Kafka 消費者解析
一、消費者相關概念
1.1 消費組&消費者
消費者:
- 消費者從訂閱的主題消費訊息,消費訊息的偏移量儲存在Kafka的名字是
__consumer_offsets的主題中 - 消費者還可以將⾃⼰的偏移量儲存到
Zookeeper,需要設定offset.storage=zookeeper - 推薦使⽤Kafka儲存消費者的偏移量。因為Zookeeper不適合⾼並行。
消費組:
- 多個從同⼀個主題消費的消費者可以加⼊到⼀個消費組中
- 消費組中的消費者共用group_id。設定方法:
configs.put("group.id", "xxx"); - group_id⼀般設定為應⽤的邏輯名稱。⽐如多個訂單處理程式組成⼀個消費組,可以設定group_id為"order_process"
- group_id通過消費者的設定指定:
group.id=xxxxx - 消費組均衡地給消費者分配分割區,每個分割區只由消費組中⼀個消費者消費
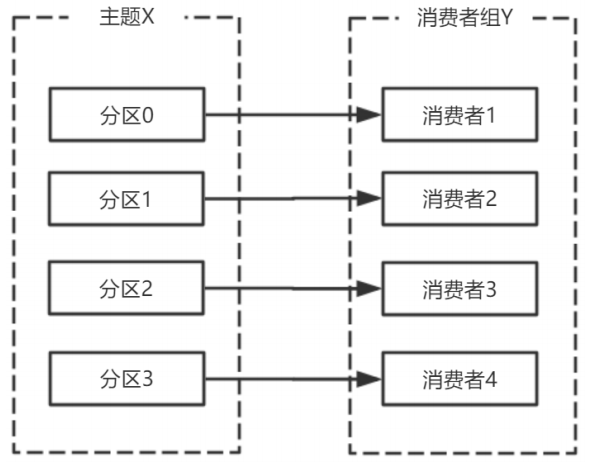
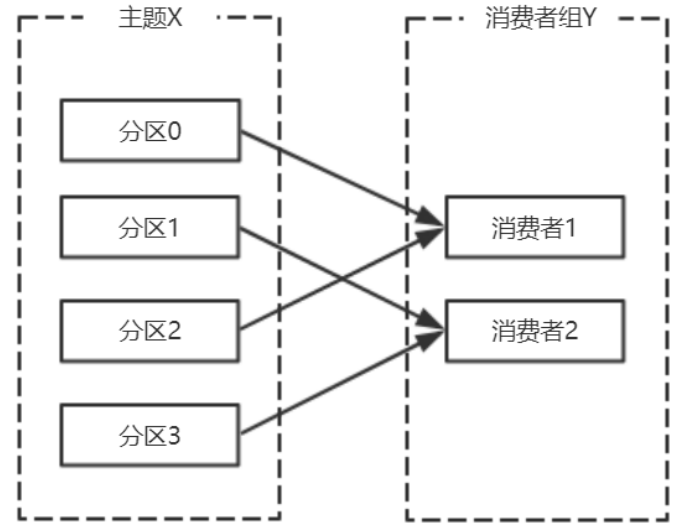
⼀個擁有四個分割區的主題,包含⼀個消費者的消費組
此時,消費組中的消費者消費主題中的所有分割區。並且沒有重複的可能。
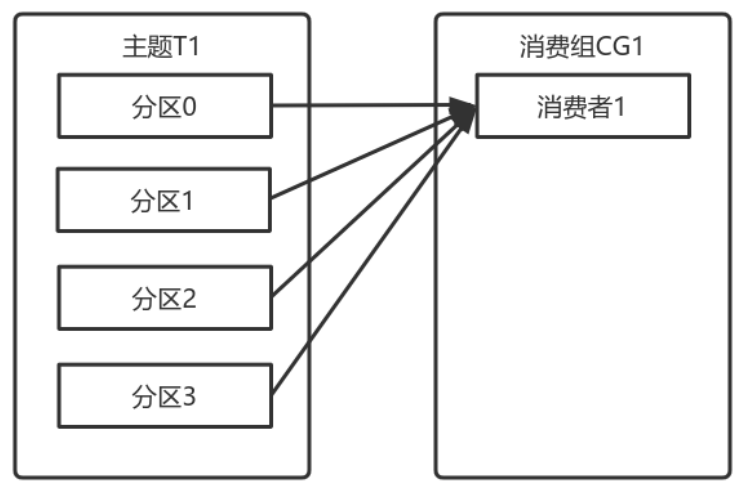
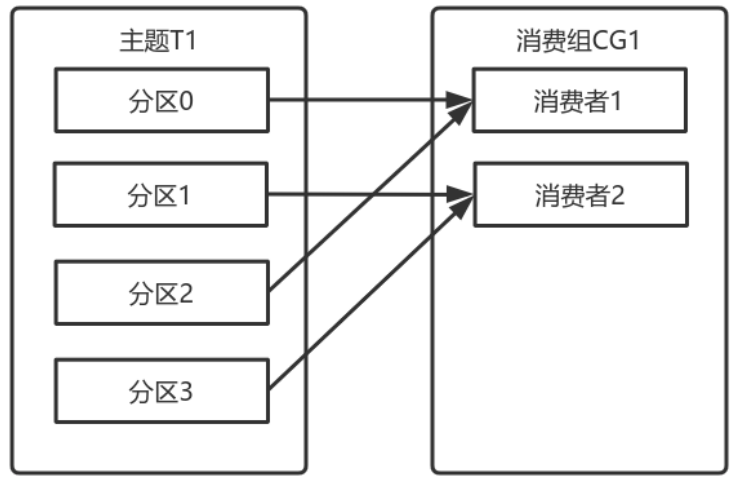
如果在消費組中新增⼀個消費者2,則每個消費者分別從兩個分割區接收訊息
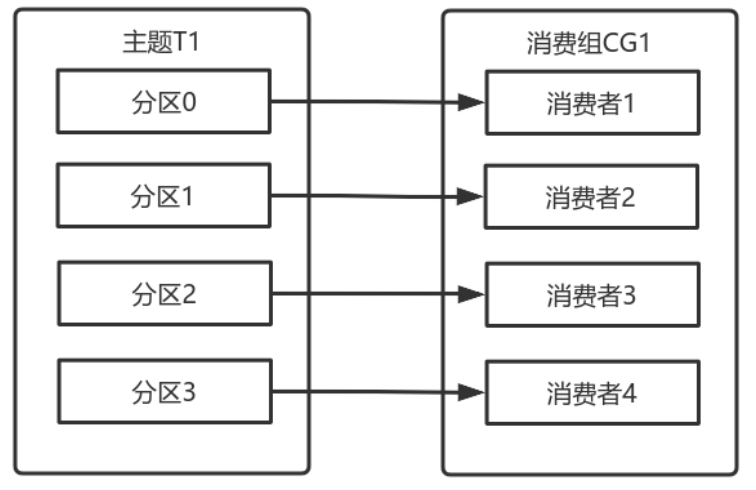
如果消費組有四個消費者,則每個消費者可以分配到⼀個分割區
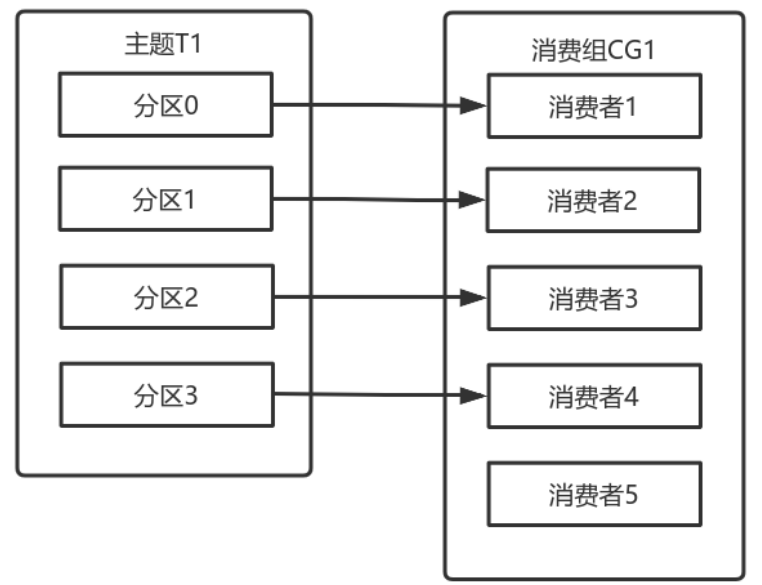
如果向消費組中新增更多的消費者,超過主題分割區數量,則有⼀部分消費者就會閒置,不會接收任何訊息
向消費組新增消費者是橫向擴充套件消費能⼒的主要⽅式。
必要時,需要為主題建立⼤量分割區,在負載增⻓時可以加⼊更多的消費者。但是不要讓消費者的數量超過主題分割區的數量。
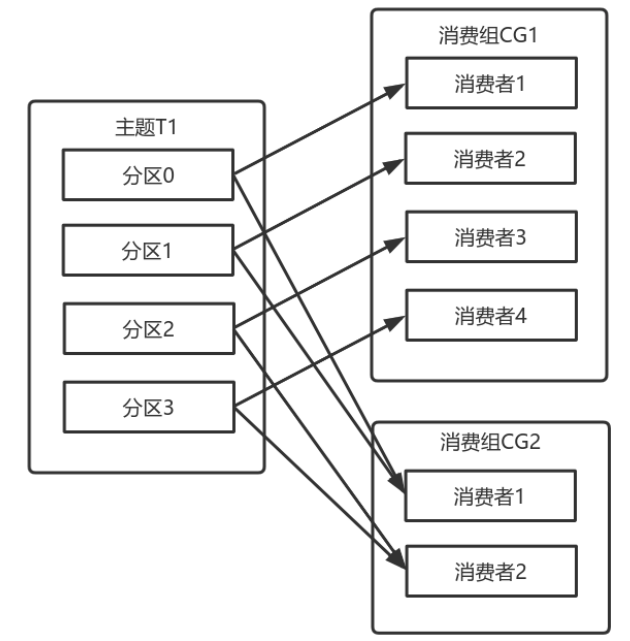
除了通過增加消費者來橫向擴充套件單個應⽤的消費能⼒之外,經常出現多個應⽤程式從同⼀個主題消費的情況。
此時,每個應⽤都可以獲取到所有的訊息。只要保證每個應⽤都有⾃⼰的消費組,就可以讓它們獲取到主題所有的訊息。
橫向擴充套件消費者和消費組不會對效能造成負⾯影響。
為每個需要獲取⼀個或多個主題全部訊息的應⽤建立⼀個消費組,然後向消費組新增消費者來橫向擴充套件消費能⼒和應⽤的處理能⼒,則每個消費者只處理⼀部分訊息。
1.2 心跳機制
初始的消費者消費分割區:
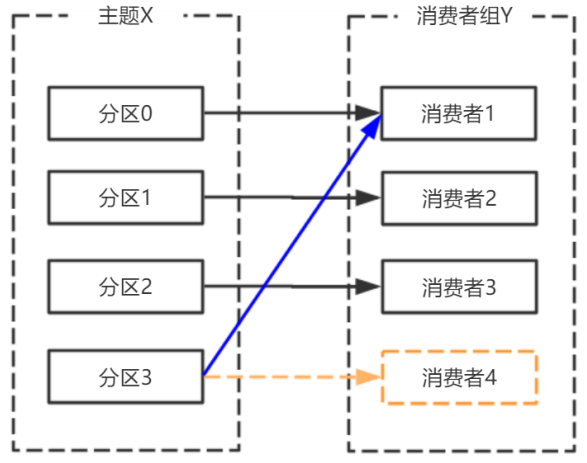
消費者宕機,退出消費組,觸發再平衡,重新給消費組中的消費者分配分割區
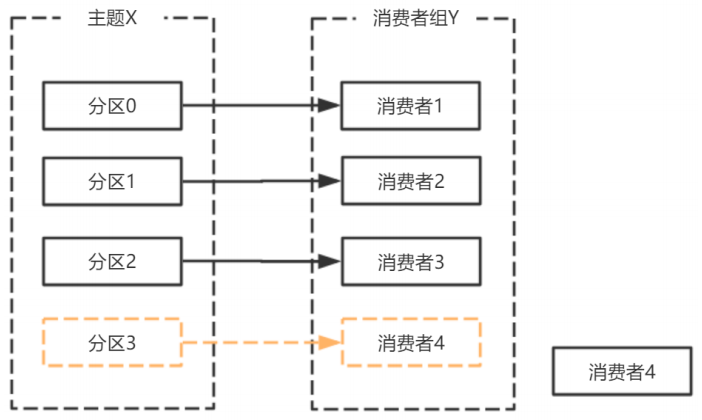
由於broker宕機,主題X的分割區3宕機,此時分割區3沒有Leader副本,觸發再平衡,消費者4沒有對應的主題分割區,則消費者4閒置
Kafka 的⼼跳是 Kafka Consumer 和 Broker 之間的健康檢查,只有當 Broker Coordinator 正常時,Consumer 才會傳送⼼跳。
Consumer 和 Rebalance 相關的 2 個設定引數:
| 引數 | 欄位 |
|---|---|
| session.timeout.ms | MemberMetadata.sessionTimeoutMs |
| max.poll.interval.ms | MemberMetadata.rebalanceTimeoutMs |
broker 端,sessionTimeoutMs 引數
broker 處理⼼跳的邏輯在 GroupCoordinator類中。如果⼼跳超期, broker coordinator 會把消費者從 group 中移除,並觸發 rebalance。
可以看看原始碼的kafka.coordinator.group.GroupCoordinator#completeAndScheduleNextHeartbeatExpiration方法。
如果使用者端發現⼼跳超期,使用者端會標記 coordinator 為不可⽤,並阻塞⼼跳執行緒;如果超過了 poll 訊息的間隔超過了 rebalanceTimeoutMs,則 consumer 告知 broker 主動離開消費組,也會觸發 rebalance
可以看看原始碼的org.apache.kafka.clients.consumer.internals.AbstractCoordinator.HeartbeatThread 內部類
二、訊息接收相關
2.1 常用引數設定
| 引數 | 說明 |
|---|---|
| bootstrap.servers | 向Kafka叢集建⽴初始連線⽤到的host/port列表。 使用者端會使⽤這⾥列出的所有伺服器進⾏叢集其他伺服器的發現,⽽不管是否指定了哪個伺服器⽤作引導。 這個列表僅影響⽤來發現叢集所有伺服器的初始主機。 字串形式:host1:port1,host2:port2,... 由於這組伺服器僅⽤於建⽴初始連結,然後發現叢集中的所有伺服器,因此沒有必要將叢集中的所有地址寫在這⾥。 ⼀般最好兩臺,以防其中⼀臺宕掉。 |
| key.deserializer | key的反序列化類,該類需要實現org.apache.kafka.common.serialization.Deserializer接⼝。 |
| value.deserializer | 實現了org.apache.kafka.common.serialization.Deserializer接⼝的反序列化器,⽤於對訊息的value進⾏反序列化。 |
| client.id | 當從伺服器消費訊息的時候向伺服器傳送的id字串。在ip/port基礎上提供應⽤的邏輯名稱,記錄在伺服器端的請求⽇志中,⽤於追蹤請求的源。 |
| group.id | ⽤於唯⼀標誌當前消費者所屬的消費組的字串。 如果消費者使⽤組管理功能如subscribe(topic)或使⽤基於Kafka的偏移量管理策略,該項必須設定。 |
| auto.offset.reset | 當Kafka中沒有初始偏移量或當前偏移量在伺服器中不存在(如,資料被刪除了),該如何處理? earliest:⾃動重置偏移量到最早的偏移量 latest:⾃動重置偏移量為最新的偏移量 none:如果消費組原來的(previous)偏移量不存在,則向消費者拋異常 anything:向消費者拋異常 |
| enable.auto.commit | 如果設定為true,消費者會⾃動週期性地向伺服器提交偏移量。 |
