基於資訊檢索和深度學習結合的單元測試用例斷言自動生成
摘要:本章節介紹基於IR的方法(包括基礎的資訊檢索技術IRar以及自動適配技術RAadapt)和結合的方法。
本文分享自華為雲社群《基於資訊檢索和深度學習結合的單元測試用例斷言自動生成》,作者:華為雲軟體分析Lab 。
一、背景介紹
單元測試用來驗證軟體基本模組的準確性。跟其他層次的測試(比如整合測試和系統測試)相比,單元測試可以更快地幫助軟體系統發現錯誤。同時在單元測試階段發現錯誤可以大大降低整個軟體測試流程的測試開銷雖然單元測試很重要,但是編寫單元測試用例往往很費時間。
為了減輕開發者編寫單元測試用例的負擔,軟體測試領域的研究者提出多個單元測試用例自動生成工具,來為開發者編寫的程式自動生成測試用例。這些工具從生成測試輸入的角度可以分為如下三類:(1)隨機測試,比如Randoop[3],它使用帶反饋的執行機制來收集執行路徑。(2)動態符號執行,比如JBSE[4],它通過動態符號執行技術來為複雜物件提供測試輸入。(3)基於搜尋,比如Evosuite[5],它應用遺傳演演算法來生成和優化滿足測試覆蓋標準的測試輸入。
上述測試用例自動生成工具除了可以自動生成測試輸入之外,還可以自動生成斷言。這些工具從生成斷言角度可以分為如下兩類:(1)捕獲執行然後進行斷言生成[6],比如Evosuite和Randoop都是通過在已經生成的測試序列的基礎上,執行這些序列,然後捕獲跟待測方法相關的物件狀態的值,作為assertion中的值。(2)差異測試[7],比如DiffGen[8]通過在同一個類的兩個版本上執行測試方法,然後通過比較函數呼叫返回值以及物件的中間狀態來是否相同來生成多言。
雖然上述的測試用例生成工具可以生成斷言,但是它生成的斷言在找bug的能力方面非常受限。對於給定的一個版本,這些工具生成的斷言只能找崩潰型別的bug,無法找邏輯相關的bug。為了更好地生成斷言,近期Watson等人[2]提出ATLAS來生成斷言。ATLAS是一個基於深度學習的方法,它通過給定的待測方法以及測試方法(除去斷言部分),來生成斷言。本文將待測方法以及測試方法(除去斷言部分)簡稱為focal-test方法。在訓練階段ATLAS使用focal-test方法作為輸入,使用資料對應的斷言作為label來訓練模型。然而ATLAS的效果受限於兩個方面,第一,ATLAS基於深度學習,其可解釋型不強。第二,ATLAS生成斷言的準確率不夠高(只有31%),並且ATLAS在生成長assertion(長度大於15個token)的效果很差,只有18%。
為了解決上述提到的問題,本文提出使用基於資訊檢索的方法IR(包含基礎的資訊檢索技術IRar以及基於資訊檢索結果的自動適配技術RAadapt)來提升斷言生成的準確性,除了基於資訊檢索的方法,本文同樣提出一個結合方法來將IR和基於深度學習的方法(比如ATLAS)進行結合,進一步提升斷言生成的準確度。本文在兩個資料集上評估本文提出的方法跟ATLAS的對比,實驗結果表明本文提出的方法在兩個資料集上的準確率比ATLAS分別高15.12%和20.54%。
二、方法
本章節介紹本文提出的基於IR的方法(包括基礎的資訊檢索技術IRar以及自動適配技術RAadapt)和結合的方法。圖1展示了本文提出的方法的整體流程圖。給定一個Focal-test方法,本文首先通過IRar技術到訓練集中檢索最相似的Focal-test方法,並將其對應的assertion作為檢索到的assertion返回。接著本文提出自動適配技術RAadapt,RAadapt技術包括兩個適配策略:基於啟發式搜尋(RAadaptH)的適配和基於神經網路(RAadaptNN)的適配。最後本文基於相容模型提出一個結合的方法,來智慧的選擇應用適配完之後生成的assertion還是應用基於深度學習方法(ATLAS)生成的assertion。文字方法部分的詳細介紹請參見本文發表在國際軟體工程會議的論文[1]。
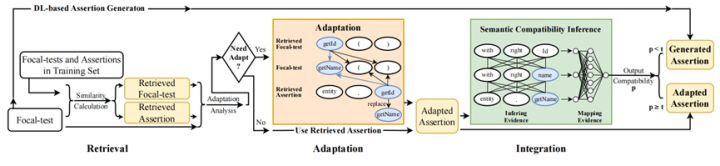
圖1 本文提出的斷言生成的方法流程圖
2.1 IRar

2.2 RAadapt

