理「 Druid 後設資料」之亂
vivo 網際網路巨量資料團隊-Zheng Xiaofeng
一、背景
Druid 是一個專為大型資料集上的高效能切片和 OLAP 分析而設計的資料儲存系統。
由於Druid 能夠同時提供離線和實時資料的查詢,因此Druid最常用作為GUI分析、業務監控、實時數倉的資料儲存系統。
此外Druid擁有一個多程序,分散式架構,每個Druid元件型別都可以獨立設定和擴充套件,為叢集提供最大的靈活性。
由於Druid架構設計和資料(離線,實時)的特殊性,導致Druid後設資料管理邏輯比較複雜,主要體現在Druid具有眾多的後設資料儲存媒介以及眾多不同型別元件之間後設資料傳輸邏輯上。
本文的目的是通過梳理 Druid 後設資料管理這個側面從而進一步瞭解 Druid 內部的執行機制。
二、 Druid 後設資料相關概念
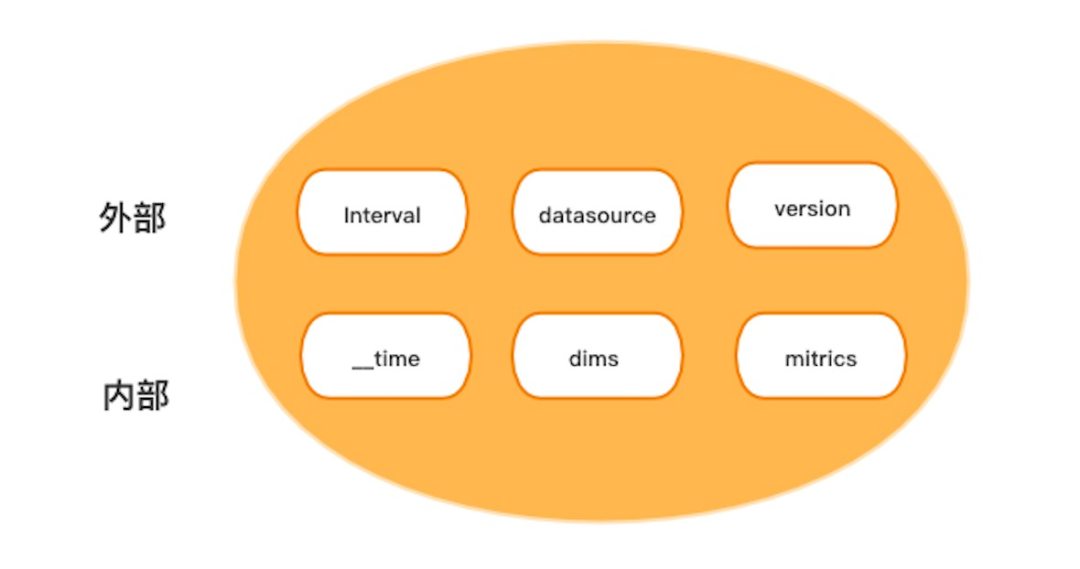
2.1 Segment
Segment 是Druid管理資料的最基本單元,一個Datasource包含多個Segment,每個Segment儲存著Datasource某個時間段的資料,這個特定時間段的資料組織方式是通過Segment的payload(json)來定義的,payload內部定義了某個Segment的維度,指標等資訊。
同一個Datasource的不同Segment的payload資訊(維度、指標)可以不相同,Segment資訊主要包含下面幾部分:
【時間段(Interval)】:用於描述資料的開始時間和結束時間。
【DataSource】: 用字串表示,指定segment隸屬於哪個Datasource。
【版本(Version)】:用一個時間表示,時間段(Interval)相同的Segment,版本高的Segment資料可見,版本低的Segment會被刪除掉。
【Payload 資訊】:主要包含了此Segment的維度和指標資訊,以及Segment資料存在DeepStorage 位置資訊等等。
segment主要組成部分
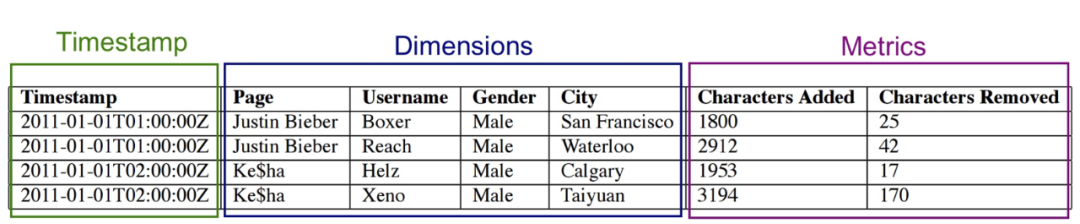
segment 內部資料樣例
2.2 Datasource
Datasource相當於關係型資料庫的表,Datasource的Schema是根據其可用的Segment動態變化的,如果某個Datasource沒有可用的Segment(used=1),在druid-web的Datasource列表介面和查詢介面看不到這個Datasource。
後設資料庫中druid_dataSource表並沒有儲存Schema資訊,只儲存了該Datasource對應 實時任務消費資料的偏移量資訊,都說Druid的Datasource相當於關係型資料庫的表,但是Druid中表(Datasource)Schema資訊,並不是定義在druid_dataSource後設資料表裡。
那麼在druid-web 頁面上看到的Datasource 的Schema資訊是怎麼來的呢?
