論文閱讀 Dynamic Network Embedding by Modeling Triadic Closure Process
3 Dynamic Network Embedding by Modeling Triadic Closure Process
Abstract
本文提出了一種利用三元組閉包過程來建模時間序列的方法。
Conclusion
在本文中,我們提出了一種新的動態網路表示學習演演算法,以及一種學習頂點動態表示的半監督演演算法。為了驗證模型和學習演演算法的有效性,我們在三個真實網路上進行了實驗。實驗結果表明,與幾種最先進的技術相比,我們的方法在六個應用中取得了顯著的效果。(基本屬於啥都沒說)
Figure and table
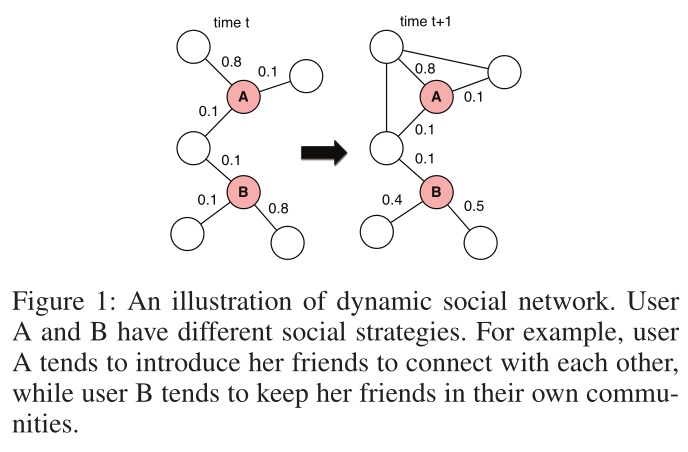
圖1 動態社群網路的例證。使用者A和B有不同的社交策略。例如,使用者A傾向於介紹她的朋友來相互聯絡,而使用者B傾向於將她的朋友留在自己的社群中。
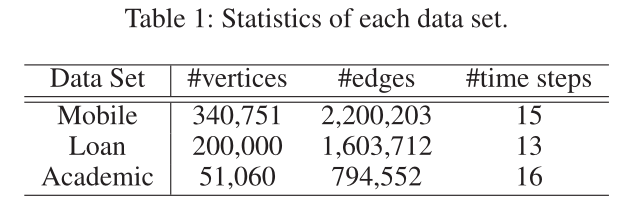
表1 資料集引數

表2 模型表現(應該是測了兩次)
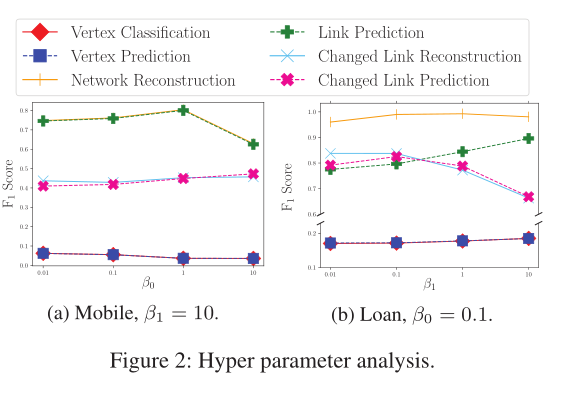
圖2 超引數分析
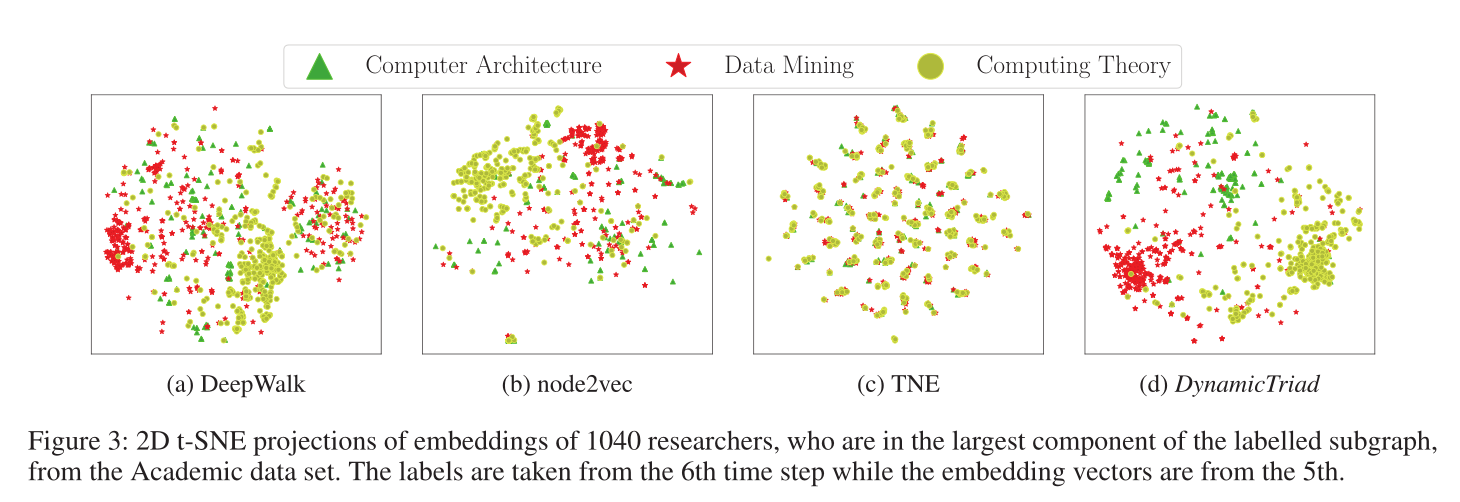
圖3 使用2D t-SNE的視覺化,資料集為academic。
Introduction
There is nothing permanent except change.— Heraclitus
如圖1,作者認為在時間步\(t+1\),A的兩對朋友相互連線,而B的朋友之間仍然沒有連結。此外,使用者B在時間步\(t+1\)時會將精力分散到其他朋友身上,而使用者A則一直專注於發展與時間步t時相同朋友的關係。使用者的不同進化模式反映了他們自己的性格和社交策略之間的差異,這些策略用於滿足他們的社交需求,如與他人建立聯絡。例如,使用者A傾向於相互介紹她的朋友,而使用者B傾向於讓她的朋友在自己的社群中保持緊密聯絡。因此,學習到的表示是否能很好地反映頂點的演化模式是網路嵌入方法的關鍵要求。
在本文中,通過捕捉網路的進化結構特性來學習頂點的嵌入向量。
具體來說 ,本文通過使用三元組的閉合過程來模擬網路結構的動態變化。
本文有三點貢獻
1)我們提出了一種新的動態網路表示學習模型。我們的模型能夠保留網路的結構資訊和演化模式。
2)我們開發了一種用於引數估計的半監督學習演演算法。
3)模型可以在幾個最先進的基線上實現顯著的改進(例如,在鏈路預測方面,F1提高了34.4%)。
Method
Our Approach
Model Description
