圖解路由協定!
想必我們大家都鼓搗過路由器,路由器可以說是我們日常生活中必不可少的一個裝備了,就算你不是程式設計師,想必你隔壁的七大姑八大姨估計也讓你設定過路由器。但是大家有沒有想過一個問題,這個路由器是幹啥用的?你可能知道這是為終端裝置提供 WI-FI 連線上網的一種裝置,當我們終端裝置連線 WI-FI 後,就可以通過路由器把資料從我的裝置傳到我想要的地方(其他終端裝置),然後實現我想要的東西和內容。
這個回答整體上是能說通的,但是這裡我就要問你一個問題了。
路由器是如何把資料傳送給其他路由器的呢?
這個問題要回答上來,就要從路由協定來說起了。
在網際網路中,不管是區域網還是廣域網,一個封包是可以通過合理的路由控制從一個終端傳輸到另一個終端的。而起到控制這個封包傳送過程就是路由控制模組,路由控制模組遵循路由協定,路由協定是整個網際網路的資料路由的規範和標準。
路由
為了能夠讓封包正確的到達目標主機,路由器必須要在資料傳送的過程中進行正確的轉發,這也是路由器的第一個作用:資料處理,除了能夠轉發外,資料處理還包括對資料進行分組過濾、加密、壓縮等。
那麼路由器是怎麼知道這個資料是要發往哪裡的呢?
路由器內部維護了一個路由表,這個路由表會記錄封包中目標主機的 IP 地址和輸出路徑。路由器的主要工作就是為每個經過路由的封包尋找一個最佳的傳輸路徑,關於路由器的一些結構和轉發規則我們已經在 路由器你竟然是這樣的... 這篇文章中提到過了。
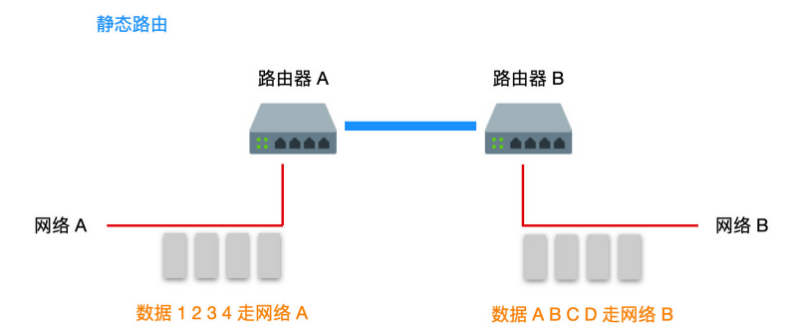
靜態路由和動態路由
我們通常會把路由器分為靜態路由和動態路由兩種,不管是靜態路由還是動態路由,都不會脫離路由表。如果資料傳送前你已經把路由規則設定好,在傳送時資料會按照你事先設定好的路徑進行轉發的話,這就是靜態路由,如果你事先沒有設定路由規則,只是讓資料在傳送的過程中按照路由協定的既定規則進行轉發的話,這就是動態路由,這兩種路由方式各有利弊。
靜態路由會讓你做大量且重複的設定路由的工作,效率低而且任務量很大,並且擴充套件性比較差,一旦新增一個路由,就會讓你把所有的路由重新設定一遍,甚至還有單點問題,當傳輸節點中某一個路由出現故障時,資料基本不會饒過這個路由,需要管理員把路由重新設定才能繼續傳送。
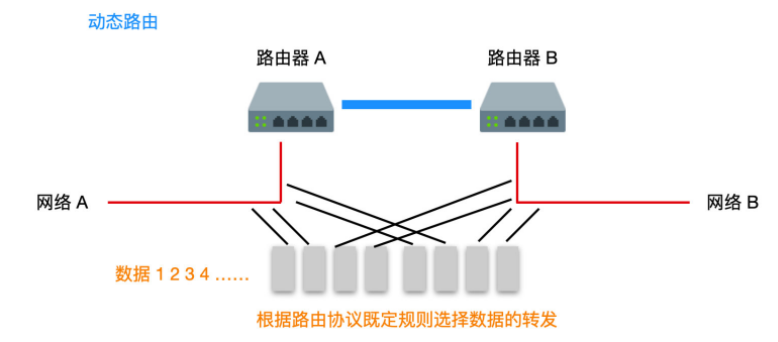
使用動態路由也需要手動設定一些東西,只不過需要設定的是路由協定,每個路由協定的複雜程度不同,所以設定的難以程度也不同,比如 RIP 協定的設定過程就比較簡單,OSPF 的設定過程就比較繁瑣。不過一旦設定完成後,如果要新增加一個路由,就只需要設定新增加的單個路由就可以,而且避免了單點問題,動態路由能夠選擇其他路徑從而繞過故障路由。
雖然靜態路由和動態路由都各有利弊,但是你把他們結合以來一起使用就可以了。成年人全都要。
路由協定
上面討論了動態路由會根據網路情況動態調整資料的轉發路徑,那麼這種行為方式是以什麼為基礎的呢?
答案是通過路由之間相互交換路由表來實現的。路由器之間會在合適的時間交換路由表,通過這種方式,可以讓網路之間所有的路由器都能夠動態調整資料的轉發路徑。當網路情況發生變化時,路由器之間彼此交換的路由資訊會告知對方網路的這種變化,通過資訊擴散使所有路由器都能得知網路變化。
常見的動態路由協定有RIP、OSPF、BGP、MPLS 等,根據不同的自治系統還可以分為 IGP(內部網路關協定) 和 EGP(外部閘道器協定)。這個內外有啥區別呢?
這就需要先了解一下什麼是自治系統:
一個自治系統(AS)就是處於一個 ISP 網路服務提供商管理控制下的路由器和網路群組,它可以是一個路由器直接連線到 LAN 上,同時連線到 Internet 上,也可以是由企業骨幹網互聯的多個區域網。
自治系統內部的動態路由採用的是域內路由協定 IGP,而自治系統之間的路由控制採用的是域間路由協定 EGP。IGP 和 EGP 又可以叫做內部網路關協定和外部閘道器協定。IGP 和 EGP 是相輔相成的關係,沒有 EGP 就不可能實現在不同機構之間的通訊,沒有 IGP 也就不可能實現自治系統的內部通訊。IGP 協定可以細分為 RIP、RIP 2、OSPF 等眾多協定。EGP 協定使用的是 BGP 協定。
我們下面就來認識一下這些協定。
RIP 協定
RIP 的全稱是 Routing Information Protocol,路由資訊協定。它是 IGP 中最先得到廣泛應用的一種協定,就像很多剛誕生的萌芽一樣,最開始一定是非常簡單的。
RIP 協定要求每個路由器都要維持一個集合,這個集合主要記錄了路由器到目的網路所走過的距離,如果路由器與目的網路直接相連,那麼這個距離就是 1 ,否則,在路由器到目的網路的這段距離中,只要走過一個路由器,它的距離就會 + 1,這個距離也稱為跳數(hop count),也就是說,每經過一個路由器,跳數就會 + 1,不過,這個跳數是有次數限制的,最大不能超過 15,所以,由此可見,RIP 只適用於小型網際網路。
RIP 不能在兩個網路之間使用多個路由,相反的,它會選擇一條途經路由最少的線路進行傳輸,哪怕選擇這條最少路由傳輸的線路時延大也沒關係。
由此我們可以歸納出 RIP 協定的兩個特點:第一個特點就是它只會和相鄰的路由器交換訊息,那麼這個"相鄰"該如何判斷呢?如果兩個路由器之間的通訊不需要再經過另一個路由器,就說這兩個路由器是相鄰的。RIP 還規定不相鄰的路由器不會交換資訊。第二個特點就是說每個路由器會毫不保留的交換自己知道的全部資訊,也就是交換彼此的路由表。
還有一個非常重要的問題我們沒有考慮到,既然我們知道 RIP 協定規定了交換資訊的規則,那它是如何規定交換的時間間隔呢?