其實它是實時根據該Datasource下所有Segment後設資料資訊合併而來,所以DataSource的Schema是實時變化的,
這樣設計的好處是很好的適應了Datasource維度不斷變化的需求在 :
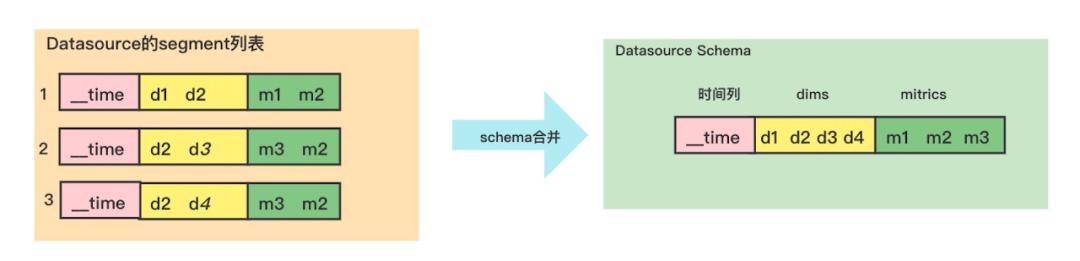
Schema的合併過程
2.3 Rule
Rule定義了Datasource的Segment留存規則,主要分兩大類:Load和Drop。
-
Load 表示Segment 保留策略。
-
**Drop **表示 Segment 刪除策略。
Load/Drop規則均有三個子類,分別是Forever Load/Drop,Interval Load/Drop以及Period Load/Drop,一個Datasource包含1個或多個Rule規則,如果沒有定義Rule規則就使用叢集的Default Rule規則。
Datasource Rule規則列表是有序的(自定義規則在前面,叢集預設規則在後面),在執行Run規則時,會對該Datasource下所有可用的Segment資訊,按照Run規則的先後順序進行判斷,只要Segment滿足某個Rule規則,後面的規則Rule就不再執行(如圖:Rule處理邏輯案例)。Rule規則主要包含下面幾部分資訊:
-
【型別】:型別有刪除規則和載入規則。
-
【Tier和副本資訊】:如果是Load規則,需要定義在不同Tier的Historical機器副本數。
-
【時間資訊】:刪除或載入某個時間段的Segment。
Rule 樣例如下:
[
{
"period": "P7D",
"includeFuture": true,
"tieredReplicants": {
"_default_tier": 1,
"vStream":1
},
"type": "loadByPeriod"
},
{
"type": "dropForever"
}
]
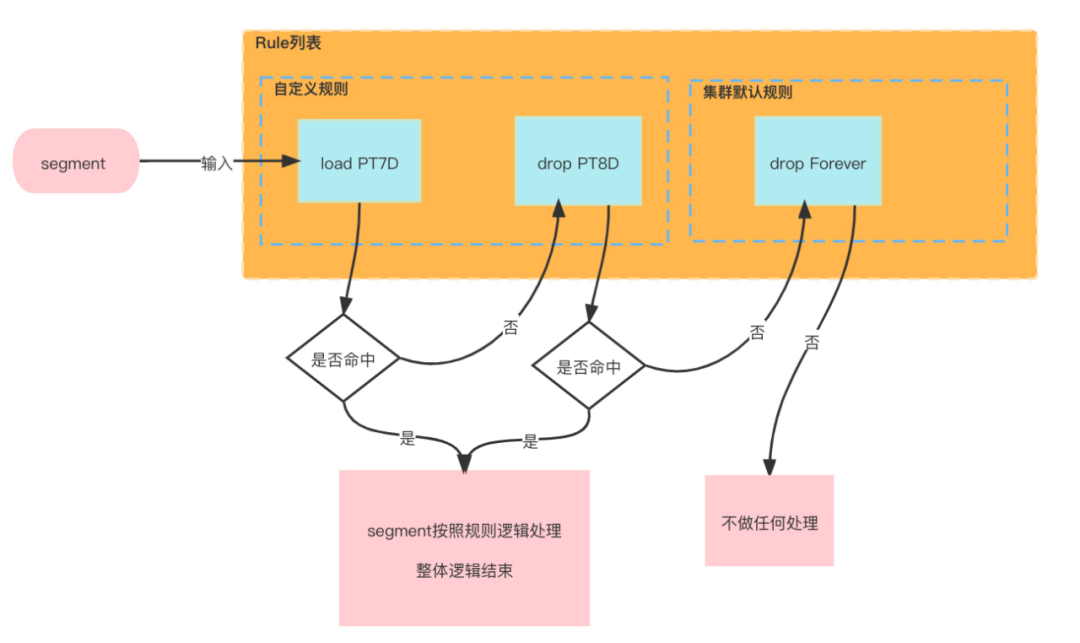
Rule處理邏輯案例
2.4 Task
Task主要用於資料的攝入(本文主要討論實時攝入kafka資料的任務),在Task的執行過程中,它會根據資料時間列產生一個或者多個Segment,Task分為實時和離線任務。
實時任務(kafka)是Overload程序根據Supervisor定義自動生成;
離線任務(型別:index_hadoop,index_parallel)則需要外部系統通過存取介面方式提交。
每個任務主要包含下面幾部分資訊:
-
【dataSchema】:定義了該任務生成的Segment中有哪些維度(dimensionsSpec),指標(metricsSpec),時間列(timestampSpec),Segment粒度(segmentGranularity),資料聚合粒度(queryGranularity)。
-
【tuningConfig】:任務在攝入資料過程中的優化引數(包括Segment生成策略,索引型別,資料丟棄策略等等),不同的任務型別有不同的引數設定。
-
【ioConfig】:定義了資料輸入的源頭資訊,不同的資料來源設定項有所不同。
-
【context】:關於任務全域性性質的設定,如任務Java程序的option資訊。
-
【datasource】:表示該任務為那個Datasource 構造Segment。
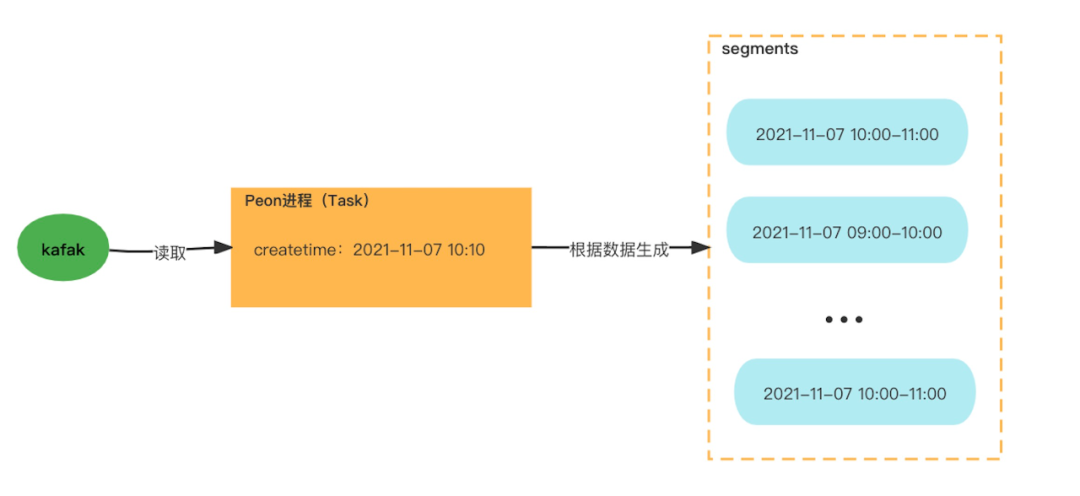
實時任務生成Segment案例
2.5 Supervisor
Supervisor 用於管理實時任務,離線任務沒有對應的Supervisor,Supervisor與Datasource是一對一的關係,在叢集執行過程中Supervisor物件由Overlord程序建立,通過Overlord介面提交Supervisor資訊後,會在後設資料庫(MySQL)中持久化,Supervisor內容與Task相似,可以認為實時Task是由Supervisor 克隆出來的。
三、Druid 整體架構
前面籠統地介紹了Druid後設資料相關概念,為了深入的瞭解Druid後設資料,先從宏觀的角度認識一下Druid的整體架構。