2.2 訂閱
Topic:Kafka⽤於分類管理訊息的邏輯單元,類似與MySQL的資料庫。
*Partition:是Kafka下資料儲存的基本單元,這個是物理上的概念。同⼀個topic的資料,會被分散的儲存到多個partition中,這些partition可以在同⼀臺機器上,也可以是在多臺機器上。優勢在於:有利於⽔平擴充套件,避免單臺機器在磁碟空間和效能上的限制,同時可以通過複製來增加資料冗餘性,提⾼容災能⼒。為了做到均勻分佈,通常partition的數量通常是Broker Server數量的整數倍。
Consumer Group:同樣是邏輯上的概念,是Kafka實現單播和⼴播兩種訊息模型的⼿段**。保證⼀個消費組獲取到特定主題的全部的訊息。在消費組內部,若⼲個消費者消費主題分割區的訊息,消費組可以保證⼀個主題的每個分割區只被消費組中的⼀個消費者消費。
consumer 採⽤ pull 模式從 broker 中讀取資料。
採⽤ pull 模式,consumer 可⾃主控制消費訊息的速率, 可以⾃⼰控制消費⽅式(批次消費/逐條消費),還可以選擇不同的提交⽅式從⽽實現不同的傳輸語意。
訂閱主題:consumer.subscribe("tp_demo_01,tp_demo_02")
2.3 反序列化
2.3.1 Kafka 自帶反序列化器
Kafka的broker中所有的訊息都是位元組陣列,消費者獲取到訊息之後,需要先對訊息進⾏反序列化處理,然後才能交給⽤戶程式消費處理。
常用的Kafka提供的,反序列化器包括key的和value的反序列化器:
- key.deserializer:IntegerDeserializer
- value.deserializer:StringDeserializer
消費者從訂閱的主題拉取訊息:consumer.poll(3_000);
在Fetcher類中,對拉取到的訊息⾸先進⾏反序列化處理:
private ConsumerRecord<K, V> parseRecord(TopicPartition partition, RecordBatch batch, Record record) {
try {
long offset = record.offset();
long timestamp = record.timestamp();
Optional<Integer> leaderEpoch = this.maybeLeaderEpoch(batch.partitionLeaderEpoch());
TimestampType timestampType = batch.timestampType();
Headers headers = new RecordHeaders(record.headers());
ByteBuffer keyBytes = record.key();
byte[] keyByteArray = keyBytes == null ? null : Utils.toArray(keyBytes);
K key = keyBytes == null ? null : this.keyDeserializer.deserialize(partition.topic(), headers, keyByteArray);
ByteBuffer valueBytes = record.value();
byte[] valueByteArray = valueBytes == null ? null : Utils.toArray(valueBytes);
V value = valueBytes == null ? null : this.valueDeserializer.deserialize(partition.topic(), headers, valueByteArray);
return new ConsumerRecord(partition.topic(), partition.partition(), offset, timestamp, timestampType, record.checksumOrNull(), keyByteArray == null ? -1 : keyByteArray.length, valueByteArray == null ? -1 : valueByteArray.length, key, value, headers, leaderEpoch);
} catch (RuntimeException var17) {
throw new SerializationException("Error deserializing key/value for partition " + partition + " at offset " + record.offset() + ". If needed, please seek past the record to continue consumption.", var17);
}
}
Kafka預設提供了⼏個反序列化的實現:
org.apache.kafka.common.serialization.ByteArrayDeserializer
org.apache.kafka.common.serialization.ByteBufferDeserializer
org.apache.kafka.common.serialization.BytesDeserializer
org.apache.kafka.common.serialization.DoubleDeserializer
org.apache.kafka.common.serialization.FloatDeserializer
org.apache.kafka.common.serialization.IntegerDeserializer
org.apache.kafka.common.serialization.LongDeserializer
org.apache.kafka.common.serialization.ShortDeserializer
org.apache.kafka.common.serialization.StringDeserializer
2.3.2 自定義反序列化器
反序列化器都需要實現org.apache.kafka.common.serialization.Deserializer<T>接⼝:
這裡根據前面自定義的序列化器,再自定義一個反序列化器。
先回顧一下前面的序列化器,新增了一個 User 物件,需要序列化User物件:
public class User {
private Integer userId;
private String username;
// set、get、toString、全參建構函式、無參建構函式 方法省略,
