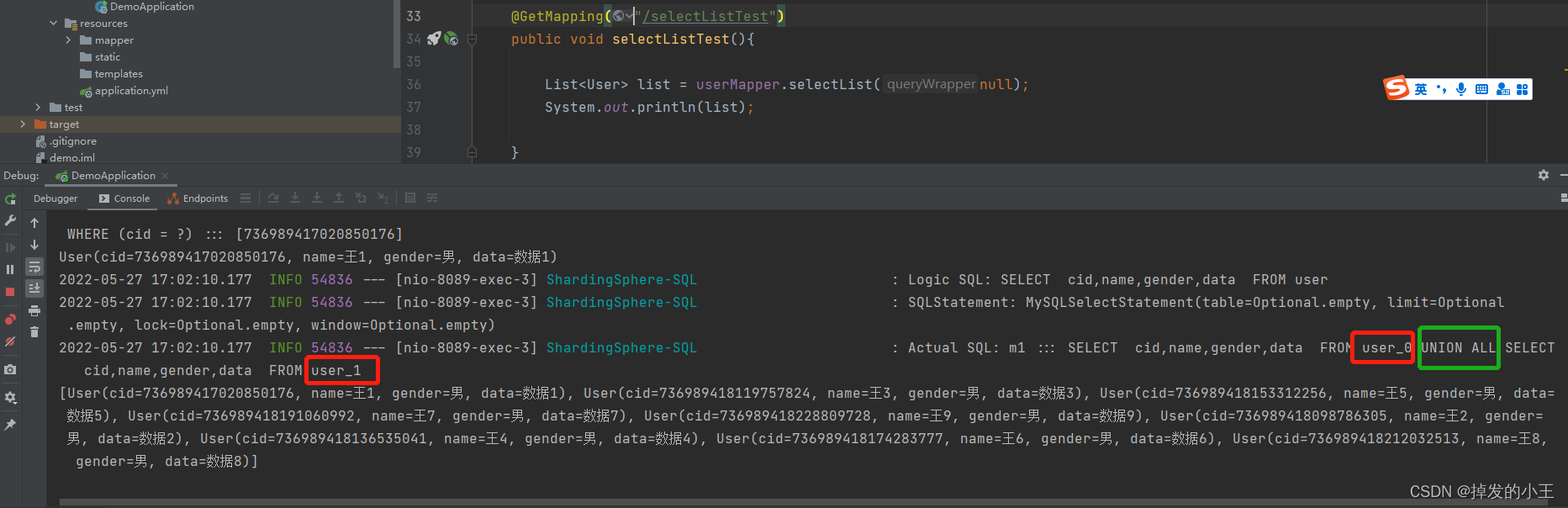
4. 分頁查詢
需要先設定mybatis-plus分頁設定類:
@Configuration
public class MybatisPlusConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
return interceptor;
}
}
@GetMapping("/selectListPage")
public void selectListPage(){
IPage<User> page = new Page(1,6);
IPage<User> userIPage = userMapper.selectPage(page,null);
List<User> records = userIPage.getRecords();
System.out.println(records);
}
我們user_0有5條資料,user_1有4條資料