RIP 協定規定按照固定的時間間隔交換路由資訊,當路由資訊發生變更時,它會及時向相鄰的路由器通過交換路由表的方式進行更新,更新的原則是路由器要找出最短路徑,使用的是距離向量演演算法。
距離向量演演算法
對於每一個相鄰路由器傳送過來的 RIP 報文,通常會進行以下操作:
-
修改 RIP 報文中的內容,會把 RIP 報文中的"下一跳地址" N 、"距離" D 欄位的值 + 1。
-
對修改後的 RIP 報文中的每一個內容,進行以下步驟:
- 如果原來路由表中沒有目的網路的地址 R ,就會修改 RIP 報文中的目的網路地址。
- 如果原來路由表中有目的網路的地址,而且下一跳路由的地址是 N,就把收到的 RIP 報文內容替換原路由表中的內容。
- 如果原來路由表中有目的網路的地址,但下一跳路由的地址不是 N,如果收到的 RIP 報文中的距離 D 小於路由表中的距離,就會進行更新。
-
如果一段時間內沒有收到相鄰路由器的路由表更新訊息,就把此相鄰的路由器標記為不可達,並把距離設定為 16,距離 16 表示為不可達。
RIP 協定報文格式
RIP 協定現階段主要有兩個版本:RIP 1 和 RIP 2 ,現在更多的使用 RIP 2 的版本,RIP 2 協定RIP 協定使用 UDP 協定進行傳輸控制。
RIP 1 和 RIP 2 的主要區別如下:
- RIP 1 是一個有類路由協定,RIP 報文中不包含子網掩碼,這就要求網路中所有裝置使用相同的子網掩碼,而 RIP 2 是一個無類路由協定,它使用子網掩碼。
- RIP 1 在傳送更新包的時候是使用的廣播方式進行的,而 RIP 2 預設使用的是組播,當然 RIP 2 也支援廣播傳送,但是使用組播的方式既能夠滿足需要,又能夠節省頻寬。
- 第三個區別是 RIP 2 支援明文或者是 MD5 驗證,要求兩臺路由器在同步路由表的時候必須進行驗證,這樣可以加強安全性。
下面是 RIP 2 的報文格式。
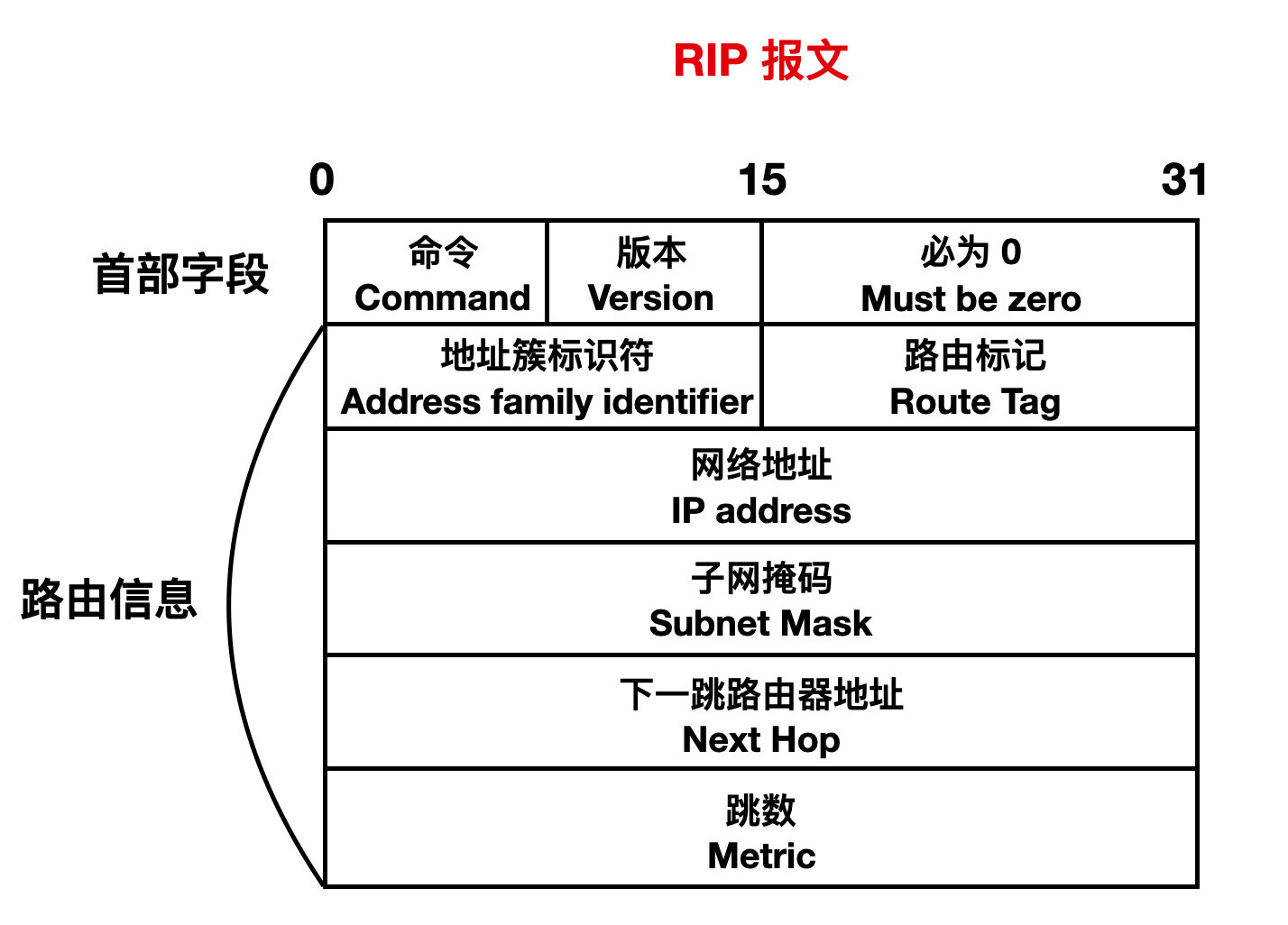
RIP 2 報文可以細分為首部部分和路由部分。
首部部分主要有命令、版本和必為 0欄位,其中命令標識報文的型別,1 標識 Request 請求,向相鄰路由請求全部或者部分路由資訊;2 標識 Response 請求,向相鄰路由器傳送自己全部或者部分資訊。然後是 RIP 版本,表示是 RIP 1 還是 RIP 2。後面的必為 0 其實主要為了要補齊 4 位元組設計的。
下面是 RIP 報文的路由資訊:
地址簇識別符號:其值為 2 時表示 IP 協定。對於 Request 報文,此欄位值為 0。路由標記:這個一般填入自治系統號,有可能存在 RIP 收到自治系統以外的路由選擇資訊。網路地址:這個就表示目的網路地址。子網掩碼:目的地址的子網掩碼。下一跳路由器地址:表示路由器的下一跳地址,如果為 0.0.0.0,則表示釋出此路由的路由器地址就是最優下一跳地址。跳數:需要經過的路由數量。
RIP 存在一個問題是當網路故障時,會經過較長時間才能將資訊同步到所有的路由器。
RIP 的主要問題以及解決辦法
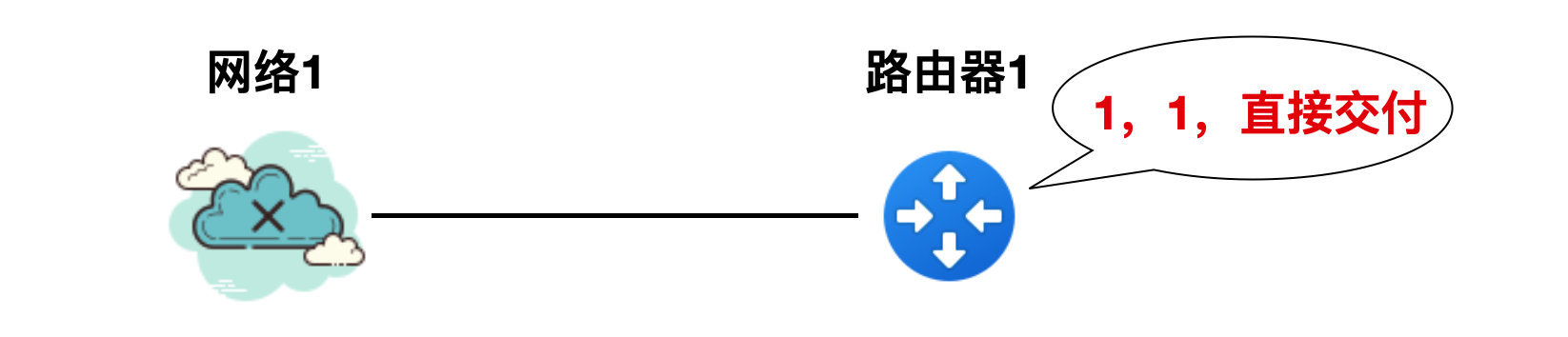
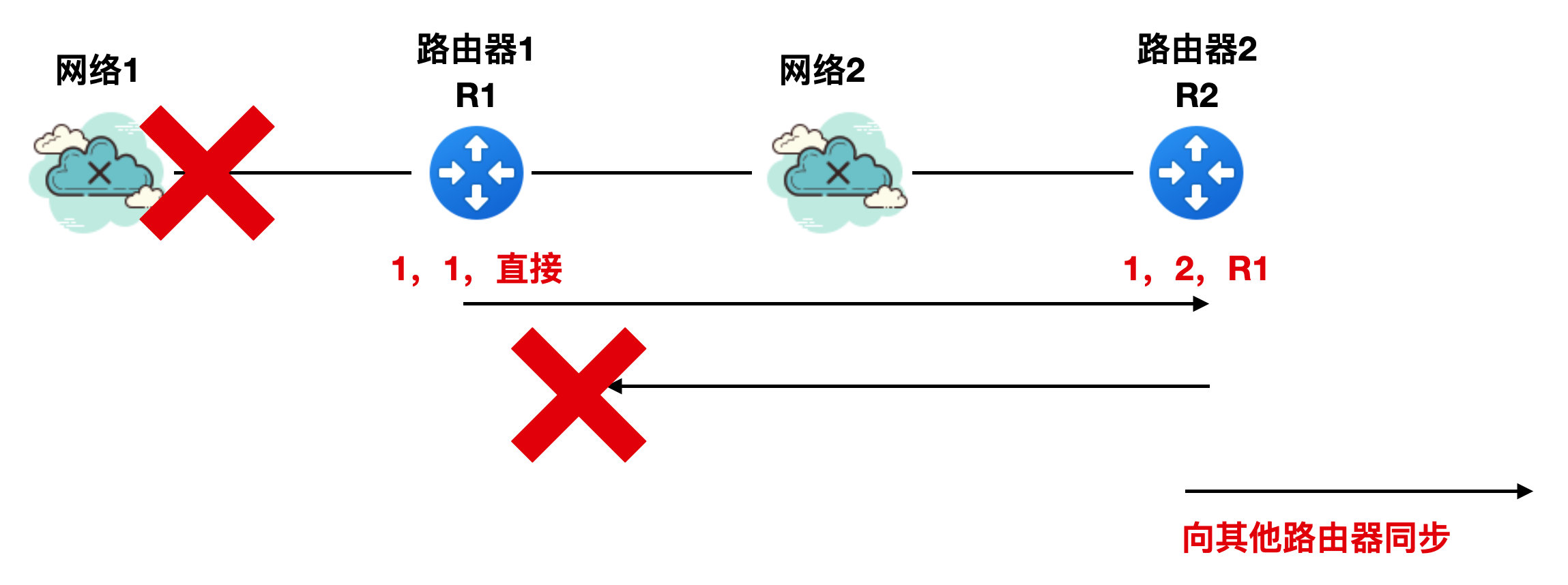
如下圖所示,有一個網路1 和路由器 1,路由器 1 到網路 1 的 RIP 報文中的路由資訊(為了方便描述,省略其他報欄位資訊)是"1,1,直接交付",這個意思就是說:到網路 1 的距離是 1 個路由器的跳數,是直連的方式。
此時加進來了網路 2 和路由器 R2,R2 到網路 1 的 RIP 報文是 "1,2,R1",它表示路由器 R2 到網路 1 的距離是 2 跳,下一個路由器是 R1。
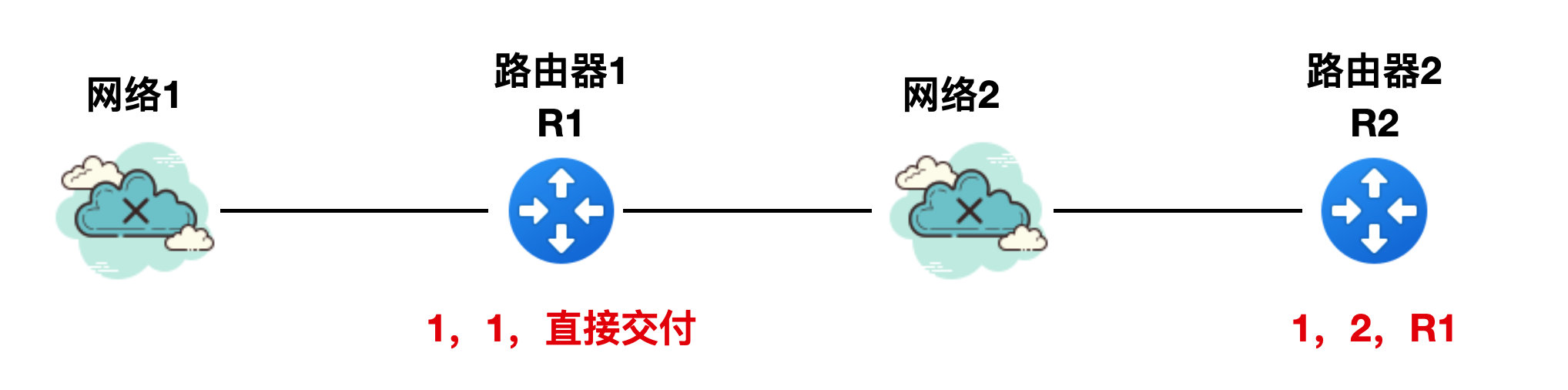
好了,上面兩幅圖中都能正常傳送 RIP 報文,相安無事。此時網路 1 出現了故障,導致 R1 無法直接到達網路 1,那麼R1、 R2 此時 RIP 的報文該如何傳送呢?
實際上,與網路 1 直接相連的是 R1,所以 R1 首先知道網路 1 是不可用的,一旦 R1 知道網路 1 不可用,就會修改 RIP 報文為 "1,16,直接",然後向 R2 同步路由表,如下圖所示:
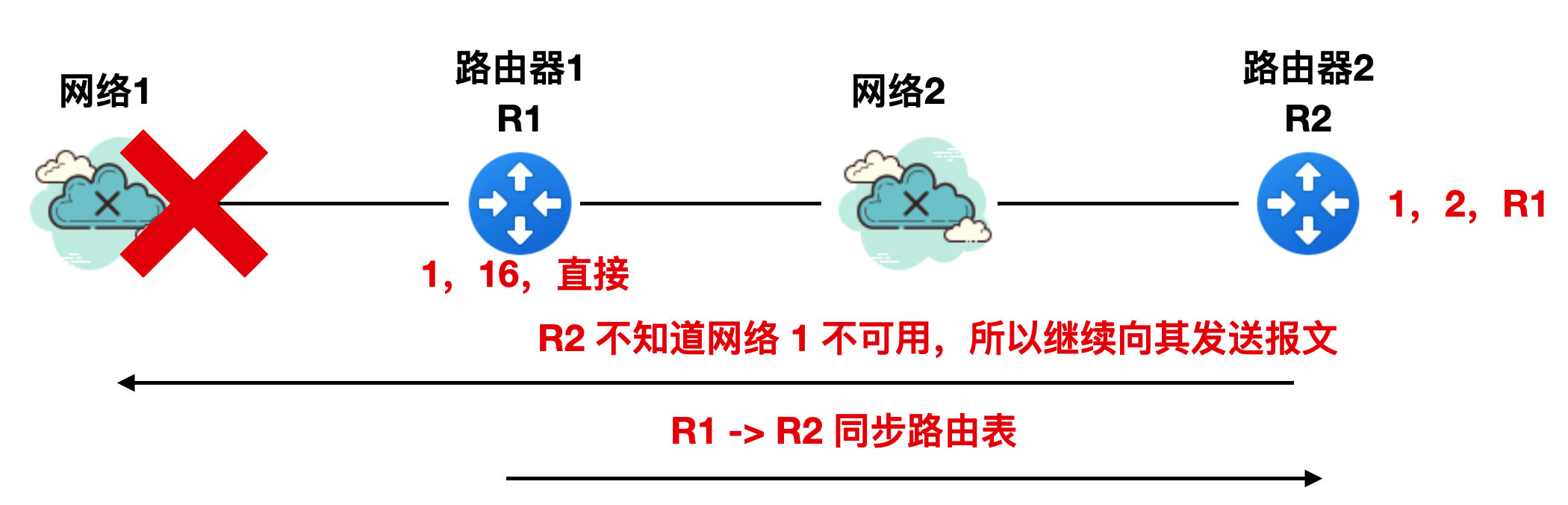
但是由於 RIP 協定本身的特性,這個路由表同步過程沒那麼快速的完成,而此時 R2 不知道網路 1 不可用,所以它還是繼續經過 R1 向網路 1 傳送報文。
一旦 R2 的報文傳送給 R1 ,R1 就會認為經過 R2 可以到達網路 1 ,所以 R1 就會把 RIP 報文修改為 "1,3,R2",表明我到網路 1 的距離是 3 跳,下一個路由器要經過 R2 ,如下圖所示
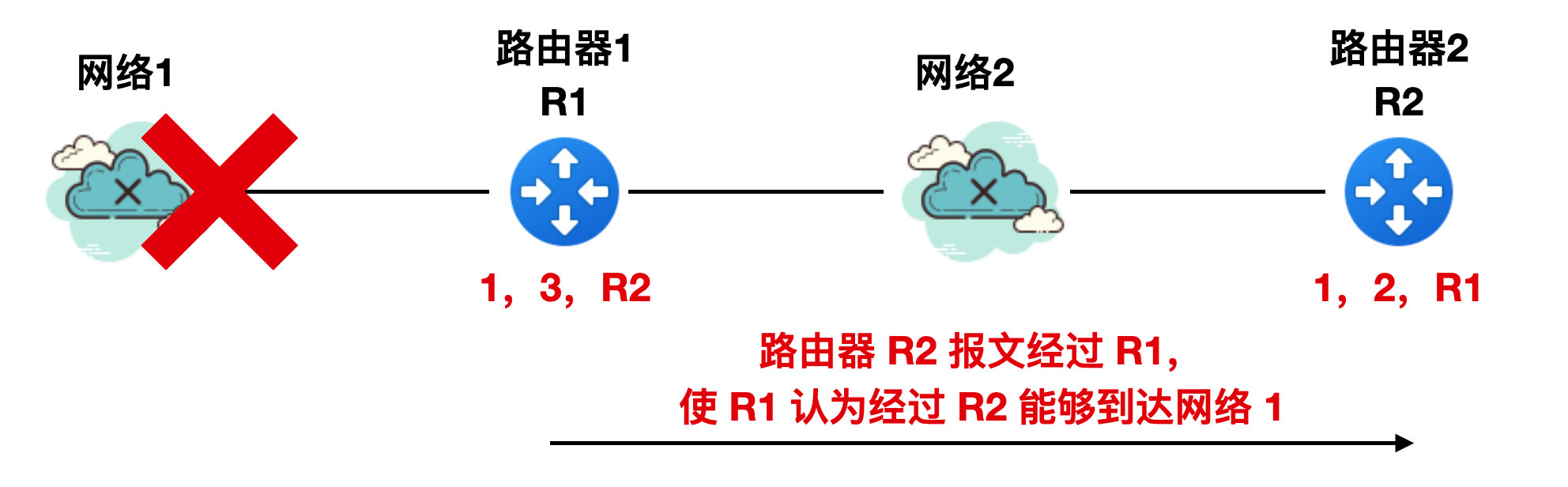
同理,R2 收到 R1 的報文後會將其 RIP 報文修改為 "1,4,R1"。。。。。。然後不斷進行 R1 和 R2 的迴圈。