}
/**
* User物件的序列化器
*/
public class UserSerializer implements Serializer<User> {
@Override
public void configure(Map<String, ?> map, boolean b) {
// do Nothing
}
@Override
public byte[] serialize(String topic, User user) {
try {
// 如果資料是null,則返回null
if (user == null) return null;
Integer userId = user.getUserId();
String username = user.getUsername();
int length = 0;
byte[] bytes = null;
if (null != username) {
bytes = username.getBytes("utf-8");
length = bytes.length;
}
ByteBuffer buffer = ByteBuffer.allocate(4 + 4 + length);
buffer.putInt(userId);
buffer.putInt(length);
buffer.put(bytes);
return buffer.array();
} catch (UnsupportedEncodingException e) {
throw new SerializationException("序列化資料異常");
}
}
@Override
public void close() {
// do Nothing
}
}
這裡再自定義一個反序列化器:
public class UserDeserializer implements Deserializer<User> {
@Override
public void configure(Map<String, ?> configs, boolean isKey) {
// do Nothing
}
@Override
public User deserialize(String topic, byte[] data) {
ByteBuffer allocate = ByteBuffer.allocate(data.length);
allocate.put(data);
allocate.flip();
int userId = allocate.getInt();
int length = allocate.getInt();
String userName = new String(data, 8, length);
return new User(userId, userName);
}
@Override
public void close() {
// do Nothing
}
}
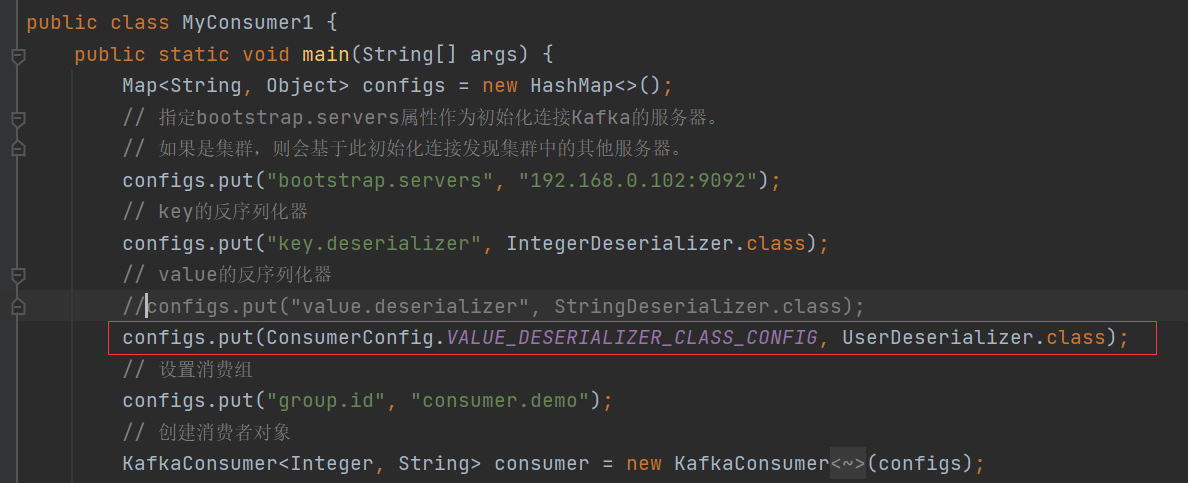
消費者使用自定義反序列化器:
2.4 攔截器
消費者在拉取了分割區訊息之後,要⾸先經過反序列化器對key和value進⾏反序列化處理。
處理完之後,如果消費端設定了攔截器,則需要經過攔截器的處理之後,才能返回給消費者應⽤程式進⾏處理。
消費端定義訊息攔截器,需要實現org.apache.kafka.clients.consumer.ConsumerInterceptor<K, V>接⼝。
- ⼀個可插拔接⼝,允許攔截甚⾄更改消費者接收到的訊息。⾸要的⽤例在於將第三⽅元件引⼊消費者應⽤程式,⽤於客製化的監控、⽇志處理等.
- 該接⼝的實現類通過
configre⽅法獲取消費者設定的屬性,如果消費者設定中沒有指定clientID,還可以獲取KafkaConsumer⽣成的clientId。獲取的這個設定是跟其他攔截器共用的,需要保證不會在各個攔截器之間產⽣衝突。 ConsumerInterceptor⽅法丟擲的異常會被捕獲、記錄,但是不會向下傳播。如果⽤戶設定了錯誤的key或value型別引數,消費者不會丟擲異常,⽽僅僅是記錄下來。ConsumerInterceptor回撥發⽣在org.apache.kafka.clients.consumer.KafkaConsumer#poll(long)⽅法同⼀個執行緒
該接⼝中有如下⽅法:
public interface ConsumerInterceptor<K, V> extends Configurable {
/**
* 該⽅法在poll⽅法返回之前調⽤。調⽤結束後poll⽅法就返回訊息了。
*
* 該⽅法可以修改消費者訊息,返回新的訊息。攔截器可以過濾收到的訊息或⽣成新的訊息。
* 如果有多個攔截器,則該⽅法按照KafkaConsumer的configs中設定的順序調⽤。
*
* @param records 由上個攔截器返回的由使用者端消費的訊息。
*/
public ConsumerRecords<K, V> onConsume(ConsumerRecords<K, V> records);
/**
* 當消費者提交偏移量時,調⽤該⽅法
* 該⽅法丟擲的任何異常調⽤者都會忽略。
*/
public void onCommit(Map<TopicPartition, OffsetAndMetadata> offsets);
/**
* This is called when interceptor is closed
*/
public void close();
}
程式碼實現
自定義一個消費者攔截器:
public class OneInterceptor implements ConsumerInterceptor<String, String> {
@Override
public ConsumerRecords<String, String> onConsume(ConsumerRecords<String, String> records) {
// poll⽅法返回結果之前最後要調⽤的⽅法
System.out.println("One -- 開始");
// 訊息不做處理,直接返回
return records;
}
@Override
public void onCommit(Map<TopicPartition, OffsetAndMetadata> offsets) {
// 消費者提交偏移量的時候,經過該⽅法
System.out.println("One -- 結束");
}
@Override
public void close() {
// ⽤於關閉該攔截器⽤到的資源,如開啟的⽂件,連線的資料庫等
}
@Override
public void configure(Map<String, ?> configs) {