可以形象地把Druid叢集類比為一家公司,以Druid不同元件類比這家公司中不同型別員工來介紹Druid叢集,Druid元件大體可以分為三類員工:領導層,車間員工和銷售員工,如下圖:
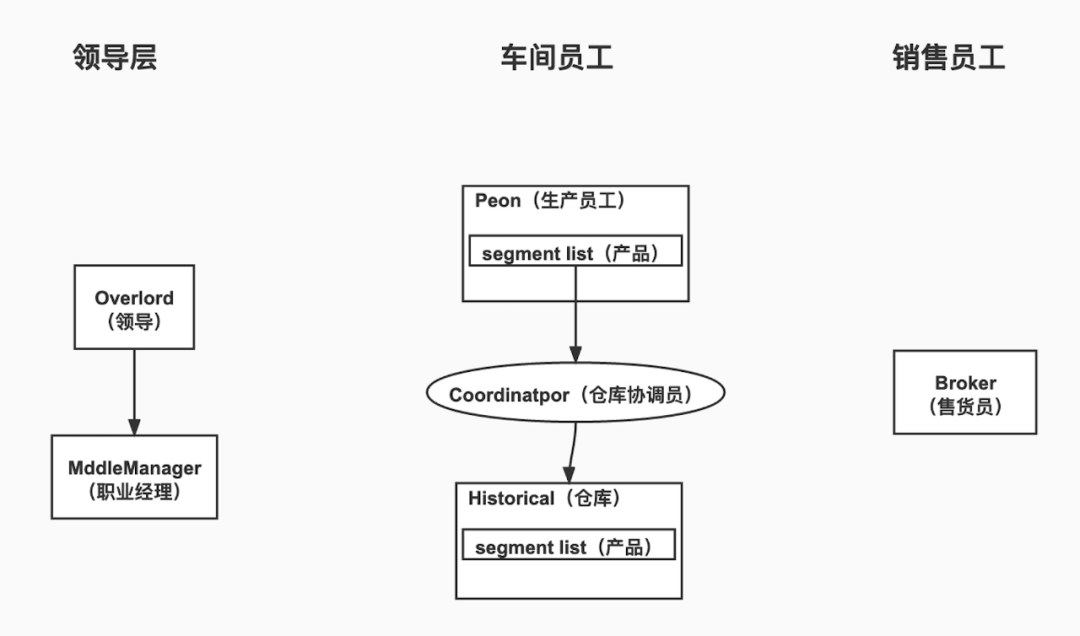
Druid元件分類
-
領導層: 領導根據外部市場需求(Overlord接收外部攝入任務請求),然後把生產任務下發到對應的職業經理人(MiddleManager),職業經理人管理團隊(MiddleManager 啟動Peon程序),下發具體生產任務給不同型別的員工(Peon程序)。
-
**車間員工: **生產員工(Peon) 負責生產產品(segment),倉庫管理員(Coordinator)負責把生產出來的產品(segment)分配到倉庫(Historical)中去。
-
銷售員工: 銷售員(Broker)從生產員工(Peon)獲取最新的產品(segment),從倉庫中獲取原來生產的產品(segment),然後把產品整理打包(資料進一步合併聚合)之後交給顧客(查詢使用者)。
上面通過類比公司的方式,對Druid叢集有了初步的整體印象。
下面具體介紹 Druid 叢集架構,Druid 擁有一個多程序,分散式架構,每個Druid元件型別都可以獨立設定和擴充套件,為叢集提供最大的靈活性。
一個元件的中斷不會立即影響其他元件。
下面我們簡要介紹Druid各個元件在叢集中起到的作用。
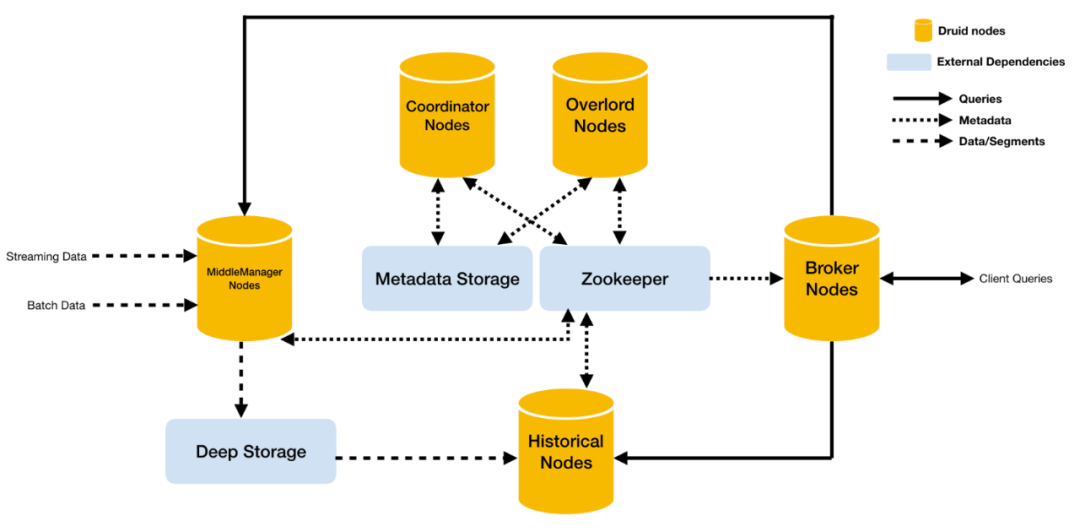
Druid架構
- Overlord
Overlord負責接受任務、協調任務的分配、建立任務鎖以及收集、返回任務執行狀態給呼叫者。當叢集中有多個Overlord時,則通過選舉演演算法產生Leader,其他Follower作為備份。
- MiddleManager
MiddleManager負責接收Overlord分配的實時任務,同時建立新的程序用於啟動Peon來執行實時任務,每一個MiddleManager可以執行多個Peon範例,每個實時Peon既提供實時資料查詢也負責實時資料的攝入工作。
- Coordinator
Coordinator 主要負責Druid叢集中Segment的管理與釋出(主要是管理歷史Segment),包括載入新Segment、丟棄不符合規則的Segment、管理Segment副本以及Segment負載均衡等。如果叢集中存在多個Coordinator Node,則通過選舉演演算法產生Leader,其他Follower作為備份。
- Historical
Historical 的職責是負責載入Druid中非實時視窗內且滿足載入規則的所有歷史資料的Segment。每一個Historical Node只與Zookeeper保持同步,會把載入完成的Segment同步到Zookeeper。
- Broker
Broker Node 是整個叢集查詢的入口,Broker 實時同步Zookeeper上儲存的叢集內所有已釋出的Segment的元資訊,即每個Segment儲存在哪些儲存節點上,Broker 為Zookeeper中每個dataSource建立一個timeline,timeline按照時間順序描述了每個Segment的存放位置。
每個查詢請求都會包含dataSource以及interval資訊,Broker 根據這兩項資訊去查詢timeline中所有滿足條件的Segment所對應的儲存節點,並將查詢請求發往對應的節點。
四、 Druid後設資料儲存媒介
Druid 根據自身不同的業務需要,把後設資料儲存在不同的儲存媒介中,為了提升查詢效能,同時也會將所有後設資料資訊快取在記憶體中。把歷史資料的後設資料資訊儲存到後設資料庫(MySQL),以便叢集重啟時恢復。
由於Druid 擁有一個多程序,分散式架構,需要使用Zookeeper進行後設資料傳輸,服務發現,主從選舉等功能,並且歷史節點會把Segment後設資料資訊儲存在本地檔案。
那麼歷史節點(Historical)為什麼會把該節點載入的Segment後設資料資訊快取在自己節點的本地呢?