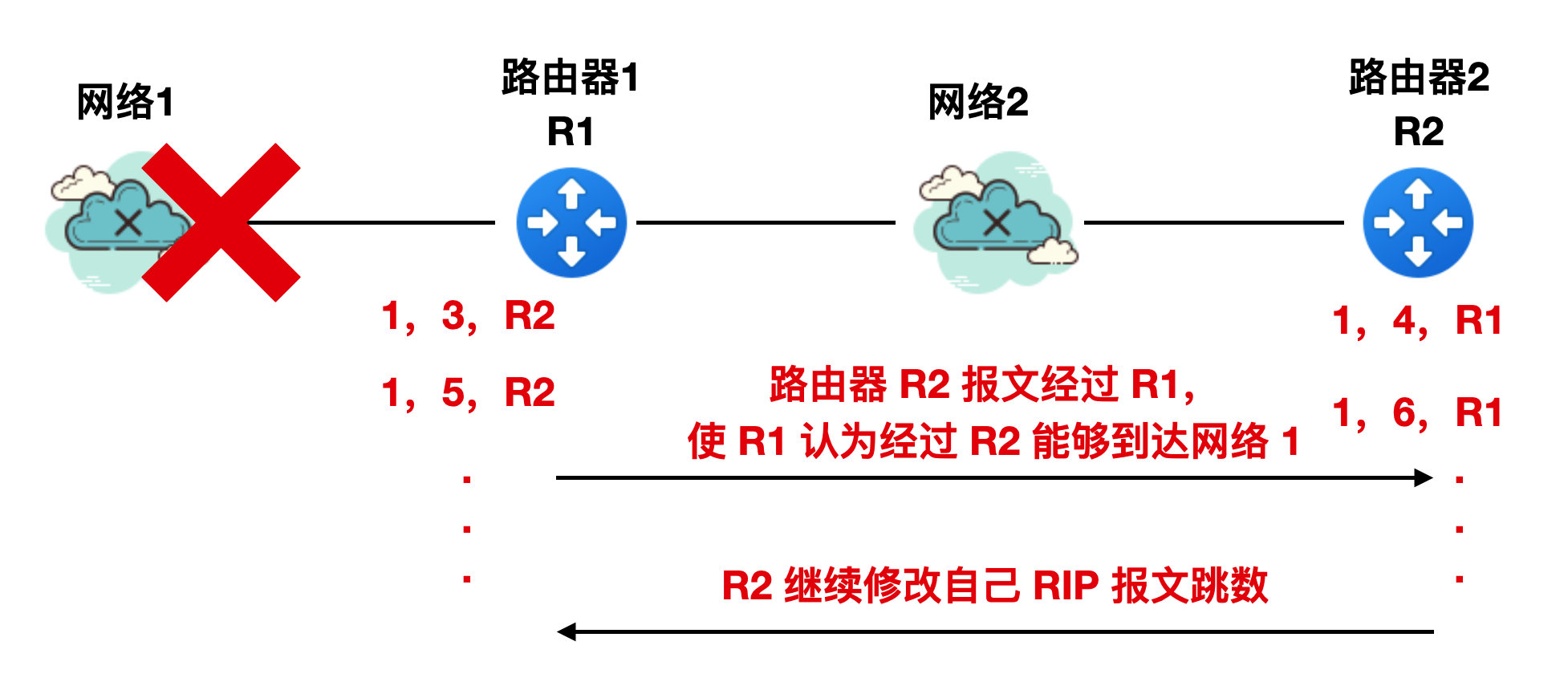
這個迴圈什麼時候終止呢?
直到 R1 和 R2 的跳數都增大到 16 時,R1 和 R2 才直到網路 1 是不可達的。這不就是白乾麼?不過這就是 RIP 協定的一個特點。這個特點通俗一點來講就是好訊息傳播的快,壞訊息傳播的慢。
有沒有什麼方法能夠補救一下這種傳播慢的方式?
一種方式就是控制跳數為 16,這相當於是從報文傳輸時間上進行控制;二是規定路由器不會再把收到的訊息反向傳輸給傳送端,這種方式被稱為水平分割,如下圖所示
還有一種方式就是當路由資訊發生變化時,不等待一定的時間(例如 30 秒)而是直接傳送出去,這看起來是更容易想到的方式,想想也是,網路都斷了,還要等待 30 s 才傳送,真的很雞肋。
總之,因為其協定特徵和報文限制了其只能用在小型網路中。
OSPF 協定
OSPF 是為了克服 RIP 的缺點在 1989 年開發出來的,OSPF 稱為 開放最短路徑優先 ( Open Shortest Path First ) 協定。注意雖然它被叫做最短路徑優先協定,但是卻並不能說明其他協定不是最短路徑優先的,一般自治系統內的路由器都會選擇一個最短路徑來進行傳輸。
OSPF 使用的是分散式的鏈路狀態協定,而非像 RIP 那樣的距離向量協定。和 RIP 協定相比,OSPF 主要有下面這些變化:
- OSPF 會向自治系統內的所有路由器傳送訊息,OSPF 首先會向相鄰的路由器傳送訊息,然後相鄰的路由器又向與之相鄰的路由器傳送訊息,漸漸的會同步所有的路由器。而 RIP 僅僅會向周圍幾個距離比較近的路由器傳送訊息。
- OSPF 傳送的訊息就是路由器相鄰的所有路由器的鏈路狀態,這些狀態包括了路由器都與哪些路由器相鄰,以及鏈路的 metric,其實就是 RIP 中的跳數。對於 RIP 協定來說,它僅僅會向相鄰的路由器同步整個路由表。
- OSPF 會在鏈路發生變化時向所有路由器同步訊息,而 RIP 在不管網路狀態是否發生變化,都會定期交換路由表資訊。
由此來看,OSPF 和 RIP 的區別還是比較大的。
由於 OSPF 會定期向周圍的路由器同步鏈路資訊,因此這些路由器可以建立一個鏈路狀態資料庫,每一個路由器都知道自治系統內有多少路由器,以及和這些路由器的 metric,因此每個路由器都可以以自己為根來構建一個路由表。RIP 協定雖然也能知道這些資訊,只不過它無法知悉整個自治系統內的所有路由資訊。
說了這麼多,那為什麼 OSPF 協定為啥比 RIP 協定更適用於大型網路?