// ⽤於獲取消費者的設定引數
configs.forEach((k, v) -> {
System.out.println(k + "\t" + v);
});
}
}
按照 OneInterceptor 攔截器複製兩個攔截器,更名為 TwoInterceptor、ThreeInterceptor
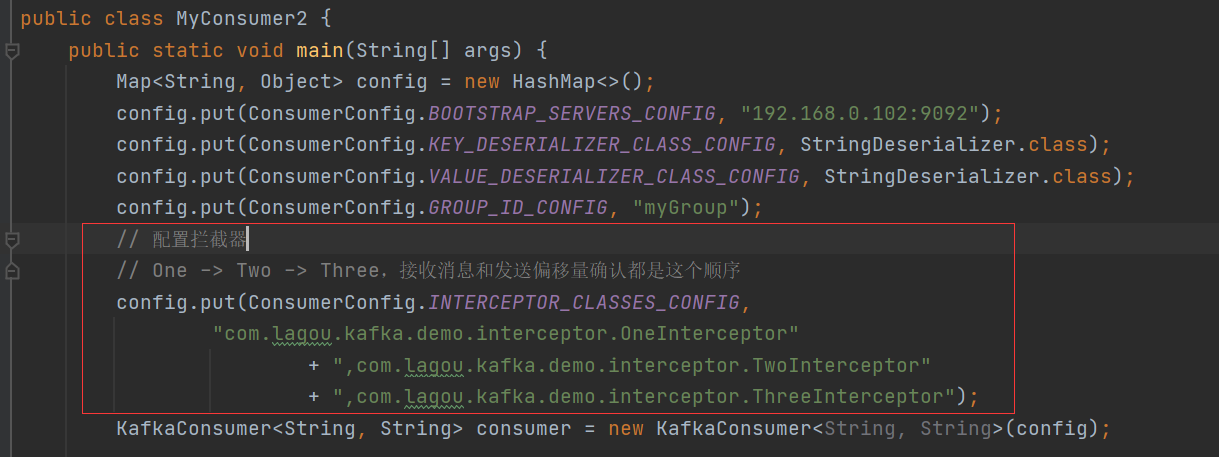
消費者使用自定義攔截器:
2.5 位移提交&位移管理
位移提交介紹:
- Consumer需要向Kafka記錄⾃⼰的位移資料,這個彙報過程稱為提交位移(
Committing Offsets) - Consumer 需要為分配給它的每個分割區提交各⾃的位移資料
- 位移提交的由Consumer端負責的,Kafka只負責保管。
__consumer_offsets - 位移提交分為⾃動提交和⼿動提交
- 位移提交分為同步提交和非同步提交
2.5.1 位移自動提交
Kafka Consumer 後臺提交
- 開啟⾃動提交:
enable.auto.commit=true - 設定⾃動提交間隔:Consumer端:
auto.commit.interval.ms,預設 5s
在消費者中設定自動提交和自動提交間隔:
Map<String, Object> configs = new HashMap<>();
configs.put("bootstrap.servers", "192.168.0.102:9092");
configs.put("group.id", "mygrp");
// 設定偏移量⾃動提交。⾃動提交是預設值。這⾥做範例。
configs.put("enable.auto.commit", "true");
// 偏移量⾃動提交的時間間隔
configs.put("auto.commit.interval.ms", "3000");
configs.put("key.deserializer", StringDeserializer.class);
configs.put("value.deserializer", StringDeserializer.class);
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(configs);
⾃動提交位移的順序:
- 設定
enable.auto.commit = true - Kafka會保證在開始調⽤poll⽅法時,提交上次poll返回的所有訊息
- 因此⾃動提交不會出現訊息丟失,但會重複消費
重複消費舉例:
- Consumer 每 5s 提交 offset
- 假設提交 offset 後的 3s 發⽣了 Rebalance
- Rebalance 之後的所有 Consumer 從上⼀次提交的 offset 處繼續消費
- 因此 Rebalance 發⽣前 3s 的訊息會被重複消費
2.5.2 位移手動同步提交
-
使⽤
KafkaConsumer#commitSync():會提交KafkaConsumer#poll()返回的最新 offset -
該⽅法為同步操作,等待直到 offset 被成功提交才返回
while (true) { ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1)); process(records); // 處理訊息 try { consumer.commitSync(); } catch (CommitFailedException e) { handle(e); // 處理提交失敗異常 } } -
commitSync 在處理完所有訊息之後
-
⼿動同步提交可以控制offset提交的時機和頻率
⼿動同步提交會:
- 調⽤ commitSync 時,Consumer 處於阻塞狀態,直到 Broker 返回結果
- 會影響 TPS
- 可以選擇拉⻓提交間隔,但有以下問題
- 會導致 Consumer 的提交頻率下降
- Consumer 重啟後,會有更多的訊息被消費
2.5.3 位移手動非同步提交
-
KafkaConsumer#commitAsync()while (true) { ConsumerRecords<String, String> records = consumer.poll(3_000); process(records); // 處理訊息 consumer.commitAsync((offsets, exception) -> { if (exception != null) { handle(exception); } }); } -
commitAsync出現問題不會⾃動重試
手動非同步提交不會自動重試的解決方案:
try {
while(true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
process(records); // 處理訊息
commitAysnc(); // 使⽤非同步提交規避阻塞
}
} catch(Exception e) {
handle(e); // 處理異常
} finally {
try {
consumer.commitSync(); // 最後⼀次提交使⽤同步阻塞式提交
} finally {
consumer.close();
}
}
2.5.3 消費者位移管理
Kafka中,消費者根據訊息的位移順序消費訊息。
消費者的位移由消費者管理,可以儲存於zookeeper中,也可以儲存於Kafka主題__consumer_offsets中。
Kafka提供了消費者API,讓消費者可以管理⾃⼰的位移。
KafkaConsumer<K, V> 的 API如下:
-
public void assign(Collection<TopicPartition> partitions)說明:
給當前消費者⼿動分配⼀系列主題分割區。
⼿動分配分割區不⽀持增量分配,如果先前有分配分割區,則該操作會覆蓋之前的分配。
如果給出的主題分割區是空的,則等價於調⽤unsubscribe⽅法。
⼿動分配主題分割區的⽅法不使⽤消費組管理功能。當消費組成員變了,或者叢集或主題的後設資料改變了,不會觸發分割區分配的再平衡。
⼿動分割區分配assign(Collection)不能和⾃動分割區分配
subscribe(Collection,ConsumerRebalanceListener)⼀起使⽤。如果啟⽤了⾃動提交偏移量,則在新的分割區分配替換舊的分割區分配之前,會對舊的分割區分配中的消費偏移量進⾏非同步提交。
-
public Set<TopicPartition> assignment()說明:
獲取給當前消費者分配的分割區集合。如果訂閱是通過調⽤assign⽅法直接分配主題分割區,則返回相同的集合。如果使⽤了主題訂閱,該⽅法返回當前分配給該消費者的主題分割區集合。如果分割區訂閱還沒開始進⾏分割區分配,或者正在重新分配分割區,則會返回none。
-
public Map<String, List<PartitionInfo>> listTopics()說明:
獲取對⽤戶授權的所有主題分割區後設資料。該⽅法會對伺服器發起遠端調⽤。
-
public List<PartitionInfo> partitionsFor(String topic)說明:
獲取指定主題的分割區後設資料。如果當前消費者沒有關於該主題的後設資料,就會對伺服器發起遠端調⽤。
-
public Map<TopicPartition, Long> beginningOffsets(Collection<TopicPartition> partitions)說明:
對於給定的主題分割區,列出它們第⼀個訊息的偏移量。
注意,如果指定的分割區不存在,該⽅法可能會永遠阻塞。
該⽅法不改變分割區的當前消費者偏移量。
-
public void seekToEnd(Collection<TopicPartition> partitions)說明:
將偏移量移動到每個給定分割區的最後⼀個。
該⽅法延遲執⾏,只有當調⽤過poll⽅法或position⽅法之後才可以使⽤。
如果沒有指定分割區,則將當前消費者分配的所有分割區的消費者偏移量移動到最後。
如果設定了隔離級別為:
isolation.level=read_committed,則會將分割區的消費偏移量移動到最後⼀個穩定的偏移量,即下⼀個要消費的訊息現在還是未提交狀態的事務訊息。 -
public void seek(TopicPartition partition, long offset)說明:
將給定主題分割區的消費偏移量移動到指定的偏移量,即當前消費者下⼀條要消費的訊息偏移量。
若該⽅法多次調⽤,則最後⼀次的覆蓋前⾯的。
如果在消費中間隨意使⽤,可能會丟失資料。
-
public long position(TopicPartition partition)說明:
檢查指定主題分割區的消費偏移量
-
public void seekToBeginning(Collection<TopicPartition> partitions)說明:
將給定每個分割區的消費者偏移量移動到它們的起始偏移量。該⽅法懶執⾏,只有當調⽤過poll⽅法或position⽅法之後才會執⾏。如果沒有提供分割區,則將所有分配給當前消費者的分割區消費偏移量移動到起始偏移量。
準備資料
# ⽣成訊息⽂件
[root@node1 ~]# for i in `seq 60`; do echo "hello $i" >> nm.txt; done
# 建立主題,三個分割區,每個分割區⼀個副本
[root@node1 ~]# kafka-topics.sh --zookeeper localhost:2181/myKafka --create --topic tp_demo_01 --partitions 3 --replication-factor 1
# 將訊息⽣產到主題中
[root@node1 ~]# kafka-console-producer.sh --broker-list localhost:9092 --topic tp_demo_01 < nm.txt
API 實戰:
/**
* 消費者位移管理
*/
public class MyConsumer2 {
public static void main(String[] args) {
Map<String, Object> config = new HashMap<>();
config.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.0.102:9092");
config.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
config.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
config.put(ConsumerConfig.GROUP_ID_CONFIG, "myGroup");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(config);
// 給當前消費者⼿動分配⼀系列主題分割區
consumer.assign(Arrays.asList(new TopicPartition("tp_demo_01", 1)));
// 獲取給當前消費者分配的分割區集合
Set<TopicPartition> assignment = consumer.assignment();
assignment.forEach(topicPartition -> System.out.println(topicPartition));
// 獲取對⽤戶授權的所有主題分割區後設資料。該⽅法會對伺服器發起遠端調⽤
Map<String, List<PartitionInfo>> stringListMap = consumer.listTopics();
stringListMap.forEach((k, v) -> {
System.out.println("主題:" + k);
v.forEach(info -> System.out.println(info));
});
Set<String> strings = consumer.listTopics().keySet();
strings.forEach(topicName -> System.out.println(topicName));
// 獲取指定主題的分割區後設資料
List<PartitionInfo> partitionInfos = consumer.partitionsFor("tp_demo_01");
for (PartitionInfo partitionInfo : partitionInfos) {
Node leader = partitionInfo.leader();
System.out.println(leader);
System.out.println(partitionInfo);
// 當前分割區線上副本
Node[] nodes = partitionInfo.inSyncReplicas();
// 當前分割區下線副本
Node[] nodes1 = partitionInfo.offlineReplicas();
}
// 對於給定的主題分割區,列出它們第⼀個訊息的偏移量。
// 注意,如果指定的分割區不存在,該⽅法可能會永遠阻塞。
// 該⽅法不改變分割區的當前消費者偏移量。