是因為在歷史節點發生重啟之後,讀取Segment的後設資料資訊不用去Mysql等其他後設資料儲存媒介進行跨節點讀取而是本地讀取, 這樣就極大地提升了歷史節點資料的恢復效率。
下面分別介紹這些儲存媒介(記憶體、後設資料庫、Zookeeper、本地檔案)裡的資料和作用。
4.1 後設資料庫(MySQL)
MySQL 資料庫主要用於長期持久化 Druid 後設資料資訊,比如segment部分後設資料資訊存在druid_segments表中,歷史的Task資訊存在druid_tasks,Supervisor資訊儲存在druid_supervisors等等。
Druid部分服務程序在啟動時會載入後設資料庫持久化的資料,如:Coordinator程序會定時載入表druid_segments 中used欄位等於1的segment列表,Overlord 啟動時會自動載入druid_supervisors表資訊,以恢復原來實時攝入任務等等。
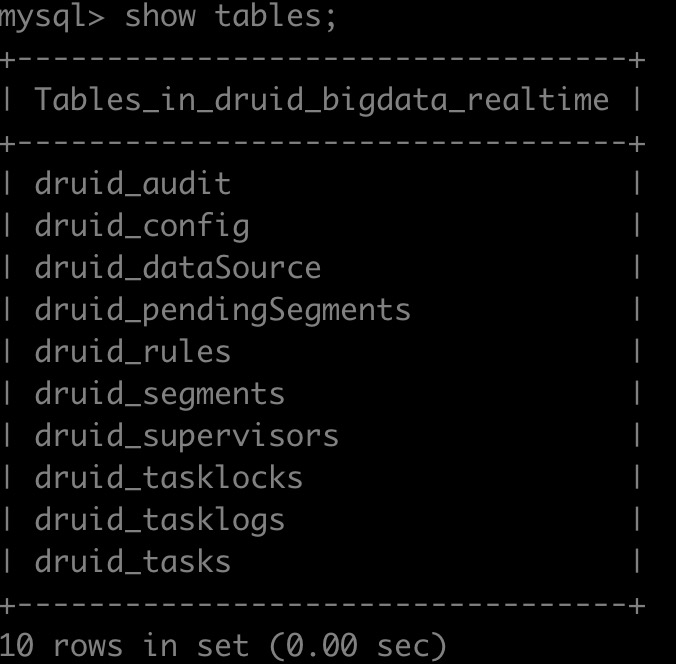
MySQL 後設資料庫表
4.2 Zookeeper
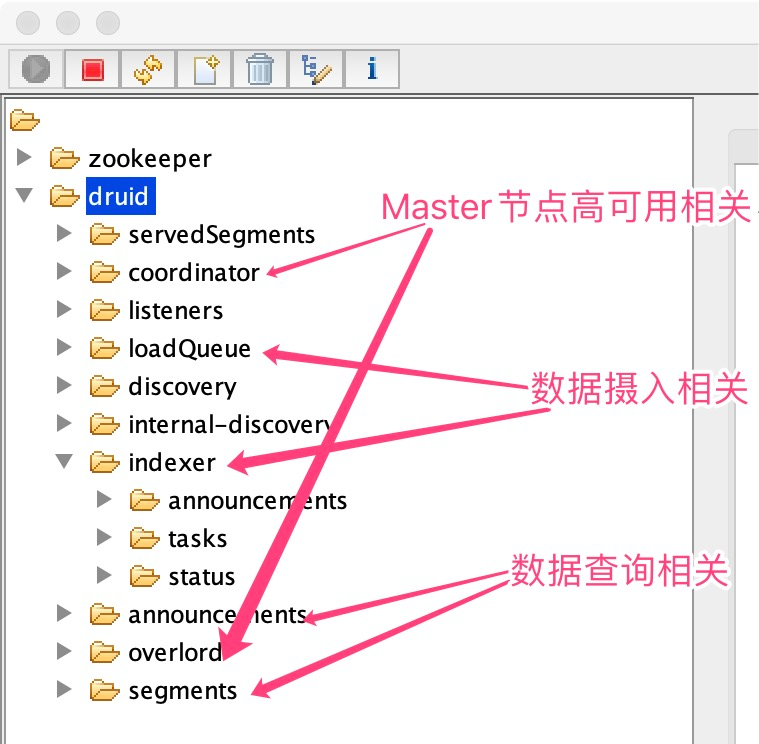
Zookeeper 主要儲存 Druid 叢集執行過程中實時產生的後設資料,Zookeeper 資料目錄大概可以分為Master節點高可用、資料攝入、資料查詢3類目錄。
下面介紹Druid相關Zookeeper目錄後設資料內容。
Zookeeper 後設資料節點分類
4.2.1 Master 節點高可用相關目錄
${druid.zk.paths.base}/coordinator: coordinator 主從高可用目錄,有多個臨時有序節點 編號小的是leader。
${druid.zk.paths.base}/overlord: overlord 主從高可用目錄,有多個臨時有序節點 編號小的是leader。
4.2.2 資料查詢相關目錄
${druid.zk.paths.base}/announcements:只儲存historical,peon程序的host:port,沒有MiddleManager,broker,coodinator等程序資訊,用於查詢相關節點服務發現。
${druid.zk.paths.base}/segments:當前叢集中能被查詢到的segment列表。目錄結構:historical或peon的host:port/${segmentId},Broker節點會實時同步這些Segment資訊,作為資料查詢的重要依據。
4.2.3 資料攝入相關目錄
${druid.zk.paths.base}/loadQueue: Historical需要載入和刪除的segment資訊列表(不止只有載入),Historical程序會監聽這個目錄下自己需要處理的事件(載入或刪除),事件完成之後會主動刪除這個目錄下的事件。
${druid.zk.paths.indexer.base}=${druid.zk.paths.base}/indexer:關於攝入任務資料的base目錄。