首先 OSPF 沒有跳數限制,而且 OSPF 會將自治系統劃分為更小的區域,每個區域都有一個標識,當然區域的劃分也是有範圍的,最大不能超過 200 個,下面就是一個 OSPF 對自治系統內不同區域的劃分。
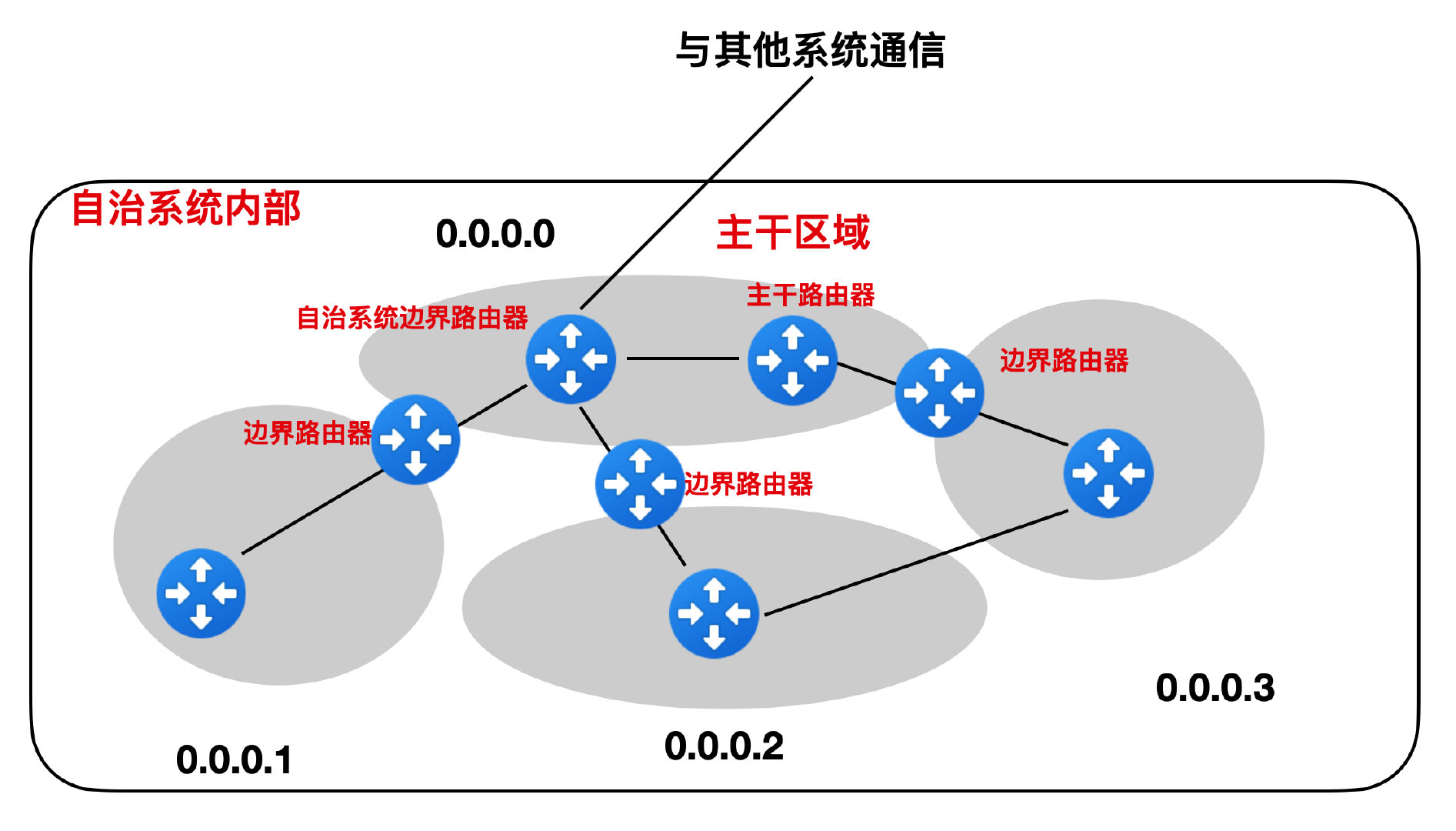
這麼做的好處是能夠提高區域內的訊息傳輸效率,減少通訊量。想象一下,如果是一個特別大的自治系統內部不做任何劃分的話,那麼每個路由器同步一次訊息需要多大的通訊量啊。
OSPF 的劃分採用的是一種分層的方式,分為上下兩層,在上層的叫做主幹區域,主幹區域的識別符號規定為 0.0.0.0,主幹區域的作用主要用來連線其他在下層的區域,每個區域內部都有負責和主幹區域路由器通訊的中間路由器,這個中間路由器叫做 區域邊界路由器,而主幹區域內的路由器叫做 主幹路由器,主幹路由器可以是區域邊界路由器,在所有的主幹路由器中,還有一個負責和外部自治系統進行通訊的路由器,這個路由器叫做自制邊界系統路由器。
分層思想雖然解決了 OSPF 內通訊量龐大的問題,但是通訊的種類大大增加,讓 OSPF 這個協定變的很複雜。不過,分層的思想是極其重要的,因為任何大型網路也好,作業系統也好,都會體現分層的思想,畢竟解耦是一門藝術。
OSPF 沒有使用任何傳輸層協定進行通訊,相反的它會直接傳輸 IP 資料包。
那麼問題來了,為什麼還有協定不會使用傳輸層協定傳輸報文呢?
因為 OSPF 需要執行可靠的多播操作,它會盡可能和自治系統內的多個鄰居路由器通訊,而 TCP 是不支援多播的,並且 UDP 無法保證可靠傳輸,所以 OSPF 實現了自己的傳輸機制,從而繞過了 TCP 和 UDP。
OSPF 構成的封包不大,這樣可以減少通訊量,還有一個好處就是不必將封包進行分片,因為但凡分片後的資料片丟失任意一個,就無法組裝成傳送的封包,必須進行重傳。
下面是 OSPF 的報文以及各個欄位的含義。
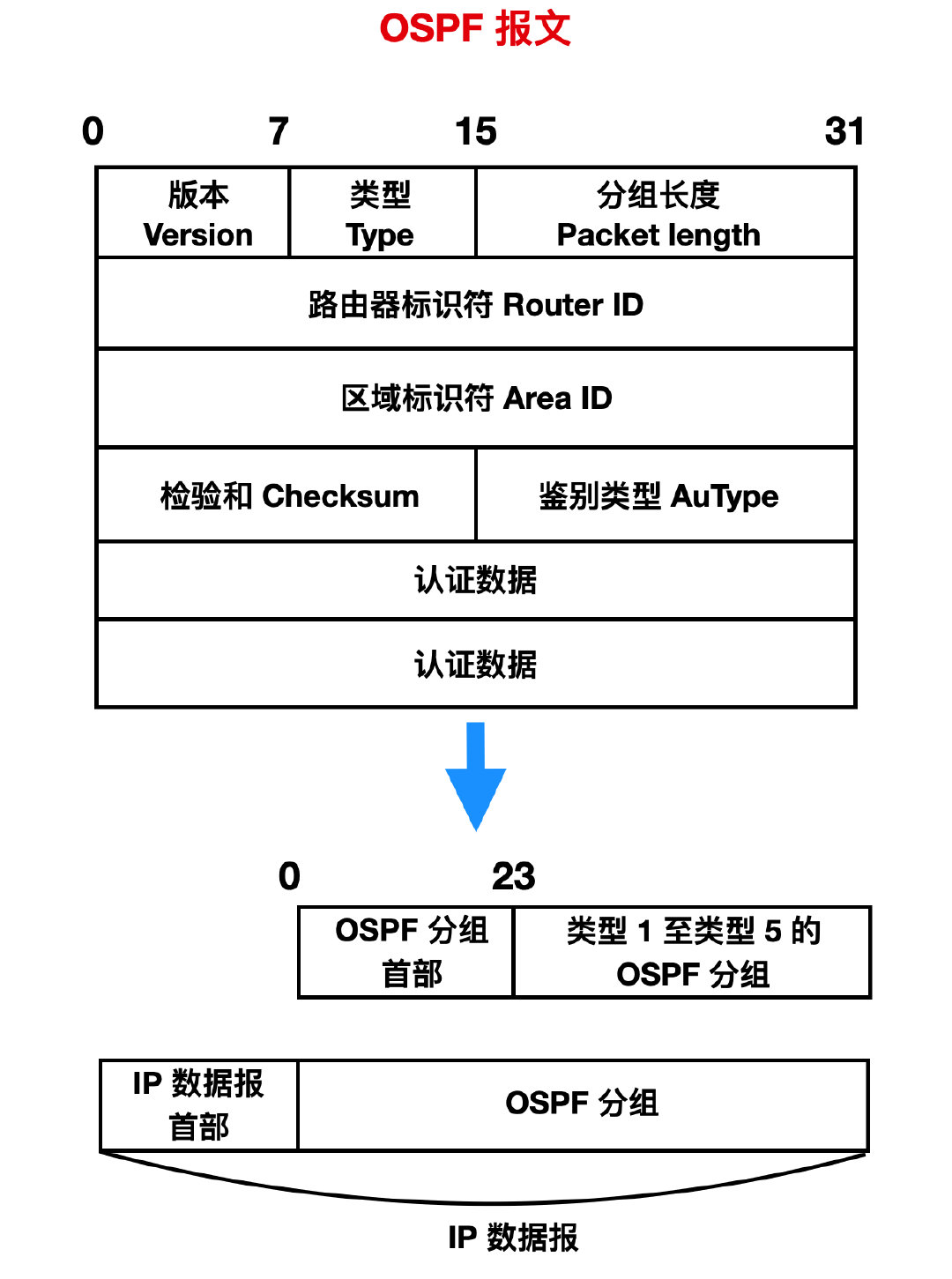
( 1 ) 版本 Version :當前 OSPF 版本號是 v2 ,主要標準是 RFC 1583 和 RFC 2328。
( 2 ) 型別 Type:OSPF 的報文型別有五類,這個型別可以表示任何一類 OSPF 報文。
( 3 ) 分組長度 Packet length:包括 OSPF 首部在內的分組長度,以位元組為單位。