Map<TopicPartition, Long> topicPartitionLongMap = consumer.beginningOffsets(consumer.assignment());
topicPartitionLongMap.forEach((k, v) -> {
System.out.println("主題:" + k.topic() + "\t分割區:" + k.partition() + "偏移量\t" + v);
});
// 將偏移量移動到每個給定分割區的最後⼀個。
consumer.seekToEnd(consumer.assignment());
//將給定主題分割區的消費偏移量移動到指定的偏移量,即當前消費者下⼀條要消費的訊息偏移量。
consumer.seek(new TopicPartition("tp_demo_01", 1), 10);
// 檢查指定主題分割區的消費偏移量
long position = consumer.position(new TopicPartition("tp_demo_01", 1));
System.out.println(position);
// 將偏移量移動到每個給定分割區的最後⼀個。
consumer.seekToEnd(Arrays.asList(new TopicPartition("tp_demo_01", 1)));
// 關閉⽣產者
consumer.close();
}
}
2.6 再平衡
2.6.1 再平衡介紹
重平衡可以說是kafka為⼈詬病最多的⼀個點了。
重平衡其實就是⼀個協定,它規定了如何讓消費者組下的所有消費者來分配topic中的每⼀個分割區。⽐如⼀個topic有100個分割區,⼀個消費者組內有20個消費者,在協調者的控制下讓組內每⼀個消費者分配到5個分割區,這個分配的過程就是重平衡。
重平衡的觸發條件主要有三個:
- 消費者組內成員發⽣變更,這個變更包括了增加和減少消費者,⽐如消費者宕機退出消費組。
- 主題的分割區數發⽣變更,kafka⽬前只⽀持增加分割區,當增加的時候就會觸發重平衡
- 訂閱的主題發⽣變化,當消費者組使⽤正規表示式訂閱主題,⽽恰好⼜新建了對應的主題,就會觸發重平衡
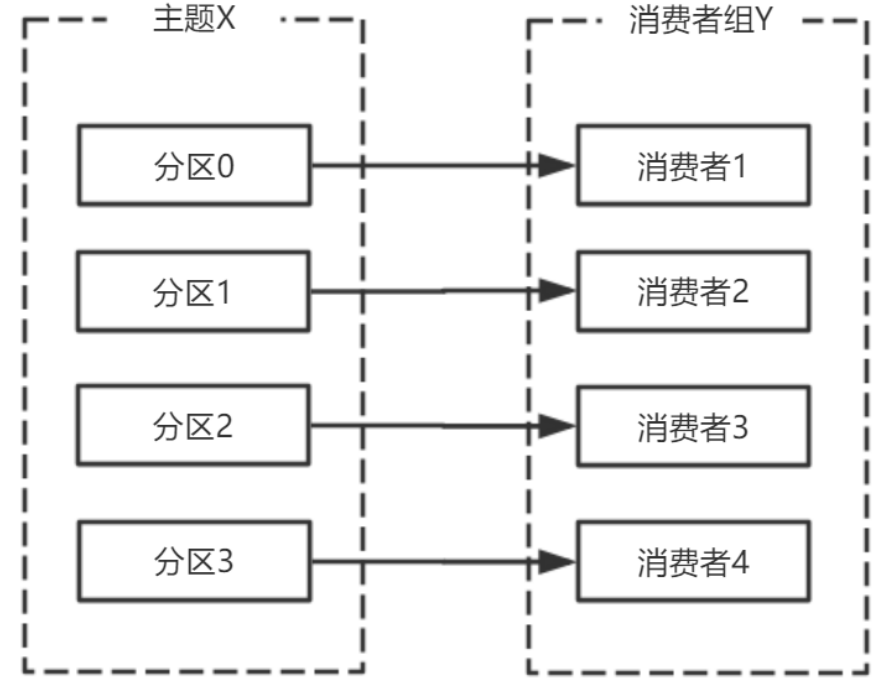
消費者宕機,退出消費組,觸發再平衡,重新給消費組中的消費者分配分割區。
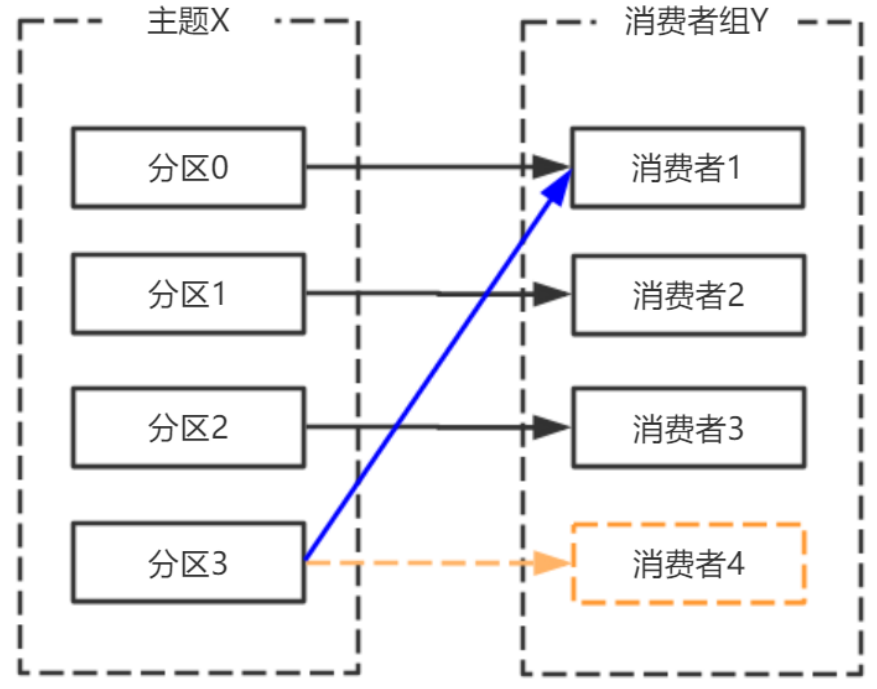
由於broker宕機,主題X的分割區3宕機,此時分割區3沒有Leader副本,觸發再平衡,消費者4沒有對應的主題分割區,則消費者4閒置。
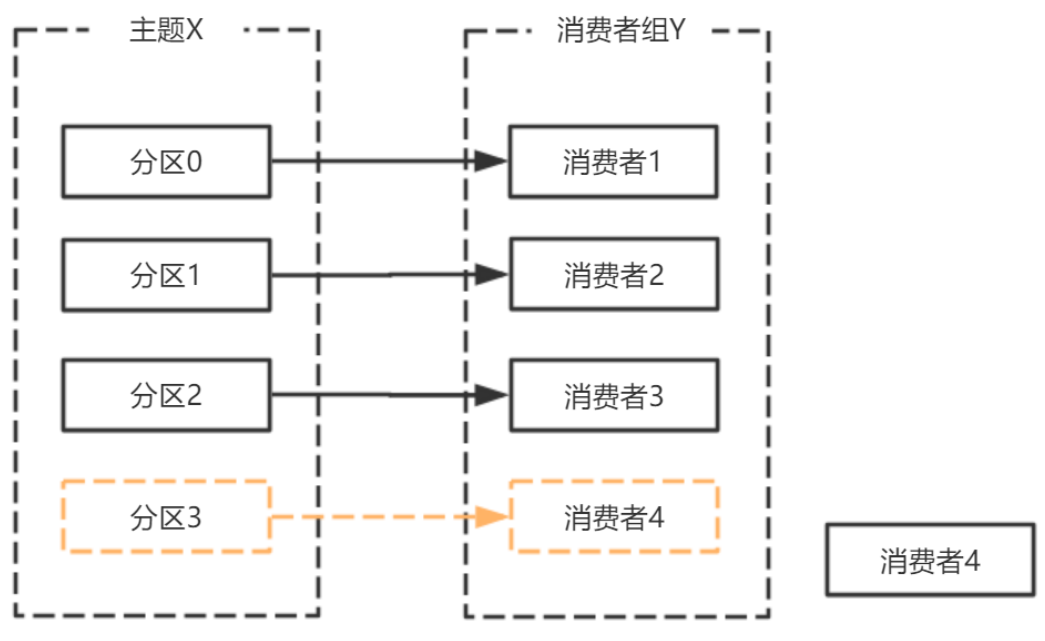
主題增加分割區,需要主題分割區和消費組進⾏再均衡。
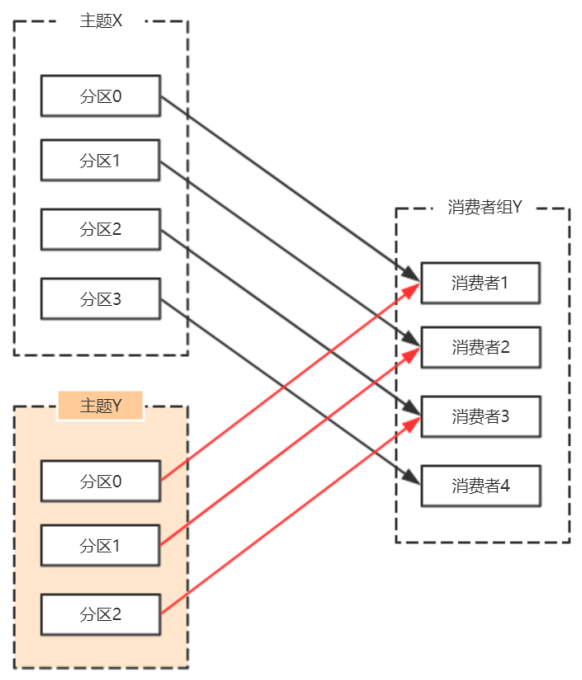
由於使⽤正規表示式訂閱主題,當增加的主題匹配正規表示式的時候,也要進⾏再均衡。
為什麼說重平衡為⼈詬病呢?因為重平衡過程中,消費者⽆法從kafka消費訊息,這對kafka的TPS影響極⼤,⽽如果kafka集內節點較多,⽐如數百個,那重平衡可能會耗時極多。數分鐘到數⼩時都有可能,⽽這段時間kafka基本處於不可⽤狀態。所以在實際環境中,應該儘量避免重平衡發⽣。
2.6.2 避免再平衡
不可能完全避免重平衡,因為你⽆法完全保證消費者不會故障。⽽消費者故障其實也是最常⻅的引發重平衡的地⽅,所以我們需要保證盡⼒避免消費者故障。
⽽其他⼏種觸發重平衡的⽅式,增加分割區,或是增加訂閱的主題,抑或是增加消費者,更多的是主動控制。
如果消費者真正掛掉了,就沒辦法了,但實際中,會有⼀些情況,kafka錯誤地認為⼀個正常的消費者已經掛掉了,我們要的就是避免這樣的情況出現。
⾸先要知道哪些情況會出現錯誤判斷掛掉的情況。
在分散式系統中,通常是通過⼼跳來維持分散式系統的,kafka也不例外。
在分散式系統中,由於⽹絡問題你不清楚沒接收到⼼跳,是因為對⽅真正掛了還是隻是因為負載過重沒來得及發⽣⼼跳或是⽹絡堵塞。所以⼀般會約定⼀個時間,超時即判定對⽅掛了。⽽在kafka消費者場景中,session.timout.ms引數就是規定這個超時時間是多少。
還有⼀個引數,heartbeat.interval.ms,這個引數控制傳送⼼跳的頻率,頻率越⾼越不容易被誤判,但也會消耗更多資源。
此外,還有最後⼀個引數,max.poll.interval.ms,消費者poll資料後,需要⼀些處理,再進⾏拉取。如果兩次拉取時間間隔超過這個引數設定的值,那麼消費者就會被踢出消費者組。也就是說,拉取,然後處理,這個處理的時間不能超過max.poll.interval.ms這個引數的值。這個引數的預設值是5分鐘,⽽如果消費者接收到資料後會執⾏耗時的操作,則應該將其設定得⼤⼀些。
總結:
session.timout.ms控制⼼跳超時時間。heartbeat.interval.ms控制⼼跳傳送頻率。max.poll.interval.ms控制poll的間隔。
這⾥給出⼀個相對較為合理的設定,如下:
session.timout.ms:設定為6sheartbeat.interval.ms:設定2smax.poll.interval.ms:推薦為消費者處理訊息最⻓耗時再加1分鐘
2.7 其他消費者引數設定
| 設定項 | 說明 |
|---|---|
| bootstrap.servers | 建⽴到Kafka叢集的初始連線⽤到的host/port列表。 使用者端會使⽤這⾥指定的所有的host/port來建⽴初始連線。 這個設定僅會影響發現叢集所有節點的初始連線。 形式:host1:port1,host2:port2... 這個設定中不需要包含叢集中所有的節點資訊。 最好不要設定⼀個,以免設定的這個節點宕機的時候連不上。 |
| group.id | ⽤於定義當前消費者所屬的消費組的唯⼀字串。 如果使⽤了消費組的功能 subscribe(topic),或使⽤了基於Kafka的偏移量管理機制,則應該設定group.id。 |
| auto.commit.interval.ms | 如果設定了enable.auto.commit的值為true,則該值定義了消費者偏移量向Kafka提交的頻率。 |
| auto.offset.reset | 如果Kafka中沒有初始偏移量或當前偏移量在伺服器中不存在(⽐如資料被刪掉了): earliest:⾃動重置偏移量到最早的偏移量。 latest:⾃動重置偏移量到最後⼀個 none:如果沒有找到該消費組以前的偏移量沒有找到,就拋異常。 其他值:向消費者拋異常。 |
| fetch.min.bytes | 伺服器對每個拉取訊息的請求返回的資料量最⼩值。 如果資料量達不到這個值,請求等待,以讓更多的資料累積,達到這個值之後響應請求。 預設設定是1個位元組,表示只要有⼀個位元組的資料,就⽴即響應請求,或者在沒有資料的時候請求超時。 將該值設定為⼤⼀點⼉的數位,會讓伺服器等待稍微⻓⼀點⼉的時間以累積資料。 如此則可以提⾼伺服器的吞吐量,代價是額外的延遲時間。 |
