MySQL中讀頁緩衝區buffer pool
Buffer pool
我們都知道我們讀取頁面是需要將其從磁碟中讀到記憶體中,然後等待CPU對資料進行處理。我們直到從磁碟中讀取資料到記憶體的過程是十分慢的,所以我們讀取的頁面需要將其快取起來,所以MySQL有這個buffer pool對頁面進行快取。
首先MySQL在啟動時會向作業系統申請一段連續的記憶體空間,這一段空間就是作為buffer pool所用。將快取的頁放入buffer pool中管理起來。
mysql> show variables like 'innodb_buffer_pool_size';
+-------------------------+-----------+
| Variable_name | Value |
+-------------------------+-----------+
| innodb_buffer_pool_size | 134217728 |
+-------------------------+-----------+
1 row in set, 1 warning (0.00 sec)
我們可以看到預設是134217728位元組,即128MB。一個頁面是16KB,我們申請16KB倍數的快取區大小就不會產生碎片。
buffer pool組成
同時呢,在buffer pool中還有包含每個頁面的控制資訊,即控制塊。每個控制塊對應管理每一個頁面 (我們使用地址參照每一個頁面) ,控制塊用來儲存頁面的一些資訊,控制塊的佔用大小不包括在innodb_buffer_pool_size中。由MySQL在啟動時自己額外申請空間。
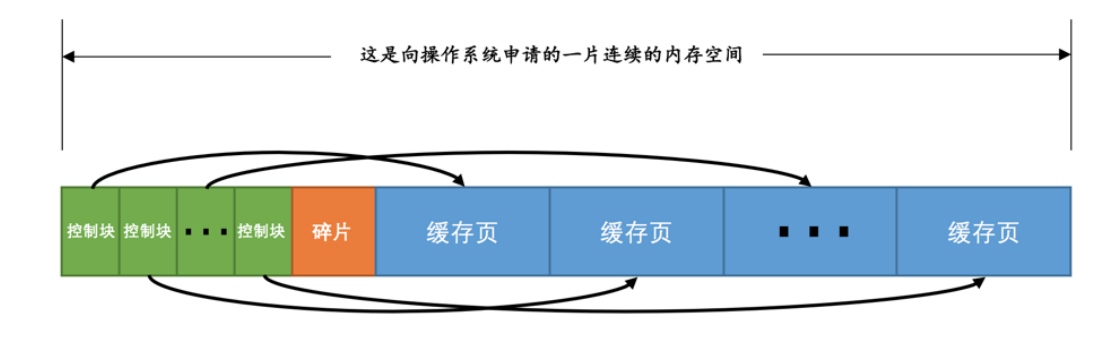
在控制塊和快取頁中間會有部分碎片,就是空間無法全部利用的產生的碎片。因為MySQL向作業系統申請的記憶體空間需要申請一定大小的控制塊空間,不能確定具體的大小,難免回有無法利用的空間。
free連結串列
free連結串列顧名思義,就是管理空閒的快取頁的連結串列,如果快取頁沒有被使用,其控制塊就會連線到free連結串列上。
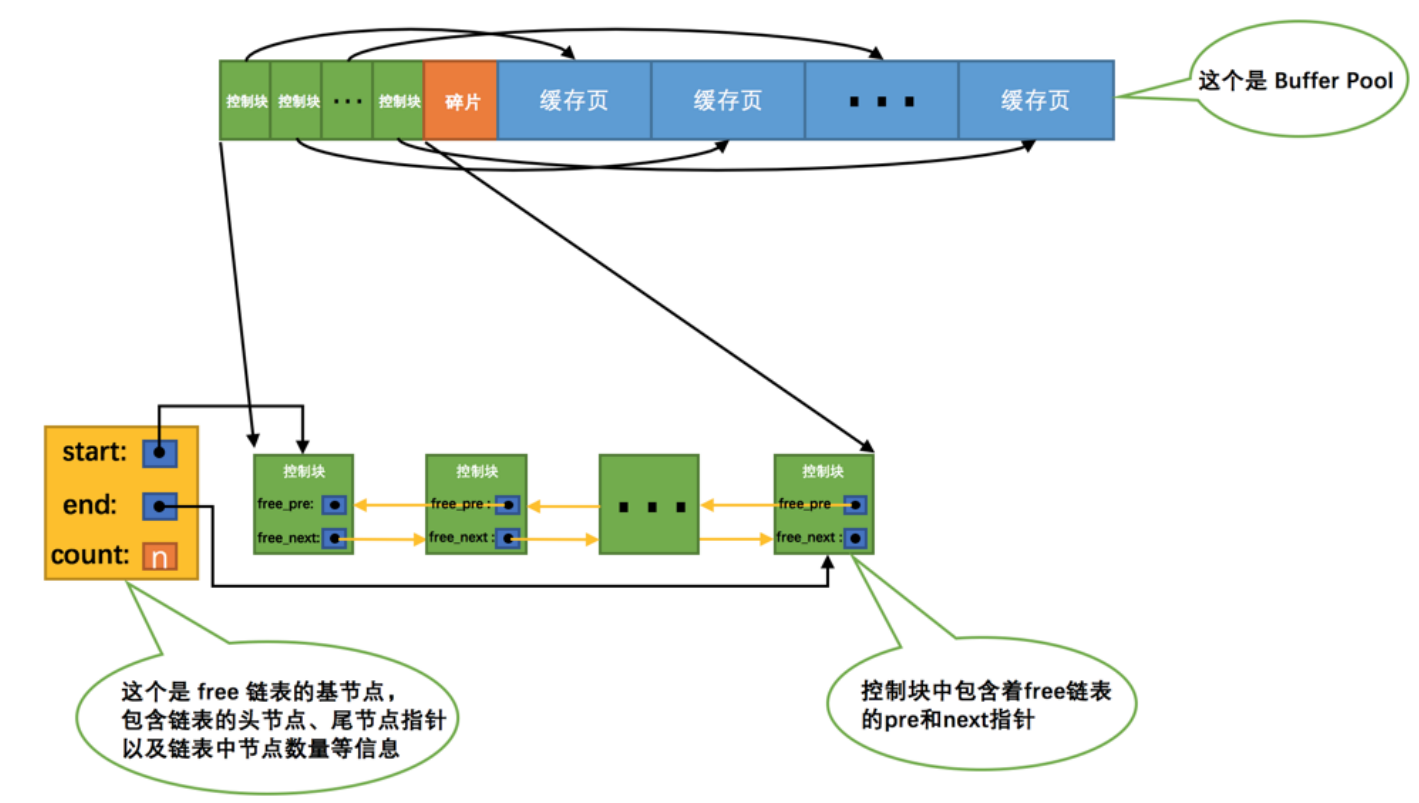
通過一個基節點連線控制塊形成一個free連結串列,並儲存空閒頁的數量等基本資訊。
當我們從磁碟讀取一個頁到buffer pool中,就會取一個空閒的控制塊填上對應快取頁的基本資訊。
快取頁的雜湊處理
MySQL在buffer pool中怎麼快速存取一個頁,以及檢視對應頁有沒有被快取到buffer pool中呢?