( 4 ) 路由器識別符號 Router ID:標誌這個分組是由哪個路由器介面發出的,這個路由器的 IP 地址。
( 5 ) 區域識別符號 Area ID:表示這個分組屬於哪個區域,它的一個識別符號。
( 6 ) 檢驗和:用於檢測分組中是否出現差錯。
( 7 ) 鑑別型別:目前只有兩種鑑別型別,0 (不用) 和 1(口令)。
( 8 ) 鑑別:鑑別型別為 0 是鑑別就填 0 ,為 1 時鑑別就填入 8 個字元口令。
OSPF 除了上述這些報文的特點之外,還有一些其他特點:
( 1 ) 如果到一個目的網路有多條相同 metric 的路徑,那麼 OSPF 會通過負載均衡的方式來使用每一條路徑。
( 2 ) OSPF 允許管理員手動的設定 metric,如果是敏感的業務就可以設定較高的 metric,如果對於敏感性要求沒那麼高,就可以設定較低的 metric。 這在 RIP 中根本不可能,RIP 只允許一條最短路徑。
( 3 ) OSPF 分組具有鑑別功能,這保證了傳輸鏈路資訊的安全性。
( 4 ) OSPF 支援可變長度的子網劃分和無分類編址 CIDR 。
( 5 ) 由於網路中的鏈路狀態經常會發生變化,因此 OSPF 會讓每一個鏈路帶上一個 32 位的序號,序號越大狀態越新。
上面說到 OSPF 有五種報文型別,主要有下面這五種:
- 型別 1 :hello 報文,這個報文會定期以組播的形式傳送,主要作用就是維護和鄰居路由器的可達性,確保能夠雙向通訊,但是並不是所有的報文都會建立關係,必須和報文中的所有欄位都匹配後,才能建立。下面是 hello 報文的欄位。

Nestwork Mask:網路掩碼。
Hello Interval:傳送 hello 報文的時間間隔。預設情況下,OSPF 在 P2P 或廣播型別的介面上傳送 hello 間隔為10 s,在 NBMA 和 P2MP 型別介面上hello間隔為 30 s。
Options:可選項,路由器通過設定 options 欄位來通告自己能夠支援某種特性
Router Pri:路由器優先順序
Router Dead Interval :路由器失效時間。預設情況下該路由介面為 hello interval 的 4 倍關係,如果在此時間內未收到鄰居發來的 hello 報文,則認為鄰居失效。