三元閉合過程:從時間t的一個開放三元組\((v_i,v_j,v_k)\)的範例開始,其中,使用者\(v_i\)和\(v_j\)彼此不認識,但他們都是\(v_k\)的朋友(即\(e_{ik}、e_{jk}∈ E^t\)和\(e_{ij}\notin E^t\))。現在,使用者\(v_k\)將決定是否引入\(v_i\)和\(v_j\),讓它們相互瞭解,並在下一個時間步\(t+1\)在它們之間建立連線。我們自然會假設\(v_k\)將根據她與\(v_i\)和\(v_j\)(在潛在空間中)的接近程度做出決定,這由\(d\)維向量\(x^t_{ijk}\)量化為
其中\(w^t_{ik}\)是在\(t\)時刻\(v_i\)和\(v_k\)的強度(應該是線性變換的可訓練矩陣)
\(\boldsymbol{u}_{k}^{t}\)是在\(t\)時刻\(v_k\)的嵌入表示
此外,定義了一個社交策略引數\(θ\),它是一個維度向量,用於提取嵌入每個節點潛在向量中的社交策略資訊。
基於上述定義,定義開放三元組\((v_i,v_j,v_k)\)演變為閉合三元組的概率。即在\(v_k\)的介紹(或影響)下,\(v_i\)和\(v_j\)將在時間\(t+1\)時在它們之間建立連結的概率如下(將上述的距離用sigmoid對映為\([0,1]\)的概率)
同樣,\(v_i\)和\(v_j\)可能由他們的幾個共同朋友介紹,因此,我們的下一個目標是聯合建模多個開放三元組(具有一對共同的未連結頂點)是如何演化的。首先定義集合\(B^t(i,j)\)為\(v_i\)和\(v_j\)在\(t\)時間的共同鄰居,並且定義一個向量\(\boldsymbol{\alpha}^{t, i, j}=\left(\alpha_{k}^{t, i, j}\right)_{k \in B^{t}(i, j)}\),其中對於每一維的值如下定義,如果\(t+1\)處的開放三元組\((v_i,v_j,v_k)\)將發展為閉合三元組。換句話說,在\(v_k\)的影響下,\(v_i\)和\(v_j\)將成為朋友,則為1。
很明顯,一旦\((v_i,v_j,v_k)\)閉合,所有與\(v_i\)和\(v_j\)相關的開放三元組都將關閉。因此,通過進一步假設每個普通朋友對\(v_i\)和\(v_j\)潛在連結的影響之間的獨立性,我們將在時間步\(t+1\)建立新連結\(e_{ij}\)的概率定義為(伯努利分佈)
同時,如果\(v_i\)和\(v_j\)沒有受到任何共同朋友的影響,則不會建立邊緣\(e_{ij}\)。我們將其概率定義為
將上述兩條可能的開放三元組(vi、vj、vk)演化可能放在一起,
且定義
\(S_{+}^{t}=\left\{(i, j) \mid e_{i j} \notin E^{t} \wedge e_{i j} \in E^{t+1}\}\right.\)為在t+1時刻成功建立連結的集合,
\(S_{-}^{t}=\left\{(i, j) \mid e_{i j} \notin E^{t} \wedge e_{i j} \notin E^{t+1}\}\right.\)為在t+1時刻沒有建立連結的集合