${druid.zk.paths.indexer.base}/announcements:儲存當前存活MiddleManager列表,注意historical,peon 列表不在這裡,這裡只儲存攝入相關的服務資訊,用於資料攝入相關節點服務發現。
${druid.zk.paths.indexer.base}/tasks Overlord 分配的任務資訊放在這個目錄(MiddleManager的host:port/taskInfo),等任務在MiddleManager上執行起來了,任務節點資訊將被刪除。
${druid.zk.paths.indexer.base}/status:儲存任務執行的狀態資訊,Overlord通過監聽這個目錄獲取任務的最新執行狀態。
4.3 記憶體
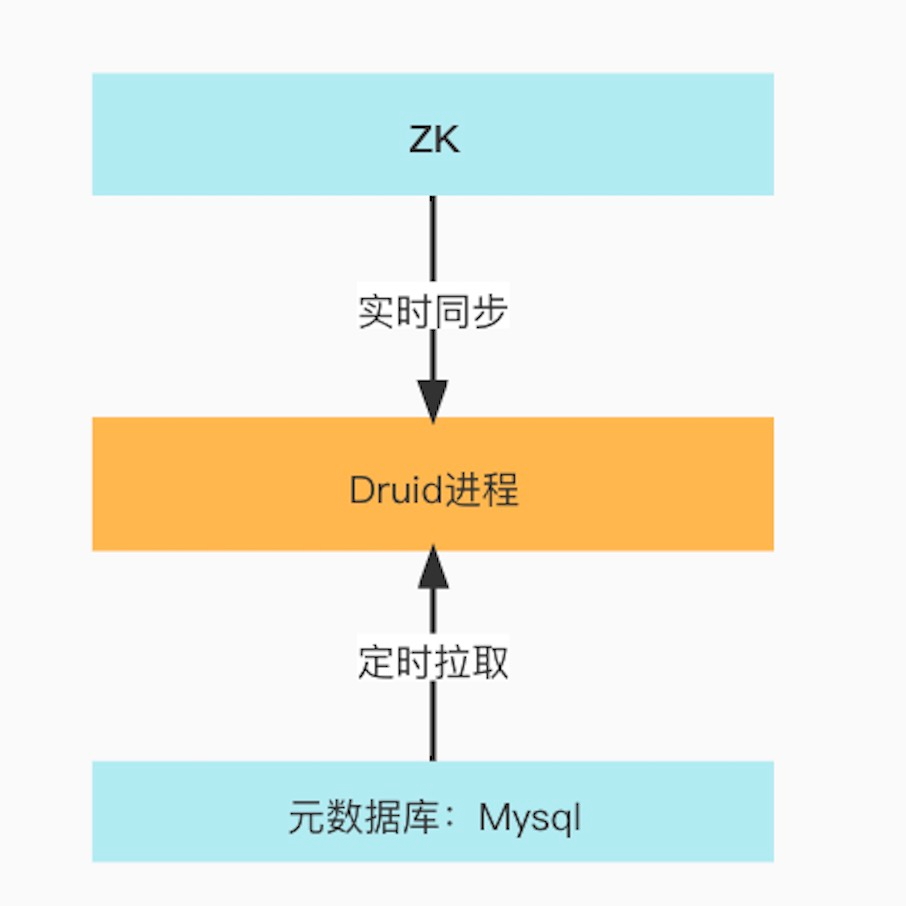
Druid為了提升後設資料存取的效率會把後設資料同步到記憶體,主要通過定時SQL 查詢存取方式同步MySQL後設資料或者使用Apache Curator Recipes實時同步Zookeeper上的後設資料到記憶體如下圖。
每個程序中的後設資料不一樣,下面一一介紹一下各個角色程序快取了哪些資料。
Druid程序後設資料同步方式
4.3.1 Overlord
實時同步Zookeeper目錄(${druid.zk.paths.indexer.base}/announcements)下的資料,使用變數RemoteTaskRunner::zkWorkers(型別:Map)儲存,每ZkWorker對應一個MM程序,在ZkW orker物件中會實時同步Zookeeper目錄(${druid.zk.paths.indexer.base}/status/${mm_host:port})任務資訊,使用RemoteTaskRunner::runningTasks變數儲存。
預設每分鐘同步資料庫中druid_tasks active = 1的資料,使用變數TaskQueue::tasks(型別:List )儲存,在同步時會把記憶體中的Task列表與最新後設資料裡的Task列表進行比較,得到新增的task列表和刪除的task列表,把新增的Task加到記憶體變數TaskQueue::tasks,清理掉將要被刪除的task
4.3.2 Coordinator
預設每1分鐘同步後設資料庫中druid_segemtns 中列 used=1的segment列表到變數SQLMetadataSegmentManager::dataSourcesSnapshot。
預設每1分鐘同步後設資料庫druid_rules表資訊到SQLMetadataRuleManager::rules變數
使用CoordinatorServerView類(後面會介紹)實時同步${druid.zk.paths.base}/announcements,${druid.zk.paths.base}/segments的資料,用於與後設資料庫中的segment對比,用來判斷哪些segment應該載入或刪除。
