mysql怎麼查詢慢的sql語句
方法:1、若未開啟慢查詢,用「set global slow_query_log='ON';」開啟慢;2、用「set global slow_query_log_file=路徑」設定慢查詢檔案儲存位置;3、用「subl 路徑」查詢檔案即可。

本教學操作環境:centos 7系統、mysql8.0.22版本、Dell G3電腦。
mysql怎麼查詢慢的sql語句
Mysql中 查詢慢的 Sql語句的記錄查詢
慢查詢紀錄檔 slow_query_log,是用來記錄查詢比較慢的sql語句,通過查詢紀錄檔來查詢哪條sql語句比較慢,這樣可以對比較慢的sql可以進行優化。
登陸mysql資料庫:
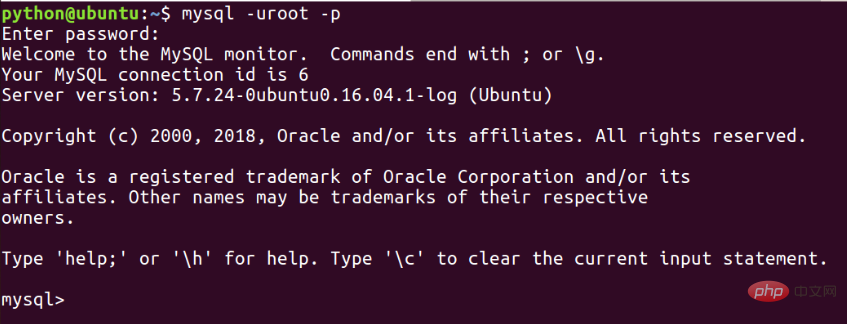
1、檢視一下當前的慢查詢是否開啟,若未開啟則開啟
以及慢查詢所規定的時間:
show variables like 'slow_query_log'; show variableslike 'long_query_time';
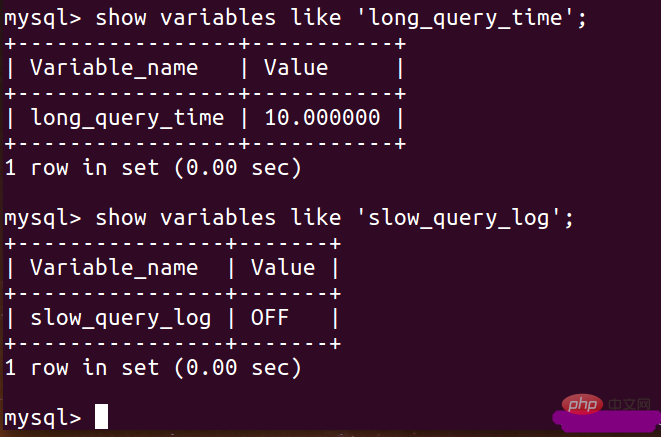
如果你的查詢後的結果是OFF 狀態的話,就需要通過相關設定將其修改為ON狀態:
set global slow_query_log='ON';
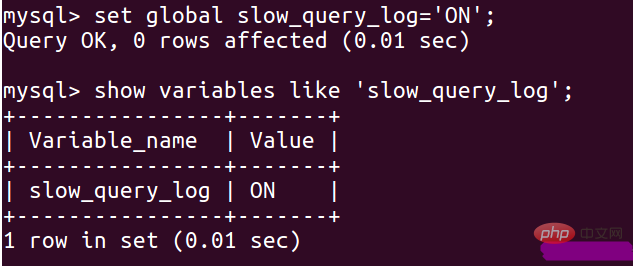
將慢查詢追蹤的時間設定為1s:
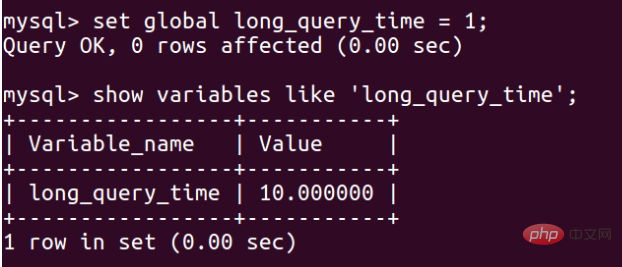
這裡你在設定之後,這個世界是不會立即變成1s的,需要在資料庫重新啟動後才生效:
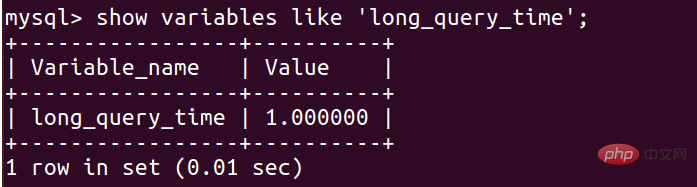
2、設定慢查詢紀錄檔檔案儲存的位置:
set global slow_query_log_file='/var/lib/mysql/test_1116.log';
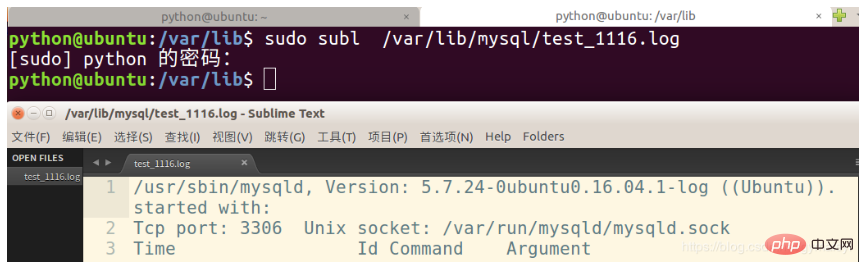
3、 檢視以下設定後的檔案:
sudo subl /var/lib/mysql/test_1116.log
擴充套件知識:
MySQL資料庫慢查詢問題排查方法
最近碰到了幾次資料庫響應變慢的問題,整理了一下處理的流程和分析思路,執行指令碼。希望對其他人有幫助。
MySQL慢查詢表現
明顯感覺到大部分的應用功能都變慢,但也不是完全不能工作,等待比較長的時間還是有響應的。但是整個系統看起來就非常的卡。
查詢慢查詢數量
一般來說一個正常執行的MySQL伺服器,每分鐘的慢查詢在個位數是正常的,偶爾飆升到兩位數也不是不能接受,接近100系統可能就有問題了,但是還能勉強用。這幾次出問題慢查詢的數量已經到了1000多。
慢查詢的數量儲存在mysql庫裡面的slow_log表。
SELECT * FROM `slow_log` where start_time > '2019/05/19 00:00:00';
這樣就能查出一天以來的慢查詢了。