2.3 Integration
本文通過計算測試集中的focal-test、模型生成的assertion以及基於資訊檢索方法生成的assertion的相容度來決定使用模型生成assertion還是使用基於資訊檢索的方法生成assertion。
三、實驗設定
3.1 實驗資料集
表1詳細展示了本文用到的兩個資料集中斷言類別及個數的分佈情況。

3.1.1 Datasetold
本文將ATLAS使用的資料集記為Datasetold,它是從GitHub的開源專案中挖掘得到。Datasetold將所有assertion中存在的token但是沒有出現在focal-test方法中的資料全部去掉因為ATLAS無法為這些資料成功生成斷言。最終Datasetold包含156,760條資料,並以8:1:1劃分訓練集、驗證集和測試集。
3.1.2 Datasetnew
實際上ATLAS使用的Datasetold資料集是去掉了有挑戰性的資料,進而簡化了斷言生成任務的評估。因此本文進一步通過將ATLAS去掉的資料加回到資料集中來構造一個更有挑戰性的資料集,本文將該資料集記為Datasetnew。最終Datasetold包含265,420條資料,並以8:1:1劃分訓練集、驗證集和測試集。
3.2 評估指標
本文使用的評估指標更ATLAS一致,使用準確率和BLEU值來評估本文提出的方法的有效性。
3.2.1 準確率
本文認為生成的斷言準確的標準是斷言在字串級別完全相等。
3.2.2 BLEU值
BLEU值在自然自然語言處理領域被廣泛使用,它用來評估生成的句子跟標註的句子的相似性。本文使用BLEU值來評估本文方法生成的斷言跟標註的斷言的相似性。
四、實驗結果
4.1 IRar方法的有效性
4.1.1 IRar方法整體效果分析
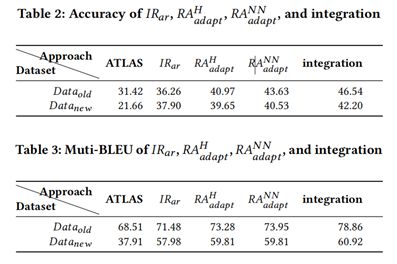
表2和表3的第三列展示了IRar方法在兩個資料集上的準確率和BLEU值,從表中可以看到在兩個資料集上,IRar方法在準確率和BLEU值上的表現都要明顯優於ATLAS。

表4展示了IRar和ATLAS在每個斷言類別上的準確率,從表中可以看到IRar在每個斷言類別上的準確率都要優於ATLAS,進一步證明了IRar方法的有效性。
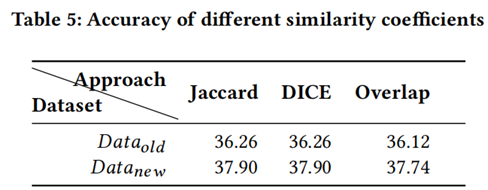
表5展示了IRar使用不同相似度係數檢索的準確率,從表中可以看到不同的相似性係數對IRar的準確率影響不大,證明了IRar方法的普適性。
4.1.2 ATLAS和IRar成功生成的assertion
為了進一步研究ATLAS和IRar生成的assertion,我們首先分析ATLAS和IRar成功生成的assertion。
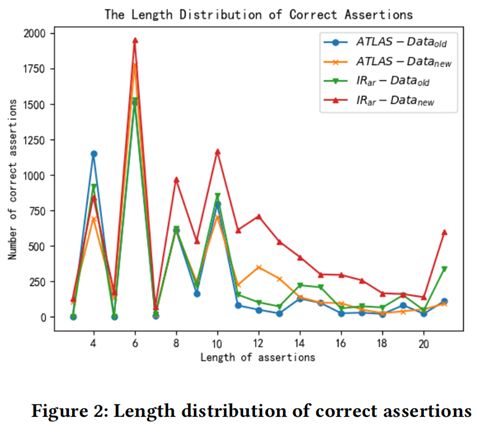
圖2展示了ATLAS和IRar成功生成的斷言語句的平均長度。從圖中可以看出,在生成長的斷言語句時,IRar比ATLAS效果更好。本文統計發現,在Datasetold資料集上,ATLAS和IRar成功生成的斷言語句的長度平均分別為7.98和8.63,在Datasetnew資料集上,ATLAS和IRar成功生成的斷言語句的長度平均分別為9.74和10.74。
接著本文分析ATLAS成功生成的斷言語句中,有多少出現在訓練集中(IRar生成的斷言語句肯定全部都出現在訓練集中)。經過統計本文發現,ATLAS正確生成的斷言語句中,絕大多數都在訓練集中出現過(其中Datasetold資料集中92.59%,Datasetnew資料集中98.76%)。實驗結果表明ATLAS成功生成「新」的斷言的能力還很弱。
4.1.3 ATLAS和IRar不能成功生成的assertion
在研究了ATLAS和IRar能成功生成的斷言之後,本文接著分析ATLAS和IRar不能成功生成的斷言。
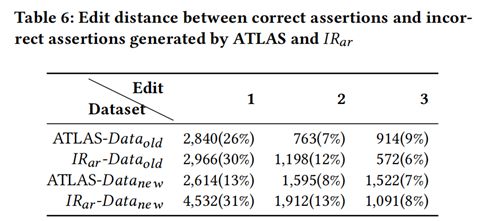
表6展示了ATLAS和IRar不能成功生成的斷言距離標註斷言的編輯距離。從表中可以看到,約40%-50%不能成功生成的斷言可以在修改三個token的情況下將其改對。