然後,我們將三元組閉合過程的損失函數定義為資料的負對數似然:
社會同質性與時間平滑:我們利用另外兩個假設來加強DynamicTriad:社會同質性與時間平滑。社會同質性表明,高度連線的頂點應該緊密嵌入潛在的表示空間中。形式上,我們將兩個頂點之間的距離\(v_j\)和\(v_k\)的嵌入\(u^t_j\)和\(u^t_k\)定義為
在當前時間步t,我們將所有頂點對分為兩組
邊組:$E^t_+ = E^t $
和非邊組:\(E^t_- =\left\{e_{j k} \mid j \in\{1, \cdots, N\}, k \in\{1, \cdots, N\}, j \neq k, e_{j k} \notin E^{t}\right\}\)
根據同質性假設,如果兩個頂點相互連線,它們往往嵌入在潛在表示空間中更緊密,所以對於社會同質性的基於排名的損失函數為
這裡先提一下排名損失函數(ranking loss-based function),知乎回答連結:https://zhuanlan.zhihu.com/p/158853633
ranking loss的目的是去預測輸入樣本之間的相對距離。這裡用的是兩個節點去做三元組的排名損失變種(因為這裡沒有錨點),希望正樣本\(g^{t}(j, k)\)的距離越小越好(接近於0),負樣本\(g^{t}(j^{\prime}, k^{\prime})\)的距離越大越好(起碼大於一個邊界值\(\xi\))
其中$[x]_+ = m a x ( 0, x) $
\(\xi\)是邊界值(margin value)
函數\(h(.,.)\)結合了權重和嵌入差異度量,通常\(h(w, x) = w · x\)
假設一個網路會隨著時間的推移而平穩發展,而不是在每一個時間步中完全重建。因此,我們通過最小化相鄰時間步長中嵌入向量之間的歐氏距離來定義時間平滑度。形式上,相應的損失函數為
因此,給出第一個T時間步的總體優化問題是
Model Learning
對數似然近似:從三元閉包的損失開始(等式5),對於計算非邊的項\(-\sum_{(i, j) \in S_{-}^{t}} \log P_{\mathrm{tr}_{-}}^{t}(i, j)\)可計算為如下(淺推了一下,只能說通透):
推導如下
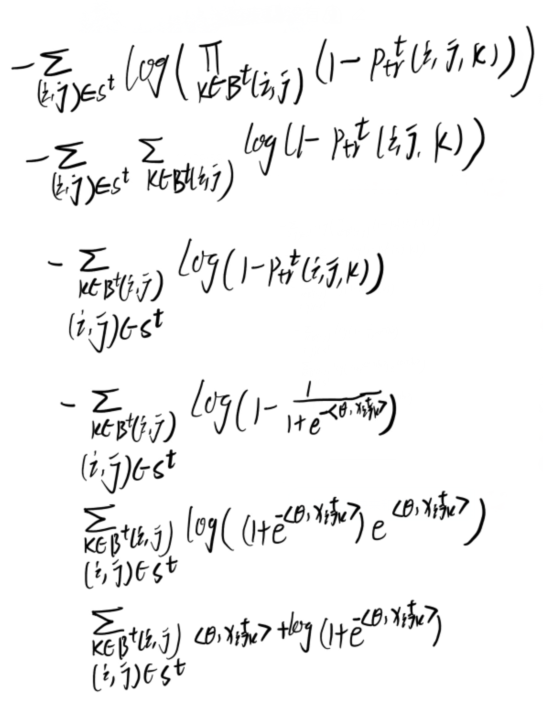
但是比較棘手的是第一項的正取樣,因為\({\alpha}^{t, i, j}\)具有指數數量的可能值,為了解決這個問題,我們採用了一種類似於期望最大化(expectation maximization,EM)演演算法的方法來優化這個項的上界。具體來說,我們計算該項的上界為
其中