檢視當前進行的查詢狀態
大家應該都比較常用show processlist來檢視當前系統中正在執行的查詢,其實這些資料也儲存在information_schema庫裡面的processlist表,因此如果要做條件查詢,直接查詢這張表更方便。
比如檢視當前所有的process
select * from information_schema.processlist
檢視當前正在進行的查詢並按照已經執行時間倒排
select * from information_schema.processlist where info is not null order by time desc
正常執行的資料庫,因為一條查詢的執行速度很快,被我們的select抓到的info不是null的查詢數量會很少。我們這樣負荷很大的庫一般也就只能查到幾條。如果一次能查到info非空的查詢有幾十條,那麼也可以認為系統出問題了。
系統問題和定位
當我們察覺到系統變慢之後,馬上用慢查詢和檢視processlist的方式做了檢查,結果發現每分鐘慢查詢數量飆升到1000多,同時淤積了大量的查詢在執行中。
因為當務之急是儘快恢復系統的正常執行,因此影響最直接的做法是在processlist的查詢結果中,檢視有多少哪些查詢處於lock狀態,或者已經執行了很長時間,把這些process用kill指令幹掉。通過不停的殺死這些可能會引發系統阻塞的process,最終能夠暫時讓系統逐步恢復到正常狀態,當然這只是權宜之計。
此外,最重要的當然是分析到底是哪些查詢為什麼會引發系統阻塞,我們還是使用慢查詢來做分析。
慢查詢表查詢結果裡面有幾個比較重要的指標:
start_time 開始時間,要通過這個引數,配合系統出問題的時間,定位哪些查詢是罪魁禍首。
query_time 查詢時間
rows_sent 和 rows_examined傳送的結果數以及查詢掃過的行數,這兩個值特別重要,特別是 rows_examined。基本上就能告訴我們,哪個查詢是需要注意的「大」查詢。
實際操作中,我們也是把有大量rows_examined的查詢一個個拿出來分析,新增索引,修改查詢語句的編寫,來徹底的解決問題。
處理結果和反思
經過對所有慢查詢的檢查和整改,目前MySQL每分鐘慢查詢數徘徊在1~2之間,CPU的負荷也非常低。問題算是基本得到了解決。
反思一下問題出現的原因,有幾個地方需要注意:
1,資料庫出問題往往不是上線即引發問題,而是有一個累積的過程,不斷累加的糟糕的查詢語句會逐步增加系統負載,最後壓倒駱駝的最後一根稻草往往看上去莫名其妙
2,最後的一根稻草甚至有可能根本不存在,不是一次發版或者是功能上線,而是隨著使用者使用量上升,資料量的累積而爆發
3,既然問題的出現是累積的過程,就需要在每次程式碼發版之前做好review
4,索引的新增很重要
5,慢查詢的監控也需要納入到Zabbix的監控範圍
推薦學習:
以上就是mysql怎麼查詢慢的sql語句的詳細內容,更多請關注TW511.COM其它相關文章!