Designated Router:指定路由器。如果欄位為 0.0.0.0 表示 DR 尚未指定或者沒有 DR。
Backup Designated Router:備份指定路由器。網路中 BDR 的介面 IP 地址。如果欄位為 0.0.0.0 表示 BDR 尚未指定或者沒有 BDR。
Neighbor:鄰居。此處填充的是鄰居的 Router ID。
- 型別 2 :資料庫分組(Database Description),用於向相鄰站點同步自己的鏈路資料庫中的鏈路狀態資訊。
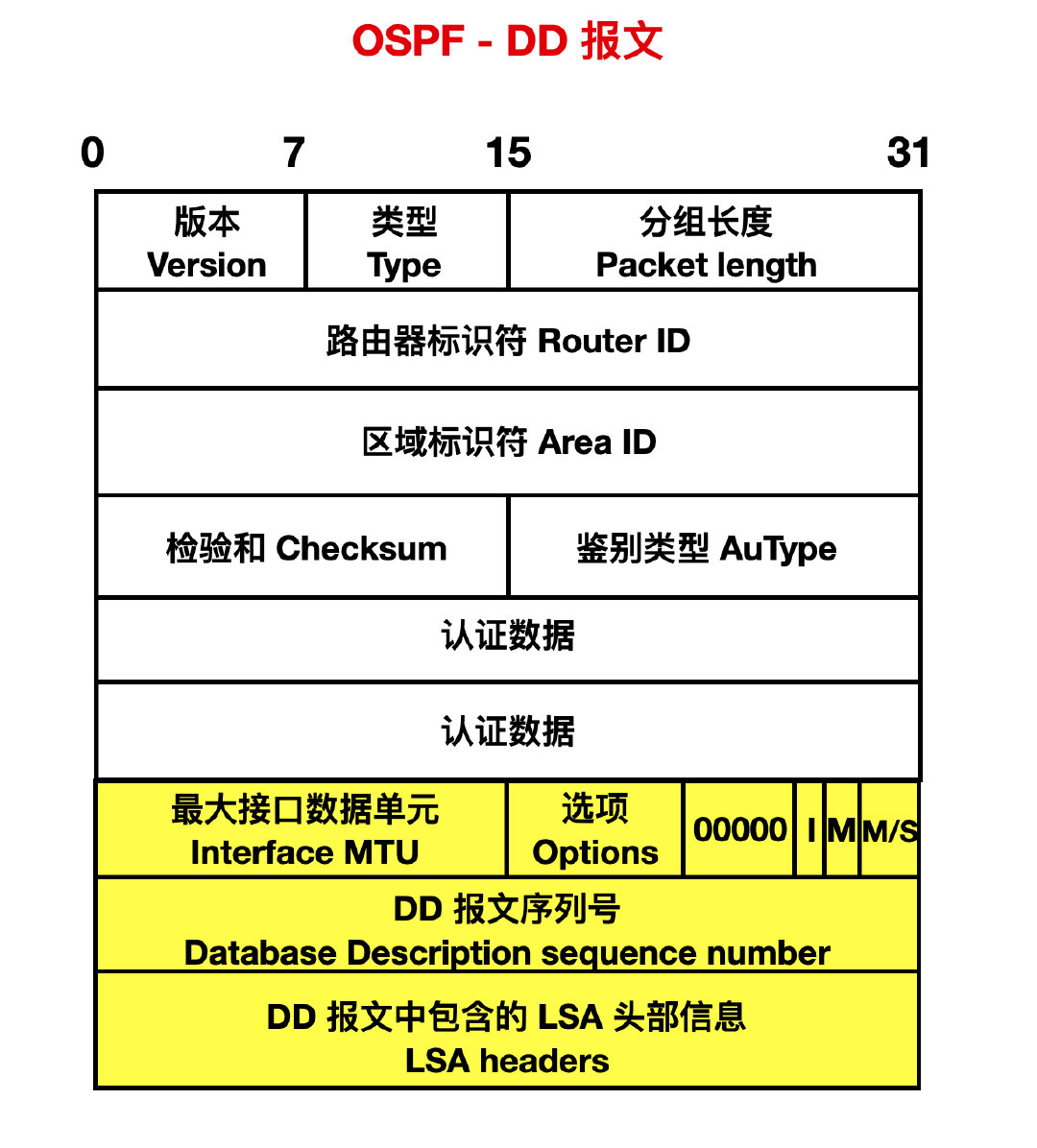
Interface MTU:最大介面資料單元,由此介面發出最大的 IP 資料長度,預設為 0 。
I:initial bit,初始標誌位,當連續傳送多個 DD 報文時,如果此報文時第一個就是 1 ,否則就是 0 。
M:more ,如果設定為1表示後面還有其他的 DD 報文,如果這是最後一個 DD 報文則設定為 0。
M/S:此位設定為 1 表示為 master 路由器。
DD sequence number DD 報文序列號。主從雙方利用序列號來保證 DD 報文傳輸的可靠性和完整性。
LSA headers:DD 報文中所含 LSA 的頭部資訊。
- 型別 3:鏈路狀態請求 ( Link State Request ) 分組,用 LSR 報文請求完整的 LSA 訊息。
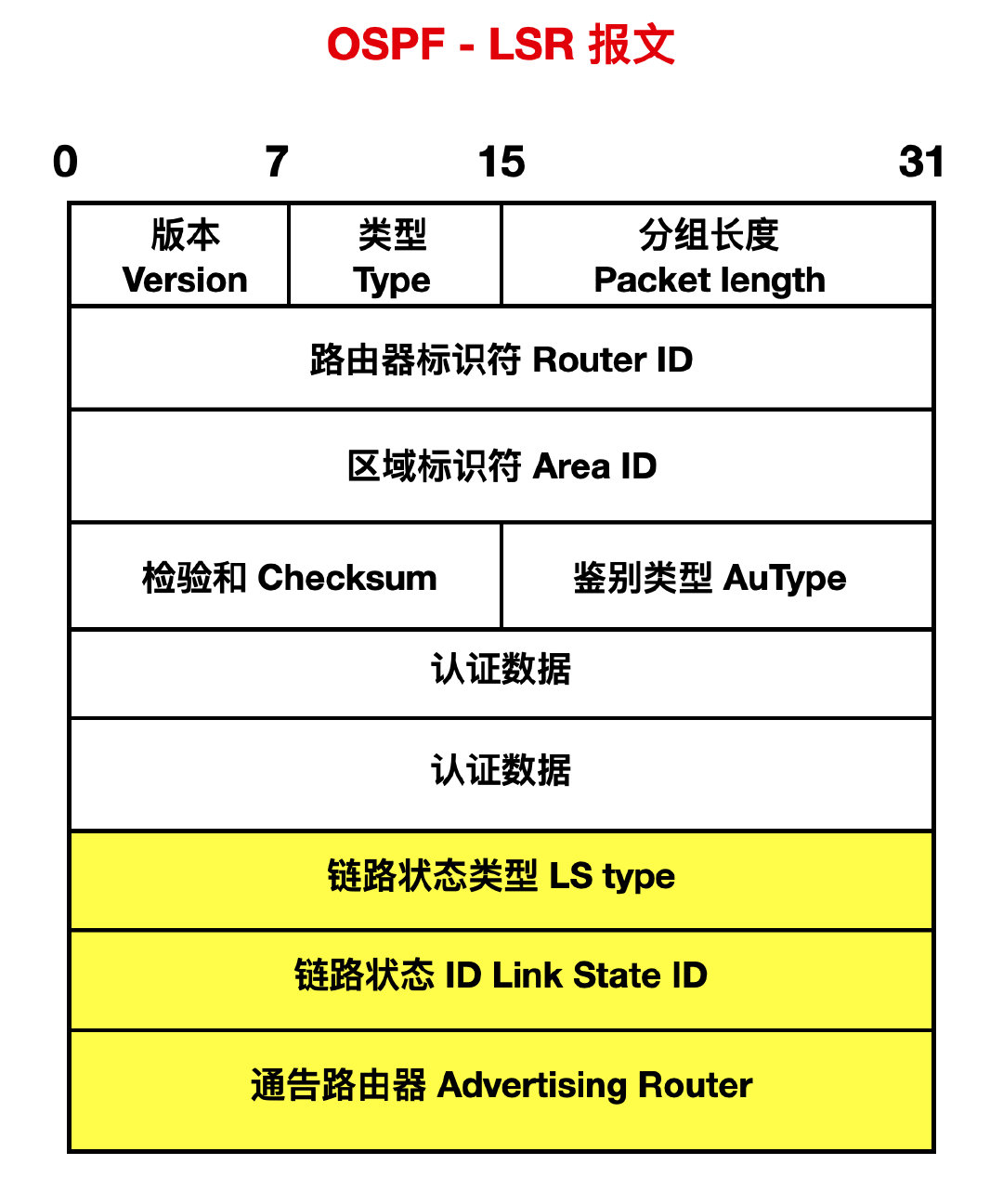
LS Type :鏈路狀態型別。
Link State ID:LSA 標識。
Advertising Router:產生該 LSA 的路由器 Router ID。
- 型別 4: 鏈路狀態更新 ( Link State Update ) 分組,
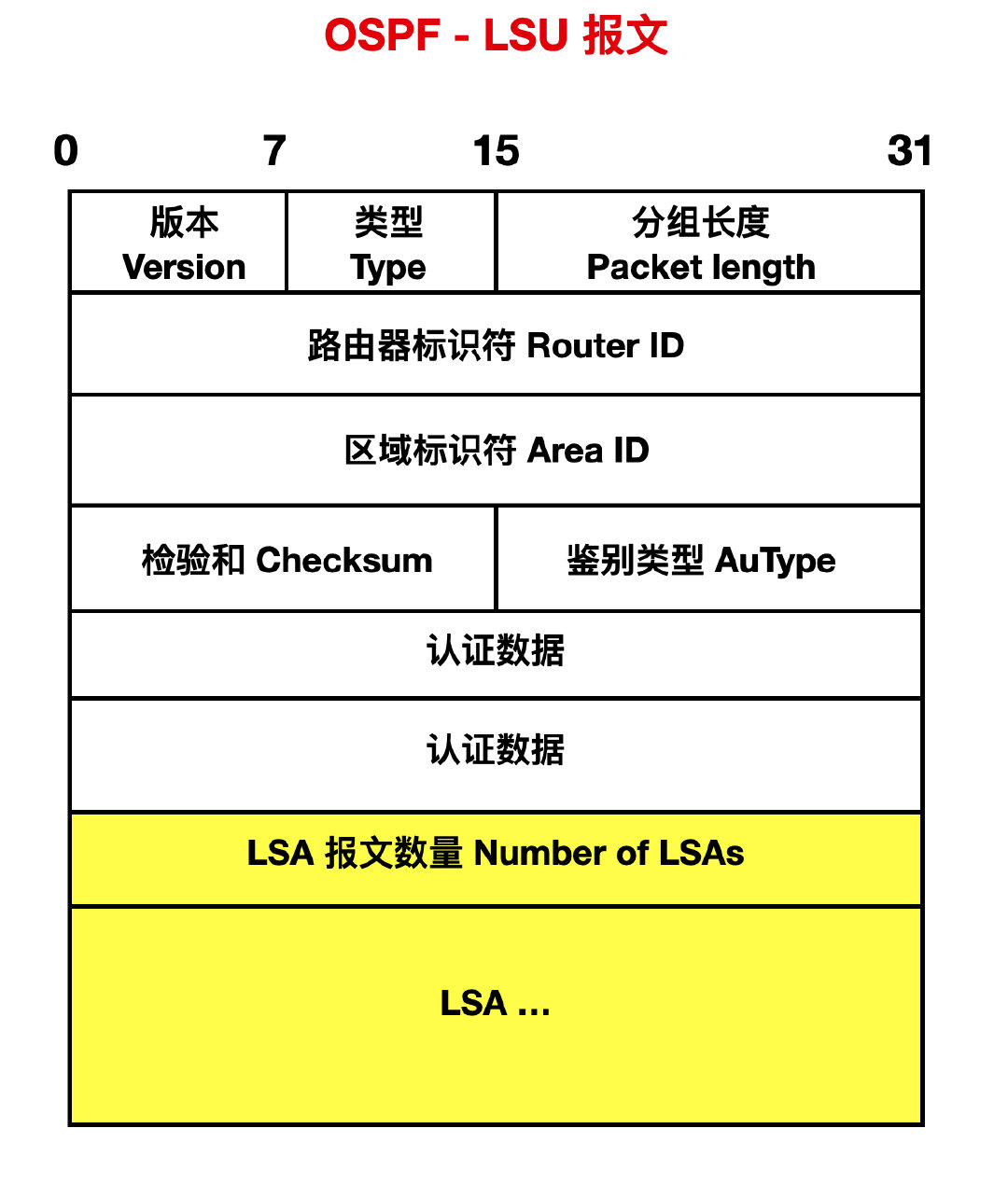
路由器收到 LSR 後會以 LSU 報文進行迴應,在 LSU 報文中就包含了對方請求的 LSA 完整的資訊。
詳細的 LSA 報文通常會分開來寫,包括 LSA Header,Router-LSA,Network-LSA。
- 型別 5: 鏈路狀態確認 ( Link State Acknowledgment ) 分組,用來對接受到的 LSU 報文進行確認。內容是需要確認的 LS A的 header,一個 LSACK 報文可以對多個 LSA 進行確認。