我們發現它會向所有的表中去進行一遍分頁查詢,第一個表資料不夠就會加上另一個表分頁拿到的值
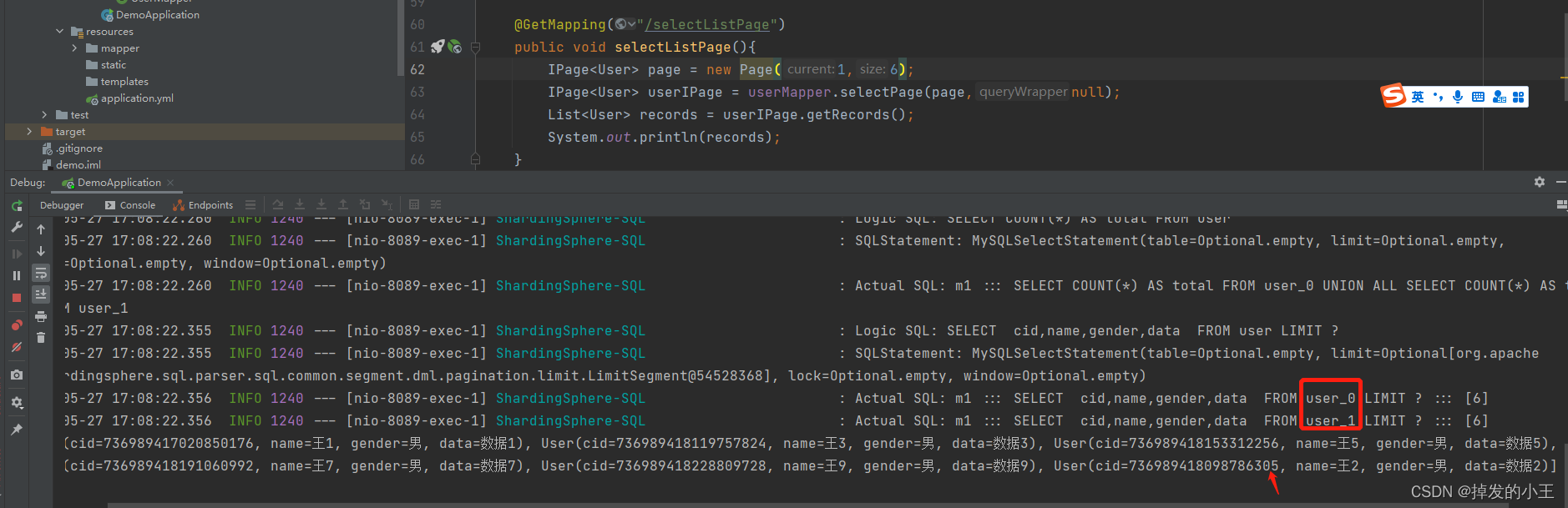
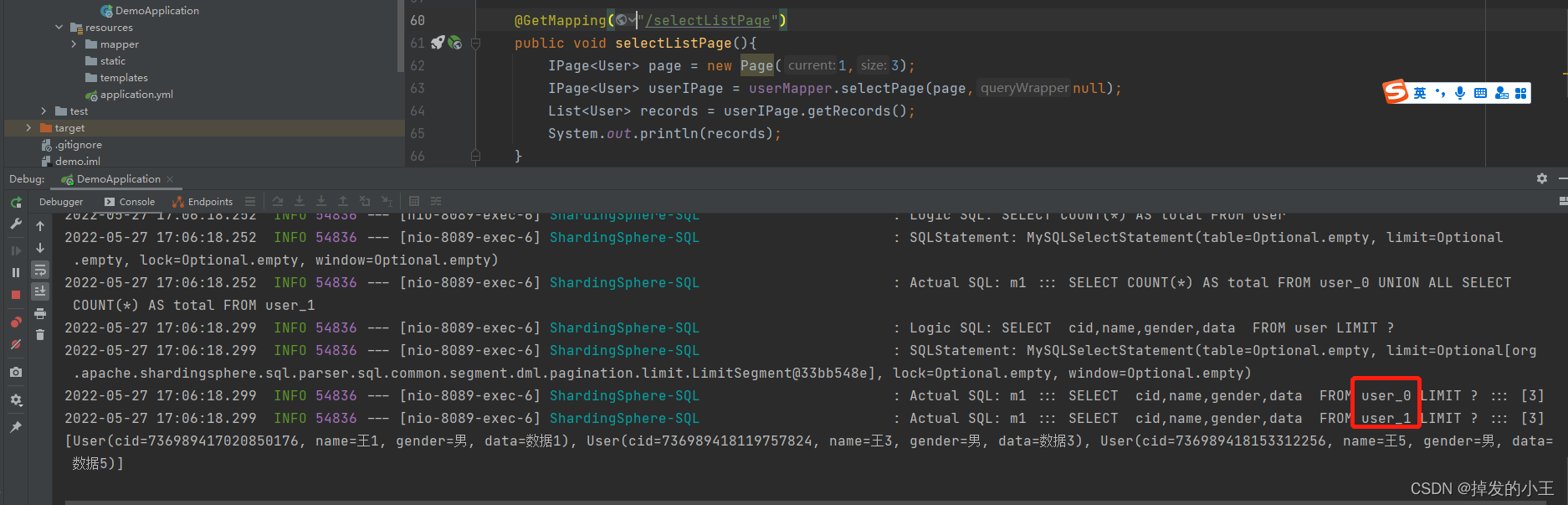
分頁size為3時,一個user_0就可以滿足分頁條件,就會忽略user_1的分頁資料。
5. 非分片屬性查詢
我們先把user_0表性別修改兩個為女,然後進行查詢!看看沒有分片的欄位是否能夠只去user_0去查詢
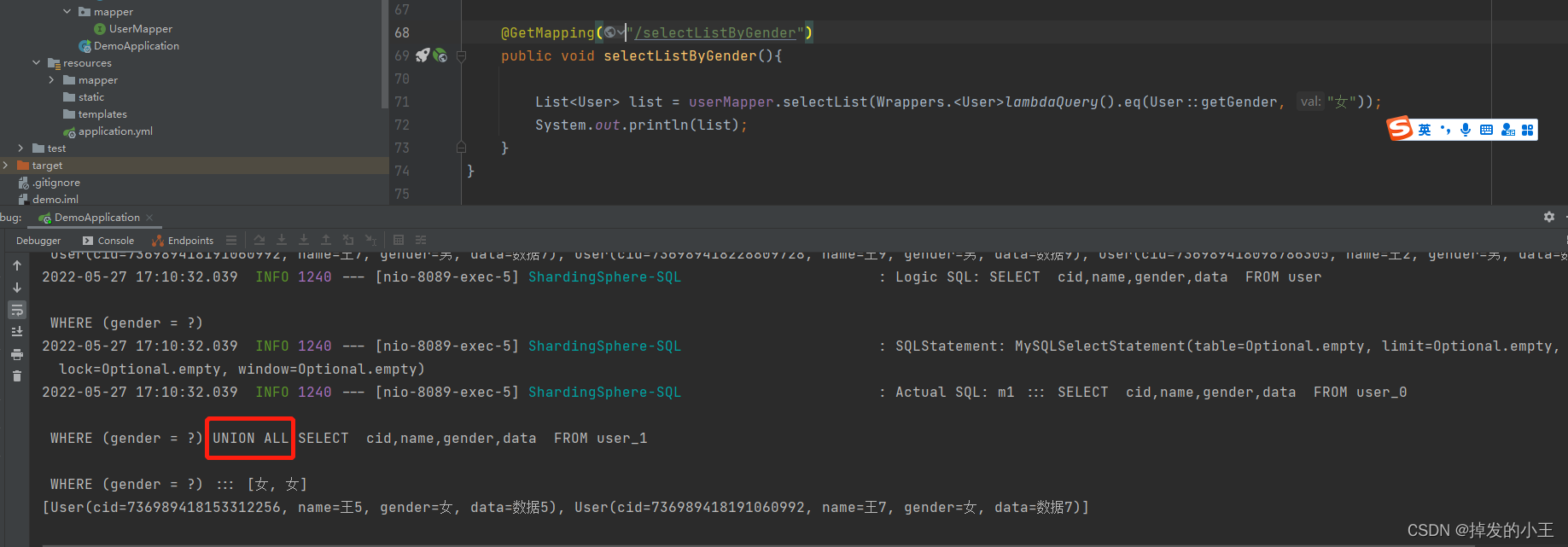
@GetMapping("/selectListByGender")
public void selectListByGender(){
List<User> list = userMapper.selectList(Wrappers.<User>lambdaQuery().eq(User::getGender, "女"));
System.out.println(list);
}