4.3.3 Historical
會實時同步${druid.zk.paths.base}/loadQueue/${historical_host:port} 下的資料,進行segment的載入與刪除操作,操作完成之後會主動刪除對應的節點。
Historical通過上報segment資訊到${druid.zk.paths.base}/segments來暴露segment。
4.3.4 MiddleManager
會實時同步${druid.zk.paths.indexer.base}/tasks/${mm_host:port}的資料,進行任務(peon)程序的啟動,啟動完成之後會主動刪除對應的節點。
MiddleManager上報segment資訊到${druid.zk.paths.base}/segments來暴露segment。
4.3.5 Broker
使用BrokerServerView類實時同步${druid.zk.paths.base}/announcements,${druid.zk.paths.base}/segments的資料,構建出整個系統的時間軸物件(BrokerServerView::timelines) 作為資料查詢的基本依據。同步過程中類的依賴關係如下圖。
下層的類物件使用監聽上層類物件的方式感知sement的增刪改,並做相應的邏輯處理, 會同時監聽${druid.zk.paths.base}/announcements和${druid.zk.paths.base}/segments的資料的資料變化,通過回撥監聽器的方式通知到下層類物件。
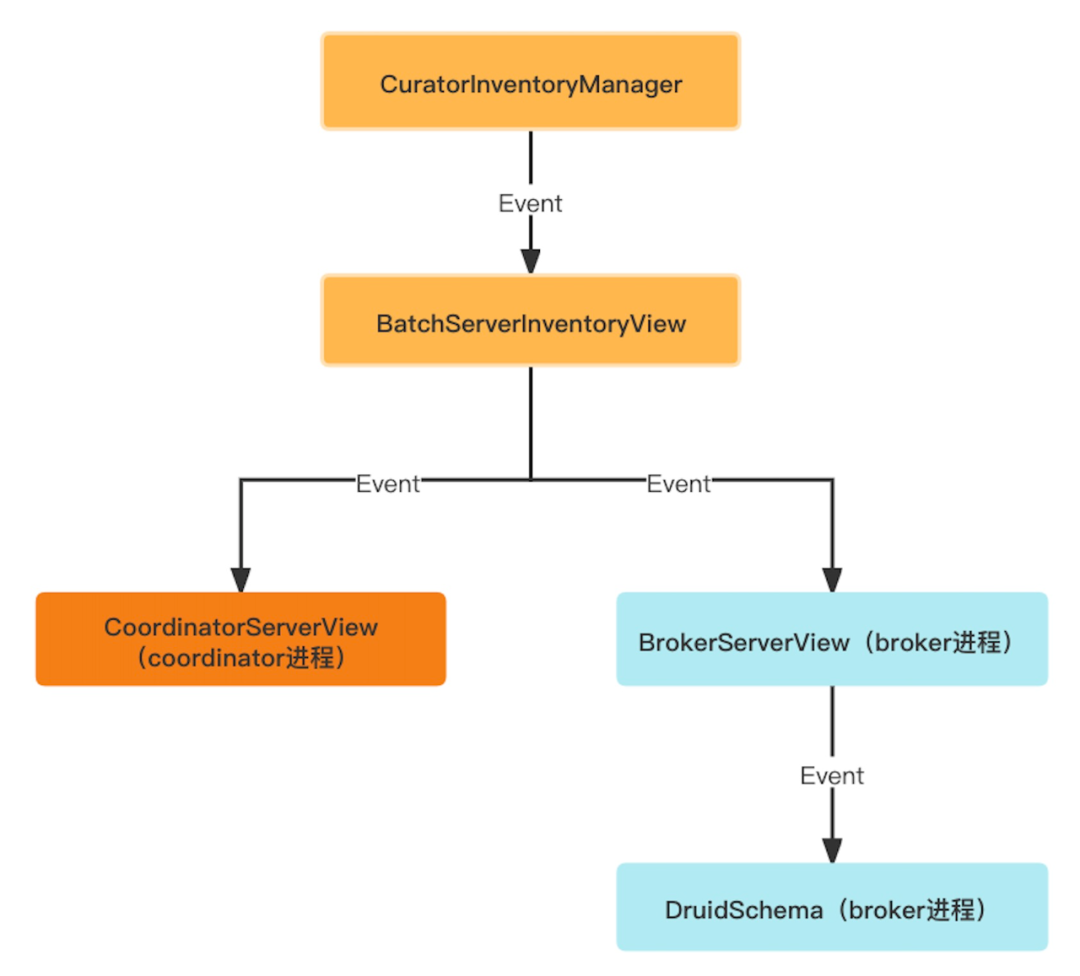
zk中segment同步到Druid程序過程中物件之間的監聽關係
4.4 本地檔案
本地檔案的後設資料主要用於恢復單個節點時讀取並載入。
例如:Historical節點第一個資料目錄下的info_dir目錄(如:/data1/druid/segment-cache/info_dir),儲存了該節點載入的所有segment資訊,在Historical程序重啟時會讀取該目錄下的segment後設資料資訊,判斷本地是否有該segment的資料,如果沒有就去深度儲存系統(hdfs)下載,資料下載完成後會上報segment資訊到Zookeeper(路徑:${druid.zk.paths.base}/segments)。
五、Druid 後設資料相關業務邏輯
由於Druid元件型別比較多,業務邏輯比較複雜,從整體到區域性方式,從宏觀到細節,循序漸進地瞭解Druid的業務邏輯,以便了解Druid後設資料在業務邏輯中發揮的作用。
5.1 Druid 後設資料整體業務邏輯
前面從整體瞭解了 Druid 叢集各個元件的共同作業關係,下面分別從攝入任務管理、資料攝入、資料查詢三個方面的業務邏輯來梳理後設資料在 Druid 叢集所起的作用。
5.1.1 攝入任務管理