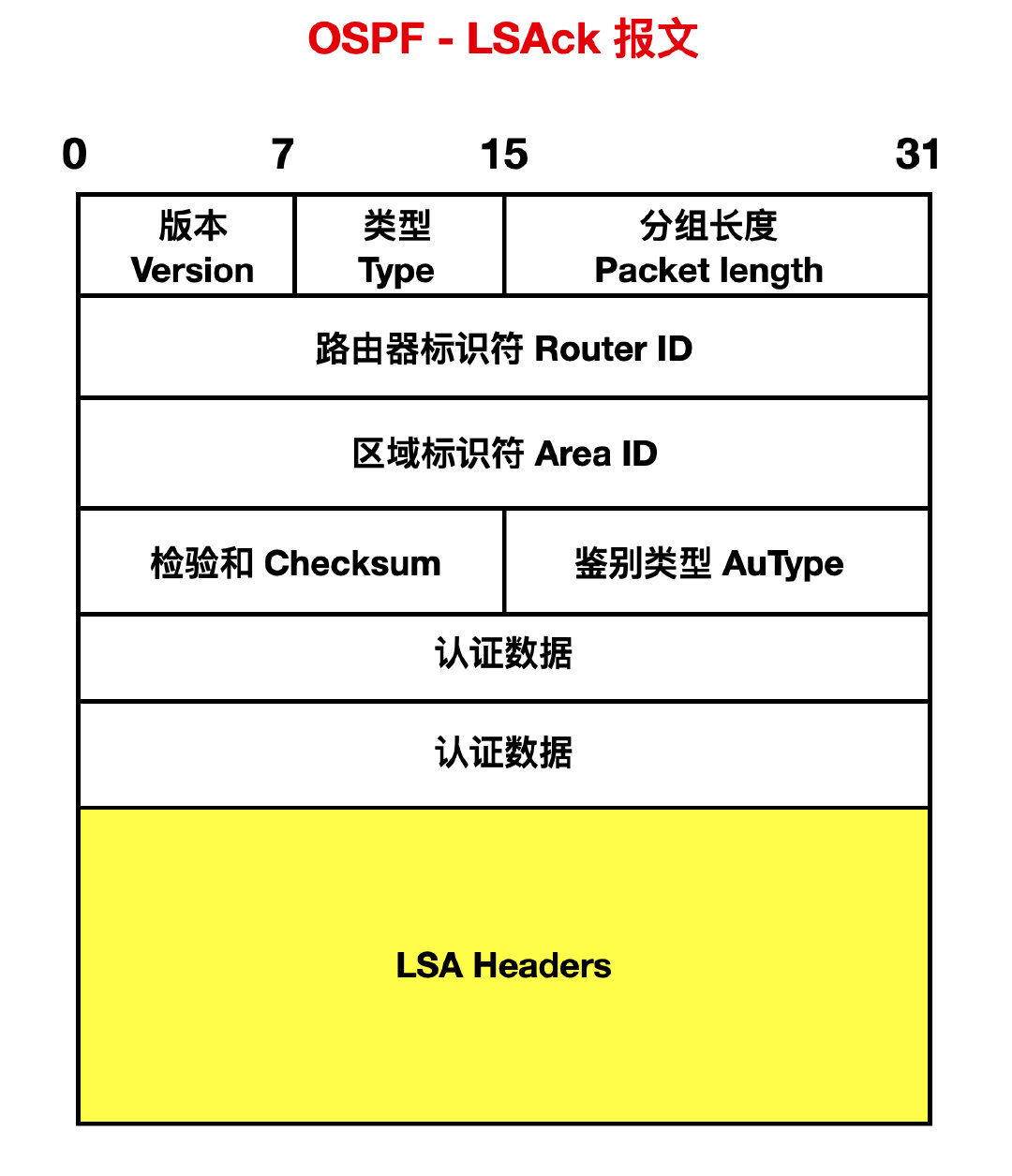
OSPF 規定,每隔 10 s 就要交換一次 Hello 分組,來判斷網路鏈路是否可達,這就很像某種心跳檢測機制。路由表就會根據 Hello 分組的檢測結果來制定的。在正常情況下,絕大多數分組都是 Hello 分組,如果在 40 s 內沒有收到發過來的 Hello 分組,就會認為相鄰路由器不可達,應該立刻修改鏈路狀態資料庫中所記錄的鏈路資訊,還要重新制定路由表。
其他四種 OSPF 報文都是用來進行鏈路狀態資料庫同步的。這個同步的意思就是說不同路由器的鏈路狀態相同。兩個同步的路由器被稱為完全相鄰的。並不是在物理距離上離的比較近就被稱為相鄰,而是要判斷它的鏈路狀態。
總結一下上面五種報文型別的用途:通過傳送 Hello 報文確認是否連線;通過 DD 分組來進行鏈路狀態資訊同步;在路由執行階段,通過鏈路狀態請求包請求路由控制資訊,然後由鏈路狀態更新包接收路由同步資訊,最後通過鏈路狀態確認包通知已接收到路由控制資訊。
當新加一個路由器開始工作時,它不知道應該向誰同步鏈路資訊,所以它需要通過分組來判斷相鄰的路由器都有哪些,以及向相鄰路由器傳送的 metric 是多少,如果所有的路由器都把自己的狀態資訊對全網進行廣播的話,那麼各個路由器把鏈路狀態資訊組合起來就能得到狀態鏈路資料庫,不過這樣開銷太大了。
所以,OSPF 通過使用資料庫分組和相鄰路由器交換鏈路資訊狀態來得到全網的狀態鏈路資料庫,下面是組合成狀態鏈路資料庫所需要傳送過的 OSPF 報文。
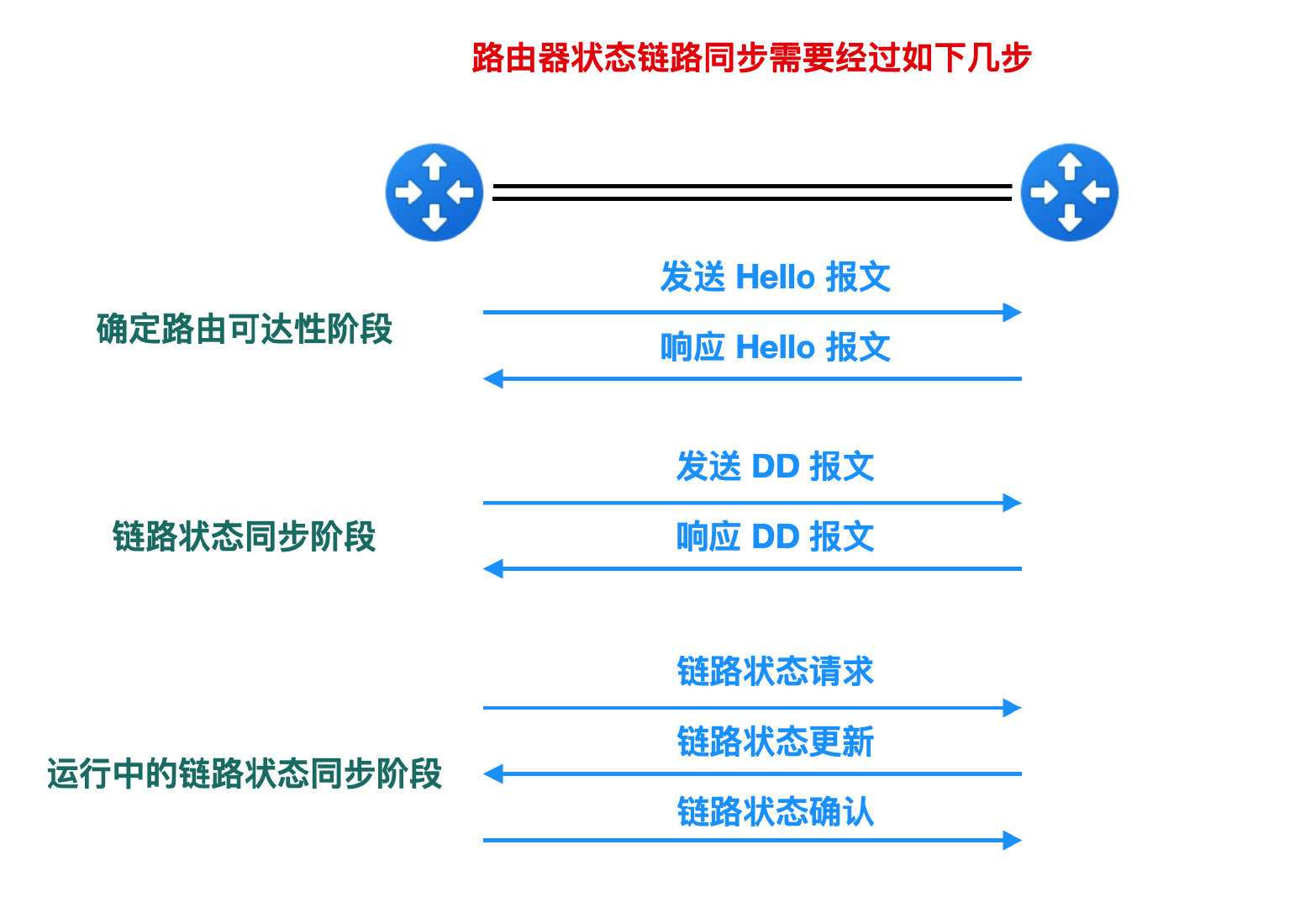
這樣一來,就會建立狀態鏈路資料庫,在網路執行過程中發生路由狀態變更的話,只需要傳送鏈路狀態更新分組即可,更新完成後需要傳送鏈路狀態確認報文。
而且 OSPF 不像 RIP 一樣具有好訊息傳播快,壞訊息傳播慢的問題。
原文連結:萬字長文爆肝路由協定!
公眾號乾貨很多,歡迎大家關注。
|
作者:cxuan 出處:https://www.cnblogs.com/cxuanBlog/ 本文版權歸作者和部落格園共有,未經作者允許不能轉載,轉載需要聯絡微信: becomecxuan,否則追究法律責任的權利。 如果文中有什麼錯誤,歡迎指出。以免更多的人被誤導。 |