這就是用到雜湊表,在Java中就是hashmap,通過表空間+頁號做處理形成一個hash的key值,然後value值就是快取頁在buffer pool中的地址。
flush連結串列的管理
學習到這一章節的時候我震驚了,首先確實和我的理解是不一樣的,以及到後面的MVCC確實讓我大開眼界,這是我學習一遍後回頭做的總結,所以比較言簡意賅哈。
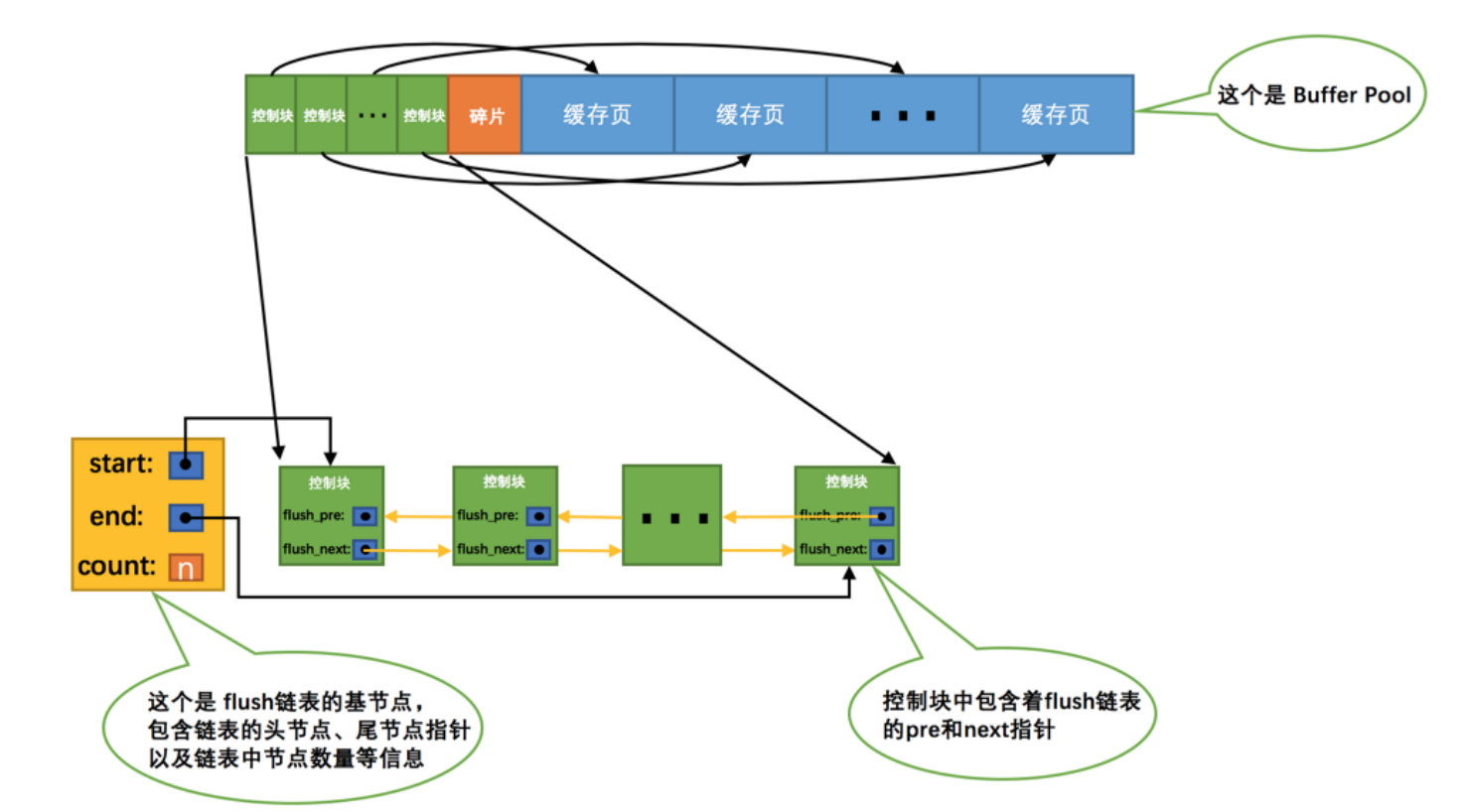
我們使用SQL語句對某條記錄進行修改的時候,就會修改某個頁面或者多個頁面,我們對於頁面的修改呢,並不會直接對磁碟進行對應的修改,因為對於磁碟IO實在是太慢了,我們首先會將修改的頁面(簡稱髒頁)鏈起來,就和free連結串列差不多,就是一個基節點將對應髒頁的控制塊連線在一起。
這個flush連結串列就代表我們即將還沒有將頁面更新到磁碟的連結串列。
LRU連結串列
因為buffer pool的大小是有限的,所以我們對於快取頁的大小是有限的,所以我們需要將不用的頁面進行一個淘汰。MySQL採用的就是LRU的方式進行淘汰。
LRU就是最久未使用淘汰的策略,我們使用一個連結串列將快取頁面鏈起來,最近存取的出現在最前面,最久未存取的在連結串列末尾,當LRU滿了新頁面都進來機會淘汰連結串列尾部頁面。
我們直接使用LRU,當MySQL進行預讀或者全表掃描出現大量低頻頁面被讀進LRU連結串列,會導致高頻的頁面直接被淘汰掉了,取而代之的是一些不經常用的頁面。
預讀就是MySQL優化器認為當前請求可能會讀取的頁面,預先將其載入到記憶體的buffer pool中。可以分為兩種:
線性預讀
當讀取一個區的頁面超過系統變數innodb_read_ahead_threshold的值預設為56,也就是說當我們讀取一個區的頁面超過56頁,MySQL就會非同步的讀取下一個區的所有頁面到記憶體中。
隨機預讀
如果buffer pool已經快取了某個區的13個頁面,不管是不是順序的,只要有13頁快取了,就會觸發MySQL非同步讀取本區的所有頁面到MySQL中。我們可以控制關閉隨機預讀,也就是系統變數innodb_random_read_ahead。預設是OFF。
所以出現了改進基於分割區的LRU連結串列,將連結串列分為兩份。
一個是使用頻率非常高的young區域,一個是使用頻率不是很高的old區。