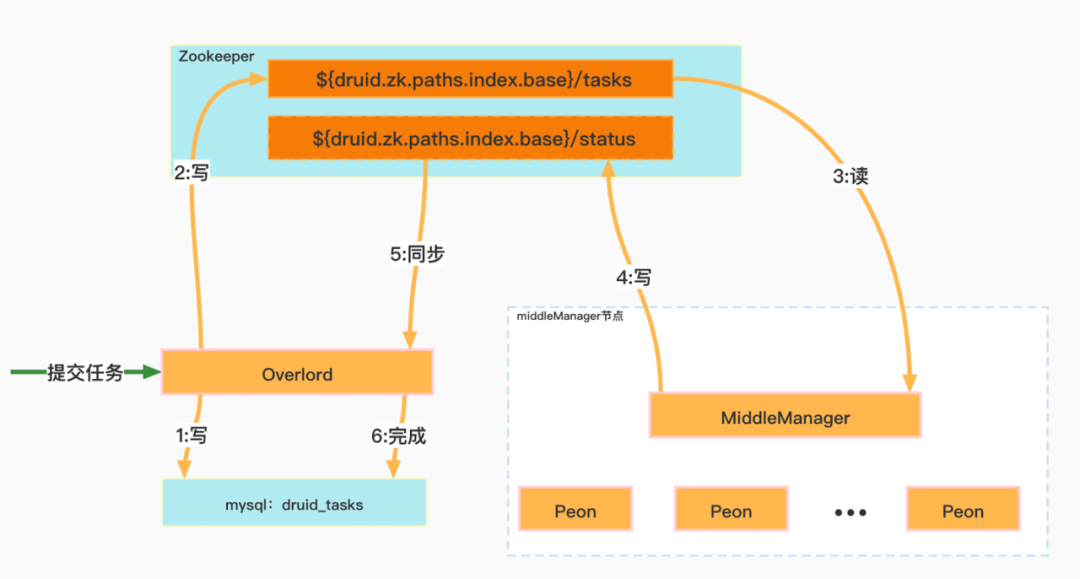
攝入資料之前需要使用者提交攝入任務,Overlord根據任務的設定會相應命令MiddlerManager啟動該任務的相關程序(peon程序)用於攝入資料,具體流程如下圖中資料序號順序執行。
任務提交與管理
下面分別按照上圖中數位序號順序介紹 Druid 內部關於任務管理的業務邏輯:
① Overlord程序收到任務提交請求之後,會把任務資訊寫入druid_tasks表,此時欄位active等於1。
② Overlord分配任務給特定的MiddleManager節點,並把task資訊寫入Zookeeper目錄(${druid.zk.paths.indexer.base}/tasks )下。
③ MiddleManager程序監聽當前節點在Zookeeper目錄(${ruid.zk.paths.indexer.base}/task)需要啟動的task資訊。
④ MiddleManager會以fork的方式啟動Peon程序(task)此時Peon程序開始攝入資料,並把任務Running狀態寫入Zookeeper目錄(${ruid.zk.paths.indexer.base}/status)。
⑤ Overlord會實時監聽Zookeeper目錄(${ruid.zk.paths.indexer.base}/status)獲取任務執行最新狀態。
⑥ 任務完成後Overlord會把task狀態資訊更新到資料庫表druid_tasks,此時欄位active=0。
5.1.2 資料攝入邏輯
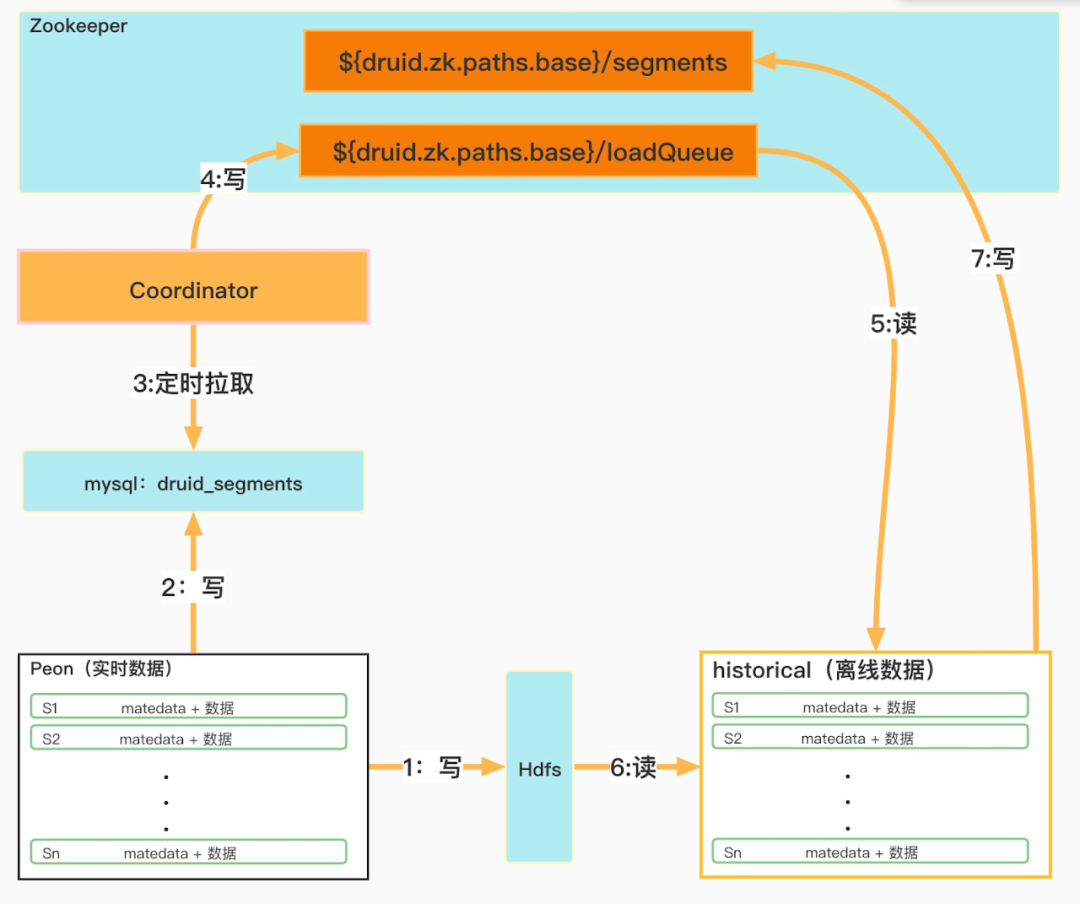
Druid資料攝入邏輯
下面分別按照上圖中數位序號順序介紹Druid內部關於資料攝入的業務邏輯:
① Peon程序在本地生產segment之後,會上傳segment資料到深度儲存Hdfs。
② 插入一條segment後設資料資訊到後設資料druid_segments表中,包括segment資料hdfs地址,Interval資訊,注意此時used欄位為1。
③ Coordinator程序定時拉取druid_segments表中used為1的資料。
④ Coordinator程序把segment分配資訊寫入Zookeeper目錄:${druid.zk.paths.base}/loadQueue。
⑤ HIstorical程序監聽當前節點在Zookeeper目錄(${druid.zk.paths.base}/loadQueue)獲取需要載入的segment資訊。
⑥ 從Hdfs下載segment資料,載入segment。
⑦把已載入的segment的後設資料資訊同步到Zookeeper目錄(${druid.zk.paths.base}/segments)。
5.1.3 資料查詢邏輯