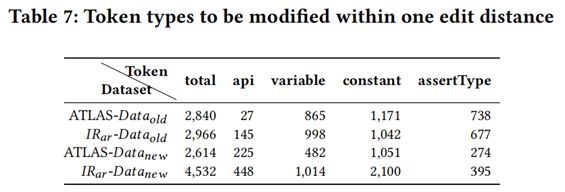
表7展示了當編輯距離為1時,該token的類別。從表中可看到,常數是最需要開發者主要修改的地方。
4.2 RAadapt方法的有效性
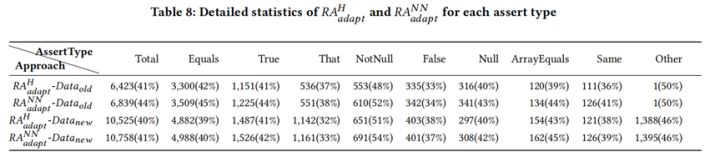
表8展示了RAadaptH和RAadaptNN在不同斷言型別的準確率,實驗結果表明RAadaptH和RAadaptNN在不同斷言型別上的準確率都高於ATLAS,同時RAadaptNN可以達到最高的準確率。
4.3 結合方法的有效性
4.3.1 基於資訊檢索方法和基於深度學習方法的互補性
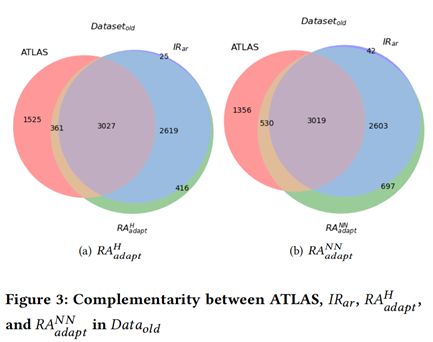
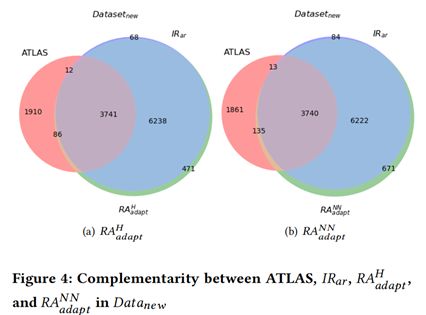
圖3和圖4分別展示了基於資訊檢索方法和基於深度學習方法在兩個資料集上的的互補性。從圖中我們可以看到,兩種方法存在很強的互補性。因此本文進一步提出了結合的方法。
4.3.2 結合方法的準確率

表9展示了本文提出的結合的方法在不同斷言型別的準確率,實驗結果表明結合方法可以在兩個資料集上達到最好的效果
五、 總結
本文首次嘗試在斷言生成中利用資訊檢索 (IR),並提出了一種基於 IR 的方法,包括IRar技術和RAadapt技術。本文還提出了一種結合方法,用於結合基於 IR 的方法和基於 DL 的方法(例如 ATLAS),以進一步提高有效性。本文的實驗結果表明,IRar要比ATLAS 更有效,在兩個資料集上分別達到 36.26% 和 37.90% 的準確率。此外,本文的RAadapt技術可以在兩個資料集上分別達到 43.63% 和 40.53% 的準確率。最後,結合的方法在兩個資料集上實現了 46.54% 和 42.20% 的準確率。本文的工作傳達了一個重要資訊,即基於 IR 的方法對於軟體工程任務(如斷言生成)具有競爭力且值得追求,鑑於近年來DL解決方案已經過分流行,研究社群應該認真考慮如果更準確有效地將DL用於軟體工程任務。
文章來自北京大學、華為雲PaaS技術創新Lab;PaaS技術創新Lab隸屬於華為雲(華為內部當前發展最為迅猛的部門之一,目前國內公有云市場份額第二,全球第五),致力於綜合利用軟體分析、資料探勘、機器學習等技術,為軟體研發人員提供下一代智慧研發工具服務的核心引擎和智慧大腦。我們將聚焦軟體工程領域硬核能力,不斷構築研發利器,持續交付高價值商業特性!加入我們,一起開創研發新「境界」!(招聘介面人:[email protected]; [email protected];)
PaaS技術創新Lab主頁連結:https://www.huaweicloud.com/lab/paas/home.html
參考文獻
- Hao Yu, Yiling Lou, Ke Sun, Dezhi Ran, Tao Xie, Dan Hao, Ying Li, Ge Li, Qianxiang Wang. 2022. Automated Assertion Generation via Information Retrieval and Its Integration with Deep Learning. In Proceedings of the 42th IEEE/ACM International Conference on Software Engineering (ICSE), https://taoxiease.github.io/publications/icse22-assertion.pdf
- Cody Watson, Michele Tufano, Kevin Moran, Gabriele Bavota, and Denys Poshyvanyk. 2020. On Learning Meaningful Assert Statements for Unit Test Cases. In Proceedings of the 42th IEEE/ACM International Conference on Software Engineering (ICSE). 1398–1409. https://doi.org/10.1145/3377811.3380429