可以在迭代開始時給定\(i、j、k\)和\(t\)預先計算,\(θ(n)\)和\(u(n)\)是當前迭代下的模型引數。由於篇幅有限,省略了推導細節。結合式(10)和式(11),我們得到了\(L^t_{tr}\)的上界
取樣:如果對所有正負樣本均進行計算,開銷較大。所以取樣策略為在時間步t處給定一個正取樣(邊)\(e_{jk}\),先隨機選擇一個節點\(v_{{j^\prime} \in \{j,k\}}\),再從其他節點隨機選擇一個節點\(v_{{k^\prime}}\),使得\(v_{{j^\prime,k^\prime}} \notin E^t\),即為負取樣。
對每個邊\(e_{jk}\)重複取樣過程,我們將訓練集定義為\(E_{\mathrm{sh}}^{t}=\left\{\left(j, k, j^{\prime}, k^{\prime}\right) \mid(j, k) \in E^{t}\right\}\),損失函數可以表示為
對於三元組閉合過程的損失函數,\((j, k, j^{\prime}, k^{\prime})\in E_{\mathrm{sh}}^{t}\)。我們首先從\({v_j,v_k}\)中隨機選擇一個頂點,在影響結果的情況下,我們假設選擇了vk。然後我們的目標是取樣一個頂點\(v_i\),其中\(e_{ik} \in E_t,e_{ij} \notin E_t\),所以我們得到一個開放的三元組\((i,j,k)\),其中\(v_k\)連線\(v_i\)和\(v_j\)。開放三元組可以是一個正範例,也可以是一個負範例,取決於它是否在下一個時間步驟中閉合(即\(e_{ij} \in E_{t+1}\)),結合公式13如下
由於\(L^t_{tr,1}\)依賴於時間步\(t+1\)處的資訊,最後一個時間步T有一個特例
綜上所述,訓練階段的總體損失函數為
其中前兩項共用一組相同的樣本,第三項對應於時間平滑度。
 續聯
續聯
演演算法流程如上
優化:採用隨機梯度下降(SGD)框架和Adagrad方法。
Experiment
Experimental Results
Data Sets
Mobile, Loan,Academic
引數資訊見表1
Tasks and Baselines
六個任務:節點分類,節點預測,連結重構(兩個節點是否存在邊),連結預測(和重構的區別是根據當前時間步t的嵌入,去預測下個時間步t+1中邊緣的存在),更改連結重建和預測。
三個baseline:DeepWalk,node2vec,Temporal Network Embedding 。
Quantitative Results
具體sota見表2
引數對本文模型的影響見圖2(影響較小)
嵌入視覺化見圖3
Summary
本文通過捕捉網路中三元組的閉合來達到建模網路演化過程,在動態圖中是一種較為獨特的思路,公式較多,但是解釋清楚。尤其是對正樣本的損失處理為了避免指數數量的可能值,採用了一種類似於期望最大化演演算法的方法來做,很巧妙。