資料查詢主要涉及到Peon、Historical,Broker三個角色,Broker會根據client的查詢請求中包含的dataSource和interval資訊,篩選出需要查詢的segment,然後Broker作為使用者端從Peon獲取實時資料,從Historical獲取歷史資料,再根據查詢要求,將兩部分資料進一步聚合,如下圖:
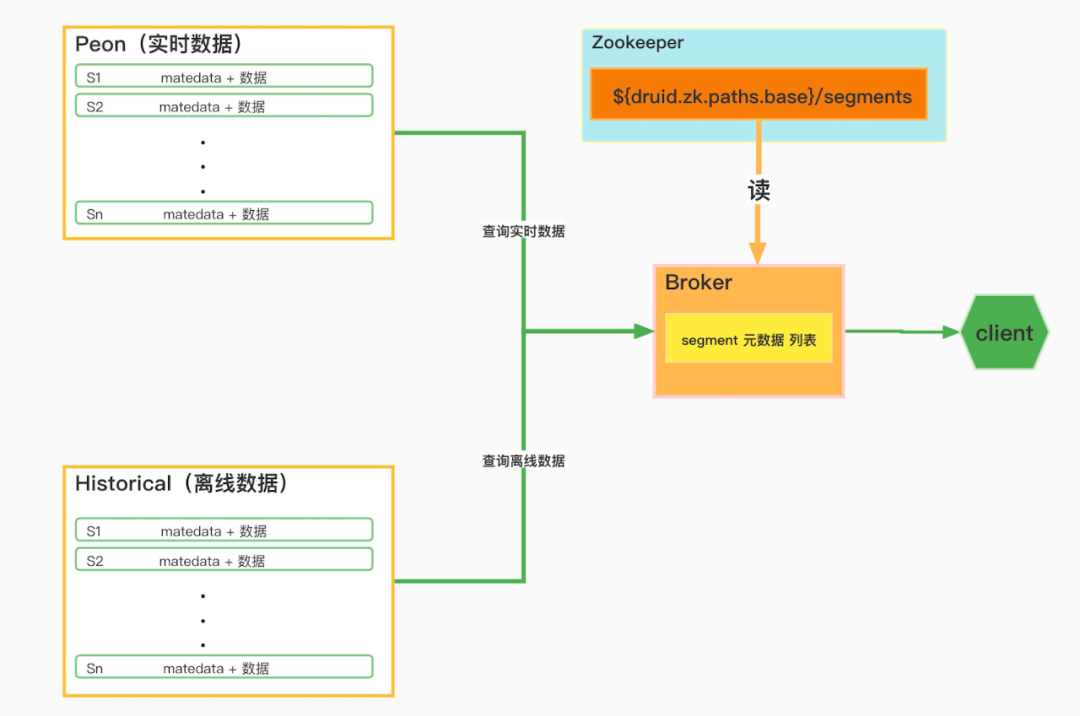
Druid資料查詢邏輯
5.2 Druid 後設資料具體業務邏輯
有了前面對Druid叢集整體認識之後,下面更為細緻的探討Druid後設資料在各個元件之間發揮的作用。
如下圖虛線箭頭表示後設資料的傳輸,下面按照圖中數位序號介紹每個虛線箭頭兩端元件與後設資料儲存媒介(MySQL、Zookeeper)之間的後設資料,每條具體從元件對後設資料儲存媒介包含讀和寫兩方面來介紹,如下:
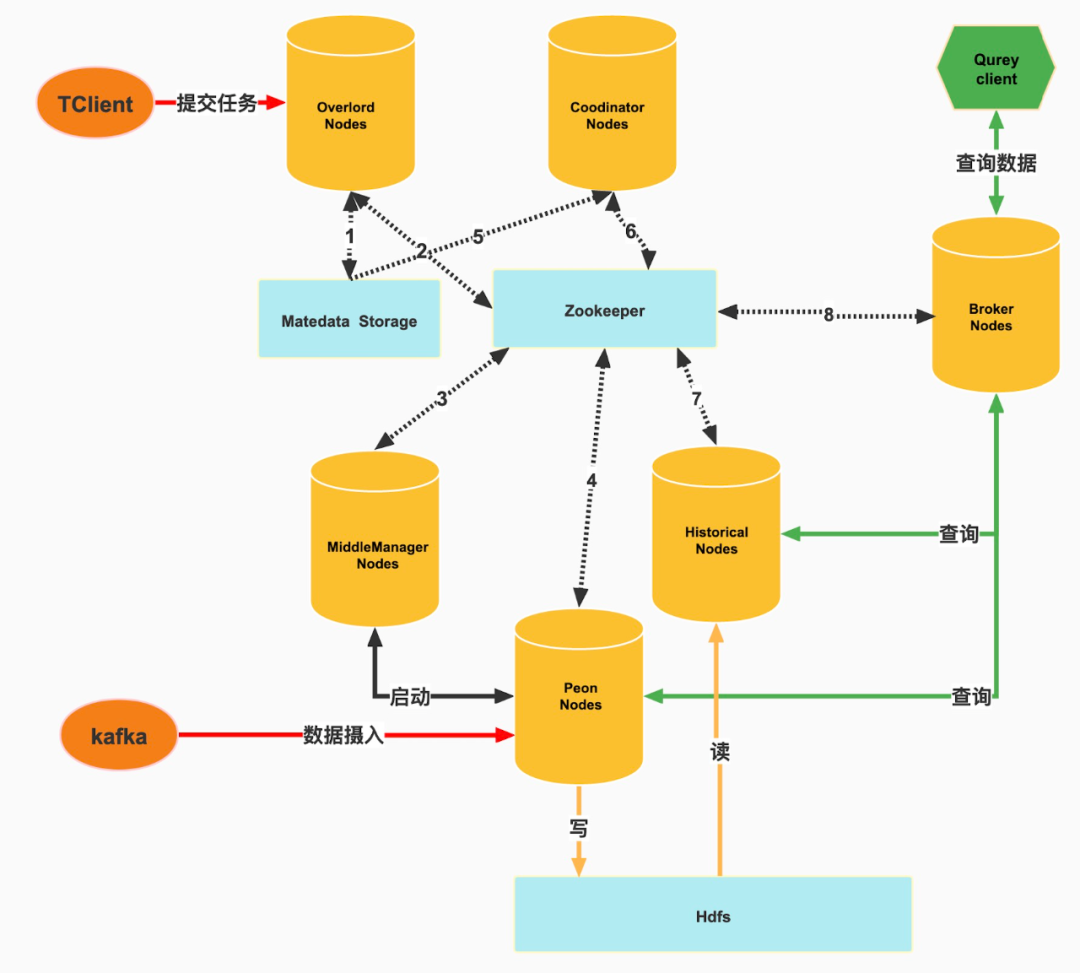
Druid後設資料業務邏輯
① 寫:啟動任務時寫入task資訊,提交實時任務時寫入supervisor資訊。讀:broker呼叫overlord介面時會查詢不同狀態下的task資訊,程序重啟時恢復supervisor資訊。
② 寫:分配任務到MiddleManager時,寫入任務資訊。讀:同步正在執行任務的狀態資訊。
③ 寫:寫入當前節點任務狀態資訊到Zookeeper,讀:讀取帶啟動或終止任務資訊。
④ 寫:任務啟動後上報實時segment資訊。
⑤ 讀:coordinator定時讀取欄位used=1的segment列表資訊。
⑥** 寫**:coordinator分配的segment資訊,讀:已分配的segment列表資訊。
⑦ 寫:已載入完成的segment資訊,讀:需要載入的segment資訊。
⑧ 讀:載入完成的segment資訊,作為資料查詢的依據。
六、總結
前面以整體到區域性、抽象到細節的方式從四個方面(Druid後設資料基本概念、Druid整體架構、Druid後設資料儲存媒介Druid後設資料相關業務邏輯)介紹了Druid後設資料在Druid叢集中扮演的角色。
Druid 擁有一個多程序,分散式架構,每個元件只關注自己的業務邏輯和後設資料,通過RPC通訊或Zookeeper 進行元件之間的解耦,每個 Druid 元件型別都可以獨立設定和擴充套件,極大提供叢集的靈活性,以至於一個元件的中斷不會立即影響其他元件,下面對Druid後設資料做一個總結:
Druid後設資料儲存媒介有記憶體、後設資料庫(MySQL)、Zookeeper、本地檔案。
後設資料庫(MySQL)和原生的後設資料起到備份、持久化的作用。Zookeeper主要起到後設資料傳輸橋樑,實時儲存後設資料的作用,同時把後設資料同步到記憶體,極大提升了Druid資料查詢和資料攝入的效能,而本地檔案的後設資料主要用於恢復單個節點時快速讀取並載入到記憶體。
在Druid元件程序中會把Zookeeper和後設資料庫(MySQL)裡的後設資料分別通過實時同步和定時拉取的方式同步到程序的記憶體中,以提高存取效率。
儲存在各個元件程序中記憶體的後設資料才是當前叢集中最新最全的後設資料。