- Carlos Pacheco and Michael D. Ernst. 2007. Randoop: Feedback-Directed Random Testing for Java. In Companion to the 22nd ACM SIGPLAN Conference on ObjectOriented Programming Systems and Applications Companion (OOPSLA). 815–816. https://doi.org/10.1145/1297846.129790
- Pietro Braione, Giovanni Denaro, and Mauro Pezzè. 2016. JBSE: A Symbolic Executor for Java Programs with Complex Heap Inputs. In Proceedings of the 24th ACM SIGSOFT International Symposium on Foundations of Software Engineering (ESEC/FSE). 1018–1022. https://doi.org/10.1145/2950290.2983940
- Gordon Fraser and Andrea Arcuri. 2011. EvoSuite: Automatic Test Suite Generation for Object-Oriented Software. In Proceedings of the 19th ACM SIGSOFT Symposium and the 13th European Conference on Foundations of Software Engineering (ESEC/FSE). 416–419. https://doi.org/10.1145/2025113.2025179
- Tao Xie. 2006. Augmenting Automatically Generated Unit-Test Suites with Regression Oracle Checking. In Proceedings of the 20th European Conference on Object-Oriented Programming (ECOOP). 380–403. https://doi.org/10.1007/11785477_23
- Robert B. Evans and Alberto Savoia. 2007. Differential Testing: A New Approach to Change Detection. In Proceedings of the 6th Joint Meeting on European Software Engineering Conference and the ACM SIGSOFT Symposium on the Foundations of Software Engineering: Companion Papers (ESEC/FSE). 549–552. https://doi.org/10.1145/1295014.1295038
- Kunal Taneja and Tao Xie. 2008. Automated Regression Unit-Test Generation. In Proceedings of the 23rd IEEE/ACM International Conference on Automated Software Engineering (ASE). 407–410. https://doi.org/10.1109/ASE.2008.60