正常來說old區佔比是37%,所以young區就佔63%,我們可以通過innodb_old_blocks_pct來修改,預設就是37。
我們來講講這個基於分割區的LRU連結串列。
- 首先buffer pool初始化,會將讀取的頁面直接放進old區。
- 但是如果我們對於同一個頁面的多條記錄進行存取的話,我們就會多次存取同一頁多次。但是如果我們是全表掃描的話,是可能會將所有頁面快取進快取池中的,所以MySQL對於其進行優化。
- 所以MySQL對於當頁面第一次讀入old區並在一定時間間隔(innodb_old_blocks_pct)內的多次存取來說是不會將其放入young區進行快取的。innodb_old_blocks_pct的值預設為1000,就是剛來的來一秒內的多次存取是不會將其轉移到young區的。
- 如果多次存取就會將old區的頁升級到young區。當young區的頁面被存取,只有young連結串列後1/4的頁面被存取時才會將其轉置到young區連結串列頭,不然就不會改動,減少一些調整連結串列的效能損失。
重新整理髒頁
MySQL會啟動後臺執行緒進行髒頁,也就是修改的頁面進行重新整理到磁碟。
以下有兩種方式重新整理髒頁:
- 從LRU的尾部掃描一些頁面,重新整理其中的髒頁到磁碟中。
- 後臺執行緒會從LRU連結串列中old區域尾部,即不經常使用的頁面中查詢有沒有髒頁,有就更新到磁碟。可以更改系統變數innodb_lru_scan_depth來控制掃描區域尾部的數量。
- 從flush連結串列中更新到磁碟。
- 我們上面說了flush連線這髒頁的控制塊,我們就可以將連線這flush連結串列的髒頁進行更新。
疑問:為什麼要兩種方式更新呢?我剛開始不懂這是我回過頭來看的時候就懂了
首先我們髒頁是快取在buffer pool中的,但是我們buffer pool空間是有限的,又因為我們使用的是LRU的方式,又因為從flush連結串列將髒頁同步到磁碟效率實在不高,所以不會很經常去更新髒頁。如果我們不更新直接將其從LRU的連結串列拋棄也就是從快取池中直接扔了,但是它是髒頁就無法同步到磁碟了,同時flush連結串列連結的也會出現問題。
所以在LRU淘汰很久未使用的頁有個前提就是它不是一個髒頁。所以我們會去檢測LRU連結串列尾部有沒有髒頁,然後更新它,我們才能去淘汰掉這些頁。
flush連結串列更新那就是它的本職工作了,它存這個也是幹這個的,應該沒有什麼問題。
