模型評估與改進:交叉驗證
2022-05-27 06:01:02
⭐為什麼要劃分測試集與訓練集?
- 用測試集度量模型對未見過資料的泛化效能
⭐交叉驗證
- 資料被多次劃分,需要訓練多個模型
- 最常用K折交叉驗證
-
k是使用者指定的數位,通常取0/5,
-
5折交叉驗證:資料劃分為5部分,每一部分叫做折。每一折依次輪流作為測試集,其餘做訓練集
mglearn.plots.plot_cross_validation()
-

1、scikit-learn中的交叉驗證
利用model_selection中的cross_val_score(模型,訓練資料,真實標籤)
#在iris資料上,利用logisticregre進行評估
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score
iris = load_iris()
lrg = LogisticRegression()
scores = cross_val_score(lrg,iris.data,iris.target)
print("cross_validation scores:{}".format(scores))
'''
`cross_validation scores:[0.96666667 1. 0.93333333 0.96666667 1. ]`
'''
預設情況下,cross_val_score執行3折交叉驗證,可通過修改cv值改變折數
#總結交叉驗證精度:計算平均值
print("Average cross-validation:{:.2f}".format(scores.mean()))
'''
`Average cross-validation:0.97`
'''
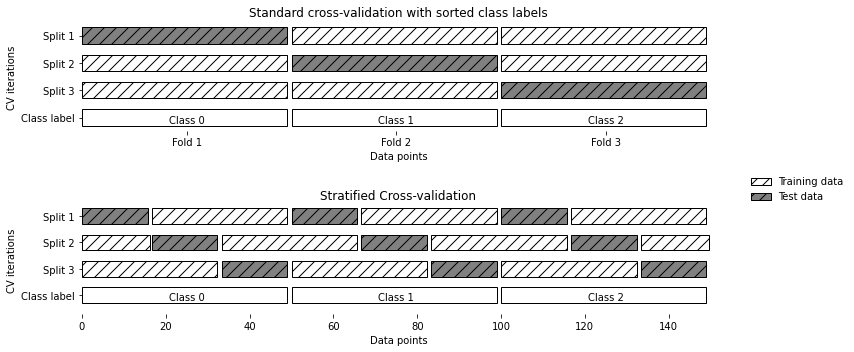
2、分層k折交叉驗證和其它策略
⭐sklearn裡面的交叉驗證
-
分類問題時使用:分層交叉驗證
- 使每個折中類別之間的比例與整個資料集中的比例相同
-
迴歸問題:標準k折交叉驗證
mglearn.plots.plot_stratified_cross_validation()
2.1 對交叉驗證的更多控制
⭐可以用cv來調節cross_val_score的折數
-
sklearn還提供一個交叉驗證分離器(cross_validatoin splitter)作為cv引數
#在分類資料集上使用標準K折交叉驗證 #需要從model_selection匯入KFold分離器類,並將其範例化 from sklearn.model_selection import KFold kf = KFold(n_splits=5) #5折 scores = cross_val_score(lrg,iris.data,iris.target,cv=kf) print("cross_validation scores:{}".format(scores)) ''' `cross_validation scores:[1. 1. 0.86666667 0.93333333 0.83333333]` ''' kf = KFold(n_splits=3) #3折 scores = cross_val_score(lrg,iris.data,iris.target,cv=kf) print("cross_validation scores:{}".format(scores)) ''' `cross_validation scores:[0. 0. 0.]` '''