| fetch.max.wait.ms | 如果伺服器端的資料量達不到fetch.min.bytes的話,伺服器端不能⽴即響應請求。該時間⽤於設定伺服器端阻塞請求的最⼤時⻓。 |
| fetch.max.bytes | 伺服器給單個拉取請求返回的最⼤資料量。 消費者批次拉取訊息,如果第⼀個⾮空訊息批次的值⽐該值⼤,訊息批也會返回,以讓消費者可以接著進⾏。 即該設定並不是絕對的最⼤值。 broker可以接收的訊息批最⼤值通過 message.max.bytes(broker設定)或max.message.bytes(主題設定)來指定。需要注意的是,消費者⼀般會並行拉取請求。 |
| enable.auto.commit | 如果設定為true,則消費者的偏移量會週期性地在後臺提交。 |
| connections.max.idle.ms | 在這個時間之後關閉空閒的連線。 |
| check.crcs | ⾃動計算被消費的訊息的CRC32校驗值。 可以確保在傳輸過程中或磁碟儲存過程中訊息沒有被破壞。 它會增加額外的負載,在追求極致效能的場合禁⽤。 |
| exclude.internal.topics | 是否內部主題應該暴露給消費者。如果該條⽬設定為true,則只能先訂閱再拉取。 |
| isolation.level | 控制如何讀取事務訊息。 如果設定了 read_committed,消費者的poll()⽅法只會返回已經提交的事務訊息。如果設定了 read_uncommitted(預設值),消費者的poll⽅法返回所有的訊息,即使是已經取消的事務訊息。⾮事務訊息以上兩種情況都返回。 訊息總是以偏移量的順序返回。 read_committed只能返回到達LSO的訊息。在LSO之後出現的訊息只能等待相關的事務提交之後才能看到。結果, read_committed模式,如果有為提交的事務,消費者不能讀取到直到HW的訊息。read_committed的seekToEnd⽅法返回LSO。 |
| heartbeat.interval.ms | 當使⽤消費組的時候,該條⽬指定消費者向消費者協調器傳送⼼跳的時間間隔。 ⼼跳是為了確保消費者對談的活躍狀態,同時在消費者加⼊或離開消費組的時候⽅便進⾏再平衡。 該條⽬的值必須⼩於 session.timeout.ms,也不應該⾼於session.timeout.ms的1/3。可以將其調整得更⼩,以控制正常重新平衡的預期時間。 |
| session.timeout.ms | 當使⽤Kafka的消費組的時候,消費者週期性地向broker傳送⼼跳資料,表明⾃⼰的存在。 如果經過該超時時間還沒有收到消費者的⼼跳,則broker將消費者從消費組移除,並啟動再平衡。 該值必須在broker設定 group.min.session.timeout.ms和group.max.session.timeout.ms之間。 |
| max.poll.records | ⼀次調⽤poll()⽅法返回的記錄最⼤數量。 |
| max.poll.interval.ms | 使⽤消費組的時候調⽤poll()⽅法的時間間隔。 該條⽬指定了消費者調⽤poll()⽅法的最⼤時間間隔。 如果在此時間內消費者沒有調⽤poll()⽅法,則broker認為消費者失敗,觸發再平衡,將分割區分配給消費組中其他消費者。 |
| max.partition.fetch.bytes | 對每個分割區,伺服器返回的最⼤數量。消費者按批次拉取資料。 如果⾮空分割區的第⼀個記錄⼤於這個值,批次處理依然可以返回,以保證消費者可以進⾏下去。 broker接收批的⼤⼩由 message.max.bytes(broker引數)或max.message.bytes(主題引數)指定。fetch.max.bytes⽤於限制消費者單次請求的資料量。 |
| send.buffer.bytes | ⽤於TCP傳送資料時使⽤的緩衝⼤⼩(SO_SNDBUF),-1表示使⽤OS預設的緩衝區⼤⼩。 |
| retry.backoff.ms | 在發⽣失敗的時候如果需要重試,則該設定表示使用者端等待多⻓時間再發起重試。 該時間的存在避免了密集迴圈。 |
| request.timeout.ms | 使用者端等待伺服器端響應的最⼤時間。如果該時間超時,則使用者端要麼重新發起請求,要麼如果重試耗盡,請求失敗。 |
| reconnect.backoff.ms | 重新連線主機的等待時間。避免了重連的密集迴圈。 該等待時間應⽤於該使用者端到broker的所有連線。 |
| reconnect.backoff.max.ms | 重新連線到反覆連線失敗的broker時要等待的最⻓時間(以毫秒為單位)。 如果提供此選項,則對於每個連續的連線失敗,每臺主機的退避將成倍增加,直⾄達到此最⼤值。 在計算退避增量之後,新增20%的隨機抖動以避免連線⻛暴。 |
| receive.buffer.bytes | TCP連線接收資料的快取(SO_RCVBUF)。-1表示使⽤作業系統的預設值。 |
| partition.assignment.strategy | 當使⽤消費組的時候,分割區分配策略的類名。 |
| metrics.sample.window.ms | 計算指標樣本的時間窗⼝。 |
| metrics.recording.level | 指標的最⾼記錄級別。 |
| metrics.num.samples | ⽤於計算指標⽽維護的樣本數量 |
| interceptor.classes | 攔截器類的列表。預設沒有攔截器攔截器是消費者的攔截器,該攔截器需要實現org.apache.kafka.clients.consumer.ConsumerInterceptor接⼝。攔截器可⽤於對消費者接收到的訊息進⾏攔截處理。 |
三、 消費組管理
3.1 消費者組的概念
consumer group是kafka提供的可延伸且具有容錯性的消費者機制。
三個特性:
- 消費組有⼀個或多個消費者,消費者可以是⼀個程序,也可以是⼀個執行緒
group.id是⼀個字串,唯⼀標識⼀個消費組- 消費組訂閱的主題每個分割區只能分配給消費組⼀個消費者。
3.2 消費者位移(consumer position)
消費者在消費的過程中記錄已消費的資料,即消費位移(offset)資訊。
每個消費組儲存⾃⼰的位移資訊,那麼只需要簡單的⼀個整數表示位置就夠了;同時可以引⼊checkpoint機制定期持久化。
3.3 位移管理(offset management)
⾃動VS⼿動
Kafka預設定期⾃動提交位移(enable.auto.commit = true),也⼿動提交位移。另外kafka會定期把group消費情況儲存起來,做成⼀個offset map,如下圖所示:
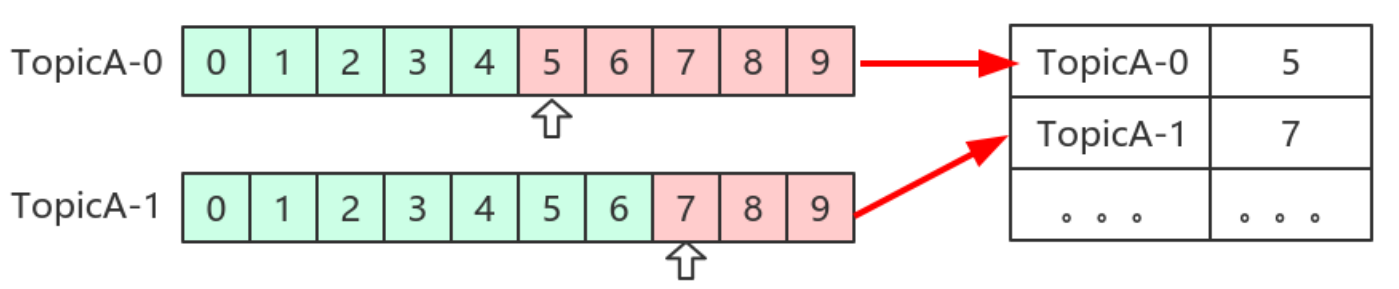
位移提交
位移是提交到Kafka中的__consumer_offsets主題。__consumer_offsets中的訊息儲存了每個消費組某⼀時刻提交的offset資訊。
[root@localhost kafka_2.12-1.0.2]# kafka-console-consumer.sh --topic __consumer_offsets --bootstrap-server localhost:9092 --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --consumer.config /usr/src/kafka_2.12-1.0.2/config/consumer.properties --from-beginning | head
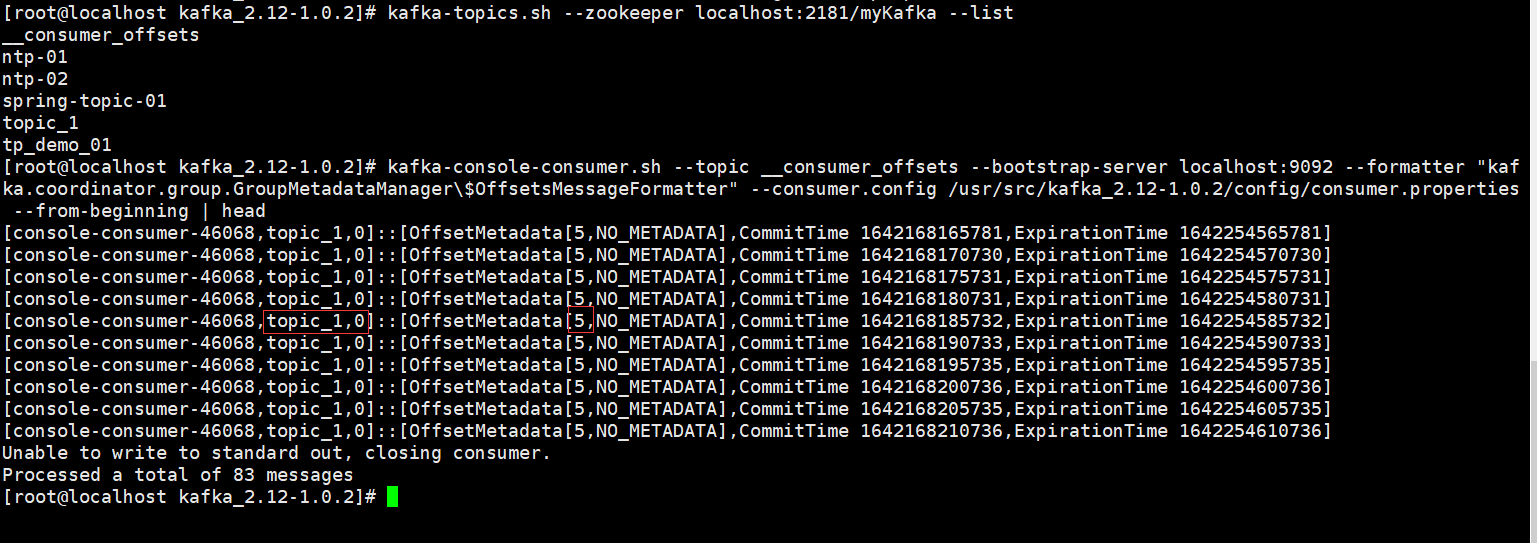
上圖中,標出來的,表示消費組為console-consumer-46068,消費的主題為topic_1,消費的分割區是0,偏移量為5。
__consumers_offsets主題設定了compact策略,使得它總是能夠儲存最新的位移資訊,既控制了該topic總體的⽇志容量,也能實現儲存最新offset的⽬的。
3.4 再談再平衡
什麼是再平衡:
再均衡(Rebalance)本質上是⼀種協定,規定了⼀個消費組中所有消費者如何達成⼀致來分配訂閱主題的每個分割區。
⽐如某個消費組有20個消費組,訂閱了⼀個具有100個分割區的主題。正常情況下,Kafka平均會為每個消費者分配5個分割區。這個分配的過程就叫再均衡。
什麼時候再平衡:
再均衡的觸發條件:
- 組成員發⽣變更(新消費者加⼊消費組組、已有消費者主動離開或崩潰了)
- 訂閱主題數發⽣變更。如果正規表示式進⾏訂閱,則新建匹配正規表示式的主題觸發再均衡。
- 訂閱主題的分割區數發⽣變更
如何進行組內分割區分配:
三種分配策略:RangeAssignor和RoundRobinAssignor以及StickyAssignor
誰來執⾏再均衡和消費組管理:
Kafka提供了⼀個⻆⾊:Group Coordinator來執⾏對於消費組的管理。
Group Coordinator——每個消費組分配⼀個消費組協調器⽤於組管理和位移管理。當消費組的第⼀個消費者啟動的時候,它會去和Kafka Broker確定誰是它們組的組協調器。之後該消費組內所有消費者和該組協調器協調通訊。
如何確定coordinator:
-
確定消費組位移資訊寫⼊
__consumers_offsets的哪個分割區。具體計算公式:_consumers_offsets partition# = Math.abs(groupId.hashCode() % groupMetadataTopicPartitionCount)注意:groupMetadataTopicPartitionCount由offsets.topic.num.partitions指定,預設是50個分割區。 -
該分割區leader所在的broker就是組協調器。
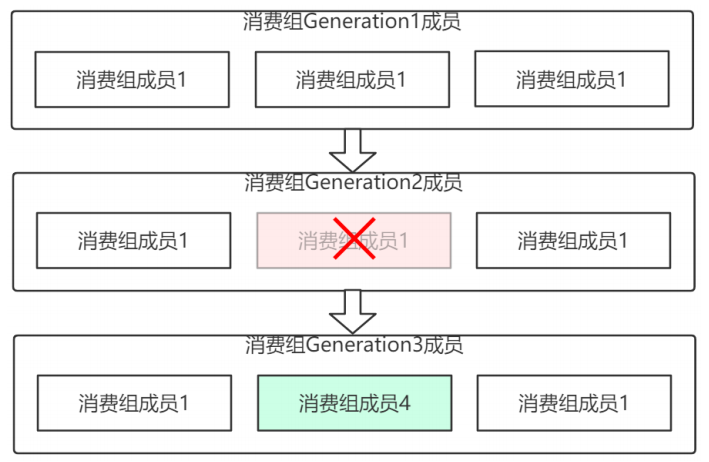
Rebalance Generation:
它表示Rebalance之後主題分割區到消費組中消費者對映關係的⼀個版本,主要是⽤於保護消費組,隔離⽆效偏移量提交的。如上⼀個版本的消費者⽆法提交位移到新版本的消費組中,因為對映關係變了,你消費的或許已經不是原來的那個分割區了。每次group進⾏Rebalance之後,Generation號都會加1,表示消費組和分割區的對映關係到了⼀個新版本,如下圖所示: Generation 1時group有3個成員,隨後成員2退出組,消費組協調器觸發Rebalance,消費組進⼊Generation 2,之後成員4加⼊,再次觸發Rebalance,消費組進⼊Generation 3.
協定(protocol)
kafka提供了5個協定來處理與消費組協調相關的問題:
- Heartbeat請求:consumer需要定期給組協調器傳送⼼跳來表明⾃⼰還活著
- LeaveGroup請求:主動告訴組協調器我要離開消費組
- SyncGroup請求:消費組Leader把分配⽅案告訴組內所有成員
- JoinGroup請求:成員請求加⼊組
- DescribeGroup請求:顯示組的所有資訊,包括成員資訊,協定名稱,分配⽅案,訂閱資訊等。通常該請求是給管理員使⽤
組協調器在再均衡的時候主要⽤到了前⾯4種請求。
liveness
消費者如何向消費組協調器證明⾃⼰還活著?
通過定時向消費組協調器傳送Heartbeat請求。如果超過了設定的超時時間,那麼協調器認為該消費者已經掛了。⼀旦協調器認為某個消費者掛了,那麼它就會開啟新⼀輪再均衡,並且在當前其他消費者的⼼跳響應中新增「REBALANCE_IN_PROGRESS」,告訴其他消費者:重新分配分割區。
再均衡過程
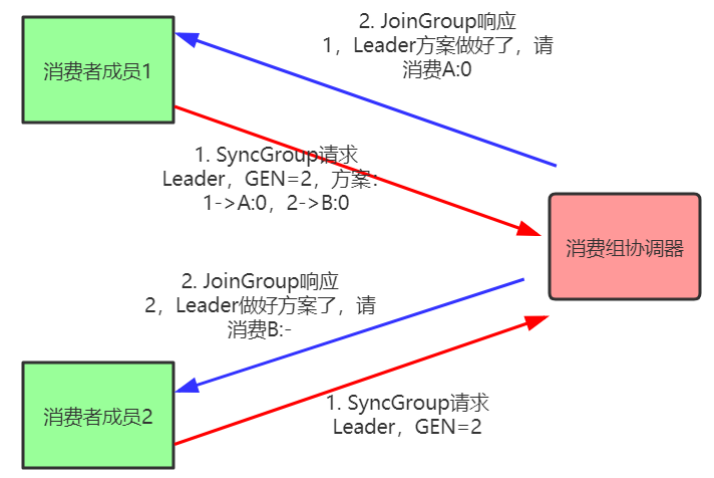
再均衡分為2步:Join和Sync
- Join, 加⼊組。所有成員都向消費組協調器傳送JoinGroup請求,請求加⼊消費組。⼀旦所有成員都傳送了JoinGroup請求,協調i器從中選擇⼀個消費者擔任Leader的⻆⾊,並把組成員資訊以及訂閱資訊發給Leader。
- Sync,Leader開始分配消費⽅案,即哪個消費者負責消費哪些主題的哪些分割區。⼀旦完成分配,Leader會將這個⽅案封裝進SyncGroup請求中發給消費組協調器,⾮Leader也會發SyncGroup請求,只是內容為空。消費組協調器接收到分配⽅案之後會把⽅案塞進SyncGroup的response中發給各個消費者。
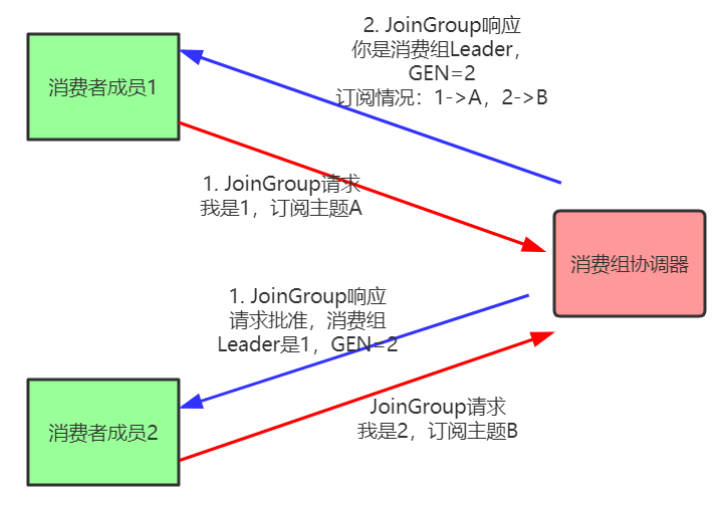
注意:在協調器收集到所有成員請求前,它會把已收到請求放⼊⼀個叫purgatory(煉獄)的地⽅。然後是分發分配⽅案的過程,即SyncGroup請求:
消費組狀態機
消費組組協調器根據狀態機對消費組做不同的處理:
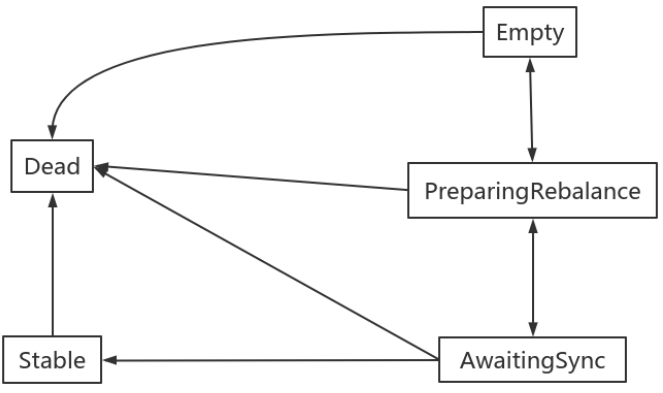
說明:
- Dead:組內已經沒有任何成員的最終狀態,組的後設資料也已經被組協調器移除了。這種狀態響應各種請求都是⼀個response: UNKNOWN_MEMBER_ID
- Empty:組內⽆成員,但是位移資訊還沒有過期。這種狀態只能響應JoinGroup請求
- PreparingRebalance:組準備開啟新的rebalance,等待成員加⼊
- AwaitingSync:正在等待leader consumer將分配⽅案傳給各個成員
- Stable:再均衡完成,可以開始消費。