當系統十分繁忙,buffer pool使用量不足的時候,因為磁碟IO太慢了,所以會出現一種情況,就是大量的使用者執行緒也在進行這個同步髒頁的活。不同步髒頁然後淘汰buffer pool的頁面,沒法讀取頁面啊。
多個buffer pool範例
我們可以設定多個buffer pool來實現多範例提高效能。
mysql> show variables like 'innodb_buffer_pool_instances';
+------------------------------+-------+
| Variable_name | Value |
+------------------------------+-------+
| innodb_buffer_pool_instances | 1 |
+------------------------------+-------+
1 row in set, 1 warning (0.00 sec)
我們可以設定innodb_buffer_pool_instances系統變數來控制範例變數。
但是當buffer pool的大小小於1G的時候,設定2個範例也是沒有用的(會被恢復成1個),多範例的情況是建立在大記憶體的情況下的。
動態調整buffer pool大小
在MySQL5.7.5後,MySQL中的buffer pool的大小是以chunk來分配了,如下圖。
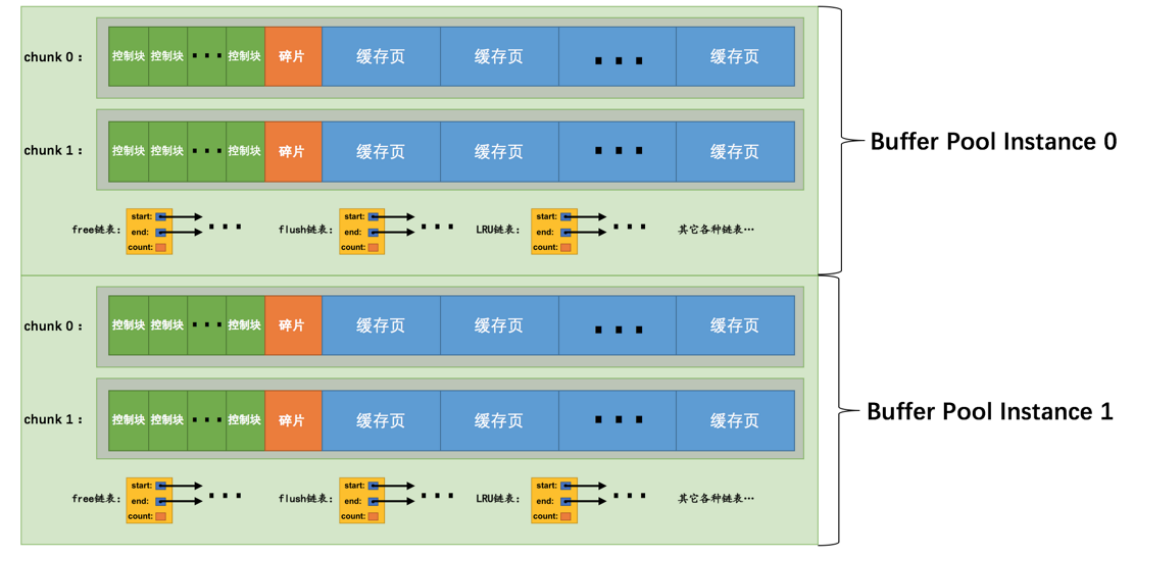
一個buffer pool是由多個chunk組成的,所以MySQL向作業系統申請連續的記憶體空間,就是以chunk的方式來申請的,這樣我們可以在MySQL執行時調整buffer pool的大小。但是chunk的大小是不能在執行時更改的,這樣是很耗費效能的。?
innodb_buffer_pool_size / innodb_buffer_pool_instances = 每個範例buffer pool的大小。
每個範例的大小 / innodb_buffer_pool_chunk_size = 每個範例由多少個chunk構成。
不是弄很明白,怎麼動態調整大小,我調整了但是mysqld佔用記憶體大小還是隻能重啟才能生效,我不會。
檢視buffer pool具體的資訊
show engine innodb status;