有圖可見:不是分片的欄位查詢,回去全連線表去查詢一遍,效率和不分表一樣了哈!!
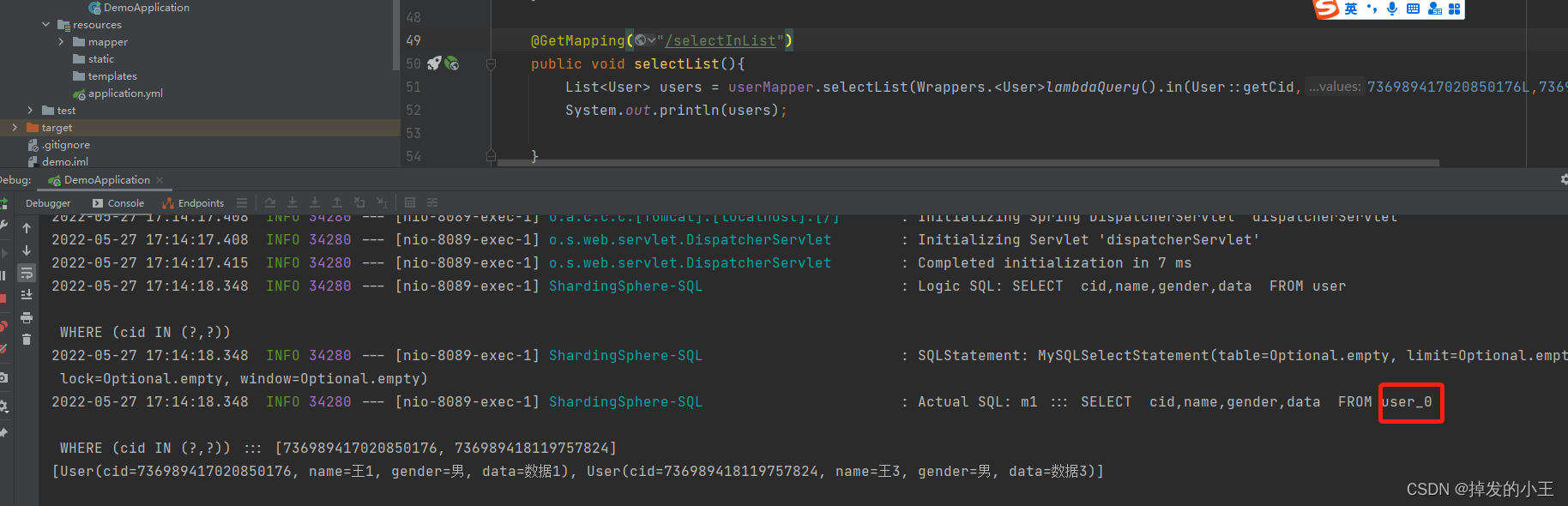
6. 分片屬性來自一個表in查詢
@GetMapping("/selectInList")
public void selectList(){
List<User> users = userMapper.selectList(Wrappers.<User>lambdaQuery().in(User::getCid,736989417020850176L,736989418119757824L));
System.out.println(users);
}
我們可以發現,我們根據分片欄位進行in查詢,sharding-jdbc會識別出來來自於那個表進而提高效率,不會所有的表進行全連線。
七、總結
這樣就完成了最新版的sharding-jdbc的簡單測試和一些坑的解決,總的來說設定很費勁,不能有一定的錯誤!
看到這裡了,還不給小編一鍵三連走起來,謝謝大家了!!
有緣人才可以看得到的哦!!!